Label Words are Anchors: An Information Flow Perspective for Understanding In-Context Learning
논문 정보
- Date: 2023-12-12
- Reviewer: 김재희
- Property: ICL, In Context Learning, LLM
1. Intro
-
ICL 수행 시 각 demonstartion의 정보는 label words의 representation에 집중됨을 확인
-
발견된 현상을 이용하여 ICL의 성능을 개선하는 방법론 제시
-
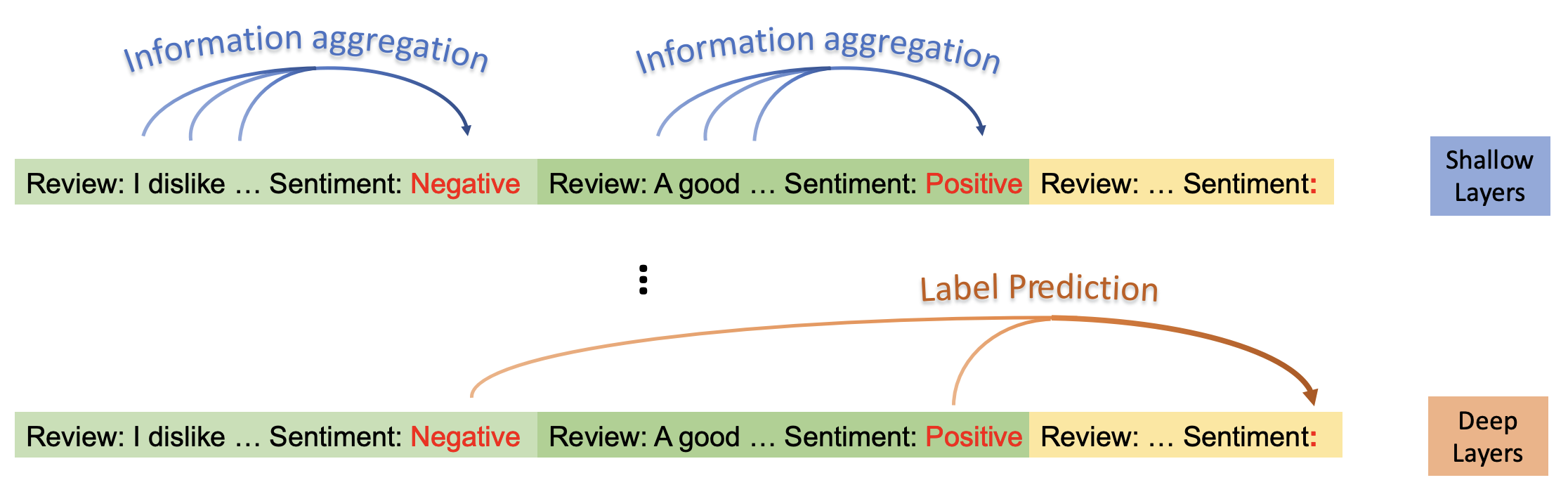
얕은 레이어와 깊은 레이어에서 attention의 흐름(information flow)가 다르게 관측
-
얕은 레이어에선 label word에 정보가 집중됨
-
깊은 레이어에선 label word에서 정보를 꺼내와 예측에 적극적으로 활용
-
⇒ 이러한 현상을 활용하여 ICL 예측 성능 개선

-
얕은 레이어와 깊은 레이어의 역할
-
얕은 레이어 : 각 Demonstration의 정보를 label word가 취합
-
깊은 레이어 : 실제 label word 예측 시 demonstration의 label word에 취합된 정보를 적극적으로 이용하여 예측 수행
-
2. Analysis
2.1. 가설 검증
-
본 논문이 관찰한 두가지 현상(deep/shallow layer)에 대한 직접적 검증 시도
-
Saliency Score를 이용하여 예측에 각 단어의 영향력을 측정
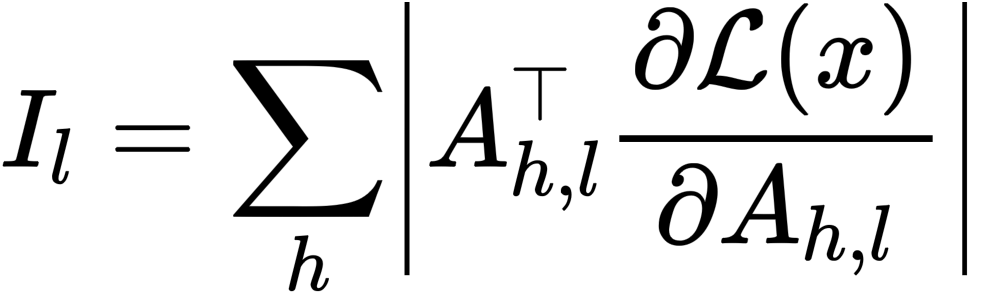
⇒ Attention Map 상에서 각 토큰 간의 attention이 loss에 미친 영향력을 수치화
-
ICL 환경에서 입력을 세가지로 구분
-
w : Demonstration 상 Input Text(or 이전 입력 전체)
-
p : Demonstration 상 Label Words
-
q : 예측할 Input의 예측할 text(or “:”)
-
-
위 3가지 입력에 따라 Saliency Score를 계산하게 됨
-
Input Text(w) → Label Words(p)
- Label Words를 예측하는데 이전 토큰이 미친 영향력, attention 정도
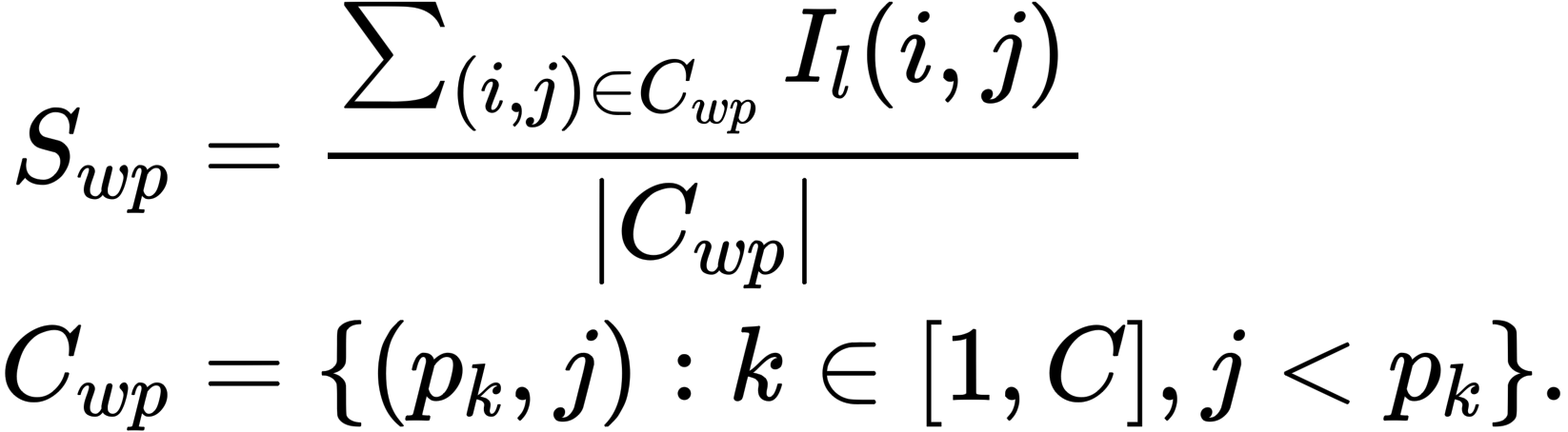
-
Label Words(p) → Prediction(q)
- Demonstration 내 각 label words이 실제 예측 label에 미친 영향력, attention 정도
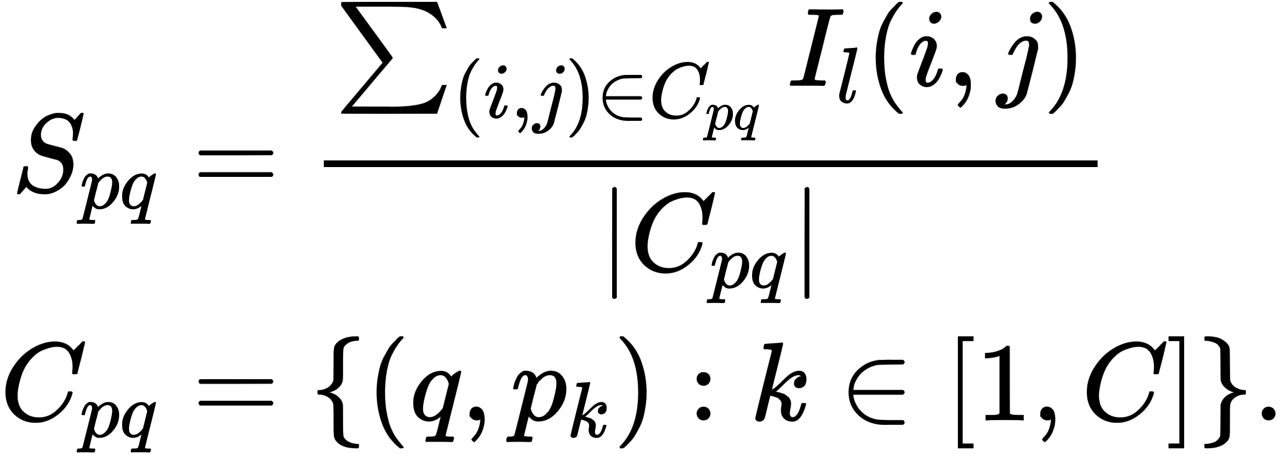
-
Input Text(w) → Input Text(w)
- Label Words와 Label 예측을 제외한 나머지 Input Token 간의 영향력
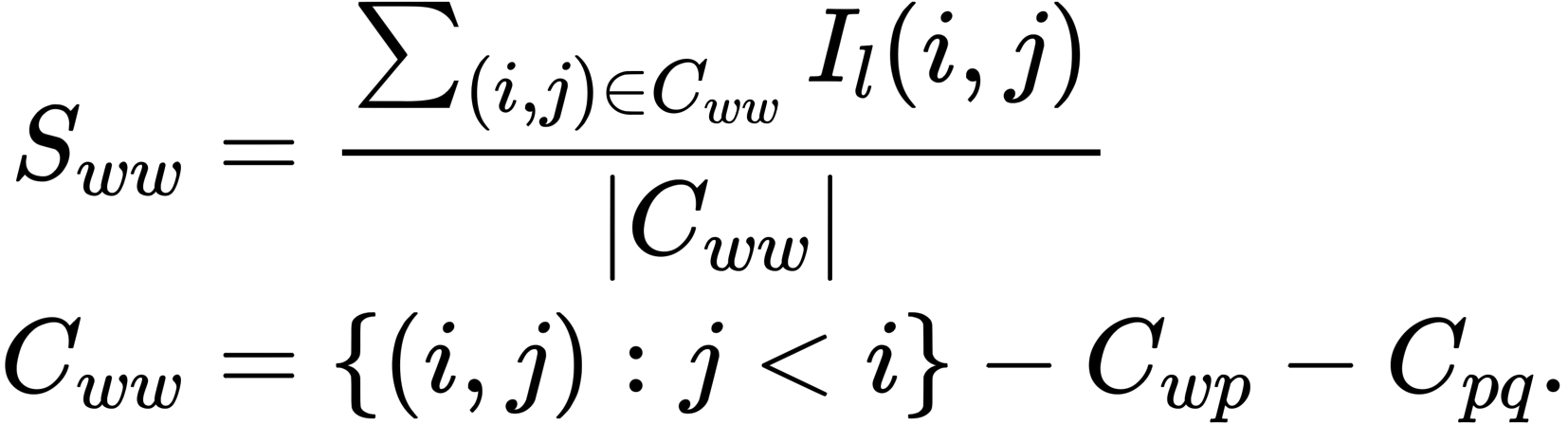
2.2 실험 환경
-
4개의 Text Classification Task 사용
-
평가 데이터 : 1,000개
-
Demonstration : Class 당 1개 사용
-
SST-2, TREC, AGNews, EmoC,
-
-
Model :
-
GPT2-XL(1.5B) : 저자들의 언급으로는 ICL이 충분히 가능하면서 실험 가능한 사이즈
-
GPT-J(6B) : 쫄렸는지 갑자기 큰 모델도 해버림
-
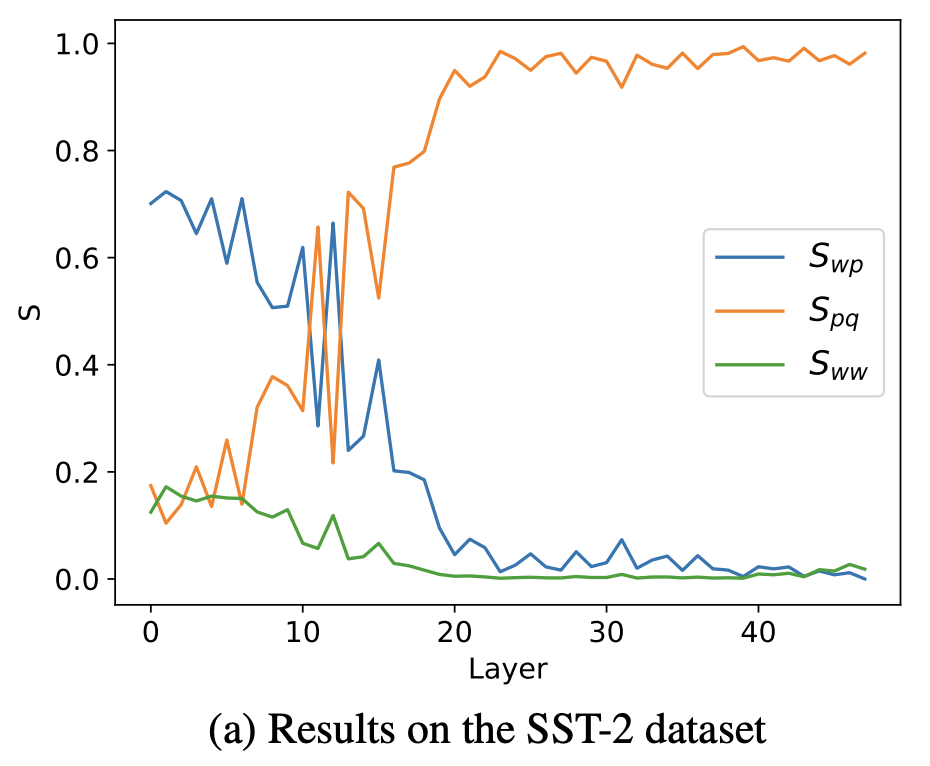
2.3 Information Flow 실험
- Layer 깊이에 따른 Information Flow
-
실험 결과 intro의 findings를 정량적으로 확인 가능
-
초기 레이어 :
-
많은 정보(attn)이 label word로 집중되고 있음
-
예측 할 토큰으로 흐르는 정보가 많지 않은 모습
-
⇒ 초기 레이어는 각 Label Word로 정보를 모음
-
후기 레이어 :
-
대부분의 정보가 예측할 단어(”:”)로 흘러가고 있음(from label words)
-
다른 토큰으로 정보가 거의 취합되지 않는 모습
-
중반 이후 레이어에서 매우 꾸준한 경향
-
⇒ 후기 레이어는 각 label word로부터 실제 예측에 사용될 정보를 취합하는데 집중
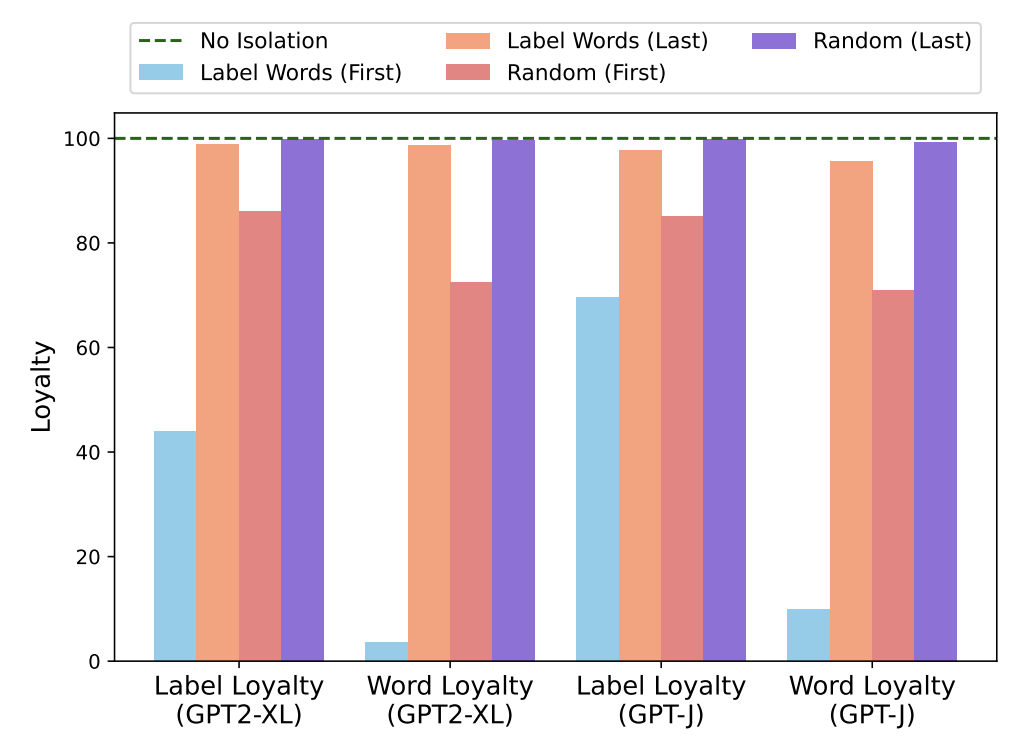
2.4 Loyalty 실험
-
Isolation(Label Words) : Attention Map을 임의로 조정하여 Input Text → Label Word의 Attention을 막는 환경
-
First/Last : 초기/후기 5개 레이어에 대해 Isolation을 수행
-
Random : Attention Map 내 임의의 attention을 조정
-
Loyalty : 2가지 측면에서 Isolation에 따른 영향력 평가
→ Isolation에 따른 예측값 변화량 측정
-
Label Loyalty : Isolation에 따른 Label 예측 변화량
-
Word Loyalty : Isolation에 따라 예측된 top-5 token과 original 예측의 Jaccard 유사도
-
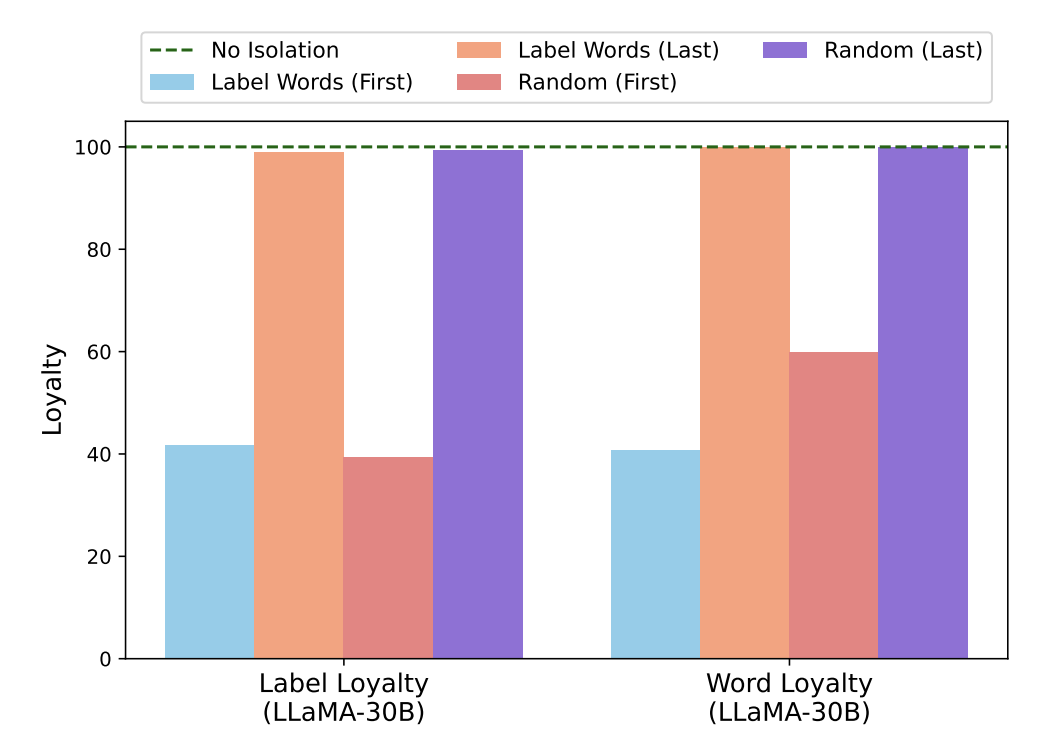
Label Word와 레이어 단위 별 영향력 평가
-
청록색 : 초기 레이어에서 Label Words에 대한 Isolation 수행 시 매우 큰 성능 저하 발생
-
주황색 : 후기 레이어에서 Label Words에 대한 Isolation 수행 시 성능 저하 거의 발생 X
-
→ Label Words에 대한 영향력은 초기 레이어에서 매우 큼
- 빨간색/보라색 : 초기/후기 레이어에서 Random한 Isolation 수행 시 성능 저하 거의 발생 X
→ 임의의 단어가 영향력을 가지지 않음
⇒ Label Words의 정보가 초기에 수집되는 것이 ICL 성능에 큰 영향
⇒ Label Words를 임의로 변경(A/B)로 하여도 비슷한 결과 관찰 가능
(GPT-J, GPT-2의 경우 Label Words를 바꾸면 Random Guessing에 가까워져서 LLaMA-30B로 변경)
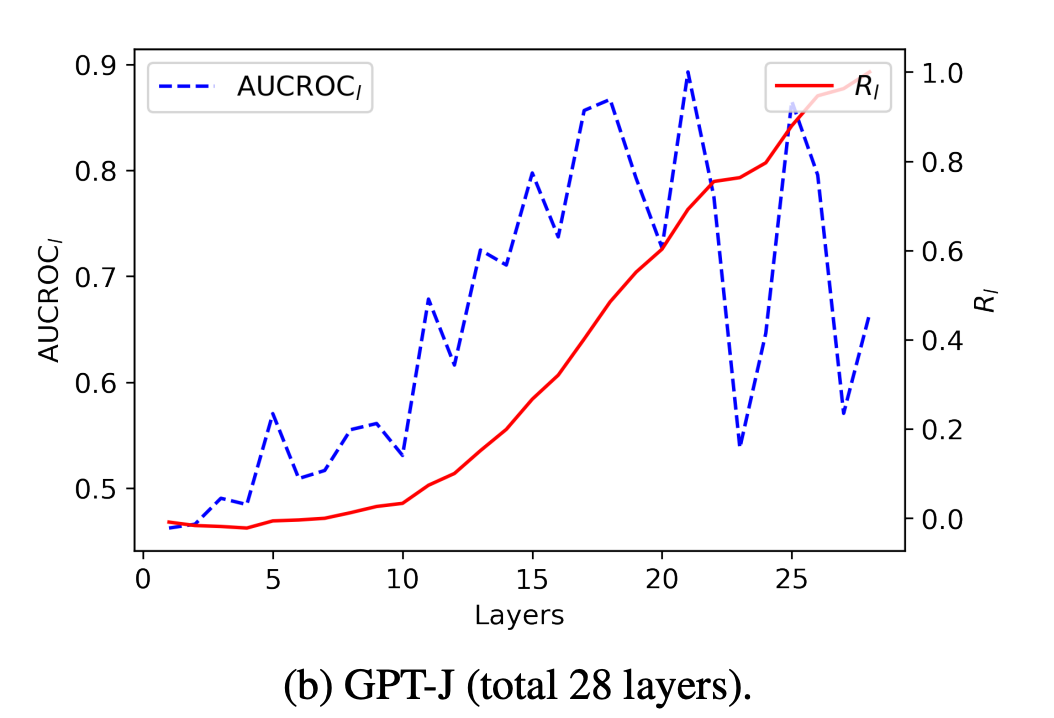
2.5 AUCROC 실험
-
l번째 레이어의 예측 시점에 대한 각 Label Word와 실제 예측값 간의 높은 Correlation 관찰
-
예측 클래스에 해당하는 Label Word에 대해 높은 attn 부여
-
…. positive, … negative …, : negative
-
positive → : : 0.2
-
negative → : : 0.8
-
-
위 가설에 대한 엄밀한 검증을 위해 AUROC 계산 실시
-
클래스 당 예측 확률 : 각 Label Word에 대한 attn값
-
Rl=\frac{\sum{i=1}^l\left(\mathrm{AUCROC}i-0.5\right)}{\sum{i=1}^N\left(\mathrm{AUCROC}_i-0.5\right)} : l번째 레이어의 Attention이 실제 예측에 영향을 준 정도에 대한 정량화
-
-
레이어가 깊어질 수록 AUROC 값이 커지는 경향성 확인
→ 모델의 실제 예측 class와 해당 Label Word에 대한 Attn Score가 깊은 레이어에서 높은 Correlation을 가짐
- 레이어가 깊어질수록 R_l값이 점차 커지는 모습 확인
→ 레이어가 깊어질수록 점차 Label Word가 최종 예측에 미치는 영향력이 커지는 모습
2.6 결론
- Label Word가 해당 Demonstration의 정보를 종합하고, 이를 예측에 전달하는 역할을 하는 모습 확인
⇒ Label Word가 정보 흐름의 관점에서 anchor 역할로서 동작
3. Proposed Method
-
앞선 분석을 바탕으로 직관적인 ICL 개선 방안 제안
- ICL의 성능 개선 및 속도 개선
-
앞선 분석의 결론
⇒ 모델 예측과 attention distribution 간 높은 상관관계 확인
3.1 Anchor Re-weighting
- Attention Mechanism을 직접적인 예측 확률의 추정으로 간주
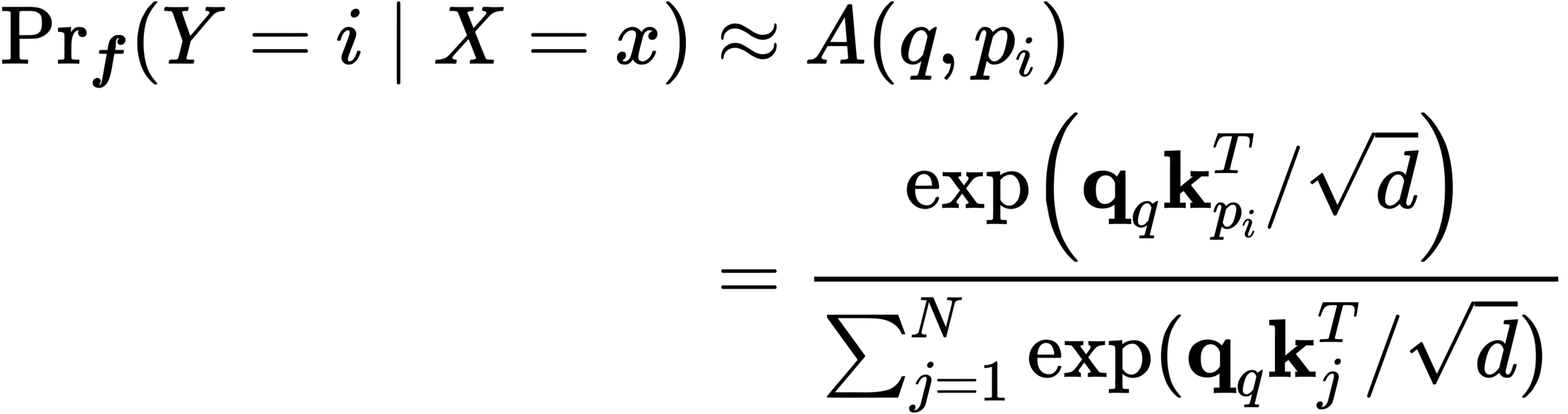
- 두가지 식을 치환하여, log prob으로 표현 가능(\textbf{q}q / \sqrt{d} = \hat{\textbf{x}}, \textbf{k}{pi} - \textbf{k}{p_C} = \beta_i )
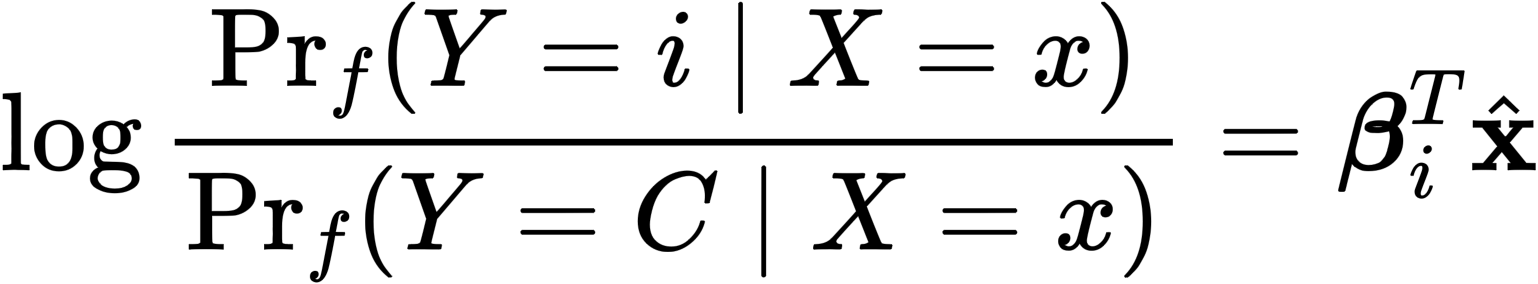
- 위와 같은 식은 결국 logistic regression 식으로 표현이 됨
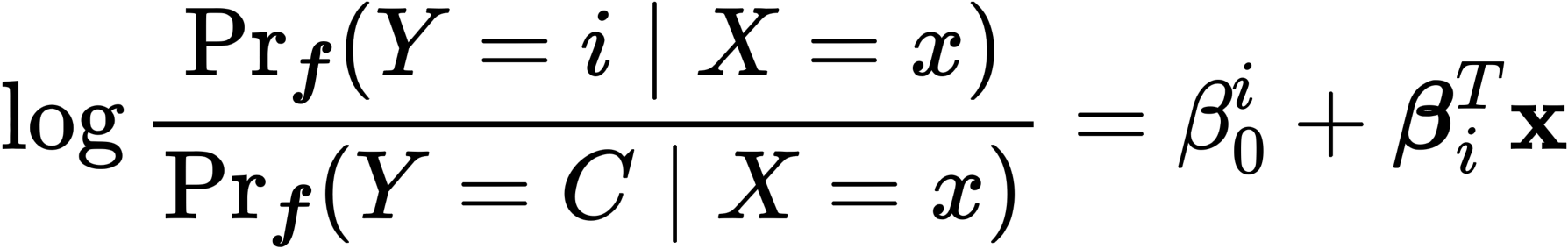
- 위 식에서 \beta_i는 original Attention Weight의 값, \beta_0가 직접적인 attention map의 수정이라고 볼 수 있음
⇒ 예측 시점에서 Attention 계산 시 query의 representation(”:”의 representation)은 고정된 상태에서 각 Label Word의 representation을 수정하는 것으로 보는듯
⇒ original attention 값을 re-weighting하는 parameter를 도입하여 이를 통해 해결하려함
-
우리는 학습 파라미터 \beta_0 에 대해서 아래와 같은 closed form을 통해 해결 가능한 최적화 가능
- 맞습니다요… ICL인데 학습 데이터가 필요해지는 상황이 오져
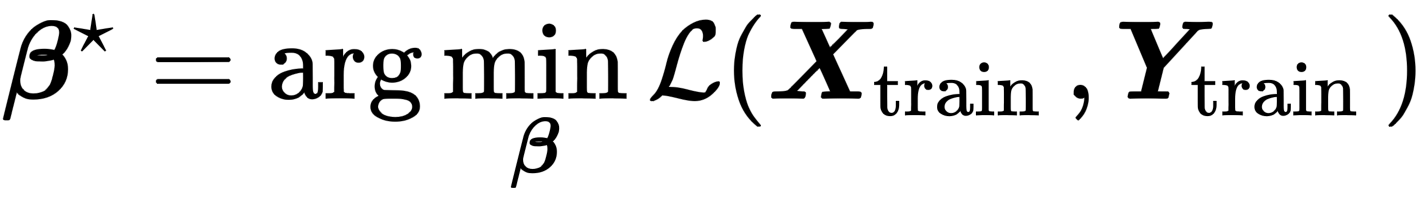
⇒ ICL을 Attention Matrix를 이용한 Logistic Regresseion으로 접근하여, LLM의 능력에 온전히 의존하지 않고, 외부에서 ICL을 수행하는 듯한 방법론
⇒ 추론과정 수행 이전에 train sample들에 대해 별도로 수행하여 진행할 수 있게 됨
3.2 Anchor-Only Context Compression
- 앞선 내용을 요약하면 모델이 예측 수행 시 Demonstration 중 Label Word에서만 정보를 취합하고 있음
⇒ ICL 시 각 Demonstration의 Label Word의 Hidden Representation만 이용하면 안되나?
-
각 Demonstration에 대해서 별도의 Inference 수행
-
Label Word의 모든 Layer에 대한 Hidden Reprensetation Caching
-
Inference 시 Caching한 Representation을 입력의 앞에 concat하여 attention 수행
→ Inference 시 Demonstration이 입력되지 않으므로 속도/메모리 개선 가능
4. Experiments
4.1 [Anchor Re-Weighting] 실험 환경
-
ICL 시 사용될 데이터 : Class 당 1개씩 샘플링
-
Re-weighting을 위해 사용할 학습 데이터 : Class 당 4개씩 샘플링
-
Re-Weighting을 위한 \beta를 해당 데이터를 이용하여 학습
-
향후 실제 ICL 수행 시 각 class 별 \beta를 적용하여 최종 예측 수행
-
-
비교 방법론 :
-
1-shot ICL
-
5-shot ICL : Re-weighting에 사용된 샘플들을 ICL에 이용한 상황
-
4.2 [Anchor Re-Weighting] 결과
- 개잘나옴;;

-
ICL 방법론과 비교하고 있지만, 해당 방법론은 일반적인 ICL과 다르게 동작함
-
모델이 예측해야 할 데이터에 대해 직접 확률 분포 생성 X
-
모델이 예측해야 할 데이터에 대한 각 Demonstration의 Label Word에 대한 attention weight을 이용한 연산 수행
- Demonstration 구축을 위한 데이터셋을 효과적으로 활용하는 방안 제시
-
4.3 [Anchor-Only Context Compression] 실험 결과
-
Text Anchor : Label Word를 직접 Inference Input 앞에 Concat
-
Hidden Random : Label Word를 제외한 임의 토큰의 representation을 caching하여 활용
-
Hidden Random-Top : Label Word를 제외한 임의 토큰을 20개 선별하고, 이 중 가장 좋은 성능을 낸 세팅 리포팅
-
Hidden Anchor : Label Word의 Representation을 caching하여 이용(proposed method)
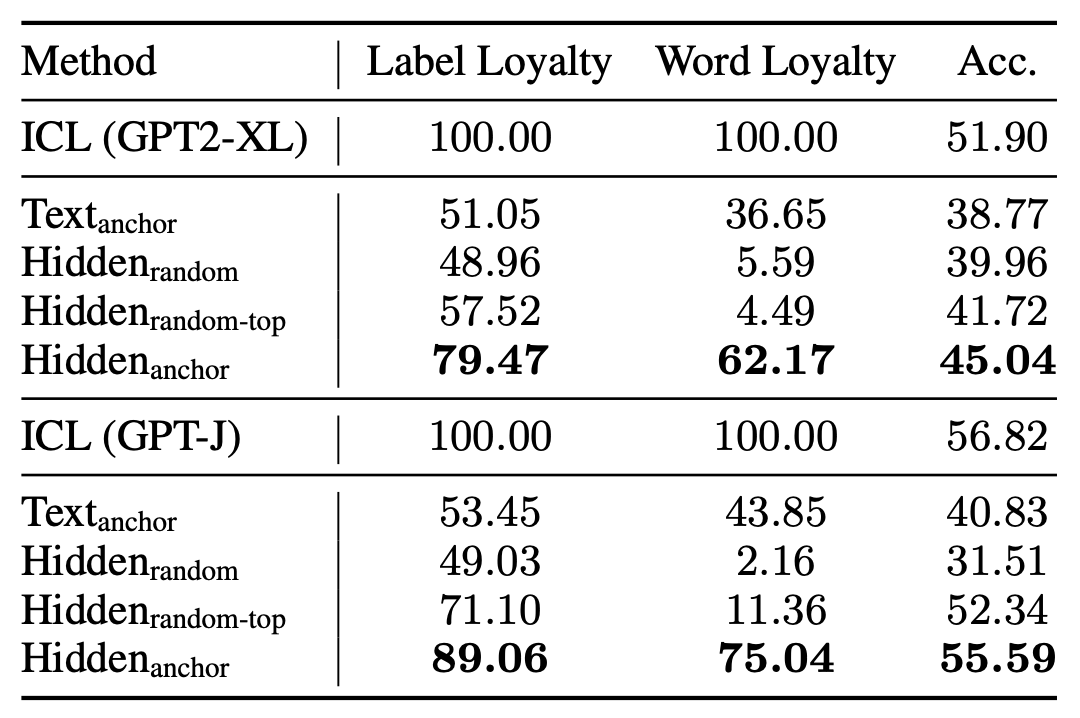
-
실험 데이터셋의 평균 결과치
-
제안 방법론이 가장 높은 성능 리포팅
→ Demonstration을 그대로 활용한 것보다는 떨어지는 성능
-
Demonstartion의 정보 중 상당수가 Label Word에 포함되어 있음
-
Demonstration의 정보 중 일부가 Label Word외 다른 토큰에 포함되어 있음. 해당 정보를 이용하는 것이 최종적이 성능 개선에 도움이 됨

- 하지만 속도 측면에서는 Caching 전략이 유효
7. Conclusion
Pros
-
ICL에 대한 심도있는 분석과 설득력있는 주장
-
주장을 뒷받침하기 위한 다양한 분석
-
분석 결과를 이용한 ICL 개선 방법론 제시 및 큰 성능 개선 달성
-
분석 결과를 이용한 ICL 개선 방법론 제시 및 속도 개선 달성
-
엄밀한 Fair Comparison을 위한 실험 설정
-
주장하는 바를 뒷받침하는 Metric 제안 및 활용
-
깔끔한 논문 서술
-
Appendix에 궁금할만한 결과물을 다 때려박음
Cons
-
교묘하게 피해가는 Contribution
- 속도 개선과 성능 개선이 동시에 달성되지 못함.
→ 이 부분을 그래서 강하게 주장하지 못함
-
복잡한 구현 방식
- Attention Matrix를 직접 이용하는 아이디어는 좋으나 너무 복잡해요 슨생님…