A Systematic Study of Knowledge Distillation for Natural Language Generation with Pseudo-Target Training
논문 정보
- Date: 2023-09-12
- Reviewer: 전민진
- Property: Knowledge Distillation
0. Abstract
-
Natural Lnaguage Generation(NLG)의 경우, 많은 연산량과 저장 공간이 필요
-
실제 산업에 활용할 때 이를 효율적으로 압축해 사용할 수 있는지 보기 위해 knowledge distillation(KD) method에 집중해 여러 가지 실험을 진행, 최적의 KD setting을 제안
- KD : 작은 student모델이 큰 teacher model을 따라하도록 학습해 teacher에서 student로 knowledge transfer를 유도하는 방법
-
특히, NLG distillation의 특성상 exposure bias problem을 해소할 수 있는 방법론인 Joint-Teaching method를 제안
- teacher와 student에서 생성된 여러 개의 pseudo-target(PT)을 활용해 word-level KD
1. Introduction
-
KD는 큰 모델에서 작은 모델로 knowledge를 transfer시키는 방법론으로, 일반적인 태스크에서 KD는 word-level 혹은 sequence-level로 적용될 수 있음
-
KD 연구는 광범위하게 진행되어 왔지만, NLU task에 집중되거나, task agnostic language modeling에, specific generation task(e.g. NMT)에 국한됨
- 특히, NLG에선 label있는 데이터가 있다고 가정하고 연구
-
본 논문에서는 NLG를 위한 KD에 대해서 체계적으로 연구
-
다양한 task에 대해서 실험 : summarization, Question Generation, Abductive Reasoning, Style Transfer and Simplificatoin
-
현실적인 setting을 가정
-
3-4천 개의 labled examples이 학습에 이용 가능한 경우(medium-resource)
-
대량의 unlabeld data
-
사전 학습된 모델 바로 사용
-
inference-time efficiency를 유의미한 compressing의 지표로 사용
-
한 번 학습하는데 드는 비용은 inference-time에 비해선 무시할만하다 가정
-
-
-
메인 연구는 중간 크기의 labled data로 medium size LM을 fine-tune한 걸 teacher로 사용하는 상황을 가정으로 함
- GPT4를 사용하는 경우도 실험하긴 하나 main은 아님
-
본 논문은 모델 구조를 비교하는 것을 시장으로, pruning, KD design decision, computational resource와 task performance사이의 tradeoff를 살펴보는 순서로 구성
- practical measure로는 latency와 throughtput에 집중
-
이후로, word-level의 KD에서 teacher와 student에서 생성된 PT를 사용하는 방법론인 Joint-Teaching을 제안
- student exposure bias를 내재적, 외재적으로 다루는게 목표
-
마지막으로 GPT4를 활용해 huge LM을 할용해 small Encoder-decoder model을 KD하는 실험을 진행
- tokenizer가 달라서 시도해봤다는 것에 의의가 있음
-
주된 실험 결과는 다음과 같음
-
Encoder-decoder 구조가 Decoder-only 구조보다 NLG의 task-specific fine-tuning setting에서는 더 뛰어난 성능을 보임
-
Decoder를 pruning하는게 encoder를 pruning하는거보다 latency, task performance측면에서 더 뛰어남
-
PT를 사용하는게 훨씬 더 효과적
-
2. Related Work
-
Exposure Bias
-
LM은 distribution P(y s,y_{<i})를 학습하는데, 이 방식을 teacher forcing이라 함 -
teacher forcing때문에, training과 inference 사이에 discrepancy가 발생하게 되는데, 이를 exposure bias라 함
- exposure bias때문에, inference시 토큰이 하나 잘못 생성되면 casacading effect를 끼친다는 문제가 있음
-
이러한 문제를 reinforcement learnign technique를 활용해 해결하거나, scheduled sampling(ground truth token을 generated token으로 교체)하는 방법론이 제안됨
- 하지만 이러한 방식의 경우, inaccurate, noisy signal로 학습하게 된다는 한계 존재
- KD setting에서 PT를 활용해, reliable signal을 사용함으로써 student exposure bias를 줄일 수 있음
-
-
Compression and Knowledge Distillation
-
model compression을 위해서 다양한 방법론이 제안됨
-
parameter sharing, pruning, quantization, factorization 등
-
pruning : pre-trained 혹은 fine-tuned LM의 가중치에서 중요하지 않은 부분을 버리는 방법
-
-
original과 compressed model사이의 성능 차이를 줄이기 위해 knowledge distillation(KD)를 사용
-
KD는 크게 2가지로 분류 가능 : task-agnostic, task-specific
- 전자는 pre-trained LM를, 후자는 fine-tuned LM를 따라하는 것
-
KD에는 3개의 단계가 존재 : word-level( or class-level), inner-level, sequence-level(only in NLG)
-
Word-level KD : logits KD로도 알려져 있으며, steduent와 teacher의 next token prediction에 사용되는 distribution의 차를 줄이도록 설계
-
L{log}(x,y) = -\sum{i=1}^{ y }KL(P*S(y_i x,y*{<i}) P*T(Y_i x,y*{<i})) -
variation으로 Noisy KD가 있음
-
KD동안에 teacher에 dropout를 적용
-
L{NoisyKD}=\sum{t=1}^{T}KL(\hat p*T^\alpha(y_t y*{1}^{t-1},x),P_S(y_t y_1^{t-1},\tilde x))
-
-
-
Inner-level KD : 추가적으로 teacher의 inner feature를 따라하는 것
-
Attention-relation KD는 self-attention states의 relation matrix(scaled dot-product)를 따라하도록 설계됨
-
L{AR} = \frac{1}{A{h} x } \sum{a=1}^{A_h}\sum{t=1}^{ x }D{KL}(A^T{L,a,t} A^S_{L,a,t}) (self attention distribution) -
L{VR} = \frac{1}{A{h} x } \sum{a=1}^{A_h}\sum{t=1}^{ x }D{KL}(VR^T{L,a,t} VR^S_{L,a,t}) - VR^T{L,a} = softmax(\frac{V^T{L,a}{V^T_{L,a}}^T}{\sqrt{d_k}})(value-relation attention)
-
-
-
Sequence-level KD
-
original dataset에서 input에 대해서 teacher가 PT를 생성, student는 이를 예측하도록 학습
-
이 때, teacher는 single PT를 beam search를 사용해 생성, 이를 P_T(y x)의 mode approximation이라 함 - 실험에서는 생성된 PT를 \hat y^T라 할 때, L{NLL}(x,\hat y^T)+L{NLL}(x,y)를 사용
-
-
-
-
3. Proposed Method
- Research Design
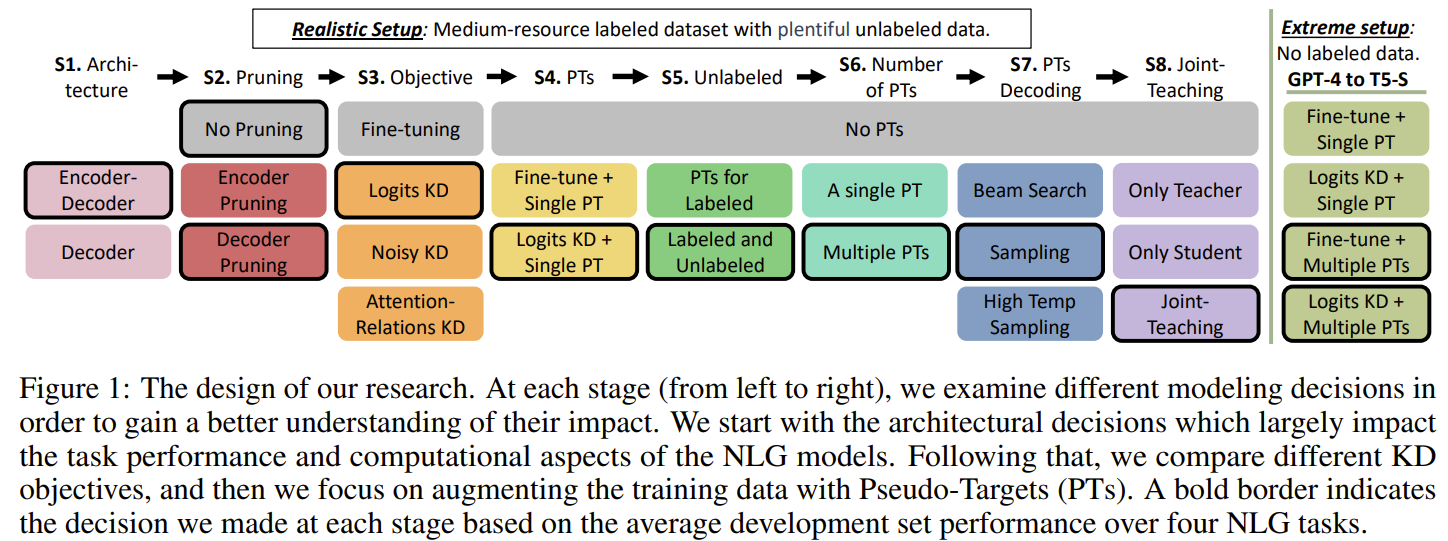
-
stage1-2에서는 architectural design로 시작, stage 3-4에서는 다양한 KD strategy들을 비교, stage 5-8에서는 KD를 위한 augemntation strategy로 PT 사용에 대한 실험 진행
-
각 단계에서 성능이 제일 좋은 setting을 다음 stage에서 계속 사용
- 검은선으로 굵게 표기된 박스가 채택된 setting을 뜻함
-
Architectuures and Pruning - stage 1,2
-
Decoder-only(DO)와 Encoder-Decoder(ED)에서의 성능 차이 확인(stage 1)
-
pruning의 효과를 확인하기 위해 encoder or decoder layer를 pruning(맨 앞과 맨 뒤를 제외한 중간 layer 삭제)(stage 2)
-
-
Objectives - stage 3
-
Conditional Language Modeling(fine-tuning)
-
L*{NLL}(x,y) = -logP(y x) = -\sum*{i=1}^{ y }logP(y*i x,y*{<i})
-
-
Logits KD(a.k.a Word-Lebel KD)
-
stage 3에서 사용
-
L{log}(x,y) = -\sum{i=1}^{ y }KL(P*S(y_i x,y*{<i}) P*T(Y_i x,y*{<i}))
-
-
Noisy KD, Attention Relation KD
- 위의 식 참고
-
이전 연구에 따라, KD method로 distillation stage후에 10 epoch정도 fine-tuning stage 거침
- teacher가 필요하지 않으므로 cheap
-
-
Pesudo-Target(a.k.a sequence-level KD) - stage 4
-
teacher로 생성한 prediction(Pseudo-Targets, PT)를 활용하여 student를 학습
-
word-level 혹은 inner-level KD가 sequence-level KD와 같이 사용될 수 있음
- Logit KD를 PT에 적용
-
본 논문에서는 single PT, multi PTs에 대한 실험을 진행
- 단 multi PT setting에서는 teacher에서 하나의 input에 대해서 beam search로 여러개의 PT를 생성, 각 PT를 하나씩, epoch마다 다른 PT를 사용해 학습
-
Fine-tune + PTs(a.k.a sequence-level KD)
- L{NLL}(x,\hat y^T)+L{NLL}(x,y)를 사용해 실험
-
Logits KD + PTs
-
Fine-tune + PTs와 같지만, L{NLL}이 아니라 L{log}를 minimize
-
L{log}(x,\hat y^T) + L{log}(x,y)
-
-
-
Unlabeled data - stage 5
-
일반적으로, student 모델에 input을 더 보여줄수록 labeled data distribution을 넘어서 더 일반화하는데에 도움을 줌
-
Logits KD + PTs for unlabeled inputs
- Logit KD + PTs와 같지만, 각각의 unlabeld input에 대해 single mode approximation PT 생성
-
-
Multiple PTs - stage 6
-
NLG는 structured prediction problem이고, 여러 후보가 정답을 형성할 수 있음
- 그래서 teacher의 knowledge에 더 잘 접근하기 위해 여러개의 PT생성
-
Logits KD + Multiple PTs
- 매 epoch마다 다른 single PT를 사용(각 input마다 K개의 PT를 생성했다면, PT를 다 보는데 K epoch이 걸림)
-
-
Sampling PTs - stage 7
-
beam search는 diversity가 부족하기 때문에 사용
-
Logits KD + Sampling Multiple PTs
- Logits KD + Multiple PTs와 동일하지만, beam search로 PT를 생성하는게 아니라 sampling, 각 epoch마다 다른 single PT가 sampled
-
Logits KD + High Temperature Sampling of Multiple PTs
-
Logits KD + sampling Multiple PTs와 동일하지만, PT를 sampling할 때, high temperature value사용(\tau = 1.5)
- 이렇게 하면 next token distribution이 flat하게 되어 더 diverse, suprising PT를 생성할 수 있음
-
-
-
Joint Teacheing - stage 8
-
teacher로 생성한 PT로 학습할 경우 내재적으로 student exposure bias를 줄일 수 있음
-
외재적으로도 exposure bias를 줄이기 위해, student로 PT를 생성해 이를 학습에 사용
-
이렇게 할 경우, 일반적으로 student가 자신의 실수를 학습해 unstable할 수 있지만, teacher가 있으므로 teacher의 distribution을 활용
-
즉, student가 생성한 PT에 대해서 teacher와 student모델이 생성하는 token prediction distribution의 차를 학습
- student가 generated sequence를 어떻게 맞게 계속 생성해야할지를 알려주면서 cascading effect를 예방
-
-
이를 위해, teacher model이 student model보다 더 낫다는 합리적인 가정이 필요
-
아래 장표는 초반의 x%를 student가 생성하고, 나머지를 teacher가 생성했을 때의 BLEU점수 변화
-
student를 학습할수록 teacher와 비슷해지긴 하지만, 항상 teacher가 student보다 더 낫다는 것을 보여줌
-
-
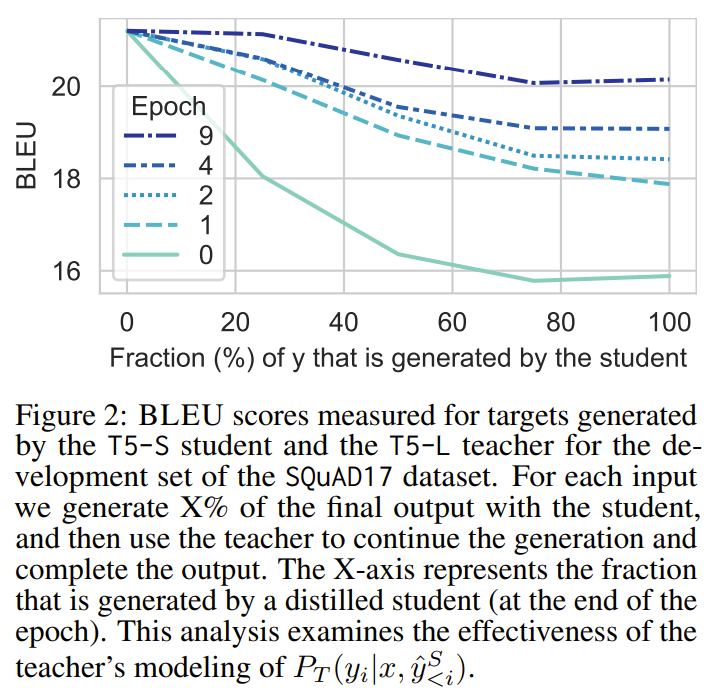
-
Logit KD + Student PTs
- L_{log}(x,\hat y^S)
-
결론적으로, teacher와 student에서 생성된 PT에 대해서 word-level KD를 적용, 실험에서는 student의 PT를 학습 과정의 50%에서 사용
-
Joint-Teaching
- \alpha L{log}(x,\hat y^T)+(1-\alpha)L{log}(x,\hat y^S)
-
4. 실험 및 결과
Task & Dataset
- 4가지 NLG task에 대해서 실험 진행
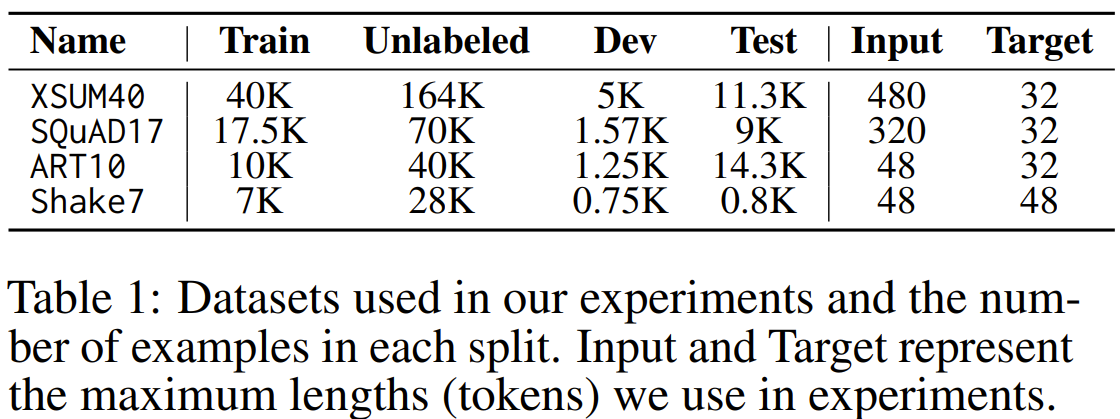
-
English-to-English core NLG task를 선택
-
labeled to unlabeled data의 비율을 1:4로 설정
-
Summarization(XSUM40), Question Generation(SQuAD17), Abductive Reasoning(ART10), Style Transfer and Simplification(Shake7),
-
abductive reasoning의 경우 2개의 observation이 주어질 때, plausible explanation을 생성하는 태스크
-
Style Transfer and Simplification의 경우 shakespeare’s text를 modern english로 번역하는 태스크
-
Models and Pruning
-
Decoder-only : GPT2, GPT-M, GPT-L, OPT-125M, OPT-350M 사용
-
Encoder-decoder : T5-S, T5-L, BART-6, BART-L 사용
-
Pruning : BART-6:6에서 pruning을 적용, encoder 혹은 decoder를 택해 맨 앞과 맨 뒤 레이어를 제외한 중간 레이어를 삭제
-
encoder를 pruning 했을 경우 BART-2:6
-
decoder를 pruning 했을 경우 BART-6:2
-
-
KD stage(3-8)에서는 T5-S, T5-L, BART-2:6, BART-L 사용
Evalution
-
Task performance
-
BLEU
-
average ROUGE(F1 scores for R-1/2/L)
-
BERTScore(F1 score)
-
PPL(=average NLL of the ground truth target)
-
-
Computational Performance
-
FLOPs(number of floating-poring operatoins)
-
latency of generation a single output
-
throughput(maximum number of examples that can be processed in a minute)
-
Result
-
S1 : Encoder-decoder model이 Decoder-only model보다 NLG의 task-specific tuning에서 더 뛰어남
-
물론, ED가 파라미터가 많은 편이지만 FLOPs는 같고 latency와 throughput을 보았을 때 비등, 성능은 전반적으로 높음
- T5-L와 GPT2를 보면, encoder-decoder모델의 parameter가 2배 많지만, FLOPs는 거의 동일, latency는 ED가 조금 느리지만 decoder-only모델이 memory footprint가 더 크기 때문에 throughput는 ED모델이 더 큼
-
-
S2 : decoder를 pruning하는게 더 낫다
-
BART-2:6과 BART-6:2를 비교해봤을 때, BART-6:2가 우월
-
아래 장표는 실선이 latency, 점선이 throughput를 나타내는데, throughput는 비슷하지만 latency측면에서 decoder를 pruning하는게 낫다는걸 알 수 있음
-
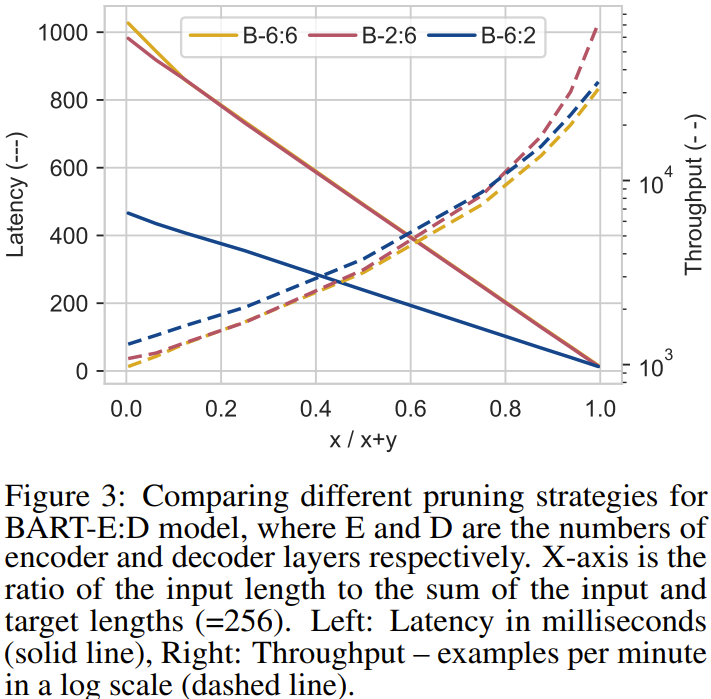
-
아래 장표는 stage마다 성능을 나타내는 장표
-
metric: \frac{KD-S}{T-S} \%, S = student fine-tuned, T = teacher fine-tuned(수치는 모든 pair와 metric 평균낸 값 사용)
-
Wins : 4 dataset, 4 metrics, 2 pairs (=442) 조합에서 이긴 횟수
-
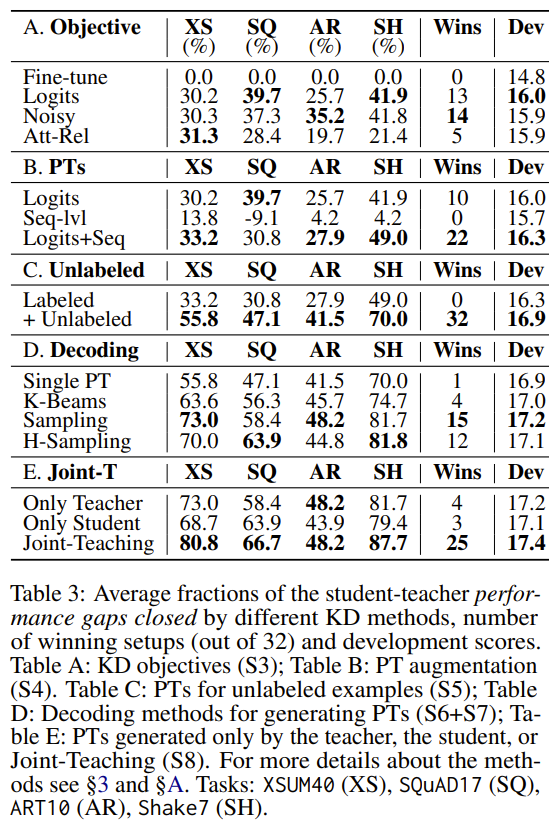
-
S3 : Logit KD를 main training objective로 사용하는게 낫다(A)
- Noisy와 비등비등하지만 Dev기준으로 봤을 때, Logits이 가장 성능이 좋음
-
S4 : Logits KD와 PT를 결합
- PT까지 함께 썼을 때, 성능이 더 좋음. 특히 Logits+Seq조합이 가장 높은 성능을 보임
-
S5 : Unlabled data를 함께 썼을 때 성능이 좋아짐
- unlabeled input에 대해 PT를 생성해서 쓰는 것이 teacher에 내재된 knowledge를 더 뽑아내는데 도움이 됨
-
S6 : multiple PT에 student를 노출시키는게 도움이 됨
- Single PT와 K-Beams를 비교해봤을 때, 후자가 성능이 훨신 높음
-
S7 : PT를 생성할 때 sampling하는게 beam search보다 나음
- D를 보면 Sampling, H-Sampling의 성능이 beam search보다 나음
-
S8 : Joint-Teaching이 student를 향상시킴
- Only teacher, only student와 비교했을 때, Joint-Teaching의 성능이 더 좋음
-
위의 장표는 Joint-Teaching으로 학습했을 때의 성능을 나타냄
- KD로 모델을 압축했을 때, teacher모델과 어느정도 비슷한 성능을 내면서 FLOPs나 latency, throughput부분에서 훨씬 향상됨
-
Extreme setup : KD with GPT-4
-
LLM with zero-shot capabilities을 teacher model로 사용할 때의 문제
-
teacher는 decoder only, student는 encoder-decoder model
-
teacher와 student의 tokenizer가 다름
-
teacher의 logit or output을 추출하는데 비용이 발생
-
-
본 논문에서는 GPT-4를 teacher model로, T5-S를 student로 사용
- GPT-4의 prompt는 3개의 labeled demonstractions로 구성
-
SQuAD17과 Sake7에 대해서만 실험 진행, 다음과 같은 베이스라인 구성
-
GPT-4 teacher
-
T5-S training with ground-truth(GT) labels
-
Student fine-tuning with a single PT
-
Fine-tuning with multiple(five) PTs
-
Student training with Logits and a single PT
-
Logits KD with multiple PTs
-
-
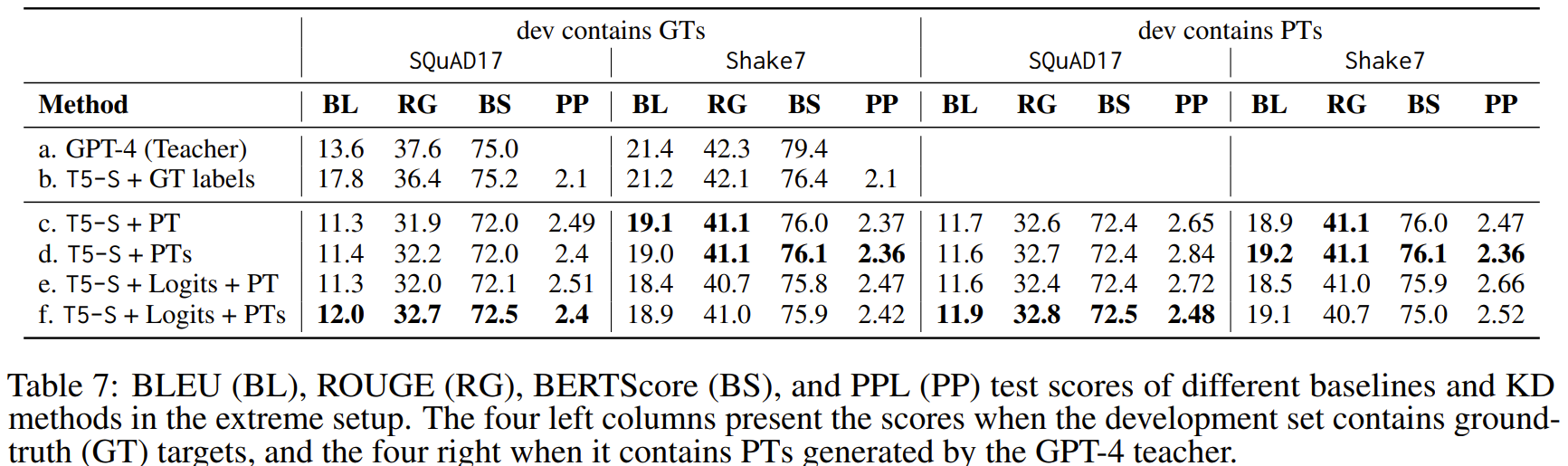
-
위의 장표를 보면, multiple PT가 single PT보다 뛰어나고, logitsKD의 경우 SQuAD17에서만 도움이 됨
-
tokenizer가 다른 문제 때문에 다음과 같은 방법론 사용
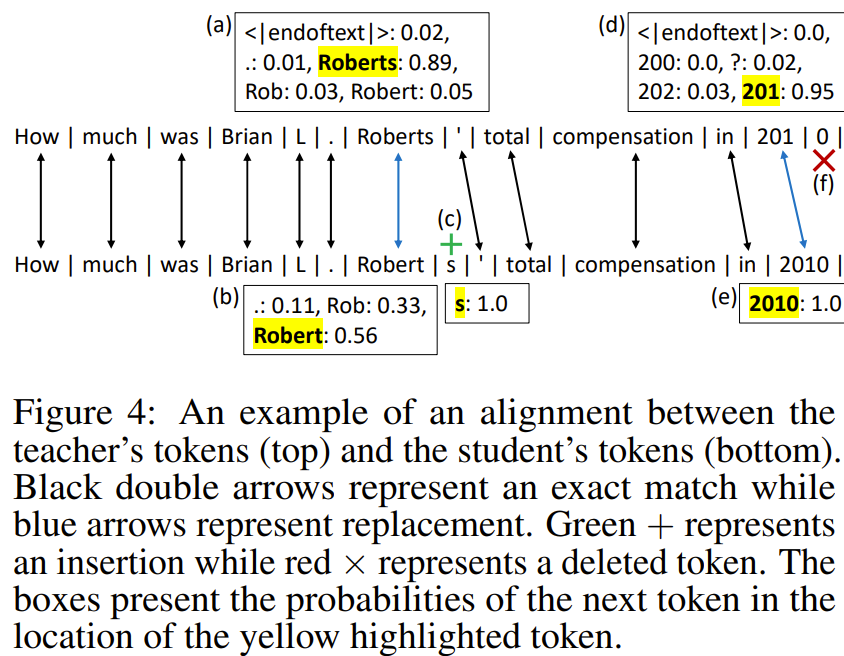
- Logits KD를 하기 위해서, next token의 logit의 확률이 필요, 즉, token alignment가 필수
- 1) teacher model의 tokenized PT sequence를 student의 tokenized PT sequence와 일치시는 것
- 2) teacher의 logit에서 student의 vocabulary에 있는 토큰과 일치시키는것
- 위의 그림을 보면, token alignment들이 검은색 혹은 파란색 화살표로 표시되어 있음
- 일부 토큰은 삽입(c)되거나 삭제(f)될 수 있음
- 이러한 mapping을 착기 위해 Needleman-Wunsch algorithm을 사용
- 이 알고리즘의 결괏값은 match, replacement, insertion, deletion과 같은 편집 연산의 시퀀스
- 두 토큰을 일치로 판단하거나 하나가 다른 것의 prefix인 경우 두 토큰을 match로 간주(파란색 화살표)
- openAI API는 각 디코딩 단계에서 top-5 토큰에 대한 확률 분포만 추출할 수 있어, 상위 다섯 개의 토큰을 학생 모델의 vocab과 정확하게 일치시킴(e.g. (a),(b) / 위의 문장이 teacher, 아래가 student) + logit에 softmax를 적용해 확률의 합이 1이 되도록 함
- 만약 일치하지 않을 경우(student PT의 token이 teacher의 top-5 token에 없을 경우) 해당 토큰의 확률을 1로 할당(e.g. (c),(e))
5. Conclusion & Limitation
Conclusion
- decoder가 pruning된 ED모델을 student로, Logit KD와 sampling한 PT를 활용한 Joint-Teaching방법이 성능이 어느 정도 방어되면서 가장 좋은 compression rate를 보여줌
Limitation
-
Using a medium size fine-tuned teacher
-
LLM을 쓰기엔 다음과 같은 문제 발생
-
개인정보 문제
-
계산량 & 비용
-
소수의 labeled example을 얻을 순 있으나 충분한 데이터를 얻는게 현실적이지 않음
-
LLM을 teacher로 활용한다해도 결국 medium size teacher를 거쳐서 distillation(이전 연구에 따르면)
-
-
⇒ 그래서 medium size의 teacher를 사용
-
The scope of our realistic setup
-
english-english NLG task만 실험
-
output이 input에 비해 짧거나 비슷한 길이의 세팅
-
-
Computational training cost
-
KD에 소요되는 계산량은 고려하지 않음
- 모델 1번의 학습에 소요되는 계산량은 누적되는 inference 계산량에 비해 무시할만하다 가정
-
Joint Teaching의 경우 student, teacher모두에서 PT를 뽑아내기 때문에 다른 KD기법에 비해 계산량이 높음
- 특히 student의 경우 모델이 업데이트 될 때마다 다시 PT를 뽑아냄
-
-
Utilizing huge LMs
-
Joint-teaching은 LLM 환경에서 실험하지 않음
- teacher의 prediction distribution을 계속 query하기엔 비용이 너무 큼
-
Logit을 뽑아낼 수 있는 LLM이 별로 없음
- 하지만 Logit KD 없이도 괜찮은 성능이 나오긴 함
-