BitNet: Scaling 1-bit Transformers for Large Language Models
논문 정보
- Date: 2024-03-11
- Reviewer: 김재희
- Property: LLM, Quantization
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
1. Intro
BitNet
-
1-Bit(1 or -1) parameter로 scratch부터 학습
-
기존 LLM 대비 적은 Inference/Train Cost를 가짐
-
기존 Post Quantization 방법론 대비 높은 성능 기록
1-Bit
-
1.58Bit(1,0,-1) parameter로 scratch부터 학습
-
동일 파라미터를 가지는 LLaMA 구조 대비 높거나 비슷한 성능 기록
-
(1,0,-1)의 상태를 가지는 bit 구조를 이용한 하드웨어 설계를 통해 모델 학습/추론 파이프라인 최적화 방향성 제안
결론
-
정말 제대로 동작하는지 잘 모르겠음
-
최근 LLM과 엄밀한 비교 수행 X
-
1-Bit는 결국 더이상의 Quantization 불가
→ FP32/FP16/BF16의 모델들과 정확한 성능 비교가 필요
재밌는 아이디어이지만 이 방법론이 미래인지는 더욱 검증이 필요 ⇒ 70B의 1-bit가 knowledge를 제대로 담을 수 있을까? ⇒ Instruction Tuning과 같이 복잡한 태스크를 학습할 수 있을까?
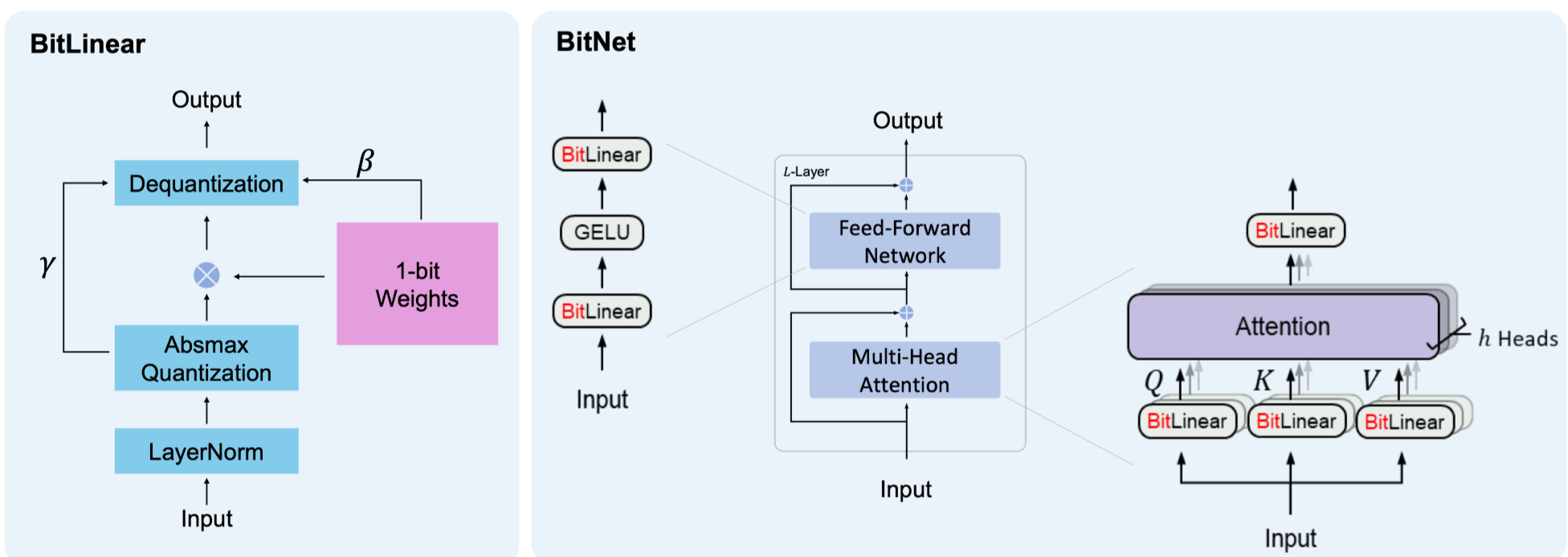
2. BitNet
Architecture
-
Transformer의 일부 레이어를 1-bit로 quantization하여 사용(original weight가 존재)
-
Linear 레이어: 1-Bit(1,-1) quantization
-
이외 레이어: 8-bit quantization으로 연산 진행(attention, …)
-
Input/Output Embedding: high precision으로 진행(16 or 32 bit)
-
→ Sampling을 위해서는 high-precision이 필요하기 때문
-
BitLinear: 기존 Transformer 구조에서 연산량이 막대한 Linear Layer를 대체
-
Input: 8 bit quantization
-
Input Quantization: AbsMax Quantization 사용(Q_b: quantize할 데이터 범위)
-
⇒ 벡터를 max로 normalizing 후 부호만 남김
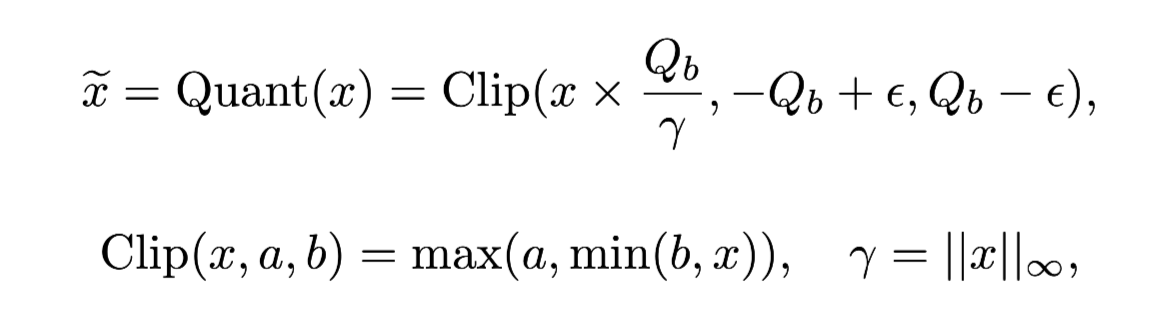
-
Input for Non-Linear Function Quantization
- Activation Function(GELU)의 입력의 경우 범위를 [0, Q_b]로 제한
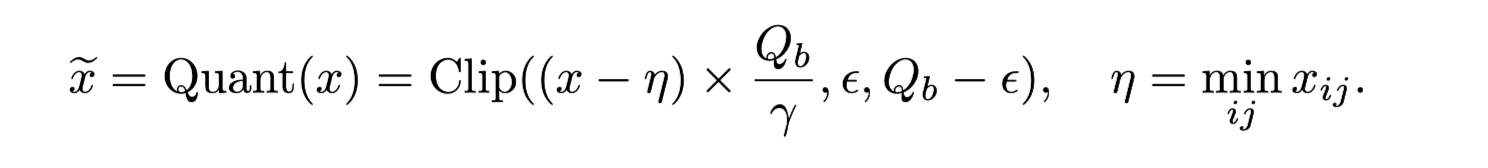
-
Linear: 1 bit quantization
- weight의 평균 대비 크기 비교를 통해 Quantization 실행
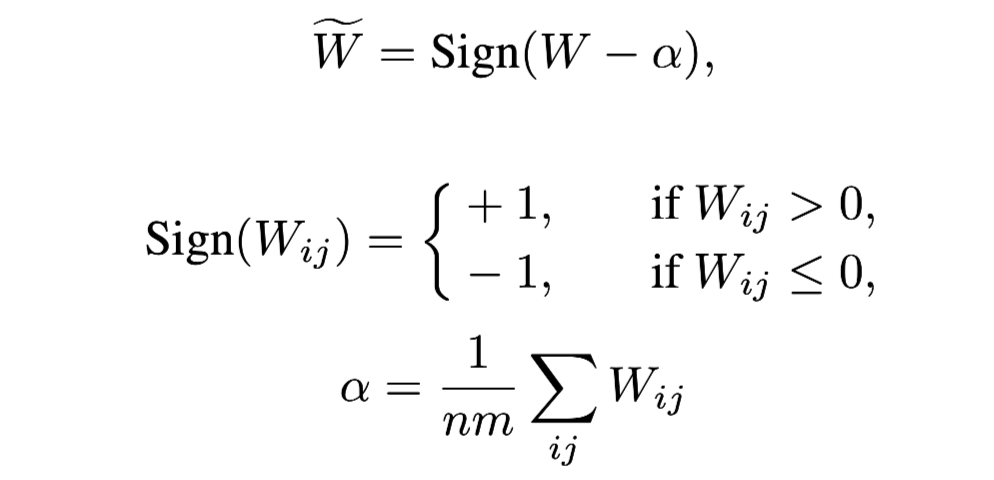
-
Matrix Multiplication: Quantized Linear와 Quantized Input은 단순 연산을 통해 계산 가능
- 하지만 이대로 수행한다면 기존 LLM의 Layer Norm이 사라짐
→ Layer Norm: 학습 안정화 및 발산 방지
- Input Quantization 이전에 Layer Norm을 적용
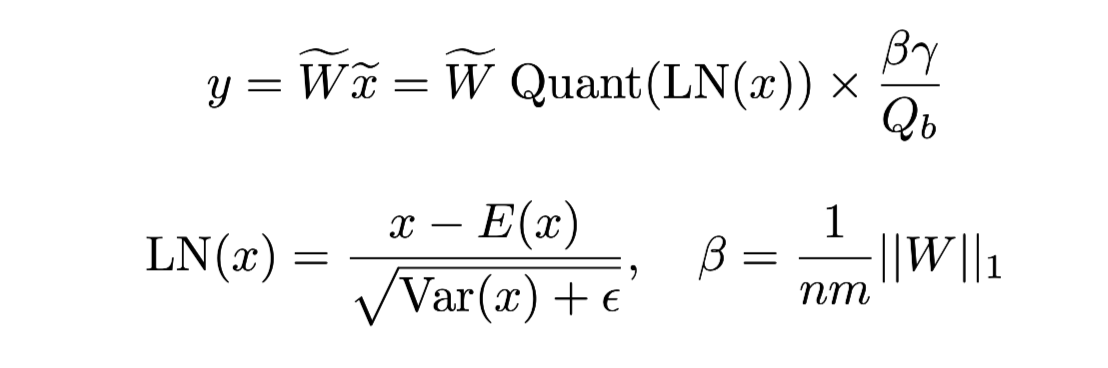
-
연산이 완료된 벡터는 다시 Quantization 시 계산 된 수치를 이용하여 Dequantization 진행 → Precision 복원
-
Pretrain 과정에서 Linear Layer의 연산량을 감소 및 속도 개선 가능
-
Distributed Training:
- 기존 Pretrain과 달리 Input 별로 Quantization 수치를 계산해야 함
⇒ 분산 학습 시 Machine 별로 독립적으로 계산 → Machine 간 통신 비용 감소
-
Mixed Precision Training
-
Forwarding 과정
- Linear Layer(FP16) 및 Sub-Module 별 Input에 대한 Quantization 진행
-
→ Low Precision(1Bit)으로 Fowarding
-
Backwarding 과정
- Gradient와 Optimizer 내 state은 모두 high precision 사용
→ FP16 Linear Layer weight 업데이트
-
High Learning Rate
-
1 bit로 Quantized 하다보니 Learning Rate가 낮을 경우 실제 weight에서 작은 변화가 발생
-
1.24214 → 1.24232
-
1 → 1
-
학습 효과가 forwarding 과정에서 반영 X
-
-
Learning Rate를 대폭 높혀 학습 진행
- 2.4e-3 ~ 4e-4
-
Experiments
-
FP16 Trasnformer와 비교
- 125m ~ 6.7b까지 Transformer와 BitNet을 scratch부터 학습하여 비교 진행
-
Quantization Method와 비교
- 기존 Post Quantization 방법론들과 비교 진행(w:weight precision a: input precision)
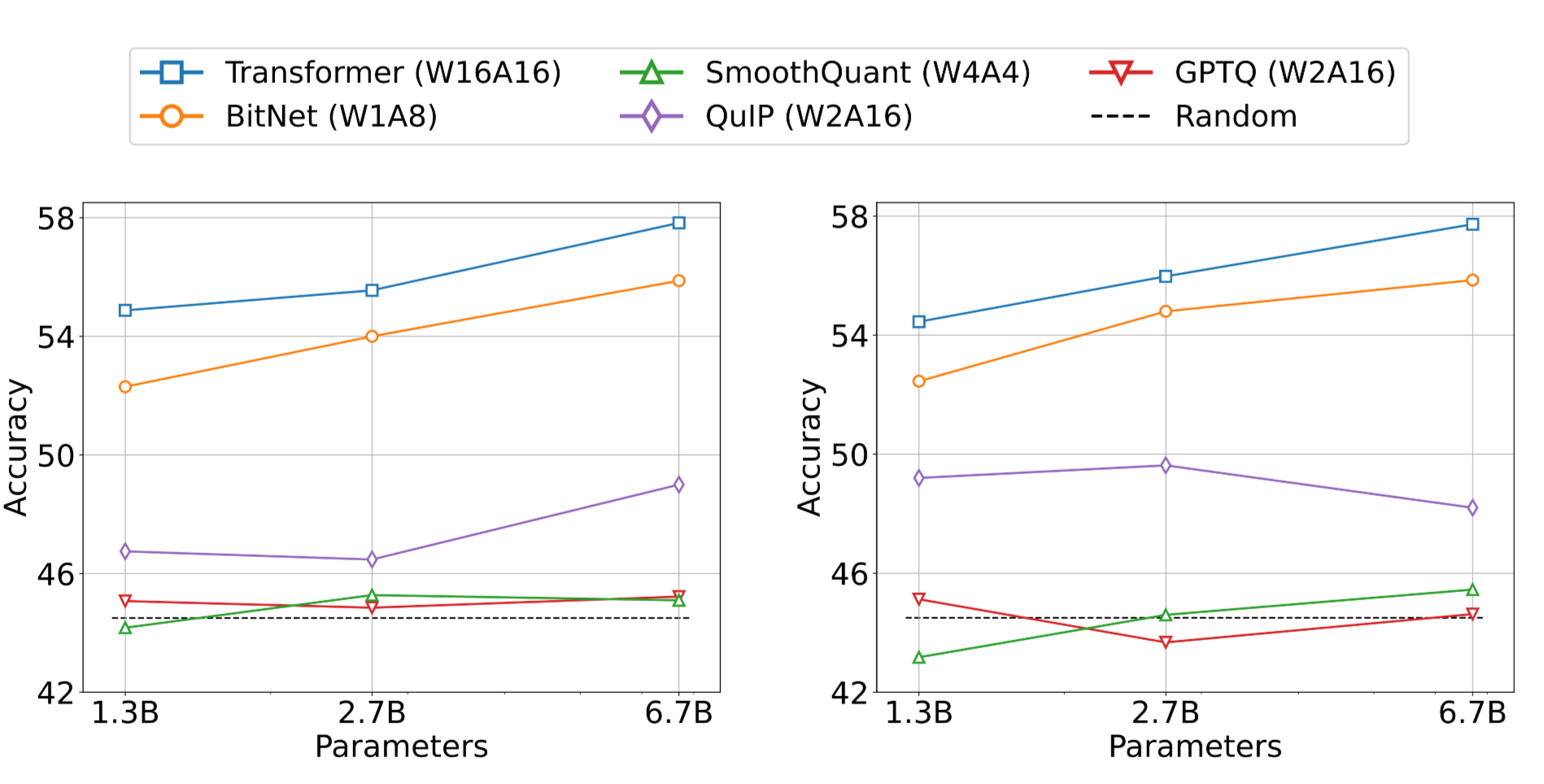
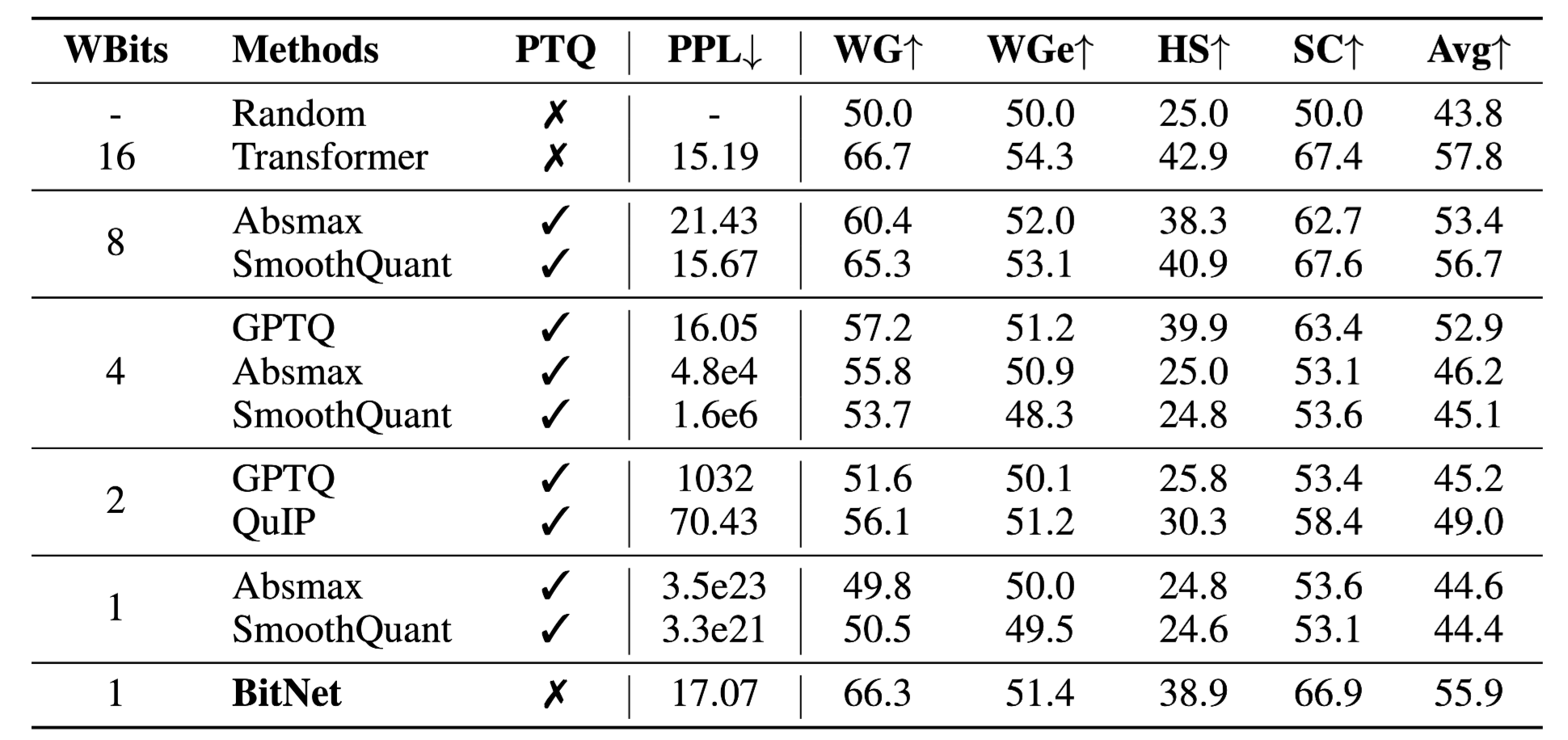
-
fp16에 비해서는 낮지만 quantization 방법론 대비 매우 높은 성능 달성
-
Energe Consumption 대비 성능 비교 (zero/few shot)
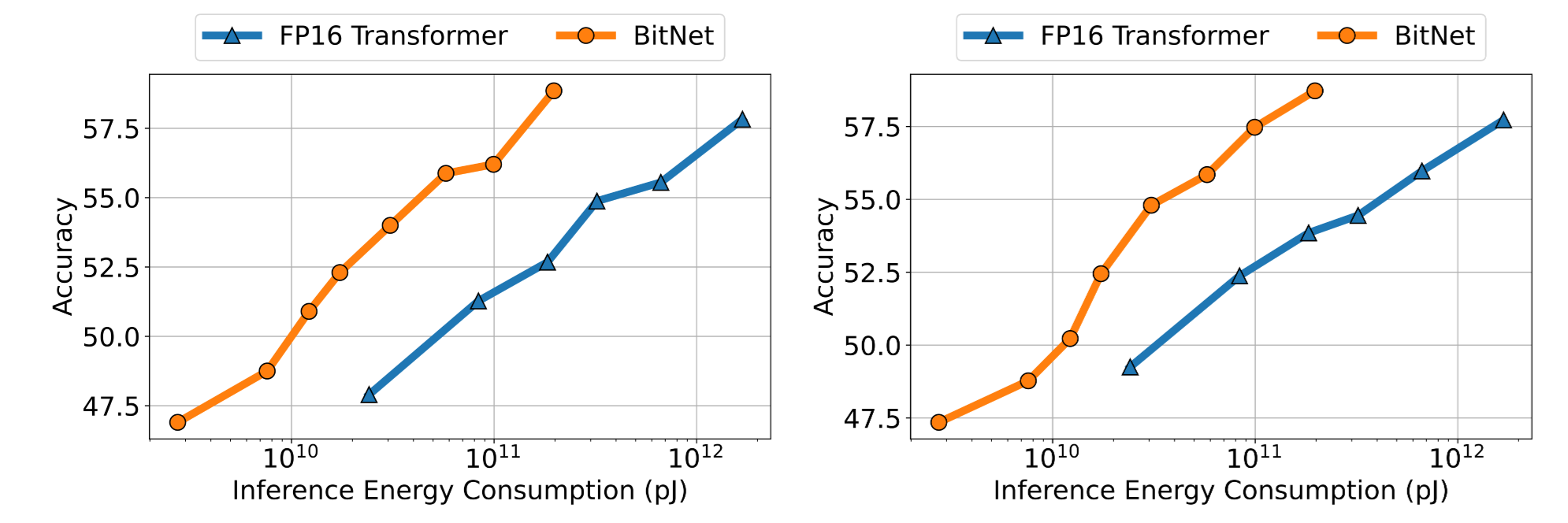
-
동일 에너지 사용 시 더 높은 성능 달성
-
동일 에너지 사용=fp16 대비 더 큰 모델 사용 가능
3. 1.58bit
Architecture
-
1.58 bit…?
-
bit= 정보량을 표현할 수 있는 이진분류 표기 체계 단위
-
1bit : (-1, 1)
-
0: -1
-
1: 1
-
-
2bit: (0,1,2,3)
-
00: 0
-
01: 1
-
10: 2
-
11: 3
-
-
만약 BitNet에서 0만 추가한다면?
-
weight를 통해 input의 정보를 사용하지 않도록 만들 수 있음
-
log_23 \approx 1.58
-
현재 하드웨어 상 구현: 2 bit 필요
-
00: 0
-
11: 1
-
01: -1
-
-
-
-
1.58bit: fp16과 비슷한 성능을 내면서 inference cost를 줄일 수 있는 방법
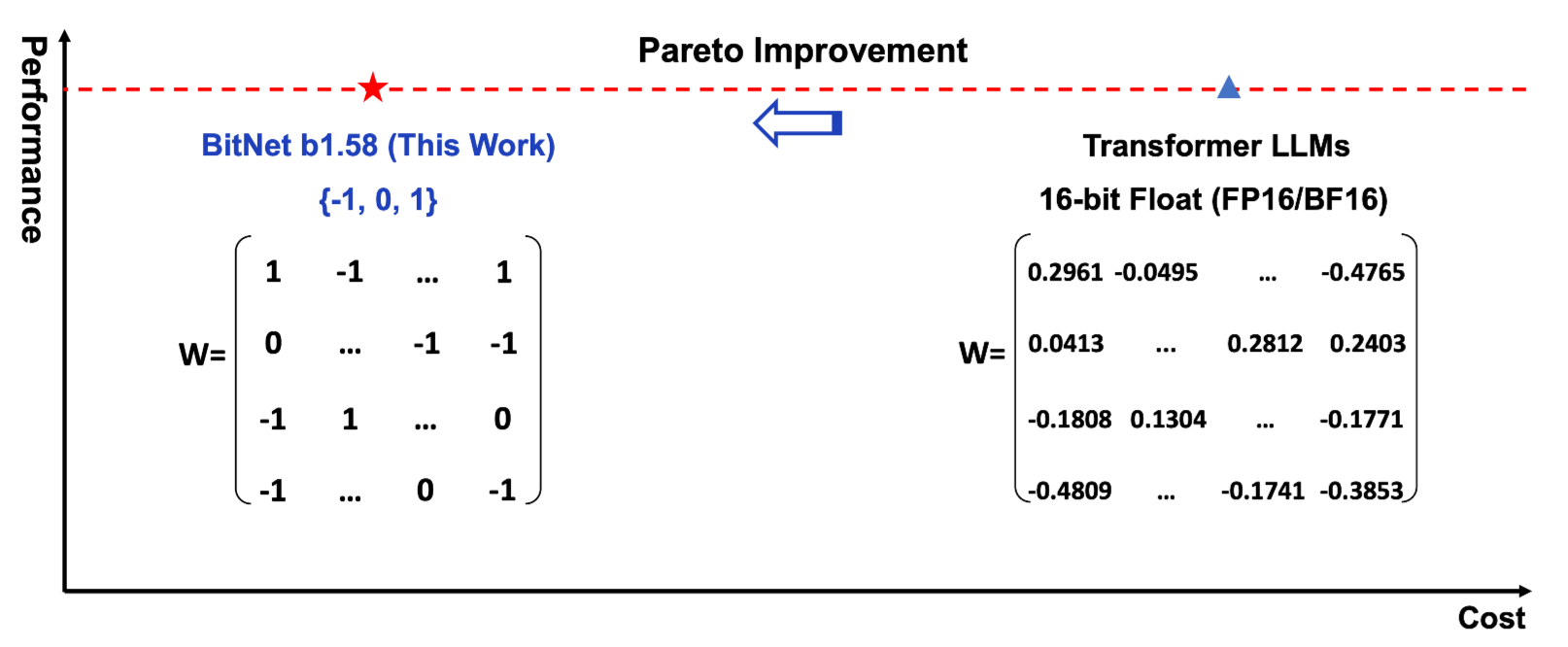
-
Modification: BitLinear 구조 거의 그대로 활용
- AbsMean Quantization 사용 (-1, 0, 1로 quantization)
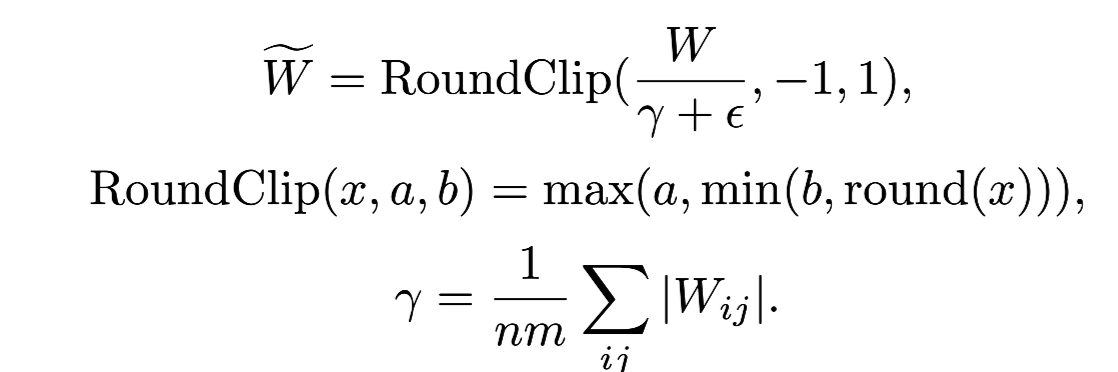
-
non-linear function 입력에 대한 scaling
-
BitNet: [0,Q_b]
-
1.58B: [-Q_b, Q_b]
-
-
모델 구조: LLaMA configuration 사용
Experiments
-
LLaMA Configuration을 이용하여 FP16 Transformer/1.58B scratch부터 학습
-
StableLM-3B에서 사용된 데이터 사용(data recipe)
- 2T token 학습
-
메모리 및 latency와 PPL 간 비교
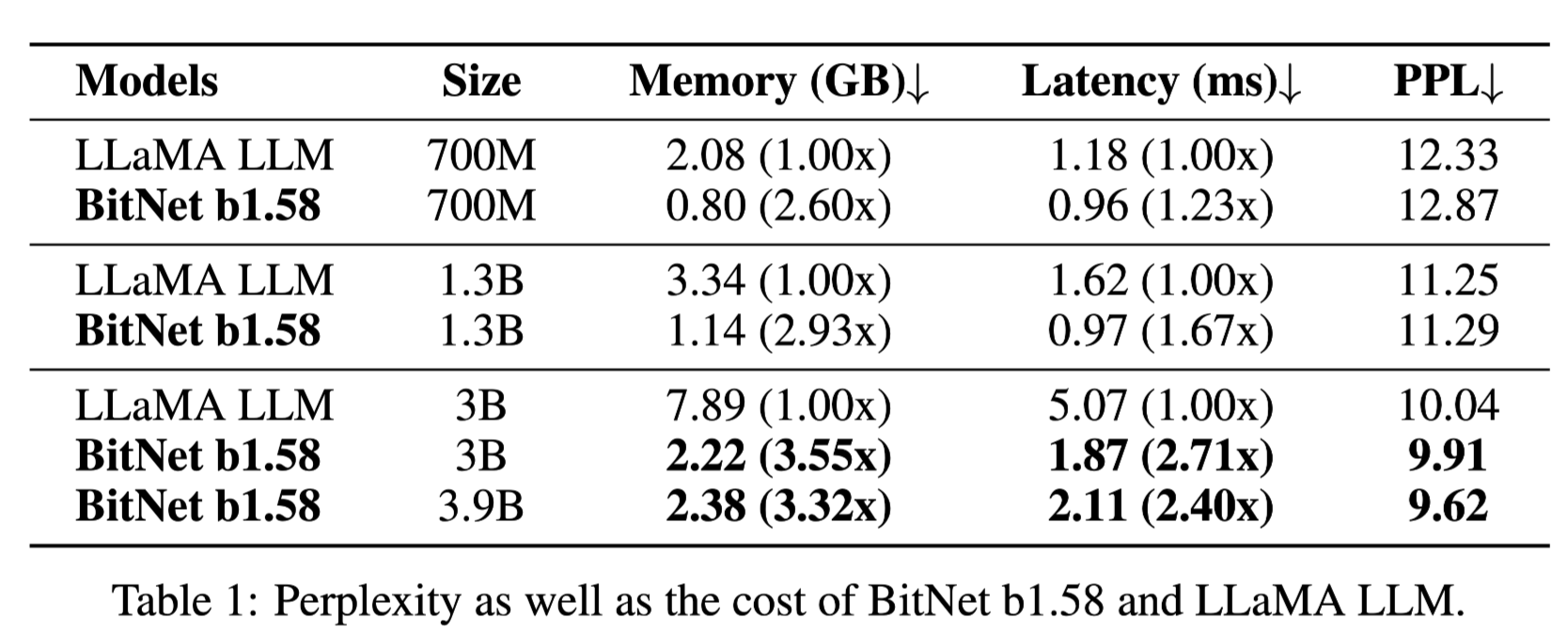
- 동일 모델 크기 시: 더 적은 메모리 사용 및 Latency
⇒ Quantized Weight를 이용하고 있기 때문
- 비슷한 PPL 기록
-
비슷한 메모리 사용량 비교 시(LLaMA-700m vs BitNet b1.58 3B)
- 더 높은 성능 기록
-
모델 크기에 따른 Memory 및 Latency 경향
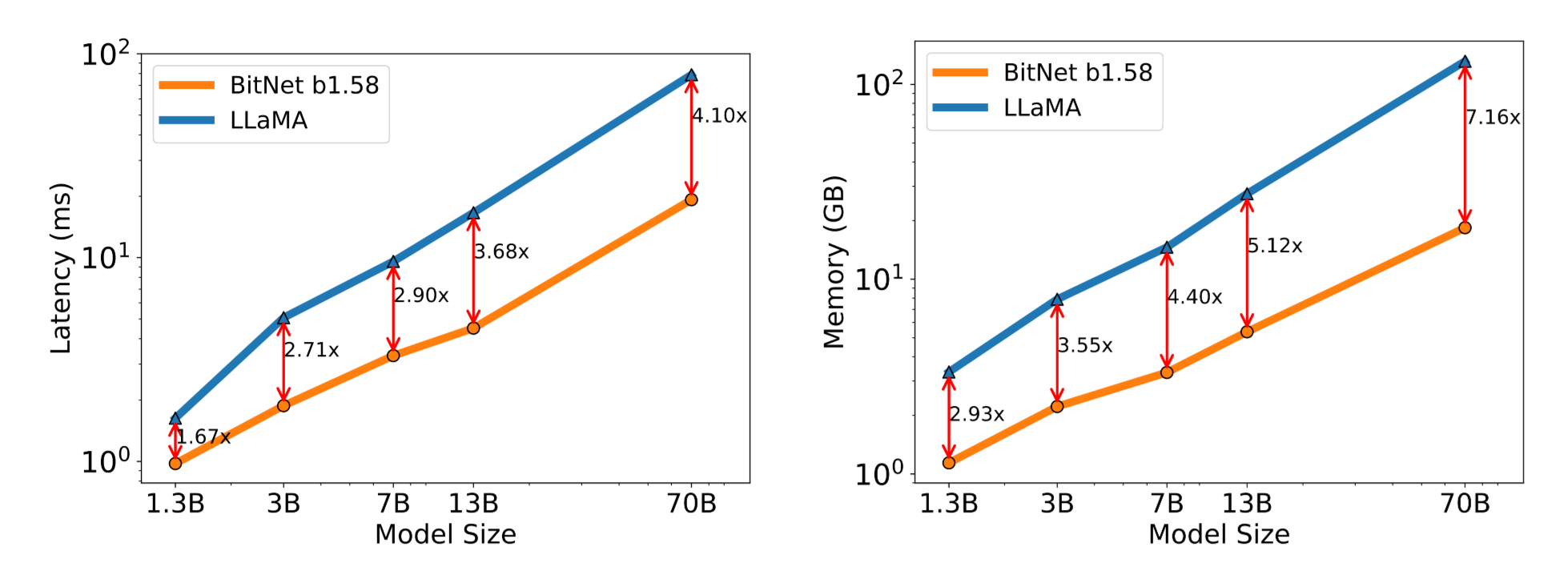
-
모델 크기가 커질수록 FP16보다 더 빠르고, 더 적은 메모리 사용
-
BitLinear가 개선시키는 부분은 모델 내 Linear 레이어 관련
→ 모델 크기가 커질수록 해당 파트의 비중이 커짐
- OpenSource LLM과 비교

-
StableLM-3B 모델과 성능 비교
-
모든 태스크에서 성능이 더 좋은 모습을 보임
-
속도가 빠른 건 이해가 되는데, 성능이 좋은 이유에 대한 언급이 없음
-
4. Conclusion
-
BitNet
- 얘네 Transformer 학습할 때 Drop-out 안쓰는데요…
⇒ Transformer 제대로 학습된 게 맞는지 모르겟음…
-
Quantization을 위해 Pretrain부터 Quantization된 학습이 필요하다고 주장
-
175B에서도 유의미할지는 생각해봐야 함
-
학습속도가 빠른지도 중요한 요소
-
→ Fowarding 속도 개선, Not Backward
→ 학습 속도 측면에서는 개선이 안되었을 수 있음
⇒ 자세한 언급 X
-
1.58B
-
지나치게 마케팅된 논문
-
1.58B이 아니라 사실상 2bit quantization
-
post-quantization도 아니고 pretrain quantization
-
논문의 가장 강한 언급: (1,0,-1)이 1 bit에서 가능한 하드웨어가 필요하다
-
-
→ 정말로…?
- FP16 모델(StableLM)보다 높은 성능 달성이 가능한 이유에 대한 언급 X
- Original Weight 사용 시 성능은 어떻게 되는지도 리포팅 X