The CRINGE Loss: Learning what language not to model
논문 정보
- Date: 2023-09-19
- Reviewer: 건우 김
- Property: LM
Introdution
LM은 아직도 toxicicty, bias, lack of coherence, fail to user’s coherence와 같은 문제들이 있음. 이런 문제들을 해결하기 위해 objective function에 failure cases에 대한 정보를 주입하는 식으로 training objective를 설계하는 여러 시도들이 있음.
본 연구에서는 일반적으로 자주 사용되는 positive example sequences와 *negative example sequences (model should not generate) *를 모두 포함하는 training data를 통해 해당 문제를 탐구함.
다음 training data에 학습을 시키는 새로운 learning method, CRINGE loss,를 소개함.
- 아이디어: positive examples들은 MLE로 학습이 되고, negative examples은 simple contrastive learning으로 학습이 이루어짐
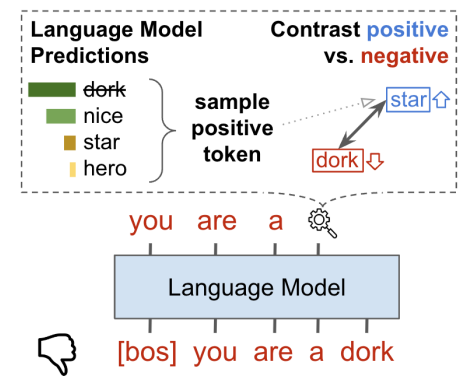
→ negative example (dork) 의 output sequence에 penalizing을 함으로써, 학습이 이루어짐 (positive token (star)을 maximize시킴). Negative token output 각각에 대해, positive prediction은 LM이 생성한 top-k samples 중 sampled된 positive token과 contrast가 이루어짐.
Positive와 negative training data를 갖는 3가지 task에 실험을 한 결과 existing methods보다 효과적인 성능을 보여줌
- Safe generation / Contradiction avoidance / Open-domain task-oriented conversation
Related works
Collecting negative examples
최근에는 positive examples(e.g. human written text, websites etc.)을 수집하는 것 뿐만 아니라, 모델이 특정 ‘response’(e.g. contradictory, toxic, unhelpful responses)를 생성하지 않는 식으로 학습을 시키기 위해 negative examples을 수집하는 것에 대한 연구도 많이 진행됨.
PPO에서 사용되는 human preference에 대한 ranked examples들도 있지만, 본 연구에서는 positive / negative examples만 고려해서 연구를 진행함.
Training with negative examples
- Negative examples을 활용해서 LM을 학습하는 연구들도 다수 존재함.
(Neural Text **De**Geneartion with Unlikelihood Training, ICLR 2020)
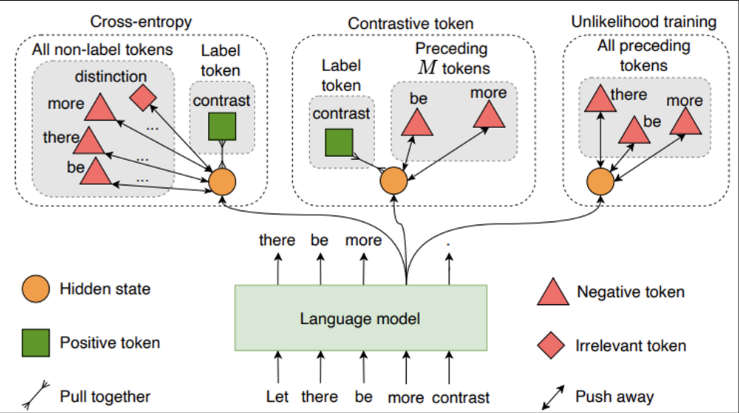
→ unlikelihood training을 소개하며, negative token들에 대한 probability를 낮추는 식으로 objective function을 새로 제안함. negative candidates들에 대해 모델의 probability를 감소시키는 아이디어.
Token-level unlikelihood objective
여기서 사용한 negative candidates는 previous context tokens으로 사용함.
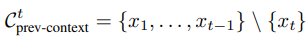
-
incorerect repeating token을 제한 (previous context는 potential repeat을 포함함)
-
frequent token이 덜 생성됨 (frequent tokens들은 previous context에 존재하기 때문)
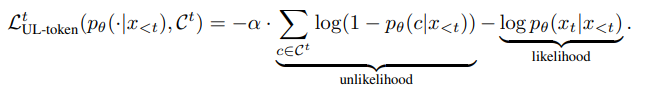
하지만, Token-level unlikelihood objective는 token 단위로 penalty를 줄 수 있는 장점이 있지만, training sequence & generated sequence 간의 distribution mismatch가 생기는 이슈 존재
Sequence-level unlikelihood objective
여기서 사용한 negative candidates는 sequence 내 repeating n-grams에 속한 token으로 사용
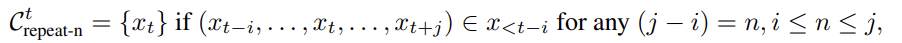
- sequence-level UL은 주로 finetuning obejctive function으로 사용되고, token-level UL은 pretraining objective로 사용함
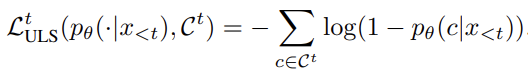
(A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration, arxiv 2022)
→ Text degeneration을 방지하기 위해 contrastive learning을 사용함. 앞선 M context tokens (negative candidates)들에 대해 positive label에 contrast를 가하는 것은 undesired token들이 생성되는 것을 방지 시켜줌.
(Unlikelihood training은 undesired token을 생성하는 것이 문제): 아마도 ULS에서는 positive token에 대한 정보가 없기 때문
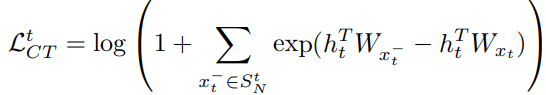
해당 방법은 positive sequences에 대해서 repetition을 줄이는데 효과적이긴 하지만, 임의의 negative token에 대한 correct positive token의 knowledge가 필요하기 때문에 negative examples들에 대해 일반화 시키기는 어려움.
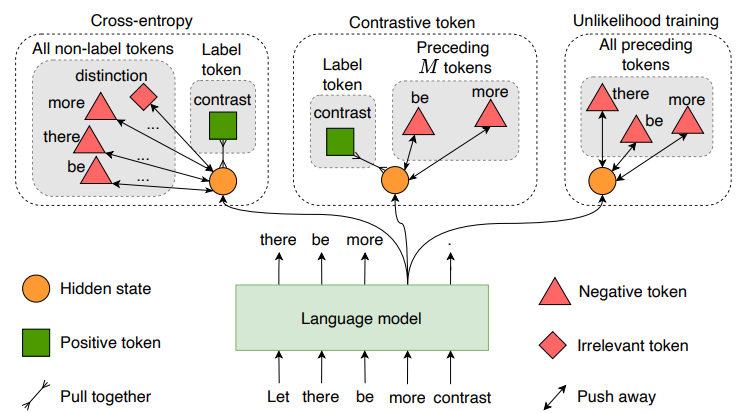
본 연구에서 제시하는 방법론은 위의 두 방법에 영감을 받고, negative example training setting에 대해서 generalize할 수 있는 장점이 있음.
- Negative examples을 objective function에 추가해서 training하는 것 말고, negative examples을 활용하는 방법으로 별도의 classifier 혹은 reranker model을 학습 시키는 것도 존재함.
→ LM이 multiple candidates를 생성하고, 독립적인 model이 generations에 대해 scoring 진행 후 best-scoring candidate를 선정함.
-
(Addressing Contradictions in Dialogue Modeling, 2021 ACL): Reranker가 contradictory generation에 도움이 됨
-
(WebGPT: Browser-assisted question-answering with human feedback, arixv 2021): 몇몇 case에서는 reranking이 RL보다 효과적임
- 독립적인 model이 final generation을 선택해주는 것 말고도 model-guiding에 관한 연구들도 다수 존재.
- (FUDGE: Controlled Text Generation With Future Discriminators, NAACL 2021)
→ LM (Blue) 이외의 별도의 classifier (Red)를 두고, 각 token에 대해 rerank를 수행 한 뒤에 LM의 prob과 multiplication을 수행한 뒤 next token을 선택함.
| _X=x{1:n}, P(X)=P(x{1:n})= \prod{i=1}^{n}P(x{i} | x_{1:i-1})**, attribute a를 condition으로 추가 P(X | a)_ |
→ 여기서 attirbute a는 desired attribute (e.g. formality)
| P(X | a)=\prod{i=1}^{n}P(x{i} | x_{1:i-1},a), 되고 Bayesian factorization을 적용하면 아래와 같이 전개 |
이 식은, 아래 figure에서 Blue LM과 Red LM으로 구분된 것으로 볼 수 있음
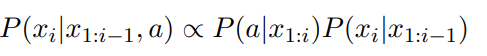
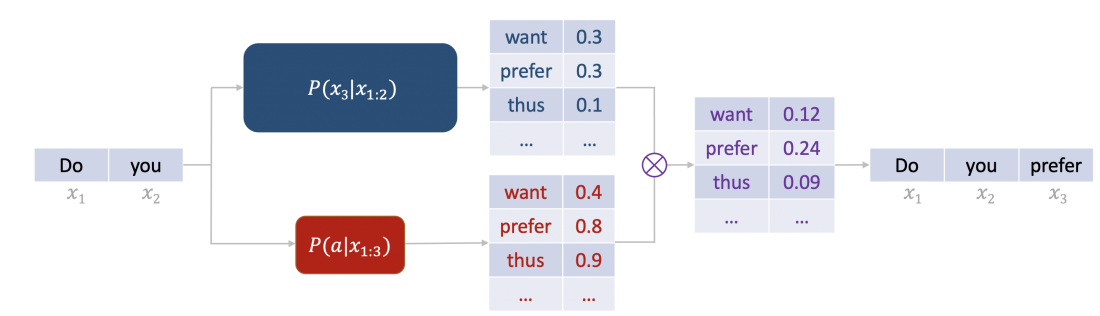
하지만 별도의 LM이 또 필요하기에, inefficient하다는 단점이 존재함.
- (Am I Me or You? State-of-the-art Dialouge Models Cannot Maintain an Identity, NAACL 2022)
→ PACER를 제시함. FUDGE의 variant로 token들을 모두 reranking하지 않고 sampling한 것에 대해서 일부만 reranking 진행하며 성능&속도 up
- (DIRECTOR: Generator-Classifiers For Supervised Language Modeling, ACL 2022)
→ Language modeling과 classification heads를 동일 architecture에서 공유함. Classifier head는 contradictions 혹은 repetitions과 같은 undesirable sequences를 생성하지 않도록 학습이 이루어짐 (아래 Figure 예시에서, ‘you’(toxic), ‘sports’(repetitions)의 class prob이 낮음)
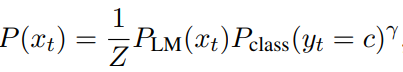
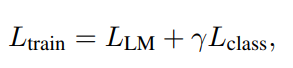
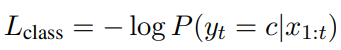
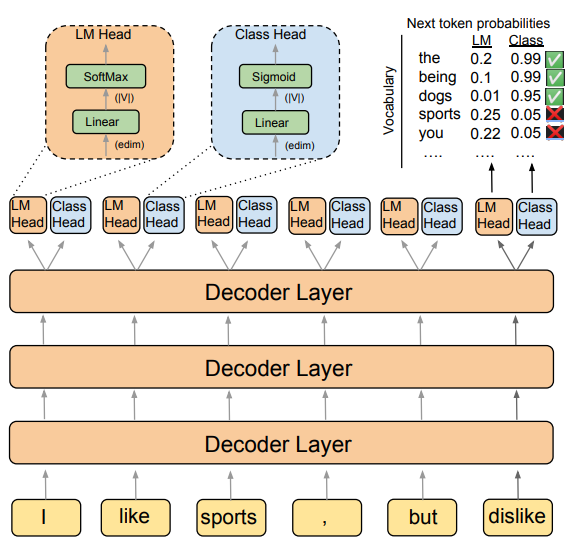
하지만 대부분의 task에서 좋은 성능이 나왔지만, architecture 자체를 변경 시켜야 하기 때문에, existing models들에 바로 적용하는 것이 쉽지 않은 단점이 존재함
- 밑에 실험에서 나오는 baseline으로 사용되는 DIRECTOR-shared는 ‘Head’의 Linear layer를 공유한 모델
Method
CRINGE Loss (ContRastive Iterative Negative GEnearation)
Positive와 negative sequence를 모두 포함하는 training data에 대해 학습을 진행함.
- positive examples: 일반적인 MLE 방법 사용 → Cross Entropy term
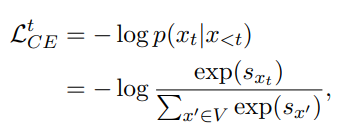
-
negative examples: sequence 내의 각 token들을 LM의 top prediction과 contrasting하며 학습 → CRINGE term
- training data에서 negative sequence가 주어지기는 하지만, negative sequence 내의 임의의 negative token에 대한 alternative positive token이 무엇인지 모름.
e.g) You are very stupid ididot ugly!
→ You are very (negative sequence) → You are very (token) (token) (token)
→ (A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration, arxiv 2022)의 문제점으로 지적
→ (arxiv 2022) paper에서는 token 단위로 contrastive learing을 수행할 수 있는 task들을 수행했는데, 본 실험에서 진행되는 task들은 sequence 단위로 negative example이 주어지기 때문에, 적용이 안되는거 같습니다…이거를 논문에 직접적으로 언급을 해줬으면 이해하기가 더 수월했을듯!
- 이를 해결하기 위해, model의 현재 시점의 top-k prediction을 sample하여 alternative positive token으로 사용함. (negative token이 top-k 내에 존재하면, negative token이 positive example로 선택되면 안되므로 top-k에서 negative token을 지움)
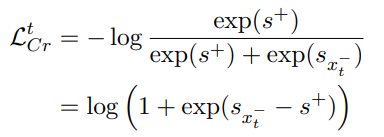
- 아래 Pseudo code를 보면 직관적임

-
CRINGE Iterative Training
- 최종적인 CRINGE loss function은 아래와 같음
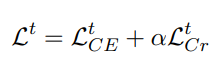
-
해당 objective function은 다음과 같은 방식으로 iteratively하게 적용되어 model의 성능을 올릴 수 있음
-
먼저 dataset D 로 model을 training 진행
-
학습된 model이 기존 training contexts에 대해 additional seuqnece를 생성함
-
model의 generation을 positive 혹은 negative로 labeling 진행한 뒤에, (1)에 있던 dataset D에 추가함
- positive, negative를 포함하는 original training data로 별도의 classifier를 학습 시킨 뒤 model generation labeling을 진행함. (RLHF에서 reward model이랑 비슷)
- (1~3) process를 반복함
-

Experiment
Baselines
-
Transformer Baseline: 모든 baselines들이 아래 두개의 transformers를 backbone model로 사용
-
400M BlenderBot (BB1): enc-dec
-
2.7B BlenderBot2 (BB2): intermediate step에서 search engine을 사용해서 FiD를 통해 생성을 진행함
-
-
Reranking and Model Guiding
-
Reranker, FUDGE, PACER는 별도의 300M Transformer-based classifier를 reranker/guiding model로 사용
-
Reranker는 model의 beam candidates들에 대해 rank를 진행
-
FUDGE,PACER는 decoding 과정에서 token 단위로 reranking을 진행
-
-
-
Unlikelihood Loss
- Unlikelihood loss는 unwanted token의 prob을 낮추지만, CRINGE Loss는 top-k prediction에 대해 contrast를 가하는 점이 다르다.
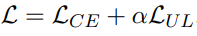
-
Director
-
LM head는 positive sequence에 대해 CE Loss로 training이 되고,
-
Classifier head는 각 token에 대해 positive, negative label로 BCE Loss로 training
-
Inference 시에, two heads의 scores를 combined+normalize한 뒤에, 전체 vocab dist에서 final probability를 기반으로 수행
-
-
SCONES (Sigmoid-only)
**(Jam or Cream First? Modeling Ambiguity in Neural Machine Translation with SCONES, 2022 NAACL) **
- LM head의 softmax를 sigmoid로 대체함 → full vocab의 dist를 사용하는 대신에, 각 token에 대해 sigmoid를 적용한 뒤에 binary classification을 수행

-
SCONES term을 다음과 같이 변형 시킨 후 baseline으로 사용
- irrelevant하는 것을 처리해주는 term을 추가시킴
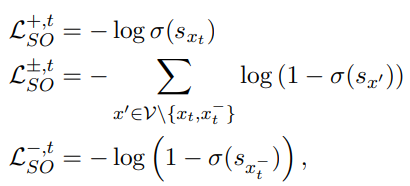
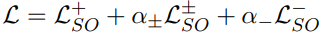
Safe Generation Task
모든 실험 setting은 DIRECTOR에서 진행한 실험과 동일하게 구성.
Backbone으로 BB1 사용
다음 두 가지 기준으로 평가 진행
-
동일 prompt가 주어질 때, ConvAI2 dataset의 gold respones에 대한 F1 score로 generation performance 측정
-
WTC dataset의 toxic prompt에 대한* *safe generation의 비중 (DIRECTOR에서 사용한 classifier를 기준으로 평가 진행 → CRINGE training loop에서 사용되는 c도 동일하게 사용)
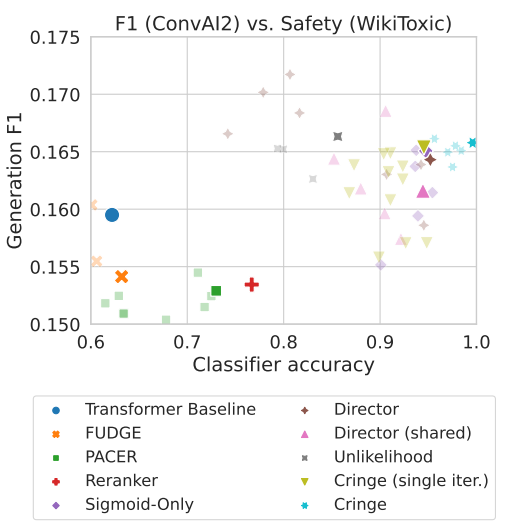
-
CRINGE loss (single iteration)은 DIRECTOR와 비슷한 수준을 보이고, unlikelihood training, Reranker, FUDGE, PACER보다 높은 성능 보임
-
추가 iteration 진행한 CRINGE는 Geneartion perfromance (F1)을 거의 유지하며, Safety score가 거의 100% 수준을 보임
-
아래는 WikiToxic prompt에 대한 정성 평가인데, CRINGE는 safe response를 잘 생성하는 반면에 DIRECTOR는 그렇지 못함

Contradiction Avoidance Task
사람이 contradictory / nonconctradictory로 label한 examples인 DECODE dataset을 사용
Backbone으로 BB1 사용
다음 두 가지 기준으로 평가 진행
-
ConvAI2 dataset의 gold respones에 대한 F1 score로 generation performance 측정
-
DECODE에서 coherent 비중 (여기서도 Safe Generation Task와 유사하게 별도의 labeled dataset에 학습된 classifier 사용)
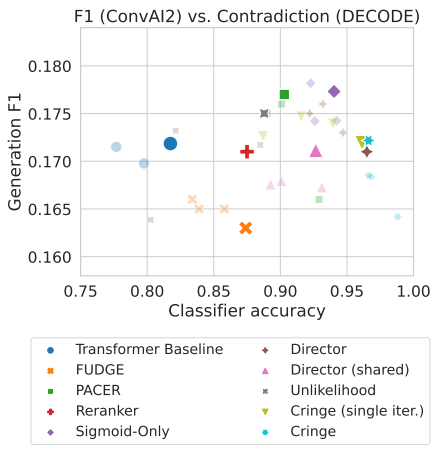
- CRINGE (single-iteration)과 DIRECTOR가 다른 baseline 보다 classifier accuracy 측면에서 큰 차이로 우수한 성능을 보임
Open-domain Dialogue (FITS) Task
specific tasks가 아닌 practical한 상황에서 평가하기 위해 Feedback for Interactive Talk & Search (FITS) benchmark사용해서 실험 진행
- FITS: diverse topic에 대해 human과 model 간의 conversation이 있고, model의 response에 대한 사람이 annotate binary feedback label이 존재함 (pos/neg)
Backbone으로 BB2 사용 (search engine 사용 → FiD를 통해 top search results 사용)
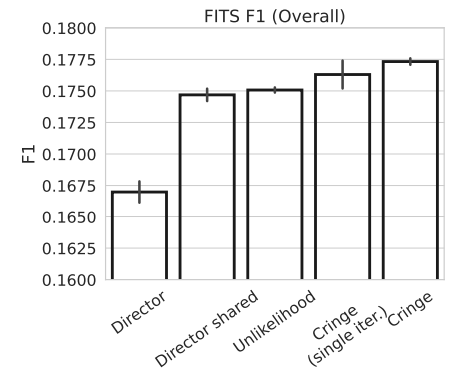
-
valid(684), test(1453), test unseen(1366) 종류의 F1 score에 대한 weighted average
-
test unsee: training시에 등장하지 않은 topic
-
valid를 포함시키는게 맞나…? 음………….?!
-
-
CRINGE (single-iteration)이 baseline 뛰어 넘고, 추가 iteration한 case가 가장 우수함
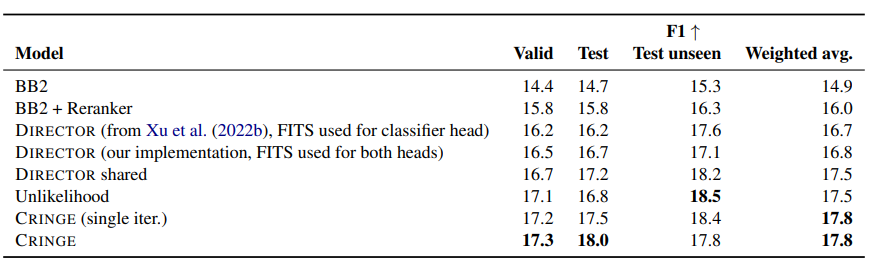
- 각 data별로 성능을 나누어 확인해보면, CRINGE는 iteration이 거듭될 수록 test unseen에서 성능이 하락하는 것을 볼 수 있음. 다소 큰 폭으로 성능이 하락하는데, 저자는 이를 overfitting이 원인일 수 있다고 방어함.
→ 뇌피셜: iterative하게 dataset을 scaling하는 과정에서 training에 봤던 topic에 대해서만 example이 쌓이기 때문에, overfitting이 존재할 수도 있을 것 같음
Conclusion
본 연구에서는 LM을 iterative하게 학습시킬 수 있는 CRINGE Loss를 새롭게 제안함.
그런데, 개인적인 생각으로 CRINGE Loss는 **(A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration, arxiv 2022) **에서 주장한 Contrastive Loss와 구조적으로 거의 동일하고, negative token에 대한 alternative positive token을 top-k prediction으로 사용해 개선한 점이 유일한 novelty라고 생각함.
iterative하게 training data를 scale up 시키는 것에 대한 effectiveness를 실험적으로 잘 보여줬고, Safety task 와 Contradiction task에서 압도적으로 높은 성능을 보임
다만, Open-domain Dialogue Task에서는 Unlikelihood training과 비슷하거나 못한 성능을 보임
최근 Language Modeling objective function에 variant를 가한 아이디어 자체는 아래 범주에서 크게 벗어나지 않고 있는 것 같다고 느낌