KALA: Knowledge-Augmented Language Model Adaptation
논문 정보
- Date: 2023-01-19
- Reviewer: yukyung lee
- Property: QA, NER, Knowledge
0. Abstract
-
Simple fine-tuning of PLMs, on the other hand, might be suboptimal for domain-specific tasks because they cannot possibly cover knowledge from all domains
-
Adaptive pre-training of PLM can help LM obtain domain-specific knowledge
→ require large training cost → catastrophic forgeting of general knowledge -
KALA
→ entities and relational facts
1. Introduction
1) 논문이 다루는 task
- Adaptation the PLMs to specific domains (distributions over the language characterizing a given topic or genre)
2) 해당 task에서 기존 연구 한계점
-
Computationally inefficient: 데이터 양이 증가함에 따라 더 많은 메모리와 computational cost가 필요함
-
forgetting general knowledge: performance degradation
3) 제안 방법론 요약
-
entities and relations는 domain specific knowledge를 위해 중요한 요소
-
Entity memory bank와 Knowledge Graph를 활용하며, 이때 KG는 factual relationshop을 사용하기 위함
-
Knowledge conditioned Feature Modulation (KFM)를 제안하며, 이는 PLM과 retrieved knowledge representation을 적절하게 결합하기 위함
-
KFM은 어떤 모델에도 적용 가능하며, original PLM을 변경시키지 않고 적용할 수 있음
-
marginal computational와 memory overhead만 필요함
-
KG의 relation 정보를 활용하여 training 과정에서 등장하지 않았던 unseen entities를 고려할 수 있음
-
Test에서 처음 나오는 entity라 하더라도 known entity들을 aggregating 함으로서 explicitly represent 가능함
-
neighboring entities들을 활용하는 방식을 취함
-
-
-
Contributions
-
further pre-training 없이 finetuning 동안 효과적으로 entity와 relations를 PLM에 augment하는 방법론
-
Structural knowledge → PLM을 위해, KG기반의 entity와 relation을 represent하는 novel layer 제안
-
NER, QA에서 significantly more efficient함
-
2. Related Work
1) Language Model Adaptation
domain-specific corpus adaptation
-
BioBERT
-
Dont stop pretraining - DAPT, TAPT
: large amount of computational cost for pre-training
2) Knowledge-aware LM
Integrate external knowledge into PLMs
Pretraining based
-
ERNIE
-
KnowBERT
-
Entity-as-Experts
-
LUKE
-
ERICA
3. Proposed Method
3.1 Problem Statement
- Learning objective (Only require general knowledge)
-
sub optimal for tackling domain-specific tasks (general knowledge는 domain-specific task를 풀이하기 위해 필요한 지식들을 모두 포함하지 않으므로)
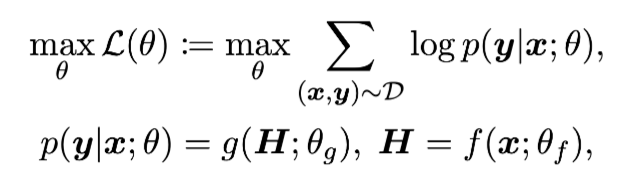
Learning objective (Augments PLM conditioned on domain knowledge)
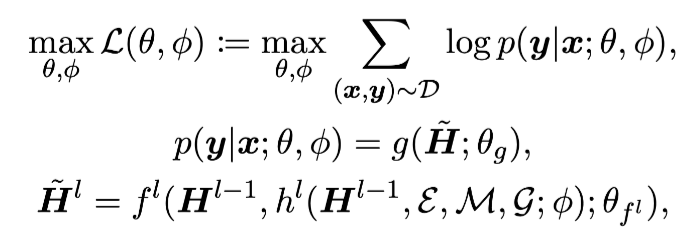
-
Definition 1: Entity and Mention
-
entity는 sequence of tokens에 등장하는 one or multiple adjacent token임
-
x = [New, York, is, a, city]
-
\mathcal{E} = {New_York, city}
-
\mathcal{M} = {(1,2),(4,4)}
-
-
학습과정에서 등장하는 모든 entity를 entity 집합으로 구성하고, test time에서 처음 등장하는 entity(unknown entities)를 다루기 위해 집함에 null entity e_{\emptyset}을 포함시킴
-
-
Definition 2: Entity Memory
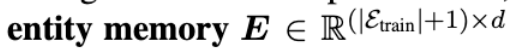
-
별도의 entity embedding function을 통해 entity representation을 학습
-
null entity e_{\emptyset}는 zero vector를 사용했음
-
Definition 3: Knowledge Graph
-
KG를 직접 construct함
-
KG는 set of factual triplet으로 구성됨 {(h,r,t)}
-
h: head entity, r:relation, tail entity
-
3.2 Knowledge-conditioned Feature Modulation on Transformer
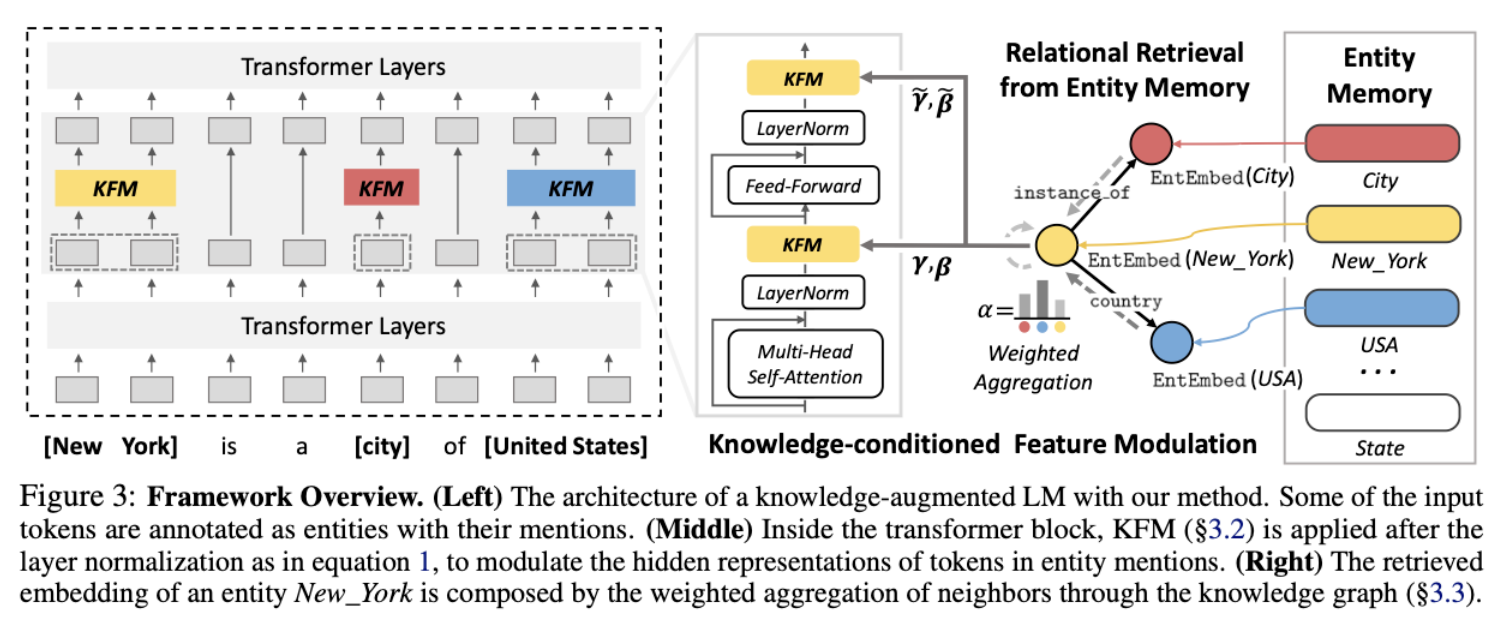
-
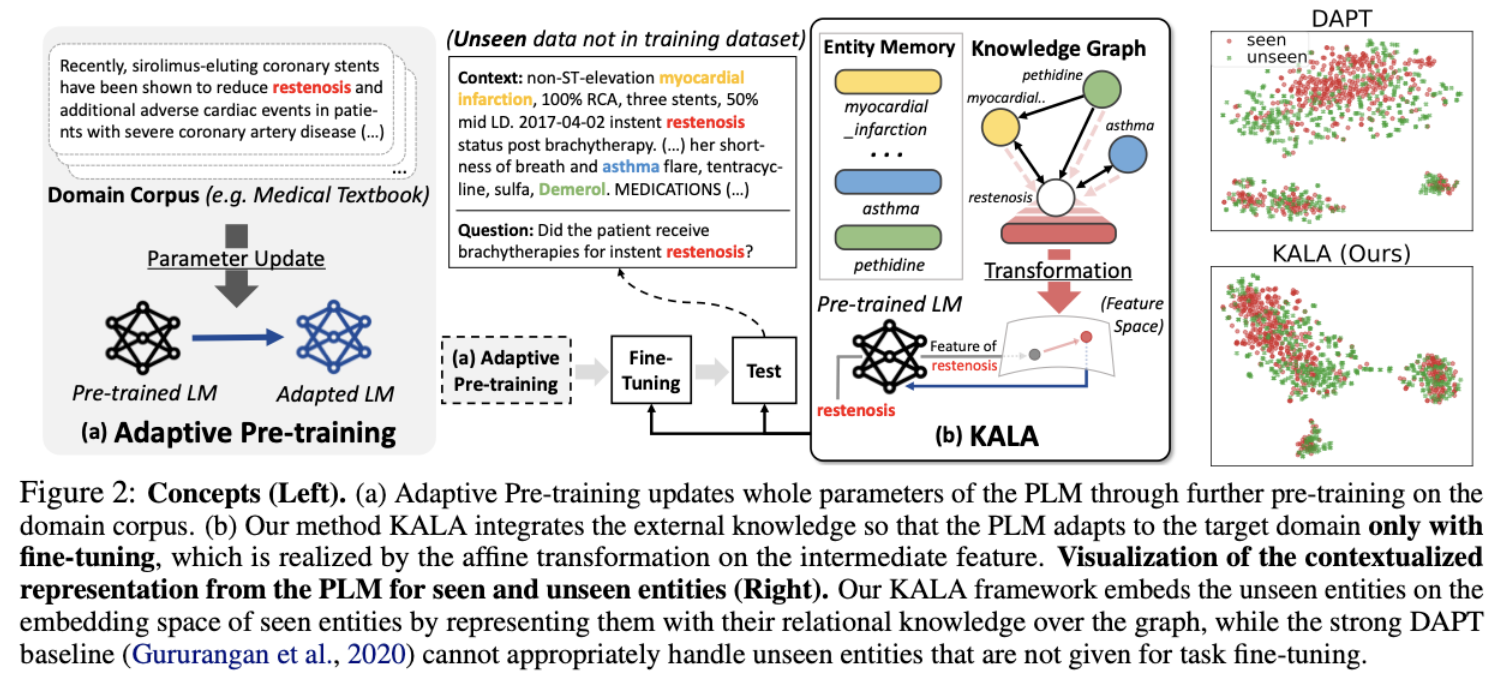
PLM에 domain-specific knowledge를 augment하는 방법 설명하는 파트
-
iterleave the knowledge from h with the pre-trainied parameters
- Original transformer
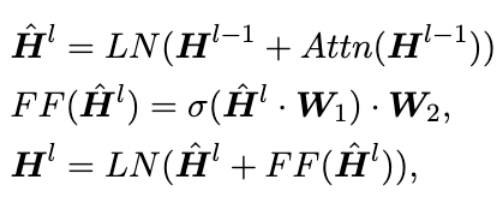
-
KFM Method
-
feature-wise affine transformation기반의 연산임
-
Layer normalization 전에 knowledge를 나타내는 entity, mention, graph를 input으로 넣어 augment하는 과정이 진행됨
-
해당 연산을 통해 learnable parameter를 얻음
-
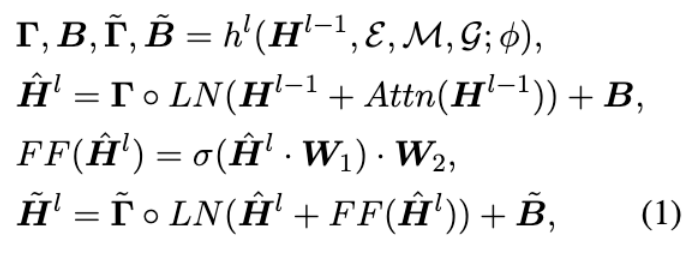
- h는 entity memory에서 input entity와 유사한 entity embedding을 retrieve함
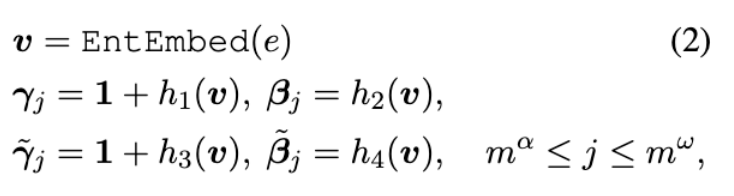
3.3 Relational Retrieval from Entity Memory
-
entity만 retrieve 하게 될 경우 한계점을 가짐
-
fail to reflect the relations with other entities
-
regards unseen entities as the same null entity
-
-
two entities 사이의 relational information도 고려해주기 위해 Relational Retrieval도 함께 수행함
-
예를들어, New_York token을 단독으로 사용하면 meaningful information을 얻기 힘듦
-
아래의 associated fact를 사용하면 보다 의미있음
-
(New_York, instance of, city) and (New_York, country, USA)
-
-
- GNN을 통해 3.1에서 정의한 entity memory의 entity embedding을 보강해줌
- 이때 neighborhood aggregation scheme을 사용함

-
aggregation이 너무 단순하면 relative importance를 반영할 수 없음
-
attentive scheme을 사용하여 target entity에 각 entity의 importance를 weight로 할당해줌
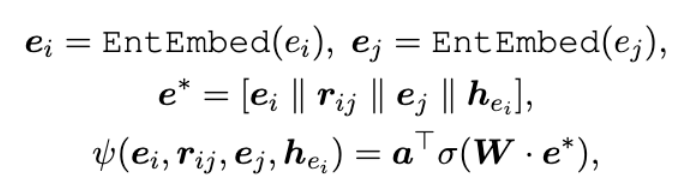
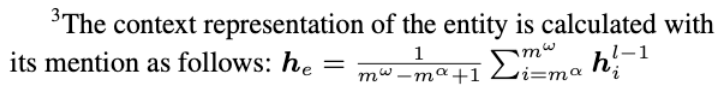
- score는 all neighbors를 모두 고려하여 normalize되고 softmax를 취해서 사용함
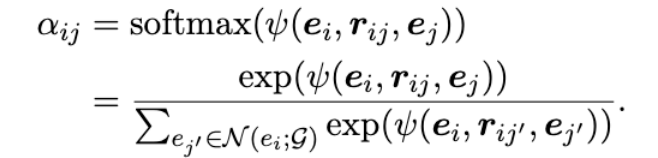
- entity embedding과 score를 결합하여 사용하는 형태임
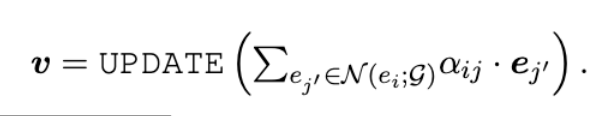
-
최종 Entitiy embedding은 바로 위의 GNN 기반의 수식으로 대체되며, entity, relation, kg까지 모두 고려한 embedding을 생성할 수 있게 됨
-
unseen entity또한 위의 과정을 통해 단순한 zero vector로 표현되지 않기 때문에 훨씬 더 효과적으로 처리할 수 있게됨
4. 실험 및 결과
Dataset
Domain-specific NER, QA Datasets
Baseline
Finetuning, TAPT, DAPT, Other knowledge models
-
Point-wise option : entity memory만을 사용해서 retrieval 하고 knowledge graph를 사용하지 않은 옵션
-
relational: entity memory에서 relational retrieval을 수행함
실험 결과
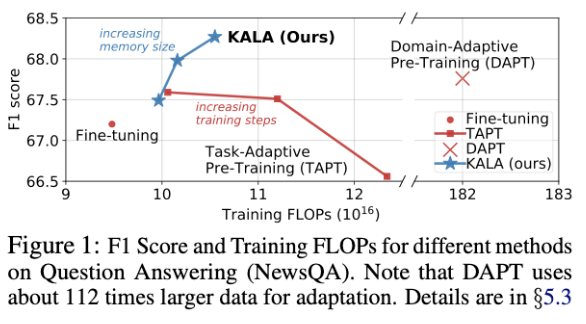
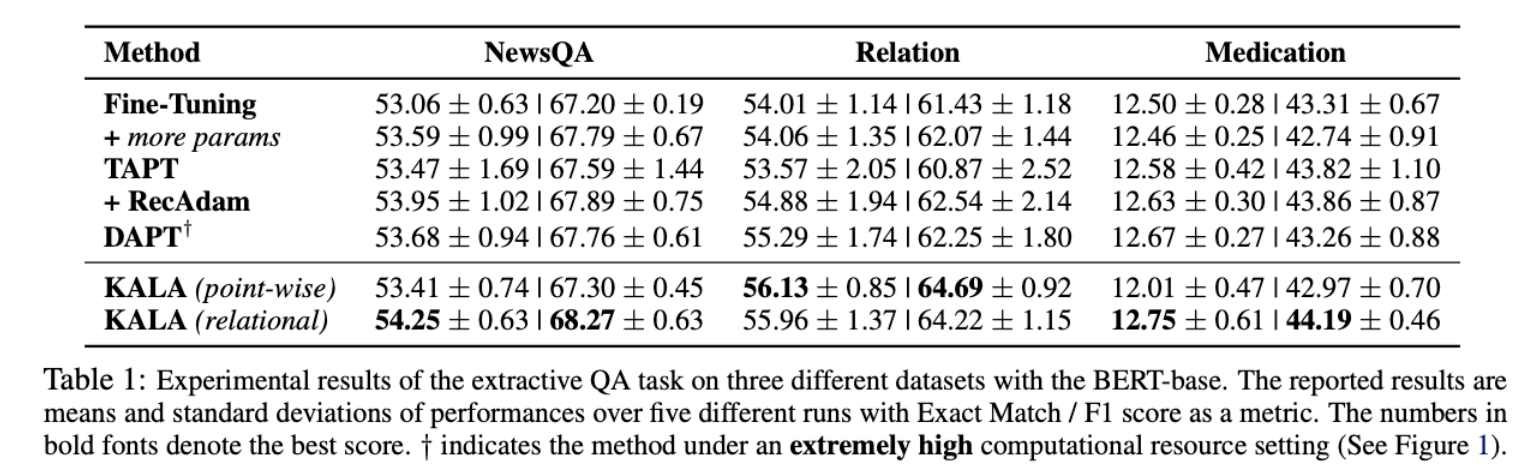
실험 1 : QA에서 KALA의 효과
-
Finetuning 보다 약 1.2점 상능효과 있음
-
DAPT로 유사 domain 다 사용하는 방법보다 target dataset의 entity를 weak supervision으로 사용하는것이 유용함
-
relational (GNN 사용한 부분)은 특정 데이터셋에서 성능향상을 보임
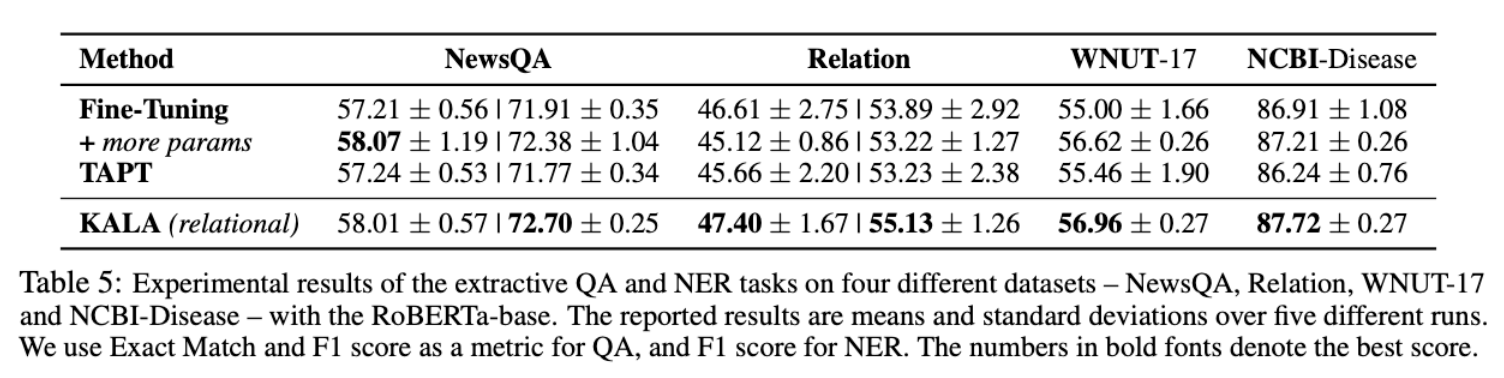
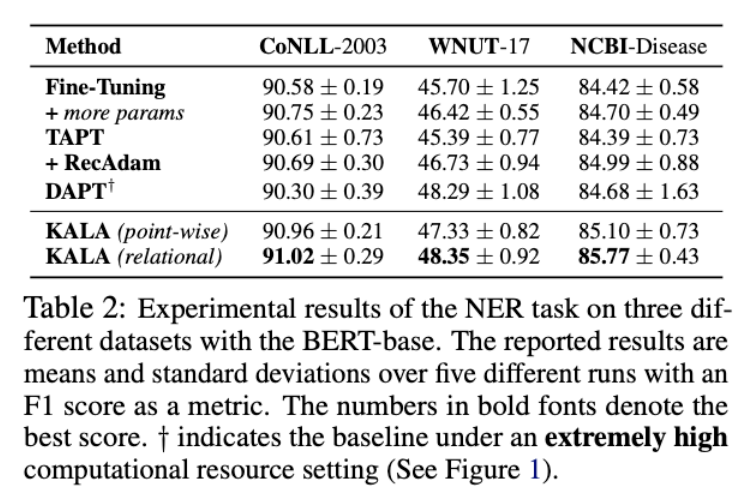
실험 2: NER에서 KALA의 효과
-
finetuning 보다 약 1~2점 효과가 있음
-
효과는 실험 1과 유사함
실험 3: gamma, beta에 대한 추가 실험
-
KFM layer에 대한 성능 차이
-
layer norm 횟수도 함께 실험했음
-
두가지를 모두 사용하는것이 가장 효과적이었음
→ knowledge integration을 적절하게 해준것으로 해석할 수 있음
실험 4: knowledge integration architecture과의 비교
-
knowledge integration 모델들과의 비교
-
Adapter의 성능이 돋보였음
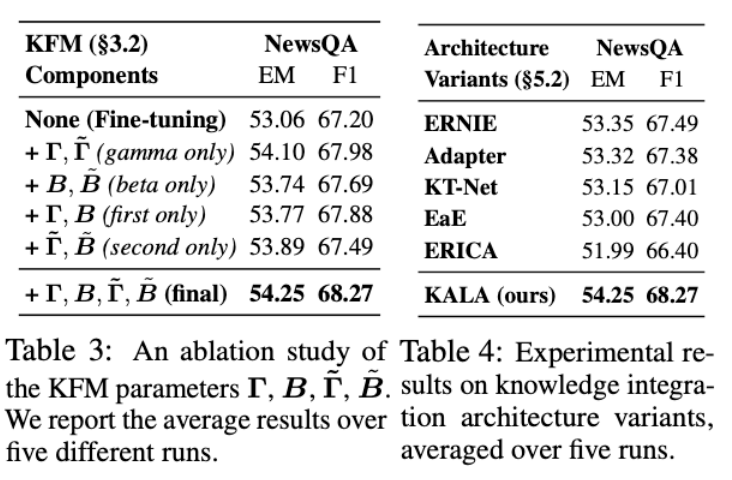
실험 5: seen/ unseen 데이터에 대한 성능 비교
-
KALA의 unseen entity가 test set에 등장해도 성능이 크게 저하되지 않음
-
저자들은 KALA가 unseen entity를 seen entity와 가깝게 embed함으로서 성능을 유지할 수 있다고 주장함
-
여기서 놀라운것은 WNUT에서의 DAPT 성능
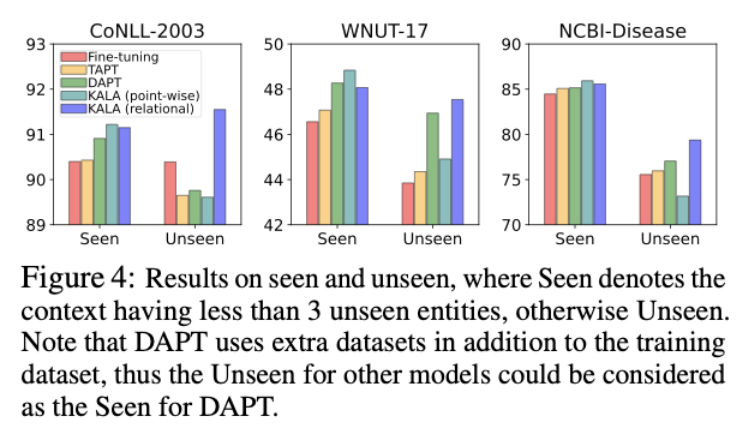
실험 6: token에 대한 case study
-
“##on”이라는 token이 각 entity별로 다른 위치에 임베딩 되는것을 볼 수 있음
-
corresponding entity에 가깝게 위치하는 모습을 보임
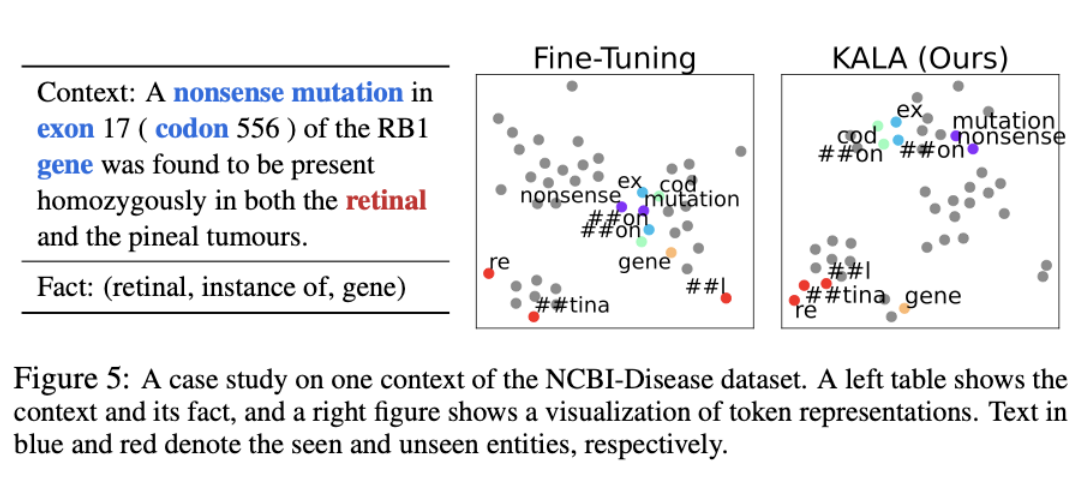
실험 7 : T5에서도 되네 ? Generative model 실험
-
Generative model에서의 성능이 놀라웠음
-
knowledge integration idea가 성능 향상에 효과적임을 알 수 있음
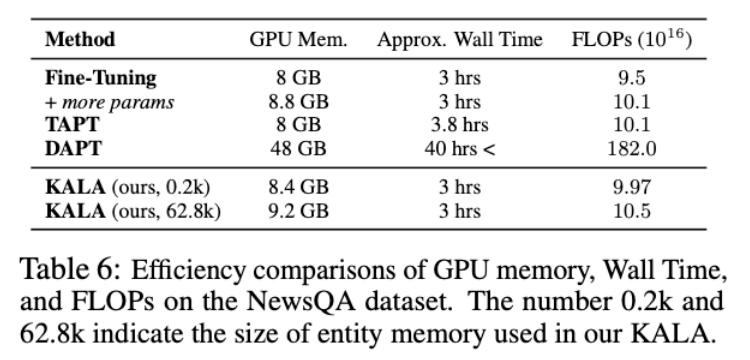
실험 8: KALA의 efficiency
-
TAPT는 생각보다 효율적
-
하지만 성능을 생각해보면 항상 좋은것은 아님
-
DAPT는 대부분의 case에서 뛰어남
-
KALA는 효율성 측면에서 뛰어나고 성능도 좋은 방법
결론 (배운점)
-
LM adaptation을 위한 novel framework 제안
-
entity memory를 통해 input text에서 domain specific knowledge를 추출하고, KG와 GNN을 통해 단일 entity 뿐만 아니라 entity 사이의 relation도 함께 고려함
-
엄청난 양의 case 스터디와 실험들을 보여주며 (Appendix에도 실험이 많음) 적어도 아이디어를 검증하려면 이정도 실험은 해야한다는 것을 보여줌
-
리뷰어가 궁금해할 실험을 모두 제시하면서 negative 질문 원천 차단
-
idea는 직관적이지만 방법론은 체계적이며, 수식전개나 논문 서술등 참고해볼게 많았던 논문임
-
하지만 entity논문들은 대부분 tricky할 수 밖에 없다는 아쉬움이 있음
논문에서 기억하면 좋을 것들
(향후 논문 작성시 reference에 도움이 될 소스들)

이런 논문을 읽는 이유
-
Real world data는 대부분 specific하며 general knowledge로는 성능 향상에 한계가 있음 (여기서의 specific은 특정 domain data라고 정의하기보다 vocab과 text style이 general LM과 차이가 발생한다는 의미임)
-
LLM으로도 문제를 해결할 수 있겠지만 짧은 시간 효과적인 학습을 통해 충분히 좋은 성능을 보일 수 있는 연구 분야도 존재함
-
entity information은 언제나 Knowledge intensive task의 좋은 source중 하나이며 (재희 반박 거절) generation model과의 궁합도 좋음