In-Context Learning Learns Label Relationships but Is Not Conventional Learning
논문 정보
- Date: 2023-10-31
- Reviewer: hyowon Cho
- Property: In Context Learning
Introduction
Brown 등(2020)은 대규모 언어 모델(Large Language Models, LLMs)은 처음 in-context learning (ICL)이 지도학습을 수행할 수 있다는 것을 보였다. ICL은 일반적인 가중치 학습과는 달리 모델 파라미터를 업데이트하지 않으며, downstream 작업의 입력-라벨 관계 예시가 단순히 LLM이 예측할 쿼리 앞에 추가된다. 이것은 종종 few-shot ICL로도 불리며, 기존 ICL 변형과 구분된다. ICL은 여러 NLP 작업에서 예측을 개선하기 위해 널리 사용되지만, 왜 ICL이 예측을 개선하는지에 대한 합의는 아직 없다.
이 논문에서는 ICL이 어떻게 작동하는 지에 대한 향상된 이해가 필요하다고 주장하며 세 가지 주요 질문에 집중한다.
첫째, ICL이 in-context 예시의 입력-라벨 관계를 고려하여 테스트 쿼리에 대한 예측을 하는가? 둘째, ICL은 pre-training에서 비롯된 예측 선호도를 극복할만큼 강력한가? 셋째, ICL은 in-context에서 제공된 모든 정보를 동등하게 취급하는가?
Background
Shortcomings of ICL
-
ICL은 in-context 학습 예시의 형식 (Min et al., 2022b) 또는 순서 (Lu et al., 2022)에 민감할 수 있다.
-
LLMs는 pre-training 데이터에서 일반적인 라벨을 예측하는 경향이 있다 (Zhao et al., 2021).
-
LLMs는 유사한 프롬프트에 대해 극명하게 다른 예측을 할 수 있다 (Chen et al., 2022).
-
LLMs는 pre-training 데이터에서 관찰된 작업 정의에 의존할 수 있다 (Wu et al., 2023).
특히, Min et al(2022b, Rethinking the role of demonstrations: What makes in-context learning work?)은 ICL이 in-context 예시에서 라벨 관계를 학습하지 않으며 ICL ‘성능이 데모에서 레이블이 무작위 레이블로 대체될 때 거의 변하지 않는다’고 주장한다. 그들은 ICL이 동작하는 이유는 모델이 general label space, 예시의 형식, 그리고 입력 분포에 대해 학습하기 때문이라고 말하며, input-label relationship을 학습하는 것이 아니라고 이야기한다. 즉, ICL이 ‘테스트 시간에 새로운 작업을 학습하지 않으며’ 많은 일반적인 시나리오에서 ‘실제로 ground truth demonstrations이 필요하지 않다’고 주장한다.
NULL HYPOTHESES ON HOW ICL INCORPORATES LABEL INFORMATION
당연히, 만약 ICL이 전통 학습 알고리즘처럼 행동하지 않는다면, 그것이 어떤 것을 달성할 수 있는지에 대한 기대를 크게 축소해야 할 것이다. 예를 들어, ICL이 LLM 예측을 충분히 조정할 수 없다면 LLM alignment를 위해 사용하는 것은 부적절할 것이다. 따라서, 다음의 세 가지 가설을 세워 그것들이 정말 사실인지 확인한다.
NH1: ICL prediction은 in-context에서 제공된 예시의 조건부 label distribution와 독립적이다.
먼저, Min et al이 말했듯, 정말 label randomization이 ICL predictive beliefs에 영향을 주지 않는지 실험한다.
NH2: ICL은 사전 훈련된 모델의 zero-shot prediction preferences를 극복할 수 있다.
사전에 훈련된 모델은 이미 여러 NLP 작업에 대한 정보를 포함하고 있고, 심지어 ICL 없이도 예측은 random보다 훨씬 우수하다. 따라서 저자는 in-context에서 제공된 정보가 이 pre-training prediction preferences와 어떻게 상호 작용하는지 알아본다.
만약, NH2가 참이라면, ICL은 결국 in-context에서 제공된 모든 라벨 관계에 따라 예측해야 한다.
NH3: ICL은 in-context에서 주어진 모든 정보를 동일하게 고려합니다.
NH3가 참이라면, ICL 예측은 라벨 관계 제시 순서에 의존하지 않아야 한다.
EXPERIMENTAL SETUP & ICL TRAINING DYNAMICS
-
Models & Tasks.
-
LLaMa-2, LLaMa, Falcon
-
SST-2, Subjective (Subj.), Financial Phrasebank (FP), Hate Speech (HS), AG News (AGN), MQP, MRPC, RTE, WNLI
-
-
Context Size
-
모든 가능한 in-context 데모 수에 대한 few-shot ICL 성능을 보고함.
-
zero-shot 성능부터 LLMs의 입력 토큰 제한 내에서 최대 예제 수까지.
-
-
Evaluation Metrics
-
정확도(↑)와 log likelihood(↑)로 few-shot ICL 성능을 평가.
-
엔트로피도 보고되며, 이는 예측된 확률이 클래스에 고르게 분포되어 있는지를 이해하는 데 유용.
-
-
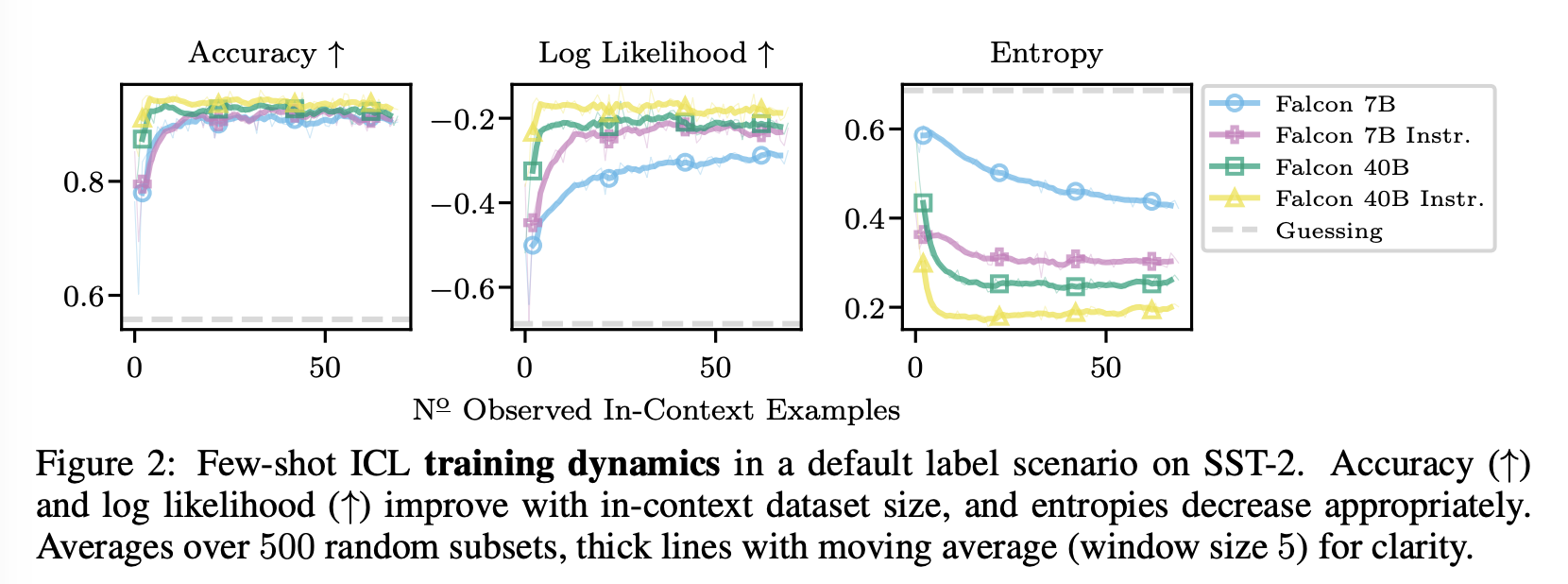
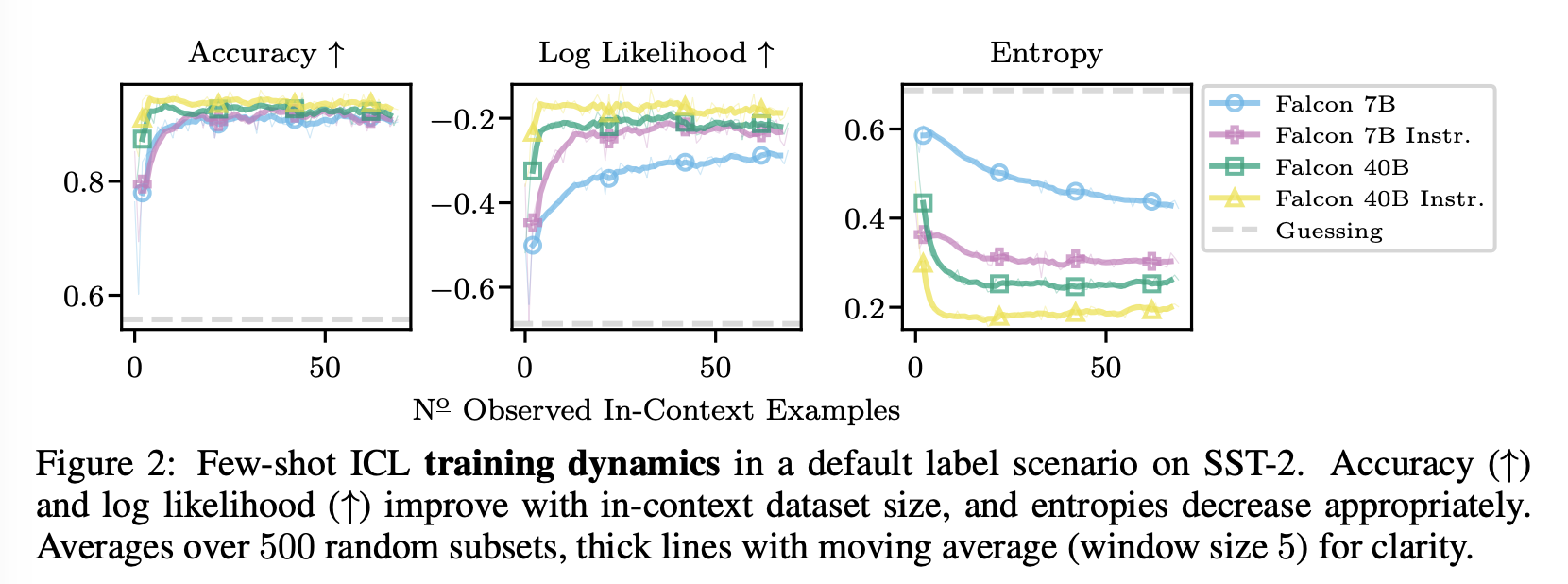
Default Training Dynamics.
-
모든 모델에 대해 합리적인 행동을 관찰: 더 많은 in-context 예제가 관찰됨에 따라 정확도와 log likelihood가 증가하고 엔트로피가 감소.
-
log likelihood에서 모델 간 차이점이 더 눈에 띄며, 큰 컨텍스트 크기에서 더 높은 certainty로 예측되는 것을 엔트로피가 나타냄. 결과는 LLaMa 및 LLaMa-2 모델에 대해서도 유사함 (Fig. F.1).
-
(1) DO ICL PREDICTIONS DEPEND ON IN-CONTEXT LABELS?
저자는 먼저 Min et al. (2022b)의 실험을 다시 살펴보기 위해 컨텍스트의 모든 예시의 레이블을 해당 작업의 훈련 세트에서 무작위로 선택한 레이블로 대체한다. Min et al.이 참이라면, 정확도, log-likelihood 및 엔트로피는 randomized와 standard label scenario와 동일해야 한다.
Figure 1은 LLaMa-2-70B의 log likelihood를 보여주며, Figure 3은 SST-2에서 Falcon 모델의 모든 메트릭을 보여준다.
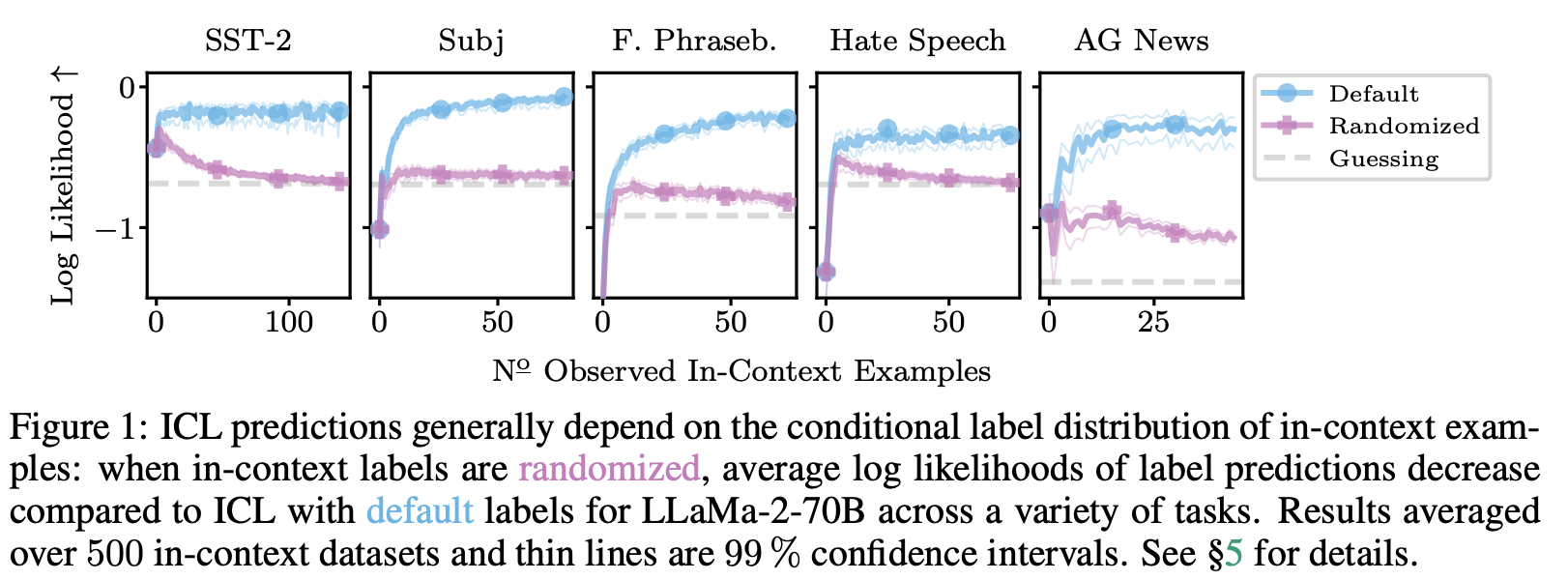
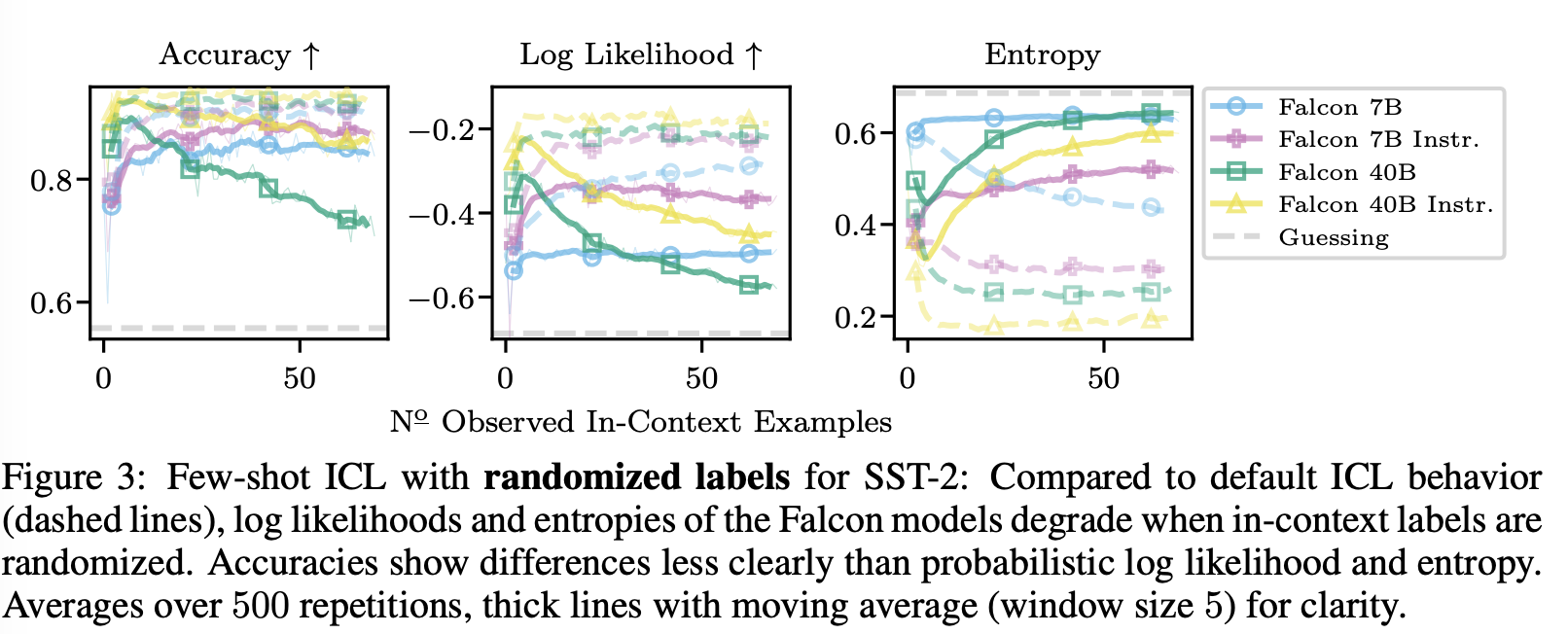
Fig. 3에서 레이블을 randomizing할 때 엔트로피가 증가하는 것을 더 자세히 볼 수 있다. 당연히, 노이즈가 있는 레이블이 관찰되면 uncertainty의 추정이 증가한다.
LLaMa(-2) 모델의 경우 정확도가 더 자주 감소한다.
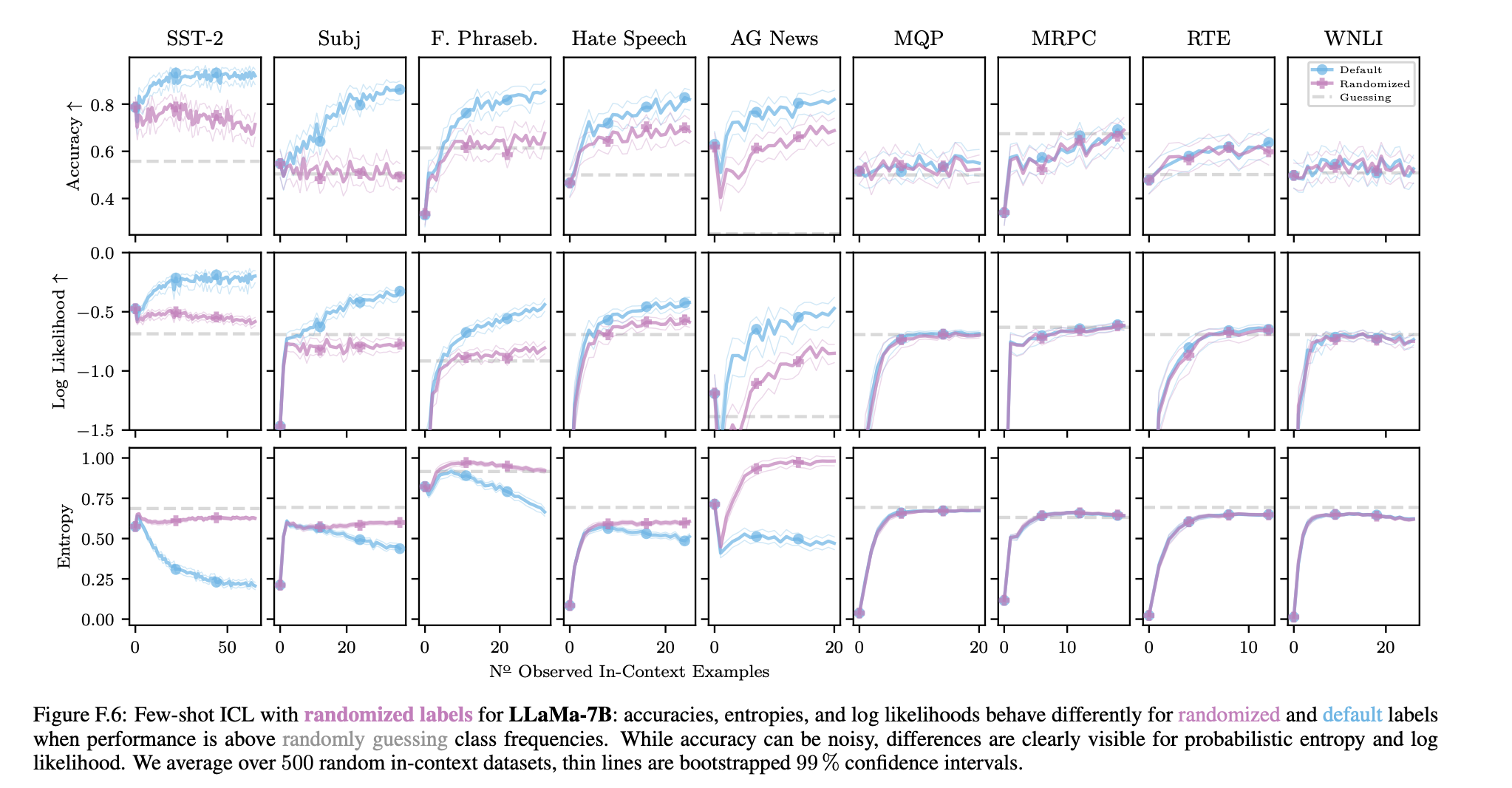
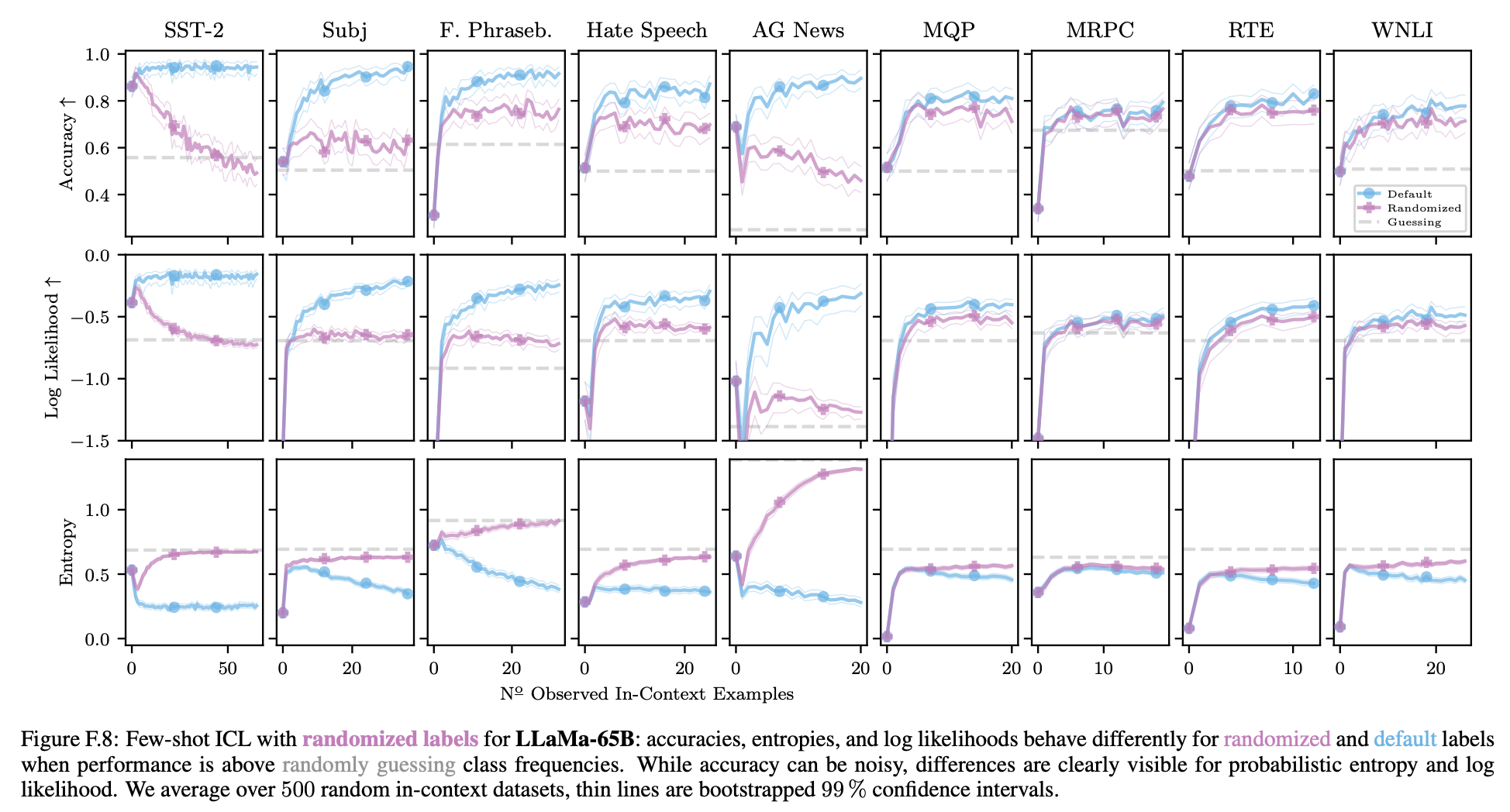

Table 1는 label randomization에 대한 전체 결과에 대한 요약본이다 (average difference in log likelihoods between the default and randomized labels at the maximum number of demonstrations for each task and model).
default label이 guessing baseline을 넘지 못한 경우를 회색으로 표기한다.
default label 성능이 무작위보다 좋을 때 (검은 색) 차이는 거의 항상 유의미하다 (bold). 이는 ICL이 randomized label에 대해 더 나쁜 성능을 보인다는 것을 나타낸다. 이러한 결과를 토대로 저자들은 NH1을 기각한다.
특히 LLaMa-2-70B는 항상 label randomization에서 더 나쁜 성능을 보여주는데, 이는 미래에 모델이 더 강력해짐에 따라 ICL에서 레이블의 중요성을 강조한다. 최종적으로 저자들은 label randomization이 ICL 예측에 부정적인 영향을 미치는 것이 규칙임을 결론 짓는다.
Discussion ab Min et al
Min et al. (2022b)의 토의: 마지막으로, Min et al. (2022b)이 label randomization only ‘barely hurts’ ICL performance라고 주장한 이유를 해석해본다.
(1) 그들은 randomization에 민감힌 probabilistic metric을 연구하지 않았다 (2) 그들은 16의 고정된 ICL 데이터셋 크기를 사용했지만, random label의 영향은 컨텍스트가 커질수록 증가한다. (3) 그들이 연구한 모델 중 하나만 20B 이상의 매개변수를 가지고 있는데(GPT-3), 저자들은 더 큰 모델이 randomization에 더 반응하는 것을 관찰함. (4) On some tasks, performance for Min et al. (2022b) could be close to random guessing, where label randomization has less of an effect.
(2) CAN ICL LEARN TRULY NOVEL LABEL RELATIONSHIPS?
여기서는 ICL이 컨텍스트에서 레이블 정보를 얼마나 추출할 수 있는지를 탐구한다. 구체적으로 LLMs가 실제로 새로운 레이블 관계를 컨텍스트에서 학습할 수 있는지를 연구한다. 이를 위해 사전 훈련 데이터에 나타나지 않을 것으로 보장된 과제를 만들어야 한다.
구체적으로, 저자들은 (Stamatatos, 2009) 논문의 두 저자 간의 개인 메시지에서 저자 확인(authorship identification) 데이터셋을 만든다. Task는 특정 메시지를 보낸 저자를 식별하는 것인데, 메시지가 private communication에서 생성됐기 때문에 이는 사전 훈련 말뭉치의 일부가 아님이 보장된다. ICL이 여기서 성공하려면 컨텍스트에서 제공된 새로운 입력-레이블 관계를 학습해야 한다.
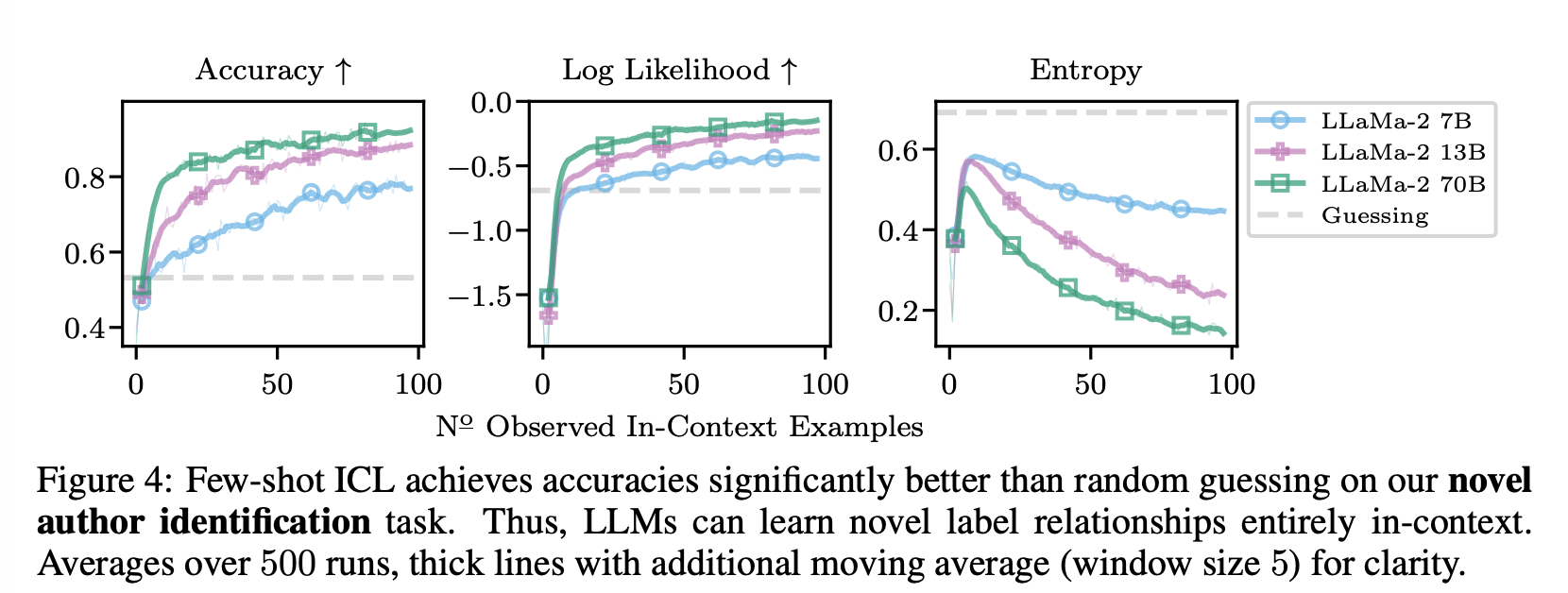
Figure 4에서는 LLaMa-2 모델의 ICL이 저자 확인 작업을 학습하는 데 성공했음을 보여준다. 정확도와 log likelihoods는 증가하며, 이는 일반적인 학습에 관한 기대와 일치한다. 큰 모델이 작은 모델보다 뛰어나지만 모든 모델이 빠르게 무작위 추측 기준선을 능가한다. 이는 LLaMa 및 Falcon 모델에 대해서도 마찬가지다.
우리는 LLMs가 컨텍스트에서 실제로 새로운 작업을 학습할 수 있으며 예제에서 레이블 관계를 올바르게 추론할 수 있다고 결론짓는다.
These results also strongly support our previous rejection of NH1 as, clearly, ICL predictions must depend on labels to learn the novel task.
(3) CAN ICL OVERCOME PRE-TRAINING PREFERENCE?
With NH2, we explore how in-context label information trades off against the LLM’s pre-training preference.Often, pre-training preference and in-context label relationships agree.
-
performance is high zero-shot and then improves with ICL.
NH2를 테스트하여 ICL이 pre-training preference를 극복할 수 있는지 확인하기 위해, pre-training preference와 컨텍스트 관측치가 일치하지 않는 시나리오를 만든다.
구체적으로는 컨텍스트 예시를 작성할 때 레이블 관계를 대체한다. (1) default label flip. 예를 들어, SST-2의 경우 (부정, 긍정)이 (긍정, 부정)으로 매핑된다. (2) arbitrary labels. 예를 들어, (부정, 긍정)이 (A, B) 또는 (B, A)로 변한다. 의도적으로 여기에서는 LLM이 이들을 긍정 또는 부정에 할당하는 데 중요한 선호도가 없어야 하므로 임의의 레이블을 선택한다.
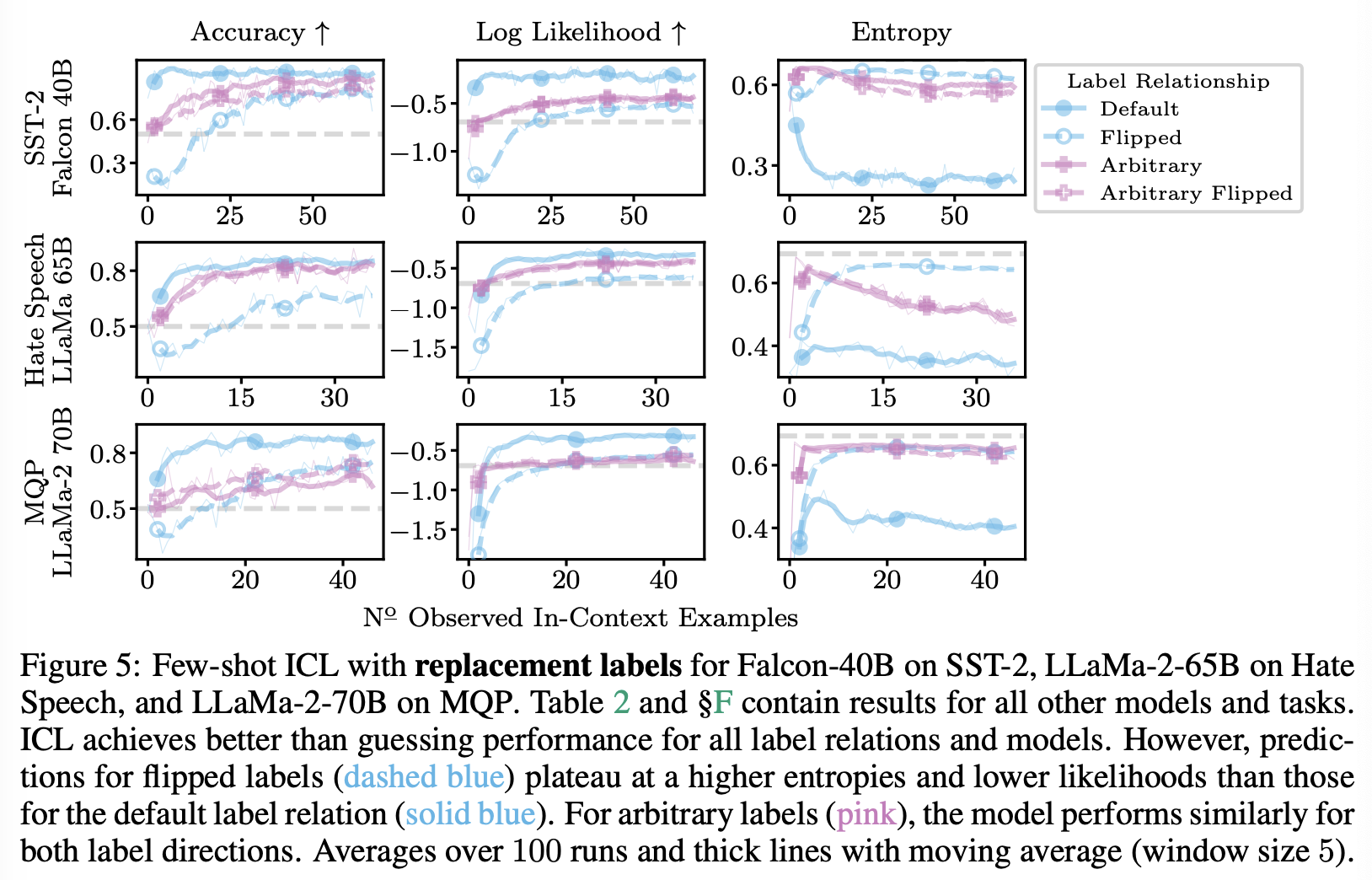
명백하게 LLM은 어느 정도까지는 pre-training preference에 반대하여 flipped label relationships를 예측할 수 있다. flipped label의 정확도는 무작위 추측보다 훨씬 높다. 그러나 특히 엔트로피의 경우 기본 및 flipped label 시나리오 간에 일관된 차이가 있다. flipped label에 대한 ICL 예측은 훨씬 나쁘며, 이러한 경향성은 아무리 예시들이 추가되어도 변화되지 않을 것으로 보인다. 사전 훈련에서 유추된 레이블 관계가 컨텍스트 관측을 통해 극복될 수 없는 영구적인 영향을 미치는 것으로 보이며 이는 전통적인 학습과 일치하지 않는다.
Figure 5는 대체 레이블 (A, B) 및 (B, A)에 대해 양 방향이 ICL에게 유사하게 쉽게 학습되는 것도 보여준다. 이는 LLM이 사전 훈련 중에 그들에 대한 선호도를 실제로 학습하지 않았다는 우리의 직관과 일치힌다. 또한 임의의 대체 레이블을 학습하는 속도는 일치하는 기본 레이블에서 학습하는 것보다 느리지만 flipped label에서 학습하는 것보다 빠르다.
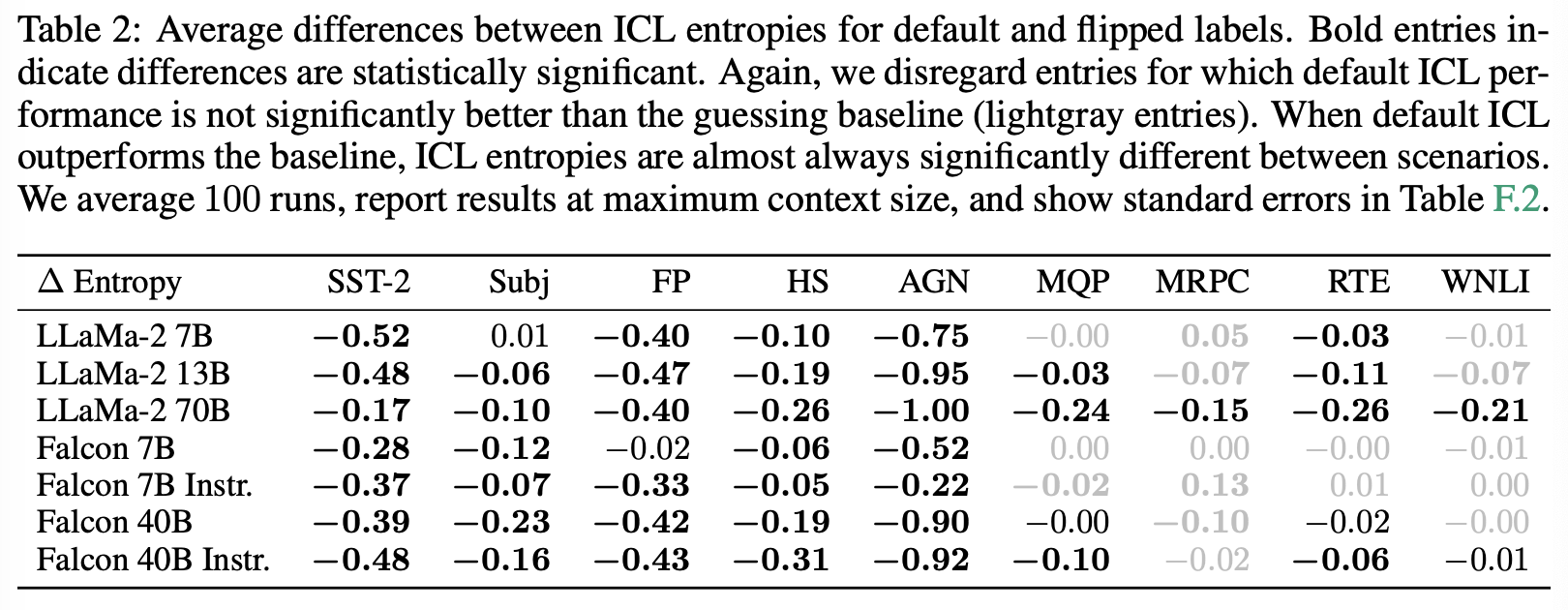
Table 2는 최대 컨텍스트 크기에서 기본 및 flipped label 시나리오 간 엔트로피 차이를 보여준다. 이때, 기본 및 flipped labe에 대한 예측 간의 중요한 차이가 최대 입력 크기에서도 지속된다.
For the models we study, we reject NH2 that ICL can overcome prediction preferences from pre-training.
Again, the results here strongly support our previous rejection of NH1, as clearly, predictions change for replacement labels.
(4) CAN PROMPTS HELP ICL LEARN FLIPPED LABEL RELATIONSHIPS?
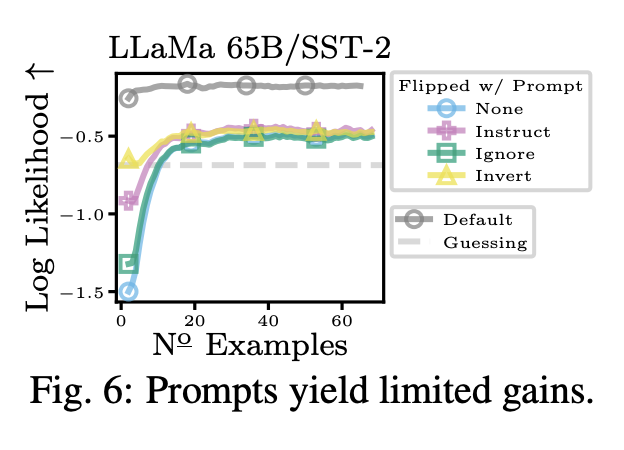
저자들은 구체적인 프롬프트, 즉 LLMs에게 뒤집힌 레이블에 대한 지시를 제공하는 경우 ICL 예측을 개선할 수 있는지 더 조사한다. 최종적으로, 몇 가지 프롬프트는 초기에 모델이 뒤집힌 레이블에 대한 예측에 도움이 될 수 있지만 결국에는 프롬프트가 예측을 향상시키지 못한다.
더 자세하게, 저자들은 기본 레이블이 flip된 경우 ,ICL 성능을 올리는데 프롬프트가 사용될 수 있는지 탐색한다. 즉, in-context examples를 주기 전에, prompt에 어떤 방식으로든 label이 뒤집혔다는 사실을 전달하면 도움이 될지도 모른다.
저자들은 세 가지 promPt를 사용한다.
-
(Instruct Prompt) ‘…negative means positive and positive means negative’
-
(Ignore Prompt) ‘…ignore all prior knowledge’,
-
(Invert Prompt) ‘…flip the meaning for all answers’.
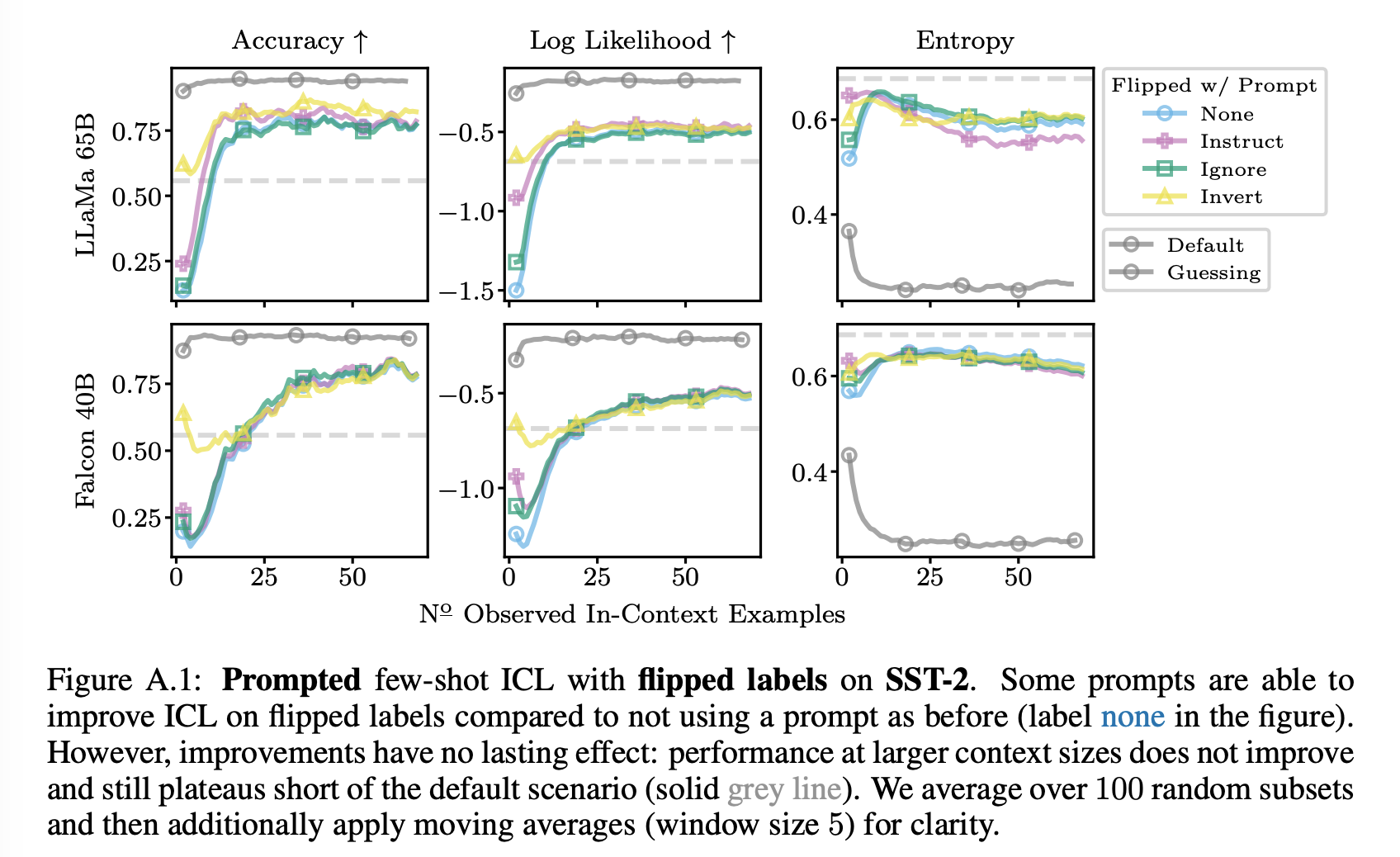
Figure A.1은 LLaMa-65B 및 Falcon-40B의 SST-2에 대한 few-shot ICL에 대한 결과를 제공한다. Appendix의 Figures F.38에서 F.46까지는 사용한 모델들 중 가장 큰 모델에 대한 결과를 제공하는데, 예상외로, prompting은 Fig. A.1의 시나리오에 대해 가장 성공적이며, prompting은 LLaMa-2-70B에 대해 가장 약한 효과를 보입니다.
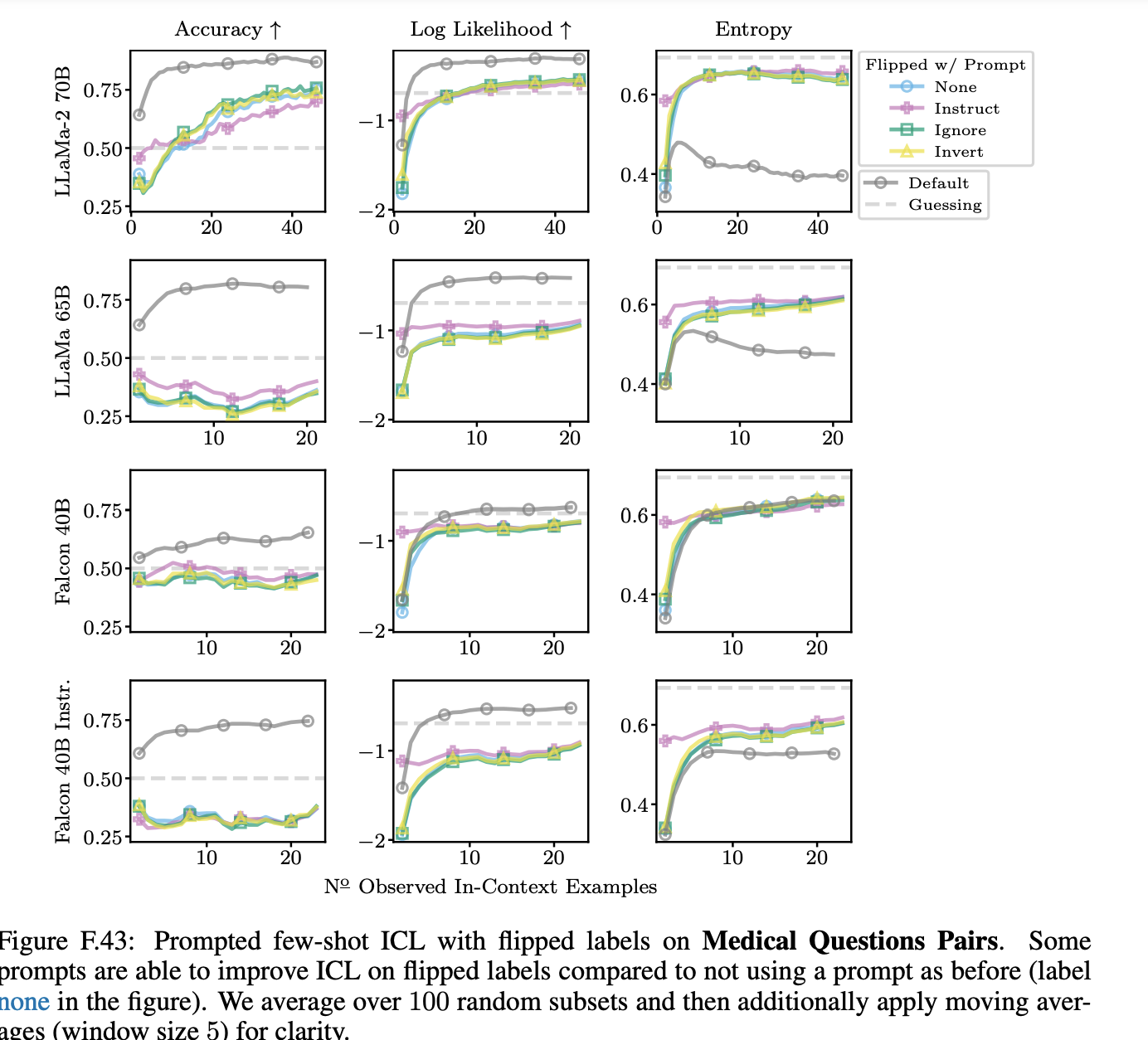
특히, Fig. A.1에서 instruct and invert prompt가 ICL 성능을 향상시키는 데 도움이 될 수 있음을 관찰할 수 있다. 그러나 프롬프트에서의 긍정적인 영향은 작은 컨텍스트 데이터 크기에서의 initial boost로 제한되는 것으로 보인다. 때로는 프롬프트를 forgetting한 것으로 보일 수 있는 성능 하락이 관찰되기도 한다. 큰 컨텍스트 크기에서는 프롬프트 중 어떤 것도 이점이 없으며, 다시 한번 기본 레이블 설정에 대한 성능에 도달하지 못하는 것을 확인할 수 있다.
따라서 결과적으로 저자는 연구한 프롬프트를 이용해도 pretrain preference를 극복할 수 없음을 보인다.
(5) HOW DOES ICL AGGREGATE IN-CONTEXT INFORMATION?
우리는 방금 ICL이 pre-training preference와 in-context 레이블 정보를 동등하게 처리하지 않음을 확인햇다. 그러나 여전히 ICL이 in-context 내의 다른 소스를 어떻게 처리하는지 알아보는 것은 중요하다.
이를 위해서 저자들은 in-context 학습 중 레이블 관계를 세 가지 다른 시나리오에서 변경힌다.
-
(D → F): 기본 레이블 관계의 N 번 관측 후에 이후 모든 관측에서 레이블 관계를 뒤집습니다. 예를 들어 SST-2의 경우 (negative, positive)에서 (positive, negative)로 변경
-
(F → D): 이제 N 개의 뒤집힌 레이블 관측을 시작하고 모델에 기본 레이블을 노출
-
(Alternate F ↔ D): 각 관측 후에 기본 및 뒤집힌 레이블 간을 번갈아가며 전환.
NH3가 참이면 ICL은 모든 관측된 레이블 관계를 동일하게 처리해야 한다.
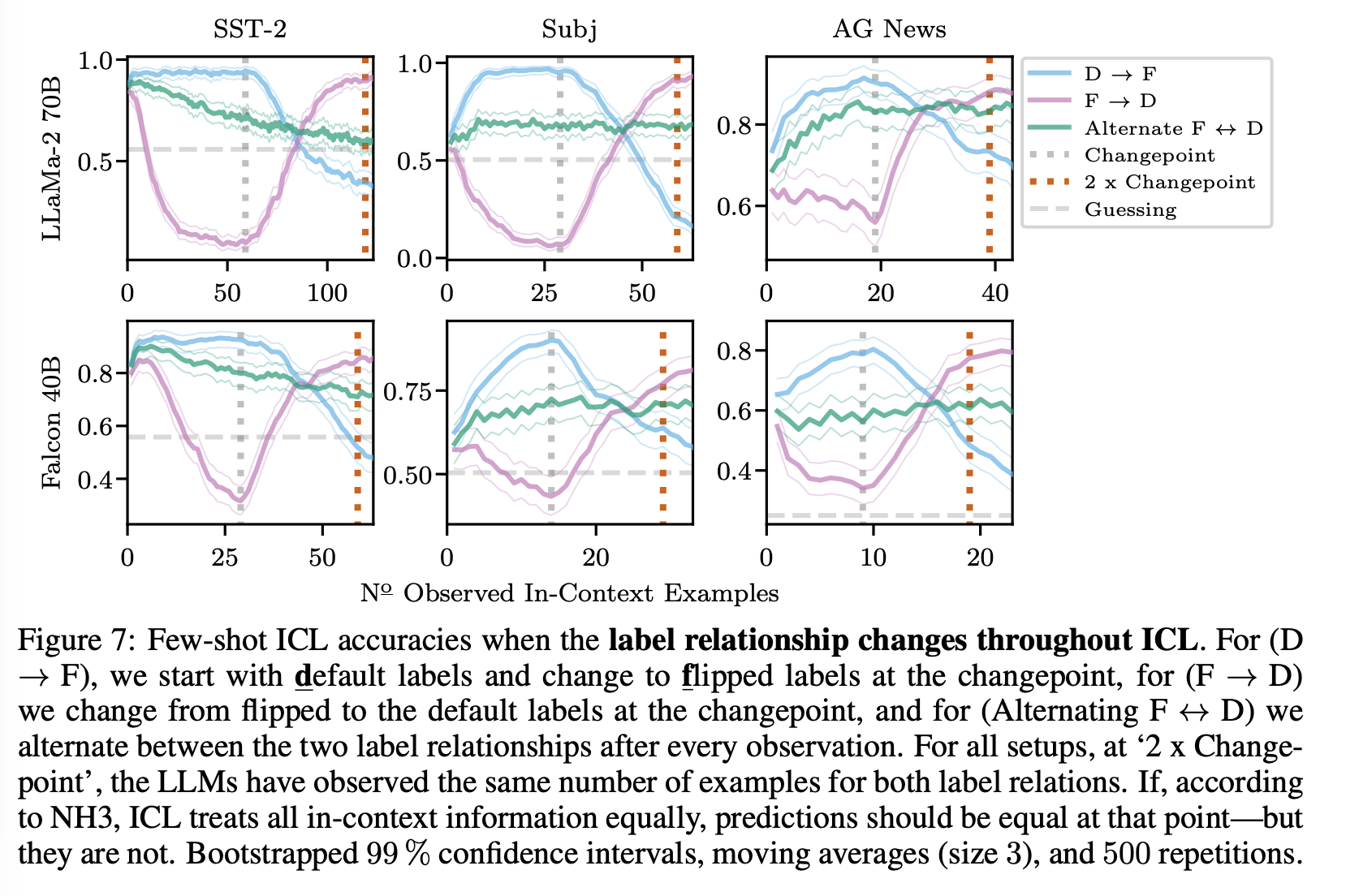
세 가지 설정 간의 예측이 동일한 수의 레이블 관계 예제를 관측한 후에도(총 2N 관측 후, 그림의 빨간 점선) 유의미하게 다르다는 것을 확인할 수 있다.따라서 저자들은 ICL이 in-context에서 제공된 모든 정보를 동등하게 처리한다는 NH3를 기각한다.
changepoint N 이후, 예측은 즉시 새로운 레이블 관계에 맞게 조정되기 시작하는데, 특히 2N 관측 후에 (F → D) 설정은 기본 레이블 관계에 따라 예측하는 편향이 있으며 (D → F) 설정은 뒤집힌 레이블 관계에 따라 예측하는 편향이 있다.
다시 말하면, LLMs는 쿼리에 더 가까운 정보를 사용하는 것을 선호하며 모든 사용 가능한 정보를 동등하게 고려하지는 않는다.
얻어갈 것
-
선행연구에 대한 완벽한 반박 및 이에 대한 설명
-
flip했을 때, prompt를 추가하면 쉽게 변화할 것이라 생각 -> 아니라는 것 확인
-
큰 scale과 많은 example로 많은 task 실험 -> 일반화 가능해보임
-
가장 가까운 example들이 중요!