EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
논문 정보
- Date: 2023-10-31
- Reviewer: 김재희
- Property: LLM
1. Intro
-
Pretrained LM의 Max Length를 늘리는 방법론 제안
-
Attention Mechanism 상 단순 Sliding Window 방식의 문제점 지적
- 단순 조정을 통한 Long Context 상에서 Attention Mechanism 문제점 개선 방식 제안
LLM Streaming 환경에서 22.2 배 빠르면서, 성능 저하가 없는 방법론 제안!
2. Previous Works
-
매우 긴 입력값이 Pretrain LM에 주어질 경우 두가지 문제점 발생
-
Computation Cost : Attention Mechanism은 O(T^2)의 복잡도를 가지고 있음
-
입력 길이가 길어질수록 매우 많은 연산을 필요로 하게 됨
-
Performance Deline : Pretrain 길이보다 긴 입력 시 급격한 성능 저하 발생
-
학습되지 않은 Positional Encoding
-
긴 입력에 대해 모델이 적절한 Attention 부여 실패
-
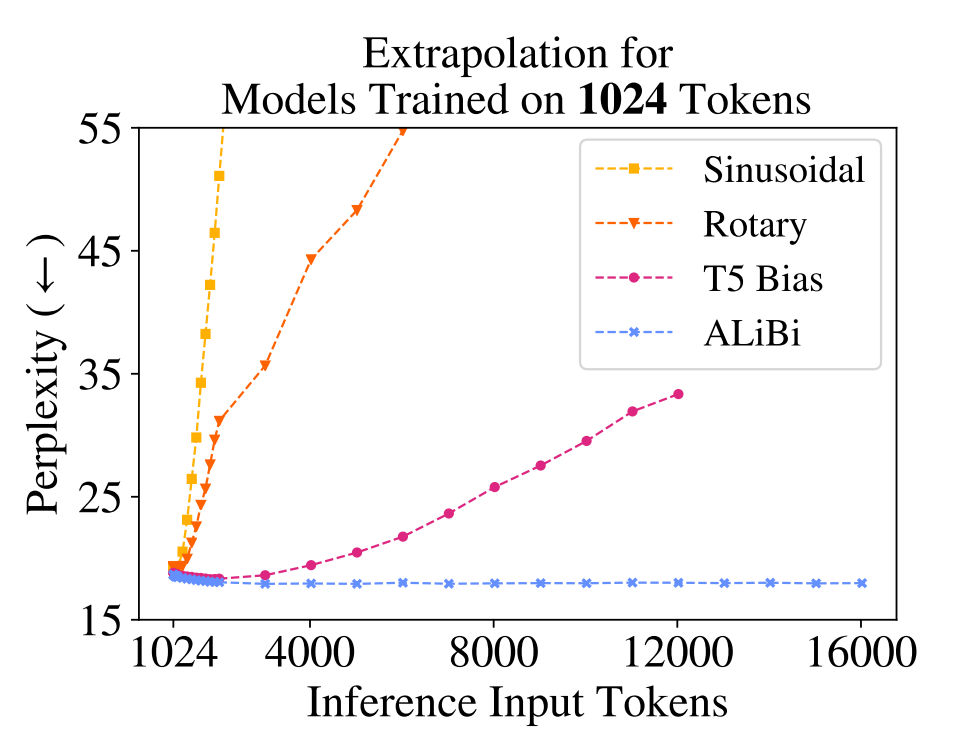
- Positional Encoding 및 Attention의 문제는 ALiBI 및 RoPE 등을 통해 완화되고 있는 추세
⇒ Query-Key 간 거리에 따라 Attention Score를 직접 조정하는 방법론들
⇒ Pretrain 및 Model Architecture 설계 시 미리 반영되어 있어야 함.
-
긴 입력을 나누어 처리하는 방법론 역시 존재
-
L : Model Max Length
-
T : Input Length
-
T » L
- Window Attention : LLM에서 흔히 사용되는 Key, Value Caching을 Max Length만큼만 유지하는 방법론
-
⇒ Max Length(L) 이상의 입력 및 출력에서 시간 복잡도를 줄일 수 있음
⇒ 성능 저하가 매우 극심하게 발생
⇒ Positional Encoding만으로 Long context를 다룰 수 없음
- Sliding Window : Input을 L 길이로 잘라서 연산하는 방법론
⇒ L 길이로 잘라서 Full Attention을 매번 계산하므로 높은 시간복잡도
⇒ 성능 저하가 거의 발생하지 않음
⇒ Long Context를 다룰 때 꼭 모든 이전 토큰이 필요하지 X
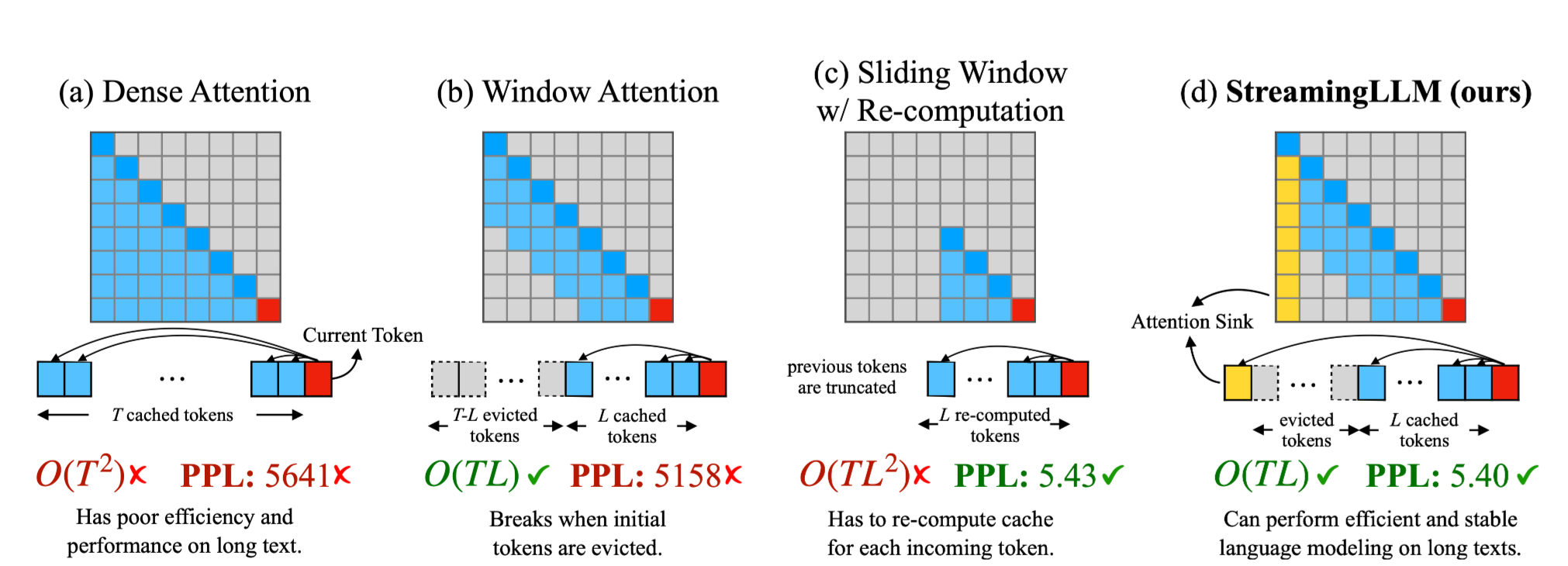
-
Window Attention은 성능이 망가지는데, Sliding Window는 그렇지 않다…?
- L 개의 이전 K, V를 이용하여 현재 시점의 Attention을 취하는 것은 동일
⇒ Long Context를 다루는 기존의 방법론들이 놓치는 무엇인가가 있는 느낌…
두 방법론의 차이를 발생시키는 Attention Mechanism의 특징을 포착하고, 이를 이용해보자!
3. Attention Sink
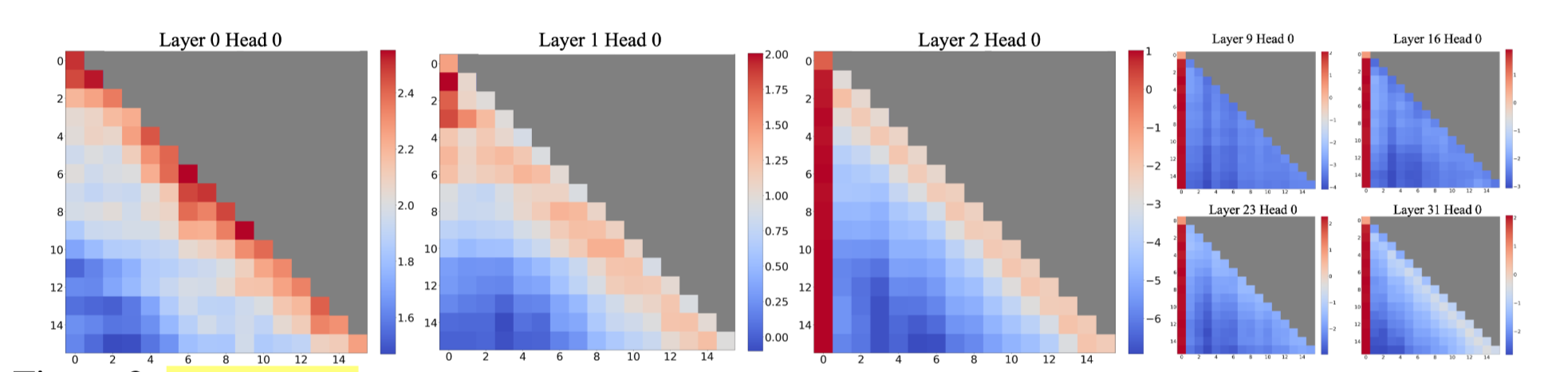
많은 양의 Attention의 특정 Token으로 쏠리는 경향이 매우 강하게 존재한다.
-
Input과 관계없이 많은 양의 Attention이 첫 토큰으로 쏠리는 모습을 볼 수 있음
-
Llama의 경우
토큰이 존재 -
의미를 가지고 있지 않은 토큰임에도 많은 Attention이 쏠리는 모습을 보임.
-
⇒ Attention Sink : 의미 및 구조 정보와 관계없이 특정 토큰(Sink Token)으로 Attention이 몰리는 경향
What Makes Attention Sink

-
위 현상의 원인을 분석하기 위해 2가지 가설 설정
-
Sink Token이 실제로 의미적으로 중요한 토큰 → Attention이 가해져야 하는 토큰들이 원래 input의 첫번재 토큰
-
Absolute Position으로 인한 강한 Bias를 학습 → 모든 input의 첫번째 토큰
-
-
(x+y) 토큰 조합을 통한 성능 변화 관찰 실험
-
x : 가장 첫 토큰 x개
-
y : 마지막 토큰 y개
-
-
0 + 1024 : 현재 토큰 이전 1024개의 토큰을 이용(Sliding Window)
-
4 + 1020 : 첫 4개 토큰과 현재 토큰 이전 1020개의 토큰의 K, V 값에 대한 attention 수행
-
4”\n” + 1020 : 첫 4개의 토큰을 \n으로 설정하고 2번째 실험과 동일 실험
⇒ 2, 3번째 실험이 비슷한 값을 보이고 있음
⇒ 무의미한 토큰(”\n”)일지라도 첫 x개의 토큰을 K,V에 포함하는 것이 성능 유지에 중요
⇒ 두번째 가설이 Attention Sink의 원인이라 할 수 있음
Why Attention Goes into Sink Tokens?
-
Attention Mechanism을 살펴볼 필요가 있음
-
현재 시점의 Query에서 이전 시점의 Key에 대한 Attention은 아래 식과 같음
-
query는 Key들에 대해 Value을 나누어 받게 되는 형태
-
이때 SoftMax 함수에 의해 Query는 이전 시점의 값들에 대해 무조건 Attention을 주어야함
⇒ 정보를 받고 싶지 않아도 무조건 정보를 받아야 함
⇒ 모델은 학습과정에서 Attention을 버릴 곳을 찾게 됨
Attention을 버릴 곳으로 거의 모든 Input에서 등장하게 되는 초기 토큰을 Attention Sink로 사용
-
위 개념에 대한 아이디어는 올해 7월 블로그 글에 처음 개제됨
- 아마 이 논문은 블로그 글을 발전시킨 형태가 아닐까…?
4. Experiments
Length에 따른 방법론 별 성능 비교

-
첫 K개의 토큰을 사용할 수 없어지는 시점부터 Dense Attention, Window Attention 모두 성능이 박살
-
Sliding Window의 경우 안정적인 성능을 유지하는 모습
- Pythia, Falcon은 Window Attention을 사용해도 성능 저하가 비교적 극심하지 않음
-
StreamingLLM(본 논문에서 Attention Sink를 이용해 첫 K개 토큰을 계속 살리는 방법론)은 Sliding Window와 비슷한 성능을 유지
Pretrain with Learnable Attention Sink
-
모델이 사전 학습 과정에서 첫 토큰들을 Attention Sink로 사용
-
첫 K개의 토큰을 Attention Sink로만 동작하도록 Pretrain시키면 어떨까?
⇒ 160m짜리 모델을 Scratch부터 학습시킴
⇒ Prompt Learning처럼 첫 K개의 토큰을 Learnable Token으로 고정

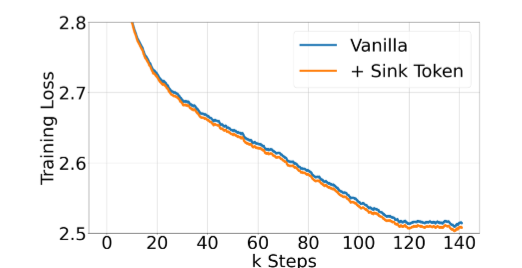
- Vanilla 모델과 비교하여 Loss 및 Downstream Task 모두에서 살짝 더 좋은 성능을 보임.

-
방법론 별 성능 차이 크지 않음
- 일관적으로 첫 k개의 토큰을 K,V로 사용하는 것이 중요
StreamingEval
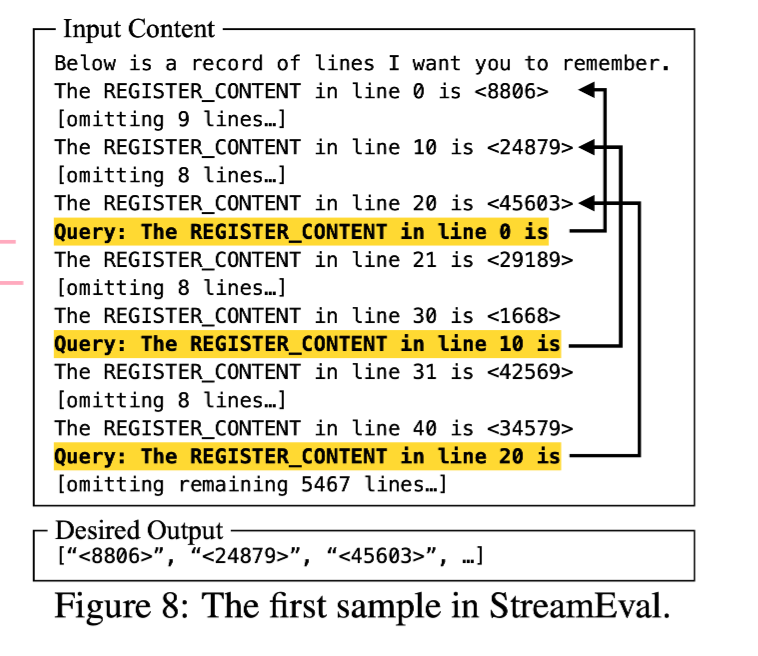
-
기존의 QA 데이터셋(ARC)를 전처리하여 Streaming 환경처럼 만든 데이터셋
-
특정 질문에 답변하기 위한 정보가 매우 먼 과거에 등장하게 됨
-
필수적으로 Long Context를 처리할 수 있어야 해결 가능한 데이터셋
-
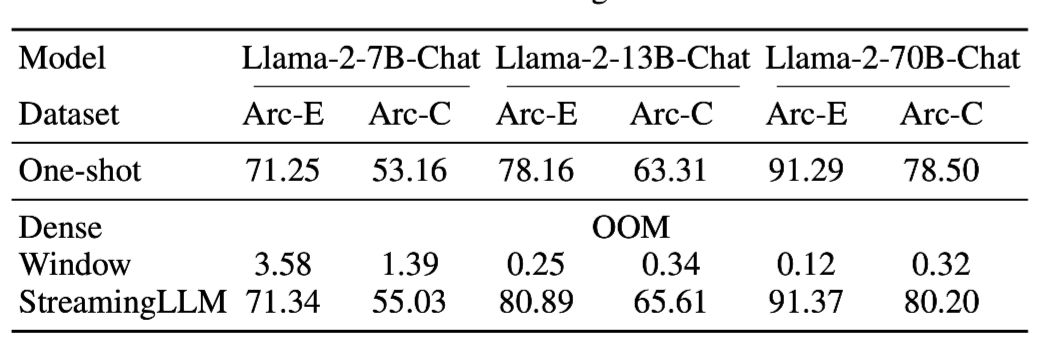
-
Dense : 너무 긴 Input으로 OOM 발생
-
Window : 역시나 성능 박살
-
StreamingLLM : 단일 QA(One-Shot)과 비슷하거나 더 좋은 성능 달성
⇒ 긴 Input에서도 필요한 정보에 잘 Attention을 줄 수 있음!
Computation Efficiency

-
결론적으로 Long Context를 다루는 방법 중 StreamingLLM과 Sliding Window만 유의미한 방법
-
연산량, Latency 등을 비교하면, Context Length가 길어질수록 매우 큰 차이를 보이고 있음
- 메모리, Latency 등에 있어 매우 큰 우위 존재
7. Conclusion
Attention Sink 현상 규명 및 이를 이용한 Long Context Handling 방법론 제안
Attention Sink
-
Pretrained LM이 학습 과정에서 고정적으로 등장하는 첫 K개의 토큰에 필요없는 Attention을 버리는 현상
-
Attention Mechanism의 특성 상 정보를 받을 필요가 없는 Attention은 의미적 관계와 관계없이 특정 토큰에 주어지게 됨
StreamingLLM
-
Attention Sink 현상을 이용하여 Long Context를 적절히 Handling 하는 방법론
-
기존 Window Attention에서 첫 K개의 토큰 K, V를 유지하는 방법론
⇒ Sink Token을 유지하여 Attention을 버릴 수 있도록 함
Contribution
-
Long Context 상에서 성능 저하가 발생하지 않음
-
Sliding Window에 비해 낮은 Computation Cost 발생
Limitation
- 조금 더 다양한 Downstream Task에 대한 성능 비교 필요