Are Emergent Abilities of Large Language Models a Mirage?
논문 정보
- Date: 2023-12-26
- Reviewer: 준원 장
- Property: LLM, Evaluation Metric
0. Abstract
-
최근 연구들에서 small scale의 model에서는 보여지지는 않지만 larger scale model에서는 보여지는 LLM의 ability를 emergent abilities라고 정의한다.
-
하지만, 이 연구에서는 LLM의 emergent abilities가 task에서 사용하는 metric을 어떻게 설정하느냐에 따라서 (연구자의 선택에 의해서) 발생하는 일종의 신기루라고 설명한다.
1. Introduction
-
“More Is Different”
- System이 복잡해질수록, 그 system의 정교한 detail한 이해를 기반으로도 예측불가능한 (설명이 불가능한) 새로운 성질이 형성되는데, 이를 “Emergent Properties라고 한다.
-
Emergent Abilities of LLMs
- smaller scale model에는 없지만, larger-scale model에서는 보이는 어떤 능력.
(단순히 smaller scale model을 extrapolating하는 것은 불가능함)
- GPT-3 family를 필두로 보이는 이 ‘Emergent Abilities’는 2가지 하위 속성이 있음
- *Sharpness:*** **transitioning seemingly instantaneously from not present to present
(어느 순간 갑자기 선명하게 능력치가 활성화됨)
- *Unpredictability***:** transitioning at seemingly unforeseeable model scales
(모델 사이즈가 커지면서 예측 불가능하게 갑자기 활성화됨)
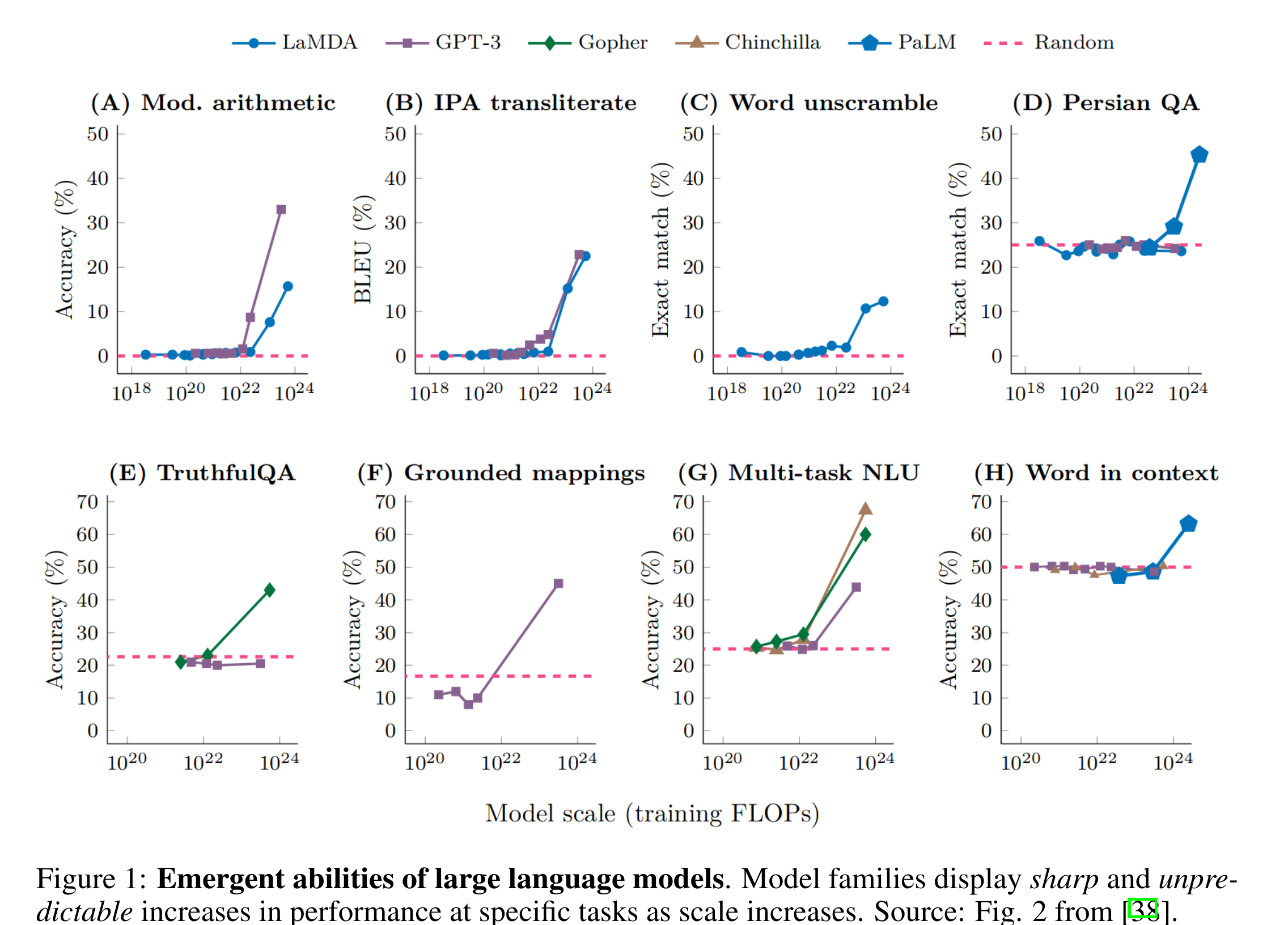
-
이러한 abilities를 무엇이 언제 어떻게 control하는가?가 이 논문이 해결하고자하는 가장 큰 Reseach Question.
-
논문에서는 특정 task에서 model size(=논문에서는 model family의 scale변화 등등 다양한 표현 사용)의 변화에 따라서 sharp하고 unpredictable한 model output (=performance)를 보여서 LLMs이 emergent abilities을 가지는것처럼 보이는 이유가 ‘Metric’ 때문이라고 주장함.
- model의 per-token error-rate이 nonlinearly & discontinuously하게 scale한다.
-
또한, test set이 smaller model의 performance를 안정적으로 측정하기에는 충분하지 않아서 emergent abilities가 더 선명하게 들어난다고 주장함.
-
이를 위해서, 간단한 mathematical model (model scale에 따른 performance bench marking)을 제시하고, LLM의 emergent abilities에 대한 대안적인 설명/주장을 펼쳐감
2. Alternative Explantation for Emergent Abilities
- LLM의 emergent abilities에 대한 대안적인 설명/주장을 하기에 없어 하나의 가정을 상정함
→ 1개의 Model Familiy내에서 Model Scale이 커짐에 따라 Test Loss는 smoothly, continuously, and predictably하게 감소함
- 이런 가정이 맞다고 할 수 있는 이유는 다음과 같은 선행연구들의 배경 때문 (neural scaling laws: empirical observations that deep networks exhibit power law scaling in the test loss as a function of training dataset size, number of parameters or compute)
→ 위의 논의를 조금 더 명확하게 하기 위해 mathematical model을 고안하는데, model parameter가 N>0, constant c> 0, a < 0일때 다음과 같은식들을 전개해볼 수 있다.
2A. Model’s per-token cross entropy loss
- 각 model의 per-token cross entropy는 parameter size N에 따라서 다음과 같이 power law를 따른다.
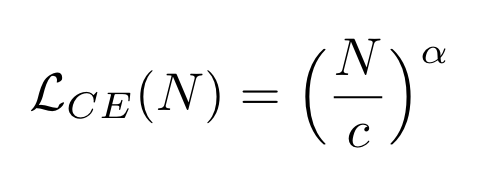
- V가 vocab set, p^_N이 parameter 크기가 N인 model의 예측분포일때 다음과 같이 써지는데 이게 특정 token을 예측한다는 관점에서 ground truth p(v)를 모르기 때문에,
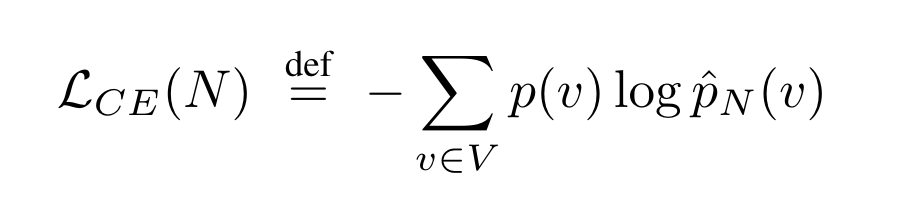
- observed token v∗를 넣어서 (one-hot distribution) 대안적인 cross entropy값을 찍는다.
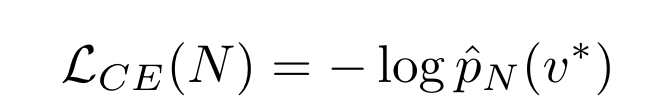
2B. per-token probability of selecting the correct token
- 위에서 구한게 결국 1개의 token에 대한 log-probability나 다름 없으니까, 이걸 확률의 영역으로 re-scaling로 해주면 다음과 같다.
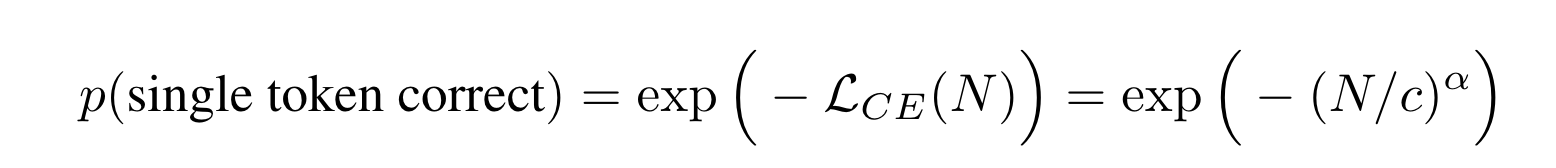
2C. per-token probability of selecting the correct L token
-
어떤 metric이 model이 생성한 모든 token이 정확해야 맞다고 한다고 해보자. ex) 10+24= 35에서 3과 5가 모두 맞아야 1임.
-
2B의 관점에서 (parameter가 N인 모델에서) 각 token이 정답일 확률이 독립적(가정이 사실이 아닌건 저자들이 인정하지만 LLM emergent abilities를 보여주는데 있어서 질적으로 유사함0)일때, L개가 다 맞아서 scoring할 확률은 다음과 같이 근사할 수 있다.
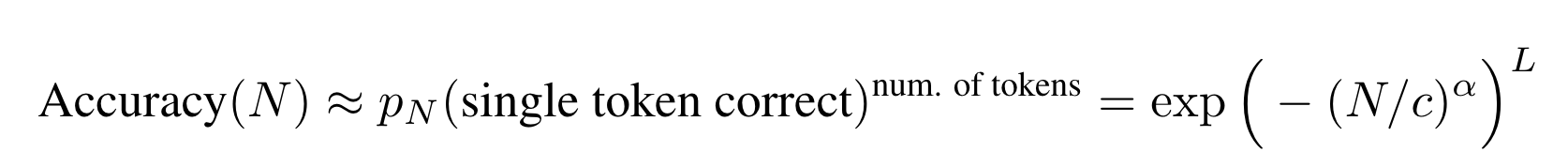
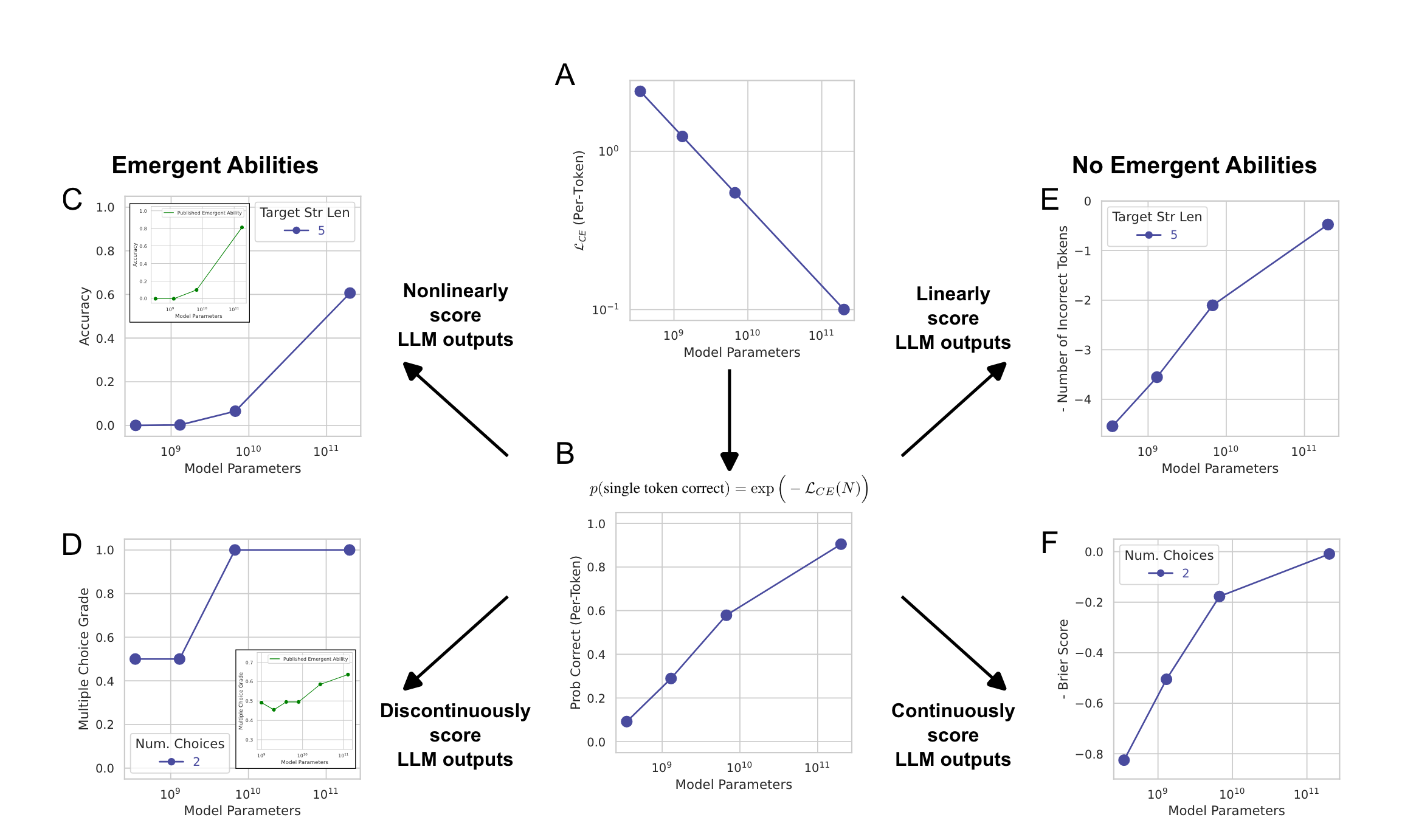
** → Accuracy는 per-token error rate에 따라 scale하는데 (non-linear), approximately linear metric like Token Edit Distance로 바꾸면 LLM의 emergent abilities가 실은 없는거 아닐까?**
- **Accuracy (2C)**

- **Token Edit Dist=ance (2E)**

2D. discontinuous metric like Multiple Choice Grade
- discontinuous metric을 사용할 때, emergent abilities를 보이는데
2F. continuous metric like Brier Score
- continuous metric으로 바꾸면 그 현상을 사라지게 한다.
결론적으로 LLM의 emergent abilties는 다음과 같은 현상 때문에 발생한다고 주장.
(1) the researcher choosing a metric that nonlinearly or discontinuously scales the per-token error rate
(2) having insufficient resolution to estimate model performance in the smaller parameter regime, with resolution set (model performance를 측정할 수 있는 최소 단위) by 1/test dataset size
(3) insufficiently sampling the larger parameter regime. → 이건 해결 못한듯..
(350M, 1.3B, 6.7B, 175B)
3. Analyzing InstructGPT/GPT-3’s Emergent Arithmetic Abilities
-
Section 02에서 보인 LLM의 emergent abilities에 대한 대안적인 설명/주장을 실험적으로 보이기 위해 GPT/Instruct GPT를 활용해 실험을 진행.
-
Task는 2가지 정수를 더하거나 곱하는 2-shot ICL
-
위에서 주장한 LLM의 emergent abilities에 대한 대안적인 설명/주장이 사실임을 보이기 위해 아래 3가지 예측에 대한 실험을 진행
-
nonlinear or discontinuous metric에서 linear or continuous metric으로 metric을 갈아끼우면 model scale에 따른 performance curve가 smooth, continuous, predictable하게 변함.
-
For nonlinear metrics이라도 test set을 추가하면, 선택한 지표의 예측 가능한 비선형 효과에 상응하는 smooth, continuous, predictable model improvements를 보일 수 있음.
-
target string length가 증가하면 accuracy(non-linear)는 model performance를 geometrically하게 token-edit distance는 model performance를 quasilinearly하게 영향을 미침.
Prediction: Emergent Abilities Disappear With Different Metrics
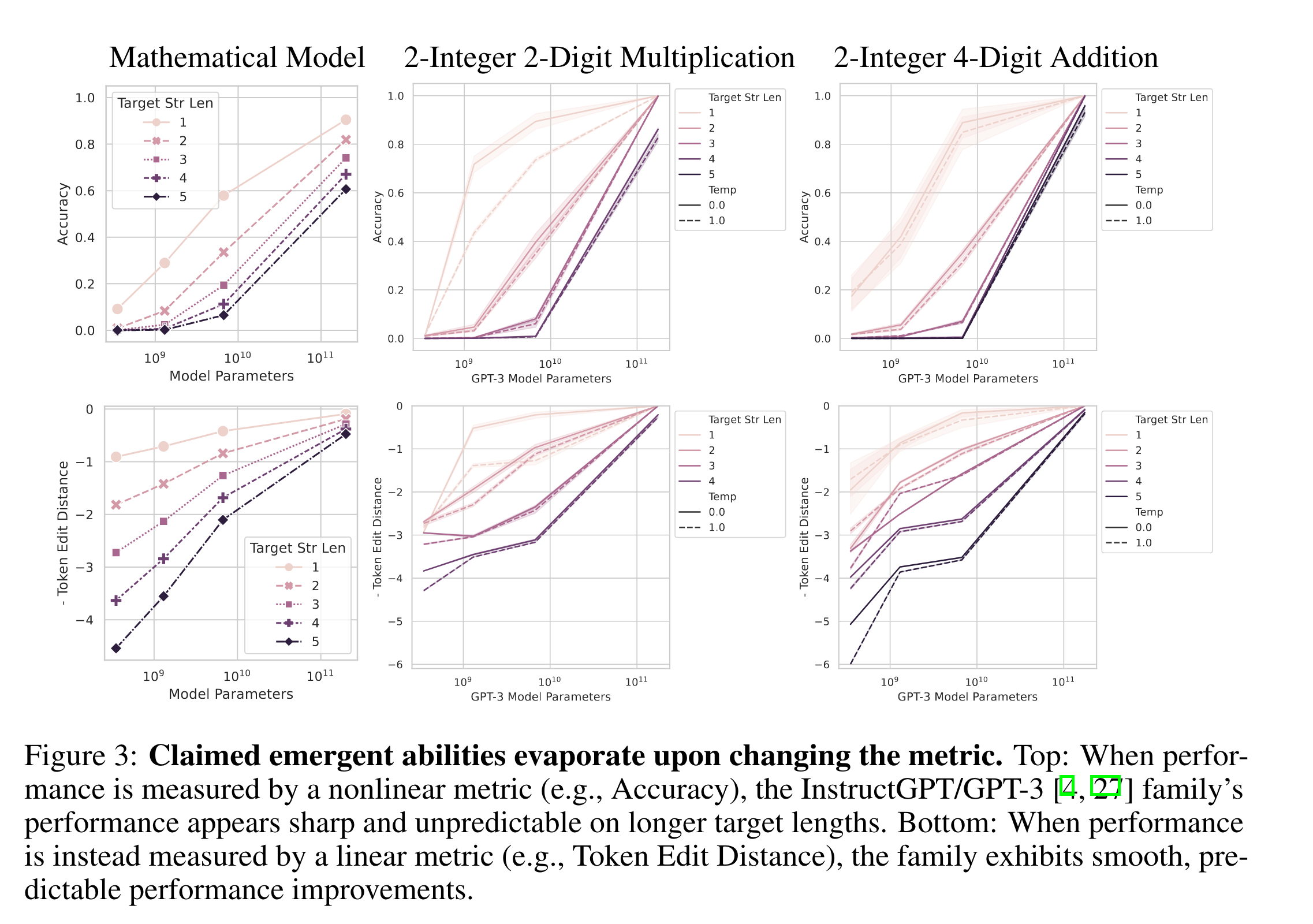
-
Metric 변경하면 emergent abitilies는 사라지며 (L=5)
-
Token Edit Distance의 경우 L이 증가함에 따라 성능하락 폭이 approximately quasilinear manner하다.
Prediction: Emergent Abilities Disappear With Better Statistics
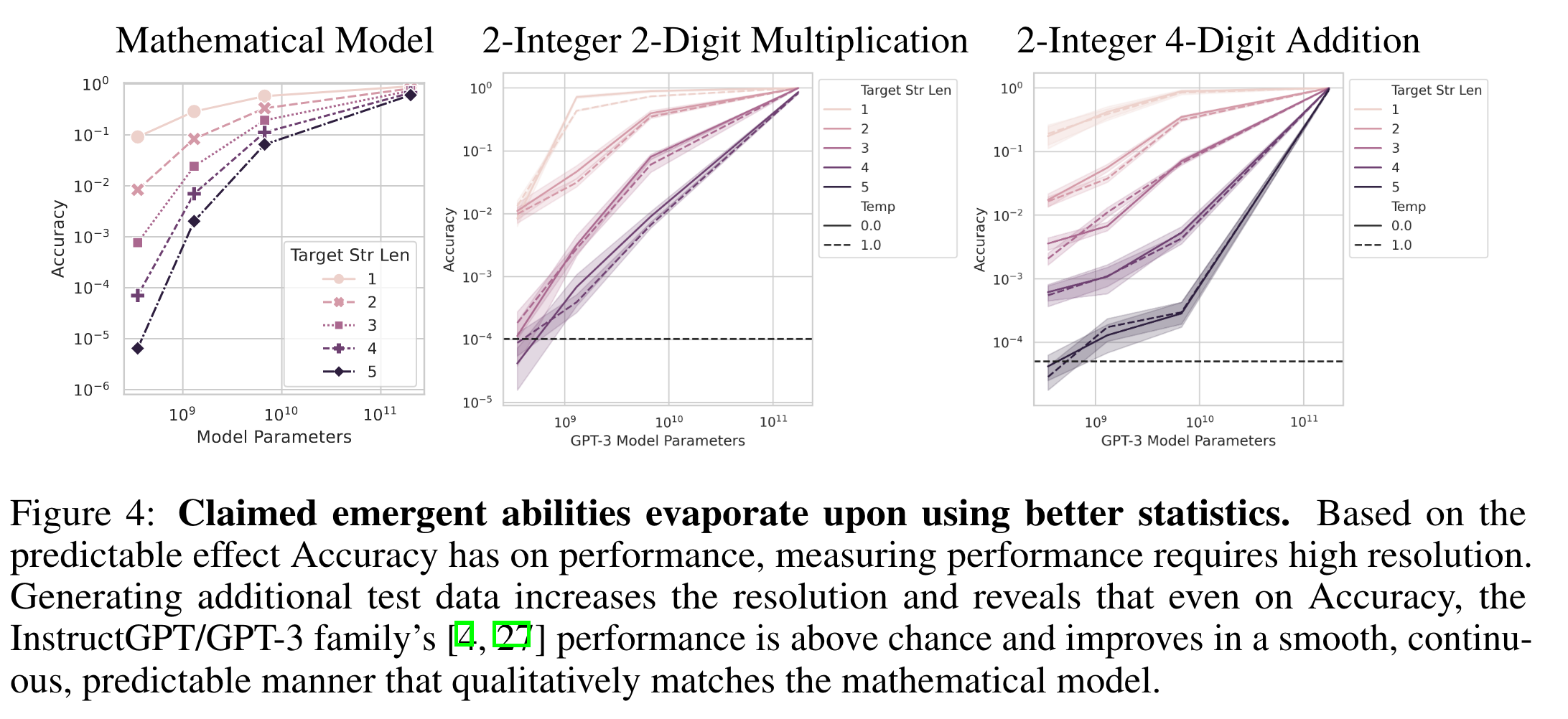
- Test set를 추가하니 Accuracy를 사용했음에도 가장 작은 모델이 어느정도 성능은 보임을 확인할 수 있다.
(Resolution set이 그동안은 너무 작았다.)
- Mathematical Model처럼 target string length가 증가함에 따라 accuracy가 geometric하게 감소한다.
4. Meta-Analysis of Claimed Emergent Abilities
→ GPT Family외에는 (연구당시) 직접 접근해서 분석할 수 있는 모델이 제한적이었기에 BIG-BENCH에 제공된 실험결과를 대상으로 위에서 진행된 논의에 대한 추가적인 논의를 이어감
→ 이를 위해 다음 2가지 prediction(가정)을 설정하고 보임
-
Task-Metric-Model Family가 있다고 할때, LLM의 emergent abilities는 특정 metric(nonlinear&discontinuous)에서 뚜렷하게 드러나지, Task-Model Family Pair만으로는 들어나지 않는다.
-
1번이 사실이라는 가정하에 metric을 변경하면 같은 task의 동일한 model output이라도 LLM의 emergent abilities가 드러나지 않을 수 있다.
Prediction: Emergent Abilities Should Appear with Metrics, not Task-Model Families
- 선행연구에 따라 다음과 같이 emergence score를 산정
(x_i: model scale, y_i: x_i에서의 performance, N: model familiy의 전체 scale 개수)
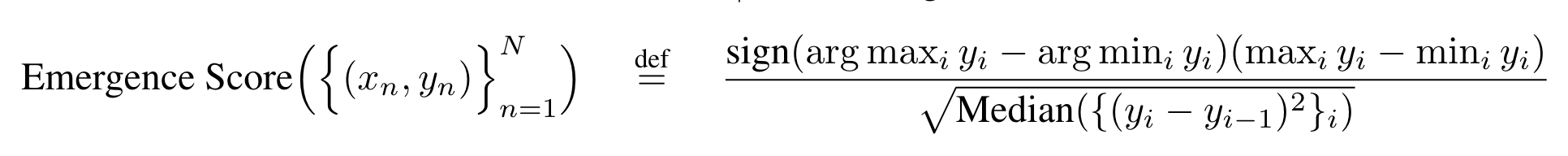
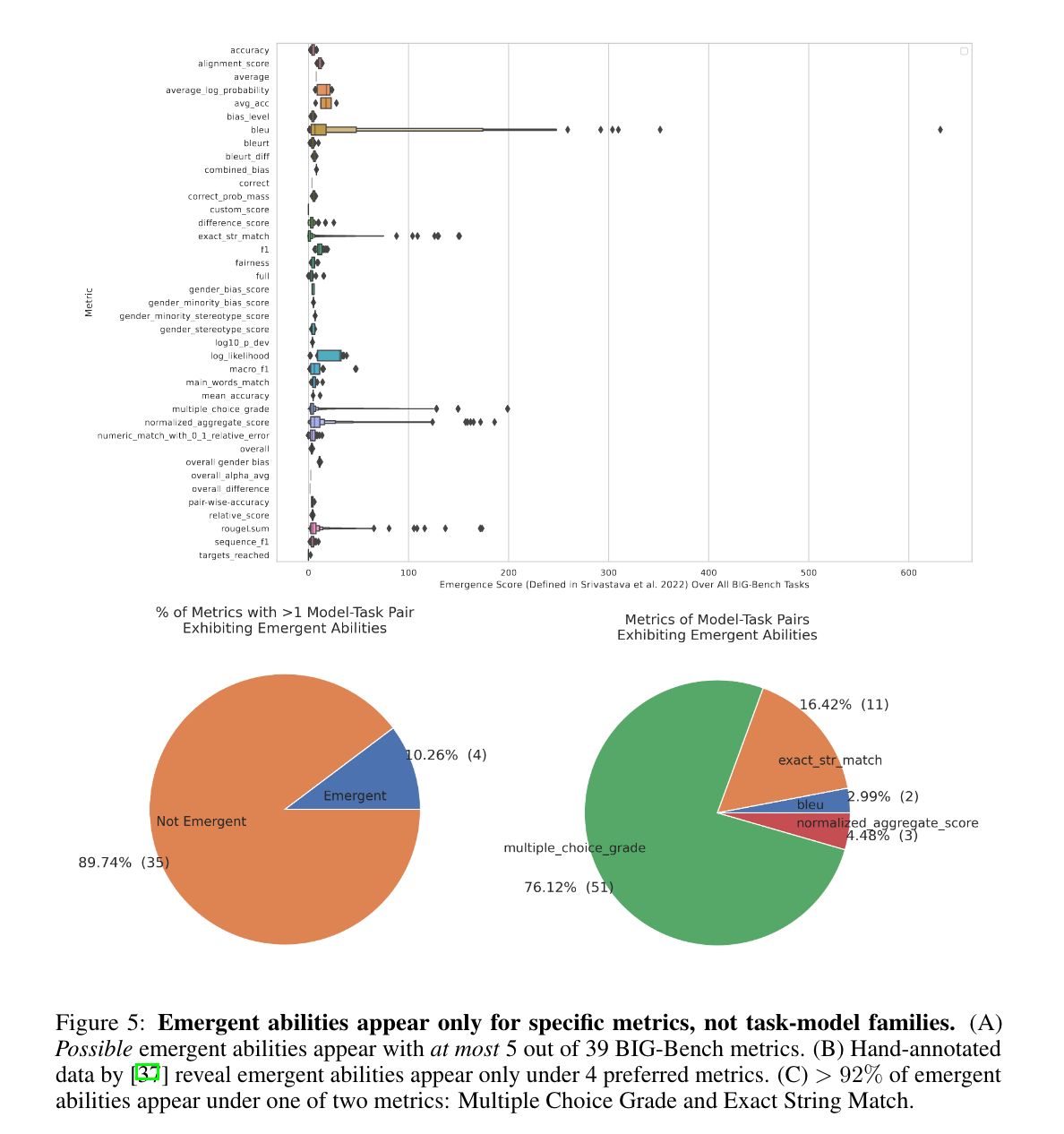
- Meta-analysis결과 5/39개가 emergence score가 높고, hand-annotated-task-abilities기반(선행연구)으로 분석한 결과 4/39개가 높음
→ Multiple Choice Grade is discontinuous, and Exact String Match is nonlinear.
(2개가 LLM의 emergent abilities을 선명하게 들어내는데 가장 주효한 metric)
Prediction: Changing Metric Removes Emergent Abilities
-
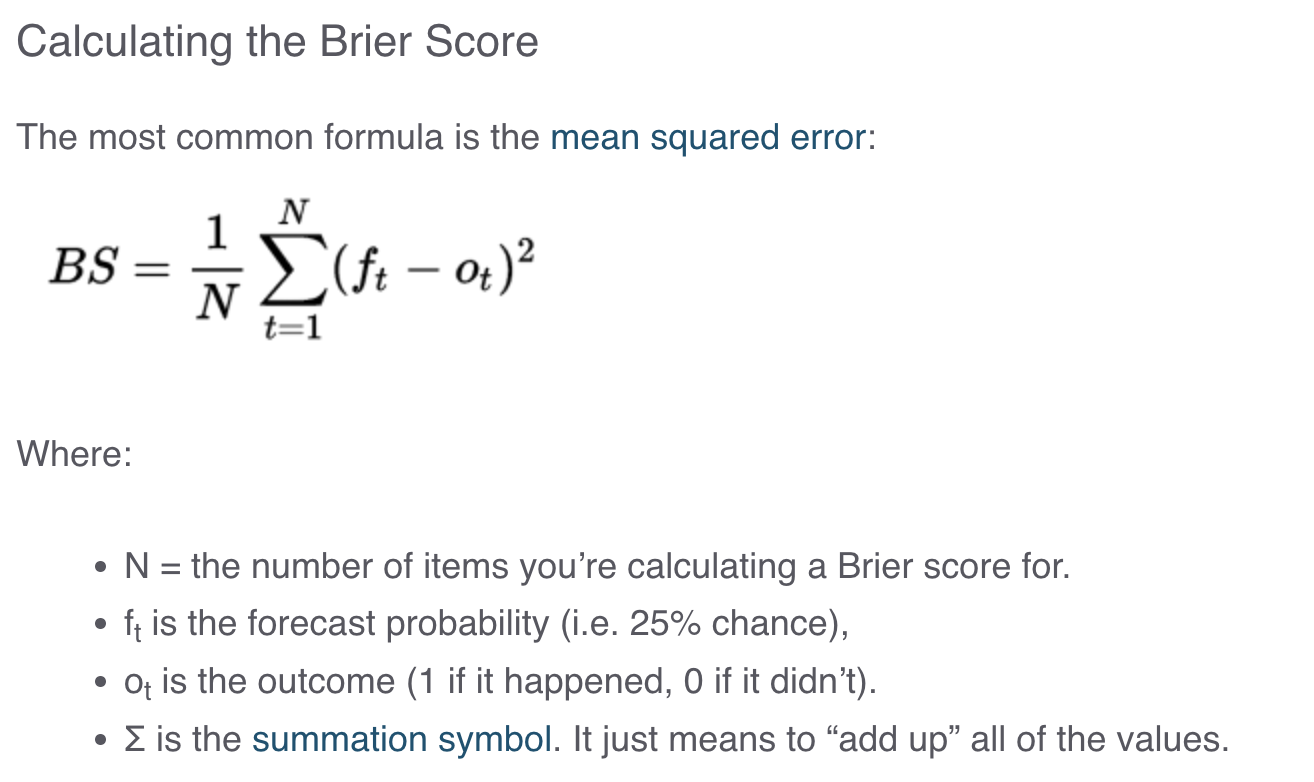
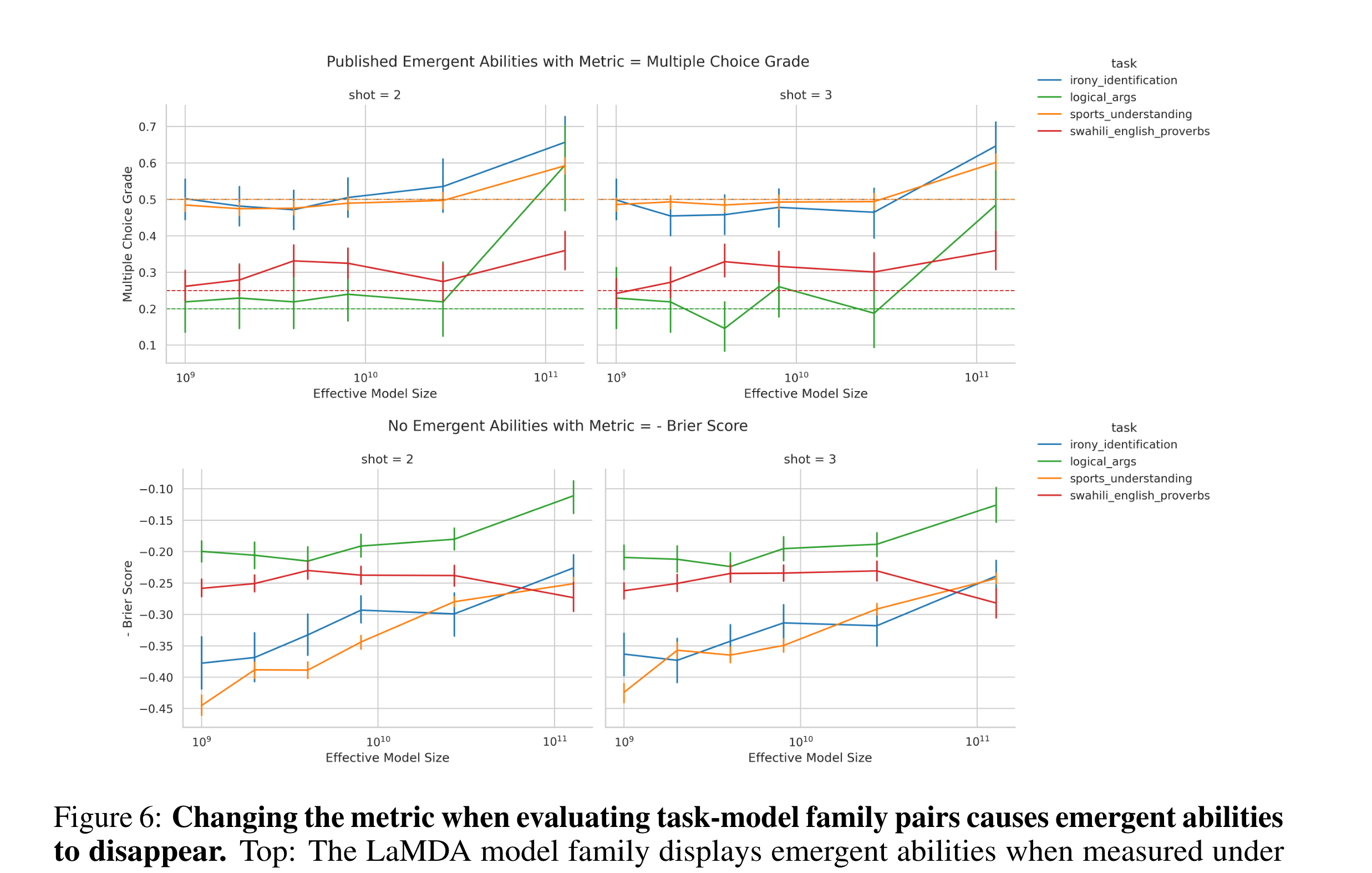
LaMDA Output이 BigBENCH에서 available해서 Multiple Choice Grade(discontinuous)를 사용하는 task를 식별한 후 metric을 continuous한 Brier Score로 갈아끼움.
- ** Brier Score**
- LaMDA’s emergent abilities가 metric을 바꿨을 뿐인데 사라짐 (Top→Bottom)
5. Inducing Emergent Abilities in Networks on Vision Tasks
-
다양성을 위해서 Vision Domain에서 추가적인 실험을 진행 (저자들 주장으로는 Vision Domain에서는 처음 한다고 함)
-
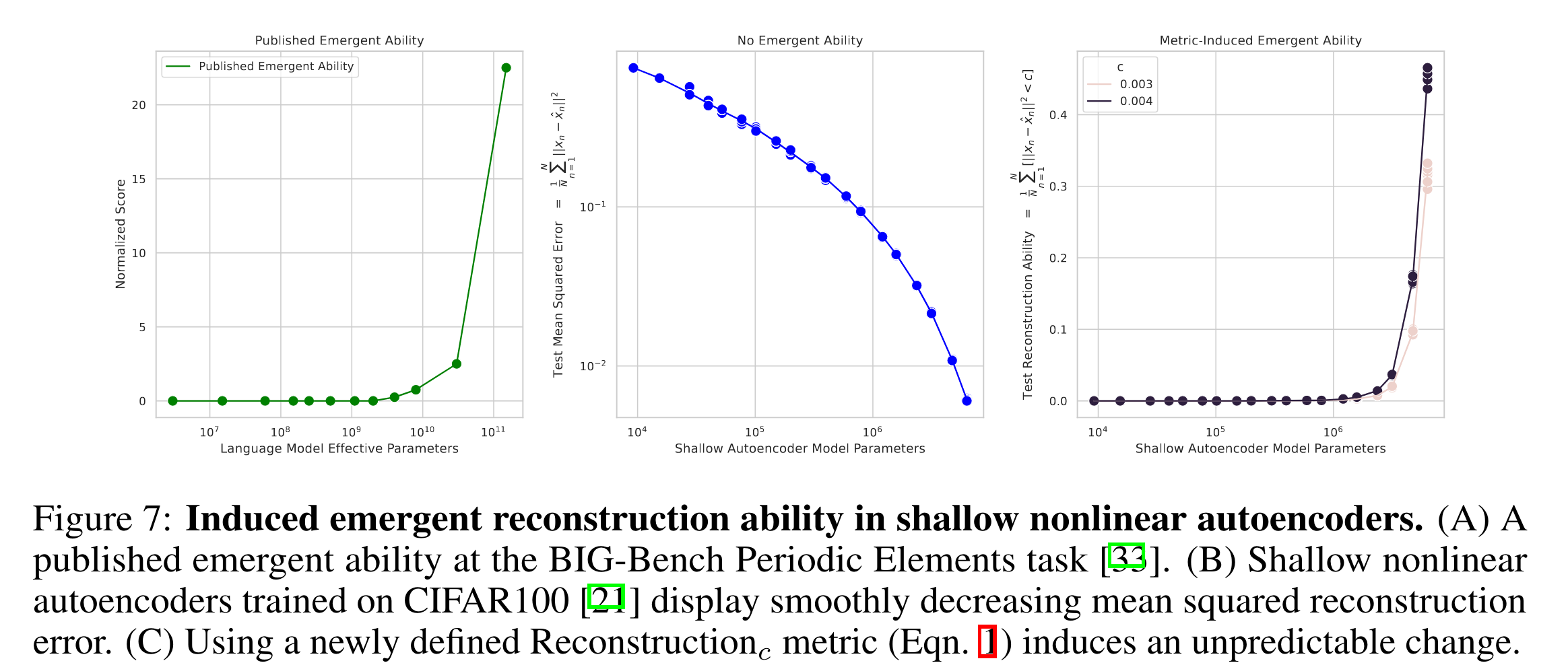
shallow (i.e., single hidden layer) nonlinear autoencoders trained on CIFAR100 natural images을 가지고 recontruction error을 측정.
-
위의 metric에서 sharpness를 보이기 위해서 metric을 아래와 같이 수정함.
- 특정 error cutoff(=c) 이하가 되어야 count가 되는 recontruction metric.
-
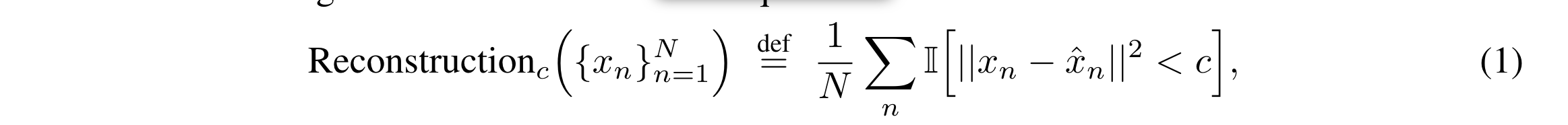
- 새롭게 정의된 metric하에서는 shallow autoencoder도 emergent abilities를 보임 (right)
6. Limitations
-
이 논문에서 주장하는 바는, LLM이 emergent abilities가 없다고 주장하는게 아니라 이전 논문에서 주장하는 일부 ‘LLM의 emergent abilities’들이 연구자들의 analyses(metric)에 만들어진 신기루일 수도 있다는 것이다. (갑자기 한발 물러섬)
-
다른 Private model에 대한 제한된 분석 (PaLM 1, Gopher, Chinchilla) .. 어쩔 수 없지
-
당연하게도 가장 좋은 metric은 인간의 선호에 의해서 결정되는게 맞다고 이야기함. 인간의 판단이 들어갔을 때 LLM이 emergent abilities이 어떻게 편하는가에 대해서는 연구가 없다고 함.