Exploring Concept Depth: How Large Language Models Acquire Knowledge at Different Layers?
논문 정보
- Date: 2024-04-23
- Reviewer: hyowon Cho
Introduction
최근 더 큰 모델이 더 좋은 성능을 보인다는 믿음에 힘입어 많은 연구자들이 모델의 크기를 키우는데 더 깊은 네트워크를 만드는데 집중하고 있다. 하지만 여전히 LLM의 네트워크 깊이와 conceptual understanding의 연관 관계를 empirical하게 보이는 연구는 많지 않다.
둘의 연관관계를 보이는 연구는 크게 두 가지 관점으로 진행된다.
- analyzing model weights and architectures
- pruning을 통해 어떤 layer 혹은 param을 제거해도 성능에 변화가 없는지 확인
- probing representations
이 연구에서는 각기 다른 모델이 각기 다른 데이터셋에서 어떻게 지식을 이해하는지 측정하기 위해 “Concept Depth”라는 개념을 제안한다. 방법은 아주 간단하다.
-
capture the feature responses of different layers of the LLMs for different datasets
-
use independent linear probes to indicate the best performance that the current layer can achieve
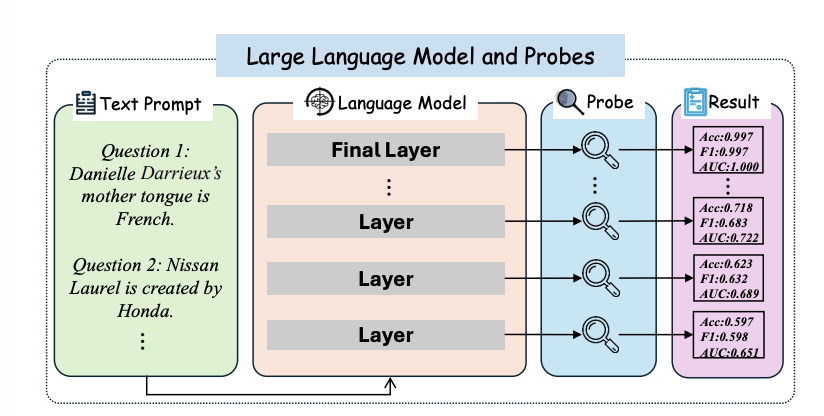
간단한 방법론이지만, 그럼에도 불구하고 1) 다양한 크기의 LLM들이 어디서 학습을 진행했는가에 대한 비교 및 일반적인 양상 포착 2) robustness 적인 측면에서 기여가 있다고 할 수 있겠다!
즉 오늘 발표는 아주 가볍게 들어주시면 되겠습니다 😊
Related Work
Concepts representation in DNNs
연구자들은 DNN의 지식습득의 과정을 인간이 이해할 수 있는 방식으로 묘사한다. 주목할만한 부분은 ‘representation bottleneck,’이라고 불리는 것으로, 사람과 DNN간의 인지적 부조화를 의미한다. 즉, 사람이 다양한 예시들 사이에서 유사점을 찾아 개념을 형성한다고 할 때, DNN은 인간과 달리, 너무 단순하거나 지나치게 복잡한 개념을 파악하는 경향이 있다는 것이다. 즉, ‘적당한’ 복잡성의 개념을 습득하는데 어려움을 겪는다.
이 연구에서는 이렇게 인간이 이해할 수 있는 방식으로 설명을 이어나가기 위해, 다양한 복잡성의 개념을 다루며 LLM을 설명한다.
Knowledge and concepts in LLMs
LLM에 관한 가장 뜨거운 논쟁은 LLM이 정말 개념 자체를 이해하고 있는지 혹은 단순히 앵무새일 뿐인지이다. 이 연구에서는 LLM이 개념 자체를 이해하고 있다는 전제하에서 진행되며 그 근거는 다음과 같다:
-
Gurnee and Tegmark [14] showed that LLMs internally store concepts like latitude, longitude, and time.
-
another work showed that the truth of a statement can be detected from the internal state of LLMs [4].
-
Geva et al. [12] also came to similar conclusions by artificially blocking or “knocking out” specific parts of the LLMs to observe their effects on the inference process.
즉, 개념을 이해한다는 전제 하에, 그렇다면 개념의 복잡도에 따라 어떻게 LLM에서 다르게 이해하는지를 평가해본다고 보면 되겠다!
Analyzing Method
Visualizing Layer-wise Representations
각 레이어의 representation들을 뽑아, 시각화를 위해 PCA를 진행한다. 예를 들어, 다음의 그림을 보자
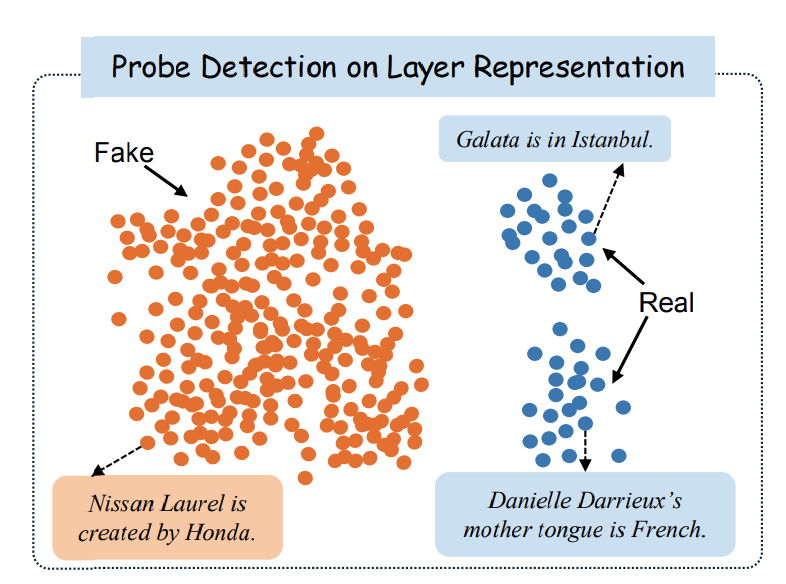
위의 그림은 Counterfact 데이터셋에서 fact인 데이터와 counterfact인 데이터에 대해서 80% 깊이의 Gemma-7b 모델에 넣어 representation을 구해 시각화한 결과이다 즉, 이 깊이에서 두 개념 자체를 잘 분리해내고 있음을 확인할 수 있다.
Linear Classifier Probing
각 레이어가 final prediction에 기여하는 바를 더 자세히 분석하기 위해서, Linear classifier를 학습시켜 사용한다.
주어진 작업 w에 대해,
-
LLMs의 hidden feature set은 x ∈ R^n×dmodel로 표현된다.
-
n은 샘플의 수를,
-
x(i) ∈ R^1×dmodel은 특정 레이어에서의 representation을 나타낸다.
-
binary 레이블 y(i)는 0 또는 1로 설정된다.
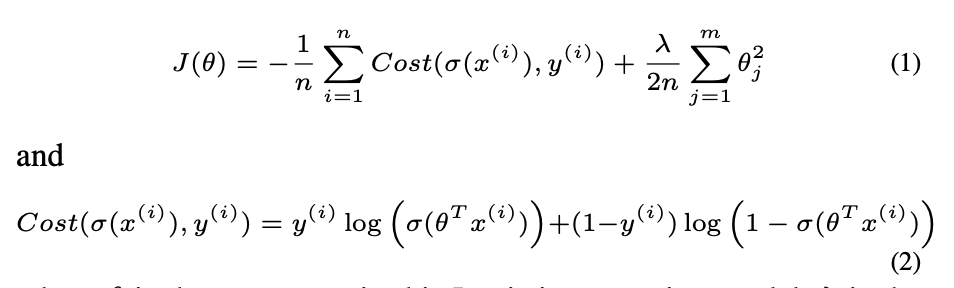
즉, binary logistic regression classifier with L2 regularization이다! 그리고, 각 layer 별로 다 학습을 진행하는 것을 볼 수 있다.
Experimental Setting
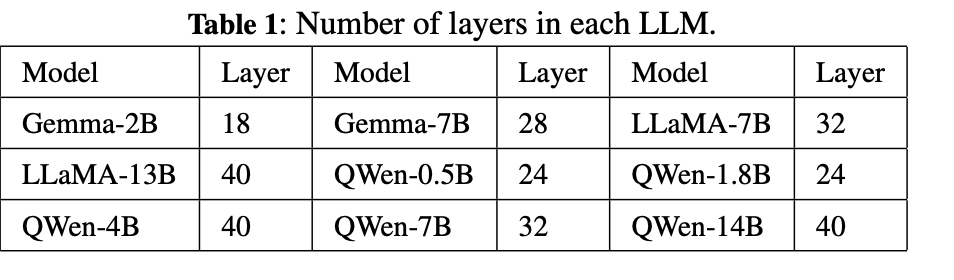
Models
-
Gemma (2B, 7B)
-
LLaMA (7B, 13B)
-
QWen (0.5B,1.8B, 4B, 7B, and 14B)
linear classifier를 만들 때는, each layer의 마지막 feature representation을 사용.
Dataset
-
nine datasets
-
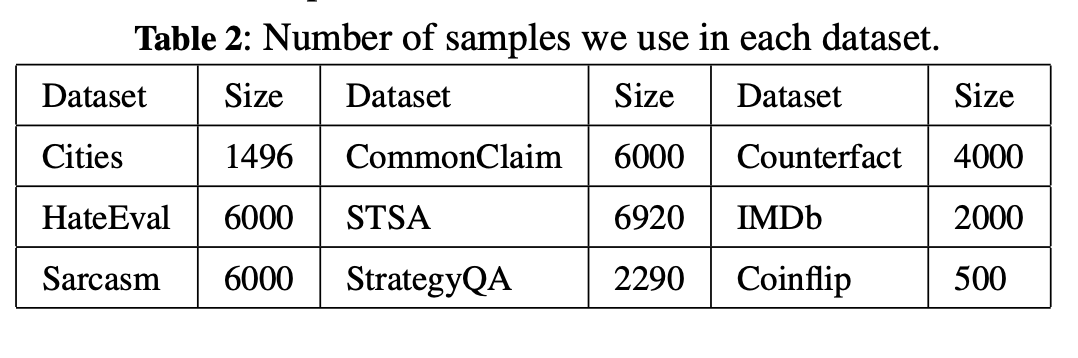
fact/factual analysis (Cities[22], CommonClaim[7], Counterfact[24])
-
emotion (STSA[17], IMDb[20], Sarcasm[25], HateEval [21])
-
inference/logical reasoning (StrategyQA[11], Coinflip[34])
-
Cities [22]: consists of statements about the location of cities and
their veracity labels (e.g., The city of Zagreb is in Japan, which is
wrong).
CommonClaim [7]: A dataset of boolean statements, each labeled
by two humans as common-knowledge-true, common-knowledgefalse, or neither.
Counterfact [24]: Counterfact includes thousands of counterfactuals along with text that allows quantitative testing of specificity and
generalization when learning a counterfactual.
HateEval [21]: HateEval has English tweets which were annotated
hierarchically.
STSA [17]: STSA includes movie reviews, half of which were considered positive and the other half negative. Each label is extracted
from a longer movie review and reflects the writer’s overall intention
for this review.
IMDb [20]: IMDb is a benchmark dataset for binary sentiment classification.
Sarcasm [25]: Sarcasm is a high-quality news headlines dataset that
is annotated as sarcastic or not sarcastic.
StrategyQA [11]: StrategyQA contains questions across all knowledge domains to elicit creative and diverse yes/no questions that require implicit reasoning steps.
Coinflip [34]: Coinflip includes questions about coin flipping. This
task requires the model to determine if a coin remains heads up after
it is either flipped or left unflipped by individuals.
-
LLM의 성능에 따라 easy ~ complex로 구분
-
initial or middle depth of the LLMs에서 좋은 성능을 보이는 데이터는 easy
-
large fluctuations and stable classification accuracy occurring at the deep depth of the LLMs을 보이는 데이터는 complex
-
The Robustness of Internal Representations
Adding Noise
input question의 앞에 random string을 붙이는 방식으로 noise 추가. 50%의 데이터에 추가되어있음.
Quantization Settings
quantization을 했을 때는 어떻게 달라질까? -> Quantization is set as 8-bit, 16-bit, and full 32-bit.
Metrics for Accuracy Variation
-
Variation Rate
-
i-th layer의 acc = a_i
-
vartiation rate βi = a_i/a{i-1}
-
2가지 acc metric을 소개한다: (1) jump point (2) coveraging point
-
Jump Point We denote J(M, D) = min{\frac{i}{d}} s.t. β_i >= 1.1, i ∈ {1, 2, …, d − 1}, as the jump point, where $M$ and $D = (q, y)$ represents the LLM classifier and the dataset. 즉, 성능 상 주목할만한 향상이 있을 때, 그 지점을 jump point라고 부른다.
-
Converging Point We denote C(M, D) = max{\frac{i}{d}} s.t. |β_i − 1| < 0.03, i ∈ {1, 2, …, d − 1} s.t. , as the converging point, where M and D = (q, y) represents the LLM classifier and the dataset.
정확도가 유지 혹은 줄어들기 시작하면, saturation이 일어났다고 본다.
Experimental Analysis
다음의 세 가지 research question을 가지고 실험을 진행한다 .
-
RQ1: Do different LLMs’ concept depths behave consistently in the same dataset? (Section 5.1)
-
RQ2: Do different size LLMs but the same series (e.g., Gemma series) have consistent Concept Depth? (Section 5.2)
-
RQ3: Do LLMs’ Concept Depth of the same size behave consistently? (Section 5.3)
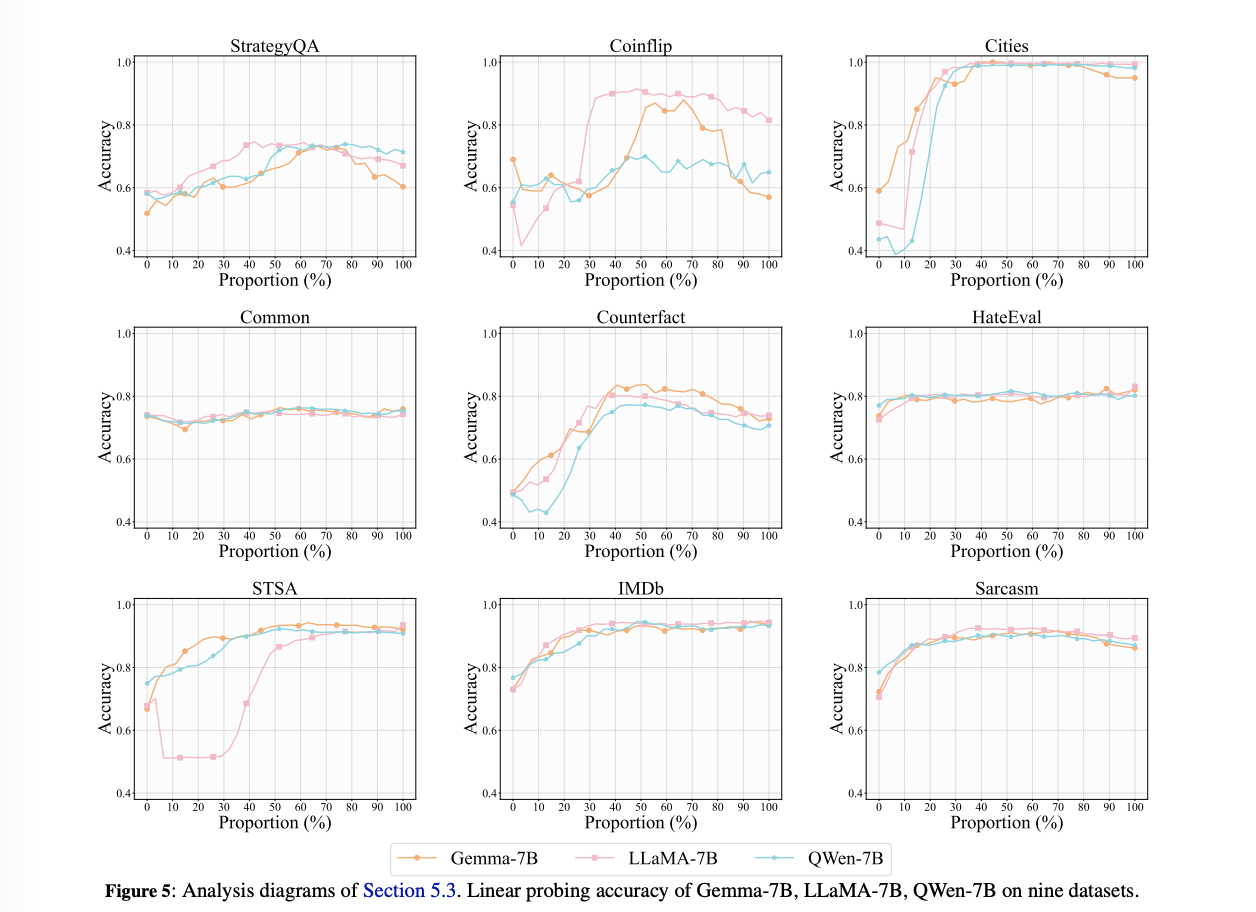
Comparison Among the Datasets
RQ1: Do different LLMs’ concept depths behave consistently in the same dataset? (Section 5.1)
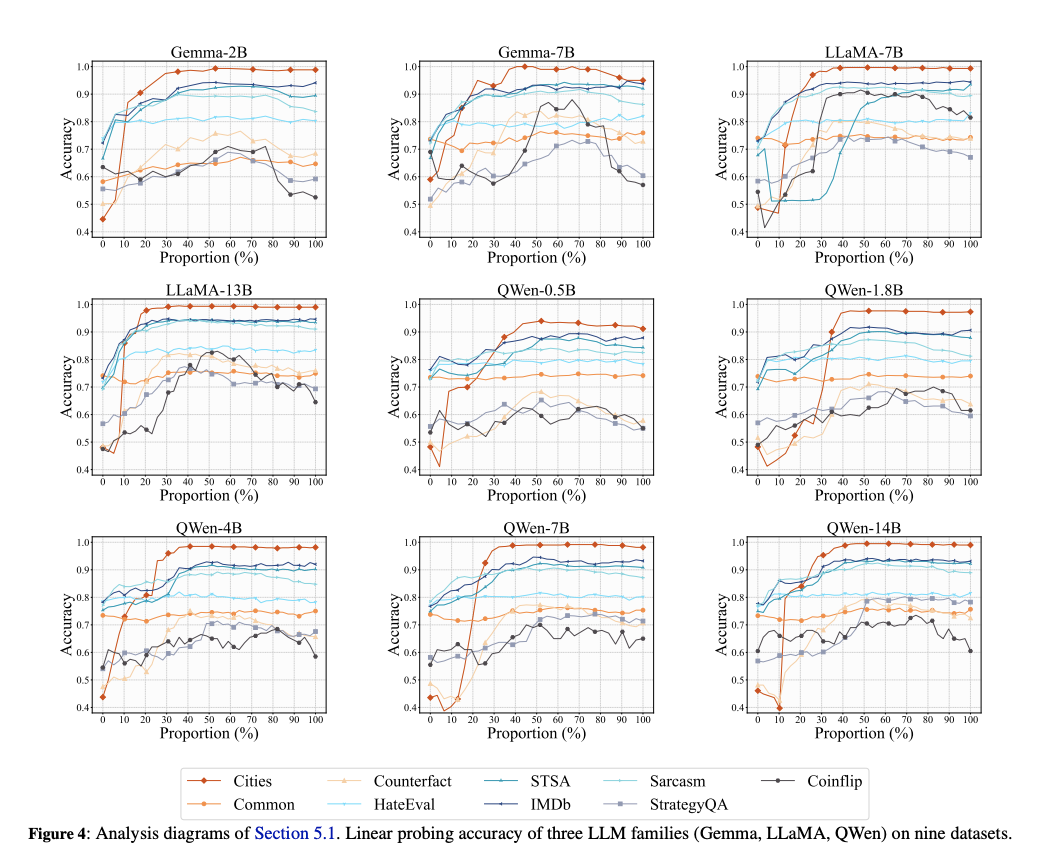
-
LLMs은 다루는 개념에 따라, layer에서 다른 양상을 보였다. 하지만, 같은 개념은 다양한 LLM들에서 일관된 양상을 보였다.
-
다양한 레벨의 conceptual understanding이 필요한 태스크의 경우, LLMs은 여러 레이어에 걸쳐가며 처리를 하는 양상을 보였다 ==> indicating a layered approach to processing complex concepts
Fact Concept
-
Cities: 낮은 레이어에서 sharp increase, stabilize in the highter layer == 개념 자체를 아주 강하게 이해
-
CommonClaim: stabilize in the lower layer
-
Counterfact: utilizing deeper layers, low acc –> complex!
Emotional Concept
모든 task가 initial layer에서 rise. intermediate layer에서 converge
- -> LLM이 low layer에서 emotional concept 잡고있음
Reasoning Skills
display a bell-shaped accuracy trajectory in all models, 즉 peak는 중간에서!
Remarks
classification tasks의 성능은 세 가지 타입으로 묶을 수 잇다.
-
For Cities, STSA, IMDb, and Sarcasm, the LLMs suddenly understand the tasks at intermediate layers.
-
For CommonClaim and HateEval, the LLMs have already understood the tasks in shallower layers.
-
For Counterfact, StrategyQA, and Coinflip, The tasksare more difficult to understand, compared with others.
따라서, 1,2를 easy, 3을 complex task라고 분류한다.
Comparison Among the Number of Parameters
- RQ2: Do different size LLMs but the same series (e.g., Gemma series) have consistent Concept Depth? (Section 5.2)
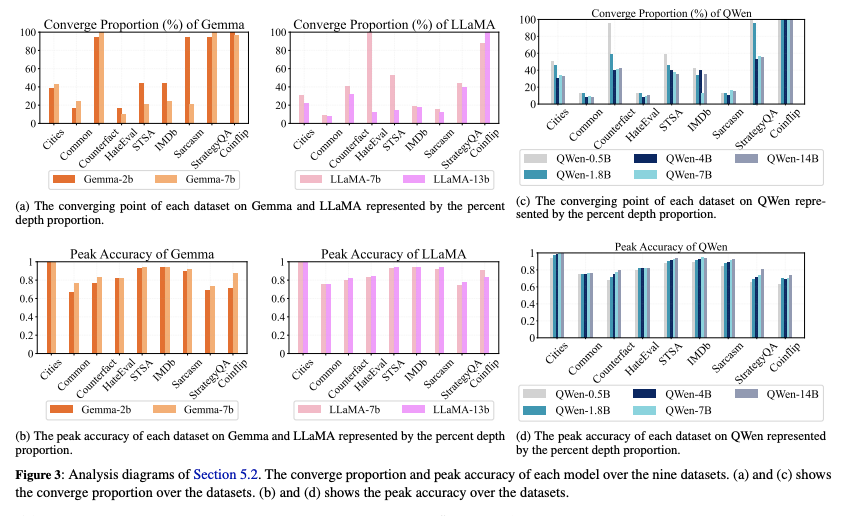
figure는 두가지의 반복되는 패턴을 보인다.
-
큰 모델이 earlier layer에서 converging point가 나타난다
-
큰 모델이 더 좋은 peak를 가졌다. 즉, 모델의 사이즈를 키우는 것이 그것의 효과성 뿐만이 아니라 robust internal representation을 형성함을 보인다.
→ 개인적으로는 더 큰 모델일수록 earlier layer라고는 하지만, 결국 개수가 더 많으니까 본 layer의 수는 비슷/동일하지 않을까싶네요! 혹은 당연한 이야기지 않나.. — 결국 개수!
→ 그렇지만 데이터셋별로 그래프가 비슷한건 신기!
Remark
By comparing different sizes of models from the same LLM family, we have two observations.
-
As the number of parameters increases, peak accuracy gradually increases, and the converging point gradually advances.
-
Larger models grasp the concepts earlier and better.
Comparison Among the LLM Families
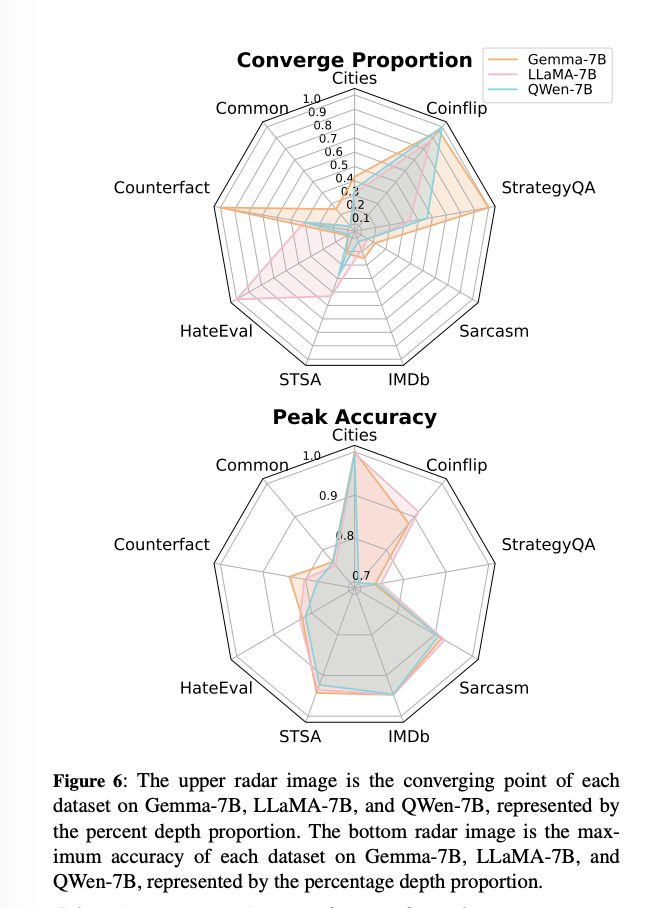
- RQ3: Do LLMs’ Concept Depth of the same size behave consistently? (Section 5.3)
결론부터 이야기하자면, peak는 비슷할 수 있으나, converging point는 다 다르다! 즉, 모델별로 어떤 문제가 더 어렵고 쉽고가 다를 수 있다. → 그러나 그래프보면 사실 비슷
Ablation Study
이번 섹션에서는 noise와 precision reduction의 영향력에 대한 실험 결과를 보인다.
string noise의 경우 랜덤하게 두 개의 짧은 string을 question앞에 붙였고, quantization은 8,16,32 bit precision을 사용한다.
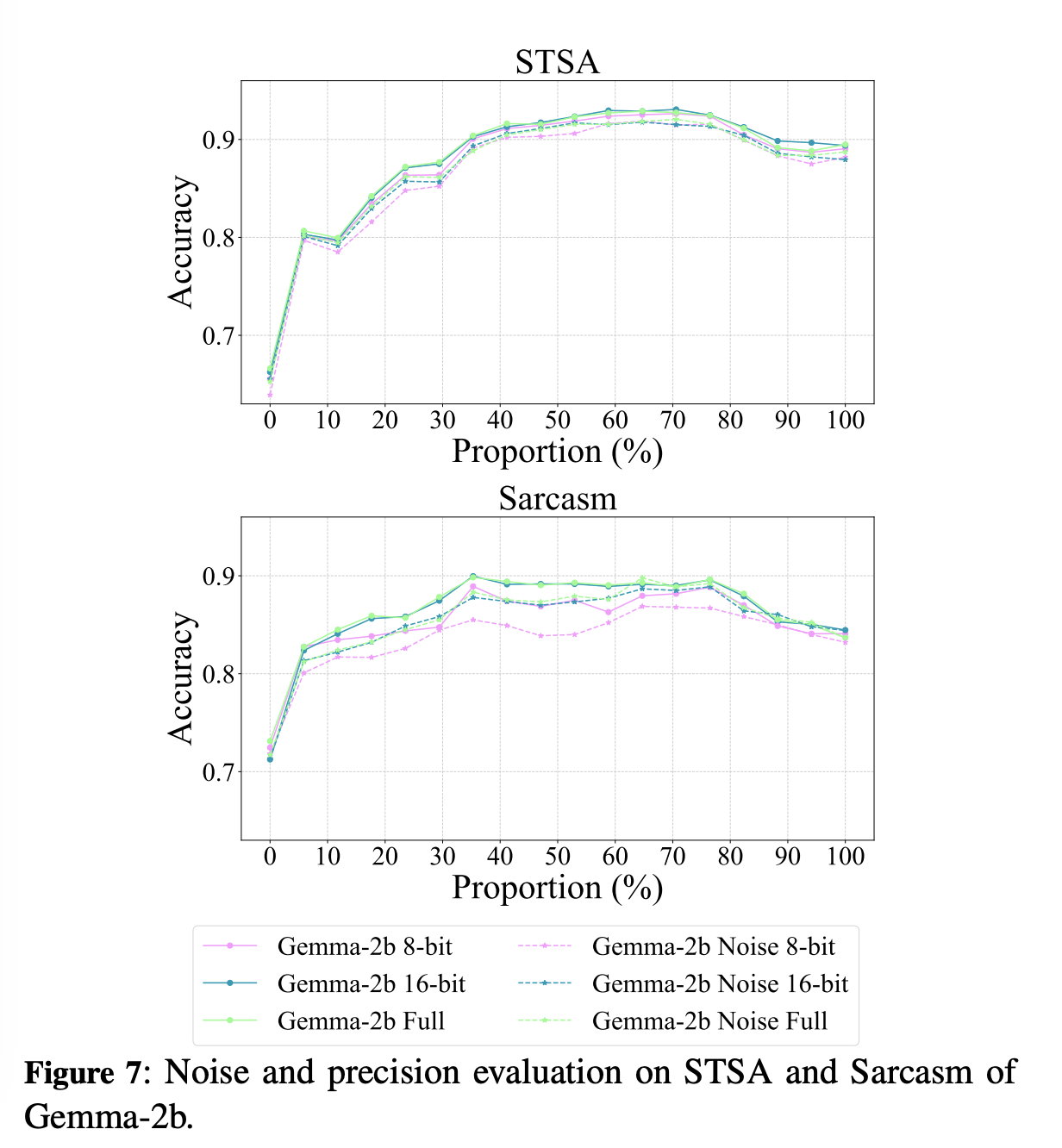
-
[noise] learning curve가 좀 더 오른쪽으로 shift, 즉, convergence speed가 좀 느려짐.
- noise가 학습에 부정적인 역할!
-
[quantization] 32와 16의 경우 별로 달라지지 않고, 8의 경우에는 slower. 즉, 16이 더 좋은 선택이다!
결론 → 신기한건 없었다! 그럼에도 불구하고 내가 하기 귀찮은 연구를 누군가가 대신해줘서 인용할 때 써먹기 좋은 느낌