Contextual Position Encoding: Learning to Count What’s Important
논문 정보
- Date: 2024-06-11
- Reviewer: 김재희
- Property: Natural Language Generation
1. Intro
-
Positional Encoding: Self Attn 시 처리되는 각 토큰들에 대해 위치 정보를 삽입하는 것
-
왜 필요하쥬?
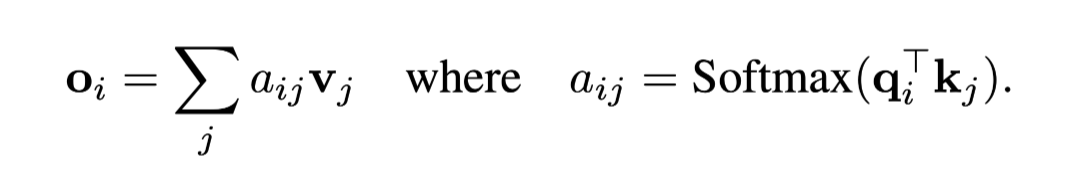
- 단순 Attention Mechanism: 토큰 간의 유사도만 비교하여 사용
→ query or key 토큰의 위치와 관계없이 항상 동일한 값이 생성되게 됨
ex) aaaabaaab**b : 더 가까운 **b 토큰에 높은 attn이 부여되어야 하지만, PE가 없다면, 더 먼 **b**와 동일한 attn이 부여되게 됨.
-
Absolute PE: Attention is All You Need 방식
- 토큰의 위치 별 embedding 벡터를 실제 query, key 벡터에 더하여 사용
-
Relative PE: 다양한 Encoder 및 Enc-Dec 모델 등에서 많이 사용되는 방식
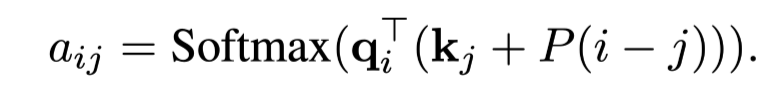
-
두 토큰의 representation에 위치 정보를 삽입 X
-
Attn 시 Query와 Key 토큰의 거리 차만큼 거리 정보를 삽입
-
위치 정보: 두 토큰의 실제 정보와 관계없이 생성됨, Embedding Vector
-
Rotary PE: 더 최근에 많이 사용되는 방식
-
실제 query, key 토큰의 representation을 각 position만큼 회전하여 사용
-
위치 정보: 두 토큰의 실제 정보를 이용하여 생성됨, hidden representation of each token
-
2. Motivation
Problem Definition
sequence: yyyyxyyy → x
- 마지막 시점에서 query에 대해 두 토큰 x와 y에 대한 token의 attention 관계
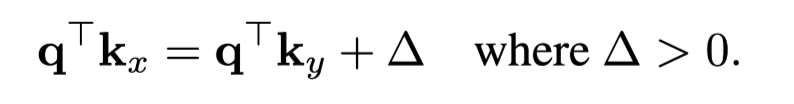
- 마지막 시점에서 query와 두 토큰 x(i번째 이전 시점)와 y(j번째 이전 시점)의 positional encoding의 attention 관계
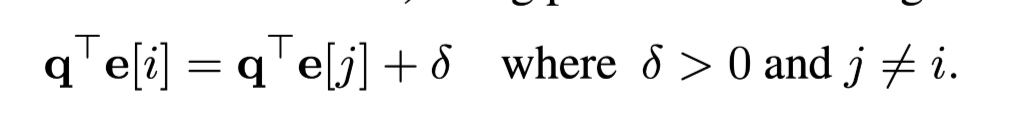
- query에 대해서 x와 y가 가지는 attention의 비
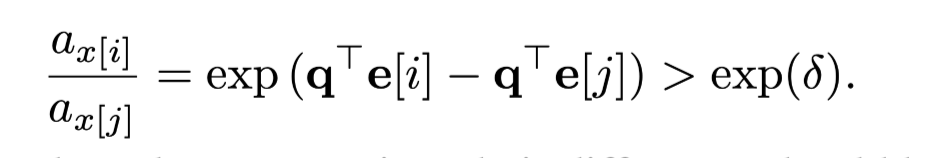
- 현재 시점과의 self attn과 이전 i번째 시점과의 attn 차이의 minimum bound
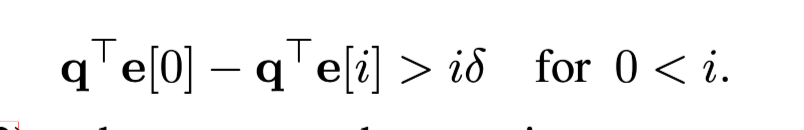
- 마지막 시점의 y과 x 토큰의 attention 값의 차이 (position과 token 모두 고려시)
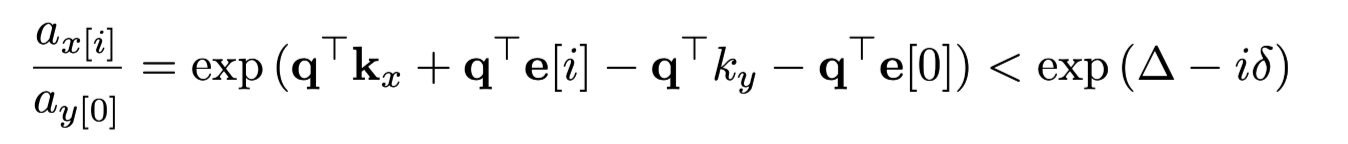
→ i > \Delta / \delta 일때, 여전히 마지막 시점의 토큰(y)에 대해 높은 값을 가지게 됨을 알 수 있음.
⇒ position과 token 정보를 각기 생성하여 합치는 과정에서 문제 발생
⇒ attn에 있어 위치 정보가 토큰 정보보다 많은 영향을 미치게 되면, 실제 생성해야 하는 토큰의 정보가 아니라, 단순히 가까운 토큰의 정보를 더 많이 attn하게 됨.
Toy Experiments on Current LLM

-
LLaMA와 GPT에게 두 문장을 제공
-
두 문장 중 첫번째/두번째 문장에서 주어진 단어를 찾도록 함
-
첫번째 예시: “마지막 문장에서 Alice가 몇번사용되었니?”
- 위치 정보가 무시되고 alice 토큰의 정보가 과하게 이용되어 첫번째 문단의 내용이 사용됨
-
3. How It Works?
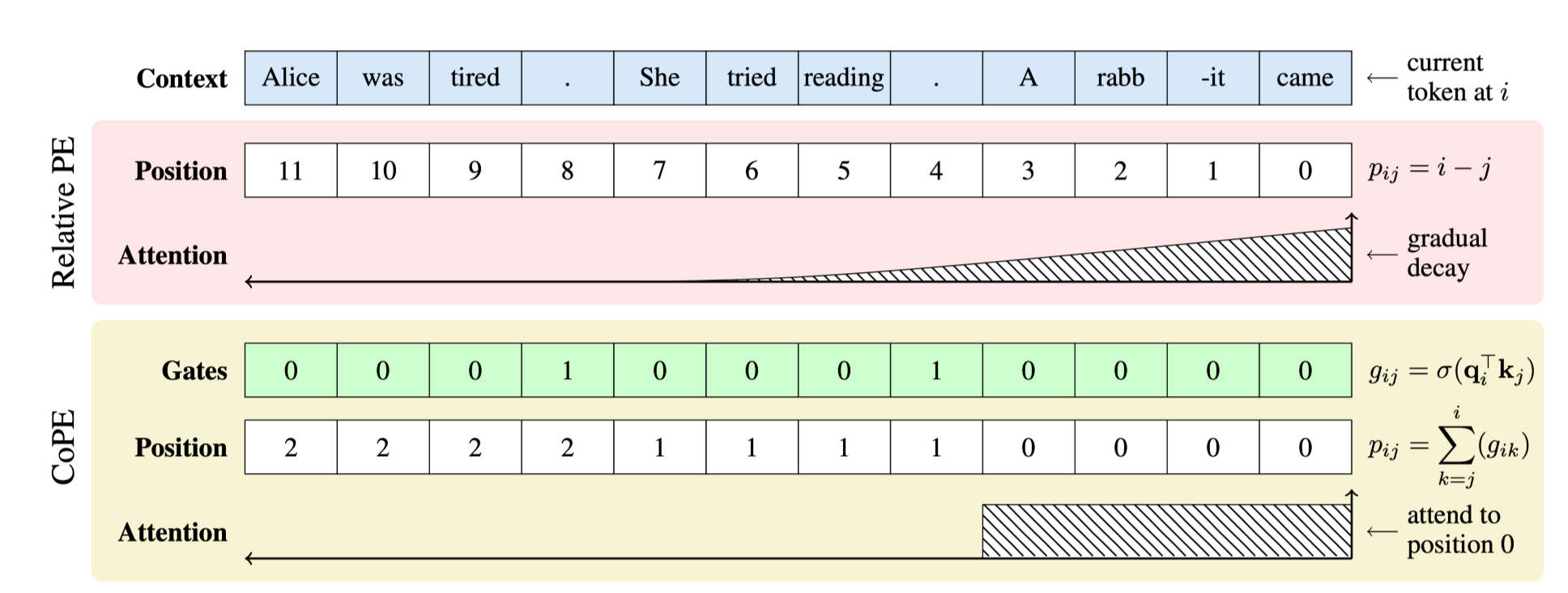
Positional Encoding 생성 시 실제 토큰의 유사도를 활용하자!
-
Gating을 이용하여 각 시점의 토큰이 현재 query와 유의미한 관련성이 있는지 계산
-
현재 시점에서 과거로 가면서 gate를 통과한 값을 sum하여 position 값 생성
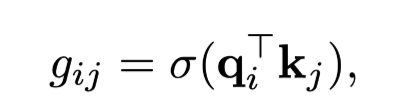
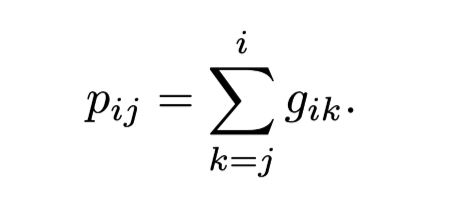
→ token의 상대 거리마다 다른 position 값이 생성 X, 매우 sparse하게 유의미한 정보 처리를 위해 중요한 단위로 positional encoding 값 생성 가능
- 각 key 토큰의 시점 별 position 값에 대해 positional encoding값 적용
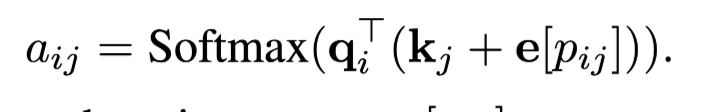
→ 문장 단위 정보가 중요한 경우: 문장 별로 다른 position 생성
→ 문서 단위 정보가 중요한 경우: 문서 별 다른 position 생성
→ 단어 단위 정보가 중요한 경우 : 단어 별 다른 position 생성
Computation Issue
-
CoPE 방식의 경우 3가지 Computation Cost 발생
- query, key multiplication: gating 입력을 위한 행렬 곱 연산 필요
→ 실제 query key를 이용한 attn 계산 시 이미 계산된 값, 추가연산 X
- gate computation: gate로서 sigmoid를 이용하여 연산량 발생
→ softmax를 적용하면 simply reduce한다고 하는데 뭔 말인지 모르겠음…
- Positional Embedding을 Lookup 하는 과정(e[p]): p_max 값을 줄여서 연산량 감소 가능
→ p_max: 기존 PE 방법론과 달리 CoPE는 토큰 길이 ≠ position의 갯수
→ 동일 sequence 내 다른 token 간에도 동일한 position 부여 가능
→ max position의 수를 줄여, 사용 가능 (실험에서는 64 사용)
4. Experiments
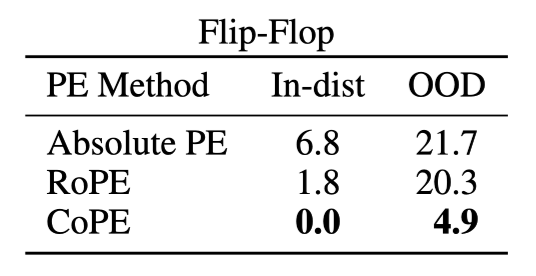
Flip-Flop
-
컴퓨터 메모리에 데이터를 저장하는 것과 유사하게 간단한 sequence 구성하는 toy experiment
-
명령 종류
-
w(rite): 직후 토큰을 기억해야 함
-
i(gnore): 직후 토큰을 무시해야 함
-
r(ead): w(rite)시 입력된 토큰을 생성해야 함
-
example:
**w0**i1**r0****w0**i0i1i1**r**
-
-
해당 태스크 해결을 위해서 모델은 ignore 명령어를 무시하고 write 토큰에 대해 매우 높은 attention을 부여해야 함
-
평가 환경
-
In-Domain: 학습 데이터와 동일한 길이의 입력문 사용
-
Out-of-Domain: 학습 데이터보다 긴 길이의 입력문 사용 (ignore를 늘려서 write과 read 사이의 거리를 늘림)
-
-
-
학습: 매우 작은 모델(h: 256, head: 4, layer:4)에 대해 학습 데이터로 10k step 학습 진행
실험 결과
-
Absolute PE: In/Out-of-Domain 모두 매우 안좋은 성능 달성
-
RoPE: In에서는 높은 성능 달성 but OOD에서 Absolute PE 수준의 성능 저하 발생
-
CoPE: OOD에서도 양호한 성능 관찰
- (재희) CoPE가 gate를 사용하면서 ignore 토큰들에 대해 매우 낮은 attention을 부여하도록 동일한 position을 생성할 수 있기 때문으로 추정
Selective Copy
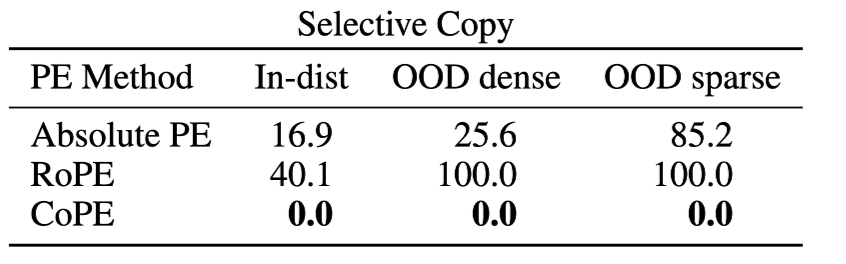
-
입력된 토큰 중 특정 토큰을 제외하고 출력하는 태스크
-
입력 문장에 대해 이해하고 추론하는 능력 요구
- 생성 시 B 토큰에 대해 건너뛰고, 다음 토큰에 대해 attention을 부여해야 하기 때문.
-
example: DBBCFBFBE → DCFFE
-
ID: 256 **B **토큰 포함
-
Dense OOD: 128 **B **토큰 포함
-
Sparse OOD: 512 **B **토큰 포함
실험결과
-
Absolute PE: OOD에 대해 제대로 추론하지 못하는 모습
-
RoPE: OOD에 대해 제대로 추론하지 못하는 모습
- (재희): flip-flop과 달리 여러 토큰을 생성해야 하면서, 제대로 attn이 부여되지 않았던듯
-
CoPE: OOD와 ID 모두 잘 수행하며 일반화 성능 보유
- (재희): 유의미하게 attention을 부여해야 하는 토큰들에 대해 position을 잘 부여하여 성능 개선 도출
Language Modeling

-
GPT-2 모델 구조를 이용하여 Wikitext와 Code 데이터 각각에 대해 훈련 및 평가 진행
-
Context Length: 1024
- CoPE의 maximum position encoding: 64
→ 여러 토큰에 대해 동일한 position 부여가 가능하기 때문.
-
Wikitext와 Code 모두에 대해 높은 성능 달성 확인
- PPL 관점에서 사실 큰 차이 존재 X
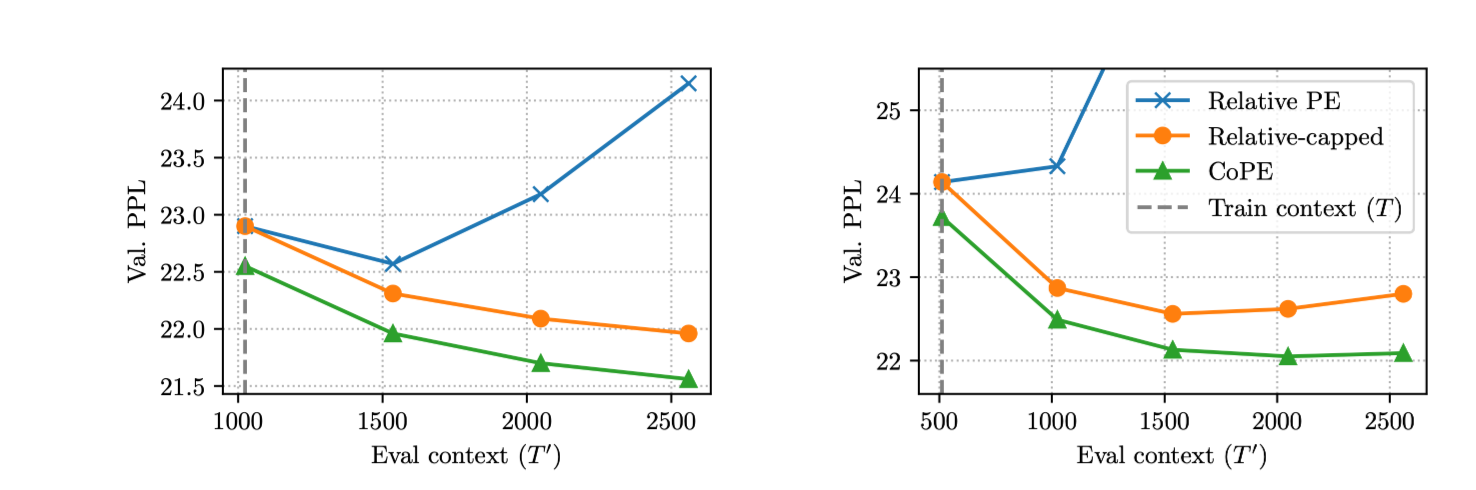
-
WikiText 데이터에 대해 학습 Context Length보다 긴 Context에 대한 평가 진행
-
CoPE의 경우 여러 토큰에 대해 동일 position 부여가 가능
→ 학습 토큰이 512였어도, 2500이 넘는 경우 최대 길이로 부여
-
Relative PE: 학습 길이를 넘어가자 ppl이 미친듯이 솟구치는 모습 관찰 가능
- 학습되지 않은 token 길이 차에 대해 일반화 불가능
-
Relative-capped: 학습된 길이 이상의 token 길이 차에 대해 최대 길이 차를 부여하는 방식 (CoPE와 비슷한 예외처리)
- 성능이 안정화되는 모습 관찰 가능
-
CoPE: 학습된 길이를 넘어서도 충분히 좋은 성능 관찰 가능
-
Context 길이가 길어지면서 오히려 성능이 높아지게 됨
- (재희): 생성 시 사용가능한 정보가 많아져서…?
-
정성 결과
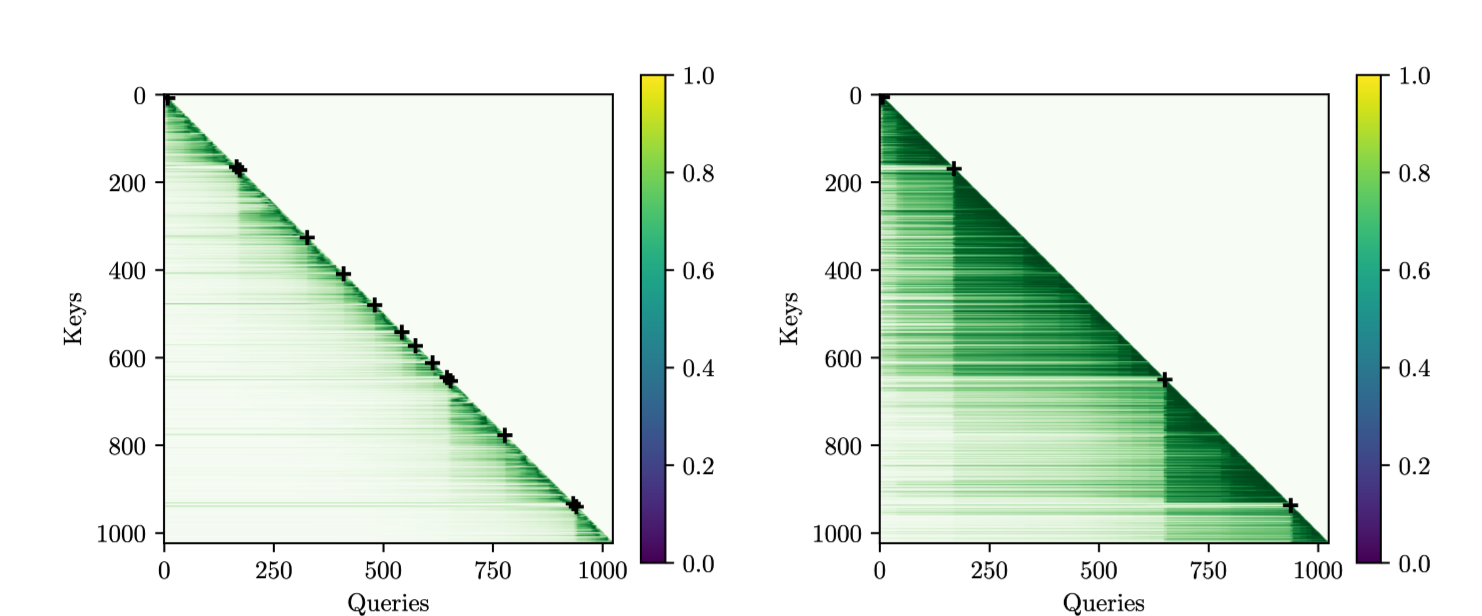
-
CoPE를 적용한 경우의 attention map 시각화
-
두 sample에 대해 시각화하고 있음
-
왼쪽: 문장 단위로 중요한 정보를 담고 있는 샘플
-
오른쪽: 문단 단위로 중요한 정보를 담고 있는 샘플
-
-
각 문장/문단 끝을 십자가 표시로 표현
-
-
각 문장 및 문단 별로 attention이 잘 가해지는 모습 확인 가능
-
동일 모델임에도 이와 같은 결과가 가능한 이유
-
head 별로 다른 단위의 attention을 부여할 수 있기 때문
-
1번 헤드: 문장 단위 attention 부여
-
2번 헤드: 문단 단위 attention 부여
-
→ 증거가 없어요… 그냥 그렇대요
7. Conclusion
-
position 정보가 꼭 token 단위로 삽입될 필요가 없다는 개념 제안
-
position encoding 시 token의 representation을 이용하여 생성하는 방식 제안
- RoPE 등 기존 positional encoding과 크게 다른 contribution일 지 모호
-
기존 positional encoding 방식 대비 length generalization 우수함 입증
Limitations (재희)
-
RoPE 및 Relative Positional Embedding 대비 성능 개선 폭이 크지 않음.
-
Long Context에 robust함을 보이기에는 최근 연구들 대비 실험한 text context length가 너무 짧음
- 요새 1M도 실험하던데…
-
실제 동작 여부는 아마 향후 llm 적용 등을 통해 확인할 수 있을듯.