Code Llama: Open Foundation Models for Code
논문 정보
- Date: 2023-08-29
- Reviewer: hyowon Cho
- Property: LLM
Introduction
domain-specific dataset을 이용해서 application에 특화된 모델을 만드는 것은 보편적인 방법이다. 이러한 추세는 언어모델을 이용하여 코드를 작성하는데까지도 이어졌다. 예를 들어, code completion, debugging, generating documentation과 같은 작업을 수행할 수 있다.
이번 발표에서는 Meta AI에서 공개한 Code Llama에 대한 리뷰를 진행한다. 해당 모델의 의의는 크게 두 가지, 제일 성능이 좋다는 것과 repository-level의 긴 context를 받아서 처리할 수 있다는 것이다.
실제 예시를 살펴보면 꽤나 좋은 성능을 내고 있다는 것을 확인할 수 있다.

요약된 특징은 다음과 같다:
- Code-training from foundation models
- AlphaCode (Li et al., 2022), InCoder (Fried et al., 2023), StarCoder (Li et al., 2023)과 같은 대다수의 최근 code LLM들은 모두 code로만 학습됨. 하지만 이번 모델은 Codex (Chen et al., 2021)와 같이 foundation model에서 출발. code로만 학습시켰을 때보다 더 좋은 성능을 내는 것을 보임
- Infilling
- 일반적인 autoregressive 목적함수만을 사용하는 것이 아니라, multitask objective (autoregressive + causal infilling prediction) 사용
- Long input contexts.
- Llama 2은 4096 토큰 input. 하지만, repository-level reasoning을 하기 위해서는 이보다 더 긴 context를 받아야함. 이를 위해서, maximum context length을 4,096 tokens to 100,000 tokens로 늘리는 finetuning stage 제안. - modifying the parameters of the RoPE positional embeddings.
- Instruction fine-tuning.
- Code Llama - Instruct 에서 추가적인 Instruction fine-tuning 진행
이 외에도 해당 paper에서는 다른 code-based LLM들과의 비교를 진행하고, 우리가 궁금할법한 다양한 ablation study를 진행한다.
Technical Details
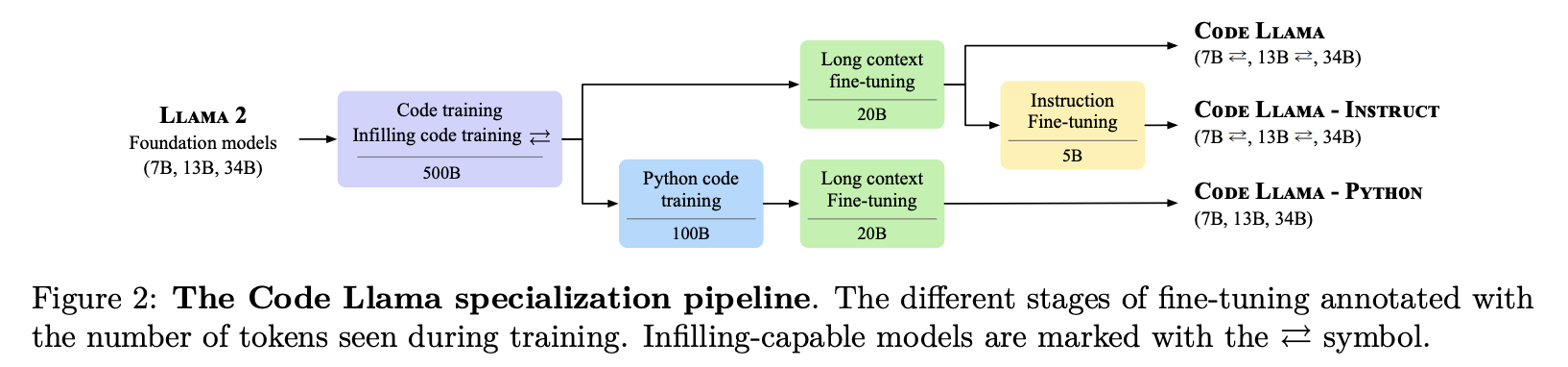
The Code Llama models family
-
Code Llama
-
7B and 13B models은 infilling objective를 이용해 진행
-
34B model은 infilling objective 없이 auto-regressive만 진행
-
최종적으로 trained on 500B tokens from a code-heavy dataset
-
-
Code Llama - Python:
-
Python에 특화된 버전
-
100B tokens using a Python-heavy dataset
-
-
Code Llama - Instruct:
- human instructions and self-instruct code synthesis data을 사용하여 finetune
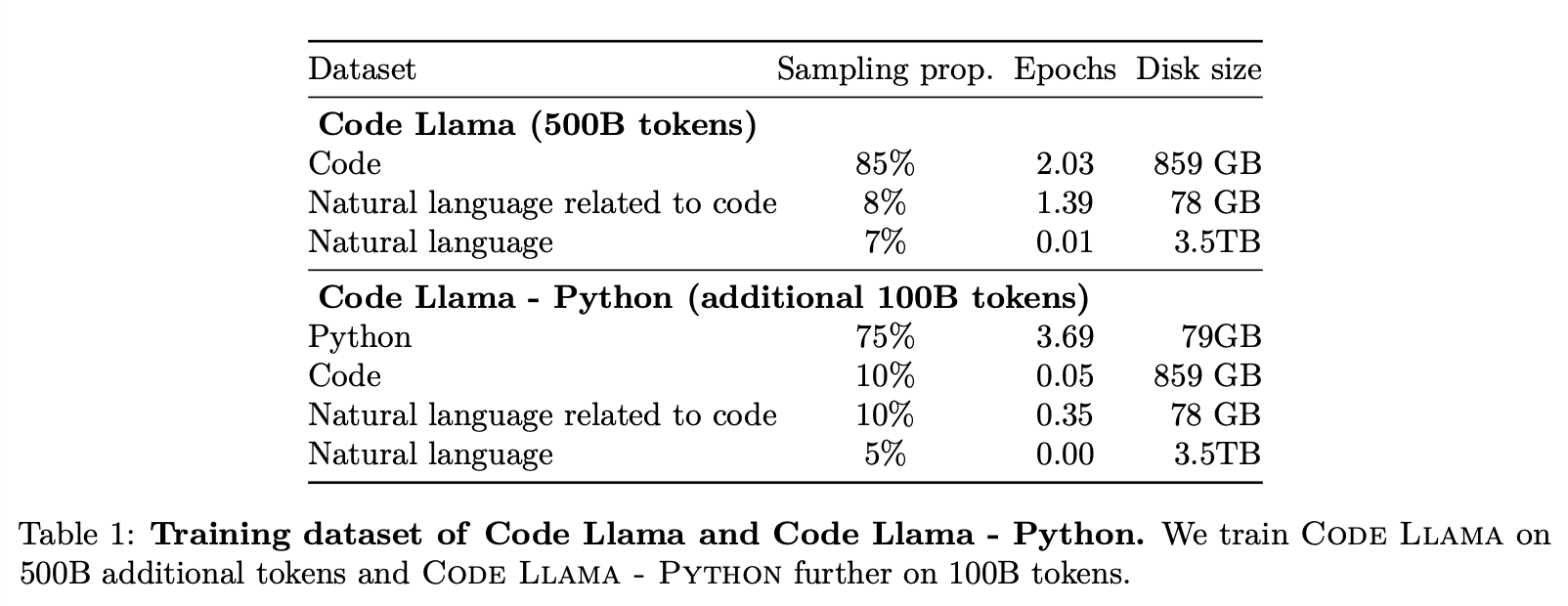
Dataset
-
Natural Language Related to Code
- discussions about code and code snippets
-
Natural Language
- natural language understanding skill을 보존하기 위해 포함시킴
Infilling
Infilling을 위한 데이터들은 다음과 같이 구성된다.
먼저 모든 데이터들은 prefix-middle-suffix로 나눠진다. (splitting locations are sampled independently from a uniform distribution over the document length.)
이후, 전체 데이터의 절반은 prefix-suffix-middle (PSM) format, 나머지 절반은 suffix-prefix-middle (SPM) format으로 구성한다.
suffix, prefix, middle의 시작과 infilling span의 끝을 표기하기 위한 토큰이 추가된다.
이렇게 재배열된 데이터에 대한 auto-regressive training을 수행한다.
전체 데이터의 90퍼센트는 Infilling, 나머지는 일반 auto-regressive수행한다.
Long context fine-tuning
Code Llama에서는 최대 16,384 tokens을 다루기 위한 long context fine-tuning (LCFT) stage를 제안한다.
이들이 제안하는 방법은 다음과 같다:
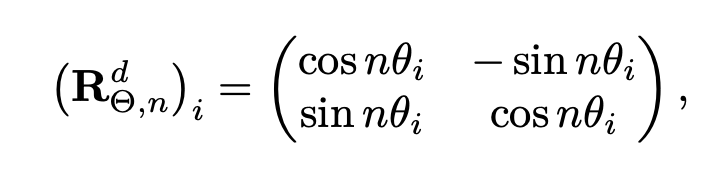
-
Problem
-
RoPE: RoPE applies a rotation operation to the input embeddings based on their positions.
-
weak extrapolation properties!
-
-
Solution: Change base period
-
Rotation frequencies are computed as θ_i = θ^{−2i/d},
-
기존에는 10,000으로 설정하여 relative position이 멀어지면 inner product값을 감소하는 효과를 가짐
-
base period θ를 기존 10,000에서 1,000,000으로 올림
-
이를 통해 보다 먼 거리까지 고려하도록 함.
-
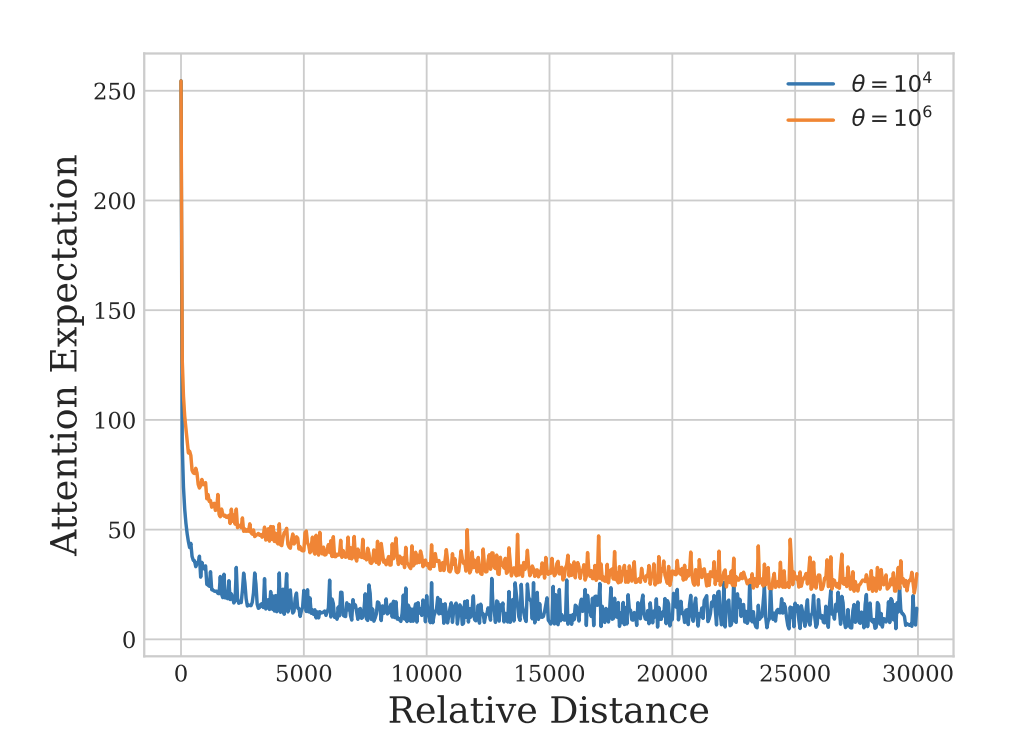
-
Attention expectations over relative distances between key and value embeddings
-
far-away tokens도 현재의 prediction에 더 기여하도록 바뀌었다는 것을 확인할 수 있음.
Instruction fine-tuning
instruction fine-tuned models Code Llama - Instruct은 Code Llama에 다음의 데이터셋을 이용하여 finetuning한 모델이다.
- Proprietary dataset
-
instruction tuning dataset collected for Llama 2
-
multi-turn dialogue between a user and an assistant.
-
few examples of code-related tasks
- Self-instruct



- Rehearsal.
- 코딩과 언어 이해 능력을 보존하기 위해서 Code Llama - Instructs는 code dataset (6%)과 our natural language dataset (2%)을 포함함.
Training details
-
batch size of 4M tokens
-
Long context fine-tuning
-
batch size is set to 2M tokens
-
10,000 gradient steps
-
Results
Code generation
-
description-to-code generation benchmarks for Python:
-
HumanEval (Chen et al., 2021),
-
MBPP (Austin et al., 2021)
-
APPS (programming interviews and competitions, Hendrycks et al., 2021).
-
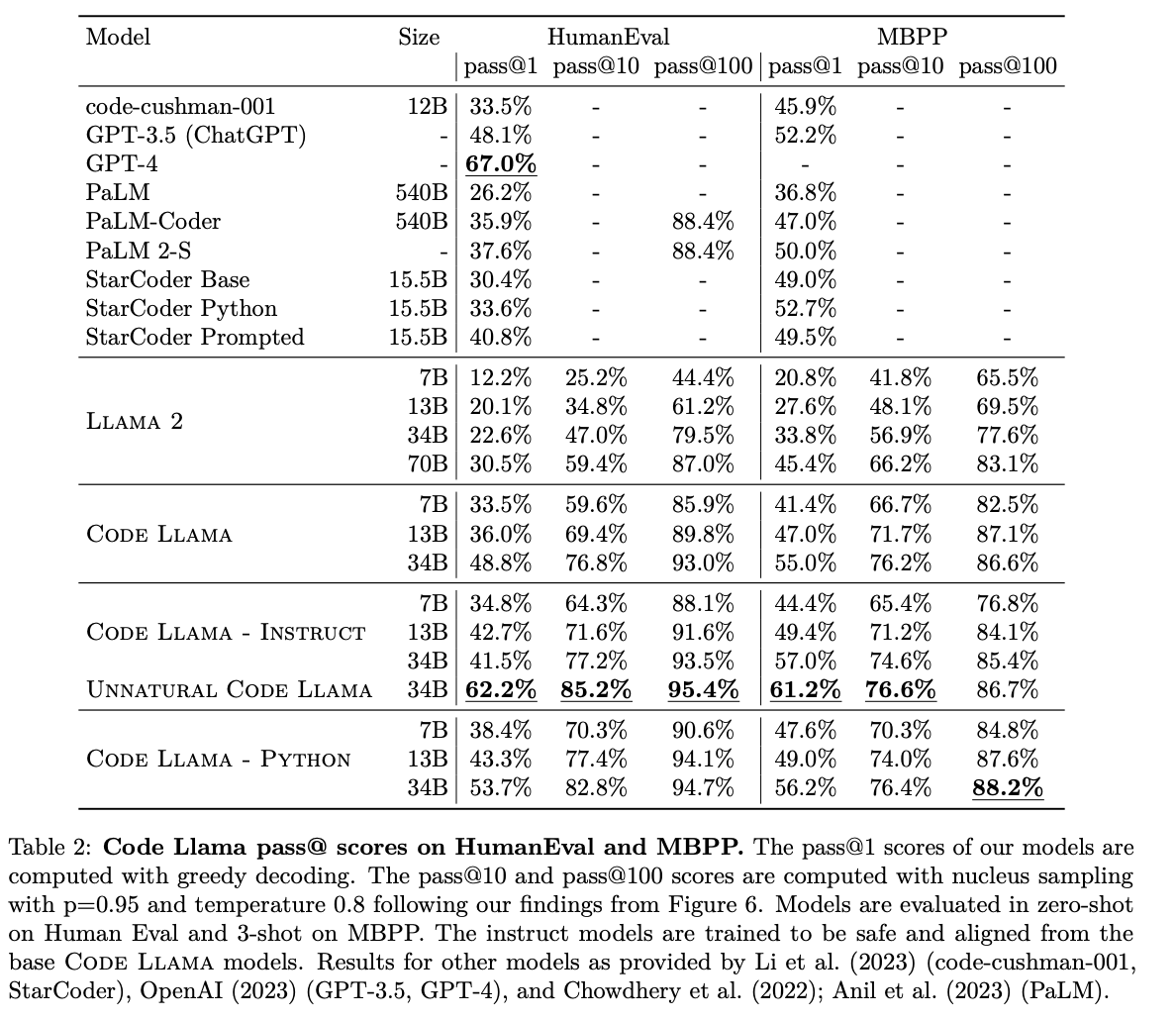
The value of model specialization.
-
Llama 2 vs Code Llama
- Llama 2 70B은 Code Llama 7B과 성능 비슷
-
Code Llama vs Code Llama - Python
- Code Llama - Python 7B가 Code Llama 13B outperform
Unnatural model.
-
unnatural instructions (Honovich et al. (2023))을 이용해 finetune
- 여러 개의 seed로 generate -> rephrase
-
indicative of the improvements that can be reached with a small set of high-quality coding data.
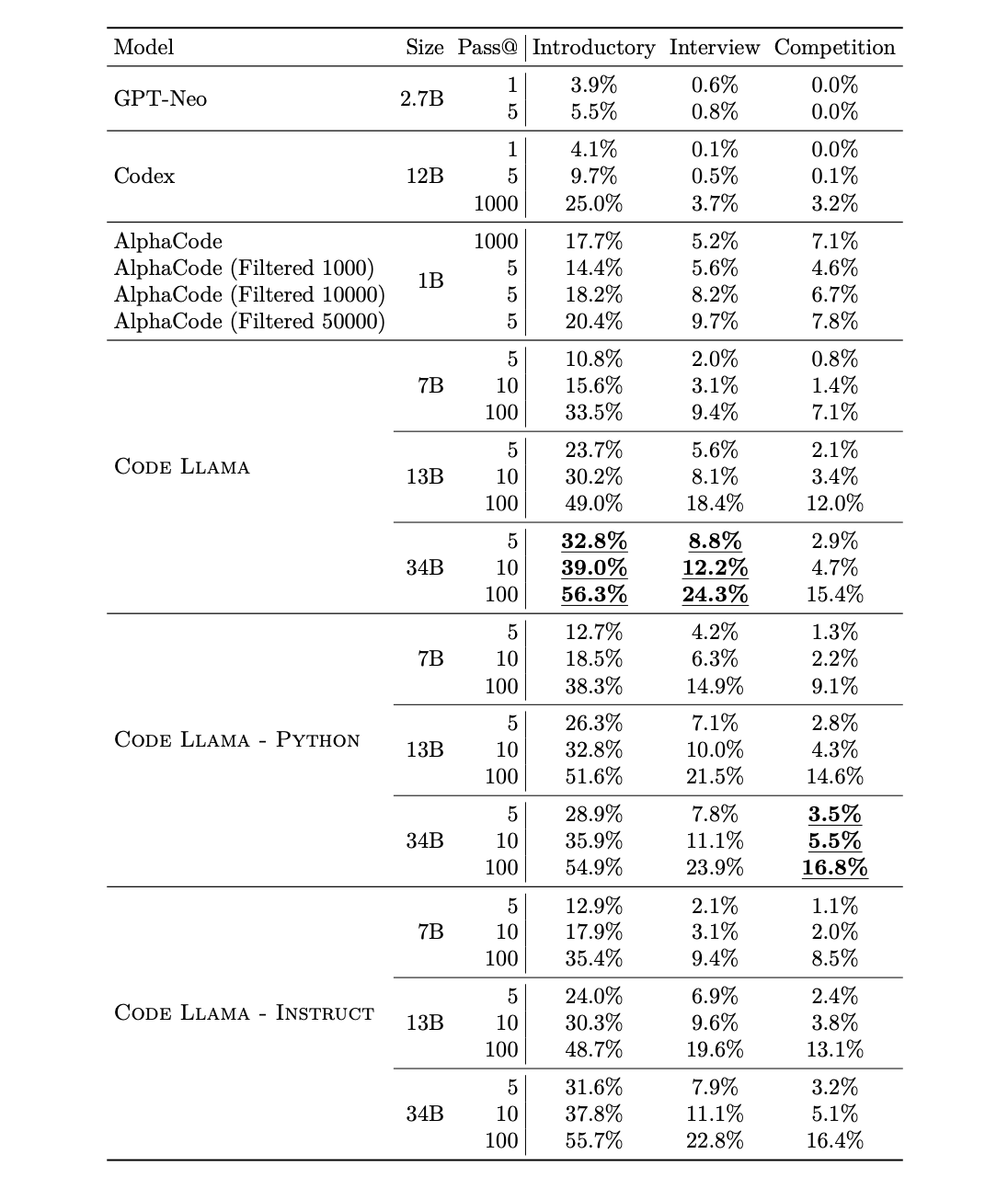
APPS benchmark는 위에서 소개된 벤치마크보다 더 어려운 태스크.
-
Code Llama - Python models은 introductory and interview level 태스크에서 성능 저하를 보였다. 즉, 프롬프트 자체를 이해하는 것이 solution을 내는 것보다 어렵다는 것을 Imply.
-
Code Llama - Python은 competition-level problems, solution 자체를 더 구하기 어려운 태스크, 에서 더 좋은 성능을 보였다.
Scaling of specialized models. specialized 모델들을 기준으로, 크기가 크면 언제나 성능이 더 좋았다.
Multilingual evaluation
Python 이외에 Multilingual 성능 또한 평가한다.
-
MultiPL-E (Cassano et al., 2022)
- C++, Java, PHP, C#, TypeScript (TS), and Bash.
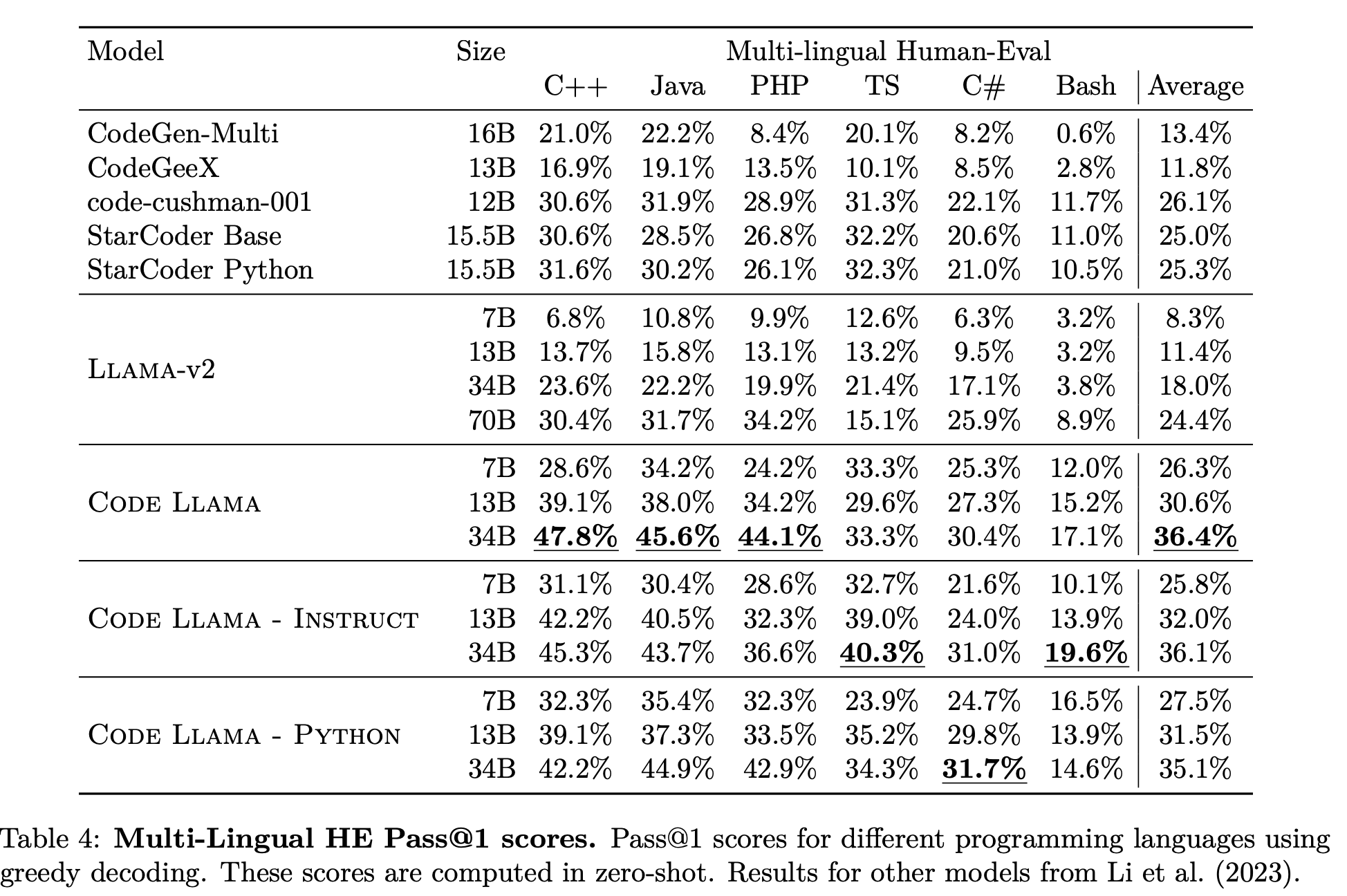
mono-lingual setting과 비슷한 결과를 확인할 수 있다.
-
Code Llama models clearly outperform Llama 2 models of the same size on code generation in any language,
-
Code Llama 7B outperforms Llama 2 70B.
-
다른 publicly available models과 비교해도 확실한 성능
-
Code Llama -Python 30B는 Code Llama 30B보다 성능이 살짝 좋지 않았으나, Code Llama - Python 7B and 13B는 더 나았음.

multilingual pre-training의 영향력을 확인하기 위해 언어별 correlations을 찍어본 결과이다.
-
C++, C#, Java, PHP 사이 high correlation on model performance.
-
Python, Bash 사이 high correlation on model performance.
-
Lastly, as expected the bigger and more expressive the models, the higher the correlation between the performance across all different languages.
Infilling evaluations
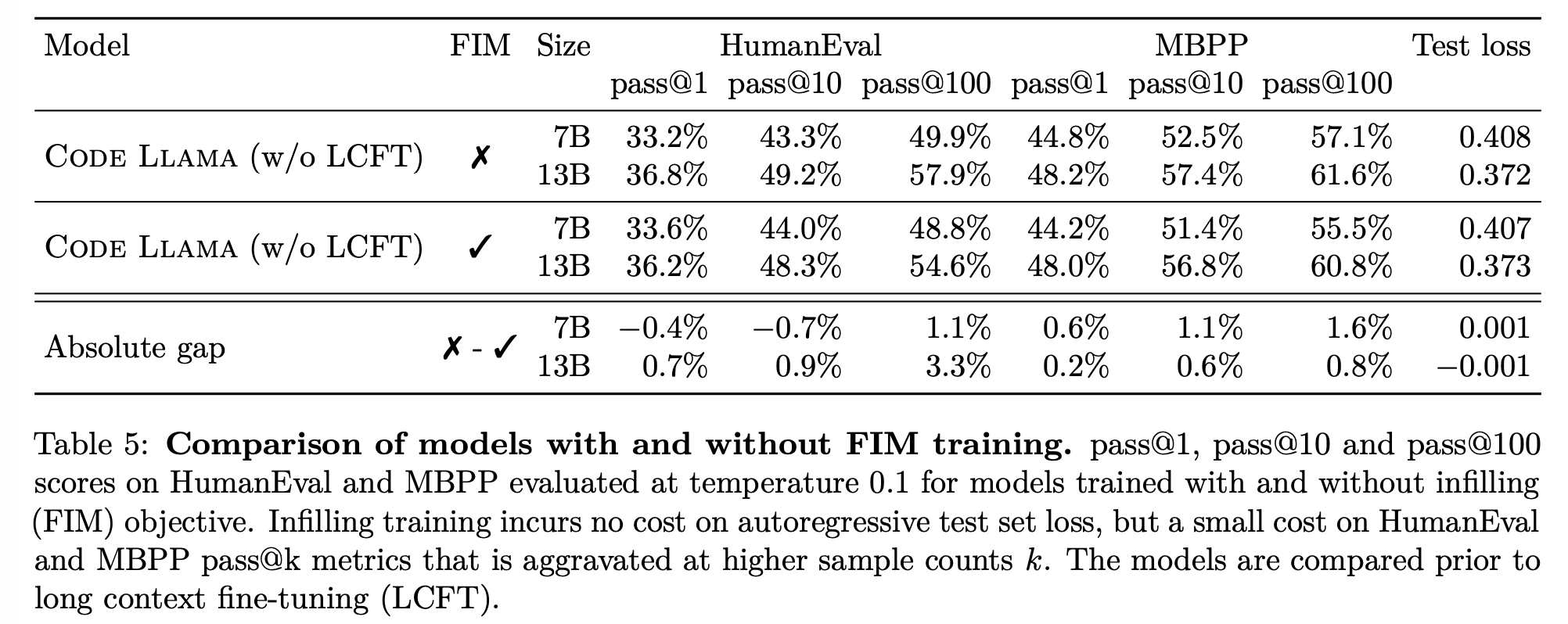
Long context evaluations
perplexity, synthetic retrieval task, code completion with long source code files
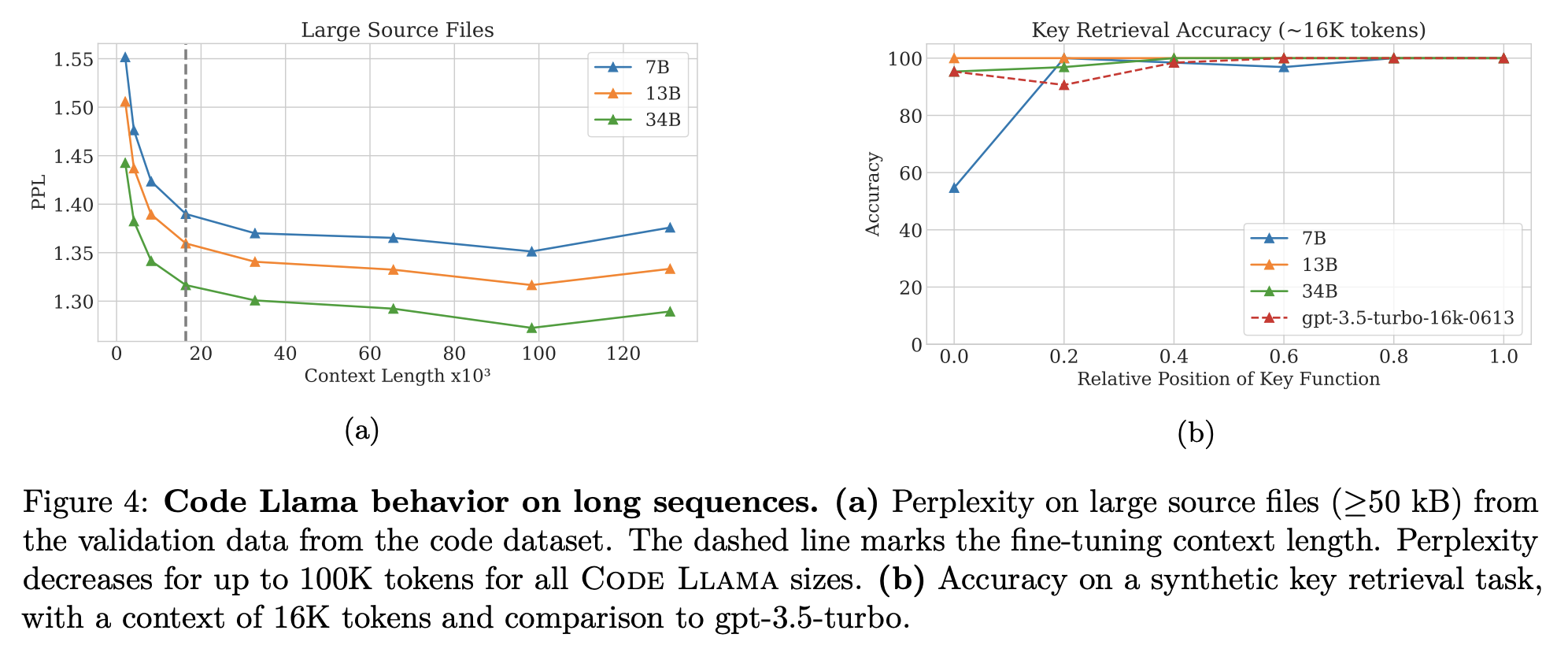
-
Perplexity during extrapolation.
- 16384 tokens 밑으로는 steady decrease
-
Key retrieval.
-
prompt: 특정 위치에 있는 scalar를 Return하는 Python function code
-
모델은 return value를 제대로 맞추는
assertstatement을 작성하도록 권유받음. -
거의 모든 모델은 strong retrieval performance
-
with the exception of the 7B model for test cases in which the function is placed at the beginning of the prompt.
-
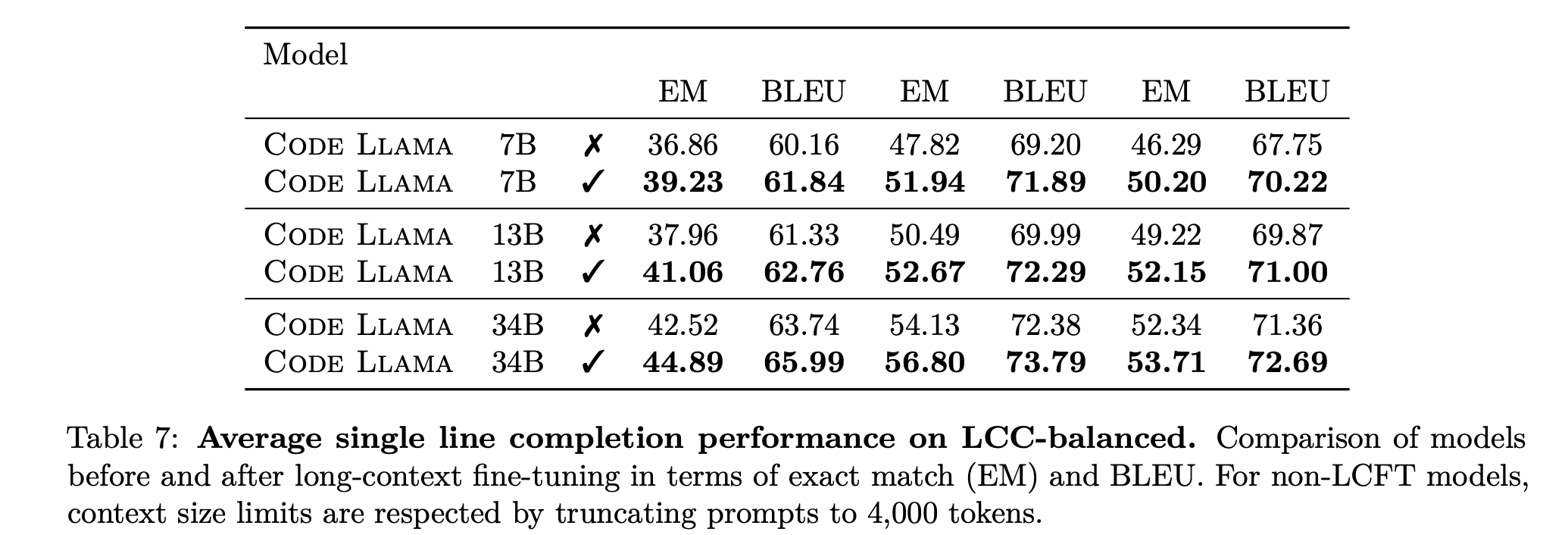
-
Single line completion.
-
Long Code Completion (LCC) benchmark
-
long contexts are informative for code completion
-
LCFT의 당위성 강조!
-
-
Performance impact on short contexts.
- LCFT을 하면 slightly hurts performance on standard code synthesis benchmarks consisting of short sequences.
Ablation Studies
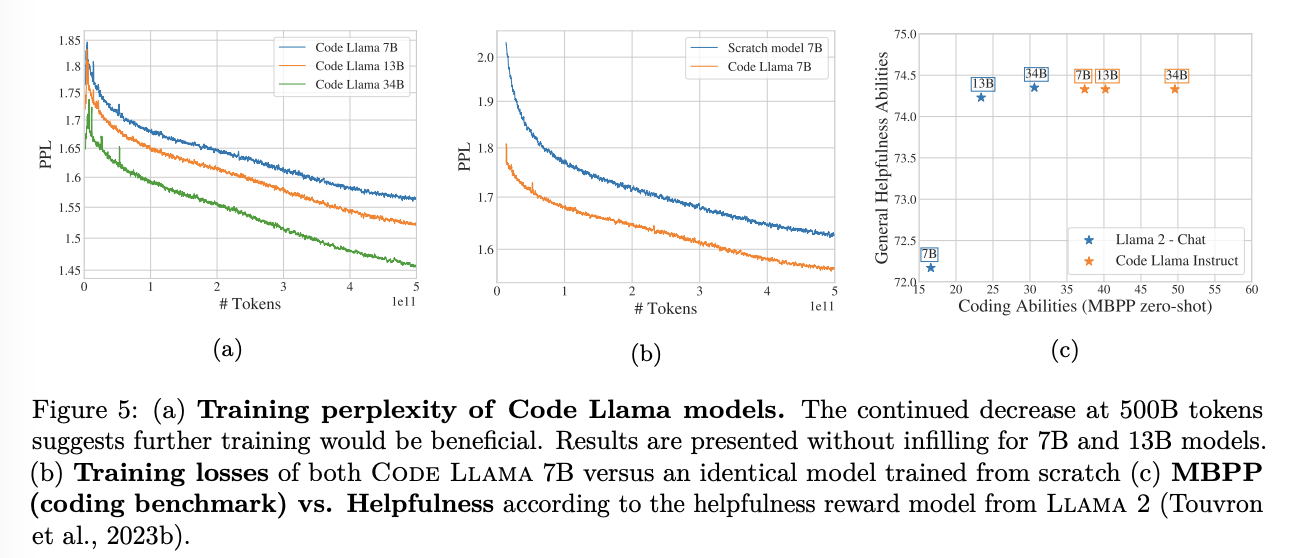
Fine tuning Llama 2 vs. training from scratch on code
(4b)를 보면, 거의 절반 차이를 보이는 것을 확인할 수 있다. 즉, fineuning이 훨씬 낫다는 것 강조!
Instruction fine-tuning
-
Code Llama - Instruct vs Llama 2-Chat
- Code Llama improves its coding abilities for each model sizes, while preserving the general helpfulness performance inherited from Llama 2.
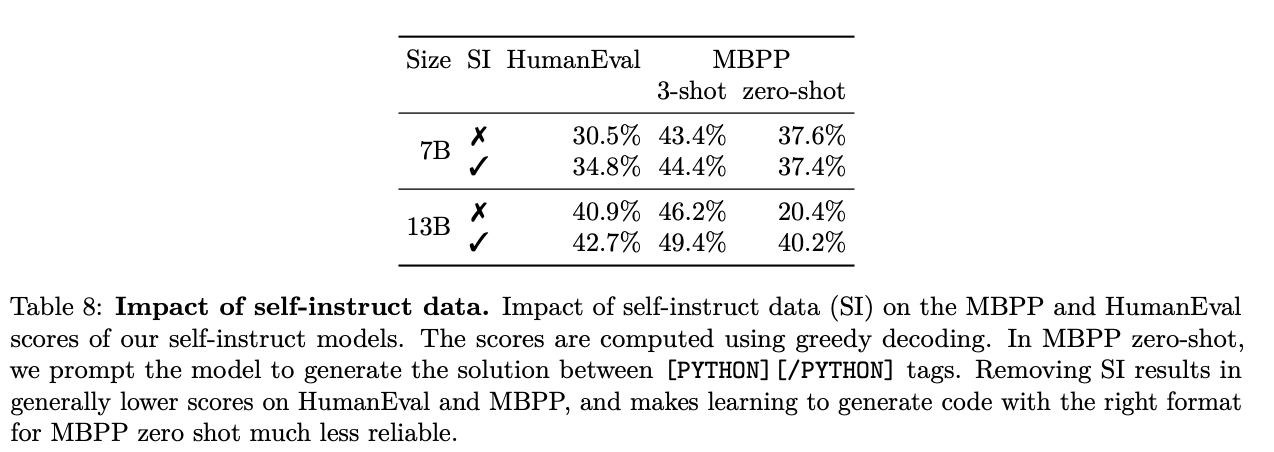
Impact of Self-instruct data