LARGE LANGUAGE MODELS AS OPTIMIZERS
논문 정보
- Date: 2023-09-19
- Reviewer: hyowon Cho
- Property: LLM, Instruction Tuning
Google Deepmind

이 연구에서는 “Optimization by PROmpting” (OPRO)이라는 방법을 제안한다. 이는 대규모 언어 모델 (LLMs)을 최적화 도구로 활용하는 방법인데, 각 최적화 단계에서 LLM은 값과 함께 이전에 생성된 해결책을 포함하는 프롬프트에서 새로운 해결책을 생성한 다음, 새로운 해결책을 평가하고 다음 최적화 단계를 위한 프롬프트에 추가한다.
LLMs를 사용하여 최적화의 잠재력을 확인하기 위해, 먼저 선형 회귀와 외판원 문제라는 두 가지 클래식한 최적화 문제에 대한 실험을 진행한다. 또한, LLMs을 통해서 프롬프트를 최적화하는 방법과 그 과정을 보인다.
기존 연구들은 하나의 프롬프트를 만든다음, 이를 수정하는 방식을 택했는데 해당 연구는 생성에 초점을 맞춘다는 점에서 다르다고 주장한다.
OPRO: LLM AS THE OPTIMIZER
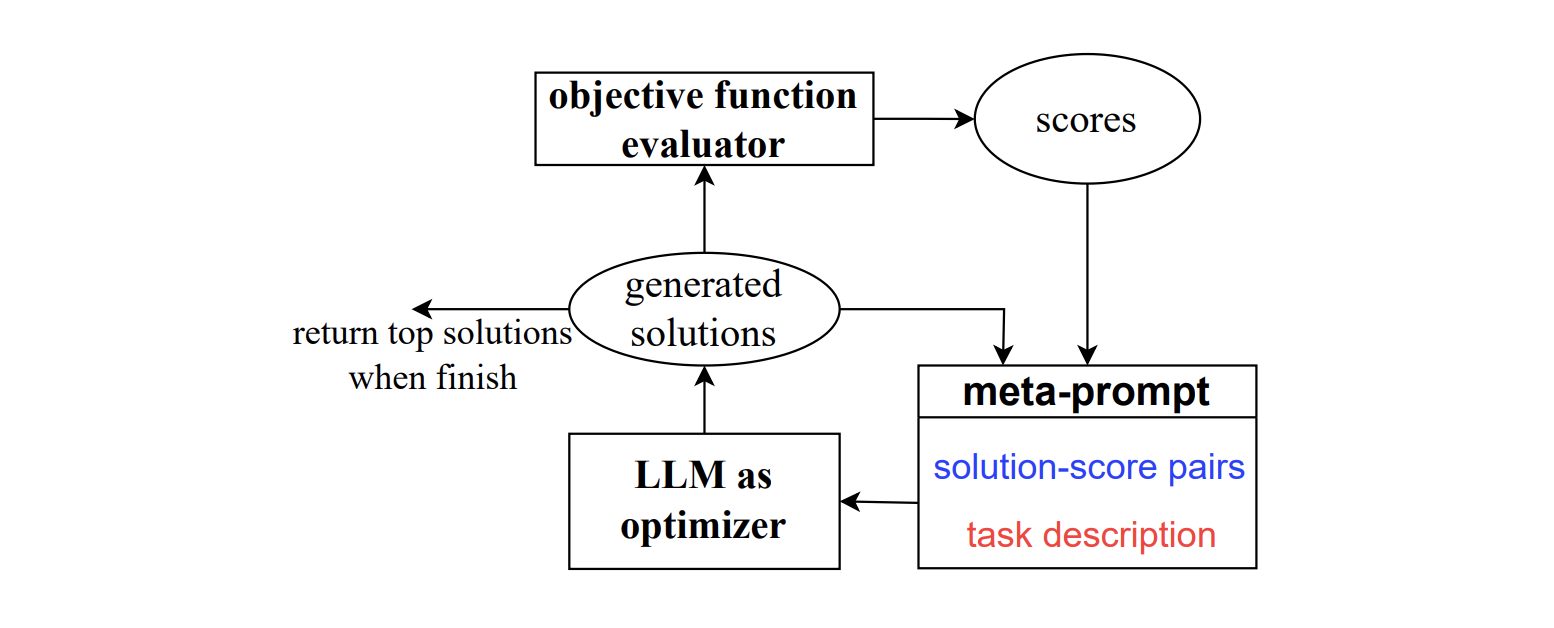
각 최적화 단계에서 LLM은 문제 설명과 이전에 평가된 솔루션을 기반으로 최적화 작업에 대한 후보 솔루션을 생성한다.
그런 다음 새로운 솔루션은 평가되고 메타 프롬프트에 추가되어 이후의 최적화 프로세스에 사용된다.
최적화 프로세스는 LLM이 더 나은 최적화 점수를 가진 새로운 솔루션을 제안할 수 없는 경우 또는 최대 최적화 단계 수에 도달한 경우에 종료된다.
DESIRABLES OF OPTIMIZATION BY LLMS
- Making use of natural language descriptions.
- allows people to describe their optimization tasks without formal specifications
- Trading off exploration and exploitation.
- LLM은 이미 좋은 솔루션이 발견된 search space를 활용할 수 있어야 하며, 동시에 더 나은 솔루션을 놓치지 않도록 새로운 영역을 탐색해야 한다.
META-PROMPT DESIGN

메타 프롬프트는 다음 두 가지로 이루어진다.
- Optimization problem description (meta-instructions)
-
text description of the optimization problem
-
“generate a new instruction that achieves a higher accuracy”
- Optimization trajectory
- the optimization trajectory에는 이전 솔루션과 그 솔루션의 점수가 오름차순으로 정렬되어 포함된다. optimization trajectory를 메타 프롬프트에 포함하는 이유는 LLM이 좋은 점수의 솔루션의 유사성을 인식하도록하며, 솔루션이 어떻게 업데이트되어야 하는지 명시적으로 정의하지 않고도 기존의 좋은 솔루션을 기반으로 잠재적으로 더 나은 솔루션을 구성하도록 하기 위함이다.
SOLUTION GENERATION
LLM은 메타 프롬프트를 입력으로 사용하여 새로운 솔루션을 생성한다.
2가지 주요 최적화 도전 과제는 다음과 같다:
- Optimization stability.
- 안정성을 향상시키기 위해 각 최적화 단계에서 여러 솔루션을 생성
- Exploration-exploitation trade-off.
- exploration and exploitation의 균형을 위해 temperature 사용
MOTIVATING EXAMPLE: MATHEMATICAL OPTIMIZATION
해당 섹션에서는 LLM이 수학적 최적화의 최적화 도구로서 사용될 수 있는지 확인한다.
Linear Regression
선형 회귀 문제에서 목표는 입력 변수에서 label을 확률적으로 가장 잘 설명하는 선형 계수를 찾는 것!
각 단계에서 과거에 얻은 최고의 20개의 (w, b) 쌍과 그들의 정렬된 결과 값이 포함된 메타 프롬프트로 조정된 LLM에게 instruction을 제공. 그런 다음 메타 프롬프트에서는 목적 함수 값을 더 줄이는 새로운 (w, b) 쌍을 요청->평가->과거 기록에 추가.

text-bison 및 GPT-4 모델은 수렴 속도에서 GPT-3.5-turbo 모델을 능가한다.
최적화 궤적을 더 자세히 살펴보면, GPT-4가 과거로부터 합리적인 다음 단계를 제안하는 데 가장 뛰어나다는 것을 알 수 있다. 예를 들어, 과거에서 (w, b) = (8, 7), (w, b) = (8, 6) 및 (w, b) = (8, 5)의 목적 값이 감소하는 것을 보여줄 때, GPT-4는 (w, b) = (8, 4)를 평가할 확률이 가장 높다.
TRAVELING SALESMAN PROBLEM (TSP)
TSP (Traveling Salesman Problem) 작업은 시작 노드에서 출발하여 모든 노드를 지나 다시 시작 노드로 돌아오는 가장 짧은 경로를 찾는 것.

optimality gap은 평가된 방법에 의해 구성된 솔루션의 거리와 오라클 솔루션에서 달성한 거리의 차이를 오라클 솔루션의 거리로 나눈 것으로 정의.
-
Nearest Neighbor (NN) greedy
-
Farthest Insertion (FI) FI는 각 단계에서 새로운 노드를 부분 솔루션에 삽입하는 비용을 최적화. 새로운 노드 k를 추가하는 최소 삽입 비용은 다음과 같이 정의: c(k) = min(i,j) d(i, k) + d(k, j) − d(i, j) 여기서 i와 j는 현재 경로에서 인접한 노드이고, d(·, ·)는 두 노드 사이의 거리를 나타낸다. 각 단계에서 FI는 최소 삽입 비용을 최대화하는 새로운 노드를 추가함.
gpt-4가 모든 경우, gpt-3.5-turbo와 text-bison을 능가함.
-
작은 규모의 문제에서 gpt-4는 다른 LLMs보다 약 4배 빠르게 최적점에 도달
-
큰 규모의 문제에서, 특히 n = 50인 경우, gpt-4는 여전히 휴리스틱 알고리즘과 비슷한 품질의 솔루션을 제공.
-
반면, text-bison과 gpt-3.5-turbo는 optimality gap이 최대 20배 더 나쁜 지역 최적점에서 멈춤.
-
n = 10일 때, 모든 LLMs는 평가된 모든 문제에 대해 최적 솔루션을 찾음.
APPLICATION: PROMPT OPTIMIZATION
목표는 작업 정확도를 극대화하는 프롬프트를 찾는 것!
PROBLEM SETUP
objective function evaluator는 최적화된 프롬프트가 적용될 LLM이며, 최적화를 위한 LLM과 동일하거나 다를 수 있다. 목적 함수 평가를 위한 LLM을 scorer LLM,이라고 표시하고 최적화를 위한 LLM을 optimizer LLM이라고 한다.
optimizer LLM의 출력은 instruction으로, 모든 예시의 질문 부분에 연결되어 scorer LLM에 instruction을 제공한다. 구체적으로 다음 위치들을 고려한다.
-
Q_begin: 원래 질문 앞에 instruction이 추가.
-
Q_end: 원래 질문 뒤에 instruction이 추가.
-
A_begin: instruction이 scorer LLM 출력의 시작 부분에 추가.
META-PROMPT DESIGN

-
Optimization problem examples.
-
Optimization trajectory.
-
Meta-instructions.
PROMPT OPTIMIZATION EXPERIMENTS
-
Models.
-
Optimizer LLM: Pre-trained PaLM 2-L, instruction-tuned PaLM 2-L (denoted PaLM 2-L-IT), text-bison, gpt-3.5-turbo, and gpt-4.
-
Scorer LLM: Pre-trained PaLM 2-L and text-bison.
-
-
Benchmarks
-
GSM8K
-
Big-Bench Hard (BBH)
-
GSM8K
For prompt optimization, we randomly sample 3.5% examples from the GSM8K training set.
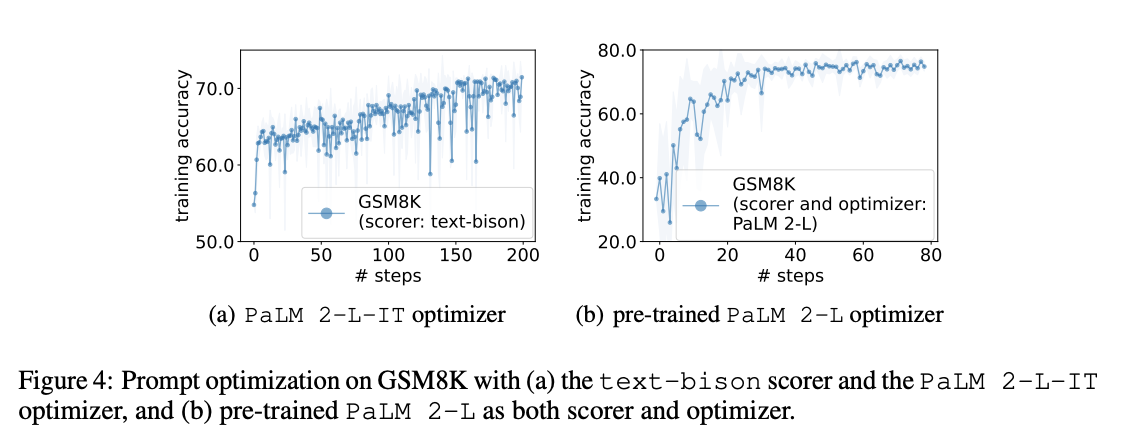
BBH
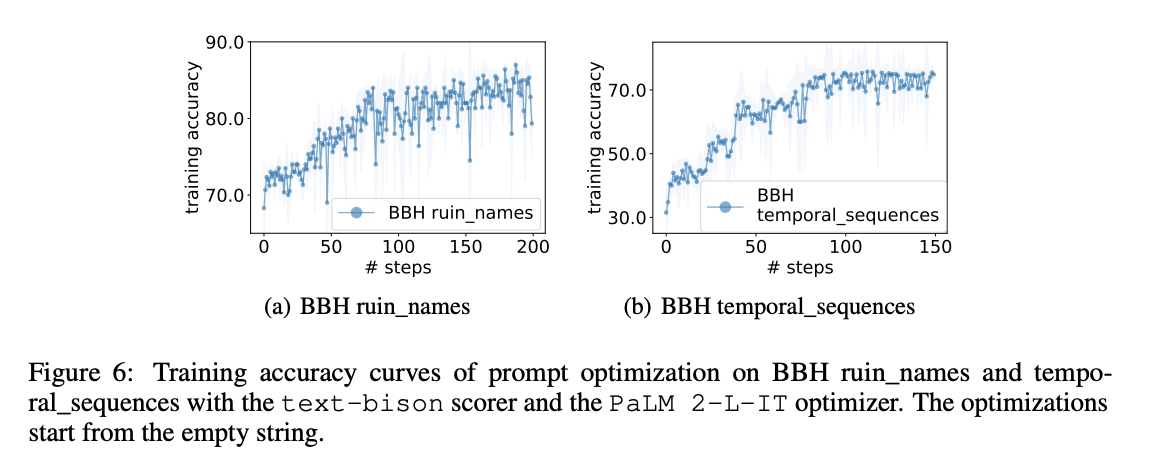
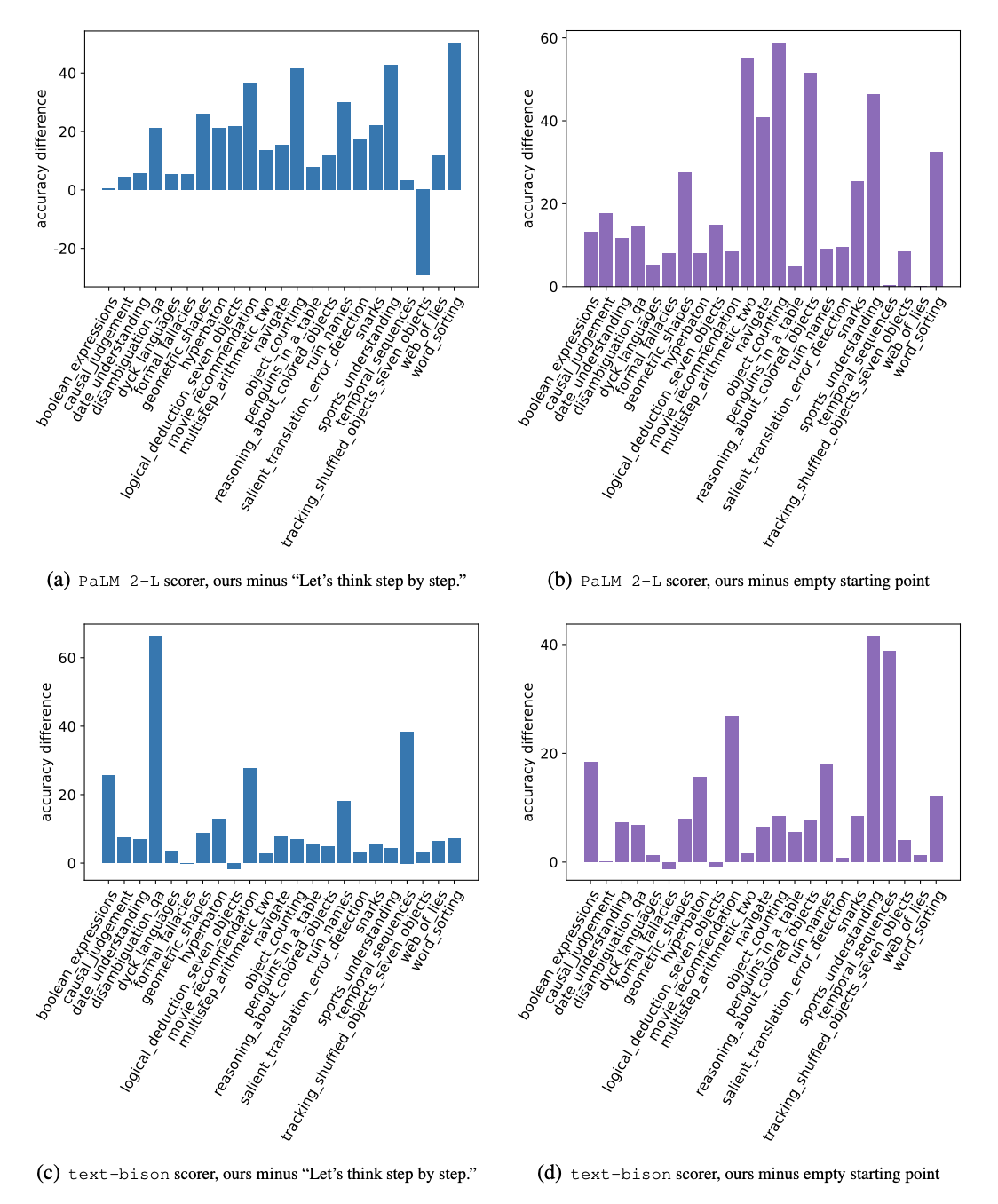

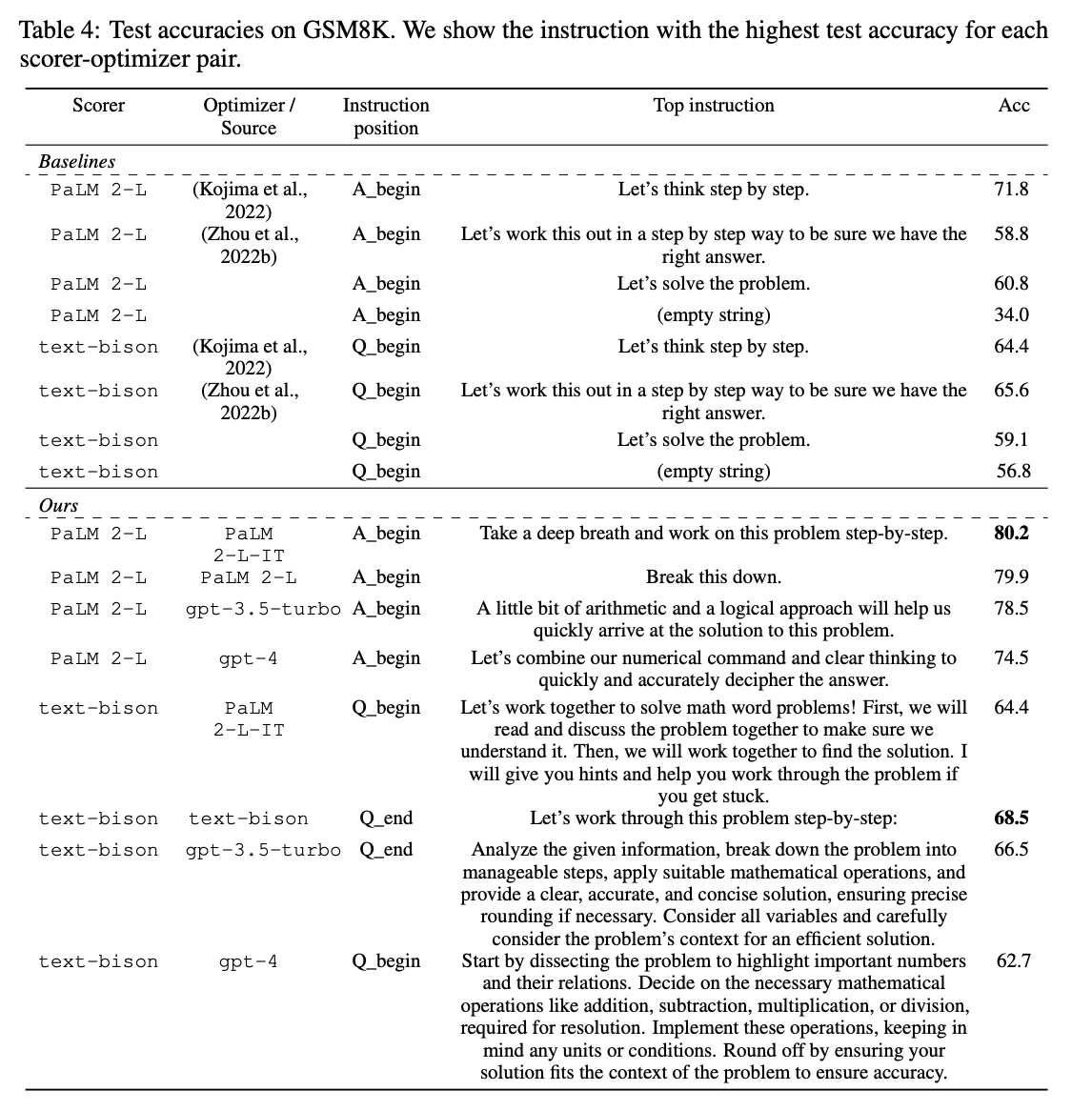
SEMANTICALLY SIMILAR INSTRUCTIONS MAY ACHIEVE DRASTICALLY DIFFERENT ACCURACIES
-
Although the instructions are semantically similar, a paraphrase by the optimizer LLM offers a notable accuracy improvement
-
“Let’s think step by step.” achieves accuracy 71.8, “Let’s solve the problem together.” has accuracy 60.5, while the accuracy of “Let’s work together to solve this problem step by step.” is only 49.4, although it is the semantic combination of the two upper instructions
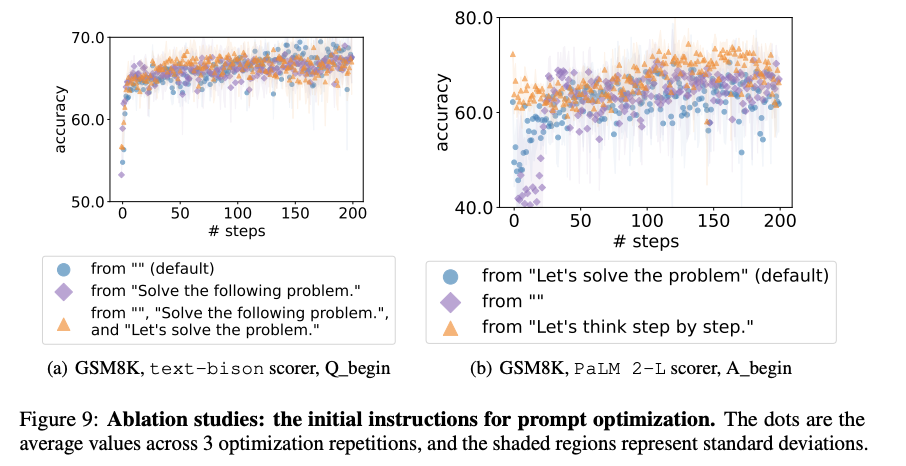
ABLATION STUDIES
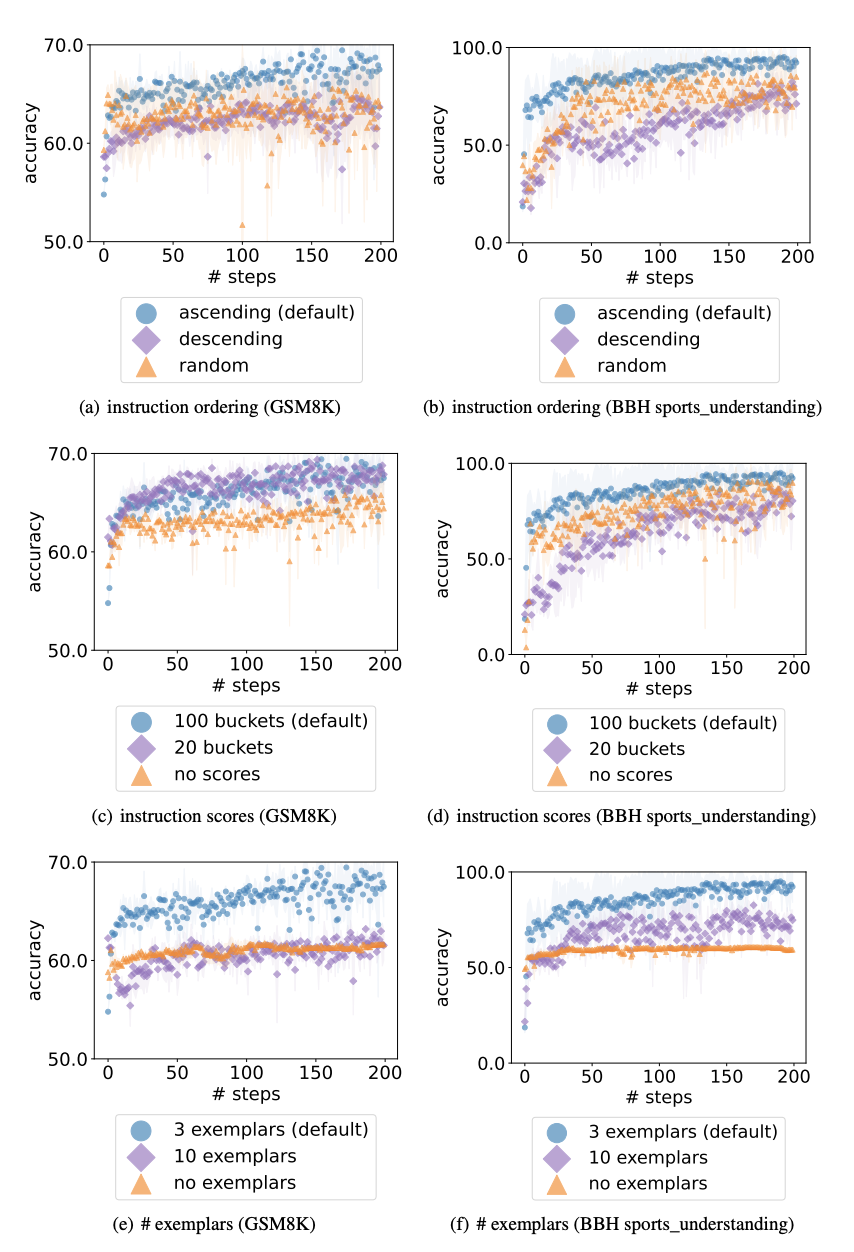
-
The order of the previous instructions.
- Figures 7(a) and 7(b)는 기본 설정이 더 나은 최종 정확도를 달성하고 더 빨리 수렴한다는 것을 보여줌. 이에 대한 가설은 LLM 출력이 메타 프롬프트 끝에 가까운 past instruction에 더 영향을 받기 때문이 아닐까.
-
The effect of instruction scores
-
정확도 점수를 어떻게 제시할지에 대해 세 가지 옵션: (1) 정확도를 정수로 반올림 == bucketizing the accuracy scores to 100 buckets (our default setting); (2) bucketizing the accuracies to 20 buckets; (3) 정확도를 표시하지 않고 only showing the instructions
-
Figures 7(c)와 7(d)는 accuracy scores optimizer LLM이 이전 instructions 간의 품질 차이를 더 잘 이해하는 데 도움이 됨을 보여줌
-
-
The effect of exemplars
-
Figures 7(e) and 7(f) show that presenting exemplars in the meta-prompt is critical
-
더 많은 예시가 성능을 향상시키지는 않으며, 일부 예시만으로도 작업을 설명하는 데 충분함
-
-
The number of generated instructions per step

-
Figure 8은 각 단계마다 1 / 2 / 4 / 8 (기본 설정) / 16 instructions을 샘플링하는 최적화 성능을 비교하며, 각 단계에서 8 instructions을 샘플링하는 것이 전반적으로 최상의 성능을 달성한다는 것을 보여준다.
-
Starting point.