DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
논문 정보
- Date: 2023-10-03
- Reviewer: 김재희
- Property: Factual Consistency, LLM, Calibrating
1. Intro
-
LLM의 Hallucination은 여전히 해결책이 보이지 않는 문제
-
Hallucination을 줄이기 위한 연구 방향성 :
-
Retrieval-and-Augment
-
Knowledge Editing
-
Contrastive Decoding
-
-
해당 연구는 기존 모델에 대해 추가적인 학습을 하지 않고도, 1) Hallucination이 발생하는 부분을 찾고 2) 이를 수정할 수 있는 Decoding 기법을 제안
- Hallucinatoin이 발생할 때 모델 내부적으로 발생하는 특징을 포착하고 분석
-
ROME 연구에서는 Transformer를 다음과 같이 분석
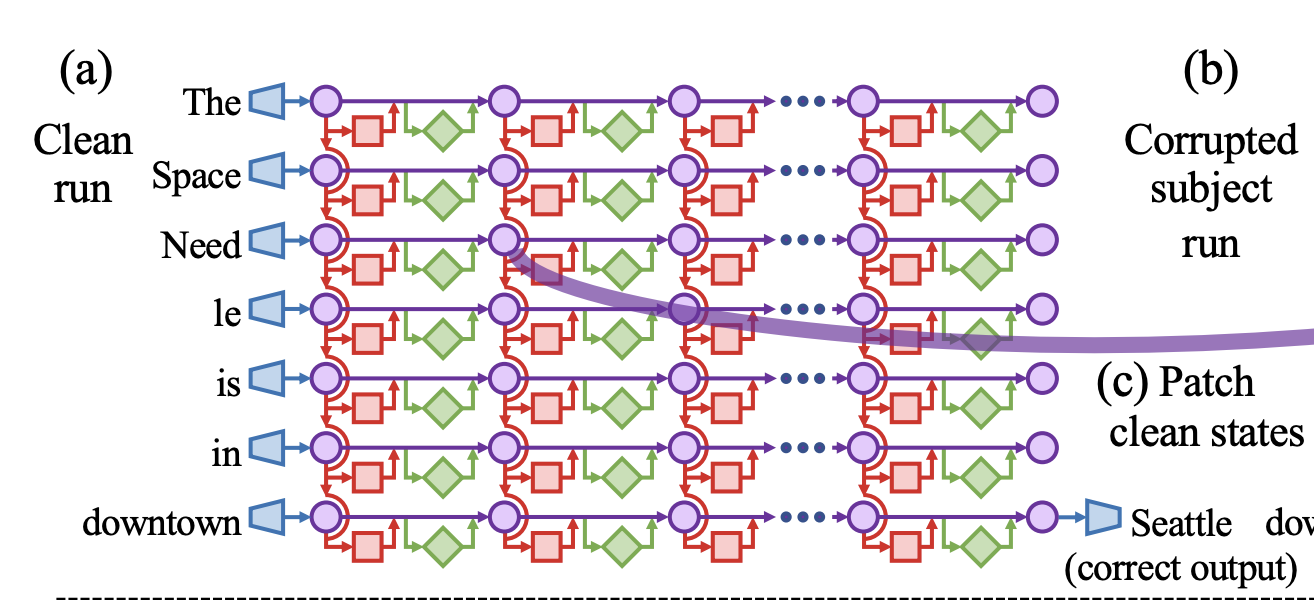
-
Input → Output으로 가는 직진 경로(Residual Connection)
-
각 레이어에선 Self Attention과 FFNN을 통해 추가적인 정보를 전달
- 이전 레이어의 정보를 이용하여 수정된 정보를 Residual Connection에 담음
-
모델의 Knowledge는 FFNN 레이어에 직접적으로 저장되어 있으며 수정가능
2. Method
- 해당 논문의 기본 아이디어 :
각 레이어 별 분포를 출력 vocab dist와 비교하면, 생성되는 토큰의 Factuality를 판단할 수 있다.
-
분포를 비교하는 것은 아래와 같은 수식을 통해 전개됨
-
t번째 토큰의 생성 토큰 distribution :
- \phi는 model_dim → vocab_dim의 FFNN 레이어
-
t번째 토큰의 j번째 레이어의 토큰 distribution
- 모든 레이어의 출력은 model_dim으로 동일하므로 \phi를 이용하여 vocab distribution을 산출할 수 있음
-
위에서 구한 t번째 토큰의 (마지막 레이어, j번째 레이어)의 토큰 Distribution의 차이를 이용하면, 아래와 같이 최종적인 생성 token distribution을 구할 수 있음
-
M : premature layer : 최종 레이어와 vocab distribution의 차이가 가장 큰 레이어
-
F : 상이하게 다른 두 vocab distribution을 이용하여 최종 생성 분포를 생성하는 함수
-
-
이때 F는 아래와 같이 정의
-
후보 Token 집합 \mathcal{V}_{\text {head }} : 실제로 Contrastive Decoding을 수행할 때 생성 후보로 고려된 토큰 집합
-
최종 생성 확률이 가장 큰 토큰 : 80%
-
V_head : 생성확률이 80*alpha 이상인 토큰
-
-
Contrastive Decoding
-
식은 매우 단순
- premature layer에서 확률을 낮게 부여하고, 마지막 레이어에서 높게 부여한 토큰일수록 실제 생성확률 역시 높도록 유도
-
-
위와 같은 Contrastive Decoding 과정은 매 토큰마다 이루어지게 됨
-
매 토큰마다 매 레이어와 마지막 레이어의 확률 분포를 이용하게 됨
-
실제로 모든 레이어에 적용하면 연산량이 많아지므로, 모델 크기에 따라 사용 레이어의 범위(초반 20개 레이어, 중간 20개 레이어) 제한 및 짝수번째 레이어만 이용
-
-
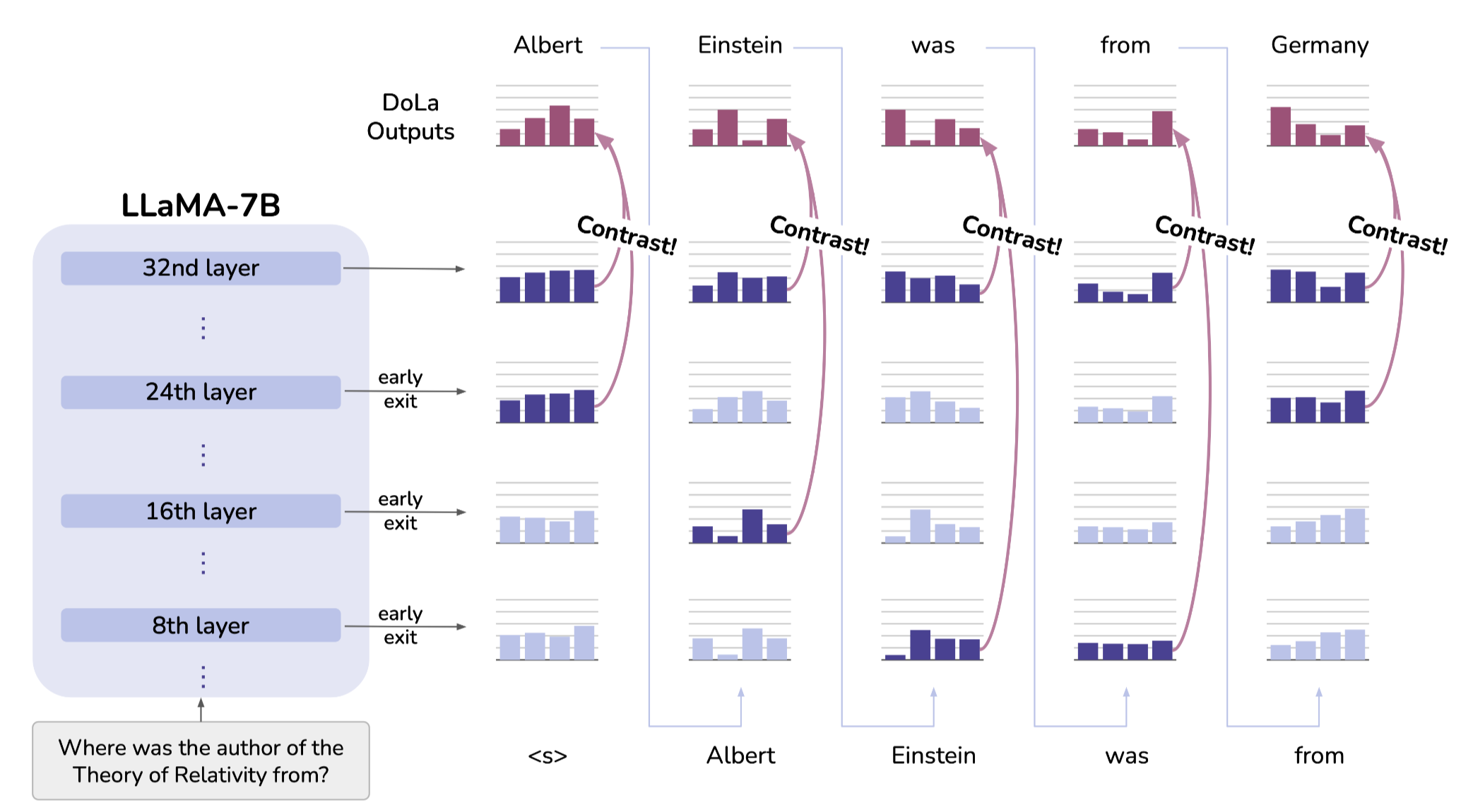
3. How It Works?
왜 위처럼 출력 Layer의 Vocab Dist와 분포 차이가 큰 Premature Layer를 이용하는 것이 Factuality에 도움이 되는가?
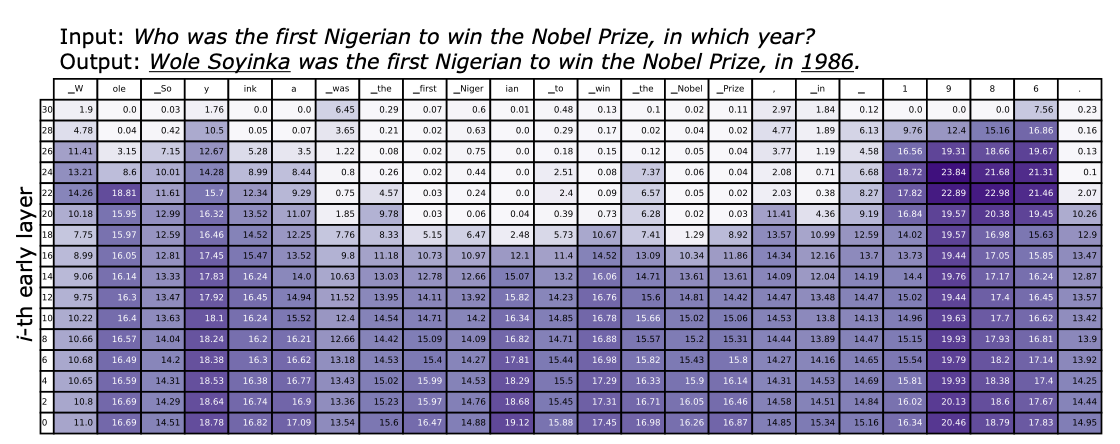
-
위 그림은 각 토큰 별 출력 레이어의 vocab dist와 각 레이어의 분포 차이를 시각화 한것
-
진한 색일수록 차이가 큼
-
크게 두가지 패턴 관찰 가능
-
-
Pattern #1 : Factuality에 중요한 토큰은 높은 레이어까지 큰 변화를 보임
-
해당 문장에서 Factuality에 중요한 Named Entity : Wole Soyinka, 1986
-
두 토큰을 생성할 때, 진한 색이 높은 레이어까지 유지되는 것을 볼 수 있음
-
⇒ Factuality에 중요한 토큰을 생성할 때, 모델은 레이어를 지나면서 지속적으로 정보를 변경
-
Factuality에 중요한 토큰은 다양한 정보를 수집하여 토큰을 예측해야 함
-
모델은 상위 레이어까지 지속적으로 다양한 정보를 수집하면서 예측을 수행
-
매 레이어마다 수집되는 정보가 바뀌면서 생성하고자 하는 토큰이 변화하는 것으로 해석
-
-
Pattern #2 : Factuality에 중요하지 않은 조사 등은 중간 레이어부터 매우 작은 변화를 보임
-
해당 단어들을 생성할 때는 많은 정보가 필요하지 않음
-
중간 레이어에서 이미 생성이 종료되었다고 볼 수 있음
-
⇒ 중간 레이어에서 생성된 토큰이 Residual Connection을 통해 끝까지 이어지는 모습
Factuality에 중요한 토큰은 상위 레이어에서 비로소 예측이 수행되므로, 중간 레이어에서는 Hallucination이 발생하게 됨. Contrastive Decoding은 Hallucination을 통한 생성을 Callibration 해주는 효과가 있는듯
4. Experiments
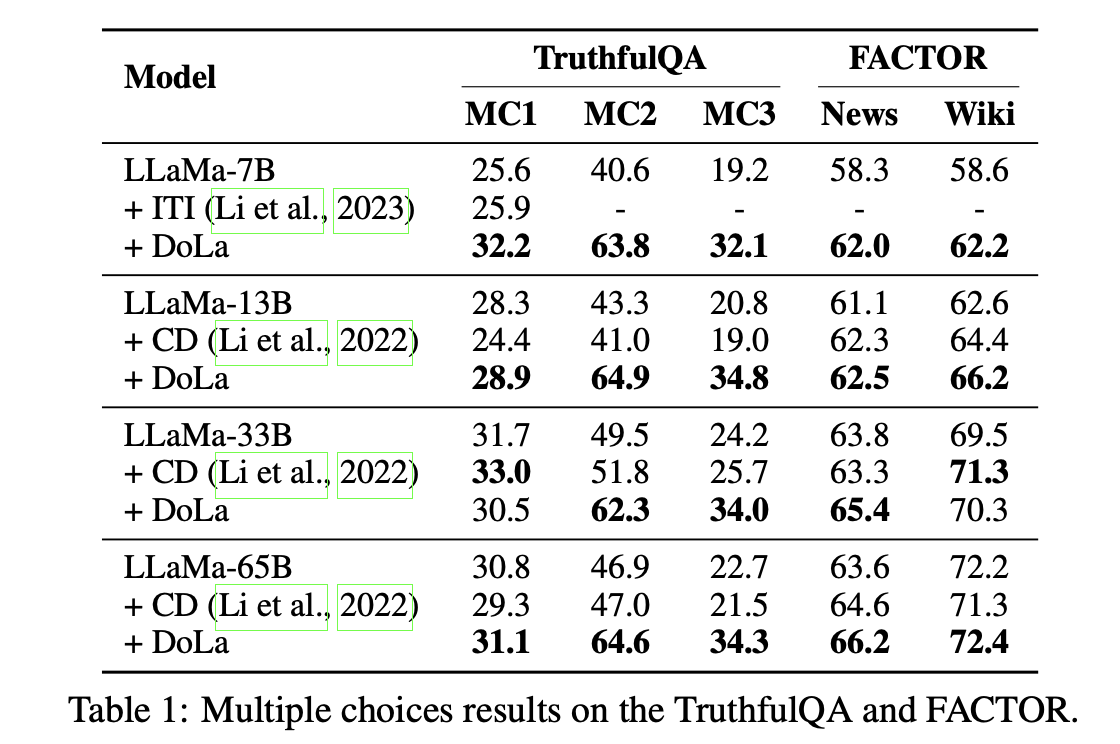
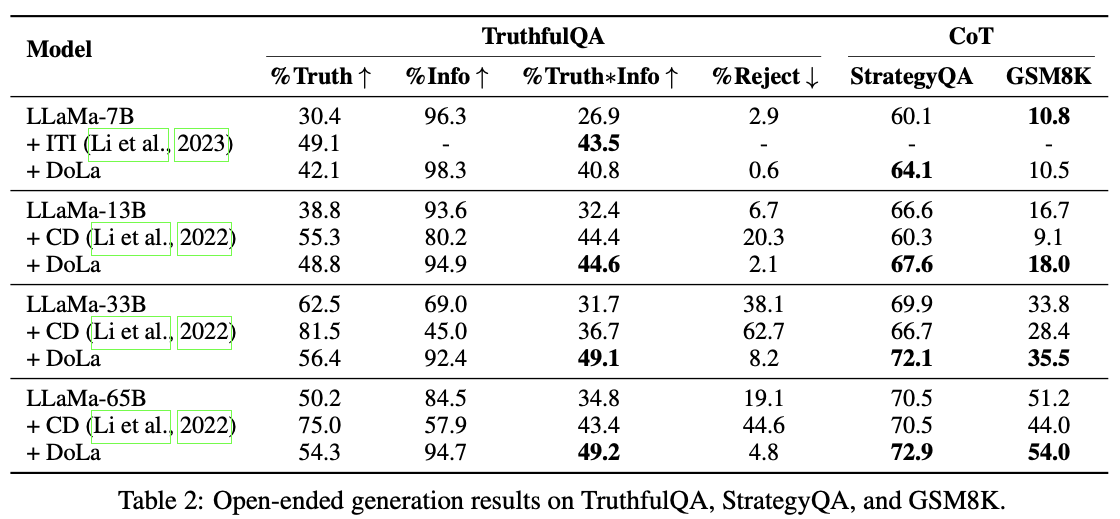
- Factuality 측면에서 별도의 학습없이도 SOTA의 성능을 달성하는 모습
-
다양한 지표에 있어서도 여전히 앞서는 모습을 보이고 있음
-
이전 연구인 Contrastive Decoding은 Information이 매우 떨어지는데, DoLa는 오히려 Information이 높아지는 모습
⇒ Hallucination이 줄어들 뿐만 아니라 정확한 정보를 원활하게 문장 형태로 생성
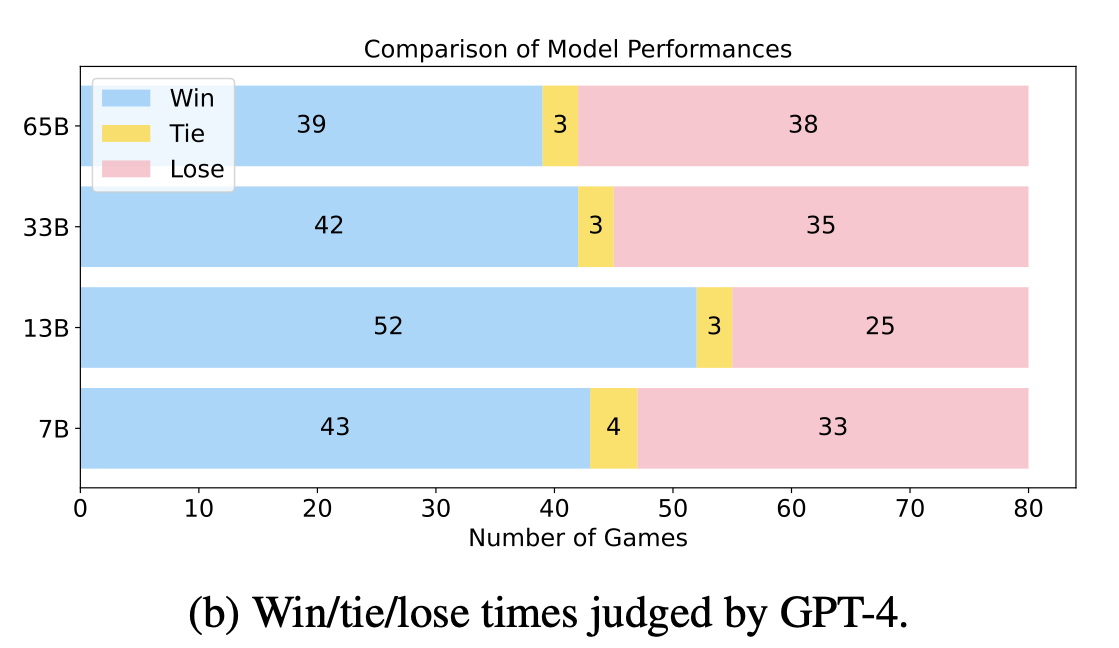
-
LLaMa 모델에 DoLA 적용 유무에 따른 Auto Eval 결과
-
모델 크기에 관계없이 비슷하거나 더 좋은 성능 기록
-
문장 생성 능력 측면에서도 악영향을 끼치지 않는 모습
-
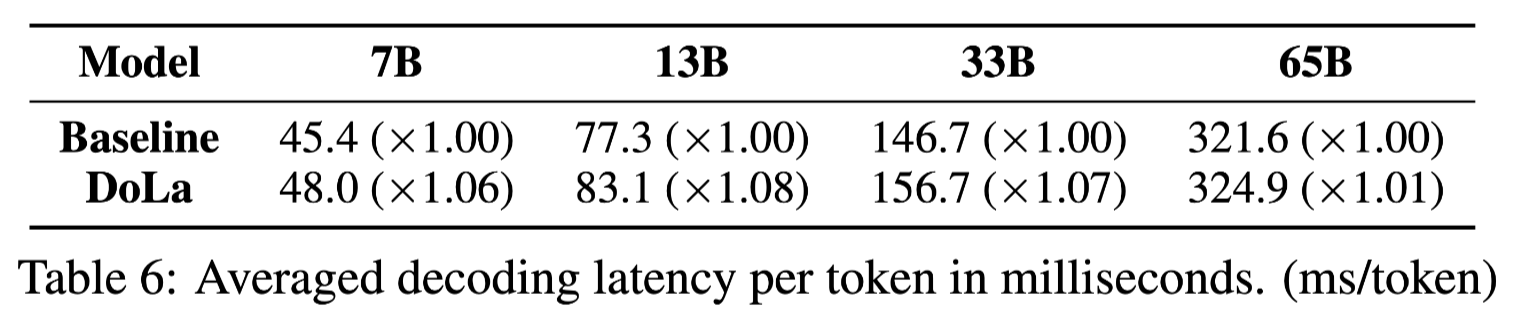
-
DoLA 적용 여부에 다른 속도
-
DoLA를 통해 필요한 추가 연산은 다음과 같음
-
각 레이어 별 Vocab Dist 산출
-
각 레이어 별 Vocab Dist와 마지막 레이어의 Vocab Dist 차이 비교
-
Premature Layer와 분포 비교를 통한 Decoding
-
-
전체 모델 크기에 비해 연산량이 매우 미비하여 속도 저하 거의 X
-
7. Conclusion
-
추가 학습 없이도 Factuality를 향상시키는 Decoding 방법론 제안
-
모델이 어떻게 Factuality를 확보하는지 내부 레이어 분석을 통해 설명
-
ROME을 많이 인용하고 있고, 아이디어의 기반으로 삼고 있음