Task-aware Retrieval with Instructions
논문 정보
- Date: 2023-01-26
- Reviewer: 건우 김
- Property: Retrieval, Instruction Tuning
1. Introduction
Information Retrieval: **the task of finding **_relevant _documents from a large colection of texts
-
Relevance
-
amorphous (체계나 통일성이 없는)
-
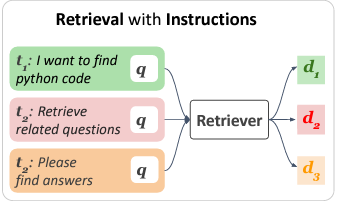
a query alone may not fully caputre user information needs
-
→ 아래 Figure 예시에서 보이는 바와 같이, ‘Implementing batch normalization in Python’ query가 주어질 때, query만 가지고는 <(1) query의 뜻을 python 함수로 구현하는지, (2) query 자체에 대한 동일한 질문을 찾는지, (3) 단편적인 함수를 찾는지> 알 수가 없다.
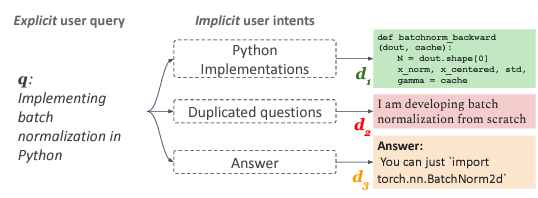
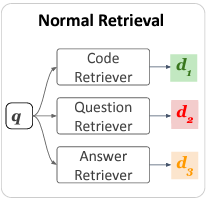
지금까지 연구된 Retrieval module은 이러한 Implicit Intent를 labeled data을 활용해서 독립적인 모델로부터 학습을 시킨다. 이렇게 하면 당연히 몇 가지 Limitations들이 존재하는데,
-
task-specific notion of relevance를 학습하기 위해서 model은 labeled data가 많이 필요
-
하나의 task에 학습된 model은 다른 새로운 task에 쉽게 transfer 할 수 없음
-
Retrieval with instructions: explicitly하게 User의 의도를 자연어로 구성된 description을 통해 모델링하는 task → 이 task의 목표는 query와 relevant하면서 instruction에 잘 반영된 document를 찾는 것이다.
-
BERRI: 대략 40개의 retrieval dataset으로 다양한 Instruction을 포함하며 구성된 데이터셋 (10개 이상의 domain)
-
TART: BERRI dataset을 기반으로 학습 시킨 single multi-task retrieval system (task-aware retriever)
-
TART-dual: dual-encoder 구조
-
TART-full: cross-encoder 구조 → (show state-of-the-art on BEIR, LOTTE-pooled)
-
-
X^2 **-Retrieval** (Cross-task Cross-domain Retrieval) Evaluation 제시: 다양한 intents들이 있는 query들이 large-scale + cross-domain한 corpus에서 relevant documents를 찾을 수 있는지 평가하는 task
-
2. Background and Related Work
Zero-shot training of retrievers
-
최근에 Neural Netwrok를 활용해서 term-based retrievers (BM25)보다 retrieval task에서 높은 성능을 보인 연구들이 다수 존재하지만, 그에 맞는 training data가 많이 필요한 문제가 있음
-
Dense Passage Retrieval for Open-Domain Question Answering (Karpukhin et al. 2020)
- Dual-encoder 구조로 ODQA task에서 처음으로 BM25보다 높은 성능을 보임
-
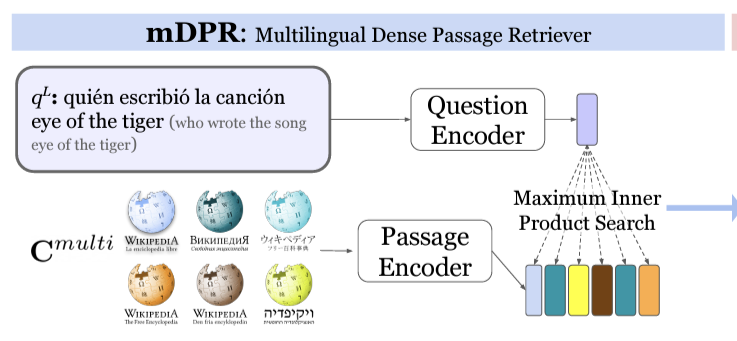
One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval (Asai et al. 2021)
- DPR의 multilingual version
-
-
KILT: a Benchmark for Knowledge Intensive Language Tasks (Petroni et al. 2021)
- KILT benchmakr 제안 → Wiki 기반으로 여러가지 Knowledge Intensive task 합친 것
-
따라서, zero-shot setting에서 Neural Network 기반 Retrieval을 연구하는 시도가 많아짐
-
Unsupervised approach
-
Contriever
-
Train a single retreival on large-scale supervised dataset
-
MS MARCO에 학습을 한 뒤 다른 dataset에 적용
-
Train customized retrievers for each task on unlabeled corpora
-
GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval (Wang et al. 2022)
-
Instruction tuning
-
최근에 instructions에 LLMs에 더해 다양한 task에서 zero-shot, few-shot 성능을 높인 연구들이 많이 존재함.
-
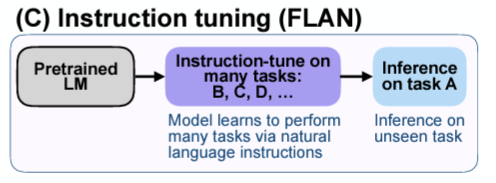
FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS (Wei et al. 2022)
- FLAN 제시한 논문: Instruction tuning (LMs을 instruction이 있는 dataset에 finetuning)
-
-
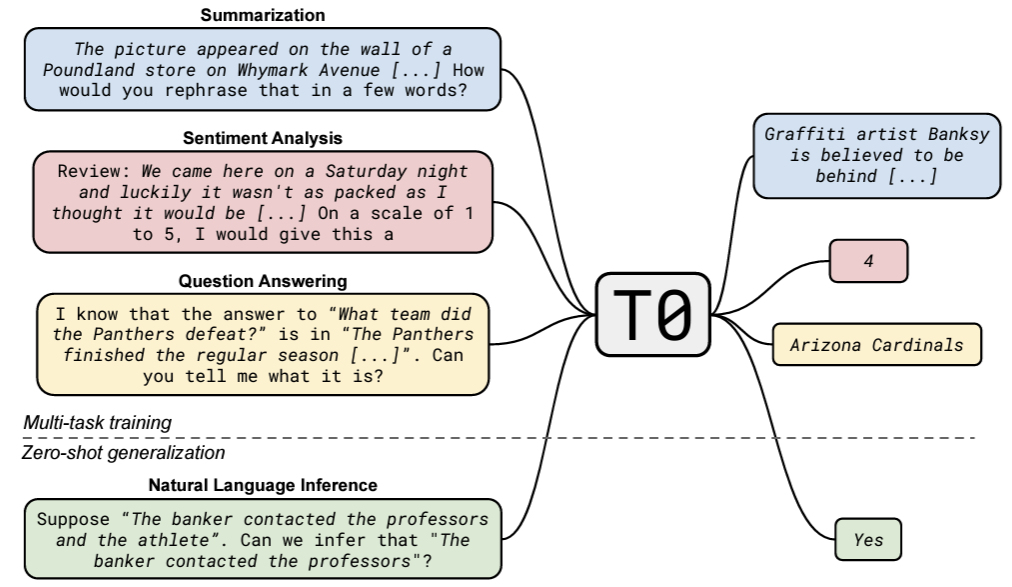
MULTITASKPROMPTEDTRAININGENABLES ZERO-SHOTTASKGENERALIZATION (Sanh et al. 2022)
-
T0 제시한 논문: zero-shot generalization을 multitask learning으로 explicit하게 학습해서 구현
-
NLP tasks를 human-readable prompted format으로 만들어 multi-task training으로 Enc-Dec 모델을 학습하고, test할 때 zero-shot으로 진행
-
-
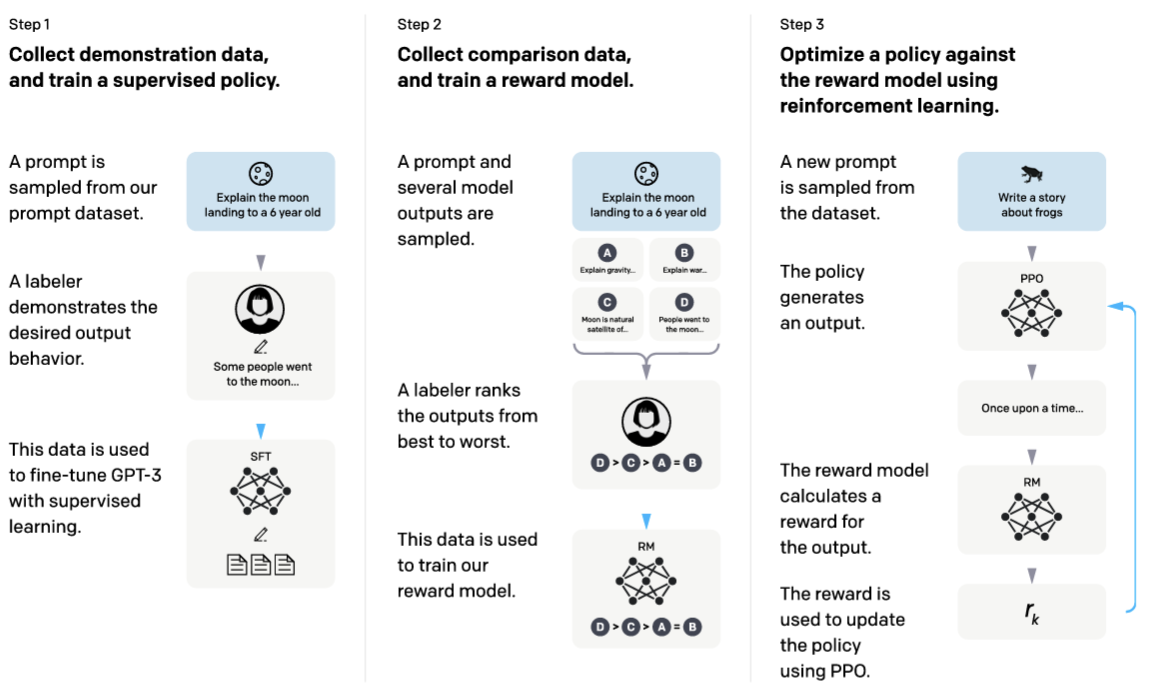
Training language models to follow instructions with human feedback (Ouyang et al. 2022)
-
InstructGPT 제시한 논문: 사전학습된 GPT-3를 RLHF를 통해 강화시킨 모델
-
Sampling된 prompt에 대해 GPT-3가 출력한 결과에 대해 사람이 직접 Ranking 매김
-
PPO를 통해 Reward Model training
-
-
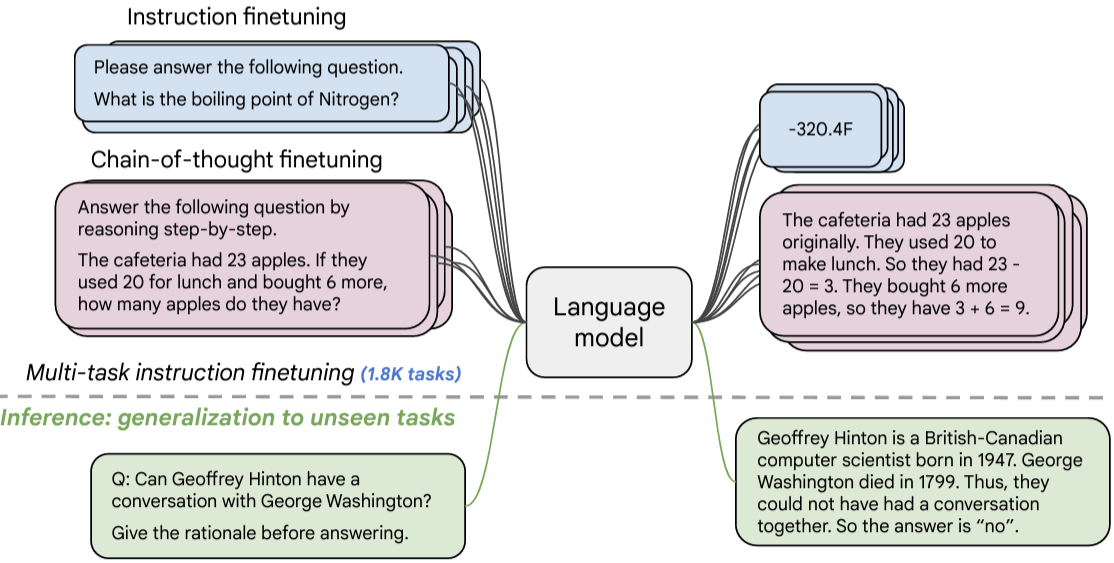
- Scaling Instruction-Finetuned Language Models (Chung et al. 2022)
-
하지만 large-sacle instruction-annotated datasets은 retrieval task를 포함하지 않는다….정말 대부분의 task에 대한 instruction-annotated dataset이 있는데 retrieval만 부재
-
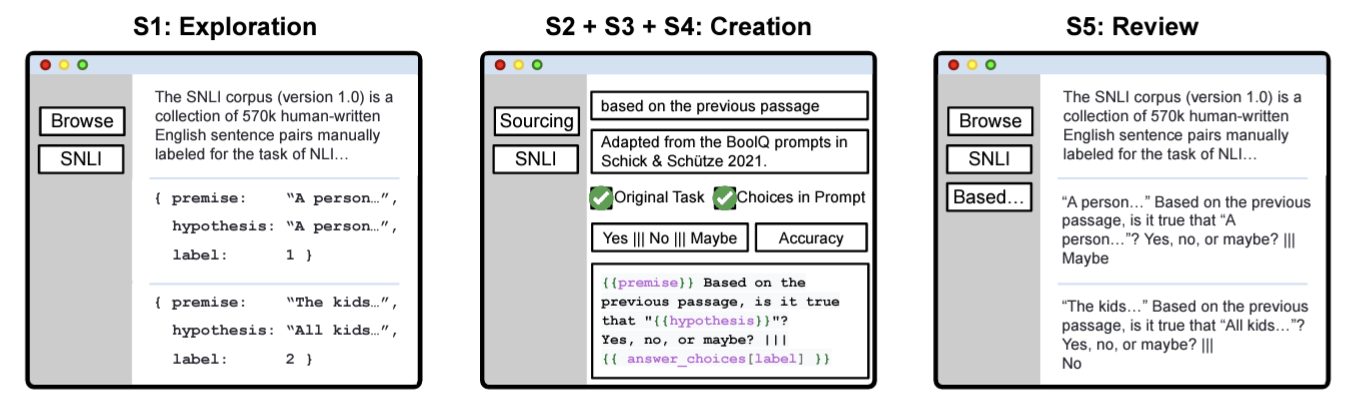
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts (Bach et al. 2022)
-
Open-source system을 직접 구축해서, community에 있는 다양한 사람들로 하여금 Natural Language Prompt 구축
-
2022년 1월 기준으로 170개 데이터셋에 대해 2000개의 prompts가 구축되어 있음. (필요할 때, 사용 가능 😀)
-
-
-
SUPER-NATURALINSTRUCTIONS: Generalization via Declarative Instructions on 1600+ NLP Tasks (Wang et al. 2022)
-
Super-NaturalInstruction이라는 benchmark dataset 제시 (1616개 NLP task + expert-written instructions)
-
해당 데이터셋에 학습시킨 Tk-INSTRUCT를 제시하며, InstructGPT보다 높은 성능을 보임
-
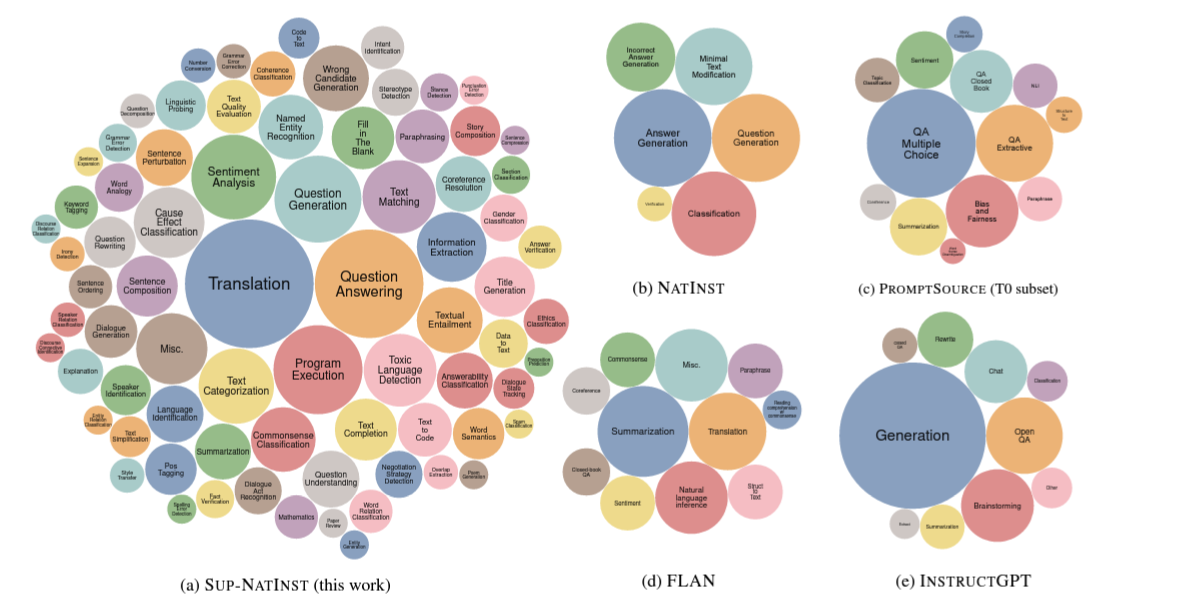
- 대부분의 Instruction을 따른 LLMs들은 generation이 목적인 architecture를 주로 갖고 있는데 (encoder-decoder, decoder-only), 수 백만 건의 documents를 encoding을 해야하는 retrieval task에는 부적절함
Retrieval with descriptions
-
이전에 retrieval module에 description을 활용한 연구는 title을 활용한 baseline에 비해 살짝 좋은 성능을 보임
-
최근에 와서 BERT 기반 LMs들이 등장하면서 더 풍부한 linguistic context를 잡아낼 수 있음
-
Context-Aware Document Term Weighting for Ad-Hoc Search (Dai and Callan 2020)
-
Deeper Text Understanding for IR with Contextual Neural Language Modeling (Dai and Callan 2019)
-
3. Task Formulation
- Retrieval with instructions (New Task)
-
Given,
-
N documents: D={d_1,…d_N}
-
Task Instruction: **t**
-
Query: q
-
→ Find out optimal document **d** (instruction t를 잘 따르며 q와 relevant가 높은 문서)
Retrieval with instruction으로 하여금 general하고 task-aware한 retrieval을 만들어보자. 이렇게 retrieval task를 새롭게 정의하면, 다른 데이터셋들이 하나의 retriever를 학습시키는데 같이 사용될 수 있는 (LLM의 Instruction tuning에서 보인 것과 마찬가지로 Cross-task interdependence에 있어 성능 향상 가능) 변화가 있다.
→ zero-shot transfer이 가능하고 multi-task instruction-following retriever는 다양한 종류의 task-specific retrievers를 사용하지 않아도 된다.
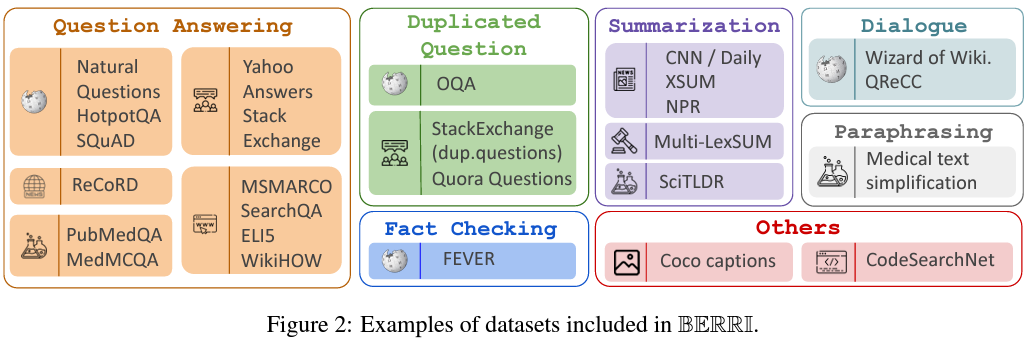
4. BERRI: Collections of Instruction-annotated Retrieval Tasks
-
BERRI (Bank of Explicit RetRieval Instructions): retrieval dataset + other NLP datasets
-
BERRI에서 각 task는 하나의 corpus와, k개의 query 그리고 하나의 instruction으로 이루어진다. 각 task의 하나의 instance는 query (q), gold documents (d^+), negative documents (d^-)과 하나의 explicit한 intent t가 있다.
-
Instruction Tuning에서 informative + diverse한 instructions들이 주된 성공 요인으로 꼽히는데, retrieval task에서 다음을 만족하는 instruction을 설계하기 위해 다음과 같은 scheme을 만듬.
-
임의의 retrieval task를 설명하는 instruction은: *intent****, **domain**, **unit***을 포함한다.
-
_intent _: retrieved text가 query와 얼마나 관련이 있는지 확인
-
_domain _: retrieved text의 expected source (ex. Wikipedia, PubMed articles)
-
_unit _: retrieved text의 text block (ex. sentence, paragraph)
-
-

-
Dataset Collection
- BERRI는 retrieval-centric datasets + non-retrieval datasets 사용해서 구축됨
-
Selecting source datasets
- Wikipedia와 같은 몇몇 domain을 제외한 나머지 데이터셋은 retrieval dataset이 없는 문제가 있다. 그래서 non-retrieval task에 사용되는 데이터셋을 retrieval task에 맞게끔 변형 시켜서 사용함.
-
Unification and instruction annotations
- MS MARCO와 같은 retrieval dataset은 query q에 대한 annotated gold document를 d^+로 설정하지만, non-retrieval dataset에 대해서는 input sequence를 query, output sequence를 gold document로 설정했다.
ex) Summarization: x: source, y: summary → x: query, y: label
- 각 데이터셋에 대하여 저자들이 직접 instruction을 작성함 (avg: 3.5개)
-
Negative documents selection
-
기존에 사용되는 negative document와 다르게 이번 논문에서는 새로운 negative document도 정의함.
-
Random negative documents
-
Denoised hard negative documents: **d^{HD}**
- Contriever와 같은 off-the-shelf retriever를 이용해서 target corpus에서 k개의 top documents (False Negative)를 추출한 다음에 cross-encoder model (ms-marco-MiniLM-L-12-v2)와 같은 off-the-shelf reranker를 이용해서 normalized score가 0.1보다 낮은 값을 d^{HD}로 설정
-
Instruction-unfollowing negative documents: **d^{UF}**
-
retrieval (TART)가 instruction을 제대로 학습하기 위해 다음과 같은 negative sample을 새롭게 정의함.
-
Instruction을 따르지 않는 negative document를 추출하기 위해서, 다른 task의 target corpus에서 off-the-shelf Contriever를 이용해 k 개의 문서들을 추출하면, 추출된 모든 문서들이 instruction 자체를 따르지 않았기 때문에 d^{UF}를 만족한다.
-
-
-

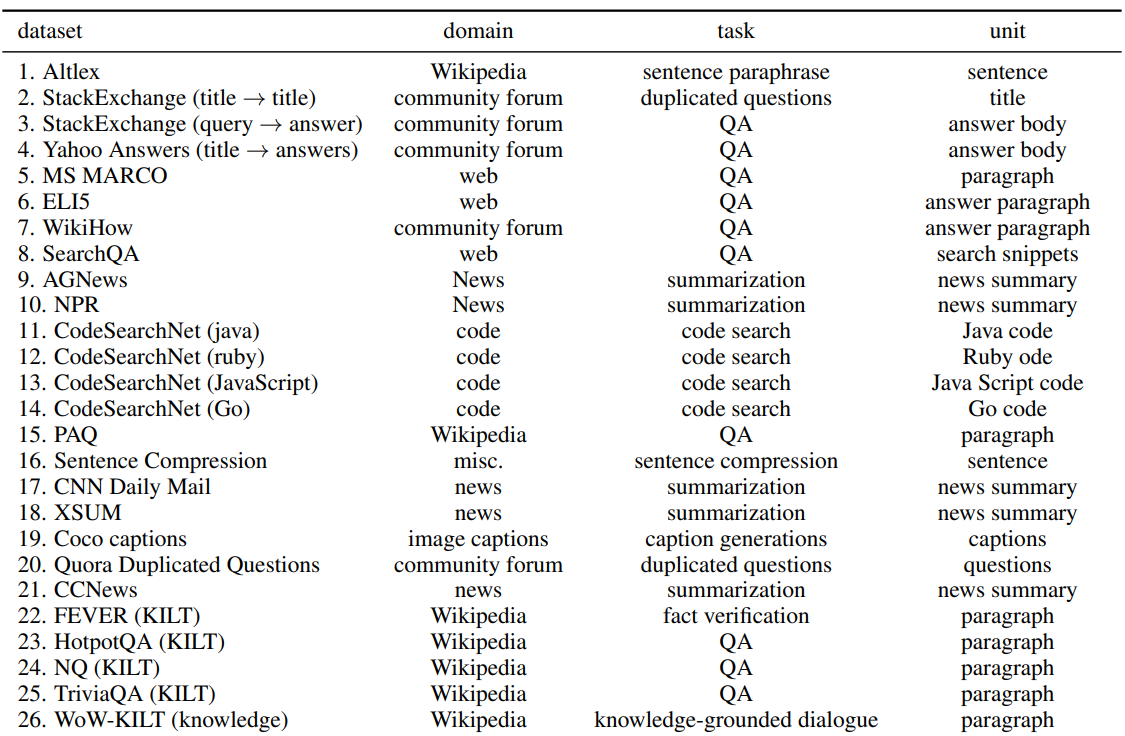
5. TART: Multi-task Instructed Retriever
-
TART (TAsk-aware ReTriever): BERRI dataset을 기반으로 multi-task instruction tuning을 통해 학습한 single unified retriever
-
TART-dual: DPR과 동일한 구조를 갖고 있어 DPR이 갖는 장/단점 동일
- 한 가지 다른 점은, query와 instruction이 concat되어 query encoder 통과함.
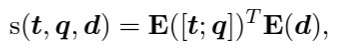
-
Training
- In-batch negative 기법 적용해서 학습 (Contrastive learning)
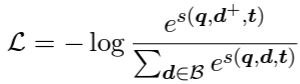
-
TART-full: 다들 아시다시피 dual-encoder는 query와 document가 독립적으로 처리되기 때문에, limited interactions이 있음. 다른 cross-encdoer 구조의 retriever와 마찬가지로 query와 document를 함께 입력하여 relevance 계산. 그런데 수 백만 건의 document에 대해 학습하기에 매우 cost가 비싸기 때문에,
- off-the-shelf retrieval (bi-encoder)를 사용해 k개를 추출하고, 추출된 k개를 TART-full에 태워서 similarity score 계산 진행 (TART-dual과 마찬가지로 instruction + query + document를 concat한 구조로 입력)
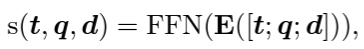
-
사전학습된 T0-3B, FLAN-T5를 TART-full의 backbone으로 사용함
-
T5를 non-autoregressive task에 접목시킨 EncT5와 동일하게 사용

-
Training
- cross-entropy loss로 학습 진행
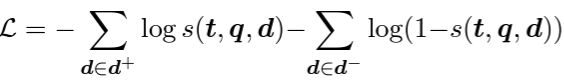
-
Knowledge distillation from TART-full to TART-dual
-
BERRI에서 default hard negative는 MS MARCO에 fine-tuned된 off-the-shelf retrievals을 기반으로 정해지는데, 다른 몇몇 domain에서는 이렇게 뽑힌 hard negative가 성능이 안 좋을 수 있다.
-
TART-full을 먼저 training을 시키고 나서, denoising step (hard negative d^{HD}얻는 과정)을 다시 진행해서, TART-full을 새로운 d^{HD} 를 기반으로 다시 학습시키면 성능이 오른다…
-
굳이..? 실험인 것 같음..;;
-
6. Experiments
-
Zero-shot retrieval
-
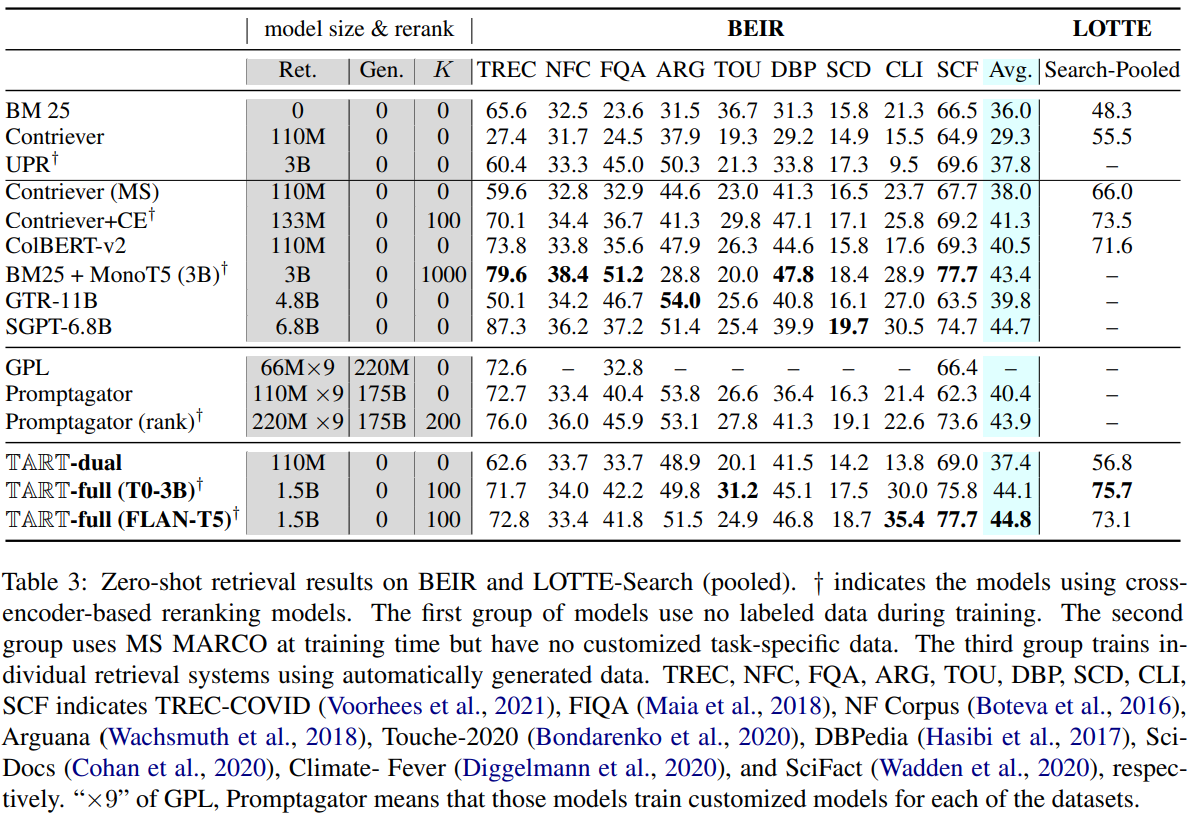
BEIR: NQ, MS MARCO, HotpotQA, FEVER, CQADupStack은 평가에서 제외
-
LOTTE-pooled: 다양한 domain의 dataset을 합쳐서 평가 시에 instruction 안에 (domain)이 들어가게 설정 (ex. “Retrieve a *cooking *StackExchange forum ~”)
→ BERRI랑 겹치는 dataset은 없음
-
Metrics
-
BEIR → NDCG@10 (랭킹기반 추천시스템에서 주로 사용되는 지표인데, retrieval task에서 자주 사용)
-
LOTTE-pooled → Recall@5
-
-
-
X^2 **-Retrieval (Cross-task Cross-domain Retrieval)**
-
Normal benchmark: 하나의 intent와 하나의 corpus 갖고 retrieval을 시행함 (oversimplify real-world)
-
X^2-Retrieval은 모델로 하여금 새로운 task에서 zero-shot으로 수행 가능하고 user의 intent를 이해하는 것을 요구한다
-
3가지 domains (Wikipedia, Science, Technical)을 포함하는 6가지 데이터셋 사용
-
Source document: 3.7 million → oracle setup과 비교하기 위해 *closed *setup도 사용 (기존 benchmark인 BEIR와 동일한 환경)
-
Metrics
-
NDCG@10
-
gap between *closed *and *pooled *setups → to check robustness
-
-

-
Baselines
-
Unsupervised models (trained only on unlabeled text / not trained)
-
BM25
-
Contriever
-
UPR (Contriever의 결과 값을 T0-3B로 reranking한 모델)
-
-
Train retrievers and rerankers on MS MARCO → 새로운 task에 adaptation없이 적용
-
MonoT5
-
Contriever-MS MARCO
-
Contriever-MS MARCO + CE
-
ColBERT v2
-
GTR
-
SGPT-BE
-
-
각 task에 맞게 학습되고 + additional data로 target corpus에서 생성한 data 추가 학습
-
Promptagator (FLAN을 사용해서 in-domain data 생성)
-
GPL (DocT5Query를 사용해서 in-domain data 생성)
-
-
-
Experimental Settings
-
TART-full
-
T0-3B , FLAN-T5 의 encoder를 initialize하여 사용
-
positive passages : negative passages = 1 : 4
-
8 GPUs 사용
-
Contriever-MS MARCO를 사용해서 initial document의 candidates 추출
-
-
TART-dual
-
Contriever-MS MARCO를 initialize하여 사용
-
positive passages : negative passages = 1 : 5
-
Negative passages
-
random: 90%
-
d^{HD}: 10%
-
d^{UF}: 10%
-
-
64 GPUs 사용 + GPU 당 batch size: 16 (너무 크다..)
-
-
7. Results
-
Zero-shot Evaluation Results
-
3번째 row에 있는 GPL, Promptagator.. 친구들은 additional data사용해서 성능을 보여주지만, TART는 human-instruction만 있으면 된다
-
그 와중에 BM 25의 성능이 정말 좋다 (학습을 x → 이 정도면 ..ㄷㄷ)
-
BM25+MonoT5의 성능도 높지만 reranking할 때, passage 개수가 1000 (TART-full은 100)
-
TART-dual과 Contriever-MS MARCO를 비교해보면 BEIR에서 (6/9)개가 높은 성능을 보이긴 하지만, Touche-2020, Climate-Fever에서 performance degradation이 너무 커서 평균 값이 낮게 선정됨
→ 이에 대해 저자는 dual-encoder의 한계 (query와 document의 limited interaction)때문이라고 핑계를 대지만, Contriever도 동일 구조기 때문에 핑계가 과연 될까 의문..) + 다만, BERT (base) 작은 크기의 LM에 Instruction tuning을 접목 시킨 것이 이유 (이전 여러가지 Instruction tuning 연구들은 LLMs만 IT가 가능하고, 모델의 크기가 작으면 적용하기 힘들다는 것을 나타냄)
-
LOTTE-pooled 결과를 보면 baselines들에 비해 TART가 큰 차이로 높은 성능을 보였는데, 이는 test시에 단순히 instruction을 추가하는 것은 크게 도움이 안된다는 것을 보여줌
-
-
X^2**-Retreival Evaluation Results**
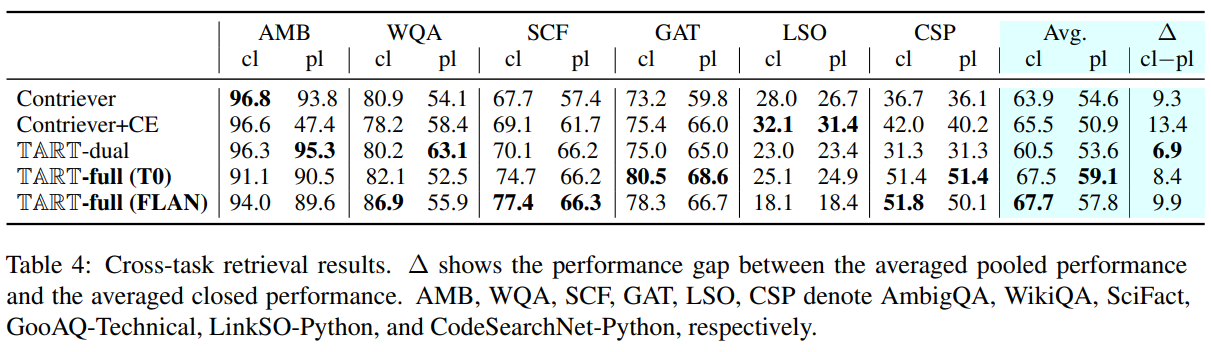
- Contriever와 Contriever+CE는 closed setup에서 높은 성능을 보여주는데, pooled setup에서는 저조한 성능을 보임. (특히 Contriever+CE가 심함)
→ 그런데, Contriever 자체의 robustness는 또 강함…음..그냥 Contriever도 매우 강력한 retrieval인 거를 이 실험에서 확인했음
-
TART-full (T0)가 전체에서 pooled setup에서 높은 성능을 보여 매우 강력한 zero-shot adaptaion + cross-task ability를 갖고 있음을 보이는데, 위에 zero-shot evaluation에서는 TART-full (FLAN)이 더 좋긴 했음. 이거에 대한 언급은 따로 없는데..
-
무엇보다 TART-dual 자체의 성능은 Contriever보다 closed setup에서도 낮게 나왔음.
→ 그런데, _robustness _척도가 가장 높게 나왔다고 해서, 저자가 또 말을 “even smaller models can be guided by instructions”이 가능하다고 하네…위에 실험이랑 다른 맥락의 말인데 이는 가볍게 무시. 그냥 작은 LM에는 instruction 적용하지 않는 것이 좋은 전략인듯
8. Analysis
-
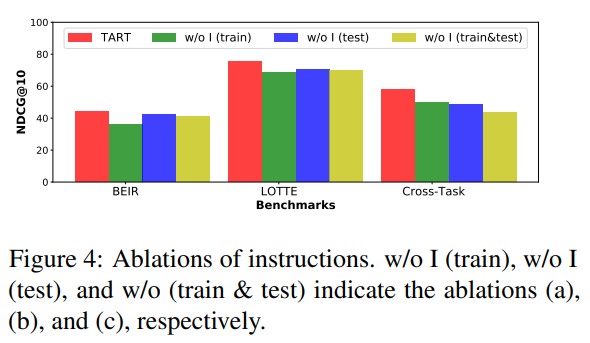
Effects of Instruction at training and inference
-
Red: TART-full (train with instruction + test with instruction)
-
Green: train without instruction + test with instruction
-
Blue: train with instructions + test without instruction
-
Yellow: train without instruction + test without instruction
-
-
**Effects of dataset scale + Effects of model scale **
→ 모델 크기 크면 좋고 + 데이터셋 number/domain/task 많으면 좋다
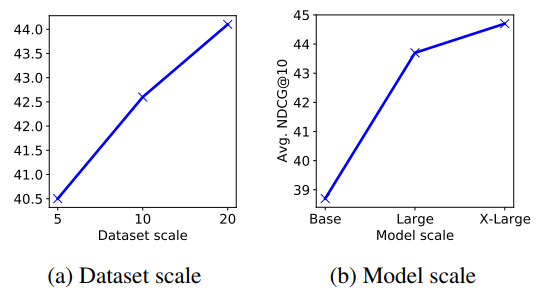
-
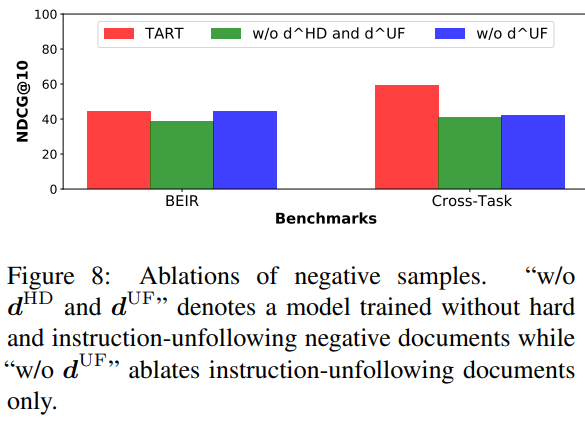
Effects of carefully-designed negative samples
-
d^{HD}, d^{UF}를 더 추가하면 (challenge negatives) TART-ful 성능 향상
-
without instruction-folloiwng samples (w/o d^{UF})인 경우에서는 BEIR 평가할 때, 그냥 TART랑 동일 성능을 보인 반면에, X^2-Retrieval task에서는 큰 하락을 보임
→ instruction을 끼고 학습 시키는 것이 모델의 robust task-aware retrieval ability 향상
-
9. Dicussion and Conclusion
- 실제 동일 query에 있어 instruction을 다르게 주면 retrieve되는 text는 다름
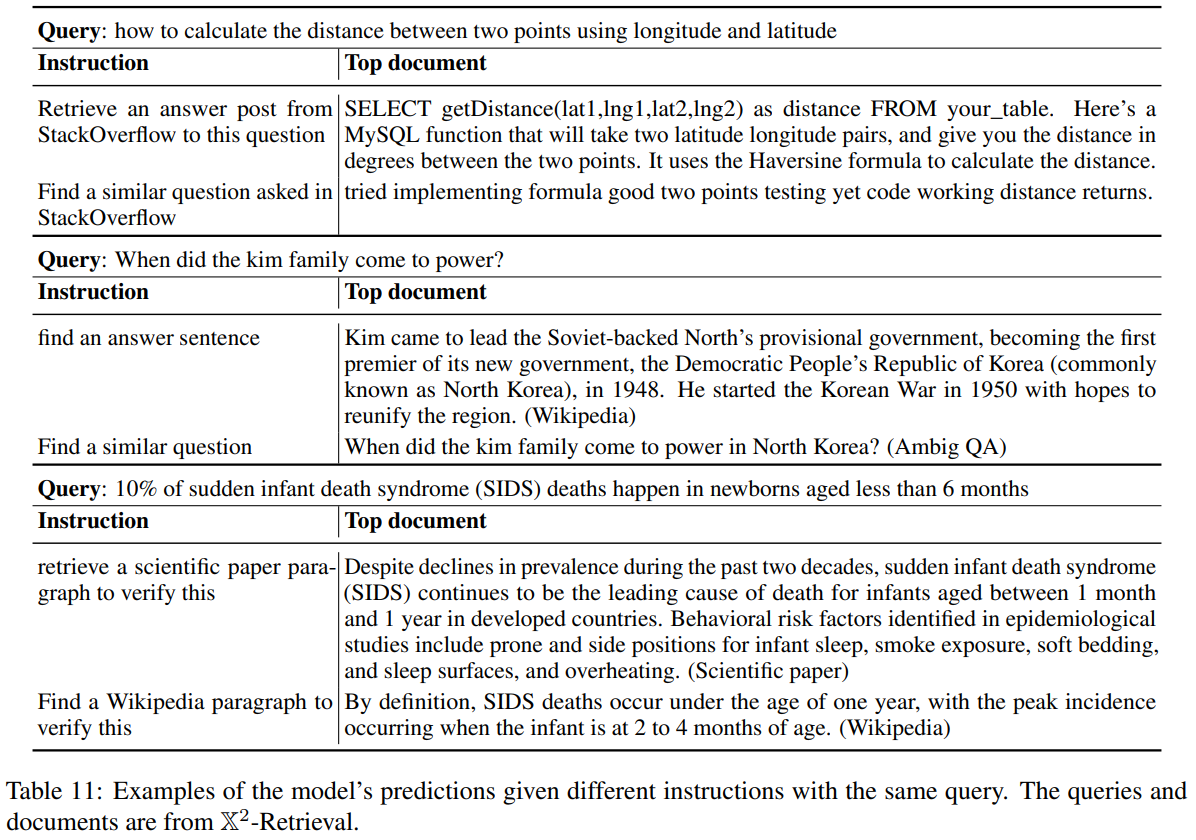
- 정성 평가 예시 (물론 체리피킹)

-
NLP에서 최초로 Instruction Tuning을 retrieval task에 접목 시킨 paper
-
dramatic한 performance gain이 있지는 않았지만, 방향을 제시한 것에 있어서 의의가 있음