Measuring Association Between Labels and Free-Text Rationales
논문 정보
- Date: 2023-05-11
- Reviewer: 준원 장
- Property: Reasoning
Introduction
→ Model의 decision making이 과연 faithful rationale을 바탕으로 이루어졌는가를 분석한 논문

-
기존의 INPUT(Question/Hypothesis)안에 표면적으로 존재한 rationale는 OUPUT까지 reasoning 하는데 한계
-
fill in the gap을 위해 free text rationale를 포함한 dataset이 나옴
→ free text rationale를 활용해 추론하는 방법에는 크게 2가지가 있다.
- Pipeline: INPUT(Question & Answer Candidiates) > MODEL 1 > Rationale && Raitonale & Subset of Input (Answer Candidiates) > MODEL 2 > Answer
[Model2를 sufficiceny라고 하는듯: is sufficient to make a prediction on its own]

- Self-rationalizing: INPUT(Question & Answer Candidiates) > MODEL > Rationale & ANSWER

→ 논문은 실험과 분석을 통해서 아래의 물음에 대한 답을 하고자 한다.
Q1. Pipeline과 Self-rationalizing 중 어느 것이 성능이 좋은가?
Q2. Predicted Label과 Generated Rationale간의 관계를 평가하는 방법이 없을까?
Dataset, Task, Evaluation
→ Dataset & Task
- Free Text Rationale이 있는 Commonsense QA & SNLI

→ Model
-
T5 Model을 다양한 Setting에 맞게 훈련해서 활용
-
I→R (inputs → rationales)
-
R→O (rationales → outputs)
-
I→OR (inputs → outputs / rationales)
-
IR→O (inputs / rationales → outputs)
-
I→O (inputs → outputs)
-
-
비교하는 Model
-
Pipeline : I→R;R→O
-
Self-rationalizing : I→OR
-
→ Evaluation
-
Rationale Evaluation
-
token overlap으로 gold rationale과 predicted rationale을 평가하는건 plausibility, faithfulness를 측정하지 못함 (Rationale의 본질의 집중하자)
-
Simulatability measures기법 차용: Rationale이 들어감으로써 Output에 대한 predictive power가 얼만큼 증가했는지 평가 (ie., IR→Ô minus I→Ô)
-
Ô을 활용할 경우 degeneration이 생겨서 gold label O를 활용했다고 해서 이를 방지
-
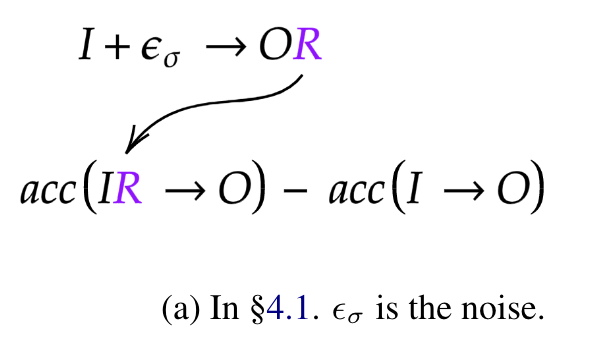
→ 직관적 이해: 노이즈가 섞인 Input으로 만들어진 Rationale로 추정한 Output Acc는 훼손될것
→ Result
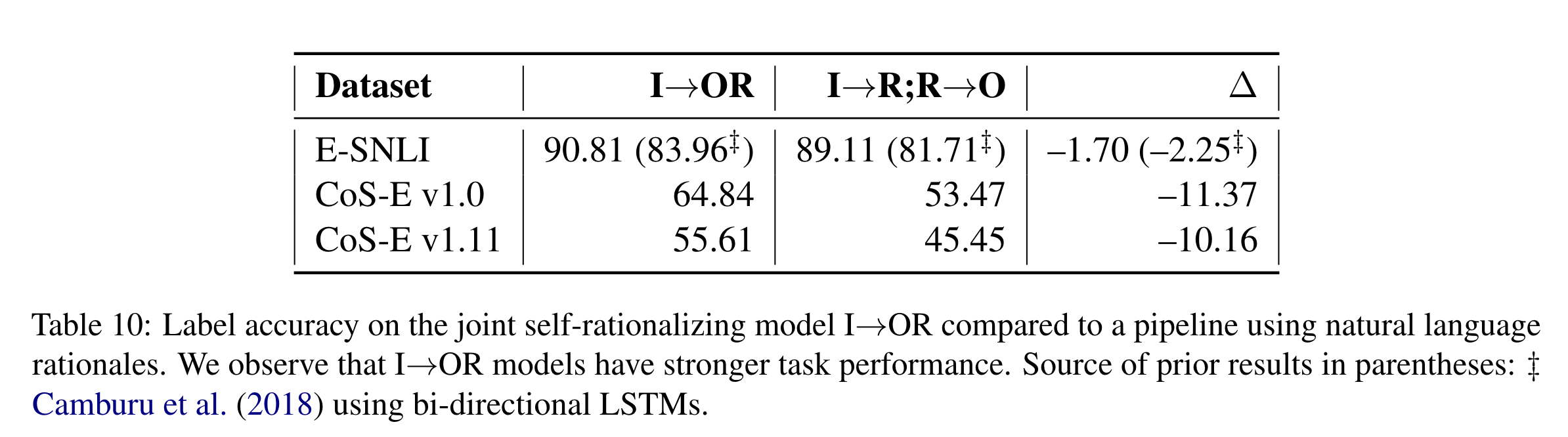
- Self-rationalizing이 pipeline보다 성능이 잘 나온다.
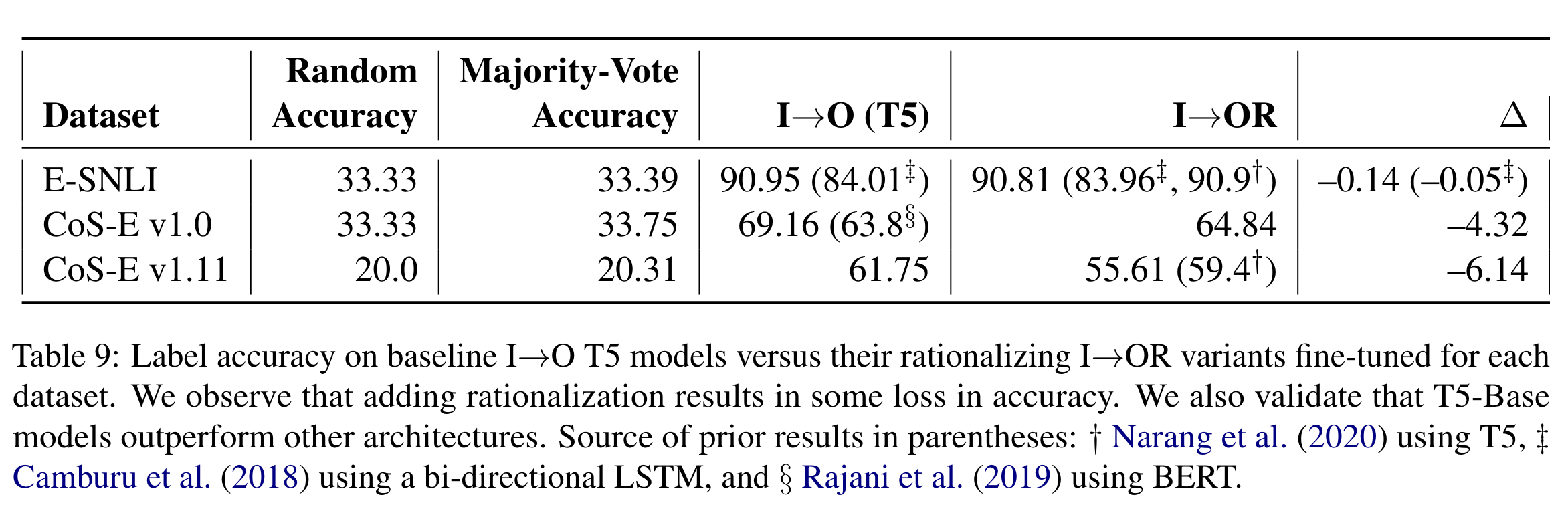
- 하지만 Self-rationalizing이 I → O 으로 직접적으로 training한 모델보다 미세하게 성능이 떨어진다.
(논문은 성능이 미세하게 떨어져도 모델이 추론능력을 학습했는지를 보여주고자 함)
Shortcomings of Free-Text Pipelines
→ Joint Model Rationales are More Indicative of Labels
- I → R로 학습한 Model은 task-specific input이 주어지지 않을 경우 output을 맞추기 위한 rationale을 학습하기 어렵다
아래와 같은 Ontonotes Dataset에 Task Specific 없이
Input “The quick brown fox jumps over the laze dogs” → Rationale
을 infer할 경우 Model은 POS나 Syntactic Parsing중 어떤 rationale 뱉을지 모르기 때문에 같은 rationale을 만들도록 학습이 됨

- Output과 Rationale을 같이 생성하는 모델이 output을 예측하는데 유용한 정보를 줄 수 있음을 실험적으로도 보임
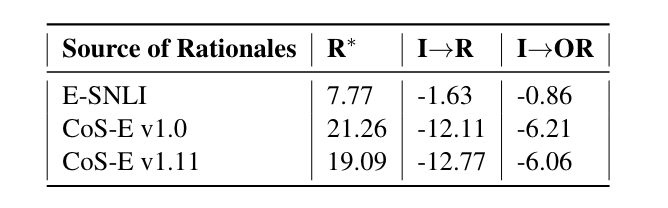
R*→ O Train한 후 (I→R, I→OR에서 생성한 Rationale를 가져와 Acc 측정)
-
test set ground-truth R∗ rationales
-
test set rationales generated by I→OR
-
test set rationales generated by I→R
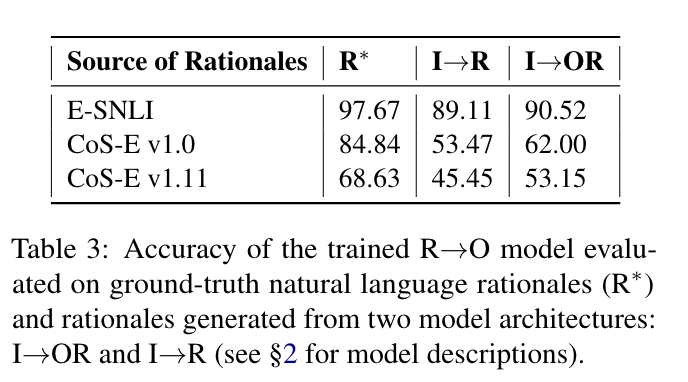
- 본인들이 제안한 metric을 바탕으로 Output과 함께 만든 Rationale이 더 유용함을 보임 (higher is better)
→ Sufficiency is not Universally Valid
-
Ouput을 알지 못한 Rationale추론(sufficiency 가정)은 universally하게 valid하지 않다.
-
IE Task처럼 일부 Token만이 정보를 추출하는데 유의미할 경우 sufficiency 가정이 유효할 수 있으나 reasoning은 아님
-
애초에 Rationale은 Input → Ouput까지 가는데 있어서 *‘Complement’ *역할인데, R → O 모델로만 Output을 예측하는 것은 당연히 성능저하로 이어질 수 밖에 없음
-
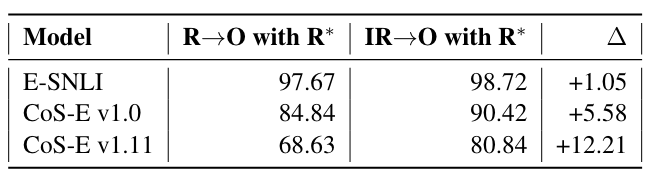
- E-SNLI 성능 차이가 미미한 이유는 Rationale에 output에 대한 rationale이 명시적으로 완벽하게 포함되어 있기 때문.
→ Pipeline을 쓰면 안되는 이유
-
cascading errors caused by low-quality rationales that are not indicative of labels
-
missing information due to rationales not being sufficient
-
double the number of parameters and more manual labor needed to reach comparable performance to an end-to-end (I→O) model; still often performing worse
Analyzing Necessary Properties of Joint Models (Ablation Study)
(I → OR 모델이 얼마나 faithful한 rationale을 가지고 prediction을 하는가
↔ predicted label과 predicted Rationales 사이에는 어떠한 관계가 있는가)
→ Robustness Equivalence
- input에 noise가 가해졌을 때 output / rationale 중 하나가 틀리면 둘 사이의 관계가 없다고 말할 수 있음
(둘다 틀리거나 아니면 같은 pattern을 가지고 틀려야 faithful한 rationale을 가지고 output을 생성했다고 말할 수 있음)
- N (0, σ^2)에 따라 σ^2를 늘려가면서 input embedding에 노이즈를 주어 output(accuracy)과 rationale(output predictive power)이 얼마나 손상되었는지 평가

- Noise가 적은 구간(0~15)에는 output과 rationale quality가 stable하게 유지되면서 하락하고 큰 구간(15~)에서는 unstable하게 떨어진다.
⇒ Noise에 따라서 같은 pattern을 보이므로 model이 생성한 output과 rationale은 관계가 있다고 볼 수 있다.
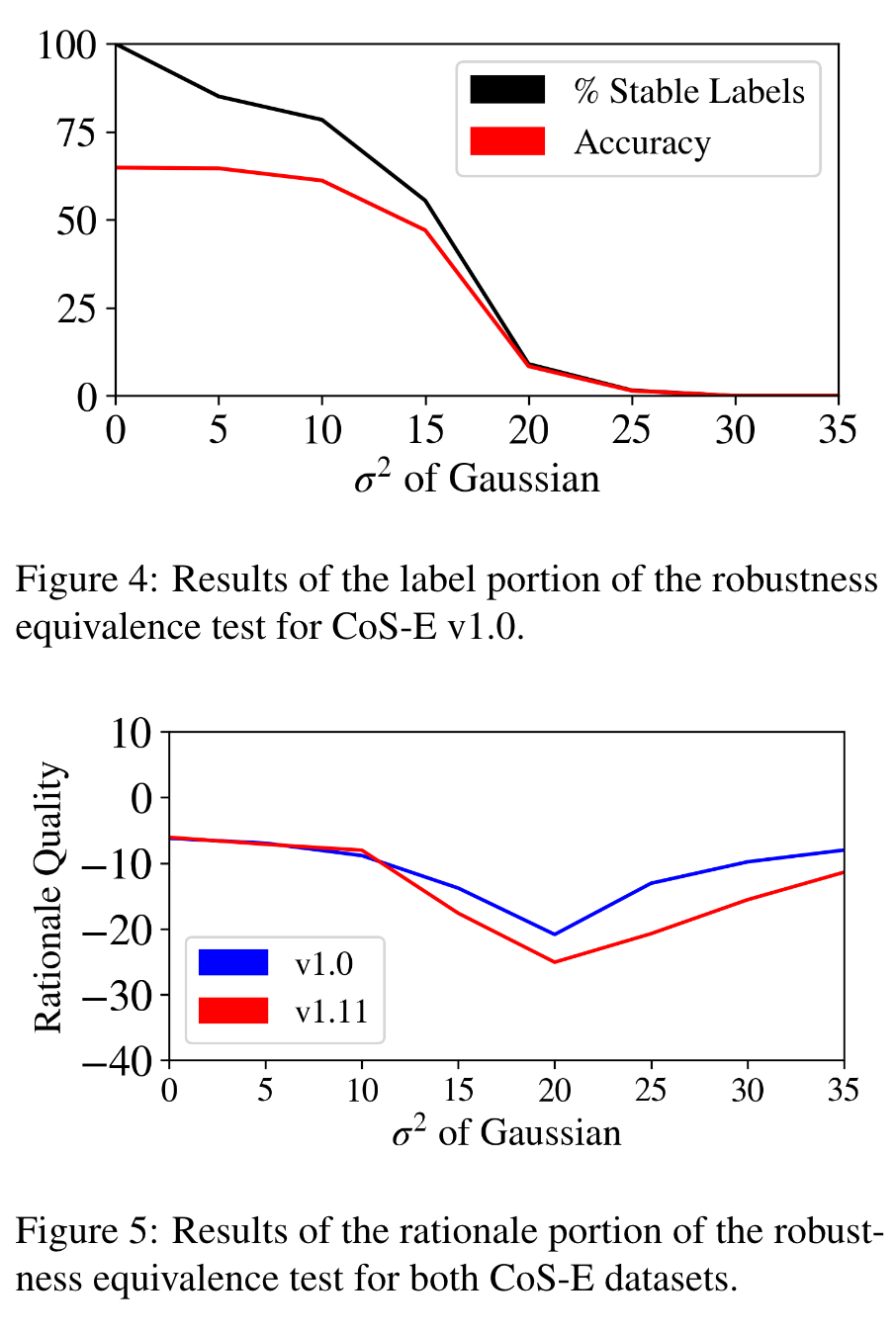
(검은색은 noise를 가해도 prediction이 변하지 않은 output의 비율)
[CoS-E dataset 기준]
→ Feature Importance Agreement
-
output과 rationale이 관계가 있다면 output 예측에 있어서 중요한 input tokens은 rationale 생성에 있어서도 중요함. 반대도 마찬가지 (important input token → output / rationale) [그 정도를 측정하는 과정]
-
중요한 token을 식별했으면, Remove and Retrain (ROAR) occlusion method을 통해 → 중요한 token에 noise가 가해졌으면 output/rationale이 비슷한 패턴으로 망가질 것
-
중요한 token을 어떻게 식별할 것인가?
- Gradient를 활용해서 input token → output / rationale 중요도 측정
: i번째 input token과 p번째 class logit과의 관계 (f=L1 사용)
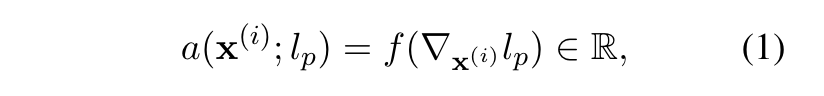
: derivative → taylor series → decoding → output / rationale
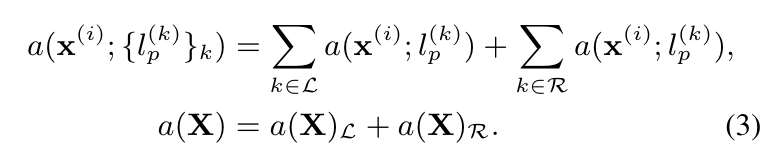
-
Remove and Retrain (ROAR) occlusion method
-
Random Token에 노이즈를 주었을때보다 Input과 관련된 중요한 Token에 Noise를 주고 재학습했을 때 성능 저하가 더 뚜렷함 (Acc)
-
마찬가지로 Random Token에 노이즈를 주었을때보다 Rationale과 관련된 중요한 Token에 Noise를 주고 재학습했을 때 성능 저하가 더 뚜렷함 (Acc)
-
⇒ LM안에서 input token → output / rationale 중요도를 추론할 능력은 있음
- Random Token에 노이즈를 주었을때보다 Input과 관련된 중요한 Token에 Noise & Rationale과 관련된 중요한 Token에 Noise를 주고 재학습했을 때 Rationale Quality 저하 (SNLI dataset에서도 hold)
⇒ (논문에서 이에 대한 해석은 없지만) 당연히 noise가 크면 acc나 rationale quality가 dissimimilair하게 움직이지만 적은 noise하에서는 acc(output)나 rationale quality가 비슷하게 망가짐
⇒ output / rationale의 관계를 보임
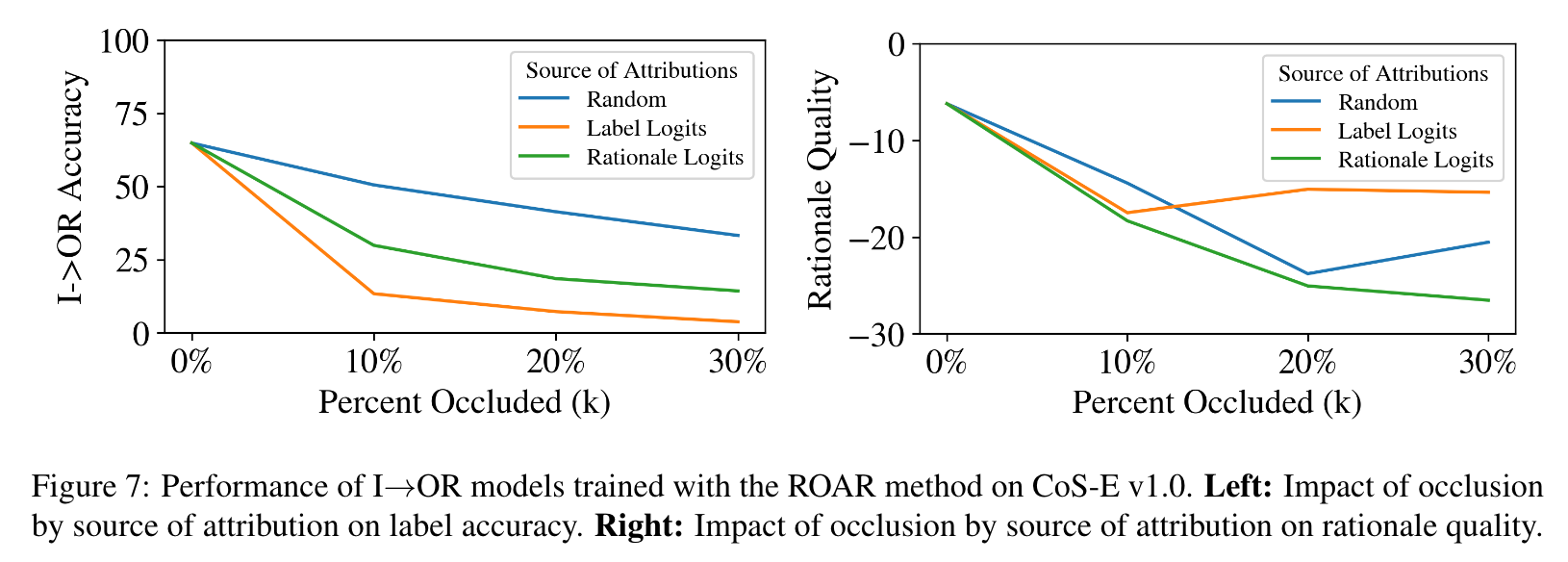
[CoS-E dataset 기준]
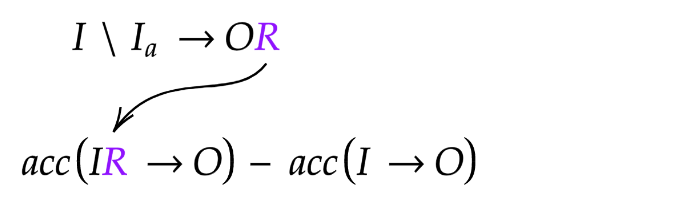
→ 직관적 이해: 노이즈가 섞인 Input으로 만들어진 Rationale로 추정한 Output Acc는 훼손될것
[Figure 오른쪽 Rationale Quality 계산]
Conclusion
→ T5 base model은 faithful한 free-text rationales을 생성하는 능력이 있다.