Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
논문 정보
- Date: 2023-05-25
- Reviewer: 건우 김
- Property: LLM, ICL
Abstract
Large language models (LLMs)들이 in-context learning을 통해 downstream task에서 좋은 성능을 보인다는 사실은 유명하지만, model이 어떻게 _**학습을 하고 **_어떤 점을 통해 성능을 내는지 확인하는 연구는 거의 없다. 본 논문에서 다양한 실험을 통해 처음으로 LLMs의 in-context learning이 어떻게 _**그리고 **_왜 작동을 하는 지에 대해서 수많은 실험을 통해 보여준다.
-
Key Aspects
-
Label spcae
-
Distribtuion of input text
-
Overall format
-
Introduction
- LLMs은 few input-label pairs를 가지고 In-contex learning (ICL)을 통해 downstream tasks에서 꽤나 높은 성능을 보여줬지만, ICL이 왜 작동하고 어떻게 작동을 하는 지에 대한 연구는 거의 없다.

-
ground turth demonstration이 실제로 ICL에 효과적이지 않음을 실험적으로 보임
- Labels in demonstration을 random labels로 바꾸어도 classification과 multi-choice task에서 성능 하락이 거의 없음. → Model은 task를 수행하는 것에 있어 input-label mapping에 크게 의존하지 않.
-
Demonstations의 어느 부분이 performance에 직접적인 기여를 하는지 알아보는 실험을 진행
-
Label space와 demonstration을 통해 특정된 input text의 distribution이 ICL에서 되게 중요한 역할을 함 (각각의 inputs에 대해 label이 올바른 것과 상관 없이)
-
Overall format은 중요함.
-
label space가 unknown일 때, label을 사용하지 않는 것 보다 random한 English 단어를 label로 사용하는 것이 더 좋음 → format 자체를 갖출 수 있
-
ICL을 objective function으로 두고 학습을 하는 meta-training은 (1)과 (2)에서 언급한 점들을 극대화 시킴.
-
MetaICL (Min et al., 2021)
-
-
본 논문에서 ICL에 사용되는 demonstration의 역할에 대해 이해하는 분석을 제시함.
Related works
-
LLMs, ICL 내용 생략
-
본 논문에서 처음으로 ICL이 zero-shot 보다 왜 성능이 좋게 나오는지 실험적으로 분석함
Experimental Setup
- Models: 6 종류의 LM을 사용함 (only-decoder model)
-
Inference method (Min et al., 2021) 2개 사용해서 총 12개의 models을 실험에 사용
-
Direct: 우리가 흔히 알고 있는 방법. 출력을 추정하는 것에 초점을 둠
-
Channel: Bayes Rule을 통해 input과 label의 순서를 뒤집어 인과관계 파악
-

-
Evaluation data: 26가지 datasets에 대해 평가 진행
-
(Sentiment analysis, paraphrase detection, NLI, hate speech detection …)
-
dataset 선정 기준
-
low-resource dataset with less than 10K training examples
-
연구에 많이 사용된 GLUE and SuperGLUE
-
다양한 domains
-
-
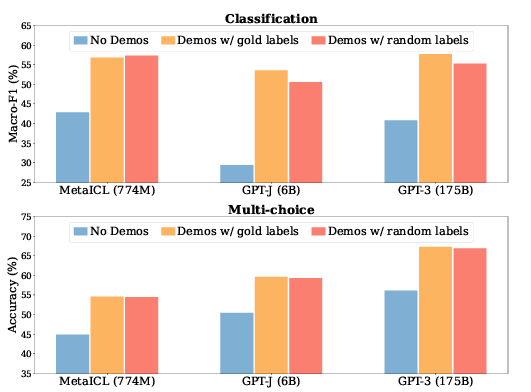
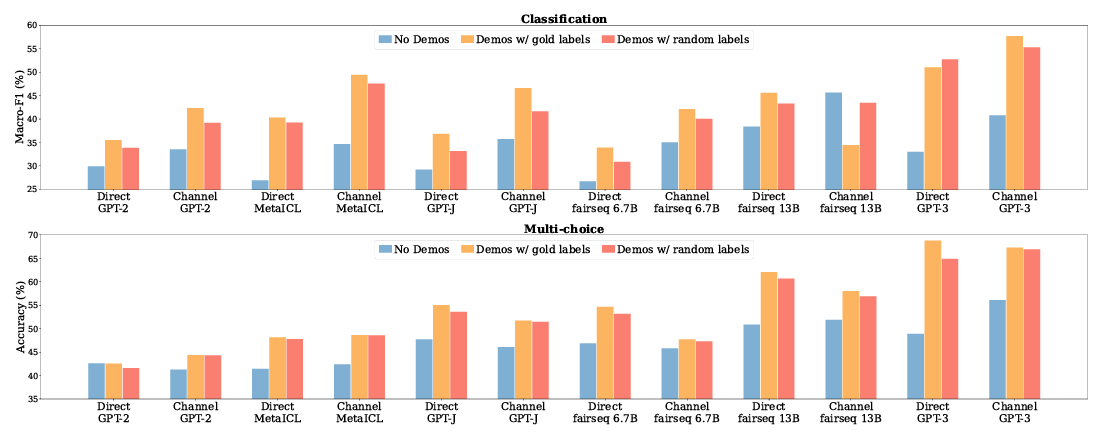
1. Ground Truth Matters Little
Gold labels vs Random labels
-
No demonstrations: zero-shot setting
-
Demonstrations w/ gold labels: ICL with *k *labeled examples
-
Demonstrations w/ ranodm lables: ICL with k labeled examples (gold → random labels), 여기서 사용한 random labels이란 gold label과 동일한 set을 공유하고 있음. (완전 random 아님x)
-
Results and analysis
-
Demonstrations w/ gold labels (Yellow)는 No demonstrations (Blue)보다 항상 성능이 높음
-
Labels을 random (Orange)과 Labels을 gold (Yellow)를 비교하면 비슷한 성능
-
→ GT input-label pairs는 performance gain에 있어 필수적이진 않음
→ 위 실험은 uniform sampling으로 random label을 뽑은 건데, true labels의 distribtuion에서 random하게 추출하면 성능의 간극을 더 줄
→ label space를 공유하기 때문이라고 생각
- MetaICL은 0.1~0.9% 성능 하락만 있었는데, ICL을 목적 함수로 meta-training 시킨 것이 input-label mapping을 무시하 demonstrations의 다른 요소에 있어 영향을 받음
Ablations
-
Does the number of correct labels matter?
-
Demonstrations w/ a% correct labels (0≤a≤100)
-
Correct pairs: k x (a/100)
-
Incorrect pairs: k x (1-a/100)
-
a=100 → equal to ICL (demonstrations w/ gold labels)
-
-

-
Result and analysis
-
실험 결과를 확인해보면 number of correct labels in demonstrations은 크게 중요 X
-
GPT-J (Classification task) 경우에서는 10% 넘게 하락이 있긴 하지만, 대체로 비슷한 양상을 보임
-
No demonstrations보단 그래도 incorrect labels이 항상 좋음
-
-
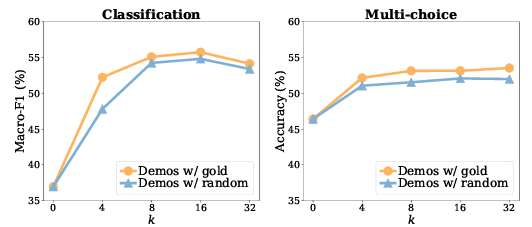
Is the result consistent with varying k?
- input-label pairs의 개수 ‘k’를 바꿔 감에 따라 실험을 진행
-
k가 4개일 경우만 보아도 No demonstrations (k=0)보다 성능이 좋음
-
k가 8을 넘어서면 examples의 개수가 많아져도 performance 개선이 없음
- 일반적인 sft 상황과 다른 양상을 보
-
Is the result consistent with better templates?
-
minimal template을 default로 사용했지만, manual template을 적용해서 비교실험 진행
-
minimal template: input의 단순 conatenation
-
manual template: dataset-specific 방식으로 작성한 방식
-
-


-
manual tempaltes을 사용하는 것이 항상 minimal tempalte 보다 좋지는 않음
-
Gold labels → Random labels로 변경할 때, 성능 하락 폭이 작은 trend는 비슷하게 보임
-
- No demonstrations보다 random labels이 더 좋은 trend도 비슷
-
2. Why *does *In-Context Learning work?
- 위에 실험에서 demonstration에서 GT input-label이 ICL의 performance gain에 큰 영향이 없는 것을 보여줌. 이번 실험에서 demonstrations에서 다른 어떤 요소들이 ICL의 performance gain에 영향을 주는지 확인.

-
Demonstraion의 4가지 aspects
-
Input-label mapping: input xi가 label yi와 올바르게 pair인지
-
앞에서 다룬 내용이지만, 이것도 aspect 중 하나로 보고 변인 통제 진
-
Distribution of input text: x1~xk의 distribution
-
Label space: y1~yk의 space
-
Format: the use of input-label pairing as format
-
Impact of the distribtuion of the input text
-
out-of-domain distribtuion demonstrations 상황에서 실험
-
demonstration에 사용되는 k개의 x들을 아예 다른 corpus에서 샘플링해서 사용
-
Demonstration의 label space와 format은 유지하며 input text의 distribtuion만 바꾸며 이에 대한 impact 평가
-
-
Results
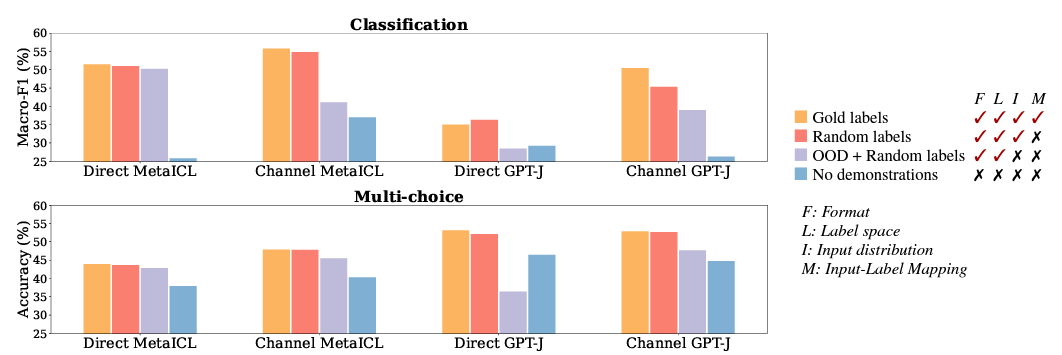
-
Orange bar랑 Purple bar만 비교해보면, OOD input을 사용할 때 큰 성능 하락을 보임
- GPT-J 경우에는 No demonstration보다 낮은 성능
-
Demonstrations의 in-distribtuion input은 performance gain에 큰 영향을 끼침
- 근데, 너무 당연한 소리 아닌가 싶음. (분류 문제를 푸는데, 쌩뚱 맞은 text를 가져와서 example로 보여주면 성능하락이 당연히 있지 않을까..근데 그 당연할 걸 또 실험으로 보여주니 역시 대단함 😀)
Impact of the label space
-
k개의 labels을 random한 English word를 사용해서 실험을 진행함.
-
원래의 label space 크기와 English word의 label space 크기는 동일하게 설정
-
전체 English word space에서 random하게 label 추출하며 demonstration 구축
-
→ 여기서도 역시 input text 및 format은 유지
- Results
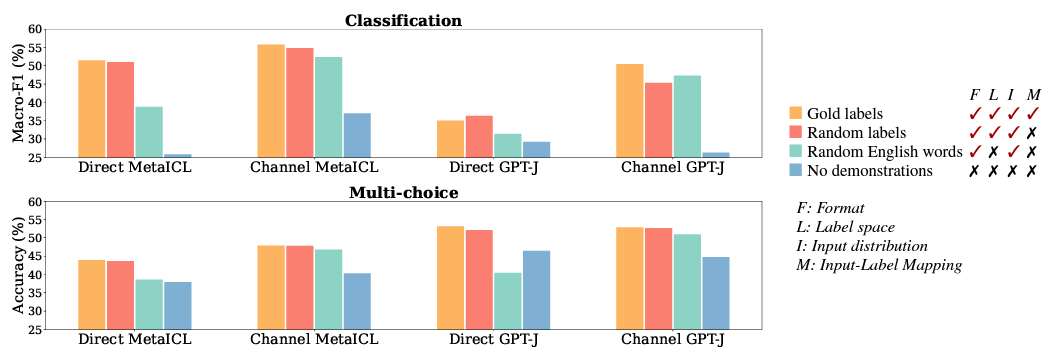
-
Orange bar와 Green bar를 비교
-
**Direct-models : P(y x)** - random label을 사용할 때와, random Enlgish words를 사용할 때의 성능 차이가 명확함
-
**Channel-models : P(x y)** -
random label을 사용할 때와, random Enlgish words를 사용할 때의 성능 차이가 미미함
-
Channel-models이 label을 condition으로 두기 때문에, label space를 아는 것에 있어 gain을 얻을 수 없다고 함. great!
-
Impact of input-label pairing
-
Format의 형태를 바꿔가며 실험을 진행함. inputs과 labels의 pairing을 없애는 식으로 작은 변화만 줘서 format의 형태를 바꿈.
-
Demonstrations with no labels: concatenation of x1~xk
- Demonstrations with random English words의 format이 없는 경우와 대응
-
Demonstrations with labels only: concatenation of y1~yk
- Demonstrations with OOD inputs의 format이 없는 경우와 대응
-
-
Results
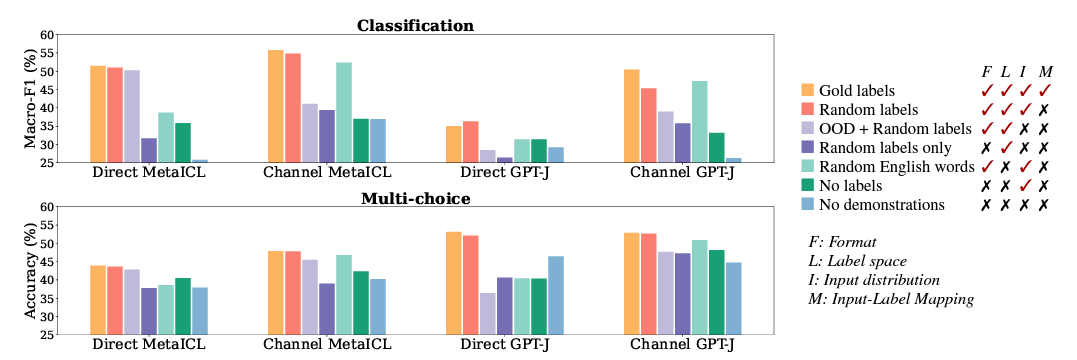
-
Format의 형태를 바꾼 경우 → **진보라 **bar(label만 존재), **진녹색 **bar(input만 존재)
-
Format을 유지하는 것은 중요하다.
-
연보라 vs 진보라: (Format vs label은 있지만 input text x가 없는 경우)
-
연녹색 vs 진녹색: (Format vs input text은 있지만 label y가 없는 경우)
-
-
Format을 없애면 No demonstration보다 낮은 성능을 보임
- 다른 case보다 Format을 없애는 것이 가장 큰 성능 하락을 보임
Impact of meta-training
-
다른 models들과 다르게 MetaICL은 ICL을 목적 함수로 두어 학습시킨 모델이다.
- MetaICL: 학습은 large collection of supervised dataset을 통해 multi-task learning으로 진행하고 Inference는 ICL과 동하게 진행함. (Unseen task에 대해서 generalizability를 높이기 위해 제안된 model)

-
위에 진행한 실험에서 MetaICL의 두드러진 몇 가지 특징이 보임
-
Format을 유지하는 것이 다른 models에 비해 더욱 중요
-
GT Input-label mapping이 다른 models에 비해 덜 중요
-
→** meta-training encourages the model to exculsively exploit simpler aspects of the demonstrations and to ignore others**
- 이에 대해 저자들의 생각은 다음과 같음
1. input-label mapping을 사용하는 것은 어렵다
1. format을 사용하는 것은 비교적 쉽다
1. model이 생성하도록 학습한 text의 space는 model이 condtion으로 둔 text의 space보다 사용하기 쉽다
→ Direct model이 input distribtuion보다 label space를 잘 이용하고
→ Channel model이 label space보다 input distribution을 잘 이용한다
(이것도 당연한 얘기가 아닌가..그치만 대박 😃)

Discussion
Does the model learn at test time?
-
Learning의 대한 엄밀한 정의를 다음과 같이 두면, ‘caputring the input-label correspondence given in the training data’
-
LMs은 test 시에 새로운 task를 학습하지는 않는다.
-
저자들은 model이 demonstration에 언급된 task를 무시하고 pretraining에 사용된 prior를 사용하는 것과 같다고 생각함.
-
-
Learning을 넓은 의미로 해석하면
-
특정 input과 label의 distribtuions과 특정 format을 demonstration에 잘 녹여낼 때, model의 prediction 결과는 더 정확해질 수 있고, 이는 model이 demonstration을 통해 새로운 task를 학습한다고 볼 수 있음.
-
test 시에 demonstration을 잘 구축하는 것이 새로운 task라고 보기보다는 사전학습된 weights를 잘 이용하는 것이니, 이것 역시 pretraining에 사용된 prior를 사용하는 거 아닐까?
-
Capacity of LMs
-
model은 input-label demonstration에 의존하지 않으며 downstream task를 수행한 것을 실험에서 보임. 이를 통해 input-label correspondence 자체를 langauge modeling (pretraining)할 때 학습을 한 것으로 볼 수 있음.
-
이는 langauge modeling 목적 함수가 zero-shot 성능의 주역이라고 봄
-
반면에, ICL은 LM에서 학습하지 못한 input-label correspondence task는 수행할 수 없다고 봄. ICL이 풀 수 없는 NLP 문제들을 어떻게 발전시켜야 될 research question을 질문함.
-
→ 이 점 역시 LM의 knowledge(task) injection 및 update와 관련이 있다고 생각
Connection to instruction-following models
-
(Instruction) natural language로 문제 설명을 설명하면 inference 과정에서 새로운 task를 수행 할 수 있다는 이전 연구들이 존재. → Demonstrations과 Instruction은 LM에게 있어 비슷한 역할 수행
-
Instruction은 model로 하여금 model 갖고있는 capacity를 끌어올리는 것을 촉진 시킬 수는 있지만, 새로운 task를 학습 시키지는 못함.
###