The False Promise of Imitating Proprietary LLMs
논문 정보
- Date: 2023-06-22
- Reviewer: 김재희
- Property: sLLM, LLM, Evaluation Metric
1. Intro
단순히 데이터를 확보해서 sLLM을 SFT 방식으로 훈련하는 것은 정말로 모델이 해당 태스크에 대한 성능을 확보하지 못함.
sLLM
-
최근 LLaMA, Alpaca, Vicuna 등을 비롯해 정말 많은 sLLM들이 등장하고 있음
-
해당 모델들이 가지는 임팩트는 다음과 같음
-
LLM 대비 작은(6b~40b) 크기
-
학습에 필요한 데이터를 경제적으로 수집 가능
-
학습 시 복잡한 RLHF 등을 수행하지 않고, SFT만으로 학습
-
1 ~ 3에도 불구하고 LLM과 비슷하거나 다소 못미치는 성능
-
Self Instuct
-
특히 데이터 수집 시 Self Instruct 등의 방법론을 이용하는 것이 일반적
-
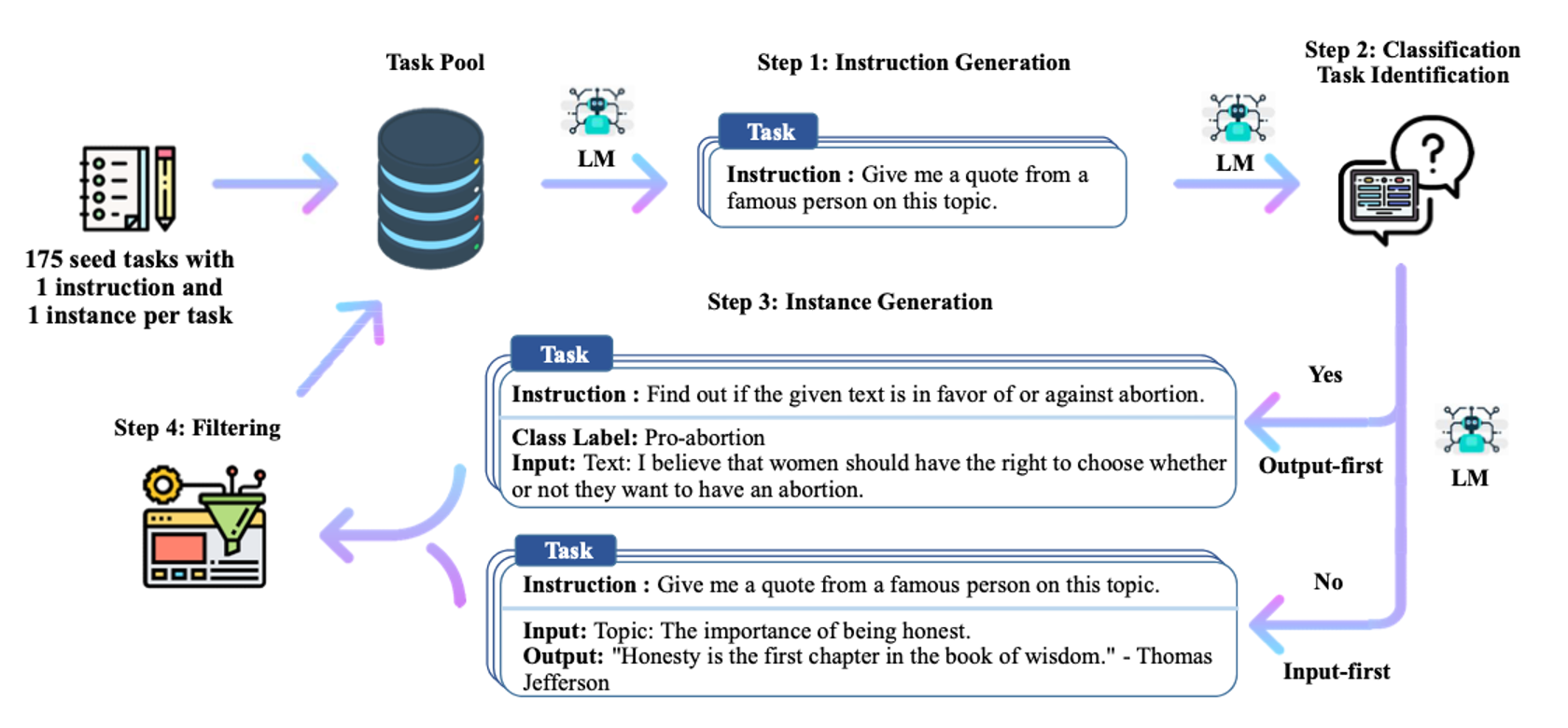
Self Instruct는 공개된 LLM 서비스를 이용하여 데이터를 구축하는 방법론
-
Self Instruct 기반 방법론을 분류하면 크게 두가지 흐름
-
저자들이 직접 작성한 초기 Prompt를 기반으로 LLM이 Prompt와 Output을 생성하는 방식
-
사용자들이 본인이 작성한 Prompt와 LLM이 작성한 Output을 공개한 플랫폼에서 데이터를 수집하는 방식
-
-
두 방식 모두 결국 LLM의 지식을 Distillation 하는 방향
⇒ LLM의 Output을 모방하도록 학습하기 때문
⇒ 본 논문에서는 sLLM을 Imitation Model이라고 부름
False Promise
-
본 논문의 저자들은 이러한 SelfInstruct + SFT 방식으로 학습된 모델의 유효성에 대해 의문을 제기함
-
이는 두가지 측면으로 구분
-
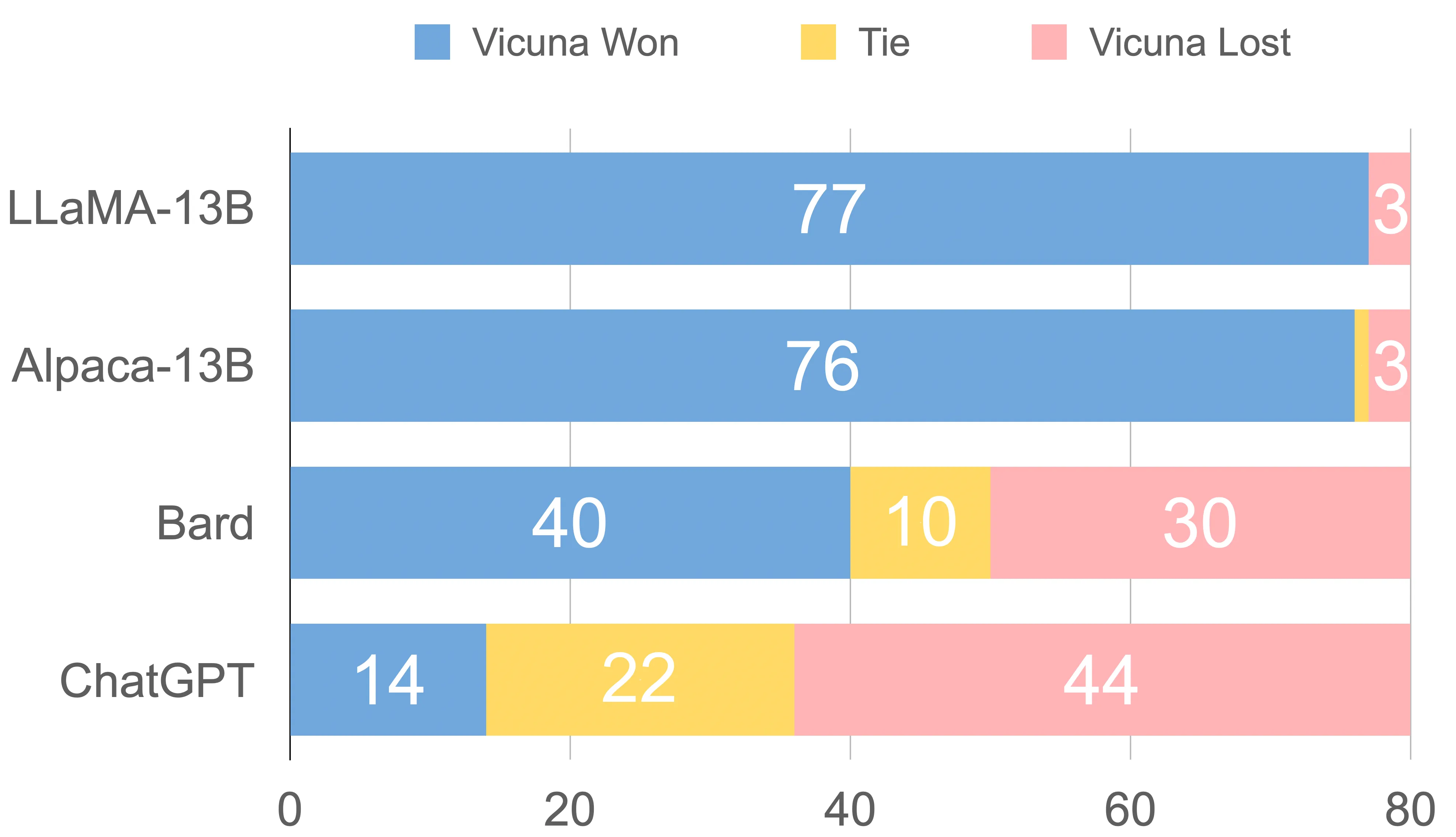
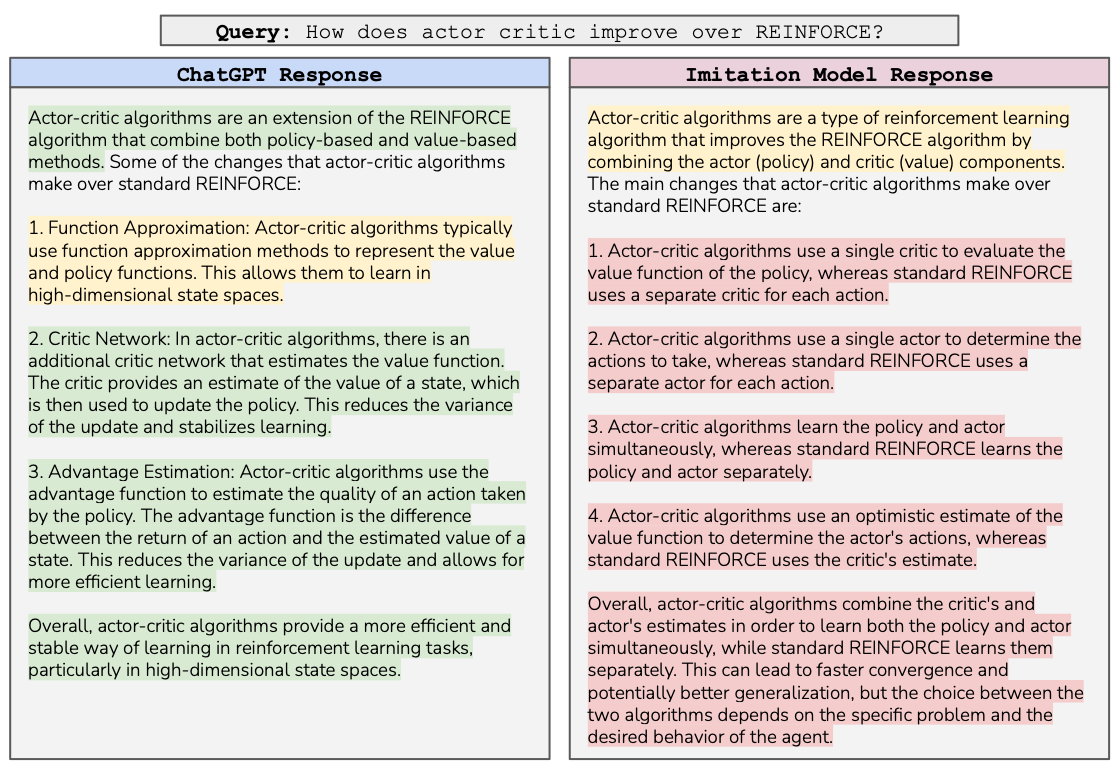
성능 : 위 그림에서도 볼 수 있듯이 sLLM은 LLM의 생성 스타일은 쉽게 모방하지만 실제 지식은 전혀 따라잡지 못하고 있음 (녹색 : 옳바른 생성, 노란색 : 애매한 생성, 빨간색 : 잘못된 생성)
-
평가 방식 : 실제 Human Evaluation 시 사람들은 생성된 문장의 Factual Knowledge를 검증할 수 없음
-
Contribution
-
본 논문은 이러한 최근 현상을 1) 지적하면서 2) sLLM 학습의 요소들을 분리하여 분석하고 3) 향후 sLLM 개선 연구의 방향에 대해 제안하고 있음
- 숫자로 보이는 성능에 열광할 것이 아니라 분위기를 가라앉히고 다시 시작하자.
2. Evaluation
-
해당 논문에서는 3가지 평가 방식 도입
-
Metric : 기존 데이터셋에서 제공하는 Metric을 이용하여 평가
-
GPT-4 : ChatGPT에게 Imitation Model과 ChatGPT가 생성한 문장을 입력하고, 선호도를 출력하도록 Prompt 구성
-
Human : Amazon Turk를 이용하여 70명의 응답자에게 두 모델이 생성한 문장 중 더 나은 문장을 고르도록 요구
⇒ Metric 방식을 제외한 두 방식은 RLHF의 Reward Model과 비슷한 방식으로 진행
⇒ Human과 GPT-4의 점수가 비슷한 경향을 보였다고 하는데, 자세한 내용은 소개 X
해당 논문에서는 모든 데이터셋의 모든 평가 방식의 평균을 담고 있음
4. Dataset
- 본 논문에서는 두가지 목적에 따라 Dataset 구축을 구분하여 사용
-
Task-Speicific Imitation : 특정 태스트에 대해서 sLLM이 LLM의 성능을 따라잡도록 학습하기 위한 데이터셋 구축
-
Self Instruct와 비슷하게 ChatGPT에게 In-Context 방식으로 Natural Questions 데이터에 대한 답변을 생성하여 구축
-
Broad-coverage Imitation : 실제 LLM 서비스처럼 광범위한 태스크들을 수행할 수 있는 범용적 목적의 sLLM 학습을 위한 데이터셋 구축
-
ShareGPT, HC3, Discord ChatGPT 채널 등 공개된 다양한 데이터셋 수집
-
기존에 사용자들과 ChatGPT가 나눈 대화를 수집한 것
-
해당 데이터를 모두 묶어 SharGPT-Mix라고 말함
- SharGPT-Mix의 경우 기존에 연구목적으로 구축되었던 Prompt 데이터셋인 NaturalInstructions 보다 높은 품질을 가지고 있다고 주장
⇒ 사용자 입력의 평균 BLEU 유사도가 8%에 불과
5. 모델
- Broad-Coverage Imatation
-
특정 태스크에 대한 성능 측정
-
학습 데이터의 크기와 모델 크기를 늘리는 실험 진행
-
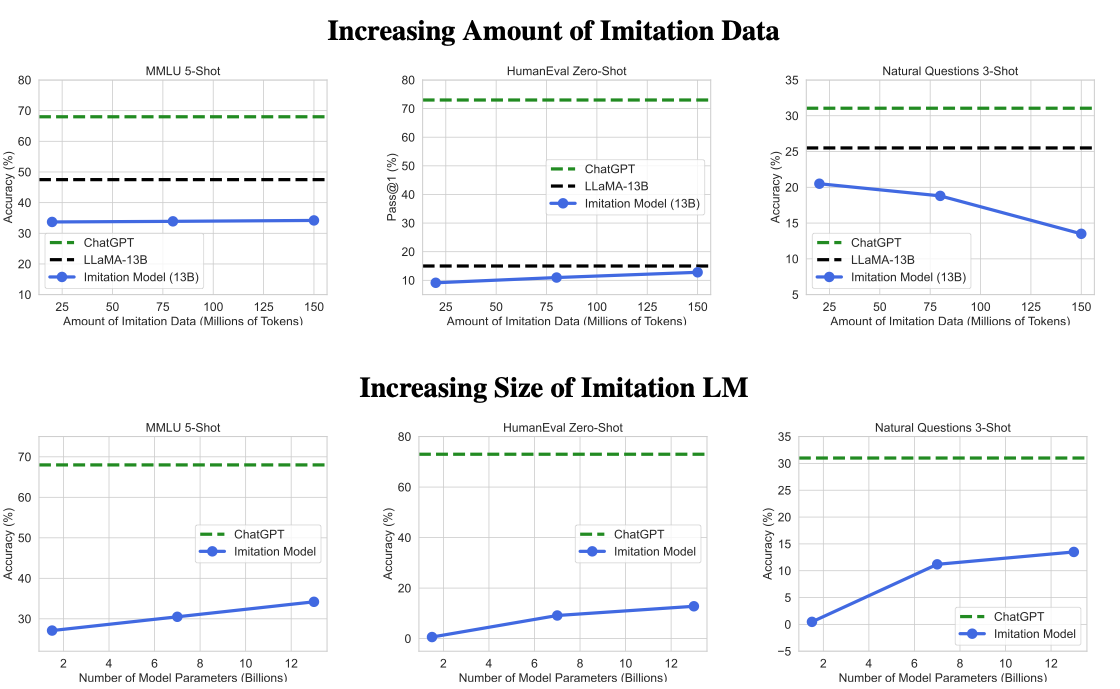
학습 데이터의 크기를 늘렸을 때(위) : 놀랍게도 SFT 학습 데이터 크기를 늘린다고 성능이 개선되지 않았다.
-
오히려 ShareGPT-Mix로 훈련되지 않은 기본 모델의 성능이 대부분의 경우 좋은 모습을 보이고 있다.
-
⇒ ChatGPT 모델에 비해 턱없이 작은 크기의 모델로 인해 발생하는 문제로 추측
⇒ ChatGPT 모델이 훨씬 더 많은 Knowledge를 내부 파라미터로 가지고 있기 때문에, 소수의 ShareGPT-Mix 데이터로 이러한 성능을 따라잡는 것은 불가능하다.
-
모델의 크기를 늘리는 실험 진행
- 모델 크기가 커지면서 점차 성능이 나아지는 모습 관찰 가능
⇒ 학습 데이터 실험 결과와 맥락을 같이하는 결과
⇒ base 모델이 가지고 있는 Knowledge가 많고, 성능이 우수해야 결국 General-Purpose 모델로 활용될 수 있음
- Broad Model - Broad Task
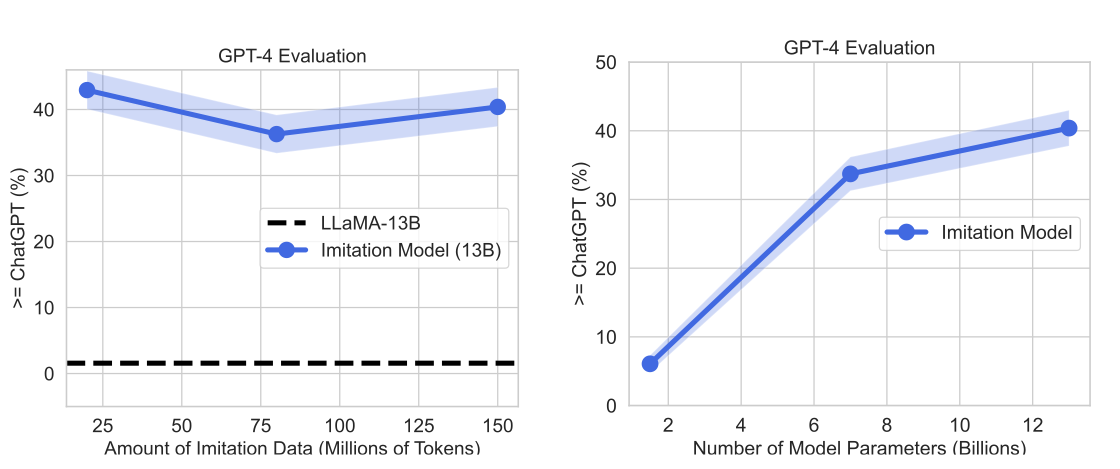
-
General한 태스크에 대해 성능을 측정하기 위해 SharGPT-Mix 데이터셋의 일부를 평가 데이터로 사용
-
학습 데이터 실험(좌)
-
학습 데이터셋의 크기가 늘어난다고 성능이 향상 되지는 않음
-
다만, SFT를 이용한 Prompt 데이터에 대한 학습 여부는 성능에 큰 영향을 미침
-
-
모델 크기 실험(우)
- 모델 크기가 커질수록 더 높은 성능을 달성하는
⇒ base 모델의 성능이 보장되어야 충분한 학습 효율을 달성할 수 있음
- Targeted Data에 대한 학습
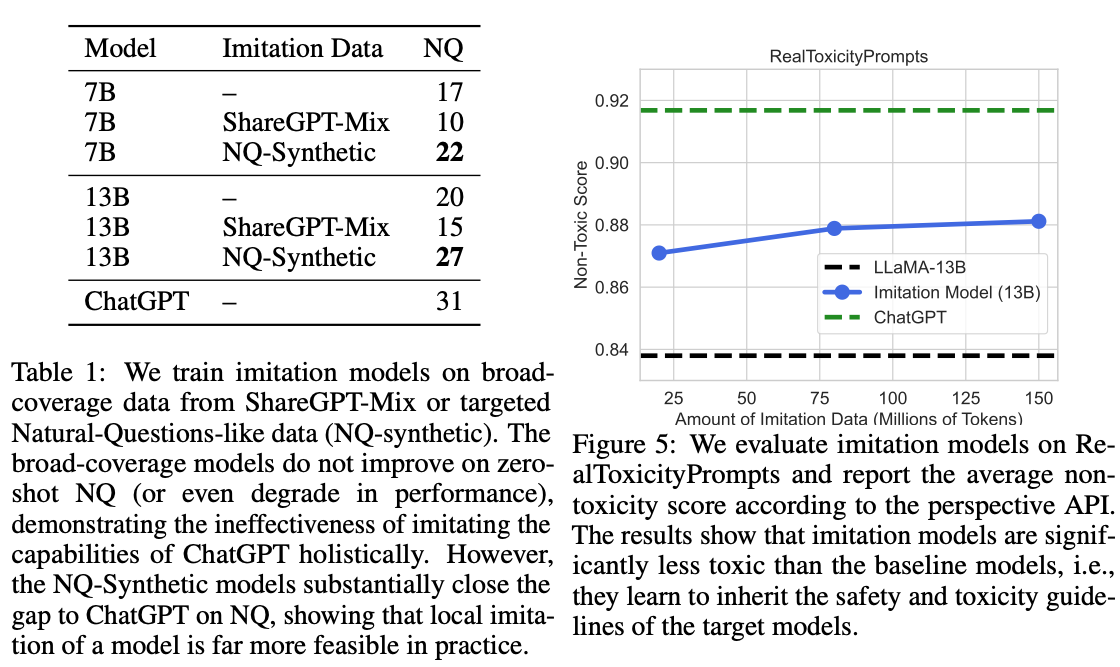
-
Taget 데이터와 범용(ShareGPT) 데이터로 학습한 실험 결과
-
ShareGPT 데이터로 학습한 모델보다 NQ 데이터로 학습된 모델이 훨씬 높은 성능을 보이고 있음
-
1번 실험과 함께 생각해보면, 결국 범용적 목적의 모델로서 SFT는 좋은 선택지는 아니지만, 특정 태스크에 대한 모델로서 SFT를 이용한 sLLM은 좋은 선택지가 될 수 있음
-
-
sLLM은 스타일을 학습
-
ShareGPT-Mix로 훈련된 모델에 대한 Toxity 평가(우)
-
base 모델에 비해 향상된 모습을 보이고 있음
-
Toxity는 결국 스타일과 관련된 이야기
-
욕설, 문장 길이, 답변이 불가능한 Prompt 등
-
-
ChatGPT가 학습한 이러한 스타일을 모델은 잘 학습하는 모습
- 특히 학습 데이터가 커질수록 이러한 스타일은 지속적으로 학습하는 모습을 보이고 있음
-
6. 결론
- 요약하면 결국 : 범용 목적의 모델은 아직 sLLM으로 도달할 수 있는지 의문이다.
⇒ 하지만 특정 태스크를 위한 모델은 충분히 sLLM으로 개발이 가능하다.
-
Human Evaluation에 대한 문제점을 지적한 점은 좋은 듯
- 하지만 이에 대한 구체적인 논리 및 증명이 부족한 상황
-
base 모델의 성능이 좋아야 Imitation 자체가 잘 진행된다고 귀결됨
- 모델의 크기를 늘리지 않으면서 기본 성능을 올릴 수 있는 방법이 있는가…?
-
LLM 개발하는 대기업 측면에서 오히려 걱정할 지점이 많아진다고 생각
- Safety를 위해 열심히 개발했더니, 단순히 SFT를 통해 따라잡을 수 있다.