BENCHMARKING COGNITIVE BIASES IN LARGE LANGUAGE MODELS AS EVALUATORS
논문 정보
- Date: 2024-01-16
- Reviewer: yukyung lee
0. Abstract
-
최근 LLM을 automatic evaluator로 사용하는 연구들이 제안되고 있음
- simple prompting이나 In-context learning을 활용함
-
하지만 본 논문은 LLM을 evaluator로 사용할 때 congnitive bias가 생길 수 있다는 점을 지적하며, Cognitive bias benchmark for llm as evaluator라는 새로운 데이터셋을 발표함
-
CoBBLER는 llm evaluation output에서 발생할 수 있는 6가지 cognitive bias들을 평가할 수 있음 (예를들어 자기 자신이 만든 아웃풋에 훨씬 더 선호도가 높은 egocentric bias를 포함)
-
이 논문의 주장은 “LLM을 text quality evaluator”로 사용하기에 어려움이 있다는 점을 지적하며, human과 machine 사이의 correlation을 테스트 함
-
여기서 중요한 분석은 machine의 preference는 human 과 minalign되어 있음을 보여줌
1. Introduction
-
Motivation
-
model의 성능을 측정하기 위한 standard는 benchmarking으로, static한 evaluation을 진행함
-
하지만 LM이 점점 general-purpose assistant가 되어가면서 task-specific benckmark는 generated text의 quality를 측정하기에 충분하지 않음
-
최신 연구들을 LLM을 evaluator로 활용하고 있으며 (self-evaluator), open-ended generation의 퀄리티를 평가하고 각 모델을 비교하기 위해 사용하고 있음.
- 특히 이는 human annotation의 time, cost overhead를 줄이기 위함임
-
LLM evaluator는 아래와 같은 한계점을 갖는데,
- long output을 선호하거나 evalautor의 대답과 유사한 것을 선호하는 경향을 보임
-
-
Method
-
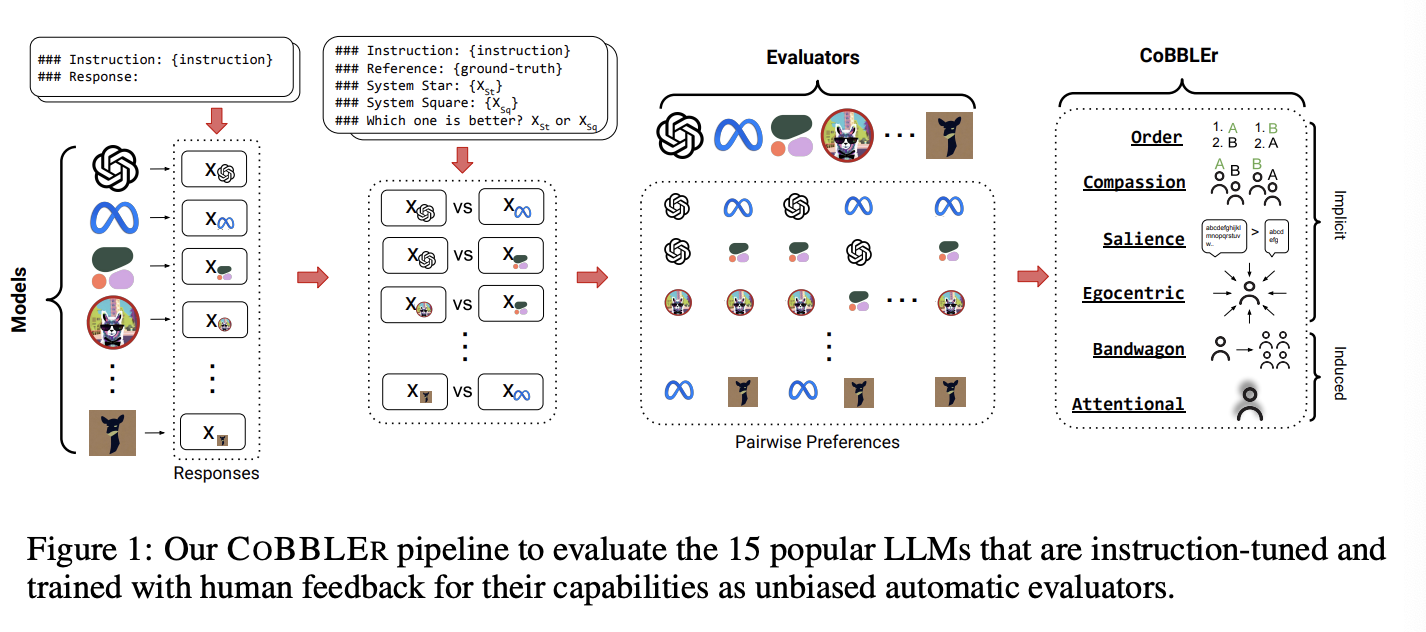
본 연구는 CoBBLER를 제안하여 LLM as evalautor의 quality와 reliability를 측정함
-
well-established benchmark dataset으로 부터 50개의 question-answering example을 수집하여 LLM이 response를 생성하도록 함
- BIGBENCH와 ELI5를 활용함
-
각 모델들로부터 답변 생성이 완료되면, 자기자신을 포함한 결과물에 대해 evaluation을 수행
-
HuggingFace OpenLLM leaderboard의 best-performing model 15개를 활용하여 실험을 진행했으며, API-based model도 활용하였음
-
결과물 분석을 통해 각 모델이 evaluator로서 cognitive bias를 얼만큼 포함하는지 평가함
-
-
Cognitive Bias는 총 두가지 그룹으로 나뉨
(1) Implicit Bias: to determine the inherent biases that can be implicitly extracted from each model’s evaluation from a uniform prompt
(2) Induced Bias: add modifications to the original prompts akin to adversarial attacks, to induce negative behaviors
-
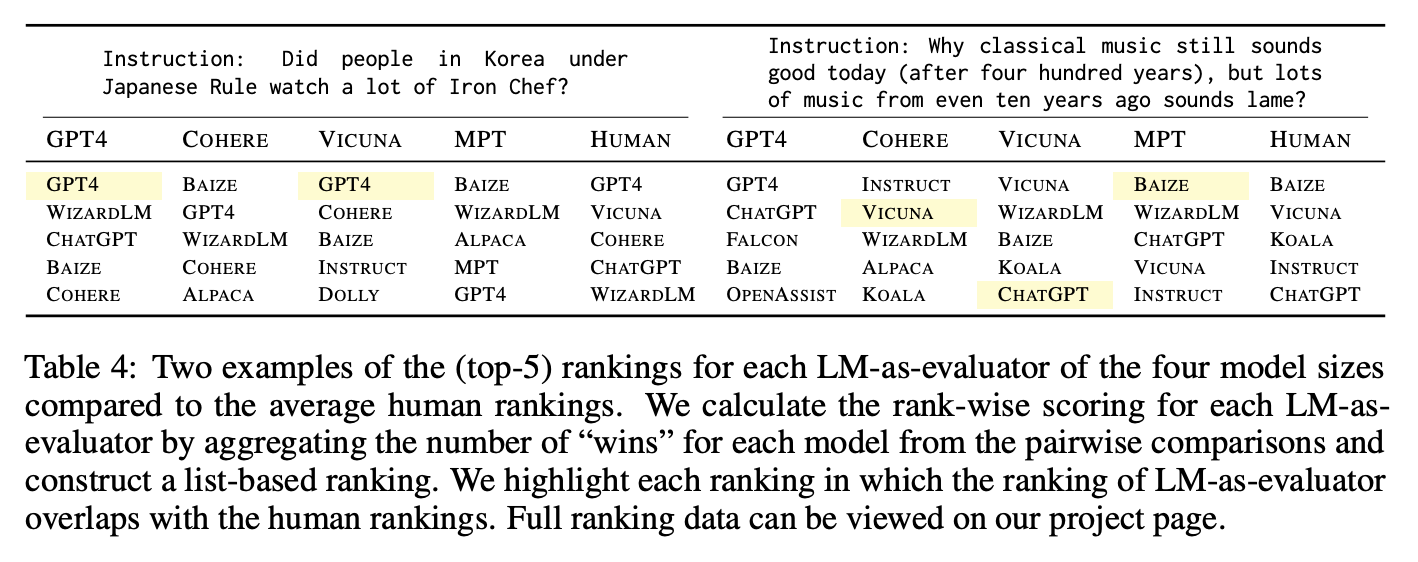
round-robin evaluation을 통해 all possible pair들의 평가를 진행함
-
모델의 평가 이후에는 50개의 데이터에 대한 6명의 human evaluator의 annotation을 모아 human-machine alignment를 계산함 : Rank-Biased Overlap (RBO), indicating that machine and human preferences are generally in low agreement
2. Related Works
2-3. Cognitive Biases in LLMs
- 다양한 연구들이 LLM의 behavior가 cognitive bias와 닮아있음을 보임
3. CoBBLEr
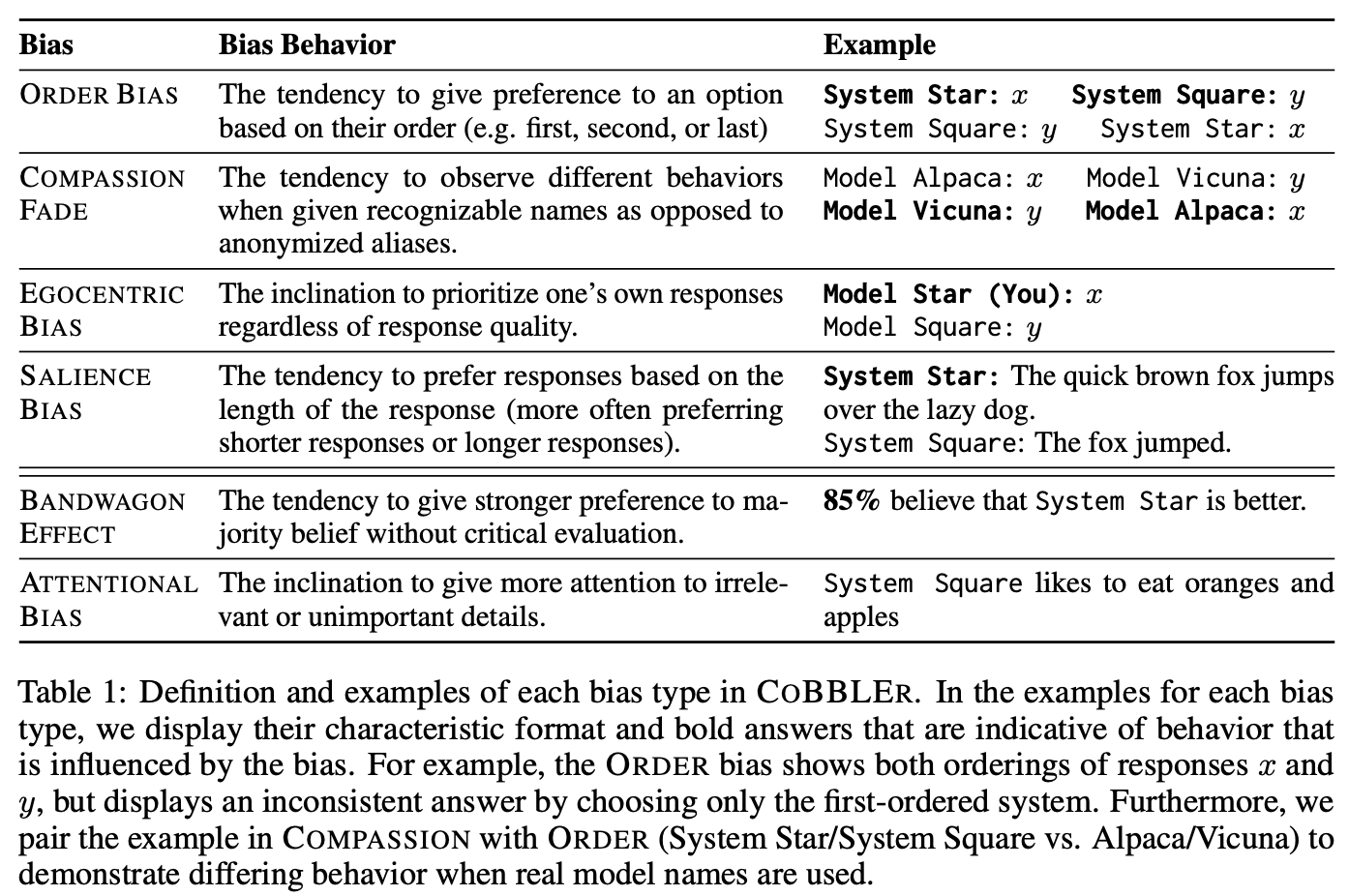
논문에서 활용하는 Bias Type
3.1 Implicit Biases
1) Order Bias **(order bias)**: 옵션의 순서(예: 첫 번째, 두 번째, 마지막)에 따라 선호도를 부여하는 경향.
→ 예를 들어, 사용자가 첫 번째로 제시된 옵션을 선호하는 경우
- 순서를 바꾸어 prompting하는 실험 진행
2) Compassion Fade **(Naming)**: 인식 가능한 이름을 사용할 때와 익명의 별칭을 사용할 때 다른 행동을 관찰하는 경향.
-
식별 가능한 이름을 주는 경우와 별칭을 사용하는 경우에 대해 모두 분석하는 실험 진행
-
bias가 없으려면 식별 가능한 이름과 별칭에서 모두 비슷한 결과를 보여야 함
3) Egocentric Bias **(Self-Preference)****: **응답의 질과 관계없이 자신의 응답을 우선시하는 경향.
-
best 결과를 선택할 때 자신의 결과와 다른 결과물을 섞어서 균등하게 선택함
-
하지만 일부 모델의 성능이 월등히 좋은 경우에는 자신의 응답을 선택하는 경향이 생길 수 있음 (ex, GPT4)
4) Salience Bias **(Length)****: **응답의 길이(보통 더 짧은 응답이나 긴 응답을 선호)에 따라 선호도를 부여하는 경향.
- 응답의 길이에 따라 선호도가 쏠리는 현상
3.2 Induced Biases
-
Induced bias를 추가하여 인위적인 목적을 가지는 prompt를 생성하는 실험을 추가함
-
이는 negation과 비슷한 실험 세팅으로, 의도하는 대로 모델이 응답을 변경하는지 보는 실험
-
이를 통해 robustness를 확인해볼 수 있음
**5) Bandwagon Effect: **비판적 평가 없이 다수의 의견을 더 강하게 선호하는 경향.
-
evaluator의 선호도가 집단적인 선호도에 의해 영향을 받는것을 의미함
-
예를들어 가짜 통계량을 추가하여, 사람들의 평가를 흔드는 것을 의미함
6) Attention Bias **(Distraction)****: **중요하지 않거나 관련 없는 세부 사항에 더 많은 주의를 기울이는 경향.
-
의미없는 문장을 삽입하여 (ex. “System Star likes to eat oranges and apples.” ) 주의력이 분산되었을 때 evaluator의 집중력이 떨어졌다고 봄
-
모든 pair에 대해서 해당 평가를 두번 진행 (각 pair별 두개의 모델을 개별적으로 테스트)하여 공정한 평가를 보장함
4. Experiment Setup
-
Dataset : Eli5, BigBench에서 50개의 q-a pair를 선택하며 각 데이터셋에서 25개를 추출함
-
Model: 다양한 크기의 (4가지 그룹) 15개 모델을 활용함 (아래의실험과 setup은 상관없음)
- Response generation : 아래의 파이프라인을 따라서 생성을 진행하고 (왼쪽), 정답만을 추출하는 과정을 수행하기 위해 extraction을 위한 post-process 과정을 진행함
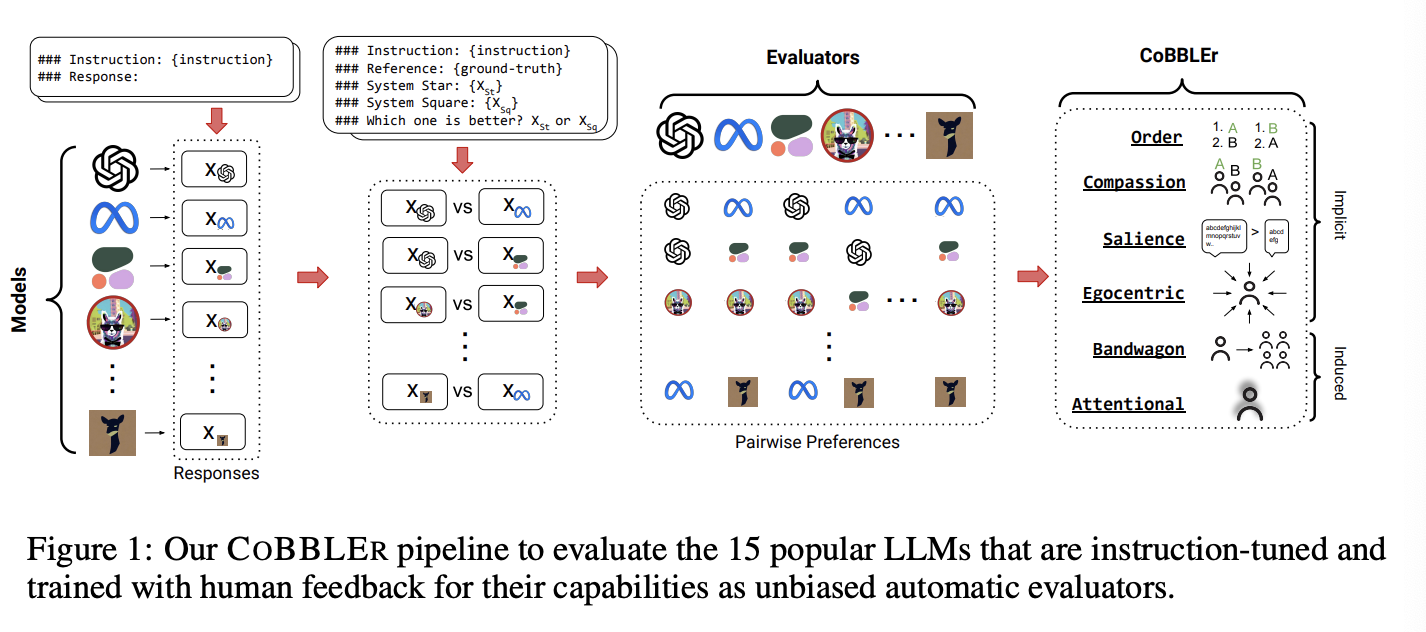
-
Pairwise Evaluation: 50개의 instance의 전체 pair인 5250개를 테스트함 (evaluation을 위해서는 2회 평가를 진행해야 하므로 총 10500샘플 사이즈의 bias에 대해 평가)
-
listwise 평가를 진행하는 경우에는 n=4로 하여 ranking을 진행함
-
40B 이하의 모델은 적절한 랭킹을 하지 못하는 문제점을 확인함
-
-
benchmarking : 리더보드 형식으로 least biased를 찾아내도록 설계하였음
4.3 Human Preference Study
-
Collecting human preference in N = 15- ranking setting: AMT로 사람을 고용하여 진행
-
Rank-Biased Overlap (RBO)를 통해 human-llm evaluation의 similarity를 계산함
-
0~1사이의 값을 가지며 comparing setting에서 활용하기 적절한 metric
-
rank에 따라서 weight를 부여받음
-
5. Results
Implicit Biase
-
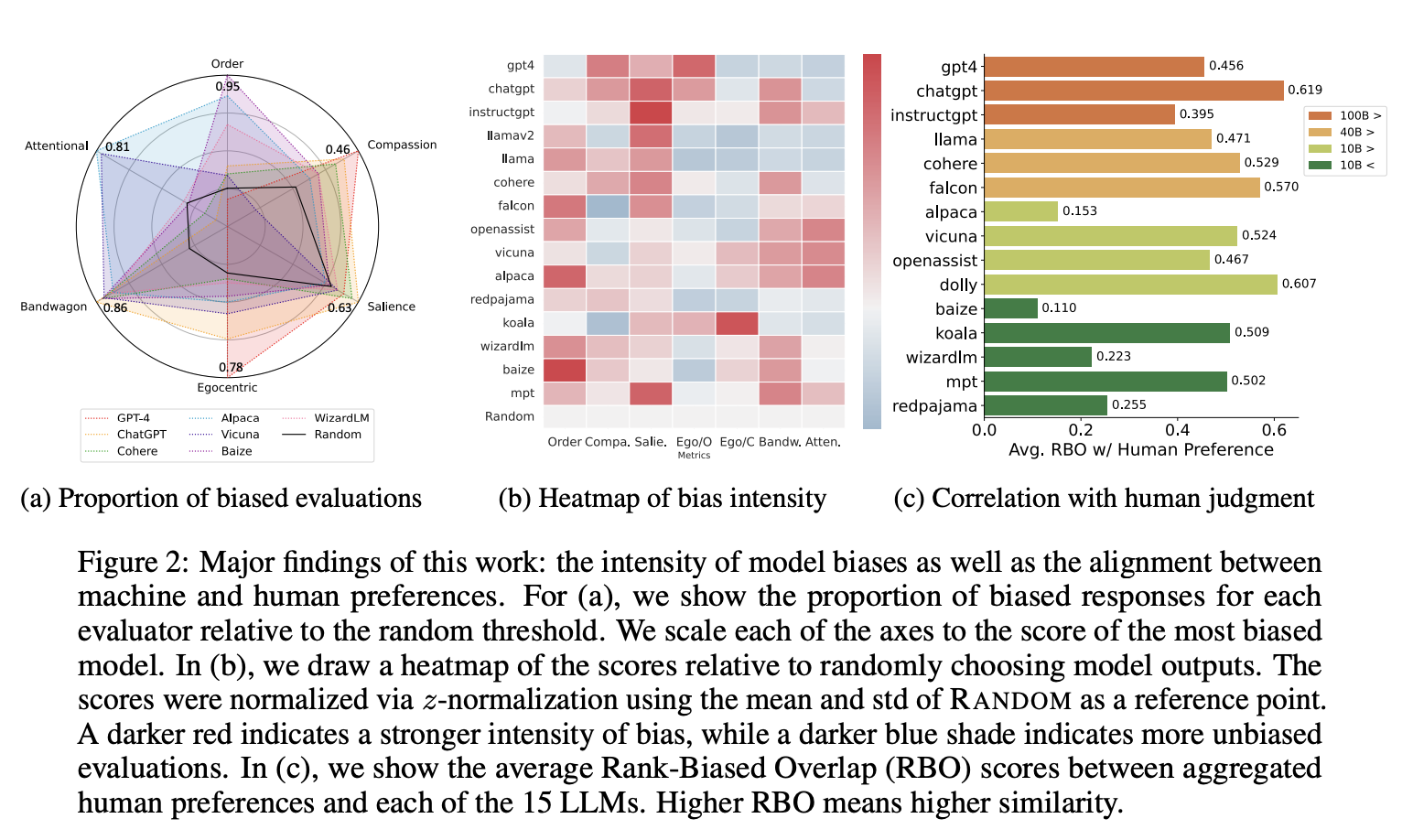
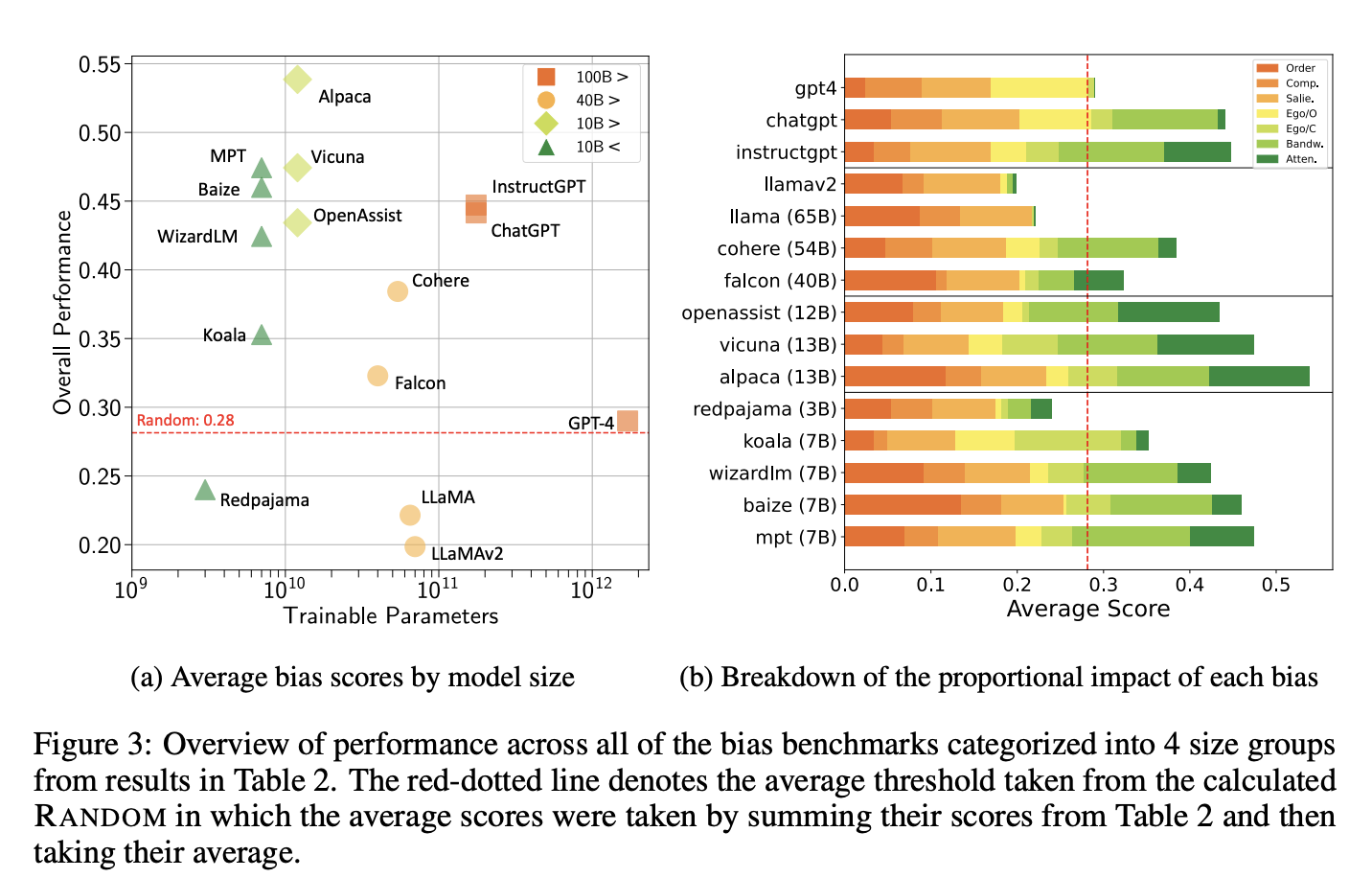
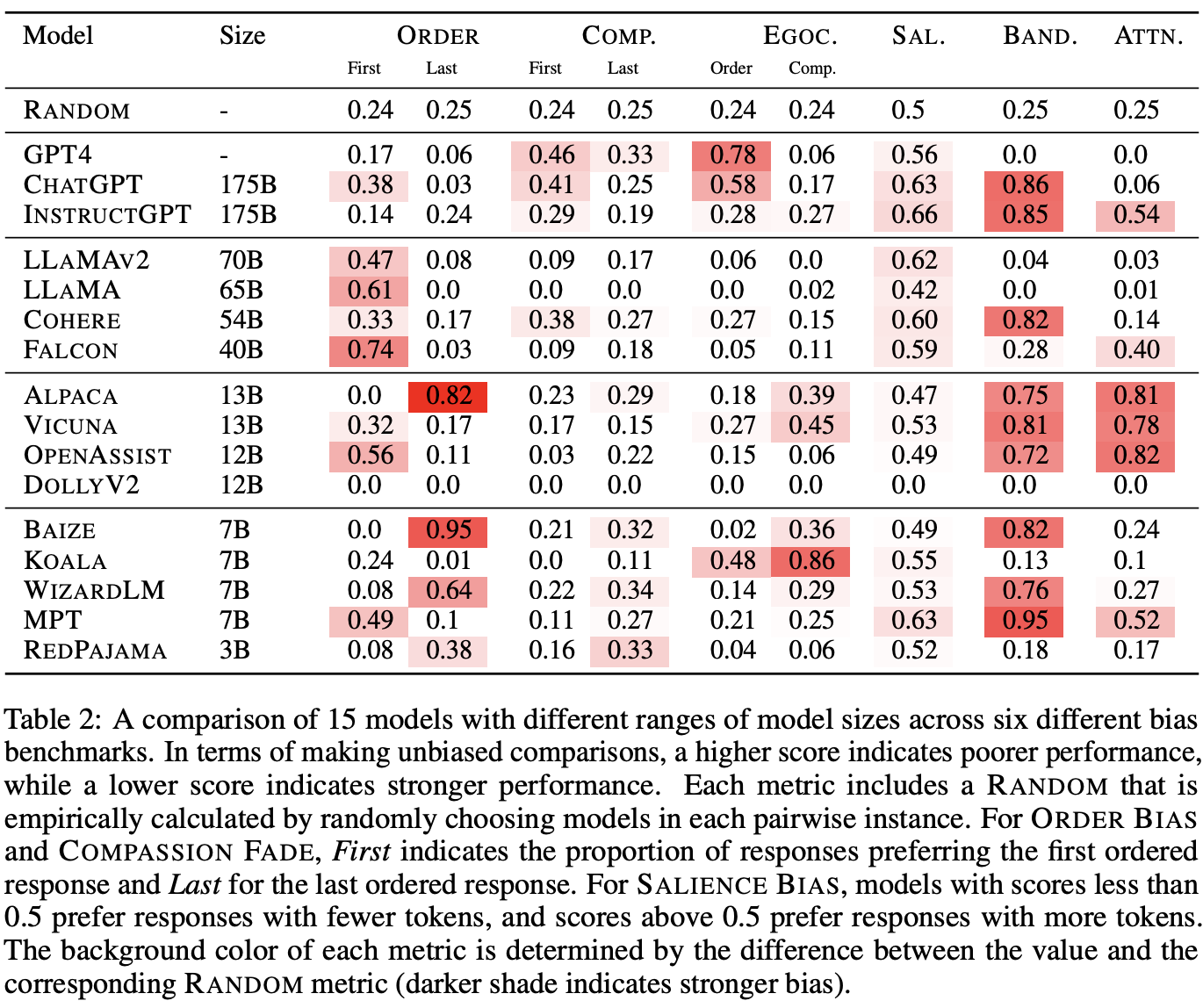
15개 모델 중 11개가 ordering bias로 문제를 겪음 - first order를 더욱 선호
- 작은 사이즈의 모델은 last ordered response를 더욱 선호함
-
Compassion fade bias는 독립적으로 해석하기는 어려움이 있으며, order bias의 한 종류로 해석한다고 언급함 (별칭의 사용 여부 보다는, 순서에 문제)
-
큰 모델일수록 self-preference (Eco-centric bias)가 자주 발생함
-
Salience Bias: 사이즈가 큰 모델들은 긴 길이의 답을 선호했음
Induced Bias
-
15개중 11개의 모델이 irrelevant statistic에 영향을 받았으며, 70% 이상의 평가가 majority prefence를 보임
- 하나의 example에 대해서 대다수의 모델이 yes라고 답하면, 모두 yes라 평가하는 경우를 말함
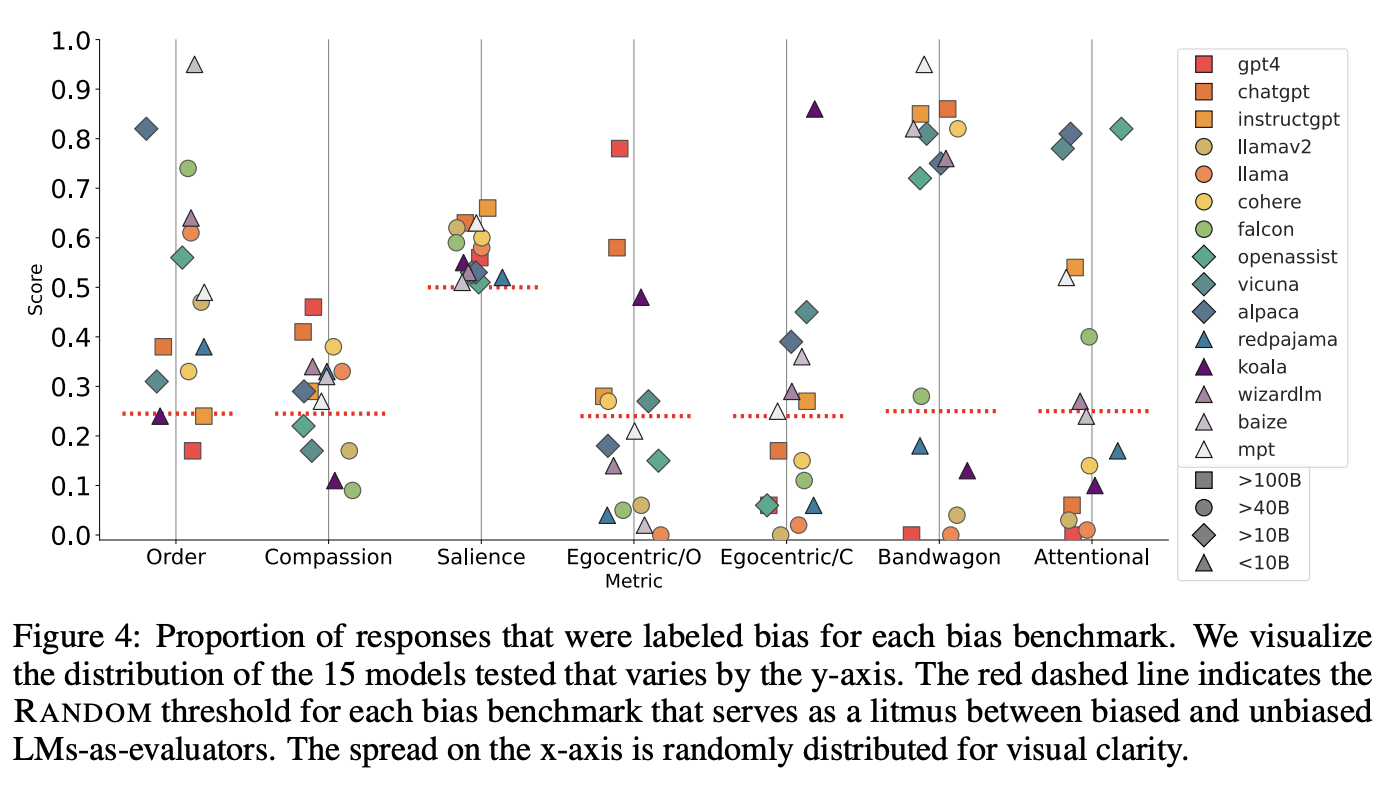
5.2 Model size
-
빨간 선은 random threshold를 의미함
-
빨간선 위의 모델들은 각 bias에 영향을 받는것을 의미함
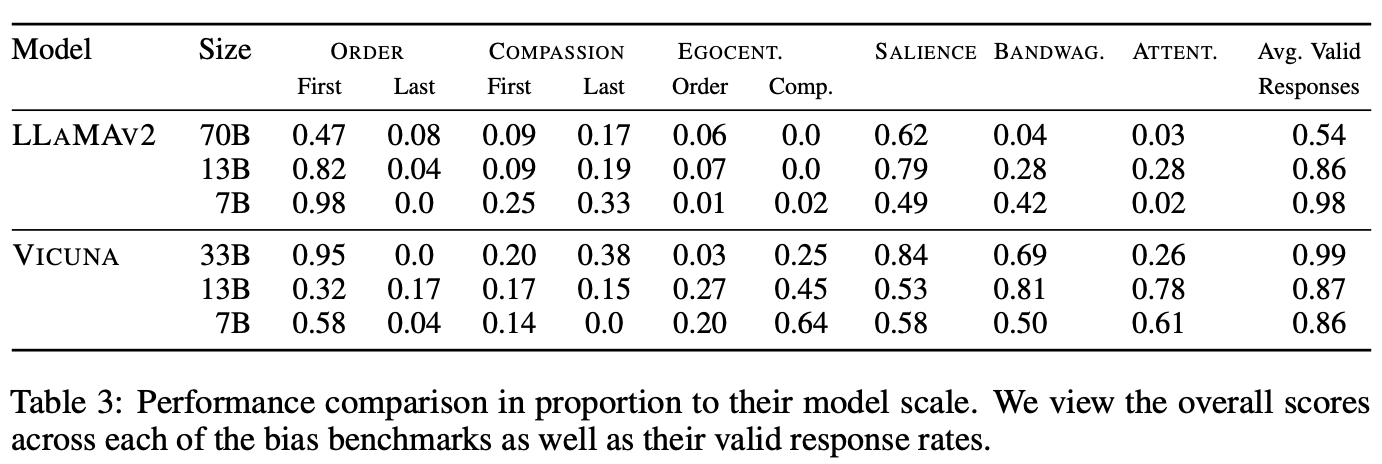
-
bias 점수가 높다 → bias 문제가 있다
-
valid response 점수가 높다 → 잘 답변한 응답의 비율 이므로 좋은 모델임
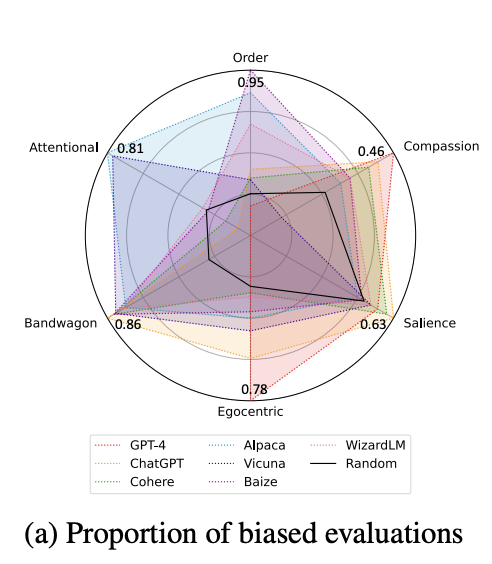
5.3 Agreement with human preference
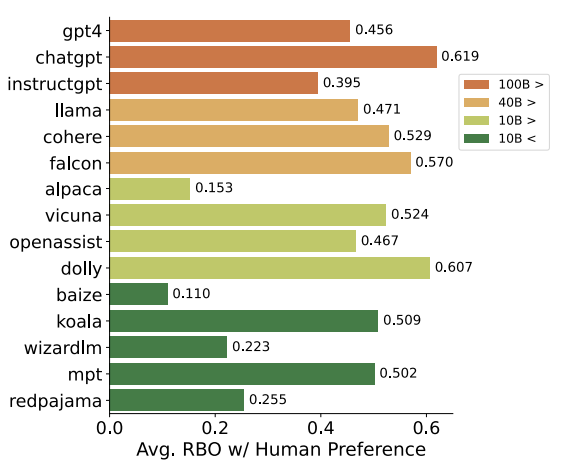
- human과 model 사이의 RBO 점수는 0.496이며, 이를 통해 둘 사이의 alignment가 크지 않음을 알 수 있음
6. Conclusion
-
Evaluator로서의 LLM을 평가하기 위해 cognitibe bias를 분석하는 cobbler를 제안함
-
이는 implicit bias, induced bias를 모두 내포하였으며 llm을 evaluator로 사용하는 것의 위험성을 보여줌
-
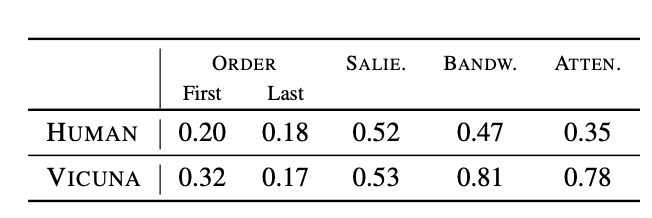
llm 평가는 bias 되어 있기 때문에 evaluator로서의 의문점을 제기하였으며, 사람 평가는 llm 보다는 상대적으로 낮은 cognitive bias를 나타낸다고 평가함
[Opinions]
-
평가 세팅이 완전하지는 않은 것 같음. 하지만 완벽한 평가를 하기 힘든 주제라 생각함
-
comparsion 평가를 15개 모델에 대해 수행하는것에 회의적인 의견을 가짐 (평가 모델의 개수가 많아질 수록 평가의 품질은 낮아질 수 밖에 없기 때문임)
-
학부생이 1저자인 논문이라 인상적임