Calibrating Factual Knowledge in Pretrained Language Models
논문 정보
- Date: 2023-03-16
- Reviewer: 김재희
- Property: Knowledge, Calibrating
1. Intro
기존 LM의 내부에 사전학습을 통해 Factual Knowledge가 저장되어 있다고 간주하는 연구들이 있음
LAMA(Language Models as Knowledge Bases?, Wu et al., EMNLP 2019)
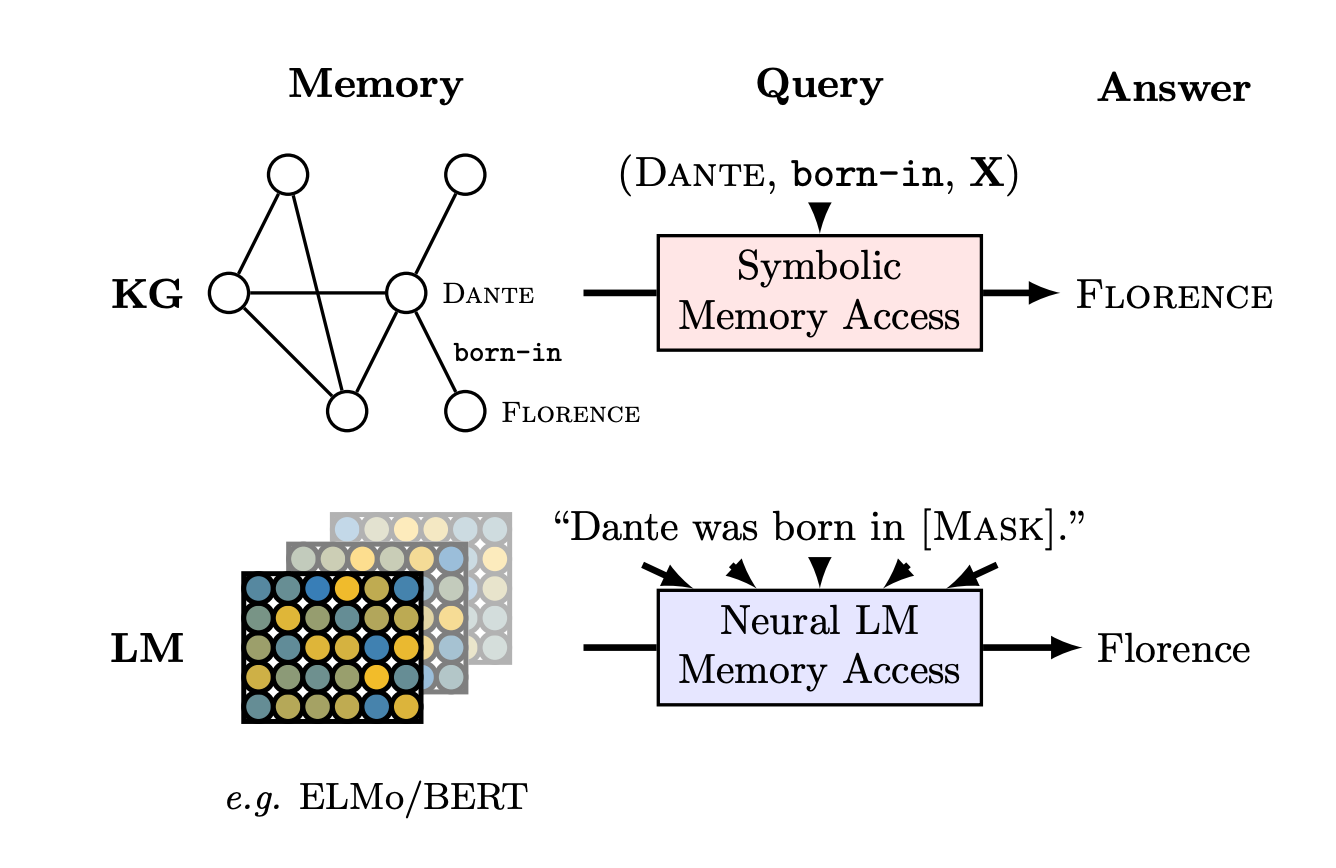
⇒ 기존 Factual Knowledge의 표현 방식 : 그래프 (subject, relation, object)
⇒ (Dante, born-in, Florence)
⇒ Factual Knowledge는 결국 사실 관계를 구성하는 두 명사 간의 관계로 표현
ROME(Locating and Editing Factual Associations in GPT, Meng et al., NeurIPS 2022)
-
최근 연구에선 GPT3의 많은 파라미터 중 FFNN 레이어에 Factual Knowledge가 주로 저장된다고 주장
-
트랜스포머의 FFNN은 model_dim → 4*model_dim → model_dim으로 2 레이어로 구성
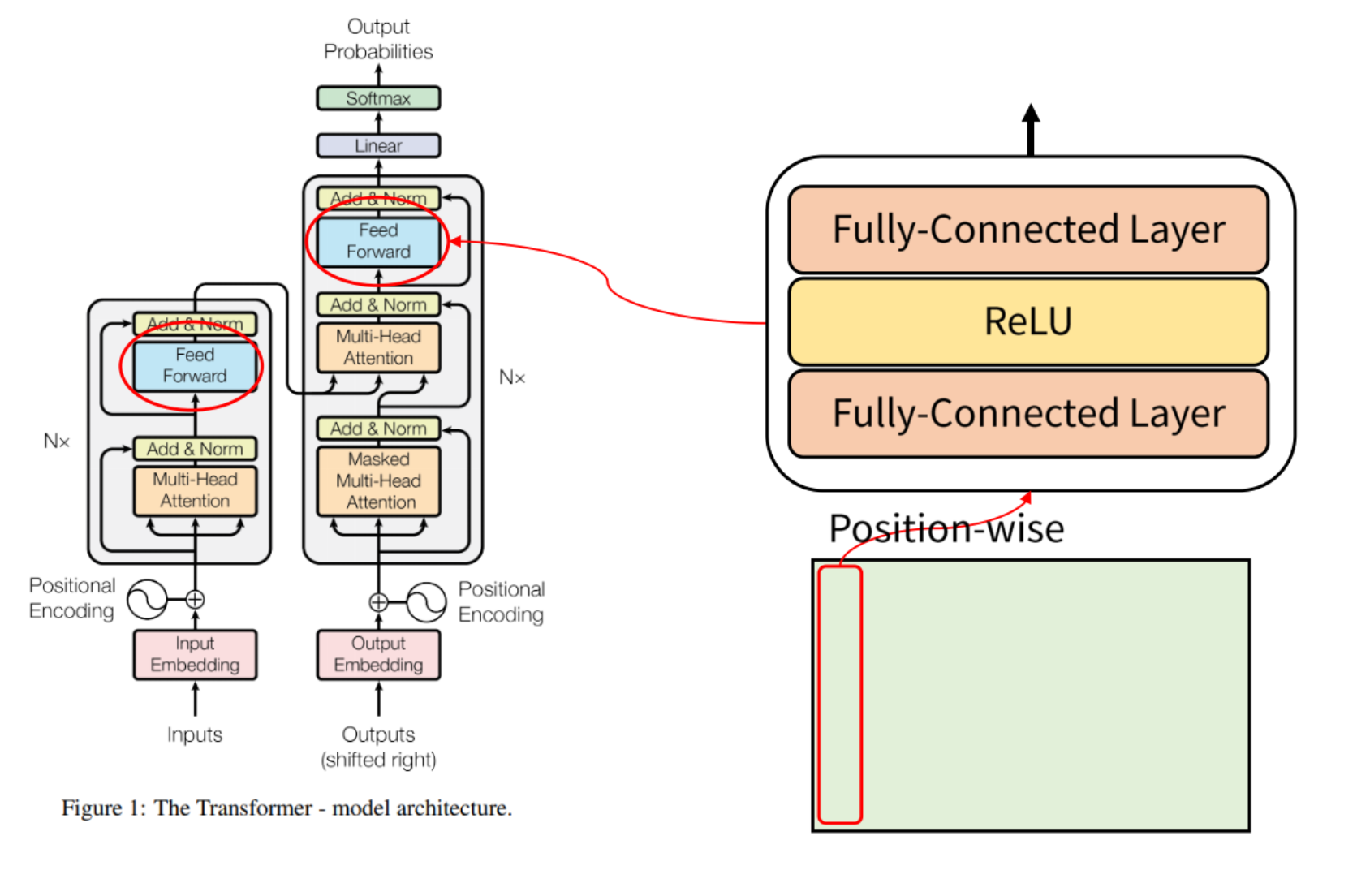
-
이때 Factual Knowledge를 가져오는 과정은 다음과 같음
-
x : Model의 Input이 입력
-
\text{key} = W_{fc}(x) : 첫번째 FC layer를 통과한 값이 Factual Knowledge를 가져오기 위한 Key로 작용
-
\text{value} = W_{proj}(\sigma(key)) : key와 가장 유사한 정보를 W_proj에서 가져옴→ Factual Knowledge로 간주
- 이러한 아이디어를 반영하여 앞으로 FFNN 레이어는 다음과 같이 표현
-
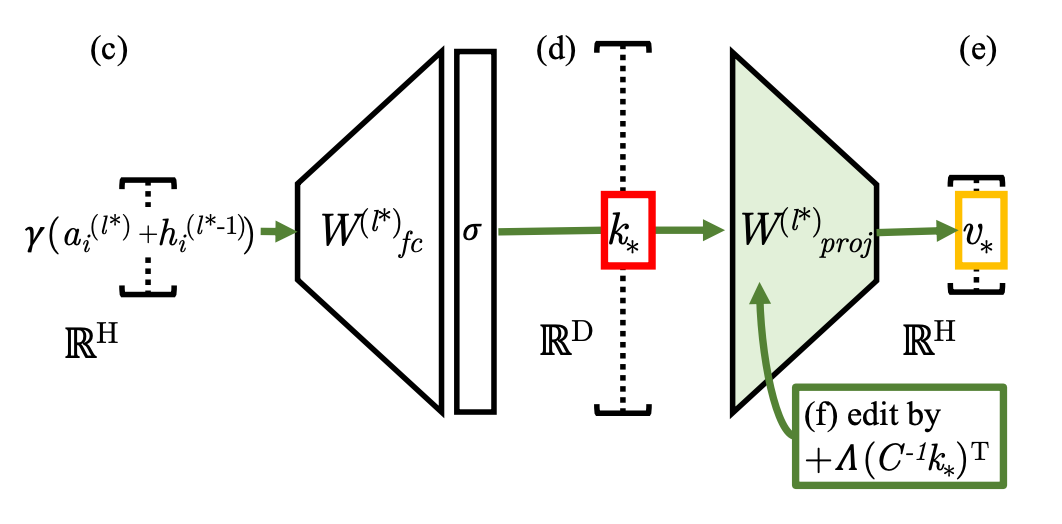
- 이를 통해 Key 혹은 Value를 산출하는 W matrix를 수정하여 모델이 가지고 있는 Factual Knowledge에 직접 접근/수정할 수 있다고 주장
Contribution
- 본 논문은 이러한 아이디어를 차용하여, 모델이 잘못 저장하고 있는 Factual Knowledge를 효율적으로 수정할 수 있는 방법론 제안
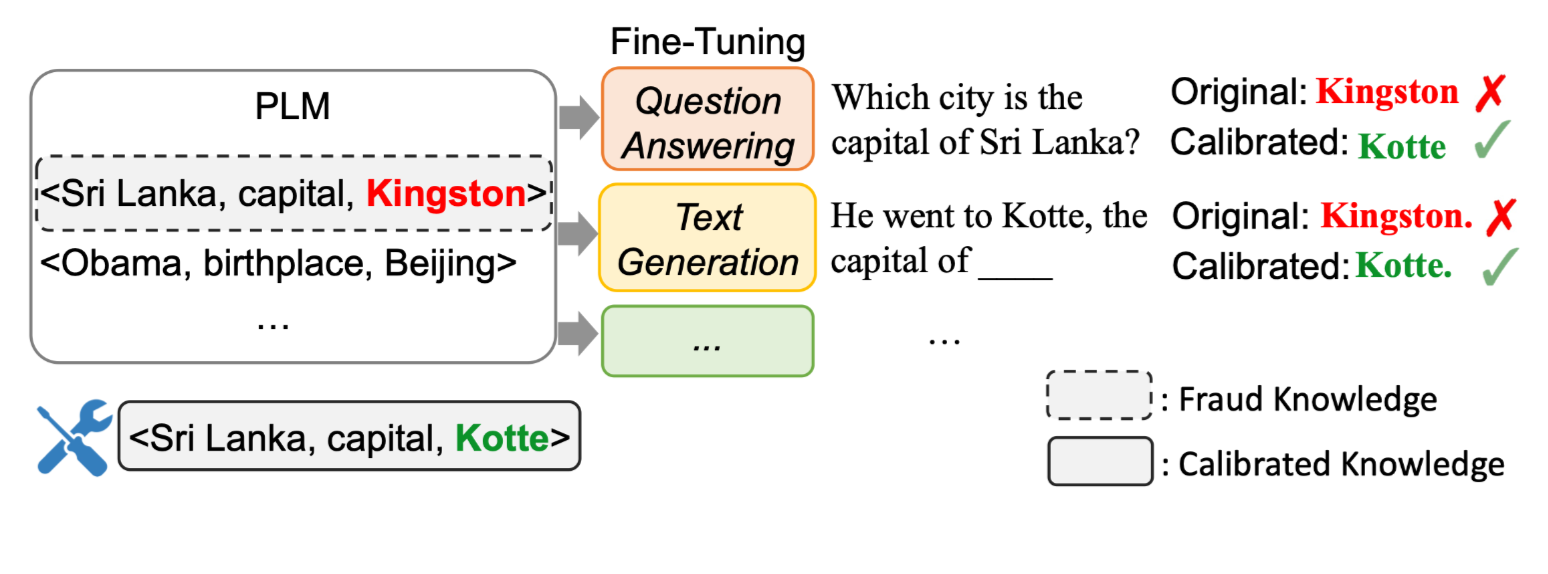
-
Retrieval Augmented LM, Knowlege Graph과 달리 오직 모델의 input-output으로 Knowlege를 수정하는 방법론 제안
-
이와 더불어 모델이 잘못 알고 있는 Factual Knowledge를 효과적으로 탐색할 수 있는 scoring 방법론 제안
2. Contrastive Knowledge Assessment(CKA)
-
본 논문의 주제는 결국 모델이 잘못 알고 있는 사실을 수정하자 임.
-
해당 문제의 출발점은 모델이 잘못 알고 있는 사실이 무엇인가?
-
LM 태스크를 통해 subject와 relation이 입력되었을 때, object가 생성될 확률을 이용하여 모델이 옳바른 Factual Knowlege를 가지고 있는지 평가
-
이러한 평가 시 두가지 고려사항 존재
-
Inexhaustible Answers : 하나의 subject, relation에 대해 복수의 정답이 존재할 수 있음
-
Frequency Bias : 단순히 학습 데이터 상에서 자주 같이 등장한 subject, object가 같이 생성되는 경향
-
-
input : Subject(s), Relation(r)을 문장의 형태로 표현(LAMA의 Template)
-
output : 다음에 등장할 토큰으로 Object(o)여야 함
-
위 과정에 대한 Scoring을 위해 실제 Relation의 반대되는 의미의 Incorrect Relation(r’)을 직접 작성하여 사용
-
Incorrect Relation : 본래 Relation과 의미적으로 반대되지만, 동일한 Object, Subject를 다룰 수 있는 Relation
-
-
수식
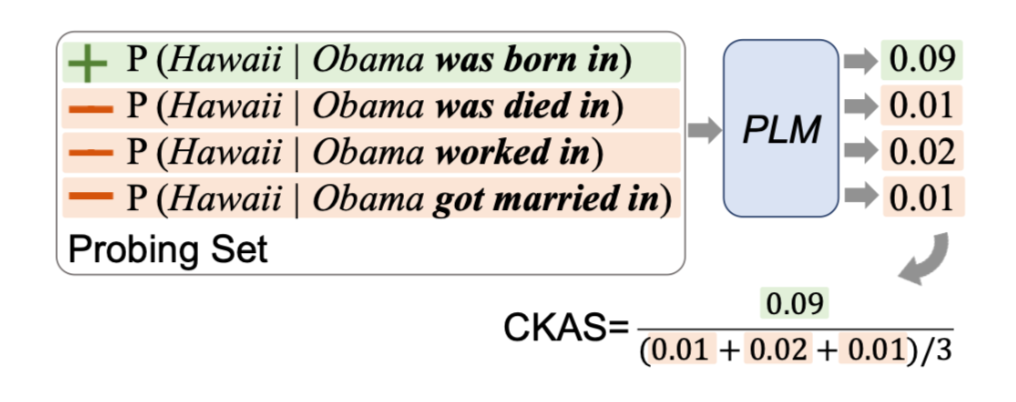
- \mathrm{CKA}{\mathrm{M}}(s, r, o)=\frac{P_M(o \mid s, r)+\alpha}{\mathbb{E}{r^{\prime}}\left[P_M\left(o \mid s, r^{\prime}\right)\right]+\alpha}
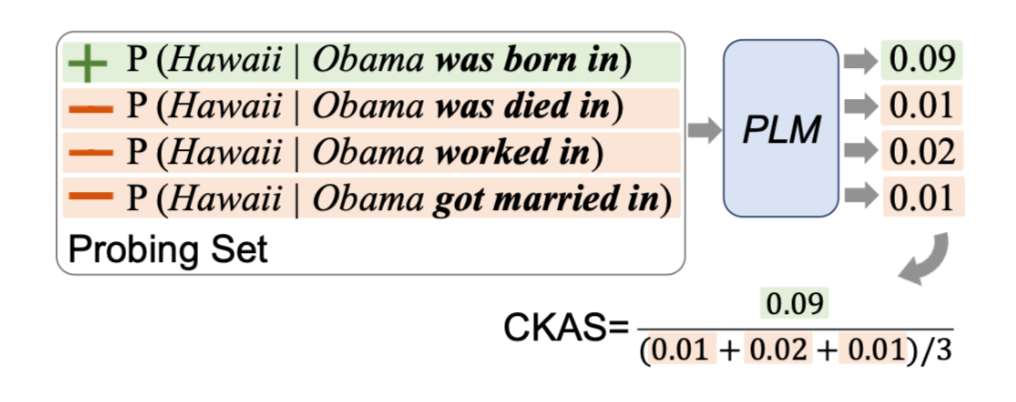
⇒ Incorrect Relation과 Correct Relation 간의 Object 생성 likelihood 비율
⇒ CKAS < 1 : 모델의 해당 Factual Knowledge를 잘못 가지고 있음
⇒ 수정될 필요가 있는 Factual Knowledge
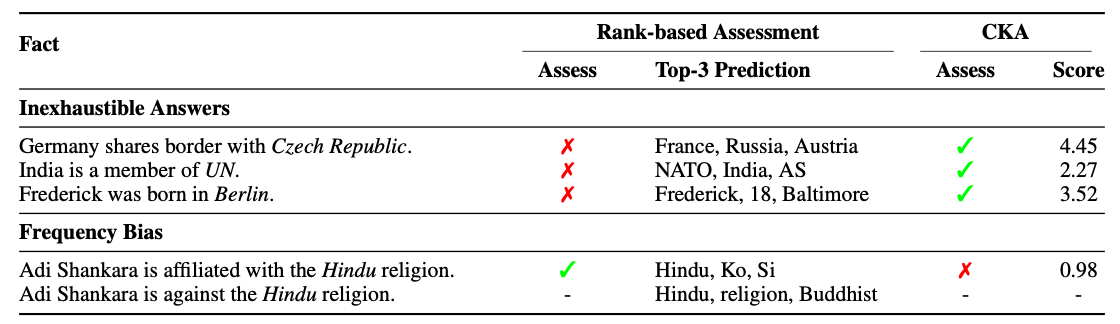
-
단순히 Top-3 Prediction을 통해 모델의 Factual Knowledge를 평가하는 것보다 정확한 평가 가능
-
복수의 정답들과 무관하게 정답을 잘 도출할 수 있는지 평가 가능
-
학습 시 자주 같이 등장한 Object, Subject 를 무시하고 실제 정답 subject에 대한 평가 가능
-
3. CaliNet
-
어떻게 모델이 옳바르게 Factual Knowledge를 생성하도록 학습할 수 있을까?
-
Basic Idea : 그냥 모델 파라미터를 업데이트하자!
-
CKA를 통해 구한 잘못 저장된 Factual Knowledge에 대해 Pretrain Task를 그대로 수행
-
Example : 만약 모델이 1번 문장의 liklihood보다 2번 문장의 liklihood가 높게 학습되어 있다면
-
Obama was born in Hawaii
-
Obama was died in Hawaii
-
-
⇒ Obama was born in Hawaii를 이용한 Language Modeling 진행
-
모델 전체 파라미터를 업데이트 하므로 비효율적
-
Catastrophic Forgetting 가능 : Factual Knowledge는 잘 생성하지만, 다른 문장들에 대한 분포가 망가짐
Main Idea :
FFNN에 대해 Calibration Module을 도입하여 Module만 업데이트하자!
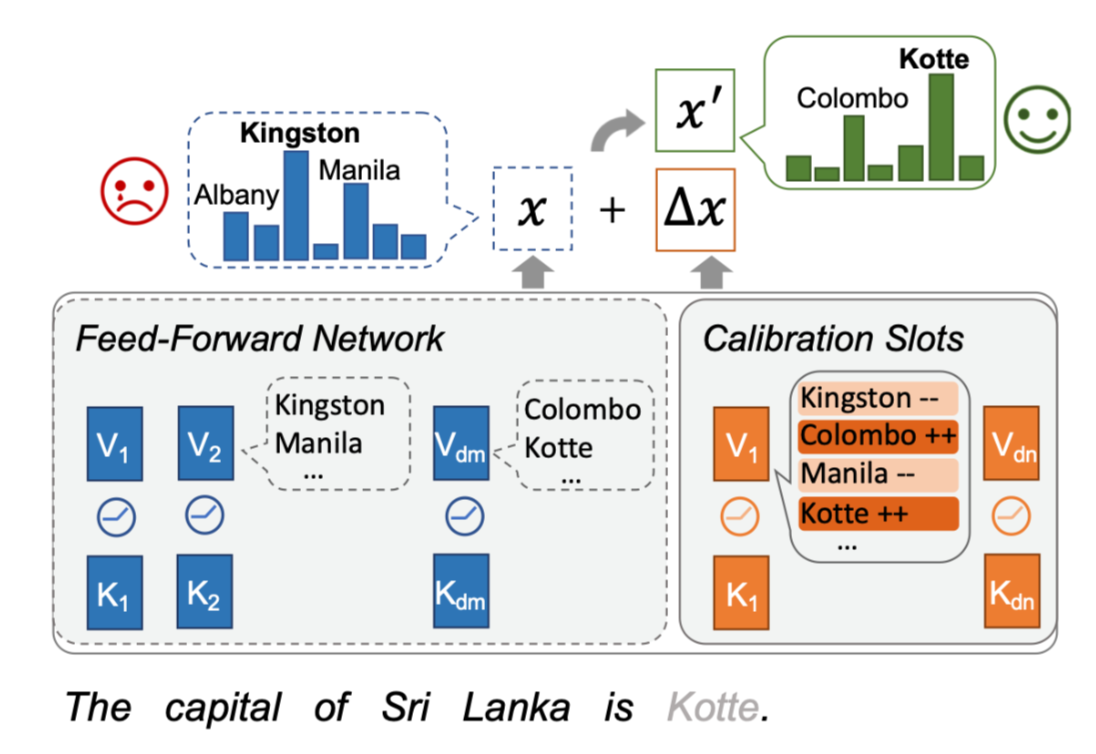
- 기존 FFNN
K, V \in \mathbb{R}^{d_m \times 4d_m}
- Calibration Slots
\tilde{K},\tilde{V} \in \mathbb{R}^{d_m \times d_c}, (d_c « 4d_m)
→ LoRA와 다른점
-
LoRA : Attention Input을 위한 Project Matrix W_q, W_v에 적용
-
CaliNET : FFNN와 동일 구조를 가지되 적은 차원의 Matrix로 구성
-
기존 FFNN과 Calibration Slots의 output을 더하여 최종 FFNN output 구성
-
기존 FFNN의 파라미터는 고정된 채 Calibration Slots의 파라미터만 업데이트
-
CaliNet은 Decoder의 마지막 레이어에만 적용 (향후 실험 있어요!)
4. 실험 및 결과
Dataset
-
실제 Factual Knowledge : Facutal Knowledge 데이터셋(T-REx)의 triplet을 샘플링하여 사용
- Example : (Tallinn, Capital of, Estonia)
→ 에스토니아의 수도는 Tallinn임
-
of dataset : 100 or 1000
Incorrect Factual Knowledge Dataset
- CKA를 통해 모델이 맞추지 못한 Factual Knowledge triplet을 선별 → (s, r, o)
-
CKA 계산을 위해 필요한 erroneous relation은 직접 구축
- 기존의 relation과 의미적으로 반대가 되면서 subject와 object 간의 연결이 가능한 relation
Main Experiment
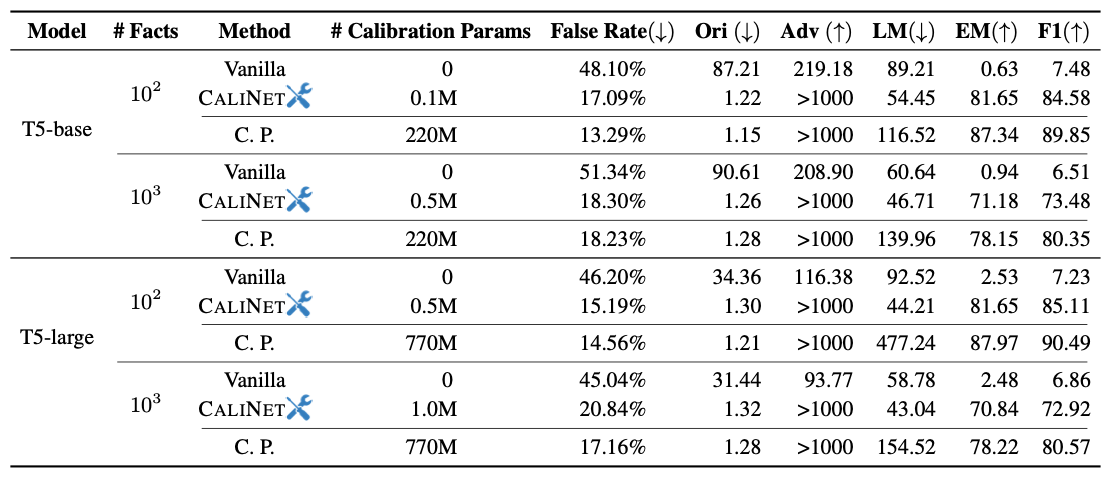
-
False Rate : 전체 Factual Knowledge 중 CKA 계산 시 Incorrect하다고 판단된 Knowledge 비율
-
Ori : 실제 Factual Knowledge triplet의 Object에 대한 Perplexity
-
Adv : Errorneous relation을 이용한 triplet의 Object에 대한 Perplexity
-
EM, F1 : object에 대한 실제 생성 정확도
-
LM : 전체 토큰에 대한 Perplexity
Ori : (Obama, born_in, Hawaii) → Obama was born in [MASK] → Hawaii Adv : (Obama, died_in, Hawaii) → Obama was died in [MASK] → Hawaii
-
CP(Continual Pretraining) 에 비해 CALINET이 적은 파라미터 이용
-
Vanilla 모델에 비해 CP가 가장 개선된 false rate을 보임, 하지만 CALINET 역시 false rate 개선
-
CP의 경우 LM의 Perplexity가 매우 악화되는 모습을 보임
-
CP는 기존 파라미터를 업데이트하기 때문에 general ability가 훼손되는 모습
-
CALINET은 기존 파라미터를 유지하기 때문에 Factual Knowledge를 수정하면서도 general ability를 유지
-
Num of Facts to Calibrate
- 수정하고자 하는 Fact의 수를 늘리면서 실험 진행
Knowledge 수정 : Factual Knowledge triplet을 이용하여 CALINET 학습하는 것
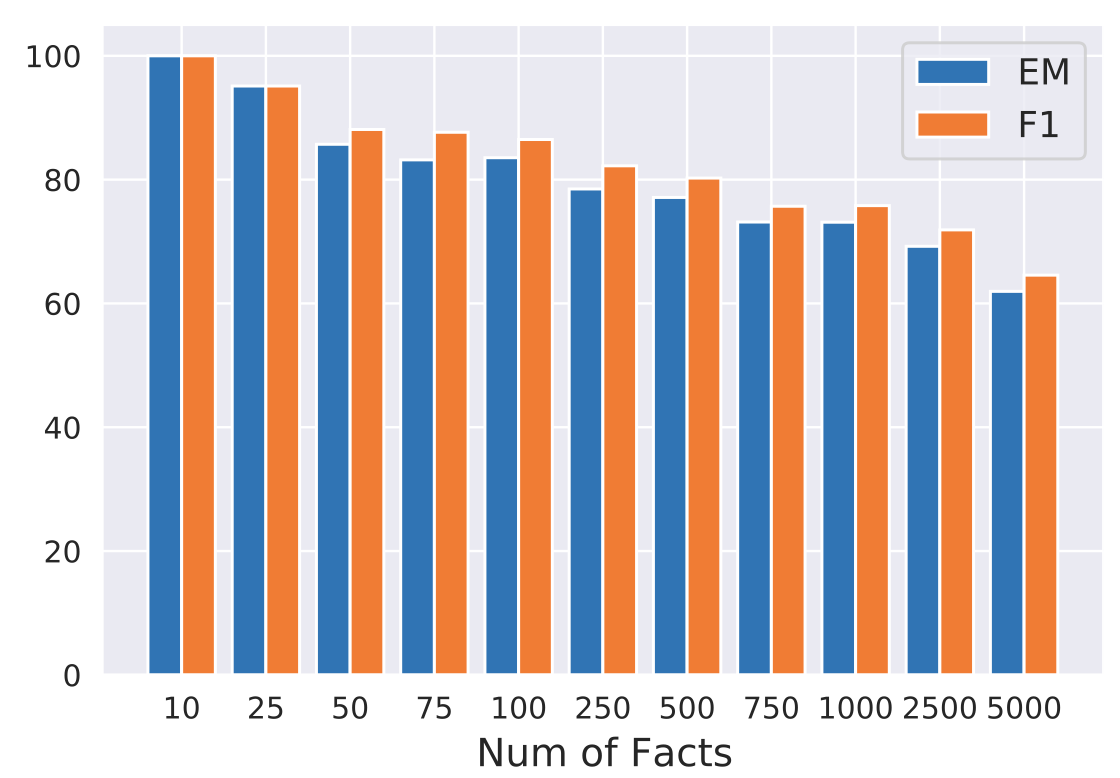
-
10개의 Factual Knowledge를 수정할 경우 모두 제대로 수정된 모습을 보임
-
수정하고자 하는 Factual Knowledge가 늘어날수록 수정되지 못하는 Knowledge 비율 증가
⇒ 기존 방법론들이 최대 125개의 Knowledge를 수정하면서도 70%의 정확도만 달성한 것에 비하면 큰 개선
Concatenating CaliNet in Different Layers
- CaliNet의 적용 위치를 변경하여 모델 수정 능력 검증
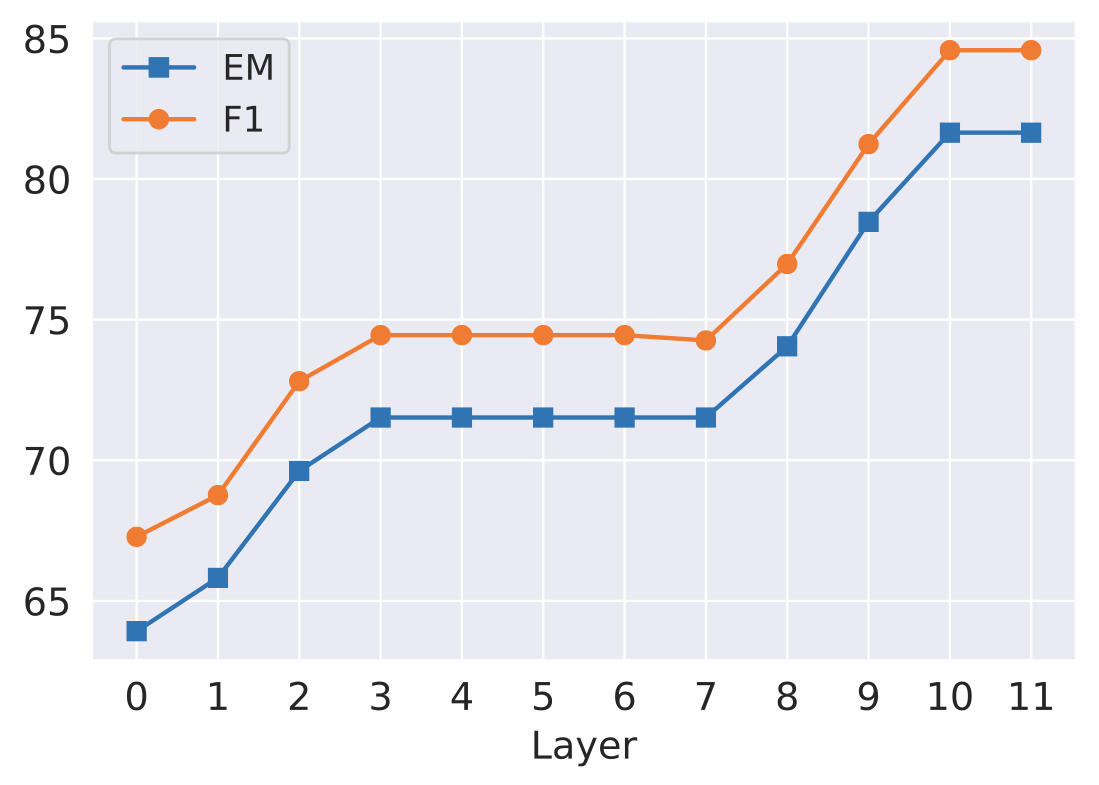
-
마지막 두 레이어에 적용할 경우 가장 큰 수정 능력 확보
-
ROME의 실험 결과와 비슷
-
초기 레이어의 값을 수정할 경우 모델이 내부적으로 다시 고치는 경향 존재
-
모델의 Factual Knowledge를 수정하기 위해선 마지막 레이어를 수정해야 함
-
Interpretability of CaliNet
-
CaliNet의 이러한 수정 능력에 대한 해석 시도
-
이전 Transformer의 FFN 레이어가 Factual Knowledge를 저장하고 있다는 연구(Transformer feed-forward layers are key-value memories, Geva et al., EMNLP 2021)의 실험을 수행
-
E : 모델의 출력 임베딩 레이어
-
\text{v}^l : 기존 모델의 l번째 레이어의 hidden representation
-
\text{v}^c : CaliNet의 hidden representation
-
p : 모델이 해당 레이어에 대해 가지고 있는 Internal Knowledge를 Vocab dist로 표현한 분포
⇒ p 중 top-30 토큰을 살펴봄
⇒ 각 토큰들에 대해 수작업으로 5가지 분류로 나눔(Date, Place, Person, Organization, Others)
⇒ 각 레이어 별로 기존 모델과 CaliNet이 Input으로 주어진 Factual Knowledge를 완성하기 위해 집중하는 entity에 대해 살펴보고자 함
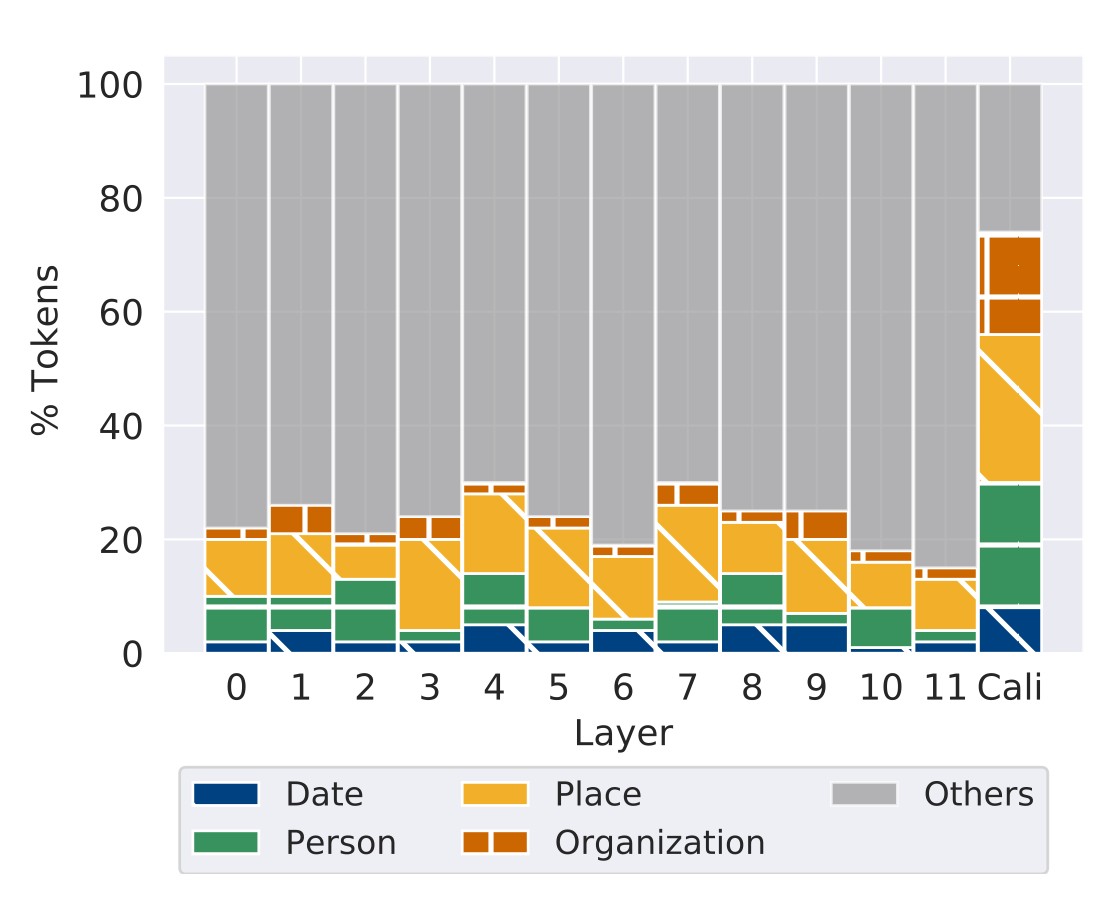
-
기존 모델의 경우 일부 토큰들만 entity에 해당하는 모습
- Cali는 상당량의 토큰이 entity에 해당하여 효과적으로 hidden representation을 조정하여 Factual Knowledge를 잘 calibration 하고 있음
Evolution of Token Distribution

-
Calibration 적용 여부에 따른 Top-10 토큰 확인
-
Calibration이 적용되지 않으면, 자주 함께 등장하는 토큰들이 생성되는 경향
-
Calibration을 통해 실제 정답 Object 뿐만 아니라 의미적으로 유사한 토큰들도 높은 liklihood가 생성됨
→ CaliNet이 단순히 특정 문장의 생성을 유도하는 것이 아니라 Factual Knowledge를 주입하여 해당 Knowledge에 대한 General Concept을 학습시킨다.
4. 결론
-
Fact Checking 논문은 아니었다…
-
Calibration을 통한 직접적인 knowledge injection을 시도
-
Factual Knowledge에 대해 모델이 잘 parameterization하고 있는지 정의하는 어려움을 해소하고자 노력
-
논문의 구성이 문제정의 → 기존 데이터셋을 이용한 문제 확인 → 해결 방법론 제안 → 방법론 해석으로 많은 양을 압축적으로 다루고 있음
-
Factual Knowledge를 모델의 generalization 성능을 떨어트리지 않으면서 입력하는 것이 매우 어려운 태스크임을 확인
→ 1000개의 Knowledge를 삽입하는 것도 매우 어렵다.