SILO LANGUAGE MODELS: ISOLATING LEGAL RISK IN A NONPARAMETRIC DATASTORE
논문 정보
- Date: 2023-09-12
- Reviewer: 김재희
- Property: LM, Retrieval, Domain Adaptation
1. Intro
-
Pretrained LM의 Domain Adaptation 능력을 평가
-
학습 데이터 및 Retrieve-and-Augment 방법론에 따라 Domain 별 성능 평가 진행
-
논문에서 제기하는 RQ : 저작권, 보안 이슈에서 자유로운 LLM을 학습/이용하는 상황을 가정할 때, Inference 성능 극대화할 수 있는 방법은 무엇일까?
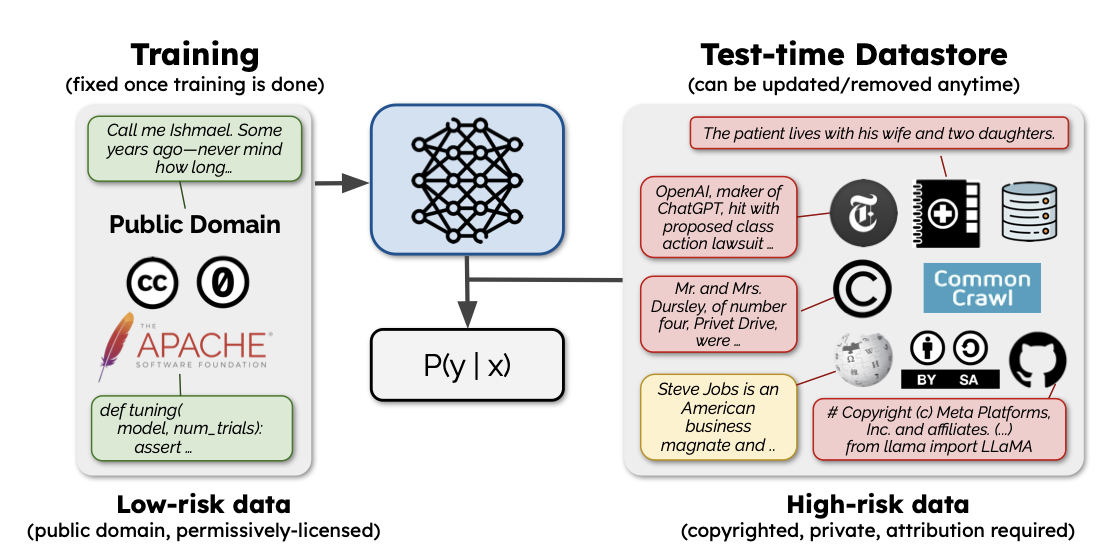
2. Problem Setup
-
기존의 Pretrain Corpus 수집 방법 : 저작권에 대해 비교적 큰 신경 X
-
최근의 Pretrain Corpus 수집 방법 : 법적 문제(저작권)에 자유로운 수집이 점차 부상하고 있는 문제점
저작권을 고려한 Pretrain Corpus 수집이 문제가 되는 이유?
-
저작권을 고려하는 순간(low legal risk) 수집할 수 있는 데이터의 크기와 도메인이 제한되게 됨
-
작은 크기와 제한된 도메인은 LM의 Domain Generalization 능력을 저하할 수 있음
- Domain : 코드 생성, 뉴스 분야, 수학, 논문 등
-
LLM의 수익화 시 현실적으로 발생 가능한 가장 큰 문제점 중 하나
저작권이 중요한 데이터(high legal risk) 활용 방안
-
논문에는 해당 시나리오의 구체적 예시가 주어져 있지는 않음
-
단순히 high legal risk 데이터를 추론 시점에 활용가능할 경우를 가정
-
(재희) : 모델 훈련과 사용 주체가 다를 경우 발생 가능한 시나리오
-
학습 주체 : 네이버
-
모델 훈련 능력 및 인프라가 갖추어져 있으나, 특정 도메인 or legal risk가 있는 데이터를 확보할 수 없는 주체
-
증권사 내부 리포트에 대한 데이터 확보 불가 or 저작권 문제 해소 불가 → 증권 데이터를 Pretrain Corpus에 포함할 수 없음
-
-
사용 주체 : 토스
-
모델 사용하고자 하는 고객사
-
사내 데이터로서 증권 리포트 데이터 사용 가능 but 모델이 학습하기를 원치 않는 상황
-
-
→ 외부 유출 등에 대한 우려
⇒ 어떻게 하면 모델이 증권 리포트 데이터에 학습되지 않고도, 증권 도메인에 대한 충분한 능력을 확보할 수 있을까?
3. Datasets & Pretrained Models
- PLM의 학습 도메인 or risk를 엄격히 통제하기 위해 다양한 버전의 데이터로 모델을 pretrain함
도메인 별 데이터셋
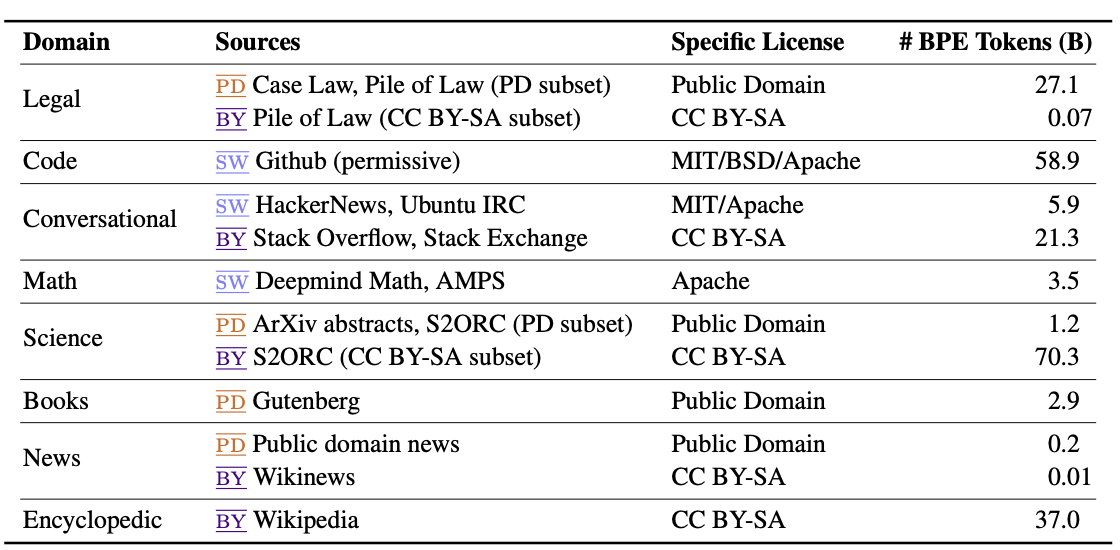
-
각 도메인 별 copyright이 다양하게 분포
-
각 도메인 및 copyright 별 데이터 크기(BPE Tokens)가 다양
⇒ 다양한 도메인을 반영하면서 copyright을 고려하는 것은 매우 어려운 작업
Copyright 별 데이터셋
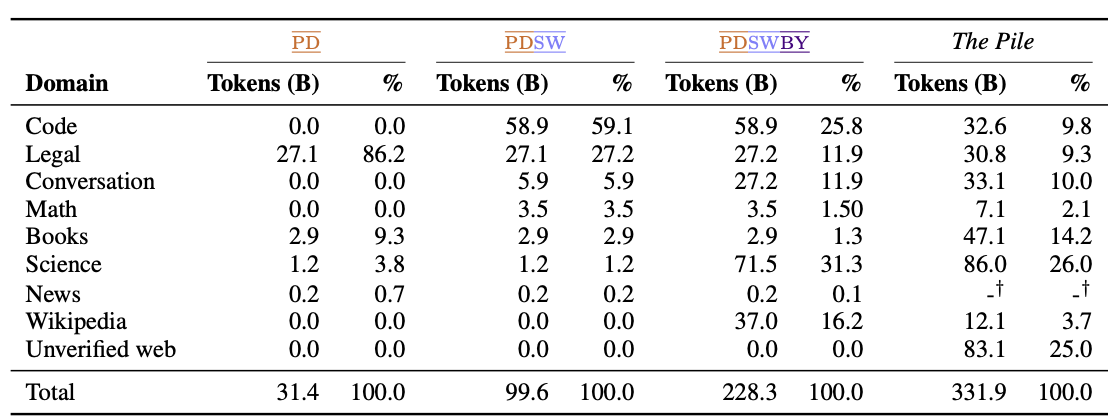
-
copyright 유형을 3가지로 구분
-
PD(Public Domain) : 저작권에 대한 우려가 전혀 없는 완전 공개 데이터. 가장 손쉽게 활용 가능
-
SW(Permissively Licensed Software) : 저작권에 대한 제한이 매우 소극적인 데이터. Apache 라이센스 등 활용에 있어 제한은 없으나 저작권 조항이 유지되어야 하는 특징이 있음.
-
BY(Attribution License) : 활용에 제한은 없으나, 저작권은 원저작자에게 귀속되는 데이터. 모델 활용 관점에서는 BY 데이터가 학습에 사용된다면, 생성문이 원저작자에 귀속되는 문제가 발생
-
⇒ 본 논문에서는 학습에 사용 X
-
카피라이트 별 데이터 분포 특성 (재희)
-
PD : 매우 제한된 도메인과 불균형한 분포를 보임
-
Legal : 공문서 중심의 데이터셋으로 대부분 차지
-
Books, Science : 논문 및 예전 서적 중심으로 일부 차지
-
-
PD,SW : 일부 완화된 분포를 보이면서 Code가 매우 많은 데이터 차지
-
PD와 비교하여 SW의 데이터가 매우 많이 차지
-
Code 데이터가 매우 많이 늘어났기 때문 → open-source의 특성
-
-
PD,SW,BY : 데이터가 매우 많은 상황, 분포가 더욱 완화
-
Conversation : Stackoverflow 및 Reddit 등 제한된 소스에서 매우 많은 데이터 확보 가능
-
Science : 논문 데이터를 arxiv와 Semantic Scholar에서 확보, 매우 많은 데이터 확보 가능
-
-
PILE : web crawling 데이터로서 저작권 구분없는 데이터 수집 방법
-
전체 데이터 크기가 PD,SW,BY 대비 50% 증가된 모습
-
저작권을 신경쓰지 않는 순간, 일반 평서문(books, news)가 대폭 증가된 모습 관찰
-
저작권을 신경쓰지 않기 때문에 데이터 출처가 불분명해짐
-
-
→ News 데이터가 상당수 존재함에도 얼마나 존재하는지 확인할 수 없음
Pretrained LM
3가지 데이터 상황 별 LLM을 학습 및 평가 진행
-
모델 구조 : LLAMA 구조 그대로 활용
-
모델 크기 : 1.3B
-
비교 모델 : Pythia (PILE 데이터로 학습된 1.3B 모델)
- 대부분의 데이터가 high-risk data
-
모든 모델이 비슷한 Compute을 소요하여 훈련
모델 별 PPL 평가 결과
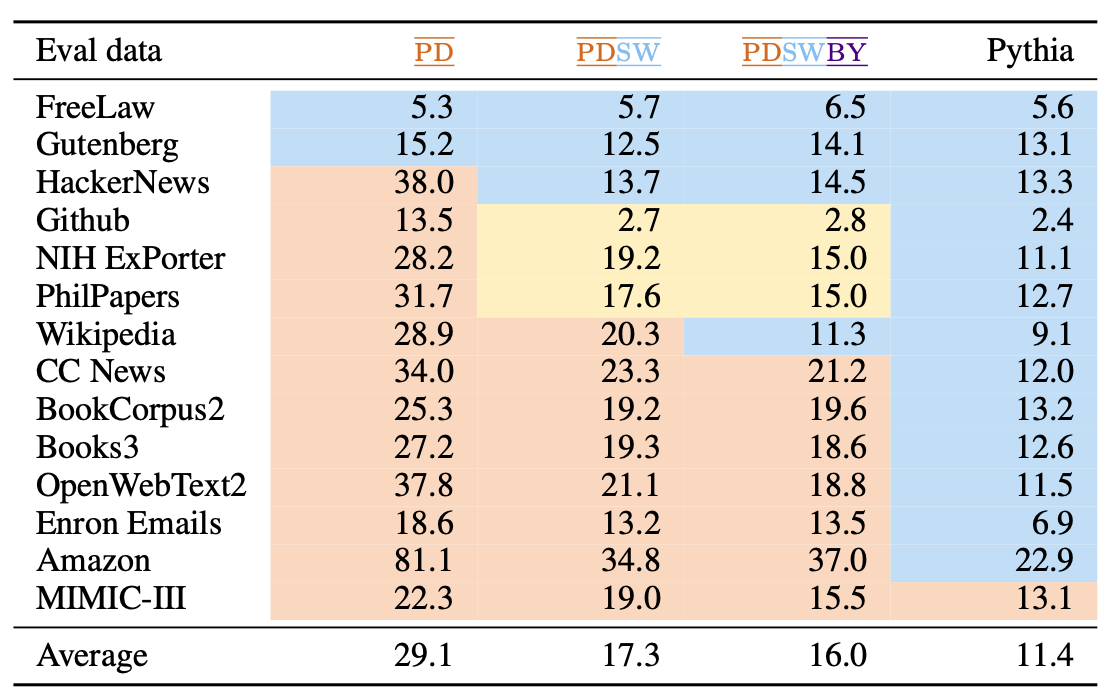
-
파란색 : in-domain/노란색 : out-of-domain but trained on relevant data/빨간색 : out-of-domain
-
in-domain : 모든 모델이 in-domain에서 우수한 성능을 보이고 있음
- (재희) 데이터의 크기가 작더라도 (PD) 충분히 in-domain에서 좋은 성능을 보이고 있음
-
노란색 : out-of-domain임에도 완전한 ood(빨간색) 대비 좋은 성능을 보이는 모습
- 특정 도메인(코드)에 대해서는 in-domain과 거의 유사한 성능 도달
-
MIMIC-III : 의료 도메인 데이터, 모든 모델의 성능이 좋지 못한 모습
- 데이터의 크기가 커질수록 ood에 대한 성능 역시 좋아지는 모습을 보이고 있음
⇒ 학습 데이터와 평가 데이터 간의 n-gram overlap 지표와 ppl 지표가 매우 높은 상관관계(-0.72)를 보이고 있음
⇒ 학습 데이터와 평가 데이터 간의 Domain 일치 여부가 성능에 큰 영향을 미침

4. Augmented Methods
- OOD 도메인의 성능을 높이기 위해 KNN-LM과 Retrieval-In-Context LM (Augmented-LM, RIC LM) 두가지 방법론 이용
KNN-LM
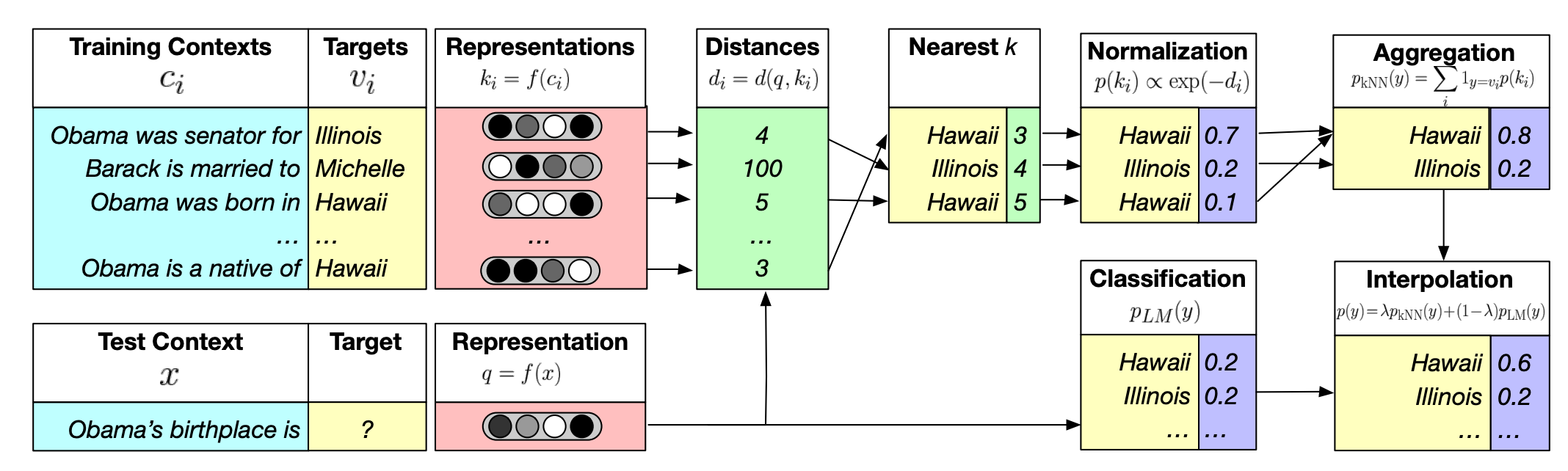
-
test 도메인의 훈련 데이터를 datastore로 설정하고, Retrieval과 생성을 Fusion하는 방법론
-
모델의 context vector를 key, 토큰을 value로 하여 생성 확률을 보정하는 방법론
-
LM의 OOD 성능을 끌어올릴 수 있는 방법론으로 알려져 있음
-
Retrival 과정에서 구해진 각 토큰과의 거리와 실제 모델의 생성 확률을 가중합하여 최종 생성확률 결정
Retrieval의 확률 변환 과정
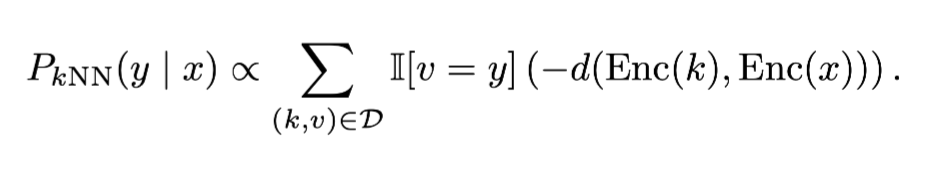
최종 생성 확률
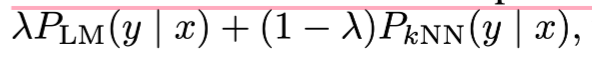
RIC LM
-
test 도메인의 훈련 데이터를 datastore로 설정하고, Retrieve된 text를 In-Context Learning으로서 활용하는 방법론
-
Retriever : BM25, OOD Retrieval 시 가장 안정적인 성능을 보이는 방법론이기 때문에 선택한듯.
-
ICL 시 사용되는 모든 M개의 Retrieved Text는 단순 concat을 통해 활용
5. Experiments
Augmented Methods 적용 시 성능 변화
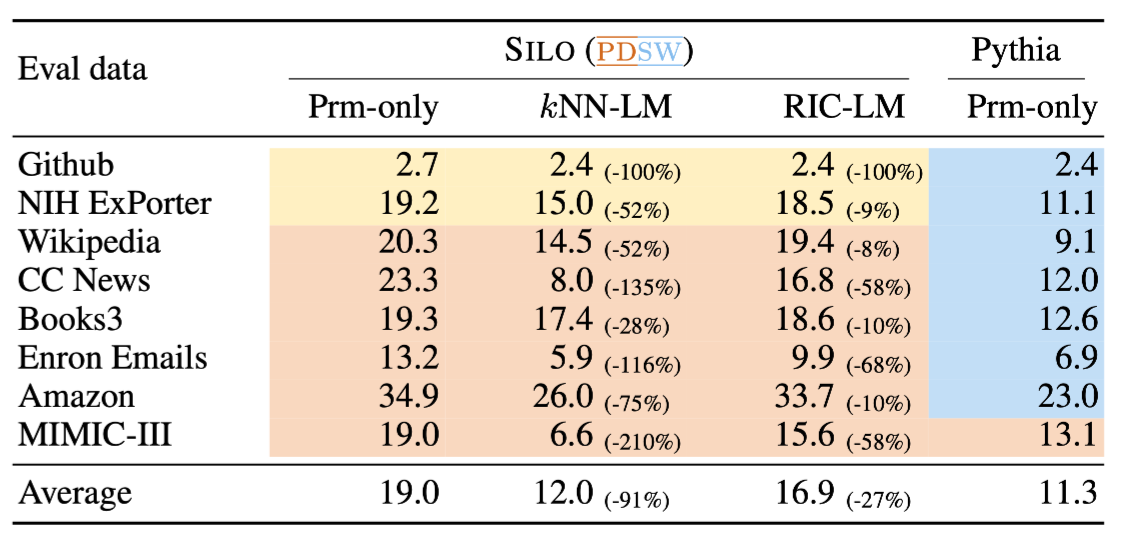
-
기존 LLM에 Retrieval 모듈 추가 시 일관된 성능 향상 기록
- OOD라 하더라도 Retrieval을 통해 성능 향상 가능
-
Pythia(In-Domain)과 성능 격차가 줄어드는 모습을 확인 가능
-
완전한 OOD(MIMIC-III) 의 경우에 더욱 큰 성능 향상을 기록하면서 Pythia보다 좋은 성능 기록
Data Store 크기 별 성능 변화
-
Data Store : Retrieval 대상이 되는 Train 데이터
-
Data Store의 크기를 변화하면서 두 방법론의 성능 변화 관찰
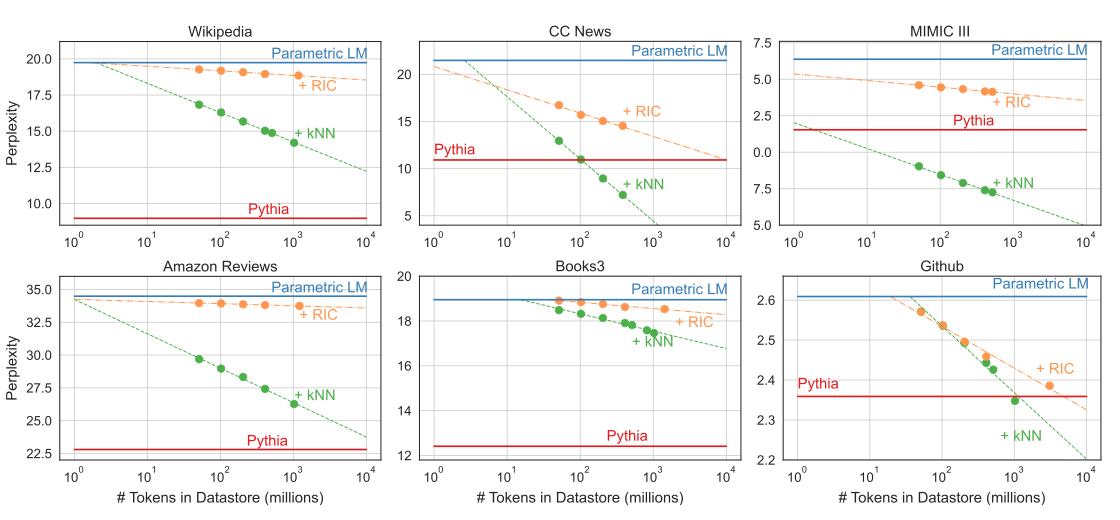
-
Data Store의 크기가 커질수록 성능이 향상되는 모습을 보임
-
일부 도메인에 대해서는 Pythia(In-Domain)보다 좋은 성능을 보이고 있음
-
KNN이 RIC보다 거의 대부분 좋은 성능
RIC vs KNN
-
두가지 가설 설정
-
Retrieval 방법론의 성능 향상 : KNN이 애초에 RIC-LM보다 성능이 좋은 모델
-
Retrieval 방법론의 일반화 성능 : KNN-LM이 RIC-LM보다 일반화 성능이 좋은 모델
-
-
1번 검증을 위해선 In-Domain에서 KNN이 RIC-LM보다 좋은 성능을 보여야함
→ In-Domain(Pythia)에서 그러한 모습을 보임
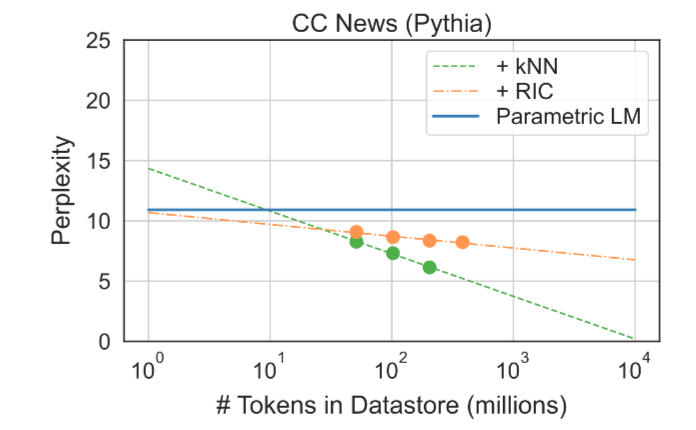
- 2번 검증을 위해선 Datastore가 커질수록 KNN-LM의 성능 향상폭이 커야 함
→ 실제로 그러하더라
⇒ 자세한 검증이 있으면 좋았겠지만, 논문의 주요 포인트가 아니어서 그런지 이 정도 실험에 그침
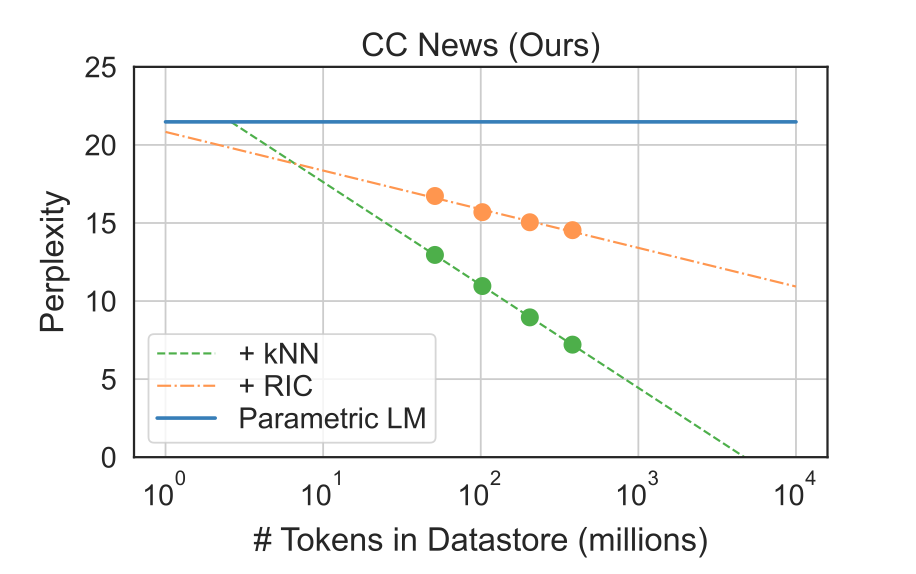
Retrieval을 통한 성능 향상 vs Retrieval을 통한 일반화 성능 향상
- 두가지 가설이 전체 성능 향상에 미치는 영향을 분석하기 위해 다음 실험 진행
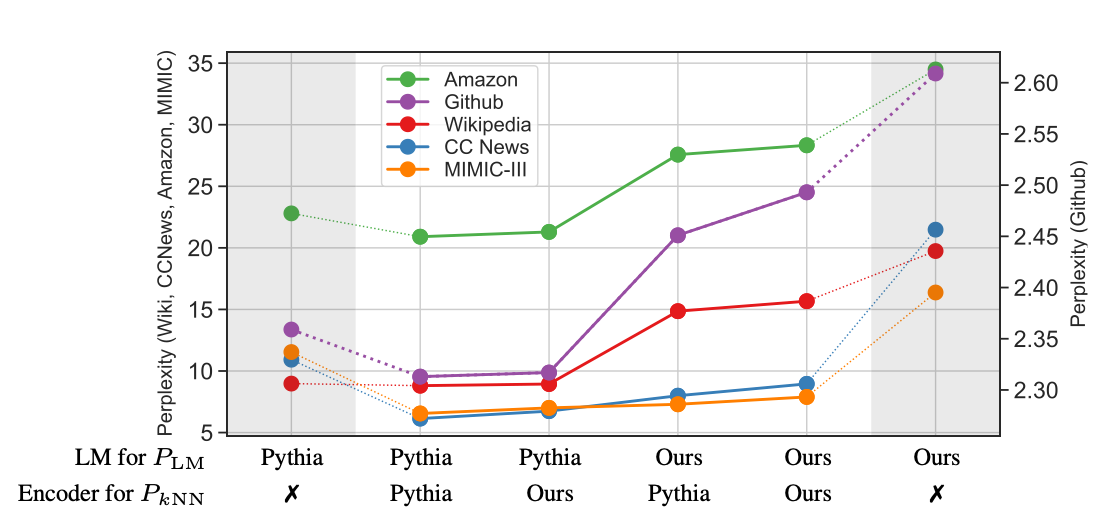
-
Retrieval와 LM으로 사용하는 모델을 달리하며 실험 진행
- (LM, Retrieval)
-
1번 (Pythia, Pythia) : Retrieval와 LM 모두 In-Domain인 경우에도 성능 향상을 보임
- (Pythia, X)와 비교를 통해 Retrieval을 통한 성능 향상 폭 확인 가능
-
2번 (Pythia, Ours) : Retrieval는 OOD인 경우
- Retrieval가 OOD더라도 충분한 성능 향상 관찰, 1번과 큰 성능 차이 X
-
3번 (Ours, Pythia) : LM만 OOD인 경우
-
2번에 비해 큰 성능 저하 but lm only보다 높은 성능 관찰
-
LM이 OOD인 것이 가장 큰 성능 변화 요인 → 결국 LM 학습 도메인이 중요하다는 소리….
-
일부 도메인에서는 여전히 1, 2번과 비슷한 성능 관찰 가능
-
-
4번 (Ours, Ours) : Retrieval와 LM 모두 OOD 인 경우
- LM only 보다는 성능이 좋지만, 1, 2, 3에 비해서는 성능 저하 관찰 가능
⇒ LM의 In-Domain 여부가 매우 중요한 요소
⇒ Retrieval 적용을 통한 성능 개선 역시 매우 뚜렷
⇒ 특히 OOD일 경우 Retrieval 적용을 통해 성능 개선 폭 뚜렷
⇒ 즉, Retrieval을 통한 성능 향상보다는 **Retrieval을 통한 일반화 성능 향상에 더 큰 비중이 있음. **
7. Conclusion

민세원이 돌아왔구나…
-
사실 당연한 문제 상황이고, 당연한 결과물임
-
LM의 OOD 성능이 떨어진다.
-
LM에 Retrieval을 통해 성능 개선이 가능하다.
-
-
하지만 이를 저작권 문제와 결합시켜서 보다 엄밀한 문제 상황 제기
- 저작권과 결합되면서 도메인, 데이터 크기 등에 대해 비교적 분명한 분석이 가능해짐
-
k-NN은 근-본
-
RIC-LM보다 더 좋은 성능을 기록
-
datastore의 크기가 커질수록 분명한 경향성 포착가능
-
-
한가지 함정을 교묘히 잘 숨겨놓음 (당당한듯 appendix에 아주 조금 넣었지만 아무리 봐도 숨겼음)
- Retrieval가 사용되는 순간 속도 저하가 발생하고, K-nn은 정말 큰 속도 저하 발생
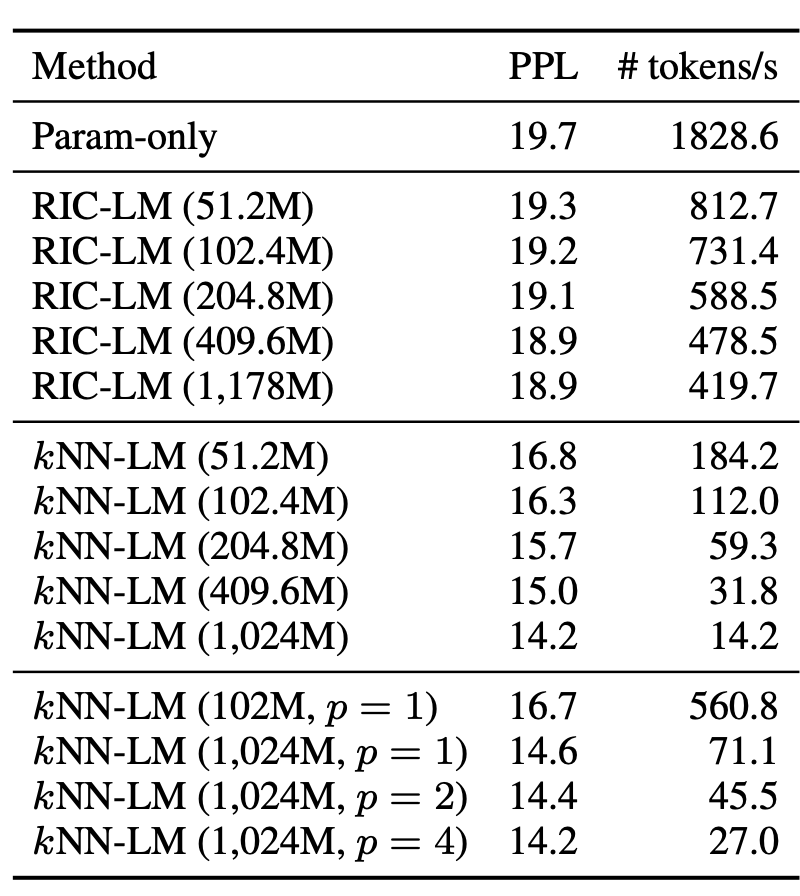
-
민세원님 논문답게 분석과 워딩, 시각화가 무척 좋다…
- 논문에 써있는 내용도 좋고, 내가 직접 해석할 여지도 충분히 남겨 놓았다.
-
결국 문제는 Retrieval을 언제 어떻게 결합하느냐…