How to Train LLM? - From Data Parallel To Fully Sharded Data Parallel
논문 정보
- Date: 2024-05-07
- Reviewer: 준원 장
- Property: LLM, Pre-Training, torch
! 본 내용에 잘못된 내용이 있을 수도 있으니, 혹시나 잘못된 부분 있다면 언제든 지적해주시면 감사하겠습니다!
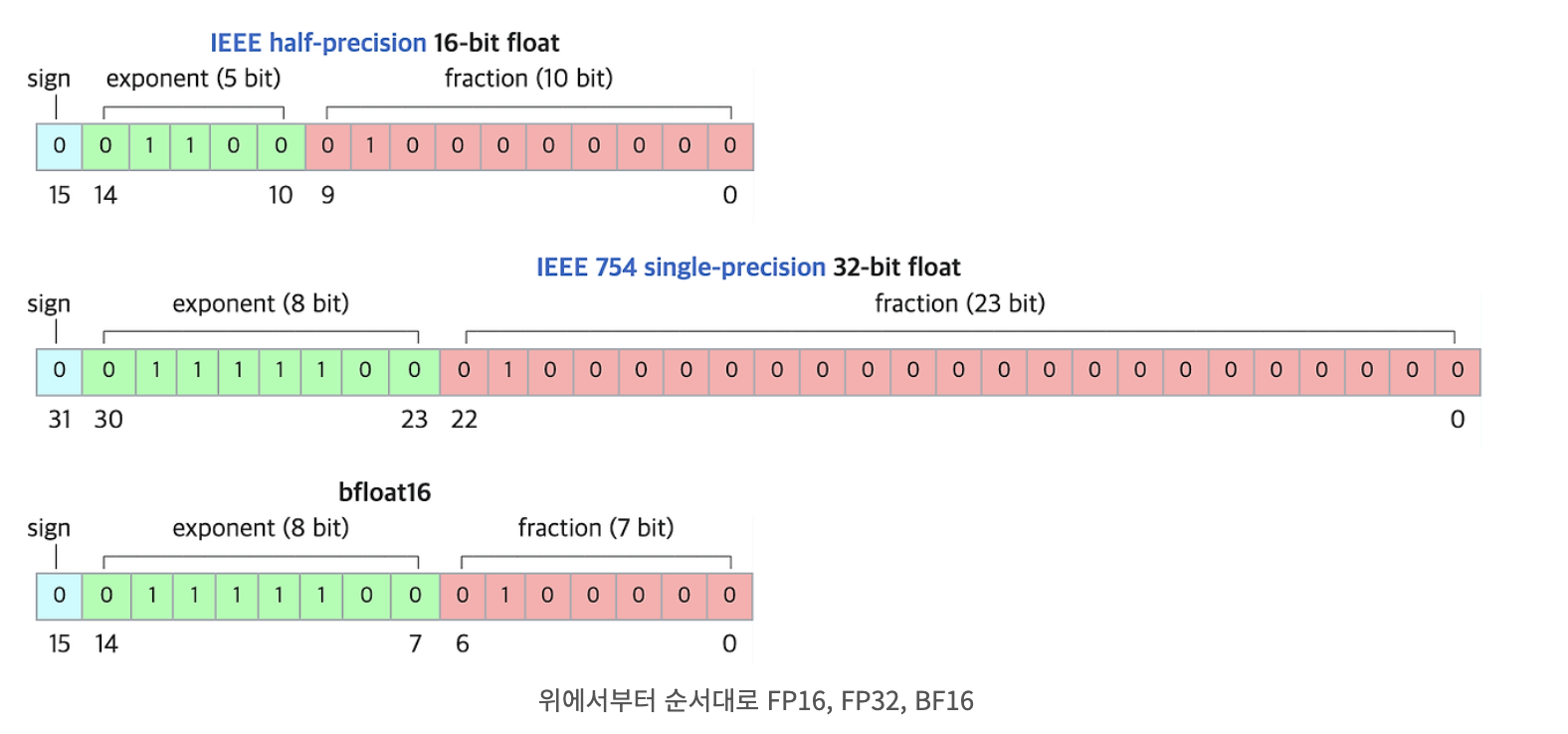
0. Floating Point
-
컴퓨터에서 실수를 표현하는 방법으로, 수를 Exponent와 Fraction로 분리하여 표현.
-
IEEE 754 표준은 floating 포인트 수를 표현하는 데 널리 사용되는 표준. 해당 표준에서는 다양한 정밀도를 제공.
-
floating exampling
-
십진수 -0.5625
-
이진수 -0.1001
- → -1.001 X x 2^(-1)
-
Sign: 1 (음수는 1임)
-
Exponent: 127 + (-1) = 126
-
Fraction: 0010 0…
-
fp32: **1 **01111110** **00100000000000000000000
-
-
FP16
→ fp32 대비 Exponent와 Fraction을 둘다 줄여 DL모델의 inference시 연구자들이 주로 사용하는 precision. (일반적으로 fp32으로 모델학습, fp16으로 inference을 하나 실험적으로 fp32대비 분명한 성능하락 확인)
- BF16
→ BF16은 fp16과 다르게 자릿수를 대표하는 exponent 동일한 8비트로 설정함으로써 더 넓은 범위의 수를 표현할 수 있음.
→ 대신 fraction의 자릿수를 희생했기 때문에 수의 정밀도가 떨어진다는 한계가 존재
(ex)
십진수 0.1을 이진수로 표현하면 무한 반복 이진수: **0.0001100110011001100...** (반복)
-
fp16
-
fraction는 10비트를 사용하여 이 값을 가능한 한 정확하게 근사:
**0.0001100110** -
exponent는 이진 표현에서 소수점을 왼쪽으로 몇 칸 이동시켜야 하는지에 따라 결정되며, 이 경우 -4. exponent 필드 값은 −4+15=11 (이진수
**01011**). -
bf16
-
fraction는 7bit를 사용하여 값을 근사:
**0.0001100** -
exponent는 FP16과 동일하게 -4이고, 지수 필드 값은 −4+127=123 (이진수
**01111011**). -
결론
⇒ Layer가 깊어질수록 logit값이 커지는 transformer계열에서는 BF16을 활용해 모델을 training하는 것이 적합해보임. input의 스케일이 크게 다른 경우, BF16은 underflow나 overflow를 방지할 수 있음.
⇒ Normalization, Optimizer state 연산 (e.g., momentum) 등 term을 계속해서 나눠주는 연산의 경우 정밀도를 희생한 BF16은 오차를 유발할 수 있기 때문에 mixed precision 같은 방법론들을 도입해서 한계를 방지해야함.
1. Mixed Precision
-
Mixed Precision은 DL 학습 시 다양한 Precision을 혼합하여 사용하는 기술.
-
대표적으로 NVIDIA의 Tensor Cores에서는 fp16과 fp32를 혼합하여 더 빠른 수행 시간과 높은 수치 정밀도를 제공
-
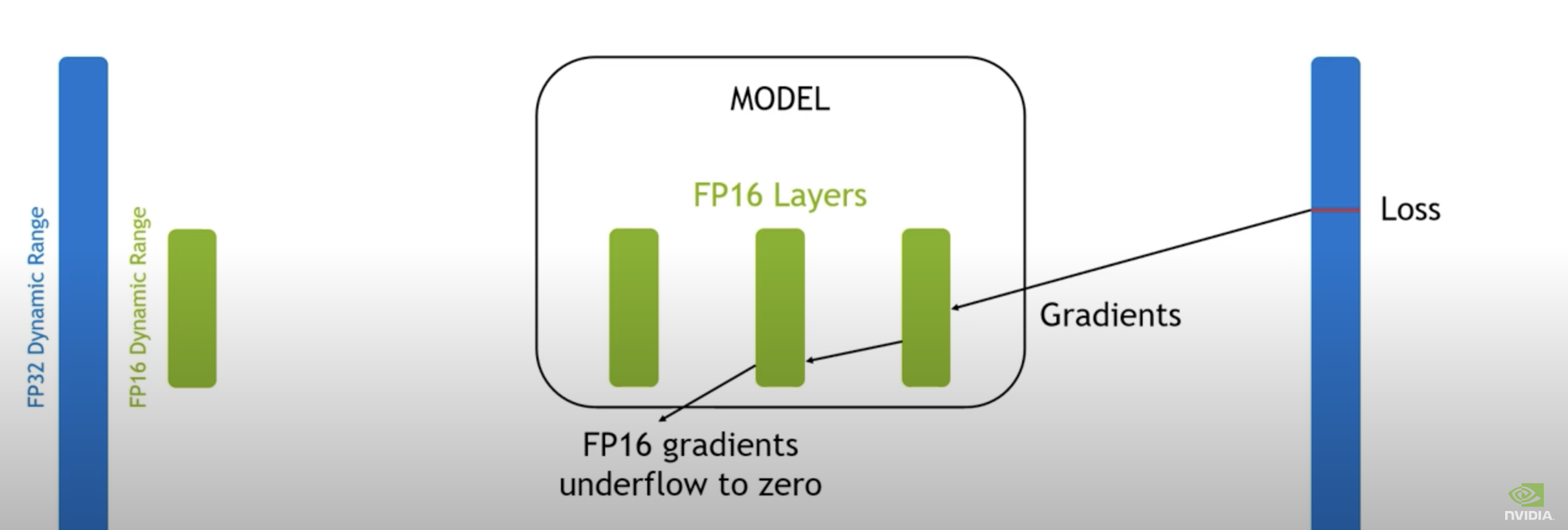
fp16으로는 표현할 수 있는 숫자체계가 제한적이기 때문에 gradient update시에 underflow 문제 발생 가능
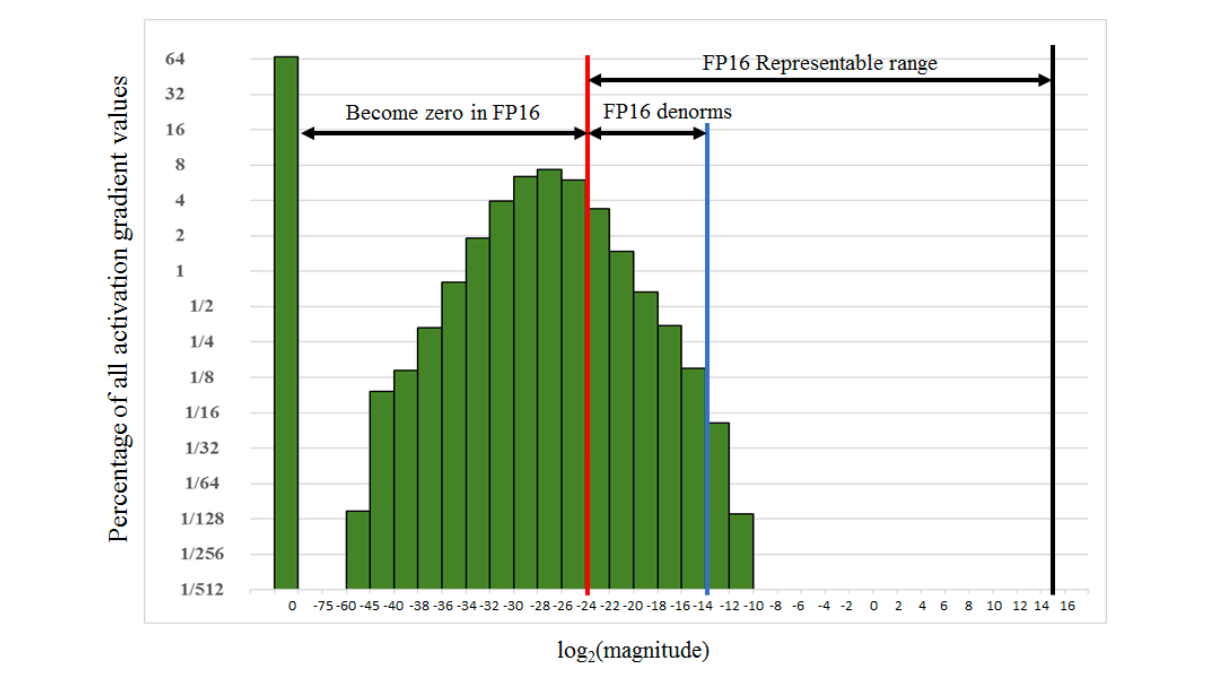
→ 빨간선 왼쪽이 fp16으로 표현할 수 없는 범위
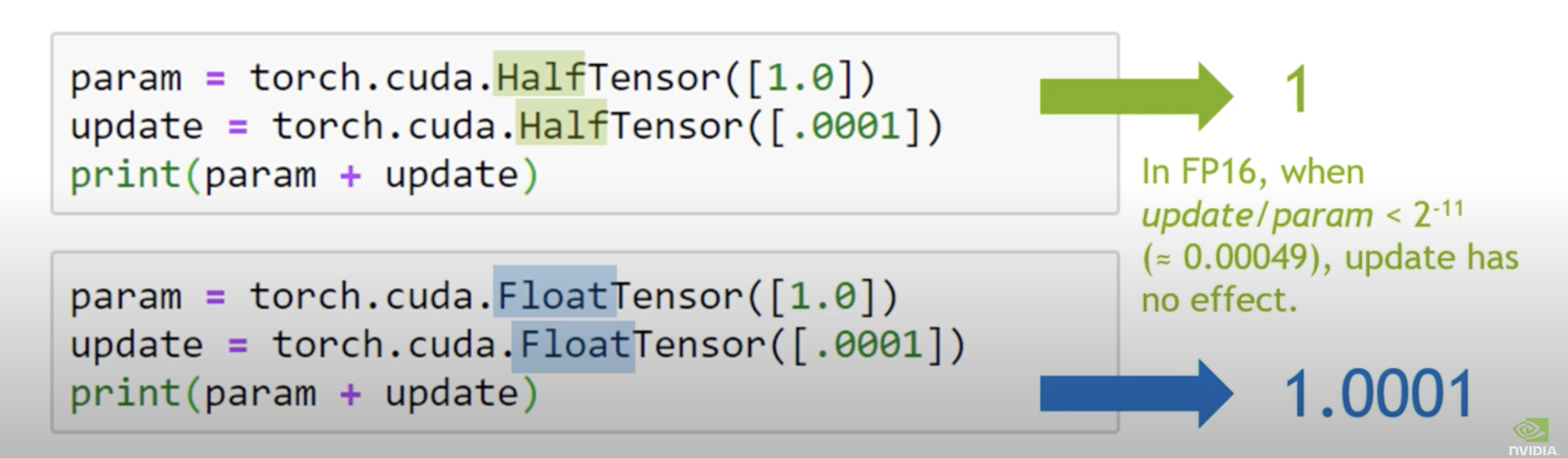
→fp16으로 tensor 연산 시의 문제점
- 위를 해결하기 위해 Precision을 혼합해서 활용하는 Mixed Precision 기법이 나옴
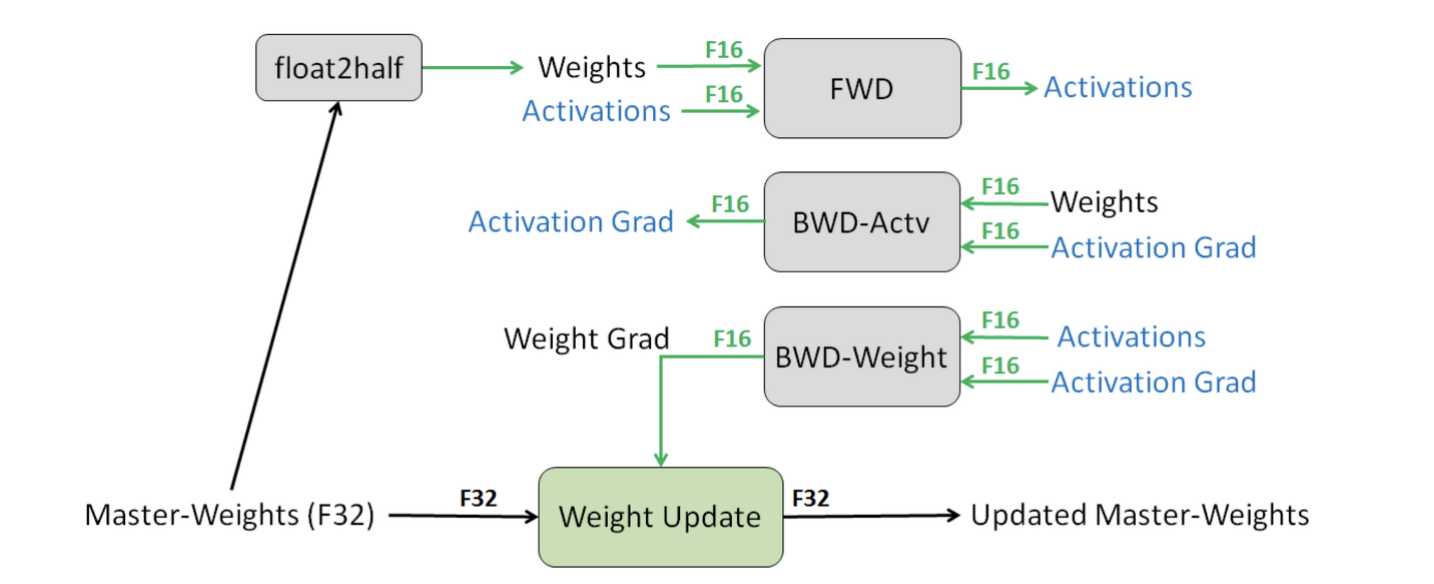
- BWD-Actv & BWD-Weight 계산 예시

- 가정: 우리의 Model은 fp32이다. 해당 모델이 가지고 있는 weights을 Master weights라고 명명.
-
fp32로 표현된 Master weights을 복사하여 fp16 weights로 가져옴
-
fp16 weights로 forward & loss 계산
-
loss값이 scaling factor를 곱한다.
(fp16으로 표현된 상태에서 Gradient을 구하면 backprop 과정 중 underflow 발생 가능)
[FROM]
[To]
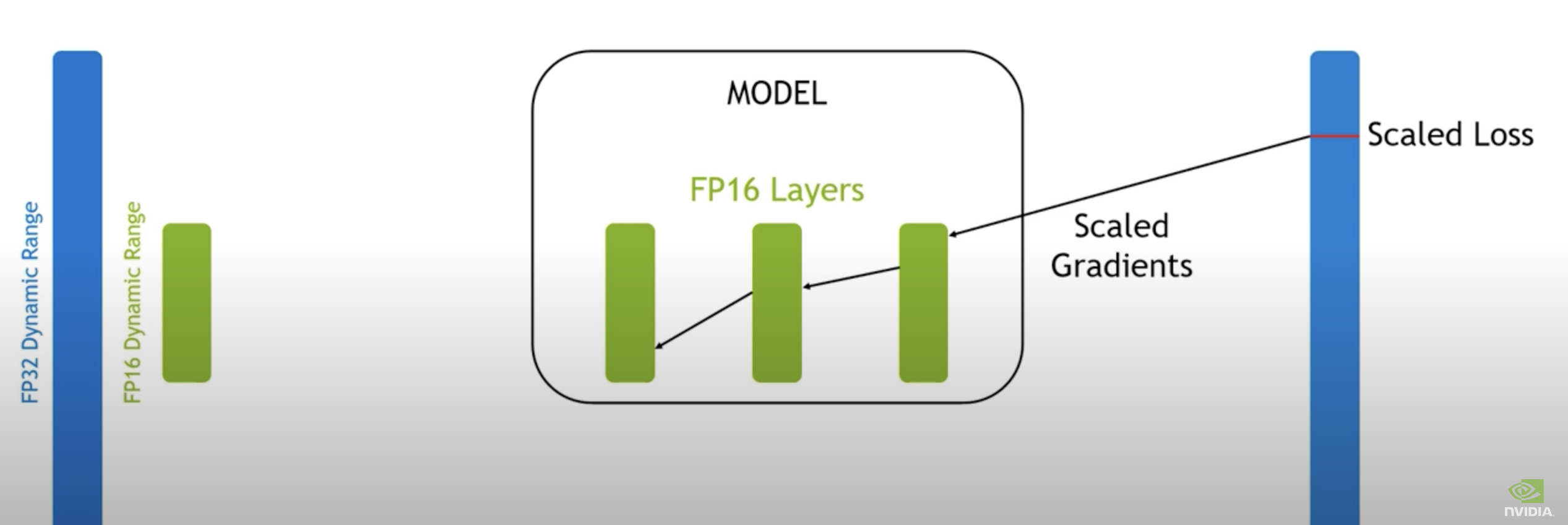
-
fp16으로 표현된 loss에서 backward (loss.backward()) → backpropagate 한다.
-
upscaling한 gradient(XS)를 optimizer.step()을 위해서 다시 unscale (X1/S)해준다.
-
이때 nan value, 0 되는지 check
-
Gradient clipping, weight decay 등을 적용
-
optimizer의 state term등은 전부 fp32 상태로 저장
(optimizer는 state initialization할때 default로 fp32를 사용)
# State initialization
if len(state) == 0:
# note(crcrpar): Deliberately host `step` on CPU if both capturable and fused are off.
# This is because kernel launches are costly on CUDA and XLA.
state["step"] = (
torch.zeros((), dtype=_get_scalar_dtype(is_fused=group["fused"]), device=p.device)
if group["capturable"] or group["fused"]
else torch.tensor(0.0, dtype=_get_scalar_dtype())
)
- optimizer.step()은 fp32에서 이루어지며 master weight을 업데이트 함.

- Torch AMP(Automatic Mixed Precision)에 위의 설명 및 코드가 그대로 반영되어 있음
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
2. List of NCCL Operation
- 2개의 프로세스간의 통신 패턴을 point-to-point communication(점대점 통신)라고 명명한다면, 여러 개의 프로세스간의 통신을 collective communication(집합 통신)이라고 명명한다.
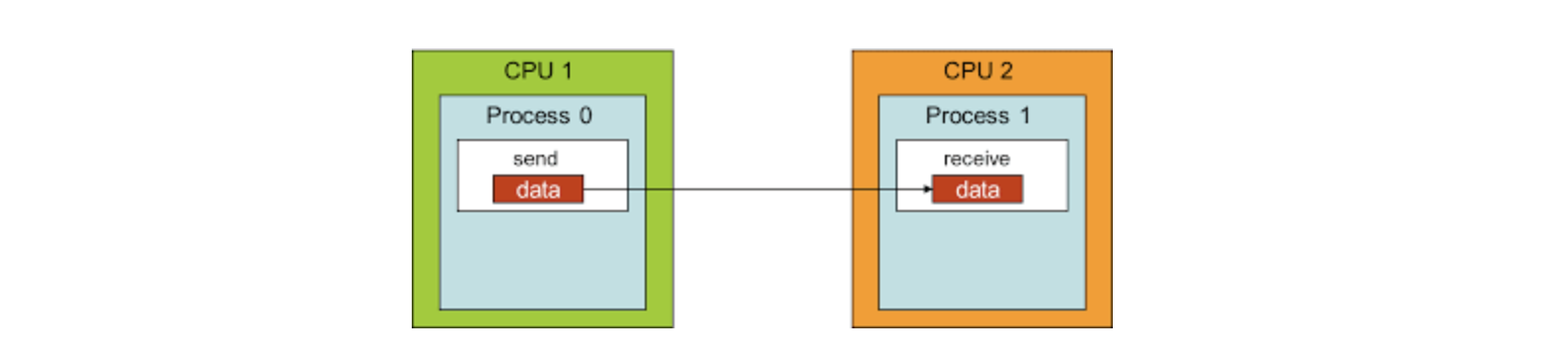
→ point-to-point communication는 sender는 데이터를 보내고, receiver는 데이터를 받도록 설계하면 되기 때문에 구현 난이도가 상대적으로 쉬움
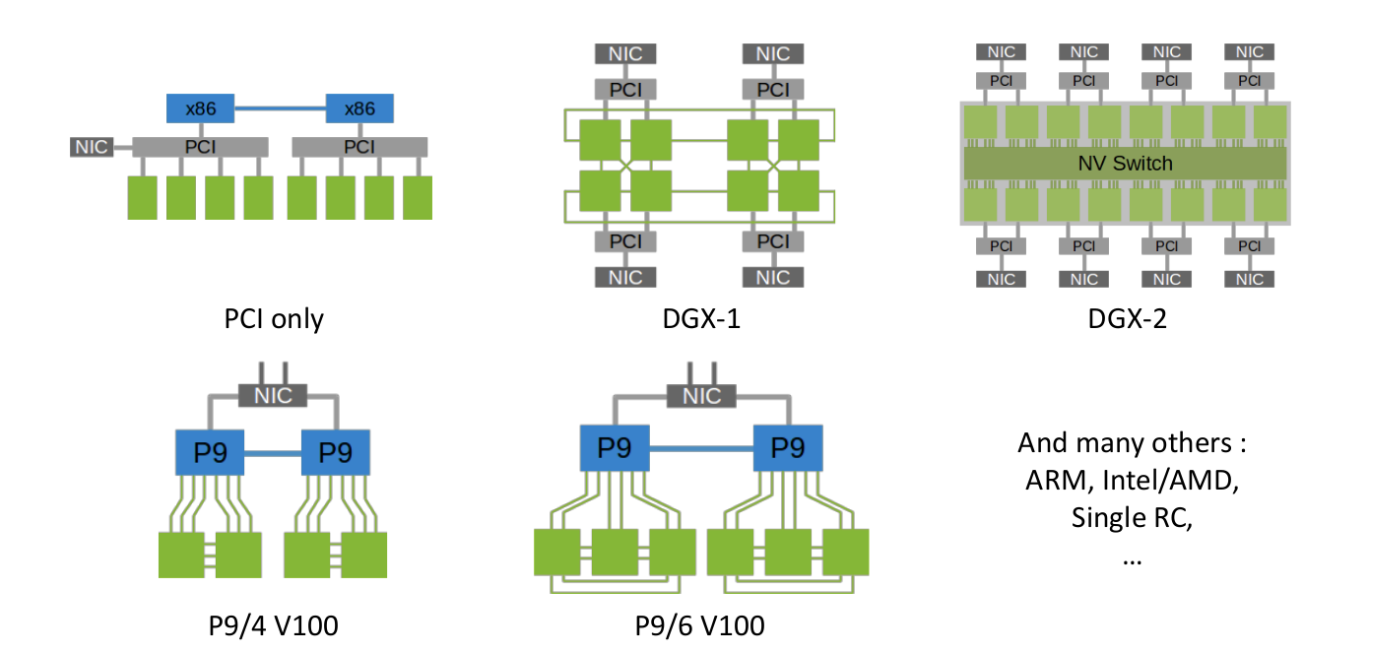
→ multiple senders와 multiple receivers가 있는 collective communication의 경우, topology들이 구성이 매우 다양하기 때문에 (위 그림처럼) 데이터 통신을 최적화하기 매우 어렵다는 한계점이 존재한다.
-
조금 더 자세히 말하면, 몇 개의 GPU가 있고, 어떤 GPU가 어떤 GPU와 어떻게 연결(PCIe, NVLink, IB, ethernet 등등) 되어 있는 지와 같은 topology 정보는 통신 최적화에 필수로 고려해야 하는 요소인데, 그 조합이 너무나도 많기에 이것을 다 만족하는 최적화된 솔루션을 찾아 구현하기가 매우 어렵다.
-
이러한 문제점을 해결하기 위해 ‘Pitch Patarasuk and Xin Yuan. Bandwidth optimal all-reduce algorithms for clusters of workstations. J. Parallel Distrib. Comput., 69:117–124, 2009.’에서 모든 어떤 topology라도 Ring(s) topology로 생각하고 구현할 경우 최적 성능을 달성할 수 있음을 보여줌.
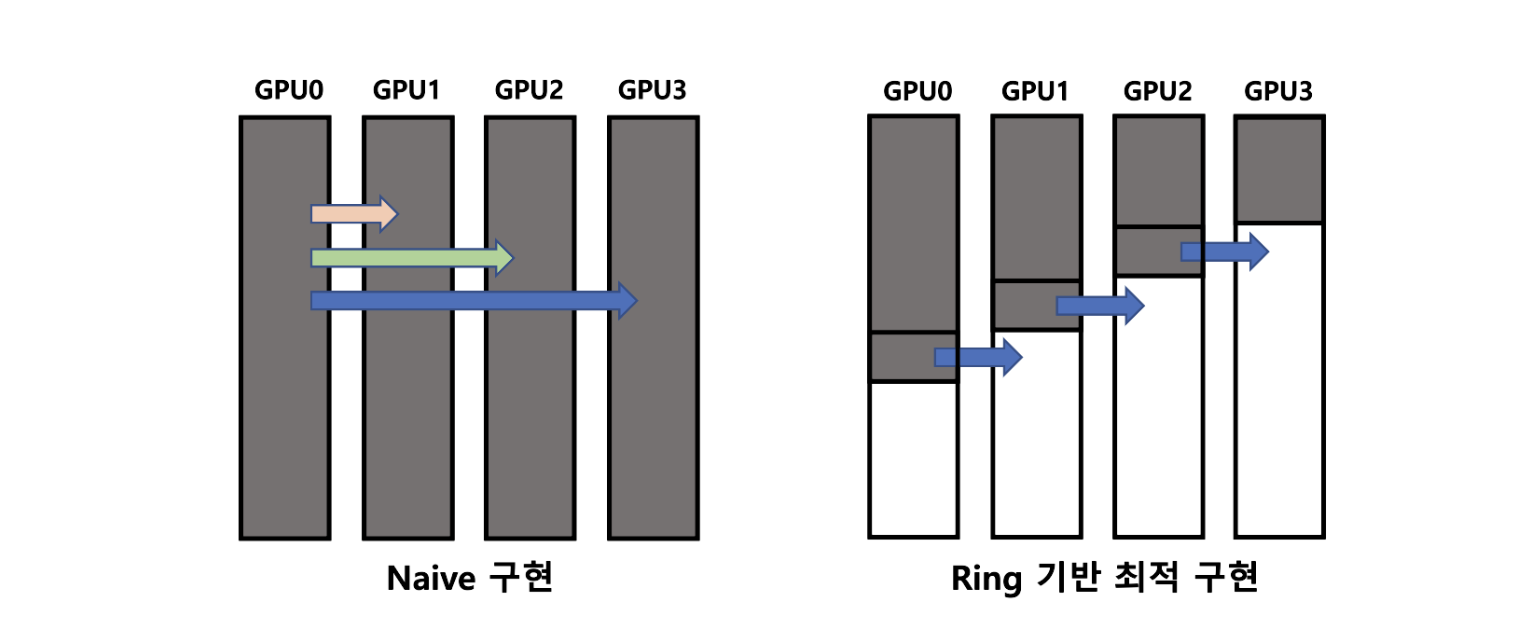
→ 위는 Broadcast 연산인데 GPU0이 GPU[1:3]에 data를 뿌릴때 순차적으로 (GPU0→ GPU1 이 끝나면 GPU0 → GPU2 …)으로 하는게 아니라 데이터를 작은 조각으로 나누어서 GPU0 → GPU1 & GPU1 → GPU2 & GPU2 → GPU3 이렇게 인접한 모든 프로세스가 데이터를 전송하도록 구현하였음.
-
NCCL(NVIDIA Collective Communications Library)은 멀티 GPU 및 멀티 노드 환경에서 고성능을 제공하는 통신 라이브러리로 다양한 네트워크 topology에서도 최적 성능을 달성하는 것을 목표로 개발되었으며 이전에 언급한 Ring-based 집합통신 알고리즘을 기반으로 최적화된 집합 통신을 구현
-
NCCL은 DL training, inference에서의 다양한 집합 연산(예: All-reduce, All-gather, Broadcast 등)을 최적화하여 각 GPU 사이에 일관되고 효율적인 통신을 제공하여 병렬 처리 성능을 극대화하는것에 목표를 두고 있음.
-
동기 및 비동기 통신을 지원하며, CUDA 스트림을 통해 다른 연산과 겹쳐서 수행이 가능하다고 함.
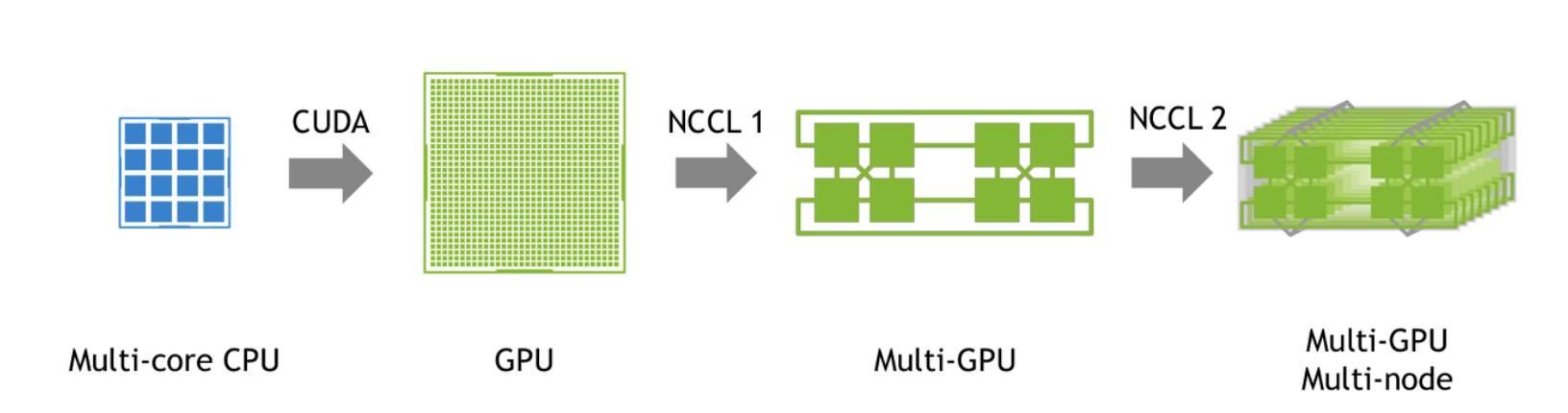
→ (1) GPU를 이용한 연산 GPGPU(CUDA)으로 가속화 (2) NCCL을 활용해 하나의 GPU가 아닌 multiple GPUs, 나아가 multi-node 상의 multiple GPUs의 통신을 통한 연산 가속화
-
General-Purpse computing on Graphic Processing Unit: 일반적으로 컴퓨터 그래픽스를 위한 계산만 맡았던 그래픽 처리 장치를, 전통적으로 중앙 처리 장치가 맡았던 응용 프로그램들의 계산에 사용하는 기술
-
간단한 용어 정리
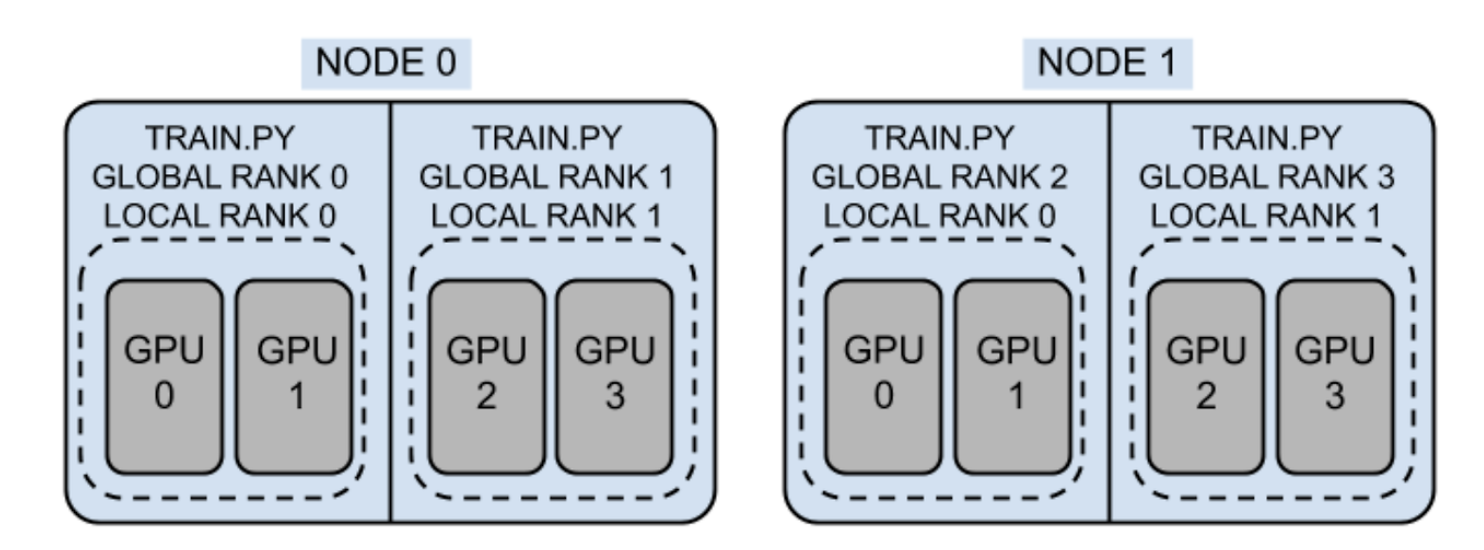
→ Node : 2개
→ Global World Size : 4 X 2 = 8
→ Local World Size : 4 X 1 = 4
- → Rank: process_id
-
일반적으로 DDP에서 1개 node안에서 각 node에서 각 gpu마다 1개 process를 배정함
-
Local World Size = # of Rank
- NCCL Operations (DP나 DDP 쓰면서 다들 호출해보셨을 operations들)
-
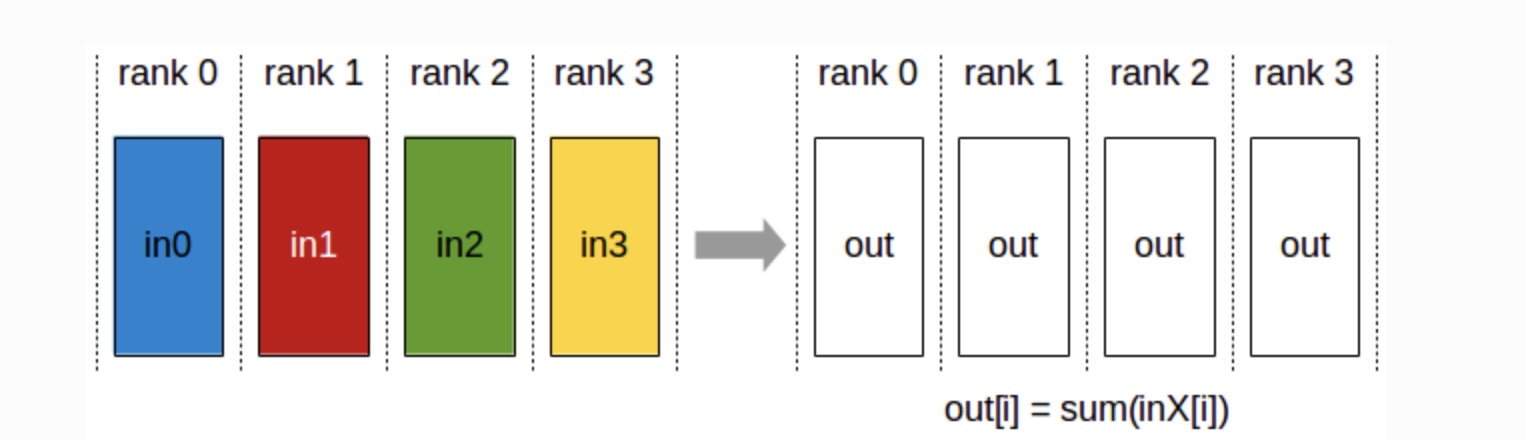
AllReduce
-
모든 GPU(rank)의 데이터를 결합하여 그 결과를 모든 GPU에 다시 배포
-
예를 들어, 각 GPU가 데이터 조각을 가지고 있을 때, 이 데이터를 합산하여 모든 GPU에 결과를 제공
-
mini batch별로 GPU에 forwarding하고 Loss 평균내기 전에 가장 많이 쓰는 operation
-
Broadcast
-
한 GPU에서 다른 모든 GPU로 데이터를 보냄.
-
예를 들어, 첫 번째 GPU의 데이터를 나머지 3개의 GPU와 공유.
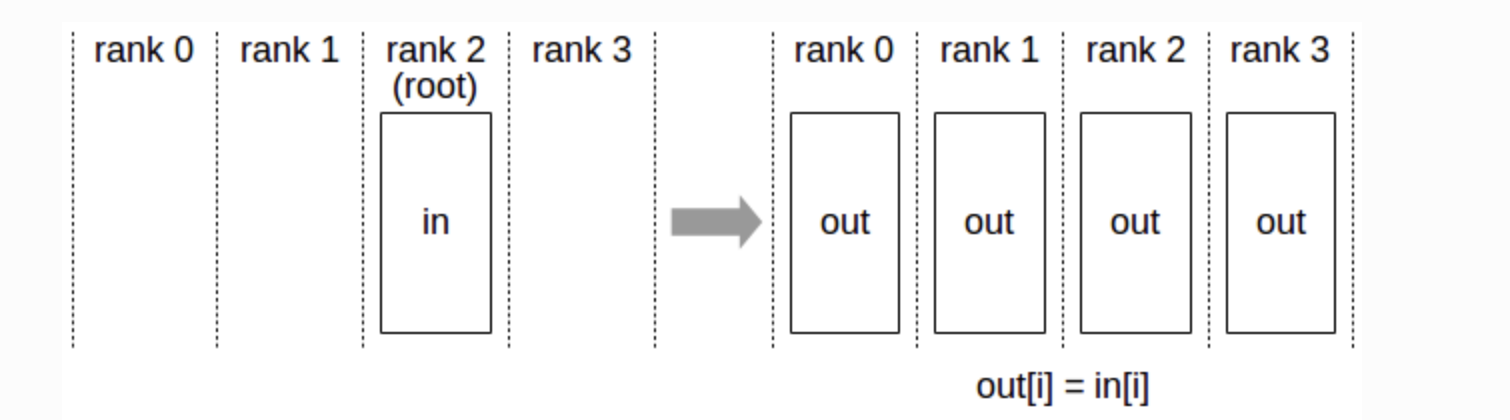
-
Reduce
-
모든 GPU의 데이터를 결합하고 그 결과를 하나의 GPU로 보냄
-
예를 들어, 모든 GPU의 데이터를 합산하고 이를 첫 번째 GPU(root)에만 전달.
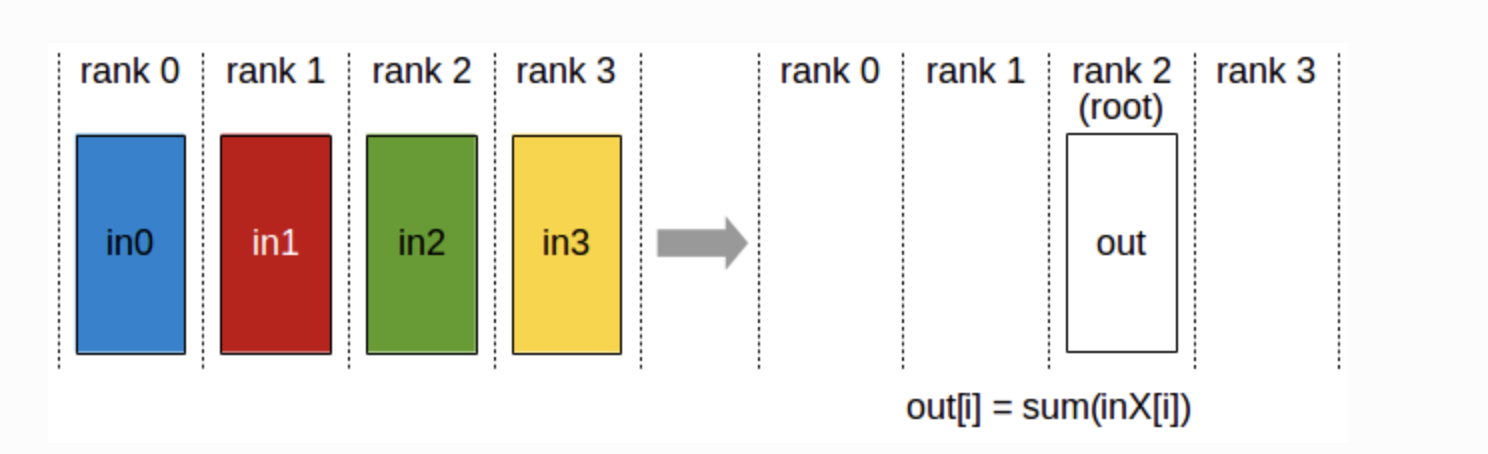
-
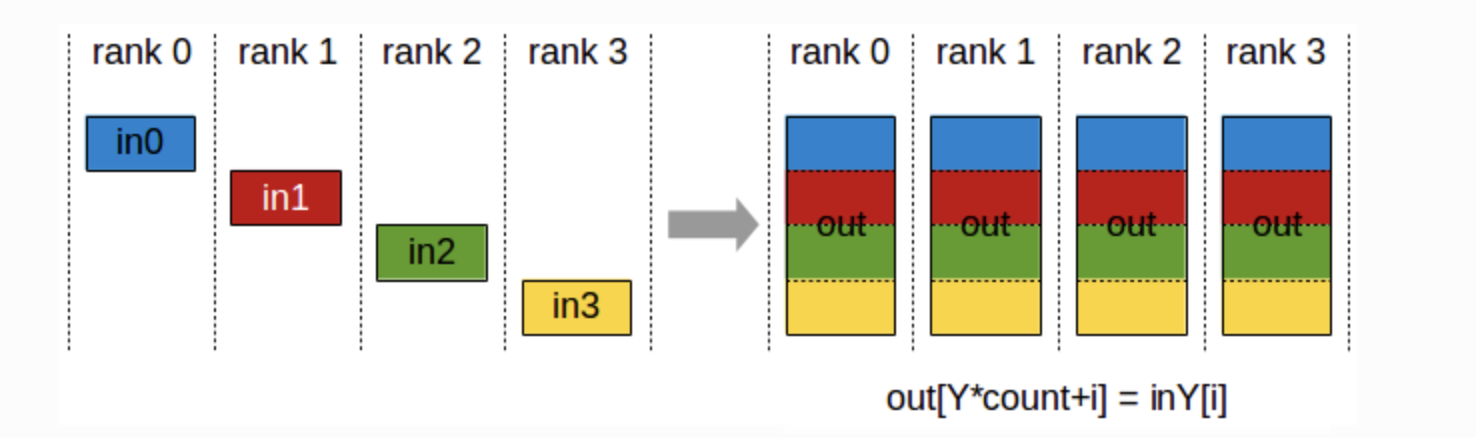
AllGather
-
모든 GPU로부터 데이터를 수집하여 모든 GPU에 분배
-
각 GPU가 데이터 조각을 가지고 있을 때, 이들을 모두 모아서 모든 GPU에 전달
-
Fully Sharded Data Parallel에 사용
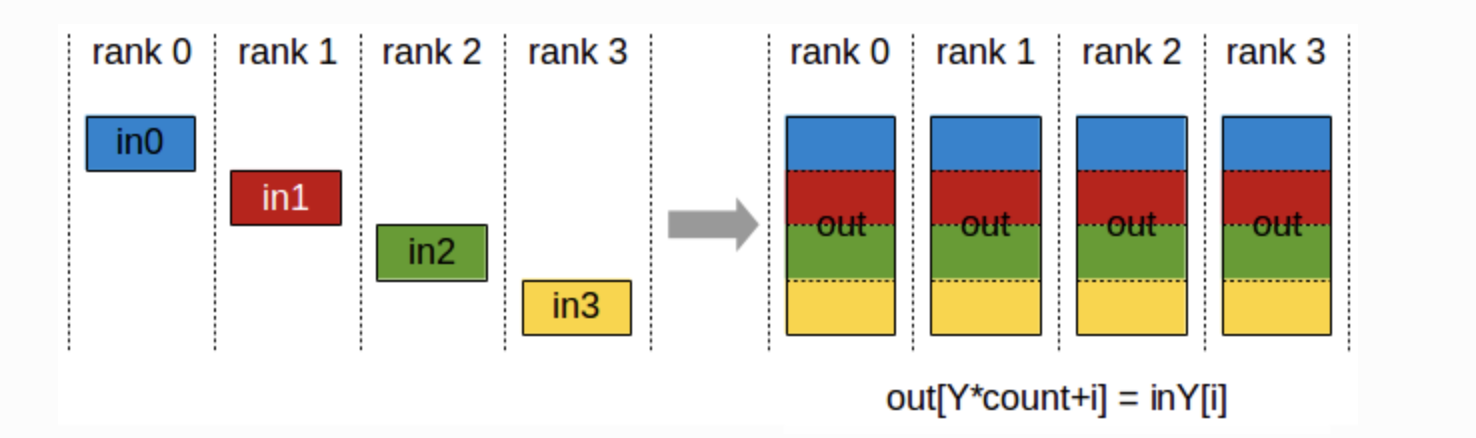
-
노드 0 :
**[in0[0], in0[1], in0[2]]** -
target node:
**out**에서**[out[0], out[1], out[2]]**에 저장 -
여기서
**Y=0**,**count=3**이므로,-
**out[0*3+0] = in0[0]** -
**out[0*3+1] = in0[1]** -
**out[0*3+2] = in0[2]**
-
-
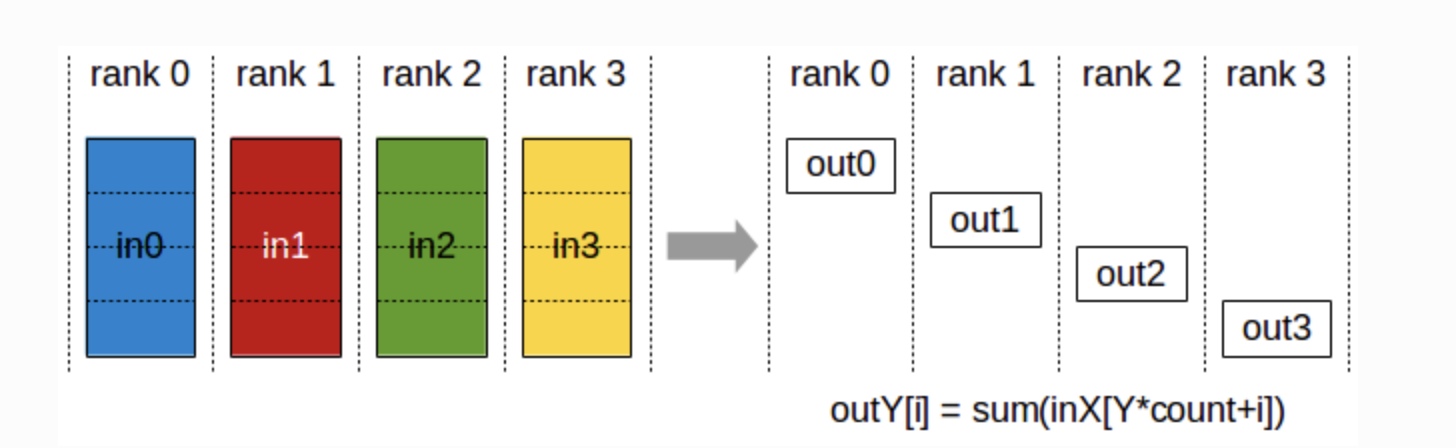
ReduceScatter
-
모든 GPU의 데이터를 결합하고 그 결과를 모든 GPU에 분산.
-
데이터를 결합한 후, 이를 여러 조각으로 나누어 각각의 GPU에 할당.
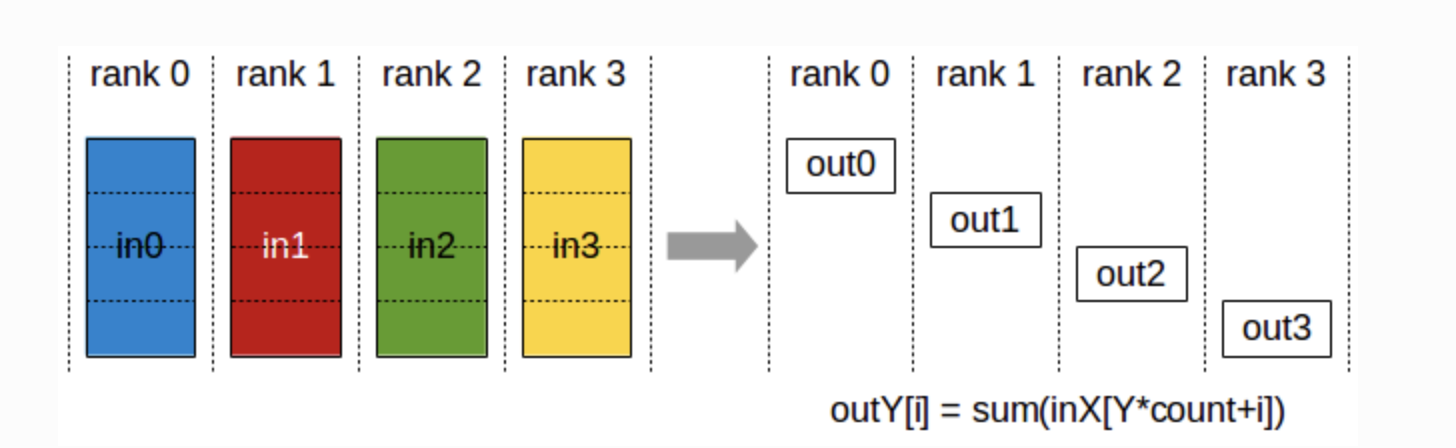
-
inXY: 노드 X에서 노드 Y로 보내진 데이터.
-
out[Y]: 노드 Y에서 모든 입력 데이터를 합산한 결과를 저장하는 배열.
-
count: 각 노드에서 전송된 데이터 요소 수.
-
i: 각 노드의 데이터 배열에서의 인덱스.
-
노드 0에서는
**[in00, in01, in02, in03]**의 데이터 존재 -
노드 1에서는
**[in10, in11, in12, in13]**의 데이터 존재 -
노드 2에서는
**[in20, in21, in22, in23]**의 데이터 존재 -
노드 3에서는
**[in30, in31, in32, in33]**의 데이터 존재
노드 0의 출력 **out0**을 구하는 방법:
-
노드 0으로 보내진 모든 데이터 요소를 합산.
-
**out0 = sum(in00*4+0, in10*4+0, in20*4+0, in30*4+0)**- 여기서
**inX0**는 각 노드 X에서 노드 0으로 보낸 첫 번째 데이터 요소를 의미.
- 여기서
3. DP (DataParallel) & DDP (DistributedDataParallel)
-
두 방법론 모두 효율적으로 모델을 학습하기 위해 등장한 방법론.
-
DataParallel은 단일 작업, 멀티쓰레드 방법론으로 GPU에 입력 데이터를 부분적으로 할당(mini-batch를 분할)하고 동일한 신경망 모델을 복제하여 이용하는 방식 -
반면,
DistributedDataParallel은 다중 작업이며 단일 및 다중 기기 학습을 전부 지원하는 방식 -
DataParallel가 가진 스레드간 GIL 경합, 복제 모델의 반복 당 생성, 입력 및 수집 출력으로 인한 추가적인 오버헤드를DistributedDataParallel가 보완해 현재는 DDP를 주로 활용, -
DP와 DDP 모두 (당연히 ) Multi-GPUs training setting을 가정함
-
DP (DataParallel)
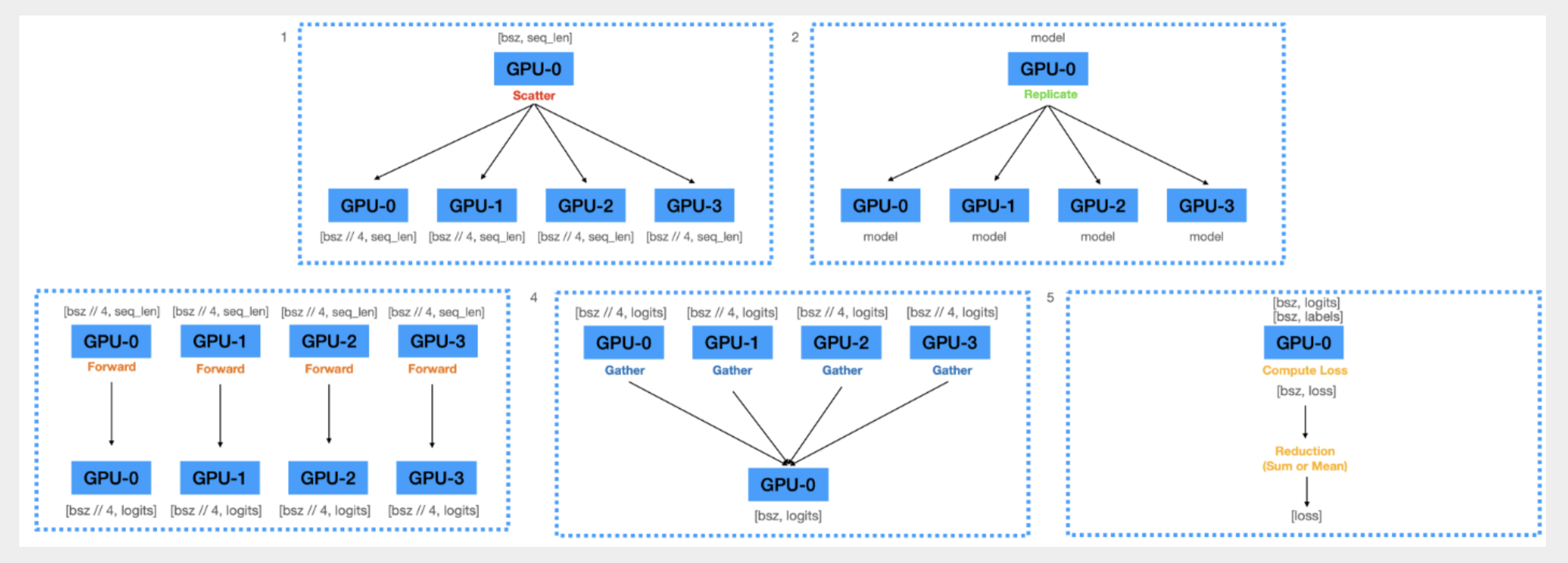
-
Scatter
-
mini-batch의 data: 128
-
GPU0이 rank_size(4)로 나누어서 GPU[0:3]에 32개씩 전송
-
Replicate
-
GPU0에 처음에 model.paramaters()를
-
model parameter를 GPU[0:3]에 broadcast
-
Forward
-
각 GPU에서 replicate model로 forward 진행
-
logit 계산
-
Gather
-
GPU[0:3]에 있는 logit을 GPU0에 계산해서 loss 계산
import torch.nn as nn
def data_parallel(module, inputs, labels, device_ids,
output_device):
# (1) [Scatter] data를 device들에 scatter
inputs = nn.parallel.scatter(inputs, device_ids)
# (2) [Replicate] model weight을 device_ids들에 복제
replicas = nn.parallel.replicate(module, device_ids)
# (3) [Forward] 각 device 에 복제된 model이 각 device의 data를 forward
logit = nn.parallel.parallel_apply(replicas, inputs)
# (4) [Gather] 모델의 logit을 output_device(하나의 device) 로 모음
logit = nn.parallel.gather(outputs, output_device)
return logits
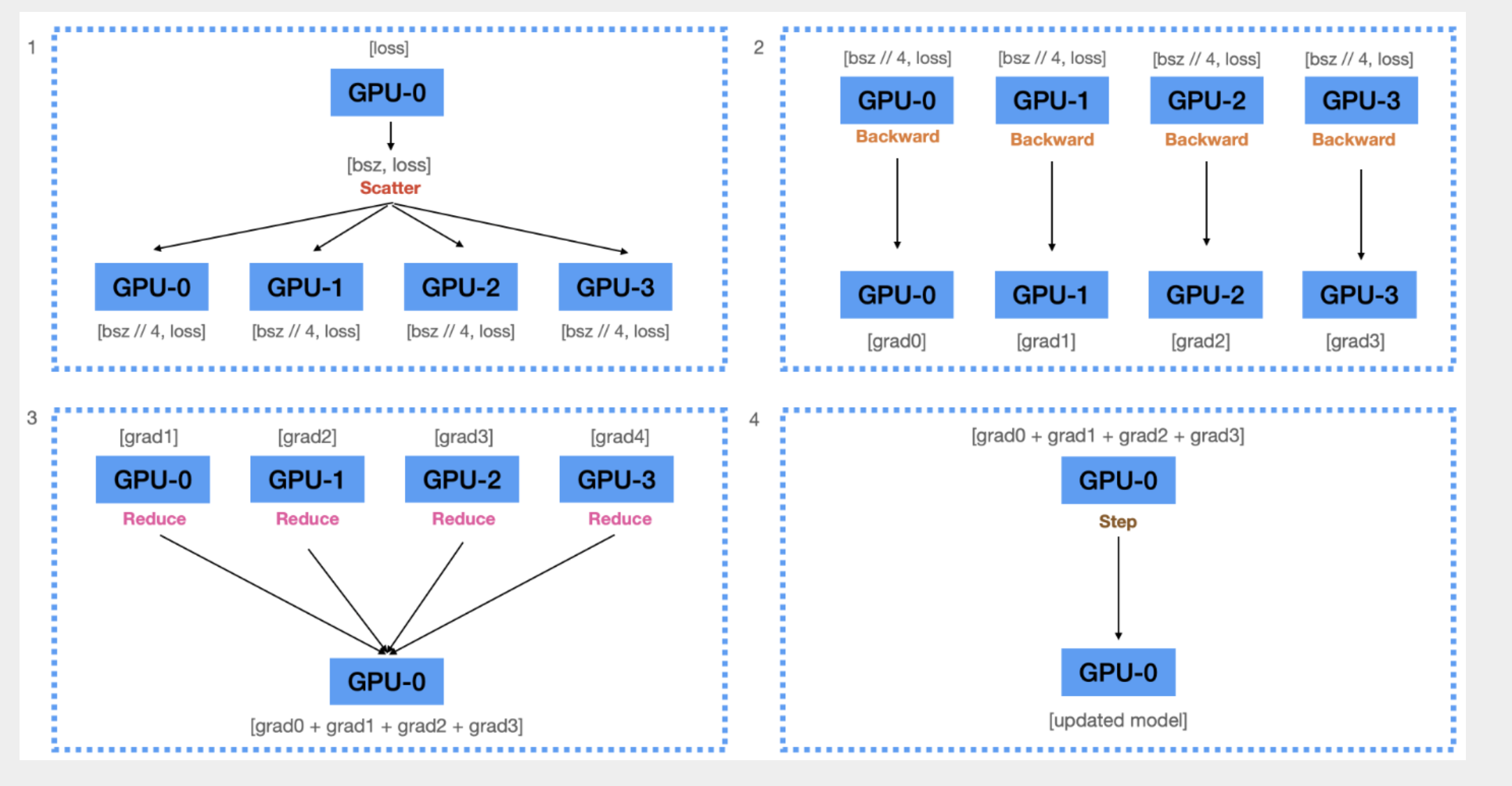
-
Scatter
-
GPU0에 계산된 loss를 각 device에 scatter
-
Backward
-
각 device(replicate model)은, 각자 전달받은 loss를 사용하여 각자 gradient 계산
-
Reduce
-
계산된 모든 graidents를 GPU0으로 reduce
-
Update
-
Gradient를 이용해서 GPU0에 있는 모델을 업데이트
-
optimizer.step()
-
이후 다시 minibatch, model을 broadcast
### DP의 문제점
→ 메모리 사용량 : 0번 GPU > 다른 GPU
→ 매 step마다 다른 device로 복제 (broadcast) 하는 문제
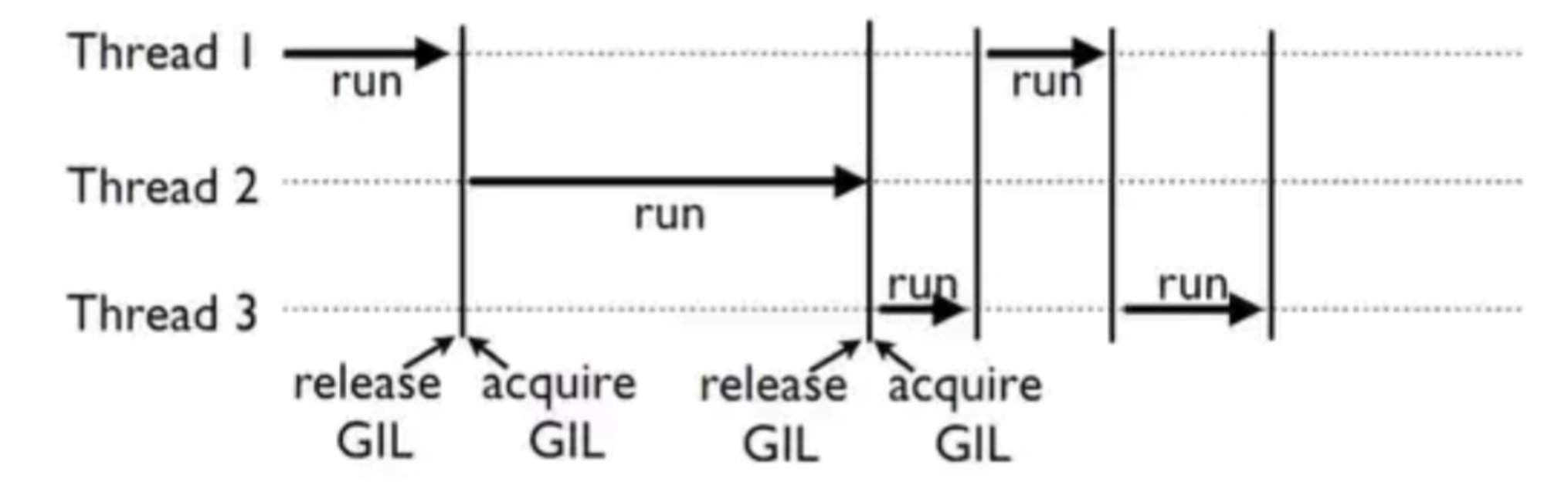
- → Python의 GIL(Global Interpreter Lock)
-
여러 개의 thread가 동시에 실행되지 못하도록 막는 기능
⇒ DDP는 multi-process로 DP의 한계를 극복하고자 함
- DDP (DistributedDataParallel)
⇒ 모델 학습 시 가장 큰 병목현상을 자랑했던 step-wise broadcasting을 해결할 수 있는 방법이 무엇이 있을까?
⇒ device에 있는 replicate들을 optimizer.step()해줄 수 있으면 모든 문제가 해결이 된다.
⇒ 어떻게 하면 모든 replicate들의 gradient들을 한 GPU에 모으지 않고 ( Gather연산) 모든 device에 한번에 뿌려줄 수 있을까? :** All-Reduce**
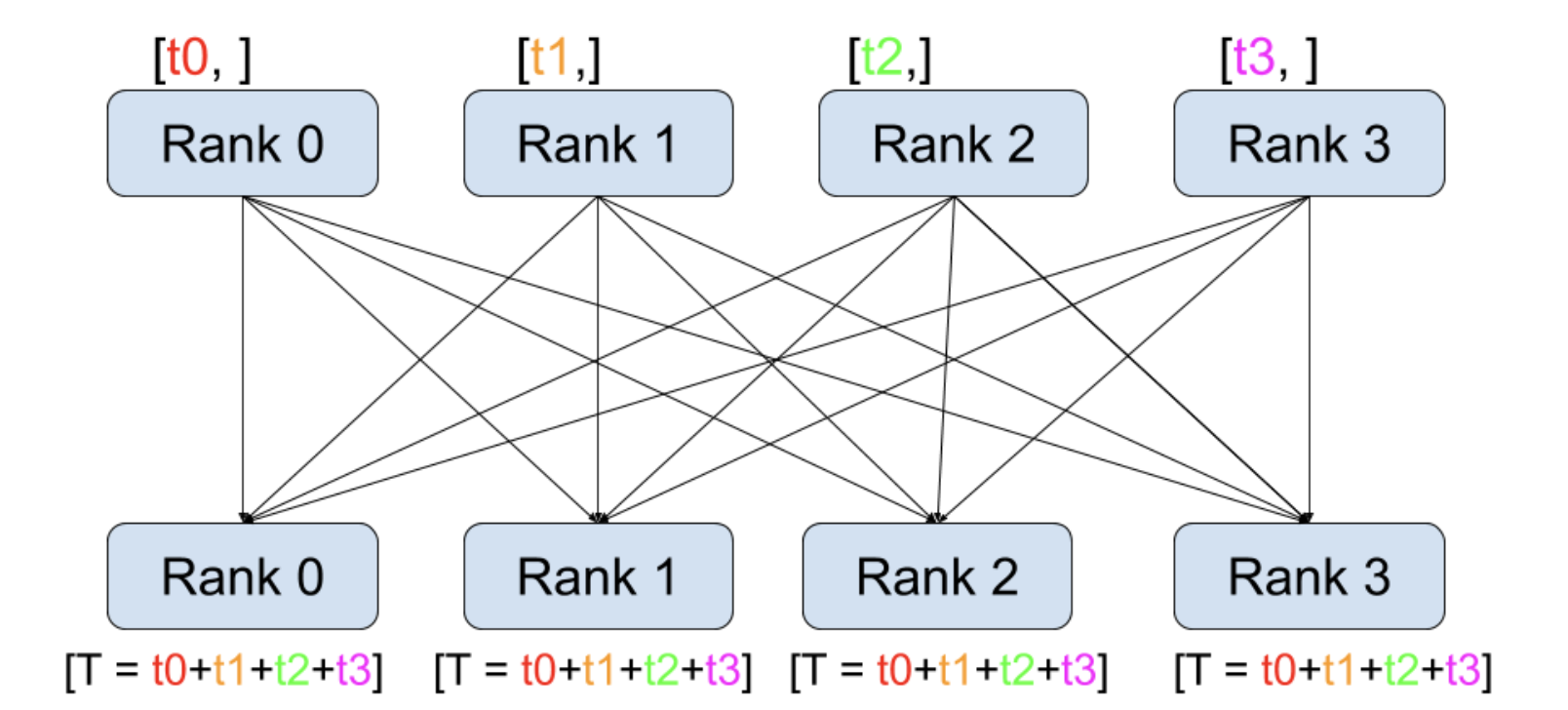
- **이전에 언급한 Ring 알고리즘 기반 All-reduce으로 **특정 device로 부하가 쏠리지 않는 프로세스 통신이 가능해짐
import torch
import torch.distributed as dist
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
tensor = torch.ones(2,2).to(torch.cuda.current_device()) * rank
# rank == 0 => [[0, 0], [0, 0]]
# rank == 1 => [[1, 1], [1, 1]]
# rank == 2 => [[2, 2], [2, 2]]
# rank == 3 => [[3, 3], [3, 3]]
dist.all_reduce(tensor, op=torch.distributed.ReduceOp.SUM)
print(f"rank {rank}: {tensor}\n)
# result
rank 1: tensor([[6., 6.],
[6., 6.]], device='cuda:1')
rank 2: tensor([[6., 6.],
[6., 6.]], device='cuda:2')
rank 0: tensor([[6., 6.],
[6., 6.]], device='cuda:0')
rank 3: tensor([[6., 6.],
[6., 6.]], device='cuda:3')
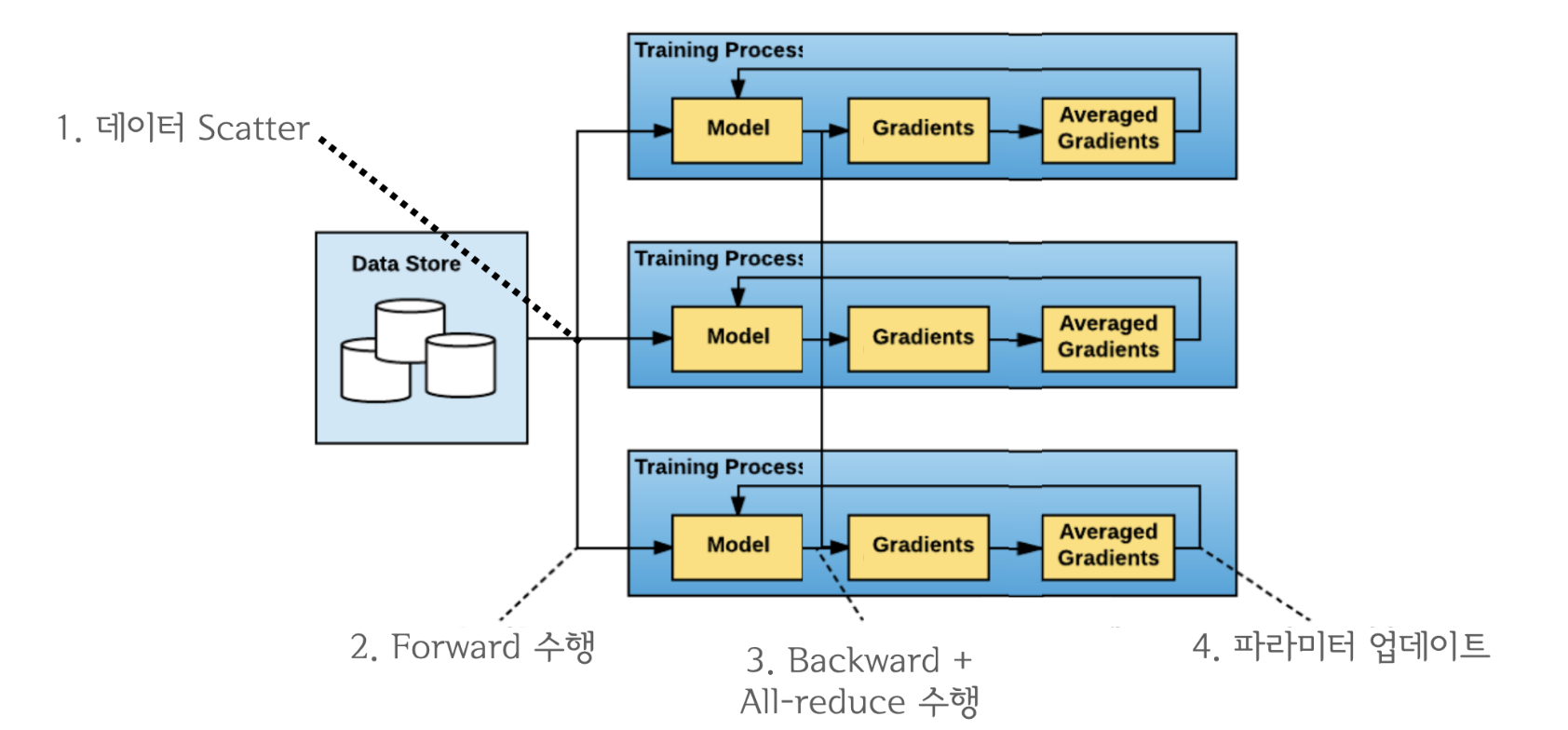
-
Scatter
-
DistributedSampler을 활용해 각 rank(process)에 mini_batch를 scatter
-
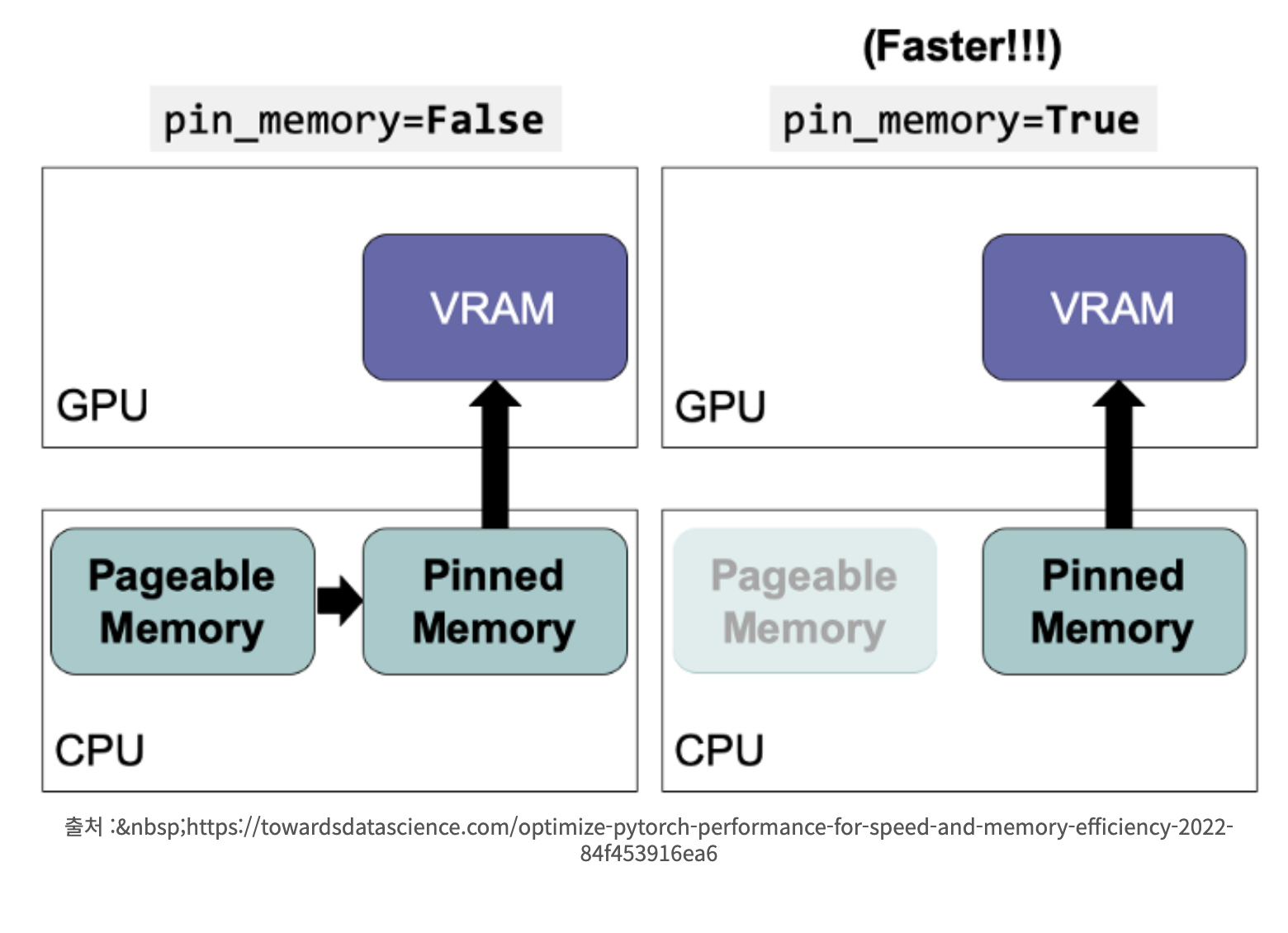
일반적으로 데이터를 메모리에 올릴 때 CPU + DRAM(pageable Memory) → Pinned Memory → VRAM에 올리는데, 속도 향상으로 위해 data load시 바로 Pinned Memory를 통해 VRAM으로 올리는 option을 사용하기도 함. (pin_memory=True)
-
Process-wise Forwarding
-
각 process마다 mini-batch로 forward 진행
-
loss 계산
-
Process-wise Backward + All Reduce
-
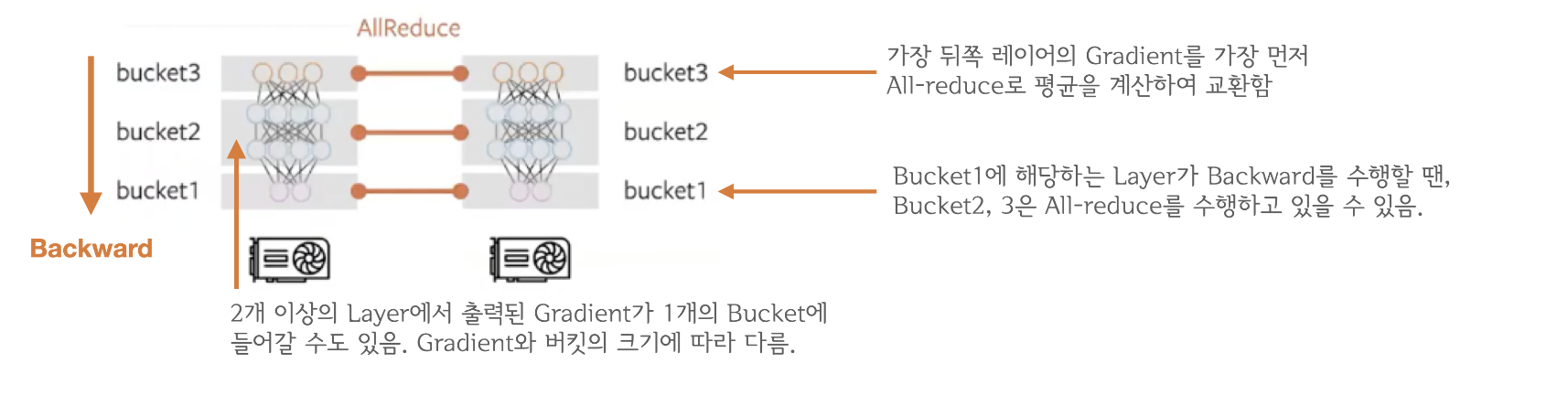
backward()연산은 프로세스별로 뒤쪽 레이어부터 순차적으로 이루어지다가 ‘Gradient Bucketing’을 수행함. -
‘Gradient Bucketing’은 Gradient를 일정한 사이즈의 Bucket에 저장해두고 가득차면 다른 프로세스로 전송하는 방식
-
쉽게 말해, 모든 process들이 정해놓은 일정 크기의 layer (bucket)
backward()연산이 완료되면, (1) 각 process들의 진행 중인backward()은 진행시켜놓고 (2)bucket-wise로 All-reduce 를 수행한 후 device개수로 나눠 average gradient를 계산하여 모든 device들의 gradient들을 동기화 시켜놓는것
-
Update
-
마스터 process 없이 data parallel이 가능함
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
from torch.optim import AdamW
from torch.utils.data import DataLoader, DistributedSampler
from transformers import BertForSequenceClassification, BertTokenizer
from datasets import load_dataset
# 1. initialize process group
dist.init_process_group("nccl")
rank = dist.get_rank()
torch.cuda.set_device(rank)
device = torch.cuda.current_device()
world_size = dist.get_world_size()
# 2. create dataset
datasets = load_dataset("multi_nli").data["train"]
datasets = [
{
"premise": str(p),
"hypothesis": str(h),
"labels": l.as_py(),
}
for p, h, l in zip(datasets[2], datasets[5], datasets[9])
]
# 3. create DistributedSampler
# DistributedSampler 는 데이터를 쪼개서 다른 프로세스로 전송하기 위한 모듈입니다.
sampler = DistributedSampler(
datasets,
num_replicas=world_size,
rank=rank,
shuffle=True,
)
data_loader = DataLoader(
datasets,
batch_size=32,
num_workers=4,
sampler=sampler,
shuffle=False,
pin_memory=True,
)
# 4. create model and tokenizer
model_name = "bert-base-cased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=3).cuda()
# 5. make distributed data parallel module
model = DistributedDataParallel(model, device_ids=[device], output_device=device)
# 6. create optimizer
optimizer = AdamW(model.parameters(), lr=3e-5)
# 7. start training
for i, data in enumerate(data_loader):
optimizer.zero_grad()
tokens = tokenizer(
data["premise"],
data["hypothesis"],
padding=True,
truncation=True,
max_length=512,
return_tensors="pt",
)
loss = model(
input_ids=tokens.input_ids.cuda(),
attention_mask=tokens.attention_mask.cuda(),
labels=data["labels"],
).loss
loss.backward()
optimizer.step()
if i % 10 == 0 and rank == 0:
print(f"step: {i}, loss: {loss}")
if i == 300:
break
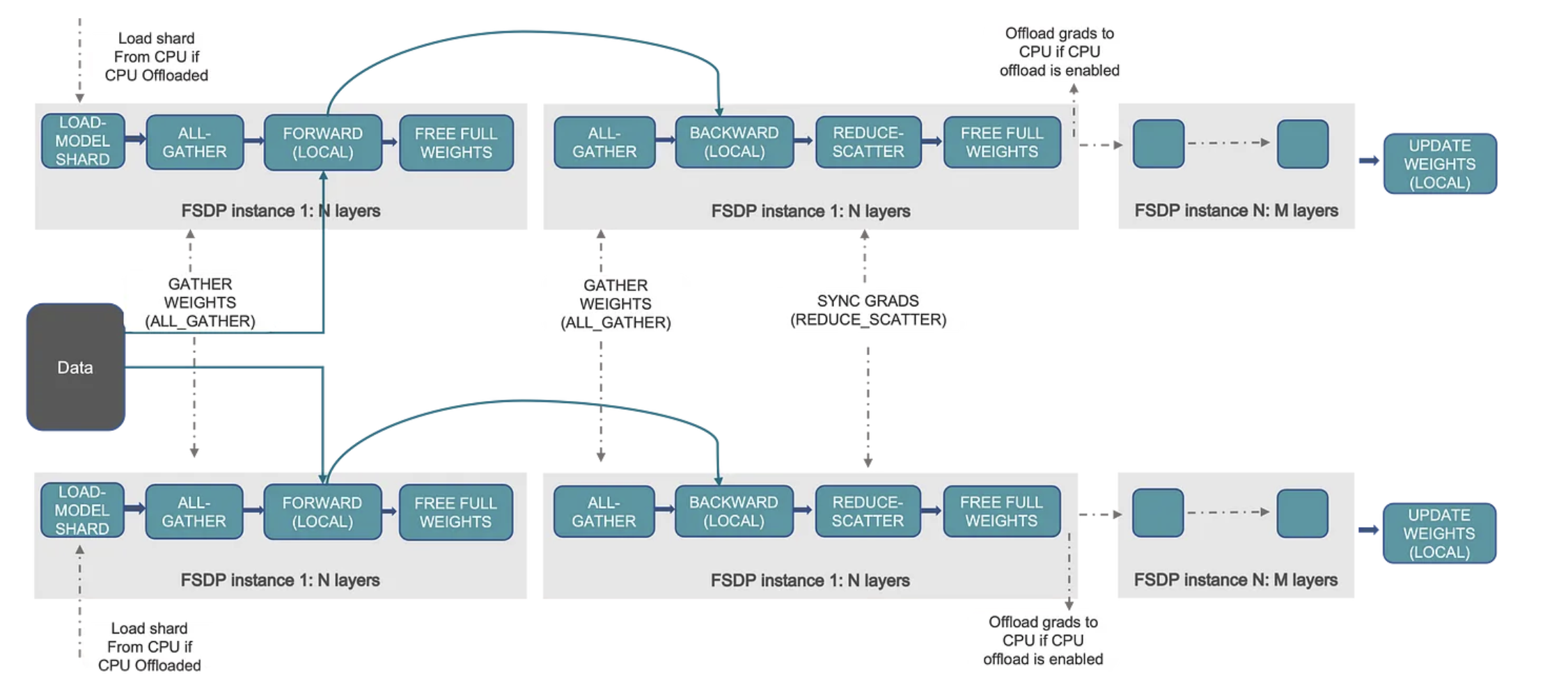
4. FSDP (Fully Sharded Data Parallel)
-
DDP에서는 model의 parameter, gradient, optimizer에서 사용하는 states 등을 모두 각 GPU에서 보관하고 GPU 통신을 통해서 model의 state를 동기화 함
-
하지만, 바야흐로 13B, 40B, 70B LLM의 시대에서 A100-80GB 1장으로 Full-Fine Tuning을 할 수 있는 시대가 되지 않았다.
-
Model의 각 Unit을 GPU에 Sharding하고 Forwarding/Backwarding할때 마다 Collective Communication을 수행해서 GPU간 통신을 증가시키지만 Large Model Training을 가능하게 한 Fully Sharded Data Parallel 방법론이 등장
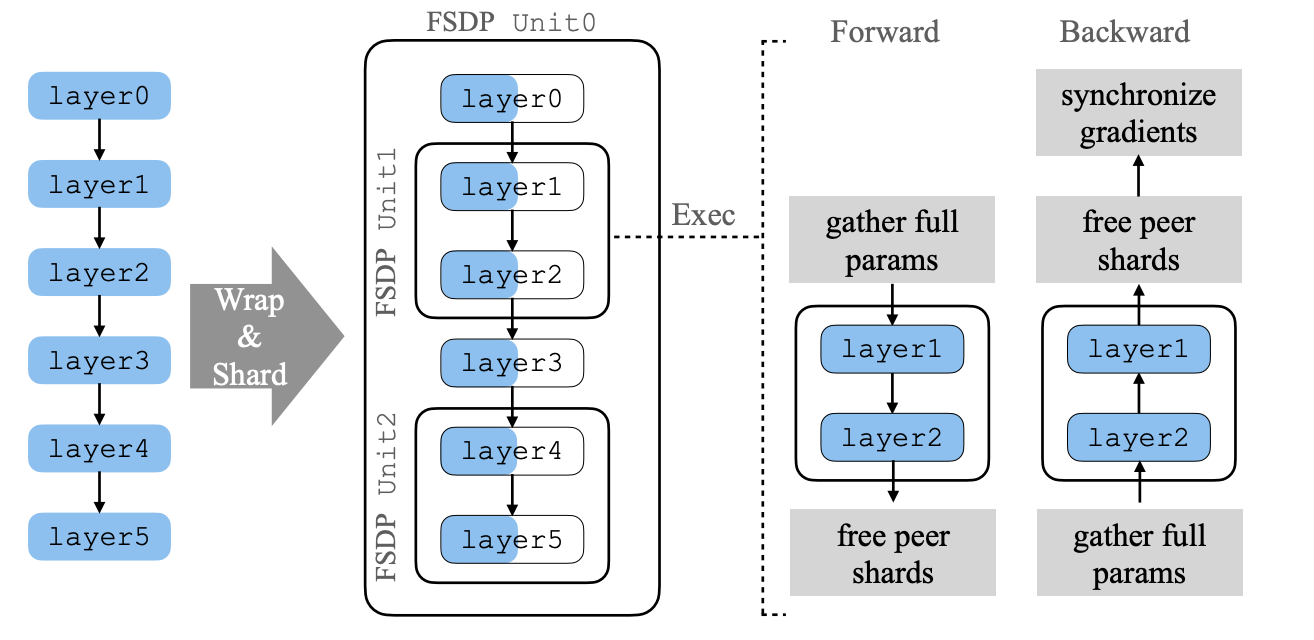
### 용어 정리
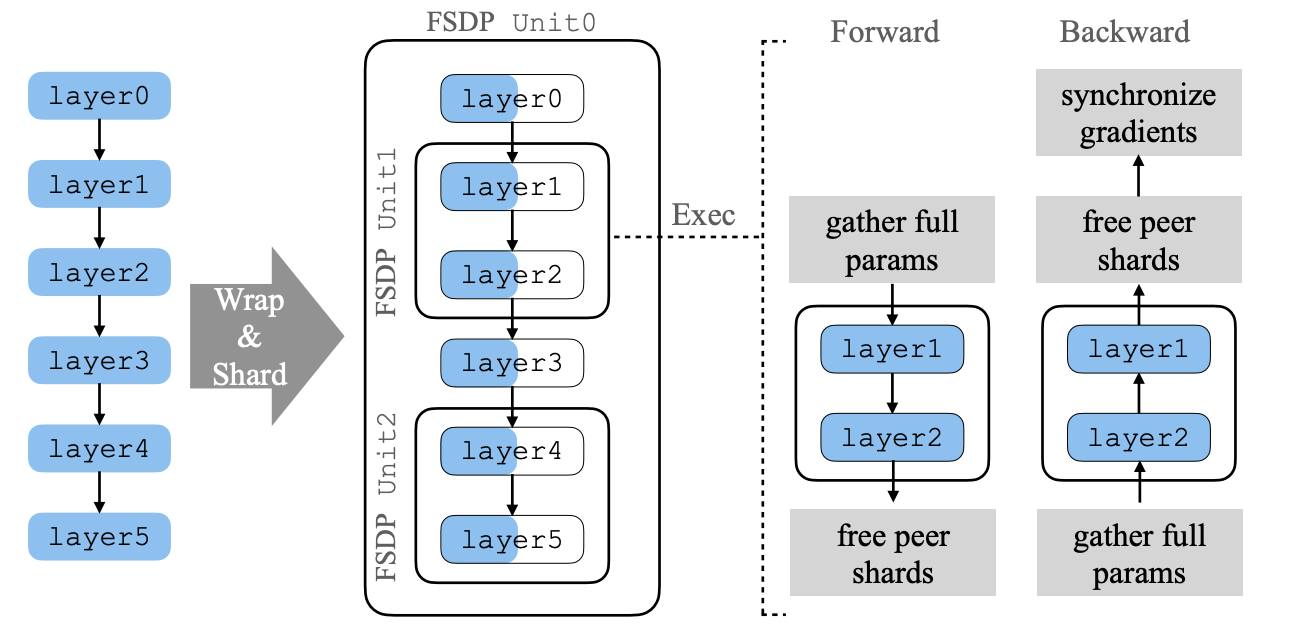
-
FSDP Unit
- Model Structure에서 Split할 대상들
(e.g., layers, TransformerBlocks)
-
collective communication의 대상
-
FSDP Unit ≠ sharding의 대상이 X
-
예시에서 [layer0,3], [layer1,2], [layer4,5]가 각각 FSDP Unit
-
** Sharding**
-
FSDP Unit(e.g., a single layer/stage)을 *FlatParameter*로 저장하는 과정
-
FlatParameter는 1D tensor로 sharding을 통해 각 FSDP unit이 각 rank에 균등하게 분배됨
-
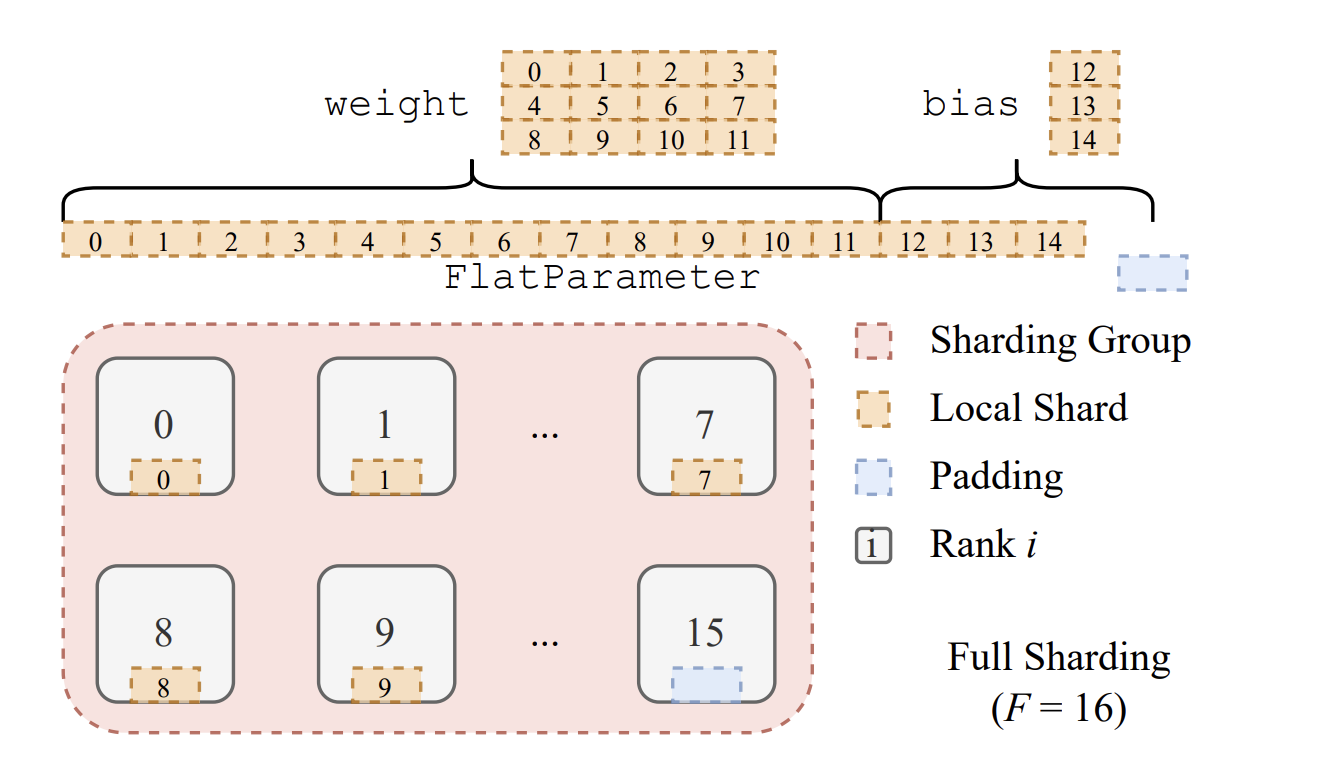
→ (16개의 Rank가 있다고 가정) 각 rank에 weight, bias flat parameter하나씩 store하고 15번 device에 padding tensor store해서 균등있게 store되도록 함 (NCCL이 equal하게 input을 뿌려야 성능이 향상된다고 논문에 표 제공)
-
위의 예시로 설명하면, [layer0,3]가 2개의 device에 sharding
-
**[Recap] All-Gather Reduce scatter**
- 자 그럼, 용어도 정리했으니 각 FSDP Unit이 어떻게 Forwarding/Backwarding되는지 알아보자.
-
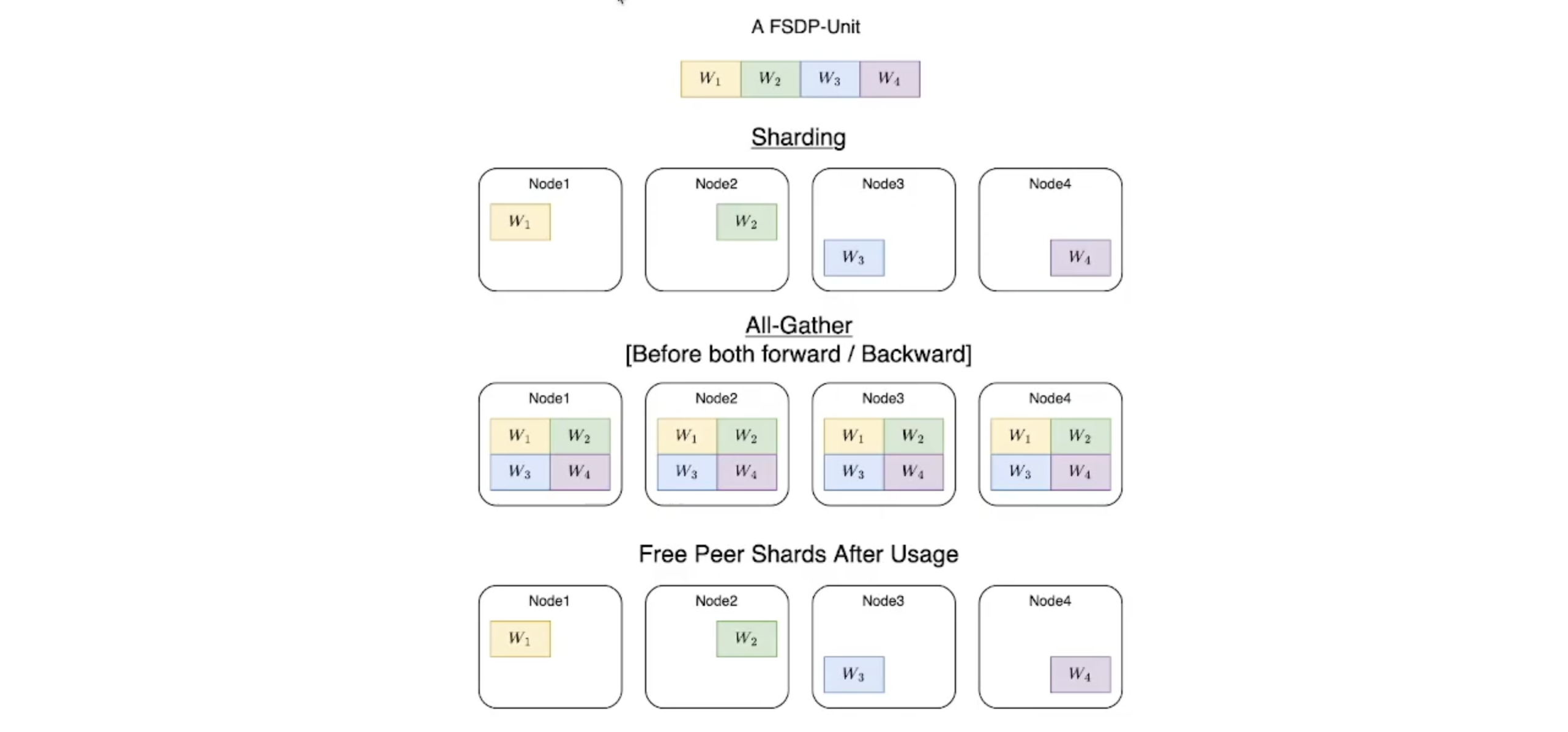
Forwarding
-
All-Gather연산으로 각 device에 sharded 되어 있는 각 FSDP Unit의 shard들 (w1~w4)을 모든 device에 뿌린다.
-
결론적으로, FSDP의 memory requirements는 sharded model (w1) & 가장 큰 FSDP unit(아래 예시에는 [w1:w4])이 device에 loaded되었을때에 비례한다.
-
모든 device에 동일한 weight이 있으면 (FSDP Unit이 존재하면) Forwarding 진행
-
각 shard에 원래 있어야할 weight 제외하고 나머지 weight (Peer Shard) Free
- Backwarding
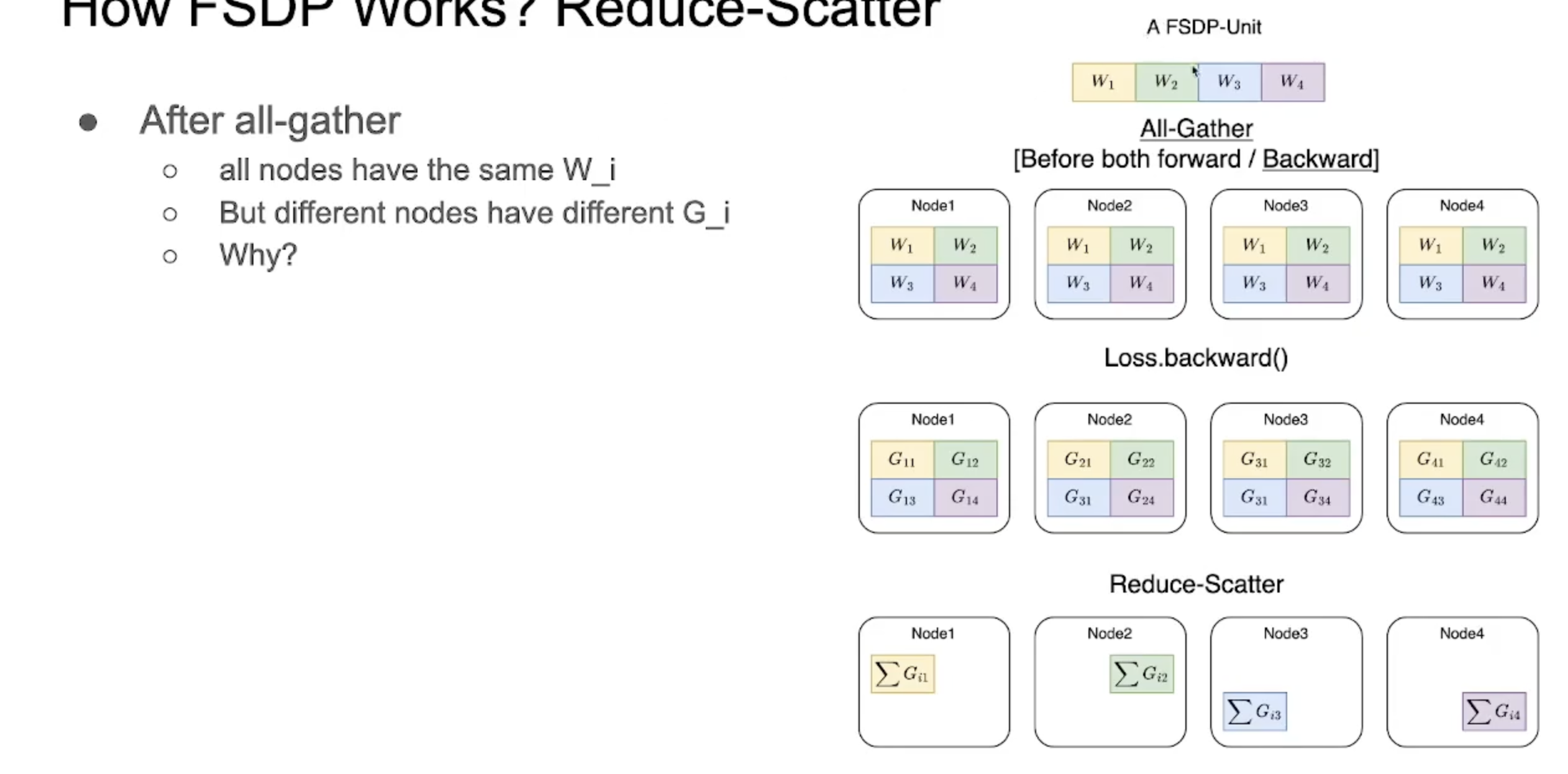
-
Forwarding과 마찬가지로 All-Gather연산 수행
-
Loss.backward()연산으로 gradient 수행
-
각 device(예시에서는 node)에 FSDP unit의 gradient가 존재
-
mini-batch가 sampling되어 올라가는 상황이기에 각 device (예시에서는 node)가 가지고 있는 gradient는 다를 수 밖에 없음
1. 따라서 sum한 후 각 shard에 할당하는 reduce-scatter 연산을 통해 gradient를 계산
- 모든 FSDP unit에 대해서 순차적으로 back propagation
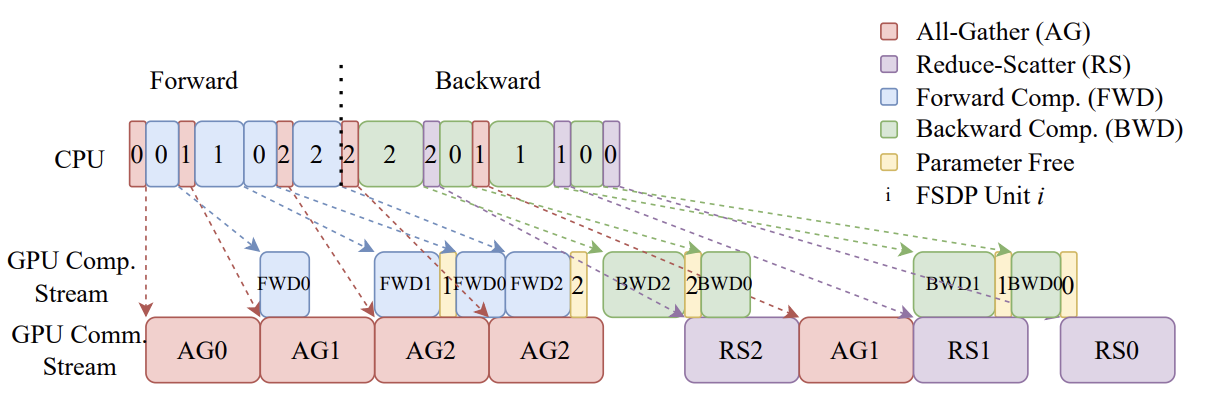
- Overall Example
[Model]
[Overlap Communication and Computation]
-
FSDP Unit_0 - [Layer0;Layer3] All-Gather
-
FSDP Unit_0 - [Layer0] Forwarding & FSDP Unit_1 - [Layer1;Layer2] All-Gather
-
FSDP Unit*2 - [Layer4;Layer5] All-Gather & FSDP Unit_1 - [Layer1;Layer2] _Forwarding & FSDP Unit_1 - [Layer1;Layer2] & FSDP Unit_1 Parameter Free (Forwarding 끝) *& FSDP Unit_0 - [Layer3] Forwarding
-
FSDP Unit2 - [Layer4;Layer5] All-Gather (BackProp용) & FSDP Unit_2 - [Layer4;Layer5] Forwarding & _FSDP Unit 2 Parameter Free (Forwarding 끝)
-
(4에서 All-Gather한) FSDP Unit_2 - [Layer4;Laye5] Backward & *FSDP Unit 2 Parameter Free (Backward 끝) & ReduceScatter & *FSDP Unit_0 - [Layer3] BackProp
-
FSDP Unit_1 - [Layer1,2] All-Gather
-
FSDP Unit*1 - [Layer1,2] Backward (Layer 3 Gradient 있기 때문에) & FSDP Unit_1 - [Layer1,2] *ReduceScatter & _FSDP Unit_1 - [Layer1,2] _ Parameter Free (Backward 끝) & FSDP Unit 0 _[Layer1] BackProp
-
FSDP Unit 0 Parameter Free (Layer1까지 Backprop 완료)
-
FSDP Unit 0 Reduce Scatter
5. Llama2 Recipes - Training Code Review
-
Meta에서 제공하는 Llama2 Recipes는 Fine-tuning Recipe를 제공하는데, 기본적으로 llama-recipes/src/llama_recipes.fine-tuning.py가 from llama_recipes.utils.train_utils import train을 호출해서 학습을 진행
-
fine-tuning.py 위주로 간단한 코드 리뷰를 진행
fine-tuning.py
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This software may be used and distributed according to the terms of the Llama 2 Community License Agreement.
import os
import dataclasses
import fire
import random
import torch
import torch.optim as optim
from peft import get_peft_model, prepare_model_for_kbit_training
from torch.distributed.fsdp import (
FullyShardedDataParallel as FSDP,
ShardingStrategy
)
from torch.distributed.fsdp.fully_sharded_data_parallel import CPUOffload
from torch.optim.lr_scheduler import StepLR
from transformers import (
AutoTokenizer,
LlamaForCausalLM,
LlamaConfig,
)
from transformers.models.llama.modeling_llama import LlamaDecoderLayer
from llama_recipes.configs import fsdp_config as FSDP_CONFIG
from llama_recipes.configs import train_config as TRAIN_CONFIG
from llama_recipes.data.concatenator import ConcatDataset
from llama_recipes.policies import AnyPrecisionAdamW, apply_fsdp_checkpointing
from llama_recipes.utils import fsdp_auto_wrap_policy
from llama_recipes.utils.config_utils import (
update_config,
generate_peft_config,
generate_dataset_config,
get_dataloader_kwargs,
)
from llama_recipes.utils.dataset_utils import get_preprocessed_dataset
from llama_recipes.utils.fsdp_utils import hsdp_device_mesh
from llama_recipes.utils.train_utils import (
train,
freeze_transformer_layers,
setup,
setup_environ_flags,
clear_gpu_cache,
print_model_size,
get_policies,
)
from accelerate.utils import is_xpu_available
def setup_wandb(train_config, fsdp_config, **kwargs):
try:
import wandb
except ImportError:
raise ImportError(
"You are trying to use wandb which is not currently installed. "
"Please install it using pip install wandb"
)
from llama_recipes.configs import wandb_config as WANDB_CONFIG
wandb_config = WANDB_CONFIG()
update_config(wandb_config, **kwargs)
init_dict = dataclasses.asdict(wandb_config)
run = wandb.init(**init_dict)
run.config.update(train_config)
run.config.update(fsdp_config, allow_val_change=True)
return run
def main(**kwargs):
# Update the configuration for the training and sharding process
train_config, fsdp_config = TRAIN_CONFIG(), FSDP_CONFIG()
update_config((train_config, fsdp_config), **kwargs)
# Set the seeds for reproducibility
if is_xpu_available():
torch.xpu.manual_seed(train_config.seed)
torch.manual_seed(train_config.seed)
random.seed(train_config.seed)
if train_config.enable_fsdp:
setup()
# torchrun specific
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
if torch.distributed.is_initialized():
if is_xpu_available():
torch.xpu.set_device(local_rank)
elif torch.cuda.is_available():
torch.cuda.set_device(local_rank)
clear_gpu_cache(local_rank)
setup_environ_flags(rank)
wandb_run = None
if train_config.use_wandb:
if not train_config.enable_fsdp or rank==0:
wandb_run = setup_wandb(train_config, fsdp_config, **kwargs)
# Load the pre-trained model and setup its configuration
use_cache = False if train_config.enable_fsdp else None
if train_config.enable_fsdp and train_config.low_cpu_fsdp:
"""
for FSDP, we can save cpu memory by loading pretrained model on rank0 only.
this avoids cpu oom when loading large models like llama 70B, in which case
model alone would consume 2+TB cpu mem (70 * 4 * 8). This will add some comms
overhead and currently requires latest nightly.
"""
if rank == 0:
model = LlamaForCausalLM.from_pretrained(
train_config.model_name,
load_in_8bit=True if train_config.quantization else None,
device_map="auto" if train_config.quantization else None,
use_cache=use_cache,
attn_implementation="sdpa" if train_config.use_fast_kernels else None,
)
else:
llama_config = LlamaConfig.from_pretrained(train_config.model_name)
llama_config.use_cache = use_cache
with torch.device("meta"):
model = LlamaForCausalLM(llama_config)
else:
model = LlamaForCausalLM.from_pretrained(
train_config.model_name,
load_in_8bit=True if train_config.quantization else None,
device_map="auto" if train_config.quantization else None,
use_cache=use_cache,
attn_implementation="sdpa" if train_config.use_fast_kernels else None,
)
# Load the tokenizer and add special tokens
tokenizer = AutoTokenizer.from_pretrained(train_config.model_name if train_config.tokenizer_name is None else train_config.tokenizer_name)
tokenizer.pad_token_id = tokenizer.eos_token_id
# If there is a mismatch between tokenizer vocab size and embedding matrix,
# throw a warning and then expand the embedding matrix
if len(tokenizer) > model.get_input_embeddings().weight.shape[0]:
print("WARNING: Resizing the embedding matrix to match the tokenizer vocab size.")
model.resize_token_embeddings(len(tokenizer))
print_model_size(model, train_config, rank if train_config.enable_fsdp else 0)
# Prepare the model for int8 training if quantization is enabled
if train_config.quantization:
model = prepare_model_for_kbit_training(model)
# Convert the model to bfloat16 if fsdp and pure_bf16 is enabled
if train_config.enable_fsdp and fsdp_config.pure_bf16:
model.to(torch.bfloat16)
if train_config.use_peft:
peft_config = generate_peft_config(train_config, kwargs)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
if wandb_run:
wandb_run.config.update(peft_config)
hsdp_device_mesh = None
if fsdp_config.hsdp and fsdp_config.sharding_strategy == ShardingStrategy.HYBRID_SHARD:
hsdp_device_mesh = hsdp_device_mesh(replica_group_size=fsdp_config.replica_group_size, sharding_group_size=fsdp_config.sharding_group_size)
print("HSDP device mesh is ready")
#setting up FSDP if enable_fsdp is enabled
if train_config.enable_fsdp:
if not train_config.use_peft and train_config.freeze_layers:
freeze_transformer_layers(train_config.num_freeze_layers)
mixed_precision_policy, wrapping_policy = get_policies(fsdp_config, rank)
my_auto_wrapping_policy = fsdp_auto_wrap_policy(model, LlamaDecoderLayer)
device_id = 0
if is_xpu_available():
device_id = torch.xpu.current_device()
elif torch.cuda.is_available():
device_id = torch.cuda.current_device()
model = FSDP(
model,
auto_wrap_policy= my_auto_wrapping_policy if train_config.use_peft else wrapping_policy,
cpu_offload=CPUOffload(offload_params=True) if fsdp_config.fsdp_cpu_offload else None,
mixed_precision=mixed_precision_policy if not fsdp_config.pure_bf16 else None,
sharding_strategy=fsdp_config.sharding_strategy,
device_mesh=hsdp_device_mesh,
device_id=device_id,
limit_all_gathers=True,
sync_module_states=train_config.low_cpu_fsdp,
param_init_fn=lambda module: module.to_empty(device=torch.device("cuda"), recurse=False)
if train_config.low_cpu_fsdp and rank != 0 else None,
)
if fsdp_config.fsdp_activation_checkpointing:
apply_fsdp_checkpointing(model)
elif not train_config.quantization and not train_config.enable_fsdp:
if is_xpu_available():
model.to("xpu:0")
elif torch.cuda.is_available():
model.to("cuda")
dataset_config = generate_dataset_config(train_config, kwargs)
# Load and preprocess the dataset for training and validation
dataset_train = get_preprocessed_dataset(
tokenizer,
dataset_config,
split="train",
)
if not train_config.enable_fsdp or rank == 0:
print(f"--> Training Set Length = {len(dataset_train)}")
dataset_val = get_preprocessed_dataset(
tokenizer,
dataset_config,
split="test",
)
if not train_config.enable_fsdp or rank == 0:
print(f"--> Validation Set Length = {len(dataset_val)}")
if train_config.batching_strategy == "packing":
dataset_train = ConcatDataset(dataset_train, chunk_size=train_config.context_length)
train_dl_kwargs = get_dataloader_kwargs(train_config, dataset_train, tokenizer, "train")
# Create DataLoaders for the training and validation dataset
train_dataloader = torch.utils.data.DataLoader(
dataset_train,
num_workers=train_config.num_workers_dataloader,
pin_memory=True,
**train_dl_kwargs,
)
eval_dataloader = None
if train_config.run_validation:
if train_config.batching_strategy == "packing":
dataset_val = ConcatDataset(dataset_val, chunk_size=train_config.context_length)
val_dl_kwargs = get_dataloader_kwargs(train_config, dataset_val, tokenizer, "val")
eval_dataloader = torch.utils.data.DataLoader(
dataset_val,
num_workers=train_config.num_workers_dataloader,
pin_memory=True,
**val_dl_kwargs,
)
# Initialize the optimizer and learning rate scheduler
if fsdp_config.pure_bf16 and fsdp_config.optimizer == "anyprecision":
optimizer = AnyPrecisionAdamW(
model.parameters(),
lr=train_config.lr,
momentum_dtype=torch.bfloat16,
variance_dtype=torch.bfloat16,
use_kahan_summation=False,
weight_decay=train_config.weight_decay,
)
else:
optimizer = optim.AdamW(
model.parameters(),
lr=train_config.lr,
weight_decay=train_config.weight_decay,
)
scheduler = StepLR(optimizer, step_size=1, gamma=train_config.gamma)
# Start the training process
results = train(
model,
train_dataloader,
eval_dataloader,
tokenizer,
optimizer,
scheduler,
train_config.gradient_accumulation_steps,
train_config,
fsdp_config if train_config.enable_fsdp else None,
local_rank if train_config.enable_fsdp else None,
rank if train_config.enable_fsdp else None,
wandb_run,
)
if not train_config.enable_fsdp or rank==0:
[print(f'Key: {k}, Value: {v}') for k, v in results.items()]
if train_config.use_wandb:
for k,v in results.items():
wandb_run.summary[k] = v
if __name__ == "__main__":
fire.Fire(main)
6. References
-
Floating Point
-
AMP
-
NVIDIA - AMP
-
Mixed Precision Training
-
AdamW Source Code
-
NCCL Operations
-
NCCL - Ring based Algorithms
-
DP
-
DDP
-
Pinned Memory
-
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
-
How Fully Sharded Data Parallel (FSDP) works?
-
다중 GPU를 효율적으로 사용하는 방법: DP부터 FSDP까지
-
Llama2 code
https://github.com/meta-llama/llama-recipes