Measuring and Improving Semantic Diversity of Dialogue Generation
논문 정보
- Date: 2023-02-02
- Reviewer: 준원 장
- Property: Dialogue, Evaluation Metric
1. Introduction
Dialogue Model들이 어느정도 ‘fluent’한 대답들을 생성할 수 있게 되었지만, 여전히 dull하고 uninformative generic한 대답을 자주 생성하는 문제는 해결하지 못하고 있다.
Dull하고 uninformative generic한 대답은 왜 문제가 되는가? → engagingness가 떨어진다.
논문에서 사람들의 Engagingness를 올리기 위해서는 diversity of responses를 향상시켜야 한다고 주장한다.
그렇다면 diversity of reponse라는 것은 무엇인가?
논문에서 명확하게 정의하지는 않았지만 아래처럼 ‘형식적인’ 대답이 아니라 다양한 어휘들을 구사해 가면서 대답을 생성하는 것을 diversity한 대답이라고 정의하는 것 같다.
‘’’
→ Yeah. I know. → Thank you . → That’s cool . → Not yet .
‘’’
또한 저자들은 좋은 diversity of responses는 human judgement와의 상관관계가 높아야 한다고 주장한다.
기존 연구들은 diversity of responses를 향상시키기 위해 ‘lexical-level’ metric에 의존했다고 한다.
-
Distinct-N
-
Entropy-N
하지만 lexical-level은 semantic diversity를 충분히 잡아내는데 한계가 있다.
(ex. 아름다운 꽃병이 있다. & 예쁜 꽃병이 책상 위에 있다. → 표면적으로 다르지만 유사한 토큰은 semantic diversity를 확장하는데 한계가 있다 → latent space 영역의 도움이 필요하다)
이를 해결하기 위해 (1) 저자들은 (latent space를 활용해) semantic diversity를 측정하는 ‘_SEM-ENT’ _라는 automatic evaluation metric을 제시하며, (2) Generated Responses의 semantic diversity를 향상시키기 위한 simple하고 effective한 방법론을 제시한다.
2. Related Works
→ Enhancing Response Diversity
-
maximize mutual information: penalize generic responses
-
using latent variables to generate multiple and diverse responses
-
selectively penalize frequent responses by removing them from the training set
-
decoding algorithms
→ Metrics for Capturing Response Diversity
-
Reference metrics (gold label과의 비교를 통해 diversity 측정)
-
Unreferenced metrics (Dist-n (fraction of distinct n-grams over possible n-grams)& LF (calculates the frequency of low-frequency words in generated responses) & Ent-n (frequency difference of n- grams into account.) )
→ 논문에서 제시하는 방법론은 기존 NLI diversity 측정과 다르게 multi[le context에 대해서 생성된 responses들에 대한 diversity도 측정이 가능하다고 한다.
(ex)
‘’’
Input Context : c{a} → Generated responses {r{a1},r{a2},r{a3}, …, r_{an}}
Input Context : c{b} → Generated responses {r{b1},r{b2},r{b3}, …, r_{bn}}
이 있다고 할 때, 기존의 NLI diversity metric은 intra-diversity ({r{a1},r{a2},r{a3}, …, r{an}})는 측정이 가능하나 context가 유사할 경우 inter-diversity ({r{a1},r{a2},r{a3}, …, r{an}} vs {r{b1},r{b2},r{b3}, …, r{bn}})를 측정하기에는 한계가 있다고 주장한다.)
! 읽으면서 아쉬웠던 POINT !
**→ context가 유사할 경우 본인들이 제시한 metric의 성능이 diversity of response를 더 잘 측정하는지에 대한 실험이 없는게 아쉽다..!! **
3. Measuring Semantic Diversity
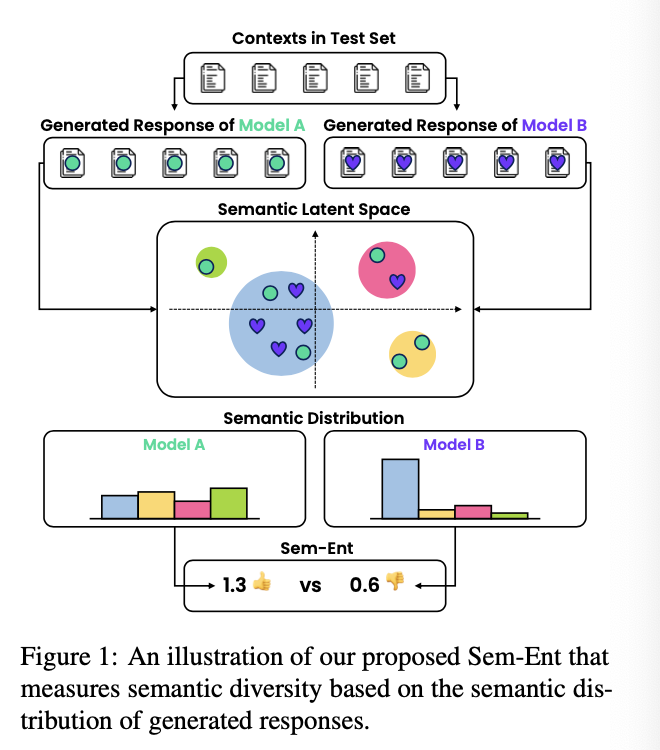
저자들이 제안하는 semantic diversity 측정 방법은 생각보다 간단하다.

- Context, Response Pair가 있는 training set (m개)이 있다고 했을 때, LM (DialoGPT)를 사용해 각 responses들을 latent space로 보낸 후, k-means 알고리즘을 활용해 k개의 cluster로 분류시킨다.

- n개의 context, response test pair에 대해서는 dialogue generation model M (위의 LM=dialoGPT와는 다름)을 활용해 response를 생성한다.

- dialogue generation model M이 생성한 n개의 responses들을 dialoGPT를 태워 latent space로 보낸 후 각각을 k개의 cluster로 indexing해 dialogue generation model M마다의 response semantic distribution을 근사한다.
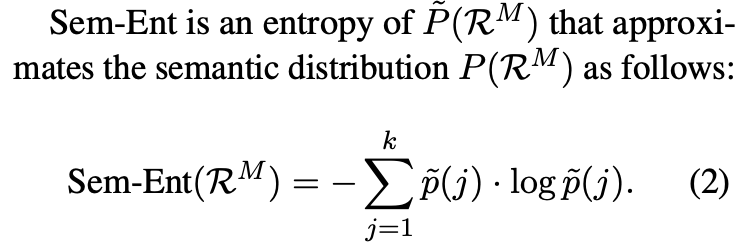
- dialogue generation model M의 entropy식이 diversity of responses를 나타낸다. (response semantic distribution이 uniform = entropy 🆙 = Sem-Ent 🆙)
Experimental Setup
-
(Blendor-Bot 90M, BART-Large) & (greedy, beam, top-k sampling, and nucleus sampling)의 8개 조합을 활용해 28 dialogue generation setting을 만듦
-
dataset : 10 contexts from the test set of a DailyDialog dataset
-
criteria: diversity and* interestingness (*5-point Likert scale)
Baselines
-
Lexical-Level Semantics
-
Dist-n
-
Ent-n
-
LF
-
-
Semantic-Level Semantics
- MAUVE (divergence of generated responses from human responses이지 generated responses 자체의 diversity를 측정하지는 X)
Results
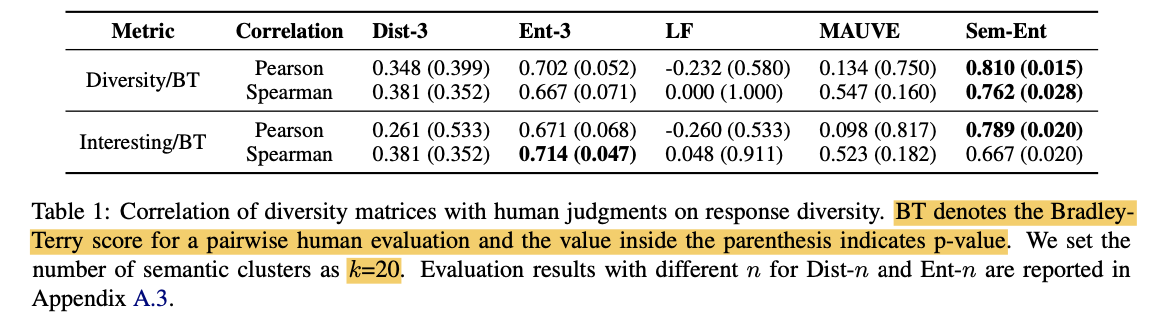
(** Bradley-Terry model은 outcome을 확률로 바꿔주는 모델)
! 읽으면서 아쉬웠던 POINT !
→ DialoGPT의 Latent Space의 reliability를 증명해 줄 실험이 전혀 X
→ Dialogue Generation Model 선택이 별로였다.
**EX) Expert Model, Amateur Model 별로 나누어서 fine-tuning을 해서 실험을 한다던가 했으면 조금 더 믿을만한 결과가 아니었을까? **
→ DailyDialog dataset과 DialoGPT의 관계가 없는 것도 아쉽… (DialoGPT는 reddit으로 tuning한 모델인데,,,??)
4. Improving Semantic Diversity
Analysis
저자들은 response distribution (training dataset)이 결국은 key라고 지적하면서 DailyDialog dataset의 response의 semantic distribution 분석을 해보기 시작한다.
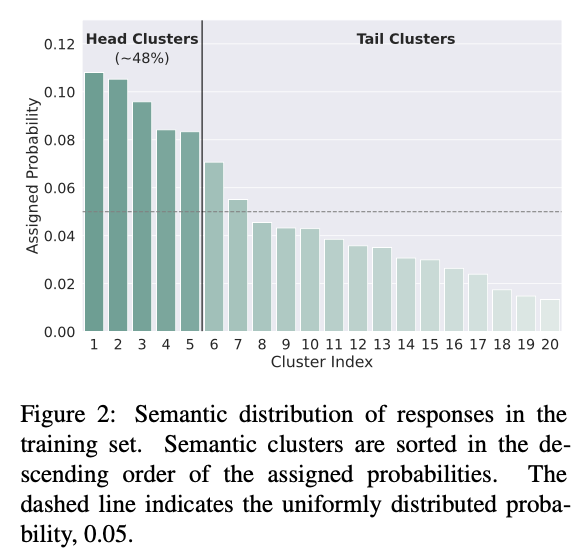

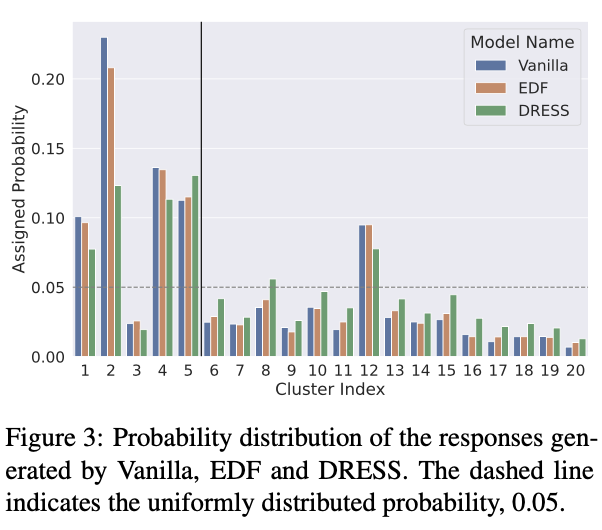
(다행히도) DailyDialog dataset은 저자들이 기대하는 diversity (uniform)한 distribution의 형태를 가지지 않았다. Dull하고 uninformative generic한 reponse들은 head clusters (idx=1~5)에 몰려있었으며, engaging한 cluster들(idx=17~20)이 전체에서 차지하는 비중은 낮았다.
DRESS
결국에는 데이터셋이 문제라는 건데, 저자들은 이를 해결하기 위해 DRESS라는 방법론을 제시한다. (역설적이게도 데이터셋이 문제가 있다는 것을 알았을 때 사용할 수 있다… → DialoGPT 태우는 비용 어쩔래?라는 반박은 대응 못할듯..)
이 방법론도 간단하다.
다음과 같이 특정 responses들마다 가중치를 주어서 보정하는 방식이다.
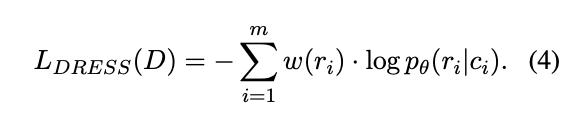
key idea는 frequent한 response보다는 infrequent한 responses들에 loss를 크게 주어서 responses semantic distribution을 uniform하게 만들자는 것이다.

그리고 여기서 trick을 하나 더 추가하는데, frequent semantic clusters 에 대해서는 강하게 penalize주는 것이다. 매 epoch마다 head cluster에 속하는 response들을 생성할 경우 loss를 오히려 반대로 주는 것이다. (i.e., Negative Training)
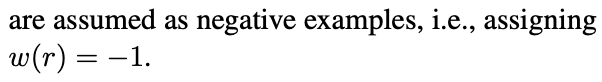
Experimental Setup
-
dataset : DailyDialog, OpenSubtitles
-
automated criteria: diversity & coherency
-
human eval: Appropriateness (coherency) & Informativeness (given response has meaningful information relevant to its given context)
(→ 일반적으로 human eval은 pairwise로 측정하는데 diversity는 pairwise 자체로는 평가하기 어렵다고 한다. … 한 모델이 비슷한 context에 대해서 여러 답변을 생성하는 것을 봐야하기 때문이지 않을까?)
Results
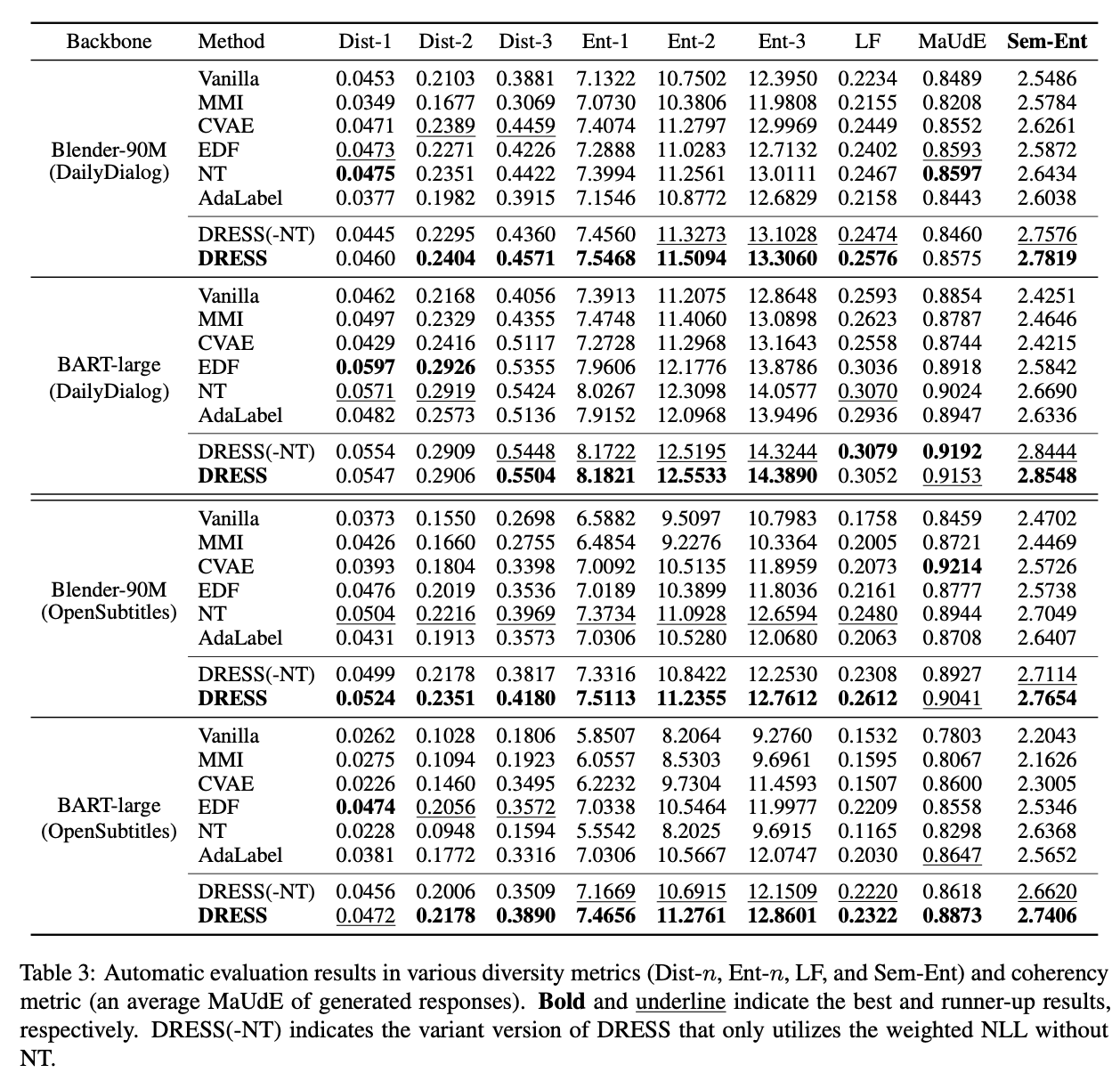
→ DRESS가 lexical-sematic한 지표들에서 성능이 잘 나온 것은 좋은 성과인듯 하다. (Sem-ENT에서 잘나오는 것은 당연,,, 목적함수 설계가 이 지표가 잘나오도록 설계)
→ (-NT) 역시 대부분 좋은 성능을 보였는데 DRESS에 대한 contribution을 강조하기 위해서 설계한 실험으로 보임
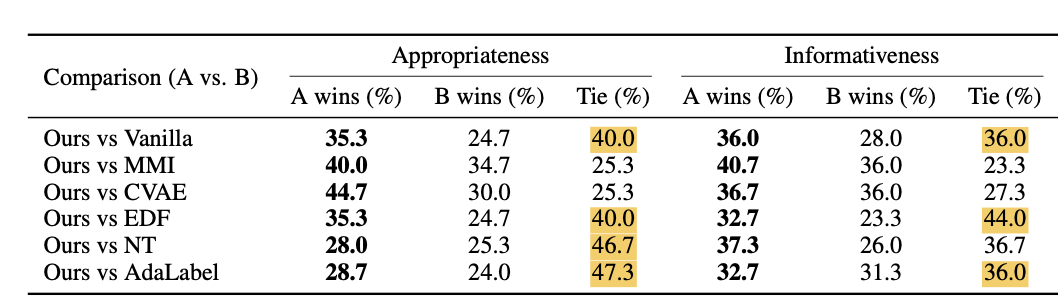
→ Human Eval 결과는 설득력 있어보이지 않음
→ DRESS를 활용했을때 Semantic Distribution이 uniform해지는 것을 보이는 것은 설득력이 있어보는 실험으로 보임