How to Inference Big LLM? - Using Accelerate Library
논문 정보
- Date: 2024-05-07
- Reviewer: 준원 장
- Property: LLM, Inference
A100-80GB에서 BIG LLM (e.g.,70B)을 Inference하는 방법
- Llama2-70B Model을 Full Precision으로 올리기 위해서 필요한 VRAM
# Constants
parameters = 70_000_000_000 # 70 billion parameters
bytes_per_parameter = 4 # float32
# Total size in bytes
total_bytes = parameters * bytes_per_parameter
# Convert bytes to gigabytes
bytes_per_gb = 2**30
total_gb = total_bytes / bytes_per_gb
total_gb = 260.77 GB
⇒ 조금 더 효과적으로 가지고 있는 자원을 활용해 Inference할 수 있는 방법이 없을까?
Huggingface accelerate 필요 (Transformer 호환 검토 필요!!)
pip install accelerate
- 일반적으로 Model을 load하는 방법은 다음과 같음
import torch
my_model = ModelClass(...)
state_dict = torch.load(checkpoint_file)
my_model.load_state_dict(state_dict)
→ state_dict란
‘’’In PyTorch, the learnable parameters (i.e. weights and biases) of a **torch.nn.Module** model are contained in the model’s parameters (accessed with **model.parameters()**). A **state_dict** is simply a Python dictionary object that maps each layer to its parameter tensor.’’’
→ ModelClass가 가지고 있는 device(mps 또는 cuda)가 요구하는것보다 더 많은 메모리를 요구하는 경우, OOM이 발생할 수 있음
- RAM(VRAM X)을 많이 차치하지 않은 empty skeleton model을 먼저 load한다.
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)
- Instantiate한 Model이 ‘Parameterless’하기 때문에 load_checkpoint_and_dispatch()라는 함수를 통해서 checkpoint를 empty model에 load하고, 모든 device(GPU/MPS 및 CPU RAM)에 걸쳐 weight를 보낸다.
[device_map="auto" 로 설정하면 GPU → CPU → RAM → DISK 순서로 자동적으로 weight를 보냄]
from accelerate import load_checkpoint_and_dispatch
model = load_checkpoint_and_dispatch(
model, checkpoint=checkpoint_file, device_map="auto"
)
→ ‘no_split_module_classes’ argument로 분리되면 안되는 layer를 지정해줘야하는데 (e.g, no_split_module_classes=['Block']) 모델별 달라서 사용전에 필히 확인!
→ Conceptual 영상에 따르면 이후 Garbage Collecter가 Checkpoint 메모리에서 회수해간다고 함
- Inference는 아래와 같은 과정으로 진행
- 각 Weight에 hook이 추가됨 (이건 weight를 VRAM에서 On/OFF loading하는 역할을 진행)
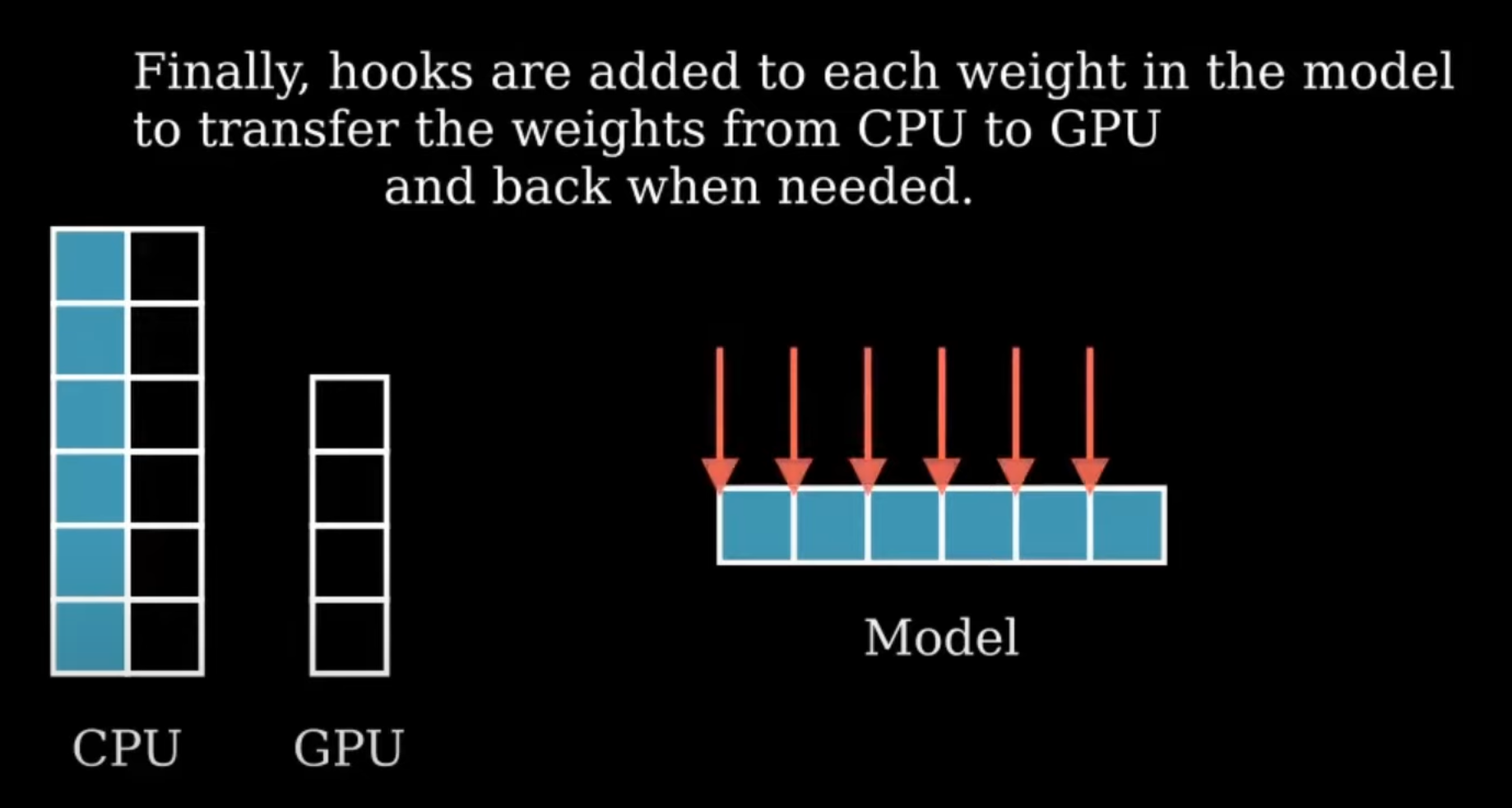
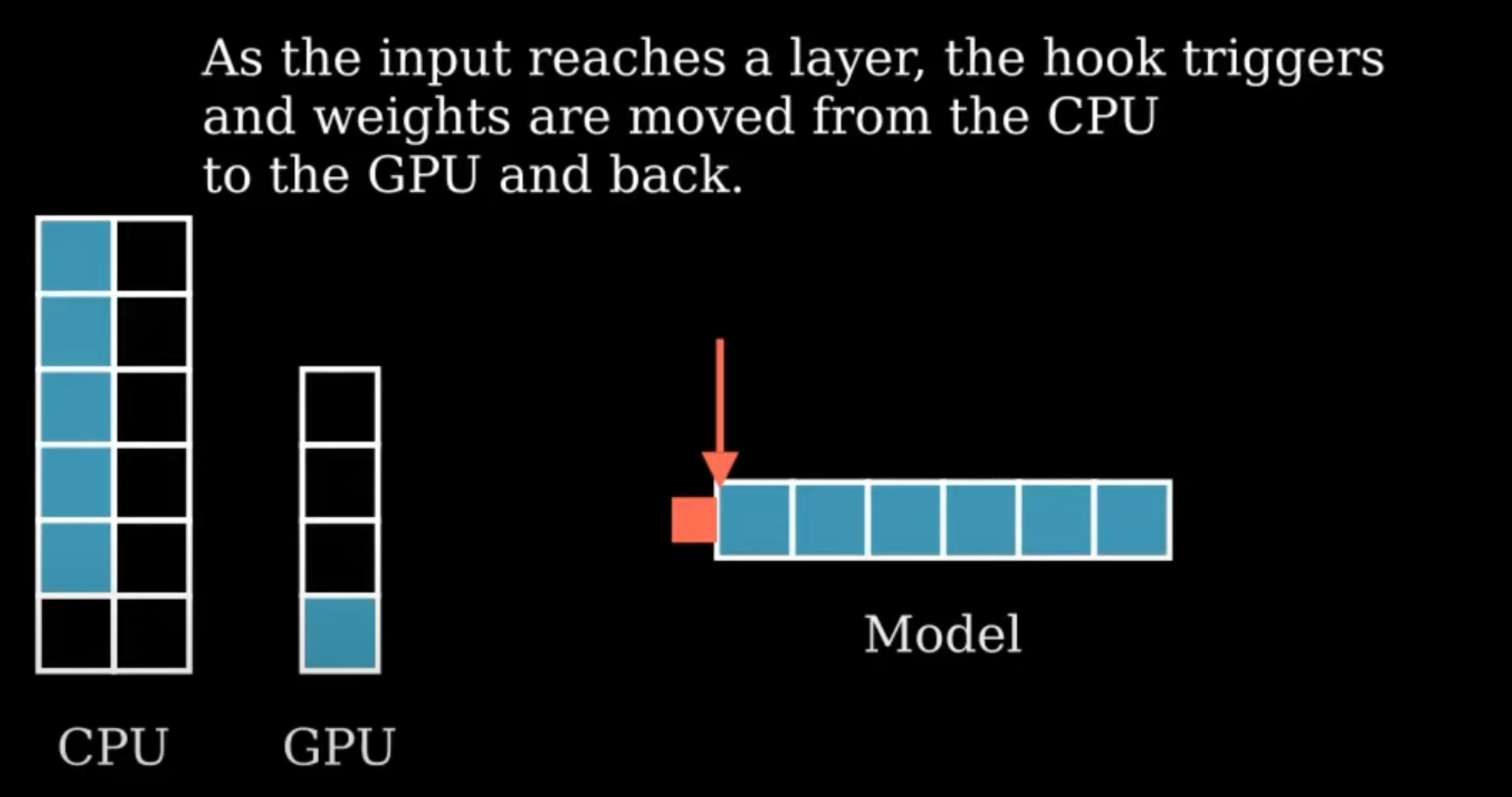
- Input이 첫번째 layer에 도달하면 hook이 trigger되면 첫번째 layer가 CPU RAM → GPU VRAM으로 이동해서 Forwarding이 진행됨
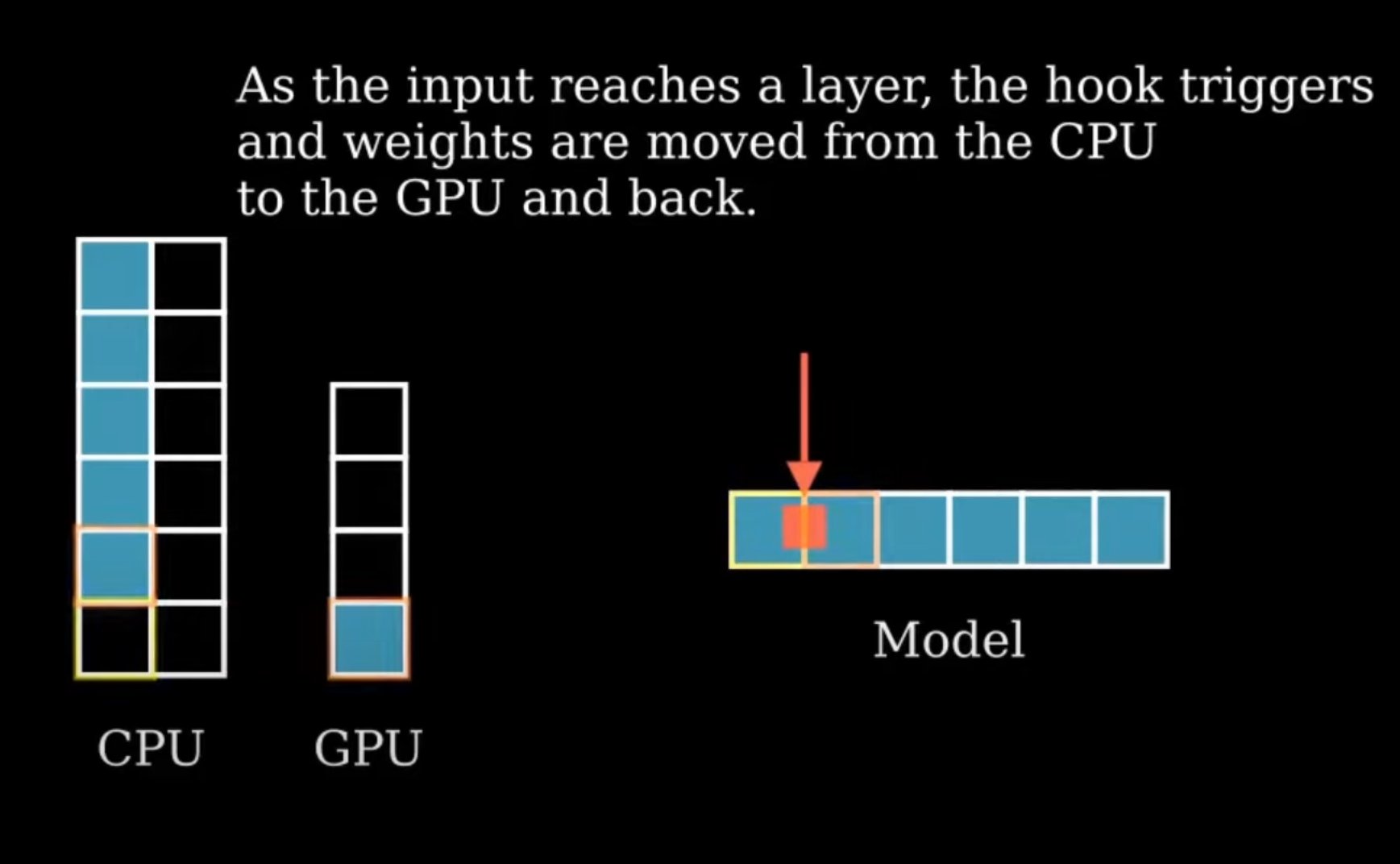
- 2번째 layer에 도달하면 hook이 trigger되고 1번째 layer는 GPU VRAM → CPU RAM으로 이동 & 2번째 layers는 CPU RAM → GPU VRAM으로 이동한 후 Forwarding이 진행됨
- 예시
# Create a model and initialize it with empty weights
weights_location = hf_hub_download(model_name, "model.safetensors.index.json")
with init_empty_weights():
model = AutoModelForCausalLM.from_pretrained(model_name)
# Load the checkpoint and dispatch it to the right devices
model = load_checkpoint_and_dispatch(
model, checkpoint=weights_location, device_map="auto", no_split_module_classes=["LlamaDecoderLayer"], dtype=torch.float16)
model.eval()
# input forwarding
model.generate(input_ids=input_ids['input_ids'].cuda(), attention_mask=input_ids['attention_mask'].cuda())
→ “”model.safetensors.index.json””
[index.json: It maps these configurations to the actual files stored in the repository, guiding users or automated systems on how to correctly load the model.]
{
"metadata": {
"total_size": 137953316864
},
"weight_map": {
"lm_head.weight": "model-00015-of-00015.safetensors",
"model.embed_tokens.weight": "model-00001-of-00015.safetensors",
"model.layers.0.input_layernorm.weight": "model-00001-of-00015.safetensors",
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00015.safetensors",
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00015.safetensors",
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00015.safetensors",
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00015.safetensors",
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00015.safetensors",
- Reference