LongLoRA: Efficient Fine-Tuning of Long-Context Large Language Models
논문 정보
- Date: 2023-10-10
- Reviewer: 건우 김
- Property: LLM, Efficient Training
Abstract
LLM의 context extension을 두 가지 aspects를 고려함
-
inference는 dense global attention이 필요하지만, finetuning은 sparse local attention으로 사용 가능 → shift short attention (S^2-Attn) 제안
-
PEFT 방법 적용 → 단순히 LoRA를 적용한 LongLoRA 제안
8장 A100으로 LongLoRA를 적용한 LLaMA2 7B는 최대 100k, 70B는 32k token까지 처리 가능
Introduction
길이가 긴 text를 처리하고자 하는 LLM에 대한 수요가 많음. 하지만 단순히 long text를 finetuning하는 것은 compuationally 매우 비싸기 때문에 이에 대한 연구들이 많이 이어져 왔음.
최근에 연구된 Positional Interpolation (Chen et al., 2023)은 RoPE을 기반으로 LLM의 context window size를 32k까지 늘리는 방법을 제안했지만, 실제로 8k 이상의 길이를 처리하게끔 학습을 시킬 때 128대의 A100이 필요하다는 resource가 여전히 많이 필요하다는 문제점이 있음.
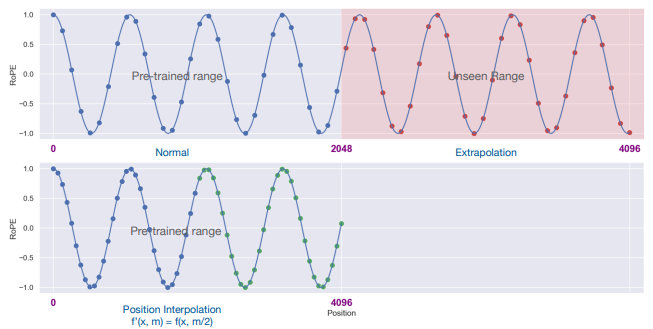
또한, Focused Transformer (Tworkowski et al., 2023)은 contrastive learning에 영감을 받은 학습 방식을 사용해서 256k 길이의 prompt까지 처리할 수 있긴 하지만, 이 역시도 128대의 TPU가 필요하다는 문제점이 있다.
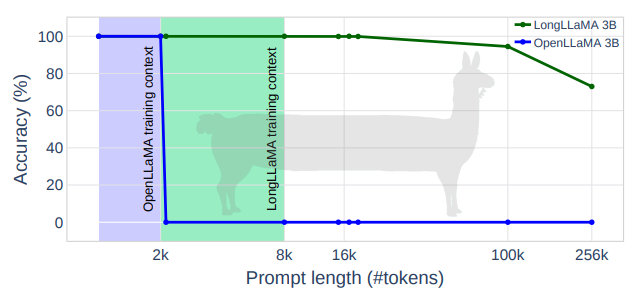
이 외에도 다양한 연구들이 최근에 진행이 되었지만, efficient하게 접근해서 long text를 처리하는 연구는 없음. 본 연구에서 efficient하게 적은 resource로 LLM을 long text에 training시키는 방법을 처음으로 제안함.
연구진들은 직관적으로 pre-trained LLM에 LoRA를 단순히 적용하는 것을 시도해봤는데, 실험적으로 이렇게 하면 long context에서 매우 높은 perplexity를 보인다고 발견함 (=no effectiveness). 또한, LoRA를 사용하는 것과 무관하게 self-attention 연산에서 computational cost가 높은 것을 지적함 (=no efficiency). 아래 그림에서 확인 가능 (LoRA)
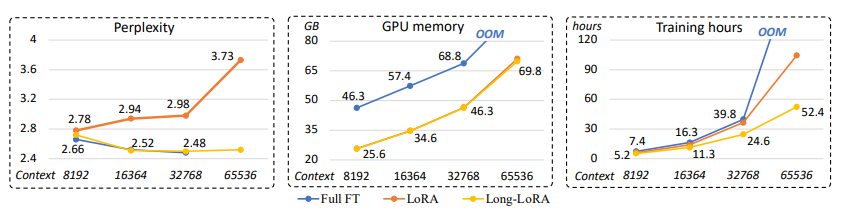
본 연구에서 위에 문제점들을 개선한 LongLoRA를 소개함.
Contributions은 다음과 같음
- shift short attention (S^2-Attn): standard self-attention 대체
→ S^2-Attn은 기존 architecture를 그대로 사용하고 있기 때문에, 최근에 나온 optimization 및 infrastructure 사용 가
- fine-tuning layers: Embedding layers + normalization layers + LoRA training
→ LoRA weight뿐만 아니라, emb+norm layers를 학습 시키는 것이 실험적으로 매우 중요하다고 언급함. 실제로 embedding+normalization layers는 LLaMA2 7B기준으로 (embedding는 model의 2%) + ( normalization layers는 model의 0.004%) 수준의 params를 가지고 있어서 low cost
- LongQA dataset: SFT에 사용되는 long text dataset을 직접 구축하고 제안
Related work
Long-context Transformers
-
retrieval-based approach: inference 시에 attention mechnaism을 변경하지 않아도 됨
-
modify multi-head attention: quadratic complexity를 갖는 self-attention 연산을 완화
-
sparse attention 적용: Longformer(2020), BigBird(2020)
-
과거 input에 대한 memory mechanism 활용: Recurrent Memory Transformer(2022), knn-augmented Transformer(2022)
-
→ 다음 방법들은 full attention과 많이 다른 연산 방식이기 때문에, pre-trained LLMs을 직접적으로 finetuning하기에는 어려움
Long-context LLMs
-
fine-tuning을 통해 context length를 확장
- Position Interpolation(2023), FOT(2023)
→ 많은 resource를 필요로 한다는 단점이 존재함
-
Postion embedding에 변화를 주는 연구
- Position Interpolation(2023), positional Skipping(2023) etc.
→ 이런 방식들은 inference를 수행할 때 original architecture을 건들어야 하지만, LongLoRA는 그렇지 않기 때문에 original architecture 그대로 사용 가능
Efficient Fine-tuning
(생략)
Method
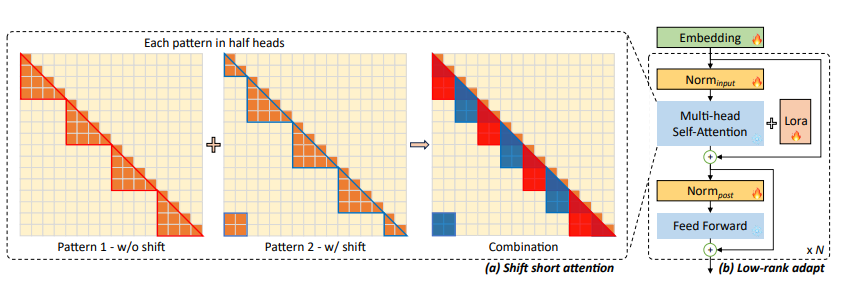
Shift Short Attention
Pilot test
-
Model: LLaMA2 7B (finetuned on RedPajama (2023) dataset)
-
Short: target context 길이의 1/4
-
Long: target context 길이
-
Metric: perplexity
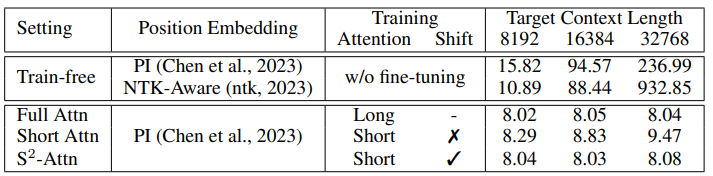
당연하게 finetuning을 하지 않으면, context 길이가 늘어남에 따라 perplexity가 매우 높아짐.
앞으로 standard baseline을 full attention으로 full finetuning시킨 model로 설정
-
Pattern 1 (Short attention)
-
Input token을 group 단위로 나누어 각 group마다 self-attention 연산을 진행
ex) input token이 8192 tokens이면, group를 4로 설정할 때, 각 group마다 2048 크기에 대한 연산 진행 (첫 번째 group: 1st~2048th)
→ 위에 Table을 보면, 준수한 perplexity를 보여주긴 하지만, context 길이가 길어짐에 따라 perplexity가 높아지는 것을 볼 수 있음. (저자는 이에 대해 각 group들 간의 정보 교환이 발생하지 않았기 때문이라고 지적)
-
Pattern 2 (Shifted pattern)
-
각 group 간의 communication을 만들어주기 위해 설계한 pattern. Group간의 parrtition을 group 크기의 절반만큼 shift를 진행시킴.
ex) 위와 동일한 상황에서, group parition은 1024 길이만큼 움직이기에, 첫 번째 group은 (1025th~3072th). 이렇게 하면 앞에 1024개와 뒤에 1024개의 tokens이 남는데, 남는 것들은 동일 group에 귀속시킴.
→ Pattern1과 Pattern2를 multi-head의 절반을 각각 계산을 하고 합치는 방식을 택함. 이 방식은 추가 연산을 필요로 하지 않고 groups들 간의 정보 흐름을 가능하게 해줌. 위에 Table을 확인하면 Full finetuning과 비슷한 성능 보임
(Recap)
-
Head dimension 기준으로 절반 나눔 → 2개의 chunks 생성
-
둘 중 하나의 chunk는 Shift Token 적용 (group size의 절반만큼 이동)
-
Tokens들을 각 group으로 나누며 self-attention 연산 진행
-
attention 연산은 각 group별로 진행시킴
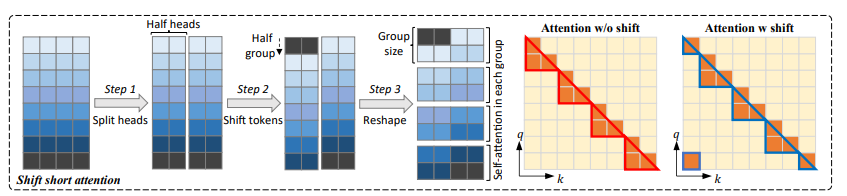
Peseudo code

Consistency to Full Attention
본 논문에서 제안하는 S^2-Attn을 다른 efficient attention과 비교 진행
-
dialted attention
-
stride sparse attention
→ S^2-Attn은 test시에 Full-attention을 적용할 수 있을 뿐만 아니라, pre-trained LLMs에 바로 long-context finetuning 적용할 수 있는 이점이 존재함. 아래 Table에서 있는 baselines은 finetuning이 가능한 dialted/stride sparse methods를 선별해서 실험 진행
-
_cro.heads: _S2-Attn을 진행할 때, head를 나눠서 attention 연산을 진행하고 합치는 원래 방식
-
_cro.layers: _S2-Attn을 진행할 때, …음..자세히 안나와 있어 뭔진 모르겠지만, 어쨋든 성능이 별로니 중요하지 않아 보
-
_only P1: _all no shift (pattern 1)
-
only P2: all shift (pattern 2)
→ 저자가 언급하길 Shifting은 특정 attention pattern에 과적합 되는 것을 방지 시킨다고 하지만, 근거가..좀..?

Improved LoRA for Long Context
LoRA를 바로 LLM에 적용해서 lon-context를 다루는 것은 어렵다. 실제로, 아래 Table에서 LoRA와 Full-finetuning간의 perplexity는 많이 차이 나고, LoRA Rank를 키워봐도 별로 효과가 없음.
따라서, 단순히 LoRA만 학습시키는 것이 아니라 Normalization/embedding layers를 LoRA와 함께 학습 시키는 것이 Full Finetuning과 성능 면에서 비슷한 것을 실험적으로 확인함
-
두 가지 종류의 layers를 학습하는 것이, trainable params 개수에 큰 영향이 없음
-
Model: LLaMA2 7B (with S^2-Attn)
-
Target length: 32k
-
+Norm/Embed: Normalization layers 혹은 embedding layers를 학습 시키는지

Experiment
Settings
-
Models and maximum extended context window sizes
-
LLaMA2-7B up to 100k
-
LLaMA2-13B up to 65k
-
LLaMA2-70B up to 32k
-
→ Position indices들은 모두 Position Interpolation으로 조정 시킴 (따라서, 학습 과정도 Position Interpolation에서 사용한 setting과 동일하게 설정)
-
Resources
-
per-device batch: 1
-
gradient accumulation step: 8
-
→ 따라서, global batch size를 64로 설정 (with 8 A100 GPUs) [~대략 1000steps]
-
Datasets
-
Training: Redpajama (2023)
-
Test: PG19 (2020), cleaned Arxiv Math proof-pile dataset (2022)
- Perplexity로 측정
-
Finetuning dataset: LongQA 직접 구축
- 3k question(theme: technical, science fiction, other books & task type: summarization, relationsips, character, detail)-answer pairs
-
Main Results
Long-sequence Language Modeling
아래는 proof-file data에 대한 perplexity. Redpajama perplexity는 appendix에 있던데, perplexity 값이 7~8 정도 되서 본문에 넣지 않은듯.
→ 그래도, dataset 상관 없이 길이가 길어짐에 따라 perplexity가 떨어지는 것을 확인할 수 있
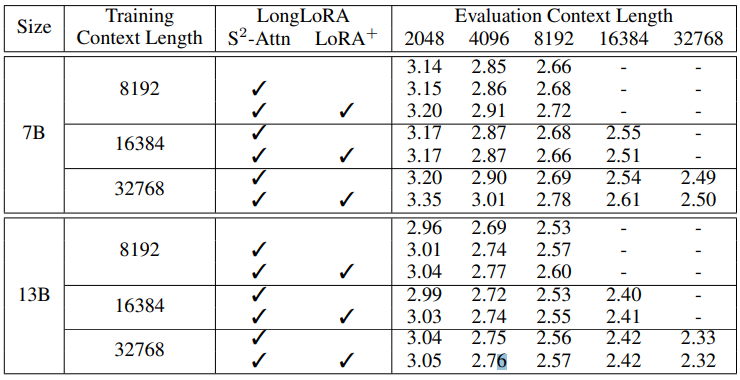
가장 흥미롭게 본 실험 결과인데, 극단적으로 context length를 늘리고 난 결과 LongLoRA는 준수한 실험 결과를 보여줌. (근데 이것도 역시 proof-pile dataset)

RedPajama도 그렇게 나쁘진 않음

Ablation study
-
Efficiency Profile
-
S^2-Attn이 얼마나 효과적인지 파악하기 위해, FLOPs 단위로 분석을 실시.
-
각 수치는 연산 비중을 나타냄
-
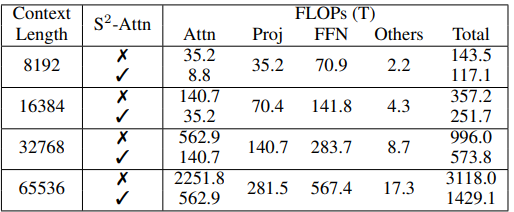
-
Fine-tuning steps
- 확실히 초반에는 Full-finetuning이 더 빠르게 수렴하지만, LoRA+ (LoRA+Norm/Emb)역시 200steps 이후에 비슷한 수준을 보임

Conclusion
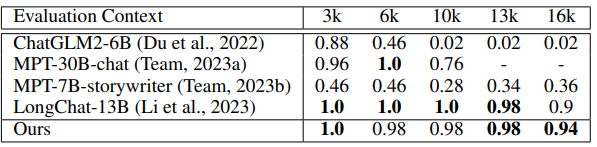
LLM이 Long-context를 다루는데 효과적인 매우 간단한 방법론인 LongLoRA를 제안함. LLaMA가 2048 tokens, LLaMA2가 4096 tokens까지 처리하는 것을 생각하면, 본 실험에서 진행한 32k~100k는 매우 크다는 것을 알 수 있음.
또한, A100 8장으로 모든 실험을 진행했기에 정말 효율적으로 학습을 진행시킬 수 있고, Full-FT와 비교해도 비슷한 수준을 선 보임. Downstream task로는 topic retrieval을 진행하고, 해당 분야에서 SOTA인 LongChat-13B와 비교했을 때, 실제로 비슷하거나 더 나은 성능을 보여줌. 다만, downstream task가 하나 밖에 없어서 아쉬움 (물론 극단적인 길이의 long-context를 처리하는 task의 부재도 있음)