AdapterDrop: On the Efficiency of Adapters in Transformers
논문 정보
- Date: 2023-04-13
- Reviewer: 김재희
- Property: Adapter
1. Intro
-
Adapter 사용 시 파라미터 수를 감소시켜, 효율적인 학습이 가능해짐
-
하지만 multi-task learning 적용 시 태스크 별 adapter가 사용되면서, 학습 속도가 저하되는 문제가 발생
-
이를 개선하기 위해선, 1) adapter를 공유하거나 2) adapter를 줄이는 방식이 필요함
-
이 논문에선 adapter를 특정 레이어 이상에서만 사용해서 학습 속도를 개선시키는 방법론을 제안

⇒ 단순 Adapter 적용 시보다 많게는 8.4%의 속도 개선 효과 발생 (w/ 성능 유지)
2. AdapterDrop
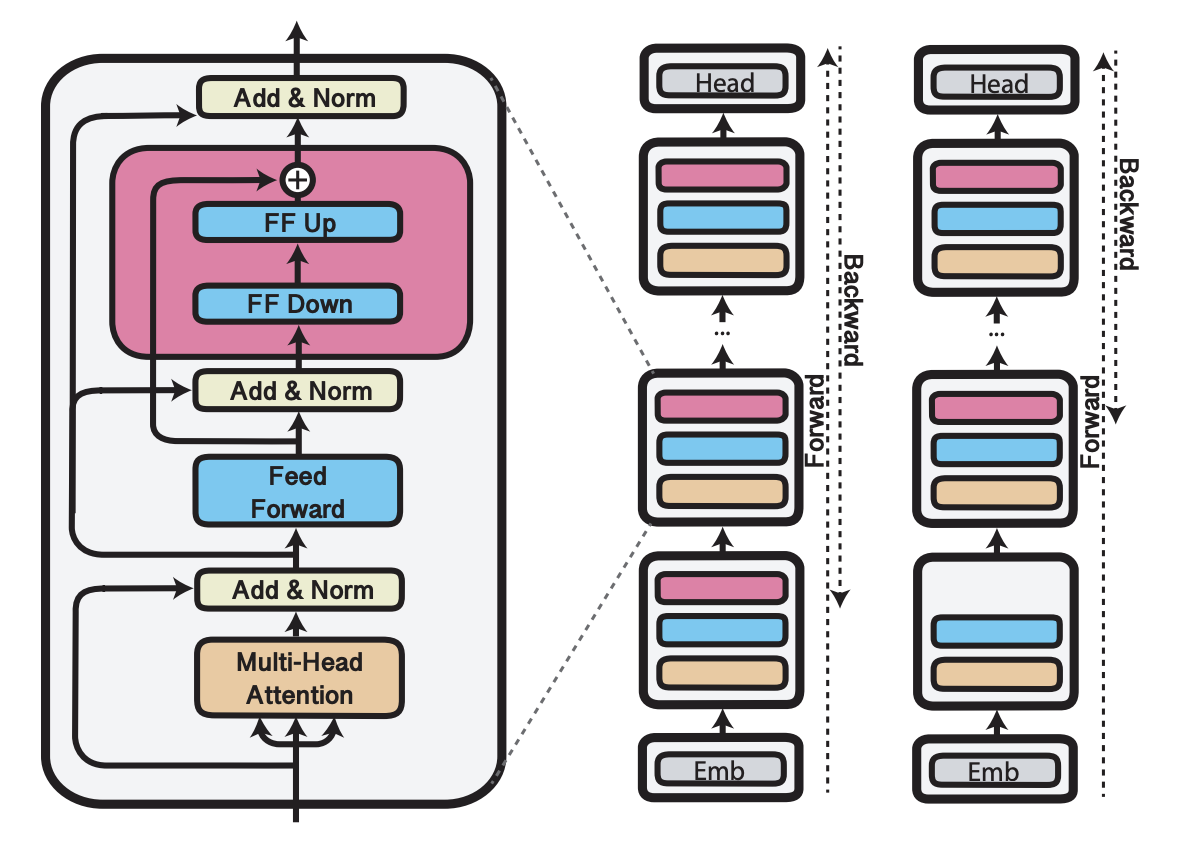
- 입력과 가까운 n개의 레이어에서 adapter를 적용하지 않는 것이 학습 속도를 개선시키는 것은 단순히 학습 파라미터가 줄어서만은 아님.
-
Adapter만 학습된다는 점과 연관이 있음
-
만약 초기 3개 레이어에 Adapter를 적용하지 않을 경우, 역전파는 loss → output → layer 12 → … → layer 4까지만 전파되면 됨
-
즉, chain rule 연산량을 줄일 수 있음
-
단순히 random 한 레이어에 adapter를 적용하지 않을 경우, 역전파는 adapter가 적용된 가장 첫 레이어까지 진행되어야 함.
-
초기 레이어에서 adapter를 적용하지 않아야, chain rule 연산을 줄이는 방법이 될 수 있음
-
3. Robust Adapter
-
하지만 위와 같이 학습된 모델은 결국 학습 자체가 초기 n개의 레이어에서 adapter가 제거된 상태로 학습됨
- 서비스 측면에서 단순히 초기 n개의 레이어를 제거하는 방식으로 학습한다면, 최적의 n을 찾기 위해 각 모델을 별개로 학습시켜야 함
-
학습 과정에서 Dynamic하게 Adapter를 사용하지 않을 레이어를 지정하는 방식으로 학습
iter 1 : layer 3 ~ layer 12 adapter 적용
iter 2 : layer 5 ~ layer 12 adapter 적용
iter 3 : layer 1 ~ layer 12 adapter 적용
-
평균적으로 초기 5.5개의 레이어에서 adapter 사용 X
-
AdapterDrop에 비해 학습 속도 향상 폭 X
-
But 매 레이어마다 Adapter를 붙여서 학습 가능
-
4. AdapterFusion
- AdapterFusion : Multi-Task Learning 환경에서 Adapter를 사용하는 기법
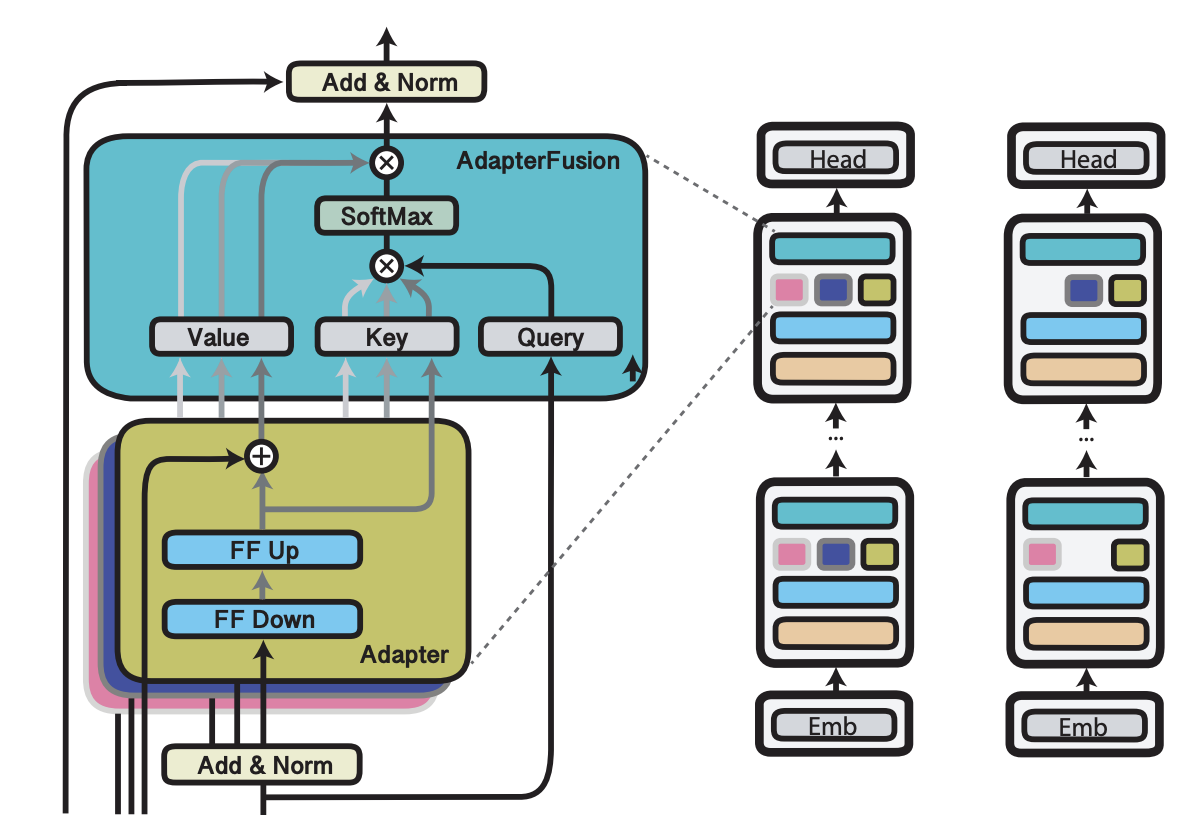
⇒ 각 태스크 별 Adapter릐 output을 Self Attention 해주는 방식
⇒ task-wise self attention(재희 생각)
-
(재희 생각) : 각 태스크마다 성능에 중요하게 작용하는 레이어가 다름
-
lexical 정보가 중요하다면 초기 레이어를 주로 사용
-
semantic 정보가 중요하다면 후기 레이어를 주로 사용
-
-
AdapterDrop을 통해 Multi-Task learning을 한다면 각 태스크마다 중요한 레이어가 다름에도 동일한 레이어에서만 adapter를 적용할 수 밖에 없음
→ Robust Adapter를 통해 Task에 대한 Scalability 확보 가능
- 논문에서도 AdapterFusion 방식에 Robust Adapter를 적용하여 실험 진행
4. 실험 및 결과
Dataset
- GLUE 데이터셋
Main Experiment 1
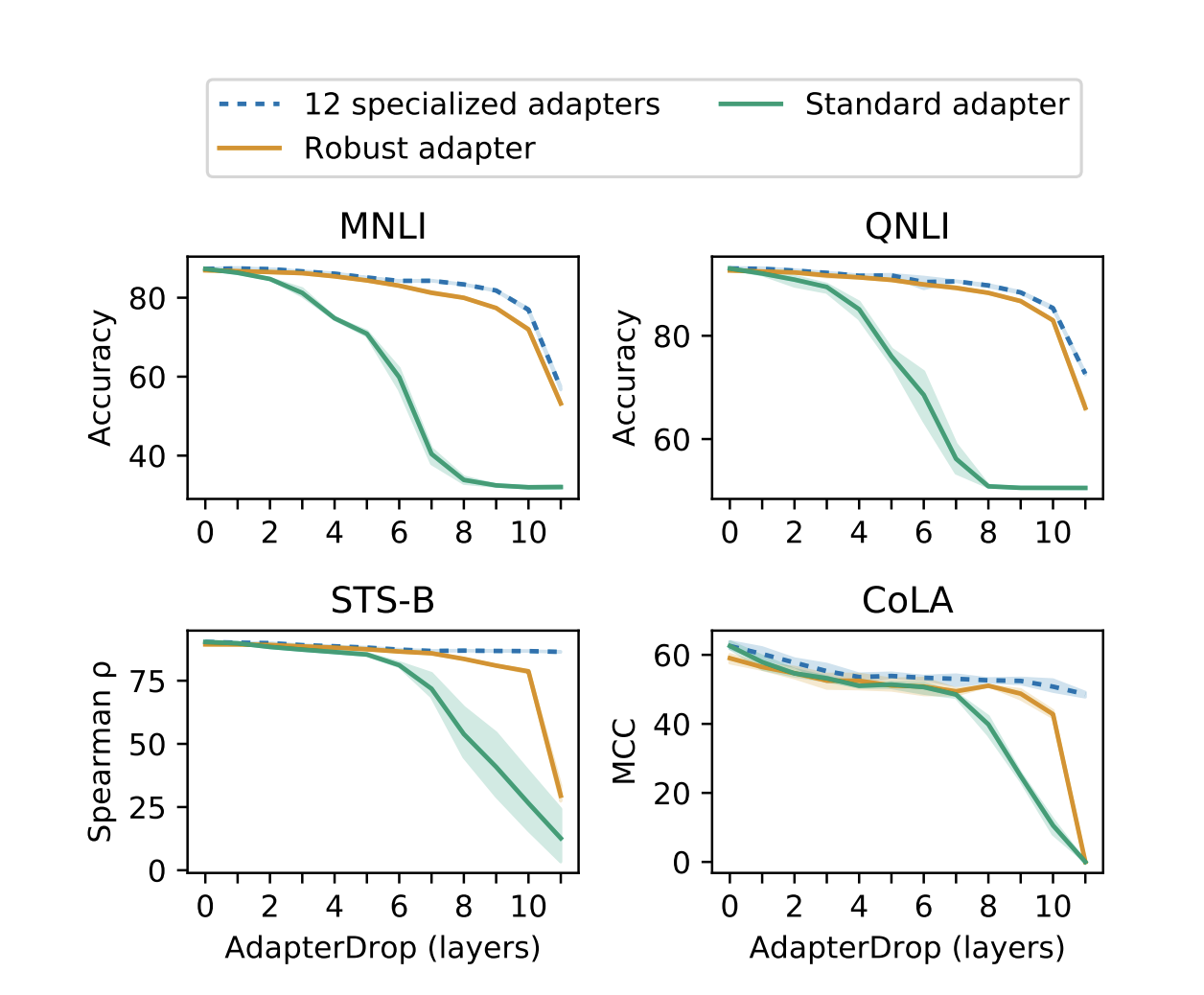
-
Standard Adapter : 모든 레이어에 Adapter를 붙이고 학습한 후 초기 n개 레이어에 대해 adapter 없이 평가 진행
-
12 Specialized Adapters : 각 태스크 별로 다른 레이어부터 adapter를 붙이고 학습 진행
-
Robust Adapter가 일정 수준의 레이어를 살릴 경우 12 adapter와 비슷한 성능을 보여줌
-
standard adapter에서 일부 adapter를 삭제하면 성능 저하 극심
→ 초기 레이어의 adapter를 지우기 때문에, 학습된 hidden representation과 다른 representation으로 평가가 진행되기 때문인듯.
Main Result 2
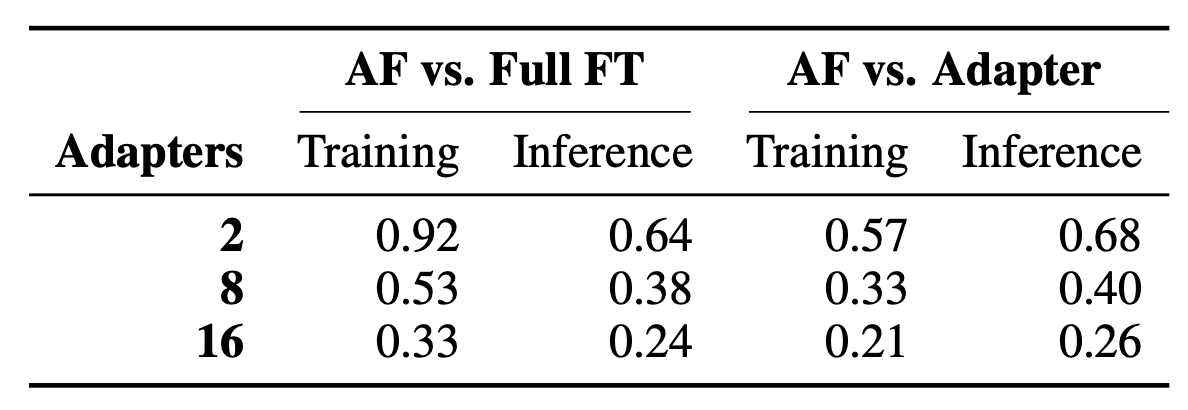
-
AdapterFusion의 full finetune 및 single adapter 대비 학습/추론 속도
-
AdapterFusion을 적용할 경우 기존 full finetune 혹은 adapter 대비 확실한 속도 저하가 관찰됨.
-
Adapters : 레이어 숫자가 아니라, 태스크 숫자임
Main Result 3
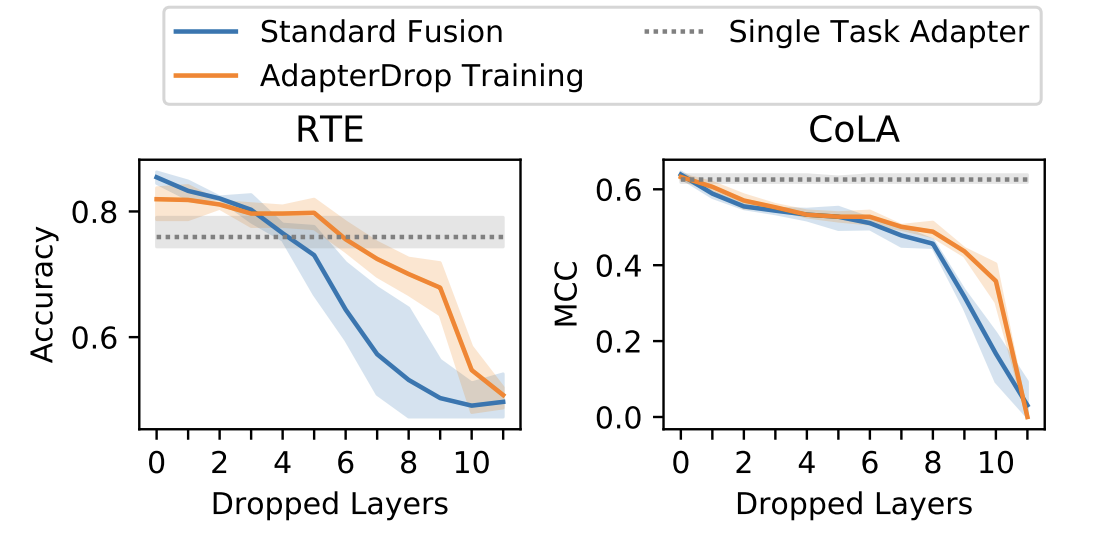
-
Robust Adapter 적용 유무에 따른 Adapter Fusion 성능 비교
-
Standard Fusion의 경우 인위적으로 레이어를 제거할 경우 성능 저하가 훨씬 심한 것을 볼 수 있음
→ Multi-task Learning을 통한 성능 이점도 상쇄할 수 있을 정도
- Robust Adapter를 적용할 경우 Adapter Fusion에 비해 빠른 학습 속도를 가져오면서도 적은 성능 저하 관찰 가능 (RTE에서 5번째 레이어까지 adapter를 안써도 성능은 single task일 때와 유사하더라~)
Main Result 4
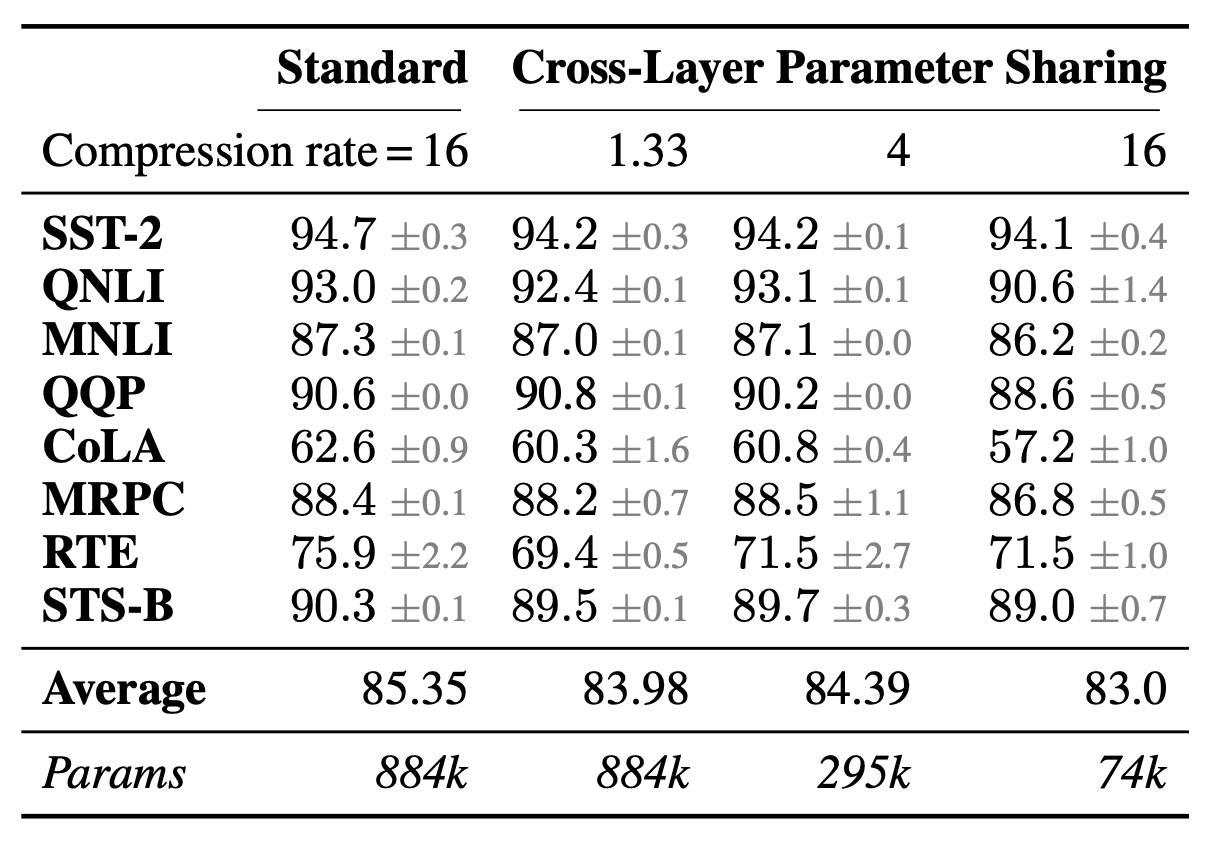
-
논문의 메인 설명엔 없지만, appendix가 거의 10쪽에 달하는 방대한 양으로 구성
-
Adapter Drop 외에도 파라미터 수를 효과적으로 줄이고, 특정 레이어에서 adapter를 쓰지 않고 inference할 수 있는 방법론 소개
-
레이어 별 adapter 파라미터를 공유하도록 설계 시 성능 저하가 거의 발생하지 않음. ⇒ 더 자세한 실험은 존재 X
4. 결론
-
Jonas Pfeiffer가 참여한 논문으로 Adapter의 활용성을 증대시키고자 노력
-
academic paper라기 보다는 technical report에 가까운 성격
-
다양하고 간단한 아이디어에 대한 최종 성능 report w/o 분석
-
GPU 종류에 따른 학습 및 추론 속도 비교
-
Multi-Task Learning을 통한 Scalability를 고려한 논문 작성
-
-
**하지만 실험해보니 너무 느려요… **
-
adapter-hub를 사용하기 위해서 별도의 adapter-transformers를 설치해야 함
!pip install adapter-transformers
import transformers # install은 adapter-transformers인데, 라이브러리 이름은 그대로 transformers임