P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
논문 정보
- Date: 2023-04-13
- Reviewer: 건우 김
- Property: Parameter Efficiency
1. Introduction
-
Prompting: feeze all params of PLM and use natural language prompt to query a LM
-
ex) Sentiment analysis: “Amazing movie!” → “Amazing movie!” + “This movie is [MASK]” choose between (good/bad)
-
Discrete prompting leads to suboptimal performance
-
-
Prompt tuning: tuning only the continuous prompts. (ex. P-tuning)
-
Two problems: Exising works lack of universality of prompt tuning for NLU
-
Model size: P-tuning (Liu et al. 2021) underperforms (less than 10B params)
-
Hard task: poor peformance on Extractive QA task, NER task
-
-
-
Contributions
-
Find proper optimized prompt tuning universally across model size and tasks
-
enable model scales 300M~10B params
-
show comparable performance on Extractive QA, NER task compared to Finetuning
-
-
2. Preliminaries
(생략)
3. P-Tuning v2:
-
Lack of universality
-
scale: (Lester et al. 2021) 준원 → poor performance when model size is (100M~1B)
-
tasks: (Liu et al. 2021) P-tuning → perform poorly on typical sequnce tagging tasks
-
-
Deep prompt tuning
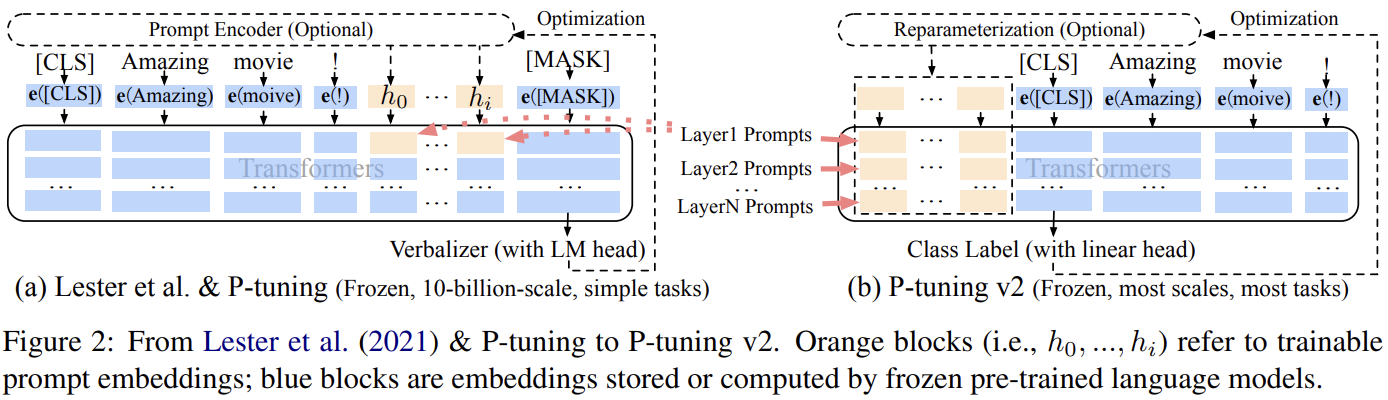
-
Existing problem → figure (a)
-
number of tunable params is limited due to the constraints of sequence length
-
input embeddings have relatively indirect impact on model prediction
-
prediction하는 LM head와의 거리가 너무 멀어서라고 추측
-
-
Proposed method → figure (b)
-
Prompts in different layers are added as prefix tokens
-
Can have more tunable params
-
have more direct impact** **on model predictions
-
-
-
Optimization and implementation
-
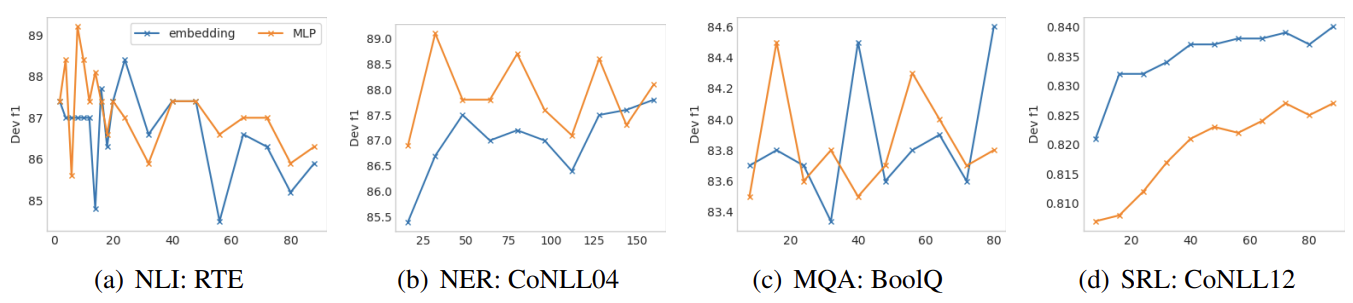
Reparameterization
-
Prior works usually use a reparameterization encoder using MLP to form trainable embeddings → but its performance depends on tasks/datasets
-
RTE/CoNLL04: MLP brings a consistent improvement
-
BoolQ/CoNLL12: MLP leads to negative effects
-
-
-
→ 저자가 주장하는 바와 다르게 일관성 있는 result가 보이지는 않지만, MLP를 사용하는 것이 꼭 좋은 것은 아니라는 것을 확인할 수 있음. (이래서 grpah를 appendix에 뺐는지..)
-
Prompt Length
-
Length affects the performance
-
Simple classification task → prefer shorter prompts (less than 20)
-
Harder sequence labeling task → prefer longer prompts (around 100)
-
-
-
Multi-task Learning
-
Optmize multiple task (pretraining) before fine-tuning for individual tasks
-
여기서 언급하는 pretraining은 finetuning하기 직전 단계에 학습 단계
-
multiple task는 서로 다른 task는 아니고, 하나의 task에서 다양한 dataset을 지칭
- ex) SRL task: combine CoNLL05, CoNLL12
-
-
Boost performance
-
-
**Classification Head **
- Prior works usually use LM head to predict verbalizers → unnecessary in full-data and incompatible with sequence labeling
-
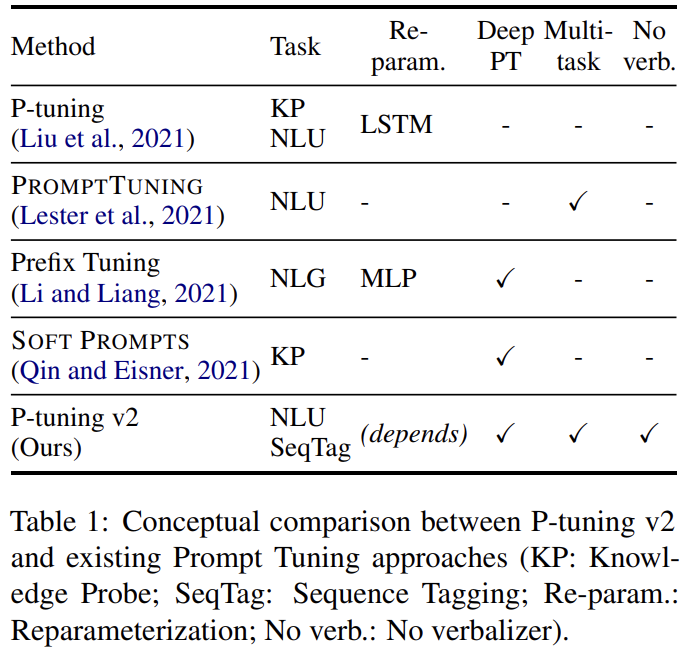
Compared to other methods
4. Experiments
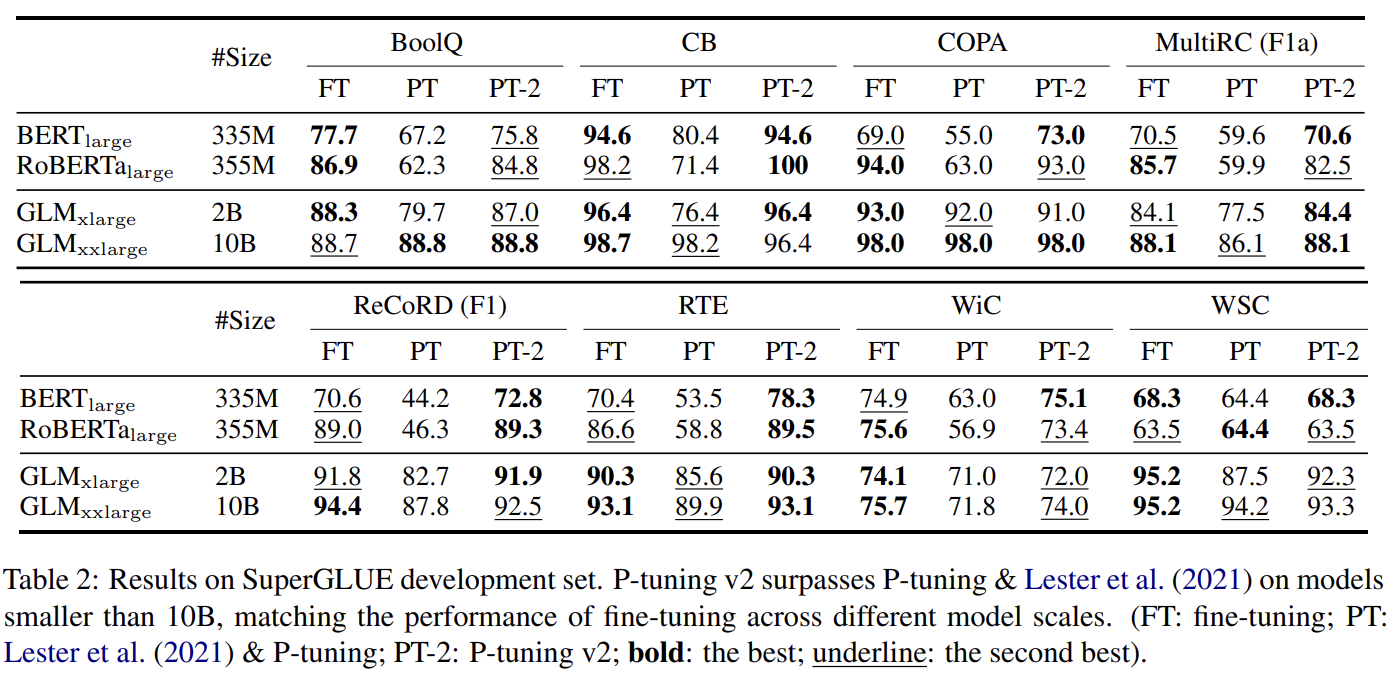
- Across scales
-
Small models (BERT/RoBERa)
-
P-tuning at smaller sclaes show poor performance
-
P-tuning v2 matches the finetuning performance in all tasks at a smaller scale
-
-
Large models (GLM)
-
Gap between finetuning and PT/PT2 is gradually narrowed down
-
P-tuning v2 is alwasys comparable to finetuning at all scales only using 0.1% task-specific params
-
-
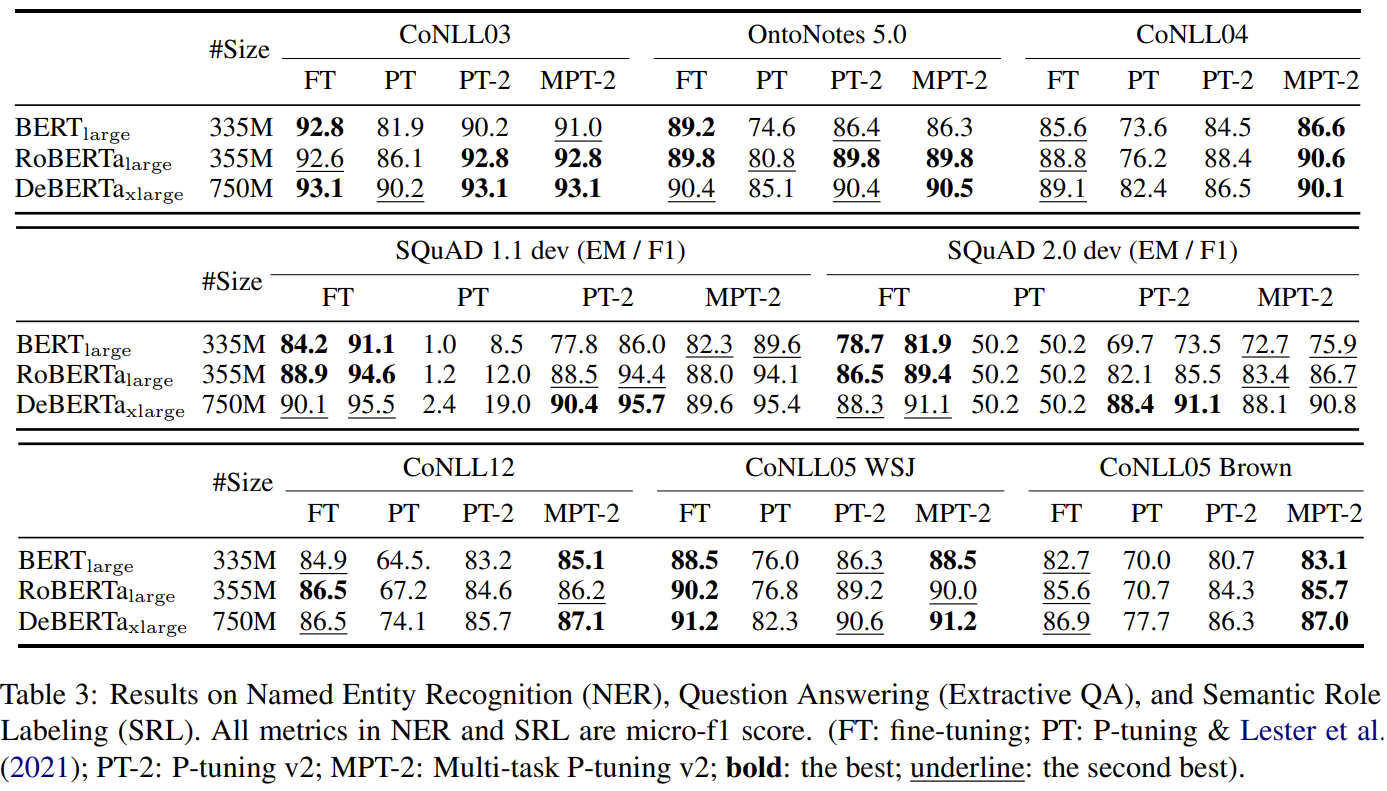
Across Taks
-
MTL boosts P-tuning v2
-
QA task: P-tuning shows extremely poor performance (BAD!)
-
Ablation studies
- [CLS]+LM-head vs Verbalizer+LM-head
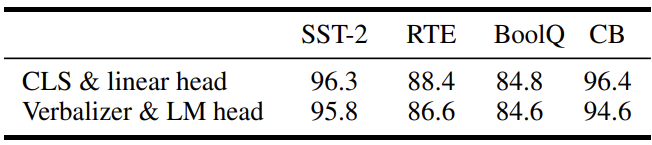
→ Results indicate there is no significant difference (verbalizer는 귀찮으니 CLS쓰자)
- Prompt depth
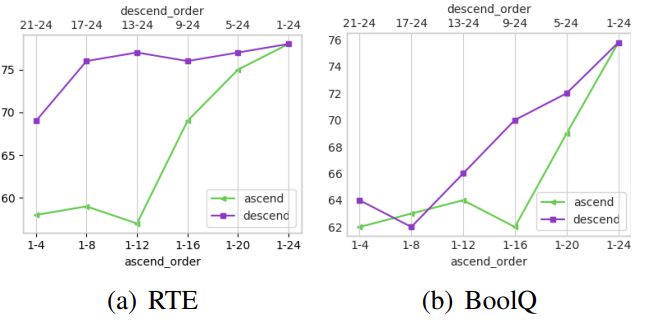
- Deeper is good
- Order
- Ascend: RTE랑 BoolQ 비슷한 trend
- Descend: RTE에서 17-24만 해도 성능 비슷
5. Code & Results
-
Code
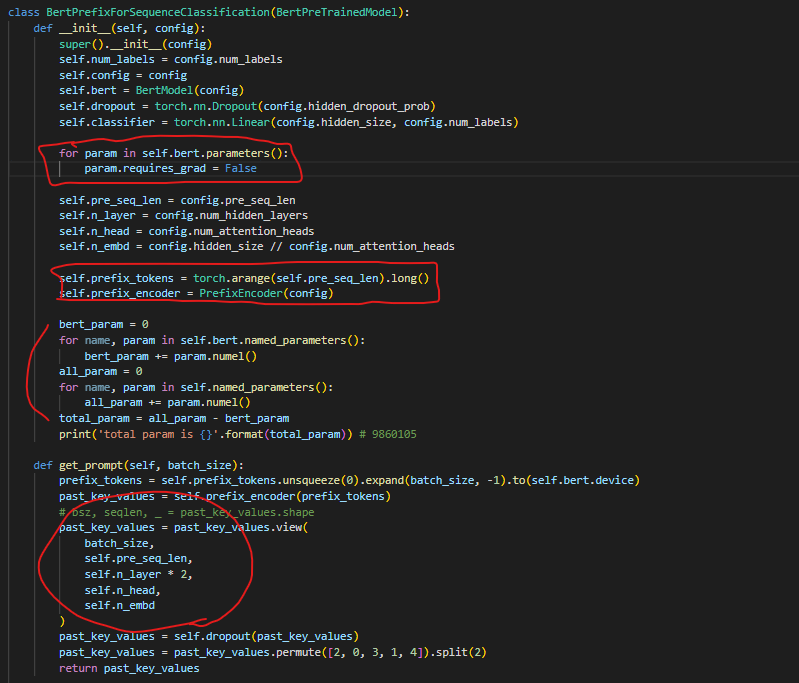
- PrefixEncoder는 동일하게 사용
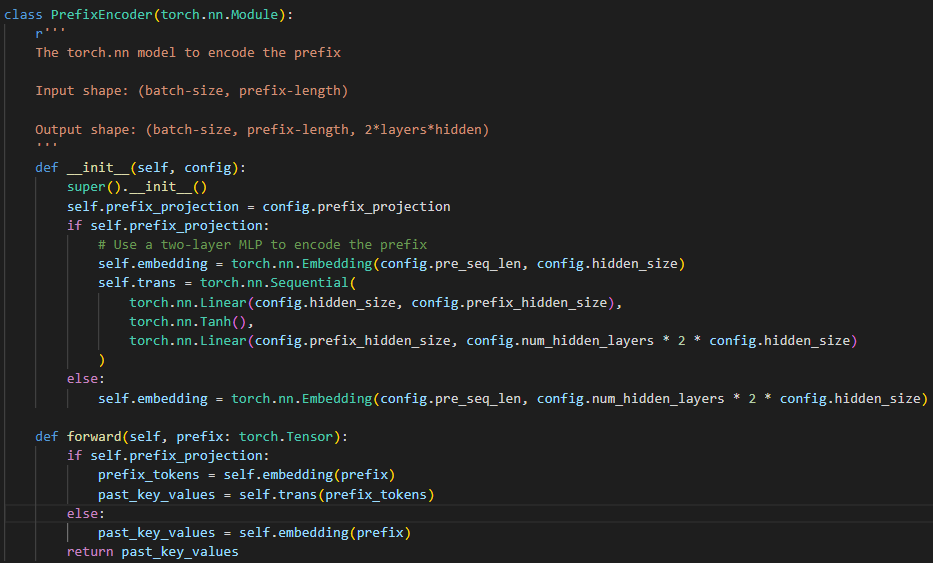
-
Deep Prompt Tuning (all layers에 적용)은 downstream task를 training할 때, 사용
-
self.prefix_encoder가 한번에 모든 layer에 prompts를 생성
-
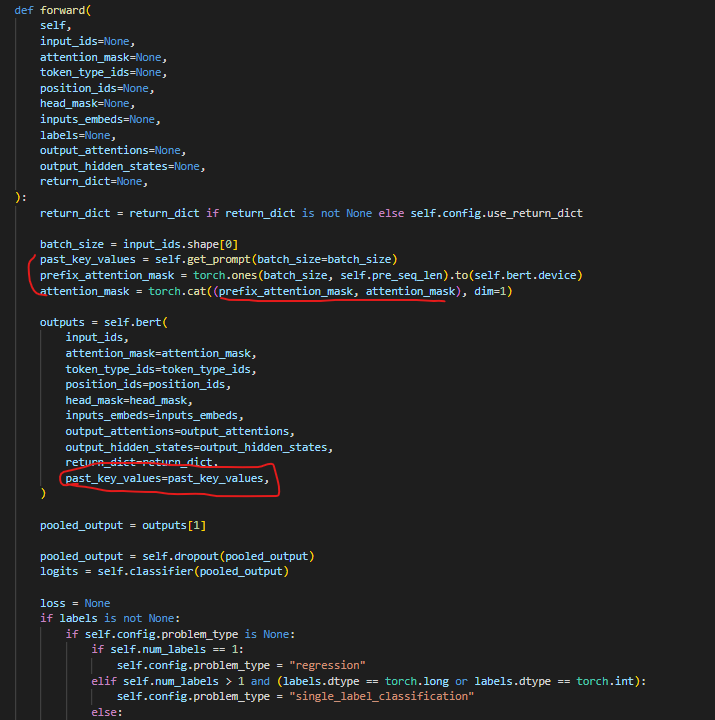
생성된 prompts는 past_key_values를 통해 BERT로 전달
- 저기서 선언하는 past_key_values는 이전 청크(생성된 prompts)에서 계산된 self-attention 값을 저장하는데 사용
-
→ 저기 past_key_values shape에서 ‘n_layer*2’를 2로 split하는게 key, value 각각을 나타내기 위함이라고 생각했는데, 저자가 말하기로는 아닌 것 같 질문 드리고 싶습니다..

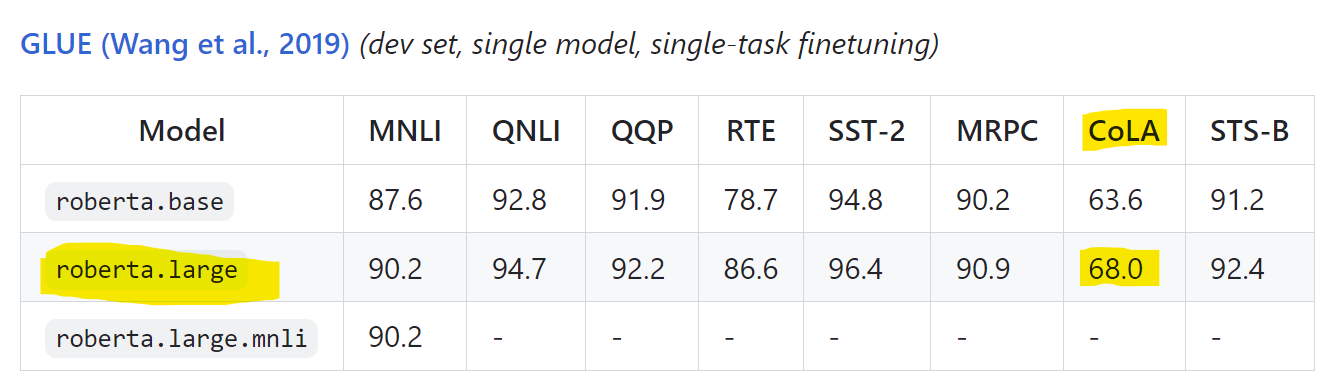
- CoLA results
비슷하게 나옴