GPT Understands, Too
논문 정보
- Date: 2023-03-30
- Reviewer: yukyung lee
- Property: Prompt Tuning
1. Overview
Summary
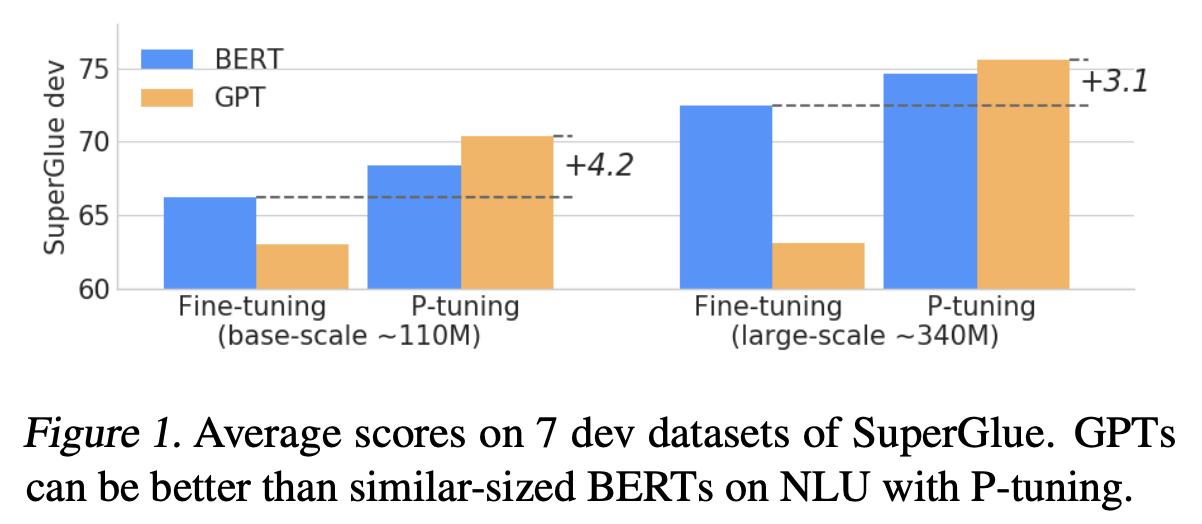
-
GPT계열의 단방향 Language model들은 NLU task에서 BERT보다 낮은 성능을 기록했음
-
본 연구에서 제안하는 P-Tuning을 적용하면 GPT는 BERT의 성능을 능가할 수 있음을 보임
-
Full finetuning보다 P-tuning의 성능 향상폭이 훨씬 더 큼을 알 수 있었음
Motivation

-
hand crafted prompt는 Input prompt의 형태가 조금만 변경되어도 성능에 큰 차이(drastic difference)를 보였음
-
기존에 수행되던 prompting 방식을 고수하기엔 문제점이 존재함을 지적함
-
GPT3는 적절한 Promp를 이용해서 NLU task를 풀이할 수 있지만 매번 좋은 Prompt를 찾는것은 현실적으로 어려운 일임
2. Background
Discrete Prompt Search
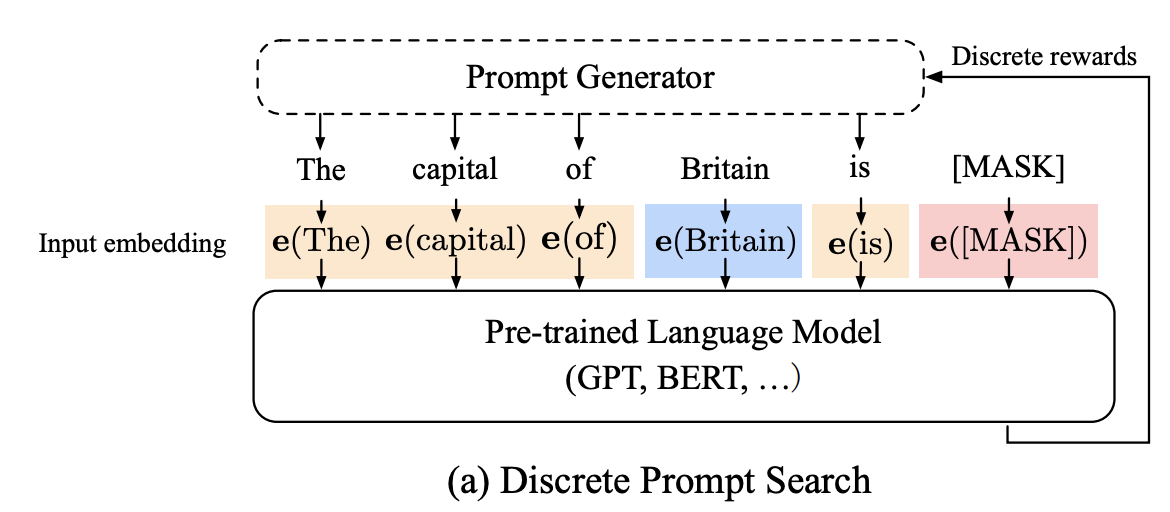
-
앞선 문제를 해결하기 위해 prompt generator가 제안됨
-
orange: prompt / blue: context / red: target ([MASK])
-
LM의 Loss를 reward로 삼아 generation을 수행했으나, 이 방법은 각 Token은 이산적이므로 NN 관점에서 기존 방법은 suboptimal 일 수 있음
3. Method
P-Tuning : Continuous space에서 Prompt를 찾자 !
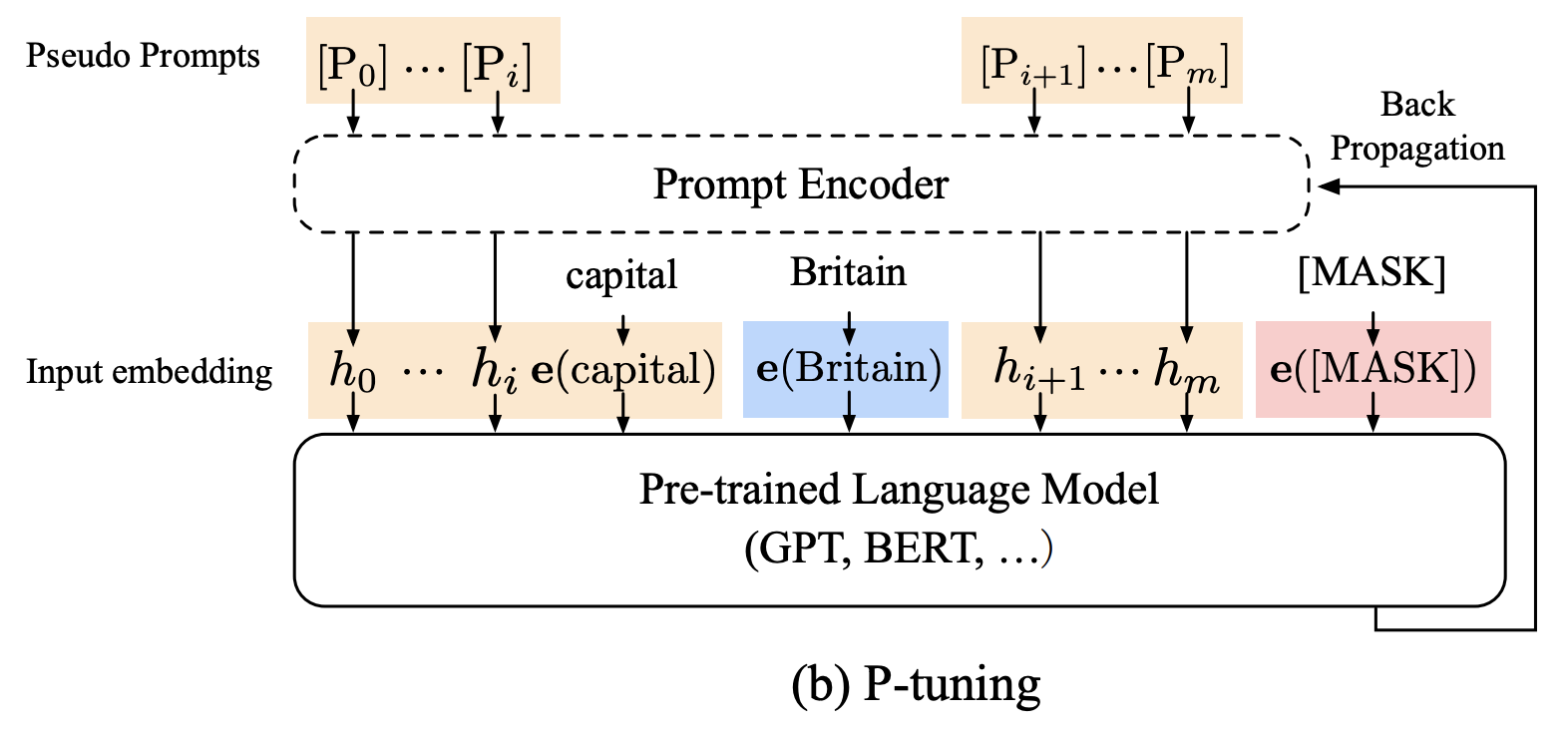
- Bi-LSTM기반의 prompt encoder를 활용하여 이산적인 token의 특징과 각 token과의 connectiveness를 함께 활용할 수 있도록 embedding을 생성하게 됨

-
Pseudo prompt라는 Random init된 값을 활용하여 prompt를 학습함
-
Original token을 그대로 사용하는 경우는 anchor token으로 지칭하며 정답 Input을 제공함
-
PLM의 Parameter는 freeze한채로 사용됨 (update X)
-
MASK에 대한 Loss를 통해 Prompt encoder를 활용하게 됨
-
메모리를 절약할 수 있는 방법 (PLM은 Inference만 수행함)
-
anchor token이 아닌 자리의 token들이 Prompt encoder만을 가지고 적절한 embedding을 학습할 수 있게 만드는 방법임
4. Results
Knowledge probling task
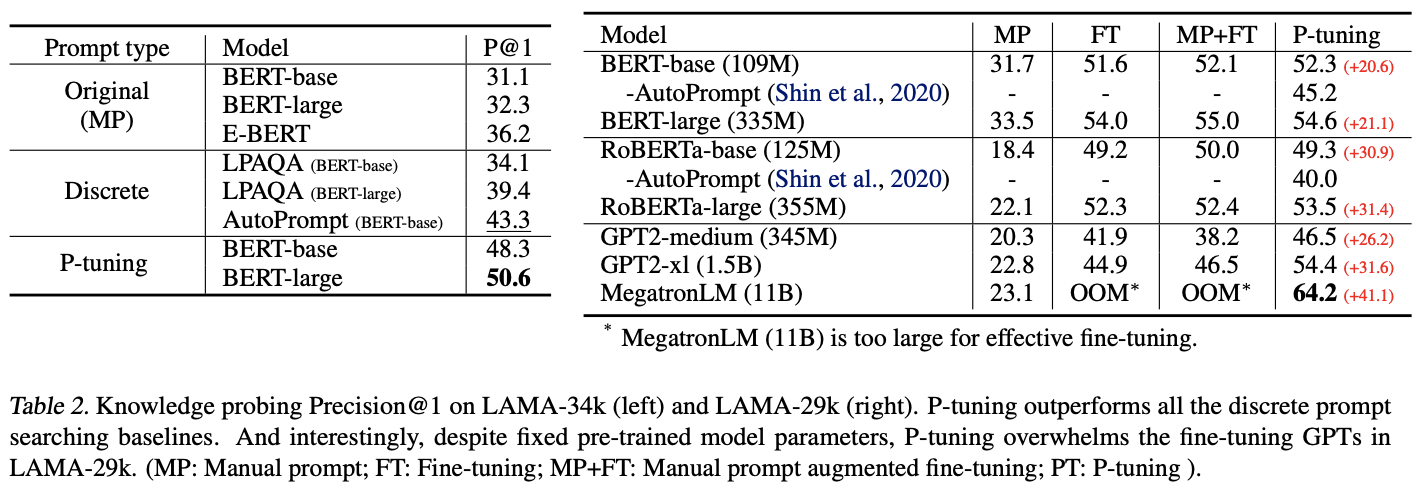
-
Manual, Discrete prompt보다 높은 성능을 보임
-
MP+FT : Manual Prompt Augmented Fine-tuning
-
거의 모든 경우 P-tuning이 높은 성능을 보임
SuperGLUE(Full finetuning)
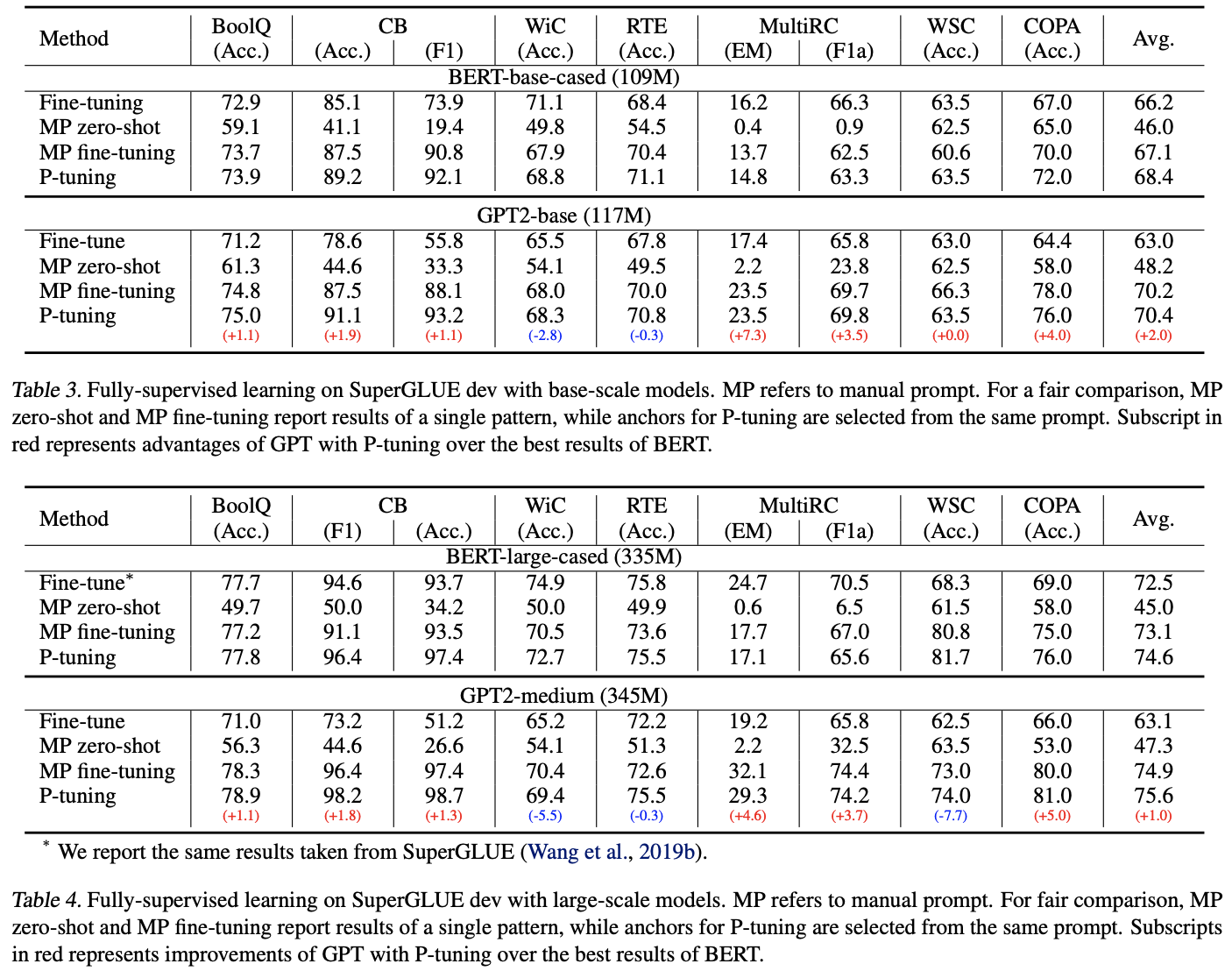
-
base-scale LM에서 finetuning보다 P-tuning이 높음
-
BERT + P-tuning < GPT + P-tuning
-
Large scale LM에서도 동일한 양상을 보임
SuperGLUE(Fewshot)
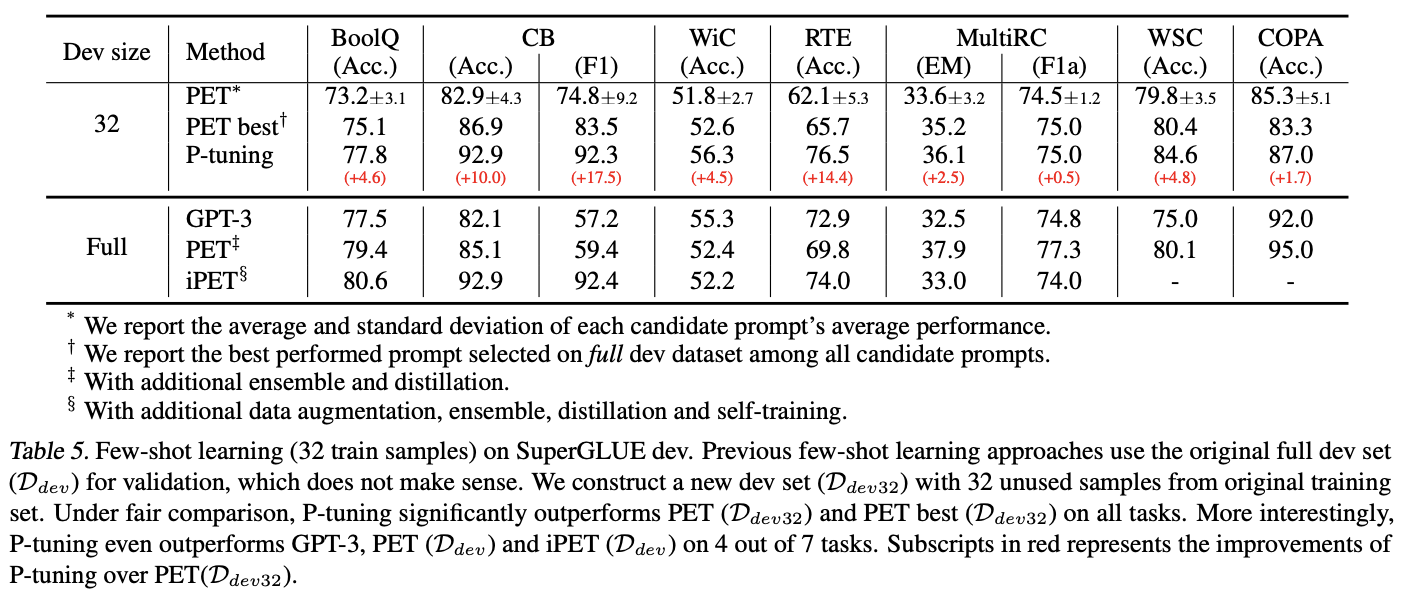
-
Few shot setting에서의 실험
-
GPT3보다 P-tuning이 더 좋은 성능을 보이고 있음