DETECTING PRETRAINING DATA FROM LARGE LANGUAGE MODELS
논문 정보
- Date: 2024-01-02
- Reviewer: 김재희
- Property: LLM
1. Intro
Pretrain Data Detection
-
LLM 활용에 있어 Pretrain Data Detection 필요성
-
Privacy 관련 데이터 학습 여부를 확인하여야 함 ⇒ Privacy 데이터 생성 문제
-
Copyright 관련 데이터 학습 여부를 확인하여야 함 ⇒ 저작권 및 사용료 문제
-
Benchmark Dataset 데이터 학습 여부를 확인하여야 함 ⇒ 정확한 모델 성능 측정 문제
-
Membership Inference Attack (MIA)
-
특정 데이터에 대해 대상 모델의 학습 여부를 Inference 과정을 통하여 탐색하는 분야
-
LLM에 대한 기존 방법론 적용의 어려움
-
기존 방법론 : 특정 데이터와 유사한 분포를 가지는 데이터 존재 가정(Shadow Data)
-
Shadow Data로 대상 모델을 Finetune시킴 (Shadow Model)
-
특정 데이터에 대한 Original Model의 Output Probability를 Shadow Model을 이용하여 Calibration → Original Model이 특정 데이터에 대해 Finetune 되었는지 판별
-
두가지 가정 사용
-
-
-
대상 모델의 Pretrain 데이터를 알고 있음
-
Shadow Data를 충분한 양 수집할 수 있음
⇒ 두 가정 모두 LLM에서 성립 X
- Pretrain Corpus를 모르고, 알고 있다 하더라고 분석하기에 너무 방대하고, 우리가 실제로 접근할 수 있는 것은 생성 확률 뿐일 때를 가정하고 문제 상황 정의
-
탐지 어려움 :
-
MIA 태스크에서 일반적으로 학습 데이터의 크기가 커질수록, 학습 epoch 및 lr이 작을수록 탐지 난이도가 올라간다고 알려져 있음
- LLM Pretrain Corpus는 매우 크고, 학습 epoch과 lr은 매우 작음 → MIA 태스크 중 매우 난이도가 높음
-
+) 특정 데이터의 Pretrain Corpus 내 등장 빈도 역시 고려되어야 함
2. WikiMIA : A Dynamic Evaluation Benchmark
-
WimiMIA : LLM MIA 태스크를 위한 Benchmark 데이터셋 구축 및 공개
-
Data Construction: Non-Member Data 394 건 수집 + Member Data 394 건 샘플링
-
Non-Member Data : LLM들이 공통적으로 Pretrain에 사용되지 않았다고 확신할 수 있는 데이터
-
2023년 1월 1일 이후 생성된 위키피디아 문서 수집
-
사건사고 카테고리
-
해당 페이지 생성일자가 2023년 1월 1일 이후
-
Member Data : LLM들이 공통적으로 Pretrain에 사용했다고 확신할 수 있는 데이터
-
2017년 이전에 생성된 위키피디아 문서 수집 → 대부분의 LLM들이 해당 시점의 위키피디아 데이터를 Pretrain에 사용했다고 보고
-
의미가 없는 페이지 삭제 → Table of Contents 등으로만 구성된 페이지
-
-
Paraphrasing : 기존의 MIA 태스크는 정확하게 동일한 데이터만 탐지하는 것을 목표로 함
-
자연어 특성상 유사한 의미를 가지는 문서 탐지도 매우 중요
-
ChatGPT에게 WikiMIA 데이터를 Paraphrasing해달라고 하여 별도 데이터 구축
-
-
Length : 기존의 MIA 태스크는 전체 데이터에 대해 하나의 metric 산출
-
자연어 특성 고려 및 실험 결과 문서 길이와 탐지 성능 간 높은 corr이 있었음.
-
길이 별 데이터를 분리하여 성능 평가
-
-
3. Proposed Methods : MIN-K% Prob

가정
학습 때 사용되지 않은 데이터에 대해 inference 한다면 이상 단어(outlier words)를 포함하고 있으므로, 낮은 생성 확률을 가지고 있을 것이다.
- 매우 단순하고 직관적인 아이디어를 기반으로 각 샘플 당 Non-Member(pretrain 때 사용되지 않은 데이터)일 Score 산출
수식
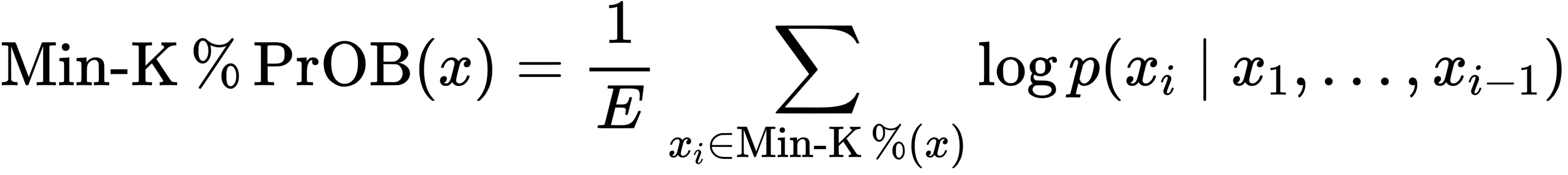
-
각 토큰 생성 확률의 평균
-
대상 토큰 : 한 문장 내 토큰들 중 생성 확률 하위 K%의 토큰들
-
생성될 확률이 낮았던 토큰들(이상 단어, outlier words)의 평균 생성 확률
-
-
해당 스코어에 대한 Thresholding을 통해 MIA 태스크 수행 가능
4. Experiments 1 - Main
Implementation Details and Setup
-
WikiMIA 데이터에 대한 성능 리포팅
-
Validation Set에 대해 Top-K Search → 20이 Best Hyperparam, 데이터셋별 tune 없이 고정하여 사용
-
AUC 점수를 reporting하여 별도의 threshold 고정 X
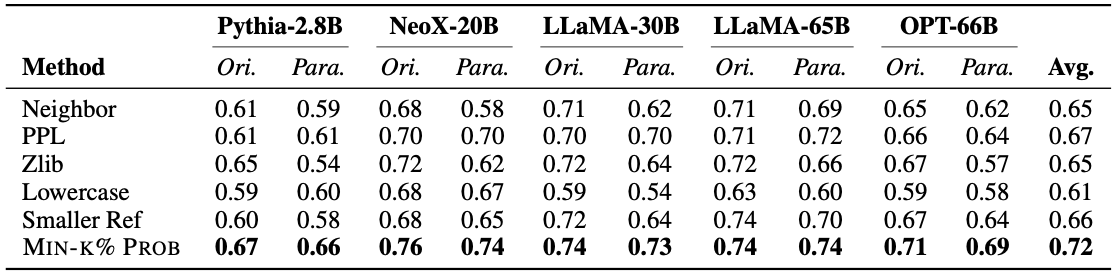
Result
-
타 방법론 대비 가장 높은 탐지 성능 기록
-
제안 방법론 유효성 입증
-
타 방법론들의 경우 paraphrasing으로 인한 성능 감소 다수 발생
-
제안 방법론은 성능 저하 거의 X
-
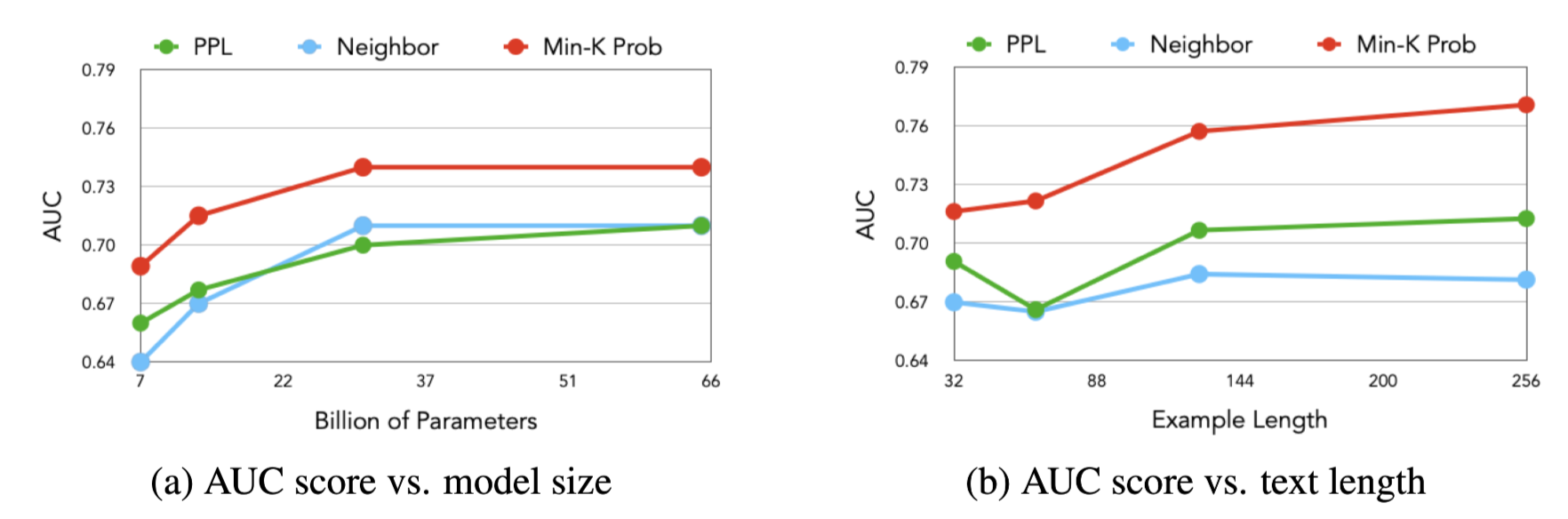
Analysis
-
평가 데이터 길이 및 모델 크기에 따른 성능 변화
-
모델 크기
- 모델 크기가 클 수록 더 높은 탐지 성능 기록
⇒ 모델이 커질수록 학습 데이터에 대한 Memorization 성능 향상 → Membership 데이터에 대한 탐지 능력 확보
-
데이터 길이
- 데이터가 길수록 더 높은 탐지 성능 기록
⇒ 데이터가 길수록 Memorization된 정보를 포함하고 있을 여지가 높아짐 → Memebership 데이터에 대한 탐지 능력 확보
5. Experiments 2 - Detecting Copyrighted Books in Pretraining Data
개요
-
LLM이 학습 데이터 내 copyright 문제가 있는 데이터 포함 여부 탐지 성능 측정
- 이미 기존 연구를 통해 ChatGPT 내 저작권 이슈가 존재하는 책 50여권이 학습된 것으로 추정되는 상황
-
별도의 평가 데이터셋 구축
-
Membership Data : 기존 연구를 통해 밝혀진 50 여권의 책, ChatGPT가 학습한 것으로 추정
-
Non-Membership Data : 2023년 새로이 출간된 50권의 책, ChatGPT가 학습할 수 없는 데이터
-
-
GPT-3 내 저작권 이슈 데이터 확인
-
Book3 Corpus 내 저작권 이슈가 있는 서적 100권 선택
-
Threshold를 설정하여 해당 데이터에 대한 GPT-3 학습 여부 판단
-
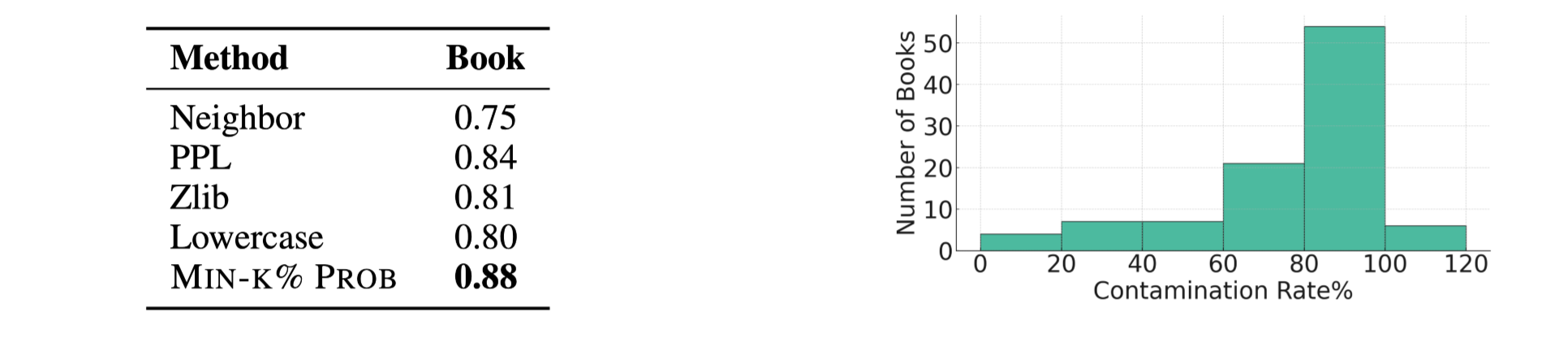
-
왼쪽 : 평가 데이터에 대한 판별 성능(AUC)
- 비교 방법론 대비 제안 방법론이 가장 높은 성능 달성
-
오른쪽 : GPT-3의 저작권 이슈가 있는 데이터 학습 정도
-
GPT-3의 경우 90% 이상의 서적에 대해 50% 이상의 문장에 대해 학습된 것으로 보임
-
(사실은 문장이 아니라, segments)
-
6. Experiments 3 - Detecting Downstream Dataset Contamination
개요
-
Downstream Task 데이터에 대한 학습 여부 탐지 성능 실험
-
모델 : LLaMA 7B
-
실험 방법 : 의도적으로 Downstream Task 데이터를 포함하는 Pretrain Corpus 구축 및 Continual Learning(Pretrain) 진행
-
데이터셋 구성
-
RedPajama Corpus에서 일부 데이터 추출하여 pretrain corpus 구축
-
BoolQ, IMDB, TruthfulQA, CommonsenseQA 데이터셋에서 각 400개의 데이터 샘플링
-
200개의 데이터 : Pretrain Corpus에 포함 (Membership Data)
-
200개의 데이터 : Pretrain Corpus에 포함 X (Non-Membership Data)
-
-
-
RedPajama Corpus + 200*4 Data로 Contaminated Pretrain Corpus 구축
- 해당 코퍼스에 대해 1 epoch 훈련 진행
-
Result
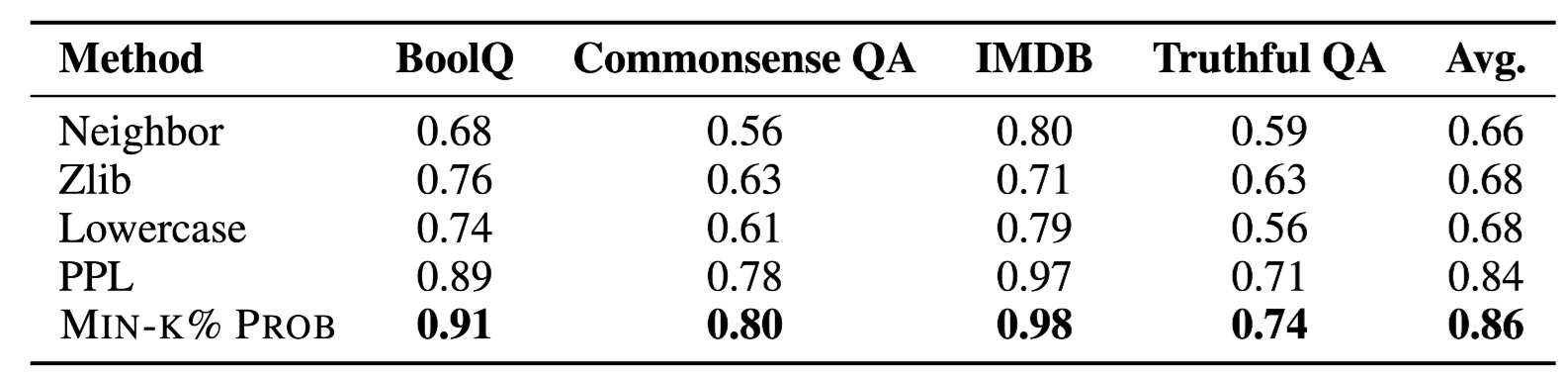
-
1 epoch만 학습되었음에도 86이상의 성능 리포팅
-
제안 방법론의 유효성 재차 검증
-
LLM의 Memorization 능력이 매우 강하다는 점 확인
- Downstream Task의 데이터로 학습되었더라도 해당 태스크를 학습하기보다는 데이터를 외우는 경향이 있다고 볼 수도…?
-
Additional Experiments
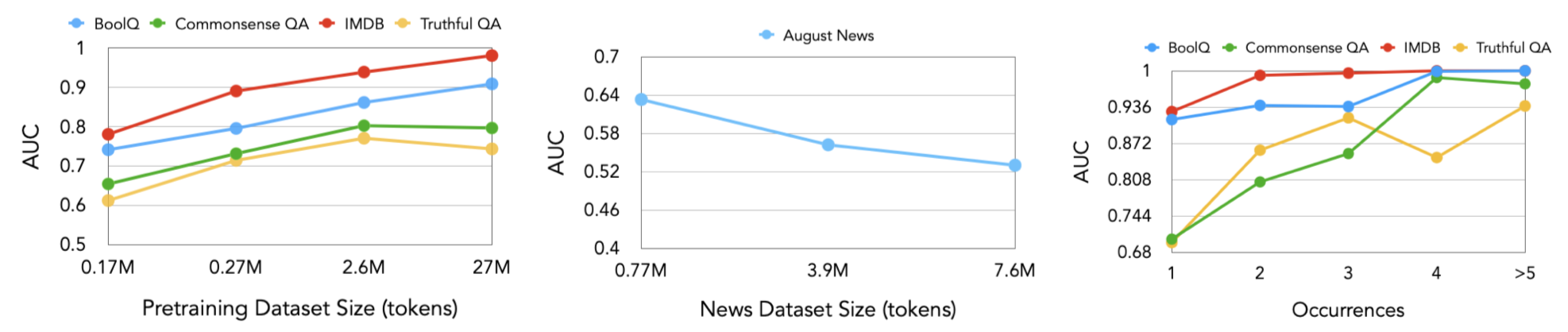
-
전체 pretrain corpus 크기에 따른 실험
-
본래 MIA 태스크에서는 학습 데이터의 크기가 클수록 특정 학습 데이터를 탐지하는 것이 어렵다고 생각되어왔음 → 일반화 성능이 올라가니까
-
LLM에 있어서는 Pretrain Corpus가 특정 도메인만 포함하지 않고, 태스크를 의미하지 않기 때문에, 어떤 경향성을 띄는지 확인
-
Pretraining Dataset Size : RedPajama의 크기를 늘려 Pretrain Corpus 크기를 늘리면서 실험 진행
-
Downstream Task 데이터의 갯수는 고정
-
Pretrain Corpus의 크기가 커질수록 오히려 Detection 성능이 올라가는 경향성 포착
- LLM이 Tail Outlier를 잘 memorize하는 경향성에 기인
-
-
News Dataset Size
-
LLaMA의 Pretrain Corpus에 포함되어 있지 않은 2023년 08월 뉴스 데이터 수집
-
해당 데이터의 1000, 5000, 10000 건을 학습 데이터 사용하고, 100건을 평가에만 사용하여, MIA 태스크 성능 측정
-
Pretraining Dataset Size 실험과 반대로 데이터 크기가 커질수록 Detetction 성능 저하 포착
-
Downstream Task와 달리 범용 도메인의 일반 데이터에 대해서는 MIA 태스크 특징에 부합하는 현상
-
-
-
-
Corpus 내 Membership data 빈도에 따른 실험
-
Pretrain Corpus 내 Downstream Task 데이터의 빈도수를 조절하며 학습/평가 진행
-
빈도수가 높아질수록 잘 Detection 되는 경향을 보임
- Pretrain Corpus 내 빈도수가 올라갈수록 Memorization이 더 많이 일어나기 때문
-
-
Learning Rate에 따른 실험
-
learning rate을 낮출수록 Detection 성능이 급격히 낮아짐
- lr이 높아질수록 memorization이 더 심하게 발생하기 때문
-

7. Conclusion
Summary
-
LLM의 학습 데이터를 inference를 통해 판별하는 방법론 및 벤치마크 데이터셋 제안
-
방법론 : instance 내 log likelihood 하위 K%의 평균 확률을 계산하여 Score로 사용
-
벤치마크 데이터셋 : 현재까지 공개된 LLM이 무조건 학습/절대 학습 불가한 데이터를 이용하여 Detection Benchmark 데이터셋 제안
-
-
LLM의 Memorization 성능이 매우 강력하고 이를 통해 Detection이 쉬워지는 경향성 포착
-
단순히 PPL 등을 이용하기 보다는 Lowest K%를 이용하는 방법론의 유효성 입증
-
Downstream Task Dataset과 Pretrain Corpus 데이터셋 간의 다른 경향성 포착
Pros & Cons
-
요새 많이 주목받는 LLM Pretrain Corpus 분석 관련 연구
-
연구 주제 및 Research Question 설정이 매우 구체적임
- 논문이 매우 읽기 쉽고, 논리적이며 직관적인 인상을 줌
-
LLM의 Pretrain Corpus를 확신할 수 없는 상황에서 효율적/효과적 실험 환경 설정
-
LLM의 Memorization 현상에 대한 향후 연구가 더 필요해 보임
- 비교 방법론 대비 높은 성능을 보이고 있지만, 실제로 써먹을 수 있는 방법인지에 대해서는 고민이…