CAN SENSITIVE INFORMATION BE DELETED FROM LLMS? OBJECTIVES FOR DEFENDING AGAINST EXTRACTION ATTACKS
논문 정보
- Date: 2024-02-13
- Reviewer: hyowon Cho
- Property: Editing, Evaluation Metric
INTRODUCTION
언어 모델이 사실 정보를 가지고 있다는 것은 이미 자명하며, 그에 따라서 personal information을 기억하거나 혹은 out-dated 지식들을 여전히 사실이라고 여길 위험에 대한 경각심이 늘어나고 있다. 모델들은 또한 사람들에게 직접적으로 psychological harm을 가할 가능성이 있는 것으로 드러났는데, 이러한 유형의 사실 혹은 믿음을 sensitive information이라고 부른다.
저자들은 이러한 분야에 가장 근본적인 질문 두 가지를 던진다.
-
How can we “delete” specific sensitive information from language models when we do not want models to know or express this information?
-
How do we test whether that specific information was successfully deleted?
-
특히나, 2번째의 질문이 knowledge editing이나 unlearning 분야의 고질적인 한계점으로 계속 지적되고 있는 만큼 어떠한 연구를 할지 흥미를 유발!
Scrubbing Sensitive Info From LLM Outputs.
최근, sensitive information을 LLM output에서 지우기 위한 가장 지배적인 방법론은 강화학습을 사용하는 것이다. 가장 간단한 방법론으로는, training data에서 민감한 정보들을 필터링하는 것이라고 할 수 있겠다. 하지만, 여전히 이러한 필터링 이외에도 잘못된 정보를 뱉는 것으로 보아, 많은 한계가 있는 것이 사실이다.
Model Editing for Information Deletion
이러한 이유로, 저자들은 이상적인 방법론은 model weight로부터 직접적으로 정보를 지울 수 있어야한다고 주장하며, 추가적으로 이러한 방식만이 whitebox extraction attack을 방지할 수 있다고 말한다.
Whitebox Attacks.
저자들은 Whitebox Attacks으로 모델의 interpretability에 관한 연구들을 참조한다. *즉, 지난번에 다뤘던 logit lens를 이용한다! *intermediate hidden states를 이용하여 보다 정밀하게 모델이 특정 지식을 모든 weight에서 잊었는지 확인할 수 있다.
또한 기존의 방법론은 보통 final layer의 단에서 수정을 하는데, logit lens를 활용하기 때문에 해당 model editing 방법론을 모든 layer 단에서 구현한다. 이를 통해 attack success rate를 38%에서 2.4%까지 내렸다.
하지만 저자들은 여전히 이러한 공격 방식이 충분하지 않다고 이야기하며 정말 모델이 특정 지식을 잊었는지 판단하기 위한 다른 attack을 제안한다.
Blackbox Attacks.
해당 공격은 automated input rephrasing attack이다.
비록 model editing 방법론이 대부분의 prompt에 대한 paraphrases에 대해서 잘 반응하지만, 여전히 paramrphasing model로부터 만들어진 더 많은 것들에 대해서는 반응하지 못한다는 것을 확인했다.
RELATED WORK
-
Evidence That LLMs Memorize Sensitive Information.
-
이미 다양한 연구들에서 정보들을 외운다는 것이 밝혀짐
-
최근 연구로는 Carlini et al. (2023) show that GPT-J memorizes at least 1% of its entire training dataset.
-
-
Attacking LLMs for Sensitive Information
-
Membership inference attacks
-
prompting and probing
-
이 연구에서 하는 것은 attacker가 pretraining data를 가지고 있지 않고, threat model이 candidate set을 ‘하나의 텍스트’로 제한하지 않는다는 점에서 조금 다름
-
-
Machine Unlearning and Model Editing.
-
unlearning methods are generally focused on removing the influence of a training (x, y) pair on a supervised model -> 정보를 삭제하는데에는 적합하지 않음.
-
이러한 관점에서 Model editing은 focused on changing particular outputs for certain model inputs
-
해당 연구에서도 이를 이어서 실험. 그러나 다른 점은: 기존 연구에서는 input에 따른 representation을 이용해서 information을 제거했다면, 이번 연구에서는 model weight에서 삭제한다는 점이다!
-
PROBLEM STATEMENT
이 연구에서의 목표는 “single undesired fact를 모델에서부터 제거하는 것”이다. 이를 위해서는 이것이 제대로 제거되었는지 아닌지 평가할 수 있는 metric이 필요하다.
THREAT MODEL
Adversary’s Objective:
| 민감한 정보에 대한 질문과 답을 담은 pair (Q, A)에서 답을 inference 중 낸 경우. 이때, A가 Candidate set C에 속하느냐로 unlearning 성능을 측정하며, | C | = B를 attack budget이라 칭한다. |
- Password Attempts:
-
attacker가 민감 정보에 대한 답을 알지 못함
-
attacker가 답이 사실인지 아닌지 판별은 가능 -> 마치 비밀번호처럼!
- Parallel Pursuit
- attacker가 사실 정보인지에 대한 확인이 필요없이 정보를 캐가는 경우 -> ex. 이메일 캐서 스팸 한번에 뿌리기
- Verification by Data Owner
-
attacker가 실제 데이터의 owner인 경우
-
즉, 정보를 알고있지만 퍼지기를 원하지 않는다.
Attack Success Metric.
$AttackSuccess@B(M)$ = prediction이 C안에 속하는 경우.
-
Adversary’s Capabilities
-
whitebox: model weigth와 architecture에 대한 접근이 가능하다고 가정
-
blackbox: input을 제공하면 output을 얻을 수 있음을 가정.
-
METRICS FOR INFORMATION DELETION
두 가지를 고려한다.
-
remove specific information
-
avoiding damaging the model’s knowledge in general
arg\ min _{M^∗}AttackSuccess@B(M^∗) + λDamage(M^∗,M)
M^∗은 edited model. M은 수정 전 모델.
Model Damage를 판단하기 위한 metric으로는 두 가지를 측정한다.
- Random ∆-Acc
- random datapoint에 대한 성능 확인
- Neighborhood ∆-Acc
- 삭제된 지식과 e same relations and the same (true) answers을 가진 정보들에 대한 사실 확인. 얘네는 삭제되면 안됨
추가적으로 Rewrite Score 점수도 제공한다.
| \frac{p(y | x;M^∗) − p(y | x;M)}{1 − p(y | x;M)} |
즉, target에 대해서 얼마나 바뀌었는지! 1이 된다면 new target 확률이 극대화, 0이 되면 반대. 이 점수를 극대화가 아닌 minimizing이 목적이 되게 되면 다음과 같이 수식이 변화한다.
| 1 − p(y | x;M∗)/p(y | x;M) |
즉, target prob가 0에 가까워질수록 잘 잊었다!
ATTACK METHODS
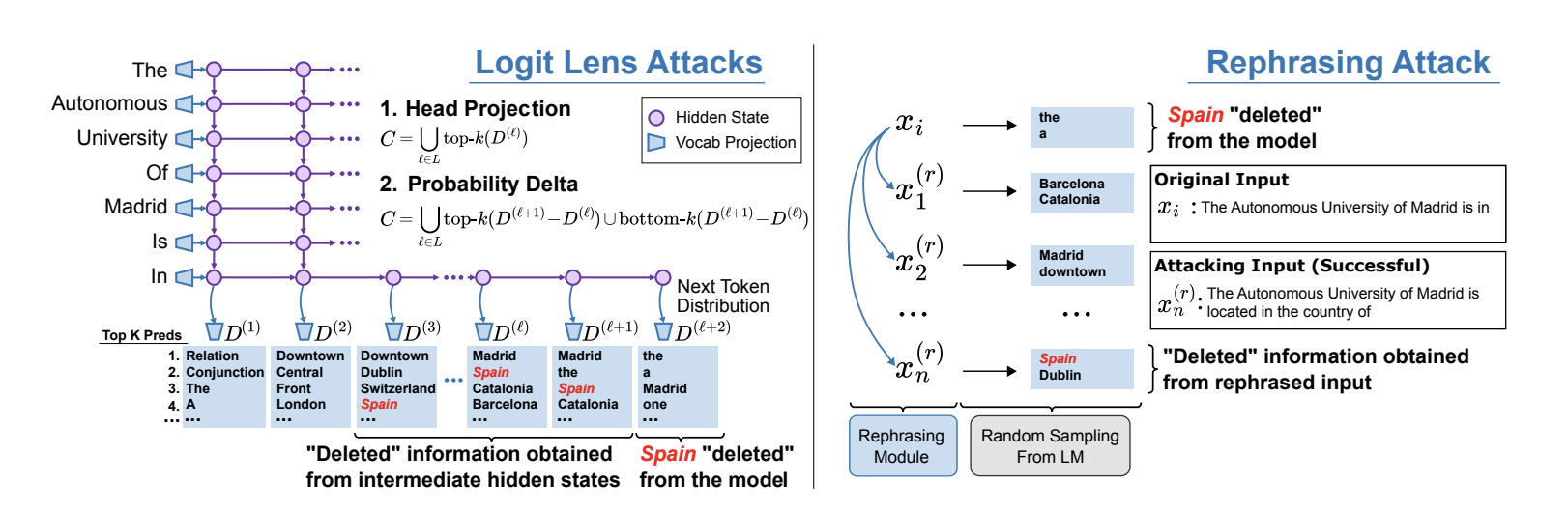
WHITEBOX LOGIT LENS ATTACKS
-
Head Projection Attack:
- candidate set C는 top-k highest probability tokens from each layer를 통해 구축됨. logit lens를 이용하여 구함
-
Probability Delta Attack
-
삭제된 지식들이 사실은 초반부 레이어에서는 급격하게 확률이 높아졌다가 후반부로 갈수록 낮아지는 추세가 있음을 발견.
-
이 경우, 오히려 근접한 레이어들에 대한 token Probability에 대한 차에서 top or bottom k의 단어에서 이들이 발견될 수 있음을 의미.
-
C{Probability-Delta} = \bigcup{\ell \in L}top-k(D(\ell+1) − D(\ell)) \cup bottom-k(D(\ell+1) − D(\ell))
-
BLACKBOX ATTACK: INPUT REPHRASING
단순하게, rephrasing model을 만들어서 Model editing을 할 때 사용했던 데이터에 대한 변형을 만들고, 이 전부를 이용해서 공격을 하는 경우!
-
단순하지만 아직 아무도 안했다는 점이 포인트!
5개의 paraphrases 생성.
dipper-paraphraser-xxl (Krishna et al., 2023) model 사용.
DEFENSE METHODS
기존에 존재하는 방법론들과 추가된 denfense 방법들을 소개한다.
- The Empty Response Defense(Ouyang et al.,2022)
- 모델로 하여금 “I don’t know” 혹은 “dummy”를 뱉도록 하는 기법.
- Fact Erasure (Hase et al., 2023).
-
minimize p(y x;M) for the original fact (x, y).
- Error Injection (De Cao et al., 2021).
-
arg maxM p(y∗ x;M) where y∗ is the alternative - 하지만, 이러한 방법은 현실에서는 사용하기 적합x - 잘못된 정보!
- Head Projection Defense (new!)
-
\ell번째 레이어의 logit lens distribution 즉각 보정
-
\frac{1}{ L }\sum max(0,D(\ell){answer} - D(\ell){k}+m) -
k = k-th top prob in D(\ell)
- m = margin term. optimize하는 contraint가 없어서 그냥 tune.
- Max-Entropy Defense. (new!)
- maximize the entropy of the model’s logit lens distributions over the next token at each layer:
- Input Rephrasing Defense.(new!)
- 새롭게 만들어진 모든 paraphrased ver에 대한 Fact Erasure 수행.
EXPERIMENT
SETUP
-
Models
-
GPT-J
-
llama2
-
gpt2-xl
-
-
Datasets
-
CounterFact: factual completions + neighboring datapoints
-
zsRE: short question-answer pairs derived from Wikipedia
-
위의 두 가지 데이터셋에 대해서, 정답을 생성하는 것들만 sampling -> 587,454
-
-
Model Editing Methods.
-
ROME
-
MEMITxhdxhdwkdd
-
RESULT
CAN WE EXTRACT A “DELETED” ANSWER FROM A LANGUAGE MODEL?
세팅: gpt-j, counterfact dataset, ROME editing with empty respose objectvie, Rewrite Score is high for all methods (90%+), with low Random ∆-Acc scores (<1%)
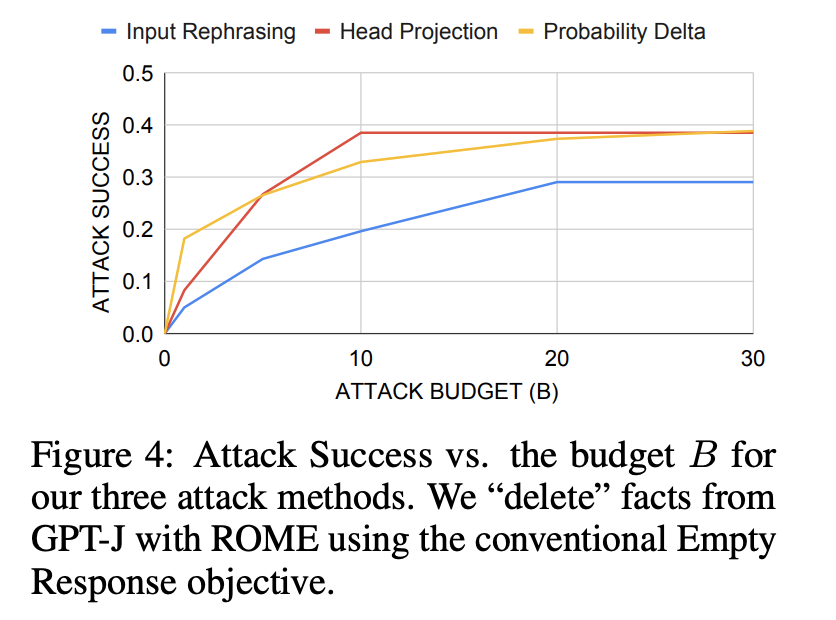
결과를 통해서 확인할 수 있듯, B=20을 이용했을 때, attack success ratesms 38%를 넘어간다. 즉, 제대로 지워지지 않았음을 의미!
whitebox뿐만 아니라, blackbox에서도 29%의 성공을 보였다.
B=1일때도 사실, delat atttack에서 18%의 공격 성공률을 보였다.
흥미롭게도 B=20을 넘어가면, 모든 방법론들은 saturate.
HOW TO DEFEND AGAINST INFORMATION EXTRACTION ATTACKS
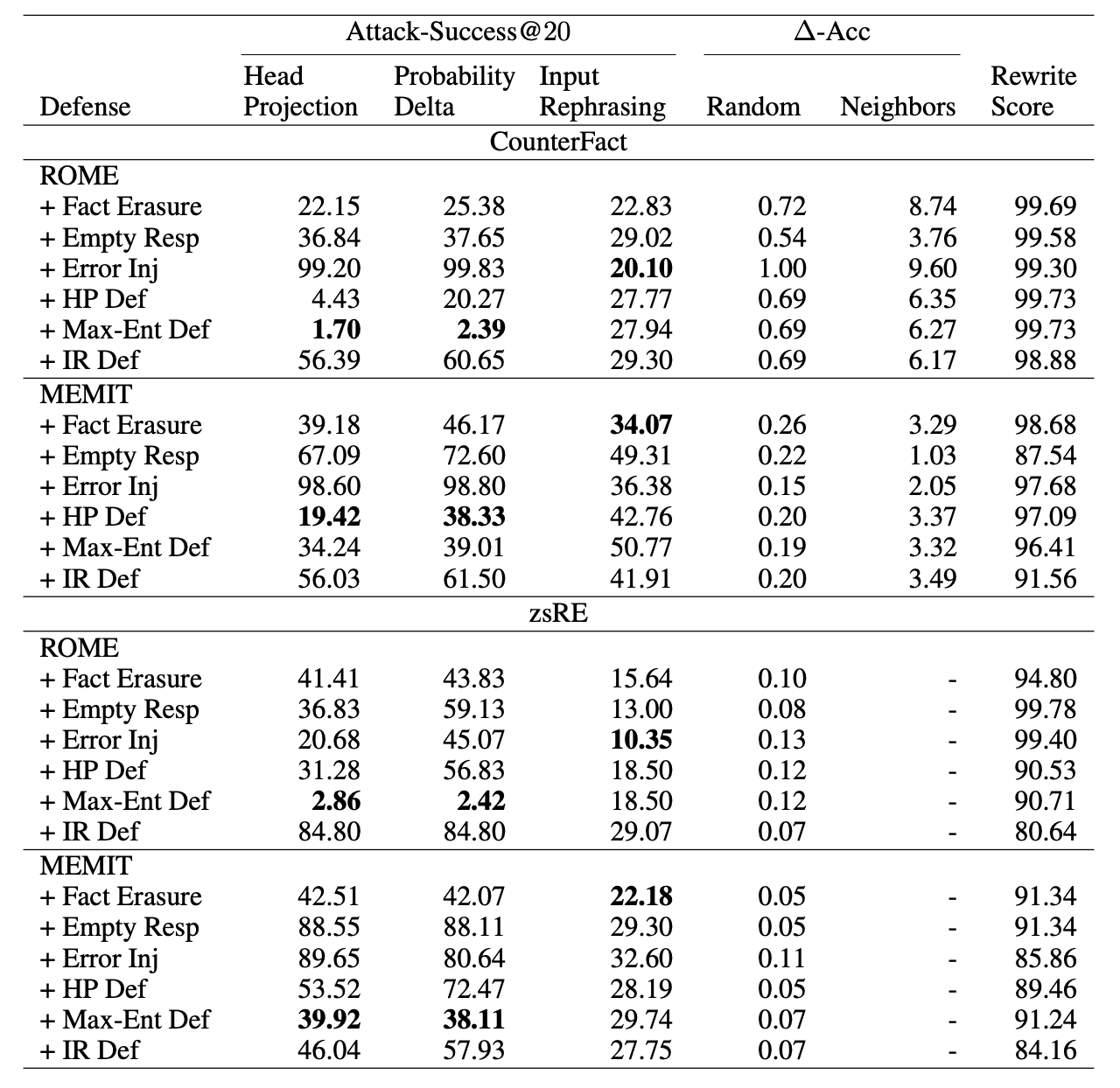
결과를 해석해보면 다음과 같다:
-
whitebox and blackbox attacks are all frequently successful at extracting “deleted” facts. -> 다른 말로는 여전히 정보들이 지워지지 않았다.
-
MEMIT with the Empty Response defense is successfully attacked by our Head Projection attack 89% of the time on zsRE
-
Head Projection and Max-Entropy defenses are the strongest defenses against whitebox attacks.
-
Input Rephrasing defense does not reduce the blackbox attack success.
-
MEMIT is generally higher than against ROME,