IN-CONTEXT PRETRAINING: LANGUAGE MODELING BEYOND DOCUMENT BOUNDARIES
논문 정보
- Date: 2024-01-23
- Reviewer: 김재희
- Property: ICL, LLM, In Context Learning
1. Intro
-
Pretrain 단계에서 In-Context Learning을 반영할 수 있지 않을까?
-
Pretrain 시 ICL 데이터 구축 방식
-
ICL Pretrain 시 성능 변화
기존 Pretrain
-
학습 효율을 위해 Batch 내 Maximum Length를 맞추는 전략을 취함
- 학습 샘플의 길이 < max length
⇒ 다른 샘플을 concat하여 maximum length 채움
-
[A, B]
-
이러한 전략은 랜덤한 Demonstration을 추가하여 Pretrain을 진행하는 방식
⇒ Model의 ICL에 도움을 줄 수 없음
ICL Pretrain
-
ICL을 Pretrain 단계(Next Token Prediction)에 활용하기 위해서는 아래 사항 고려 필요
-
ICL로 사용될 Demonstration 데이터 종류
-
Demonstration 획득 방법
-
Sampling Bias에 따른 모델 Bias 존재 가능성
-
-
Pretrain 단계이기 때문에 시간/메모리 소모가 적으면서 양질의 Demonstration 탐색 방법론 필요
2. Method
Overview
-
Pretrain Batch 구성 방식 외 다른 요소는 기존 LLM과 동일
-
Common Crawl 데이터를 이용하여 Pretrain 진행
-
Pretrain Data를 Chunk 단위로 분리
-
제안 방법론을 이용하여 유사한 데이터를 하나의 Pretrain Sample로 Concat하여 구성
-
Pretrain!
제안 방법론
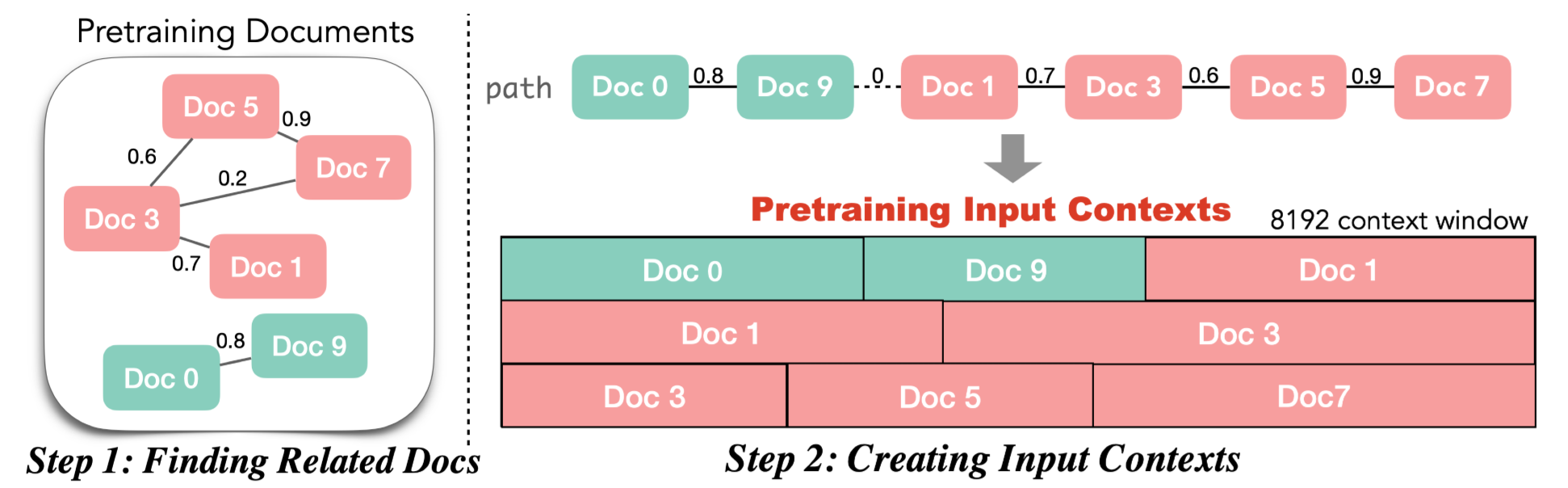
-
Finding Related Documents at Scale
-
핵심 : 서로 연관된 문서를 탐색하는 빠른 방법
→ 빠르지 않다면 Pretrain 때 추가 코스트(탐색)가 크게 발생
-
방법론
-
Pretrain Corpus를 Chunk 단위(50M 건)로 분리
-
사전에 Pretrain Corpus에 대해 Retriever(Contriever)를 이용하여 Embedding 산출 + FAISS Indexing
→ Contriever : Self Supervised Learning 기반 IR 모델(DPR과 구조는 거의 동일)
1. 모든 데이터 간 유사도 산출
1. 유사도 산출 과정에서 Pretrain Corpus 내 매우 유사한 Sample들을 확인할 수 있었음
1. 해당 Sample들은 중복 데이터로서 Pretrain에 방해가 됨
→ 중복데이터가 Demonstration으로 제공된다면 모델은 그냥 Demonstration의 토큰을 복사하여 사용하면 되기 때문에 학습 Shortcut 발생
1. 산출된 유사도를 기준으로 중복 데이터 제거 진행(부가적 효과)
-
Creating Input Contexts
-
1에서 산출된 유사도를 바탕으로 실제 Input을 구성하는 방법론
-
가장 나이브한 접근 방법론(kNN) : 각 데이터 별 top-k 유사도 샘플을 Demonstration으로 사용하는 것
→ 특정 데이터들(다른 문서의 일부 내용을 포함하는 데이터)을 유사한 데이터가 매우 많아서 학습에 중복하여 사용될 가능성이 있음
1. 특정 데이터에 대한 Overfit
1. 제한된 자원 하에서 학습에 사용되는 데이터의 Diversity 감소
-
실제 방법론
-
각 데이터 별 top-k 유사도 데이터 산출 (Neighbor)
→ 일종의 그래프 형태의 데이터 구조 산출됨
1. 세일즈맨 문제(Maximum Traveling Salesman)로 전환
⇒ 주어진 그래프 내에서 1) 모든 노드를 방문하면서 2) 거리를 최소화하는 문제
⇒ 현재 상황에 대입한다면, 1) 주어진 데이터를 모두 사용하면서 2) 유사도가 높은 데이터끼리 함께 방문하는 경로 탐색 문제
⇒ greedy search로 풀어도 해에 근접할 수 있다는 기존 연구들이 매우매우매우 많다고 함
1. 가장 degree가 낮은 문서를 starting node로 선정
1. 해당 문서와 가장 유사도가 높은 문서로 경로 이동
→ uncomplete graph이므로 모든 문서를 방문하는 경로가 탐색될 때까지 반복
1. 해당 경로가 완성될 경우 다른 그래프에 대해서 3번 ~ 4번 과정 반복
1. 해당 Chunk에서 경로가 완성되면 경로 순서에 따라 Input을 concat하여 구성
-
제안 방법론대로 Input을 구성할 경우 최대한 유사한 내용을 담은 문서들이 하나의 Input으로 구성될 수 있음
-
Doc3의 Token 예측 시 Doc1의 정보가 유용하게 활용될 수 있음
-
ICL을 모사한 Pretrain 가능
3. Experiments
Setup
-
Model Size : 0.3/0.7/1.5/7B
-
Model Architecture : LLaMA, 기타 Hyperparam도 LLaMA를 따름
-
Hardware : 128 A100
-
Pretrain 소요 시간 : 7B 기준 9일
-
3가지 조건에 따라 Scratch부터 Pretrain 진행
-
Standard : 일반 LLM처럼 Random Data를 Concat하여 Batch 구성
-
kNN : 하나의 데이터와 유사한 top-k 데이터를 함께 Concat하여 Batch 구성
- 데이터가 중복하여 사용될 수 있음
-
ICLM : 제안 방법론
-
-
Search
-
32 GPU를 이용하여 매 Batch마다 진행
-
전체 학습 중 Search 시간 : 6시간, 배치 당 평균 4,738초
-
세일즈맨 문제(Maximum Traveling Salesman) 탐색 속도 : 12 시간 with 20 CPU
-
Results
- Language Modeling : LM의 기본적인 성능 평가 (PPL)
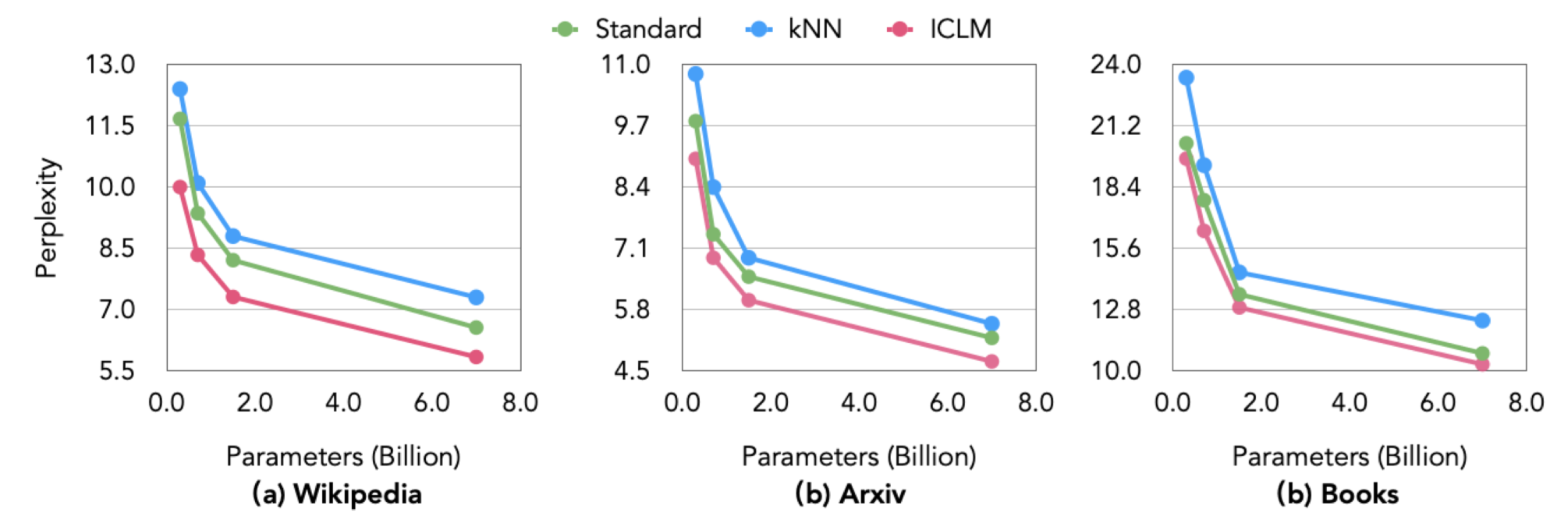
-
kNN은 Standard 대비 성능 저하 관찰
-
모델 크기, 데이터 종류와 관계없이 일관된 모습
- 데이터 중복으로 인해 성능 저하 발생 ⇒ 특정 데이터 Overfit되었다고 추정
-
이와 대조적으로 ICLM은 성능 개선 관찰
-
모델 크기가 커질수록 성능 개선폭이 커지는 모습
-
ICLM이 ICL 능력 뿐 아니라 Language Modeling에 있어서도 도움이 되는 것(당연한듯?)
-
- In Context Learning
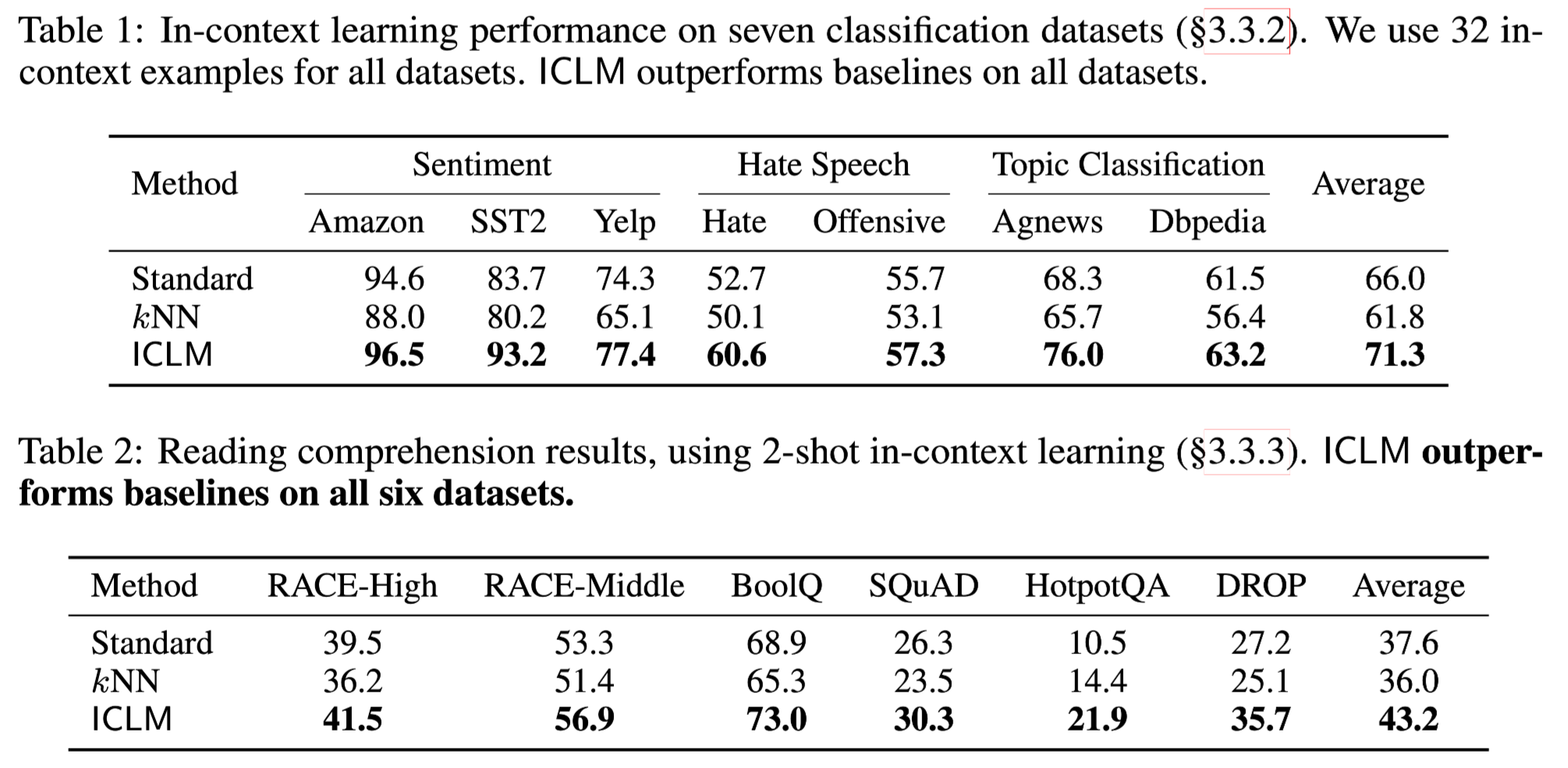
-
두가지 태스크에 대한 ICL 능력 평가
-
Classification : 32-shot 사용
-
평균적으로 8%p의 성능 개선을 확인할 수 있음
-
kNN은 Standard 대비 성능 저하가 관찰되는 모습
-
-
Reading Comprehension : 2-shot 사용 (데이터 길이가 길어 max length 제한 발생)
-
2-shot 임에도 Standard 대비 뚜렷한 성능 개선 관찰 가능
-
가장 큰 성능 개선 : Hotpot QA
-
-
→ 여러개의 Document로부터 Reasoning을 수행하여 정답을 추론해야 하는 태스크
→ ICL 및 Document 이해 능력이 매우 중요함
-
(재희)
-
ICLM이 Standard에 비해 성능이 좋은 건 뚜렷하게 나타나는 특징
-
태스크가 어려울수록 성능 개선 폭이 커지는 모습을 관찰 할 수 있음(Classification < Reading Comprehension)
-
ICLM이 In-Context Learning 능력과 더불어 NLU 능력도 향상시키는 것 아닐까?
- (or) ICL에서 중요한게 NLU 능력은 아닐까
-
- Retrieval-Augmentation
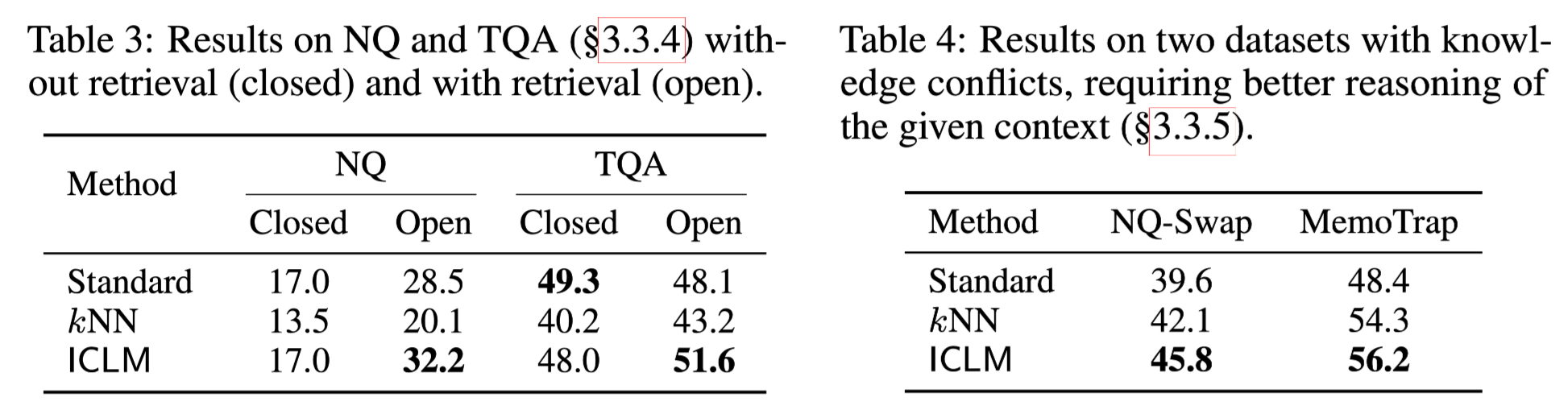
-
최근들어 매우 중요해진 분야
-
논문에서도 관련연구로서 RAG용 Pretrain/Finetune 방법론들을 언급하고 있음
-
RAG 용 Finetune : Retrieval로 제공된 문서로부터 관련정보(도메인, 태스크 등)를 잘 가지고 와서 추론할 수 있도록 Finetune
-
-
Closed : 성능 개선 X
-
ICLM이라고 해서 Knowledge를 더 잘 습득하는 것은 아님
-
추정하기로는 ICLM 방식이 모델의 Memorization 능력을 저하시킨다고 언급
- (재희) ICLM은 모델이 기억하기보다 입력 문장에 의존하도록 만들기 때문이지 않을까
-
-
Open : 뚜렷한 성능 개선 관찰 가능
- 동일한 Document를 사용하고 있음에도 성능 개선이 뚜렷하게 관찰됨
- Factuality
-
상황 정의 : 모델이 학습한 지식과 다른 내용이 프롬프트에 삽입되게 됨
- 시점 차이 등
-
모델의 Factuality 문제가 생기는 이유 : Implicit Memory에 의존하고 입력 데이터를 활용하지 않기 때문
-
ICLM은 Factuality 측면에서 큰 성능 개선을 보이고 있음
-
kNN 역시 어느 정도 성능 개선을 확인할 수 있음
- Implicit Memory 의존도를 낮추고 입력 데이터 의존도를 높이는 Pretrain 방법론
4. Analysis
Train Dynamics
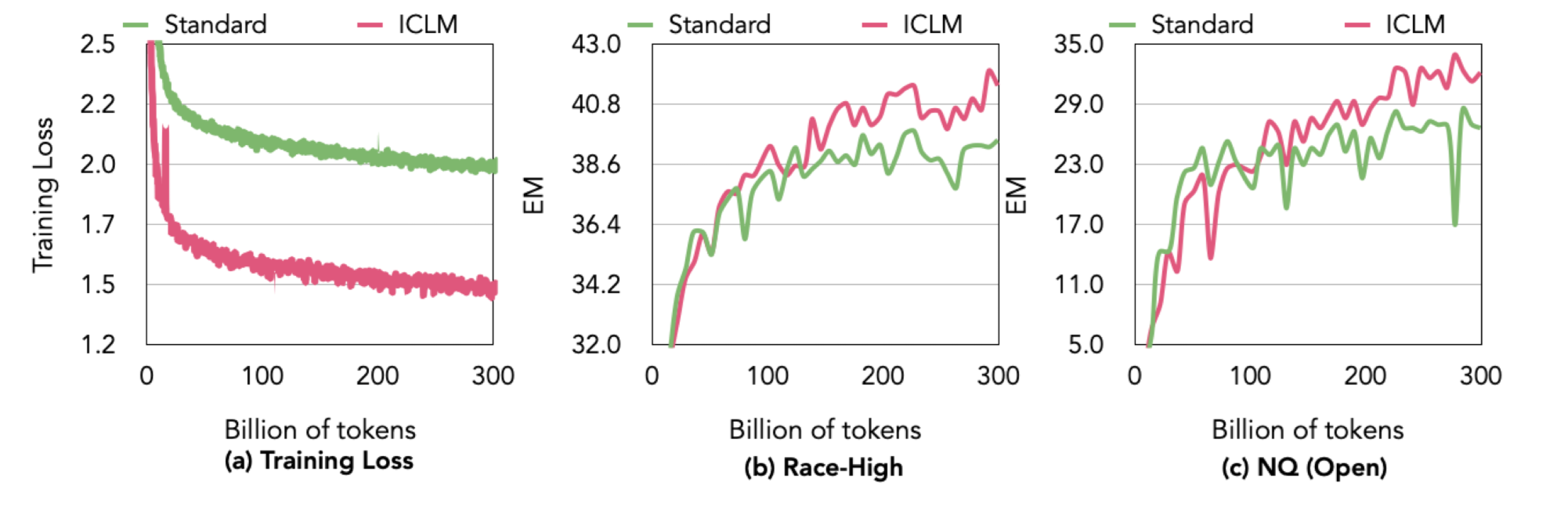
-
Loss는 초반부터 Standard부터 낮은 모습
- 학습 데이터가 비슷한 내용으로 구성되었기 때문
-
학습 중 Downstream Task 성능
-
특정 시점까지는 Standard와 비슷하거나 좋지 못한 모습을 보임
-
특정 시점 이후부터는 지속적으로 성능이 더 높고, 폭 역시 커지는 모습
- Scaling을 확장했을 때 ICLM이 더 효과적일 수 있을지도…?
-
(재희) Grokking처럼 ICL 능력은 LM 학습 이후에 가능해지는건 아닐까?
-
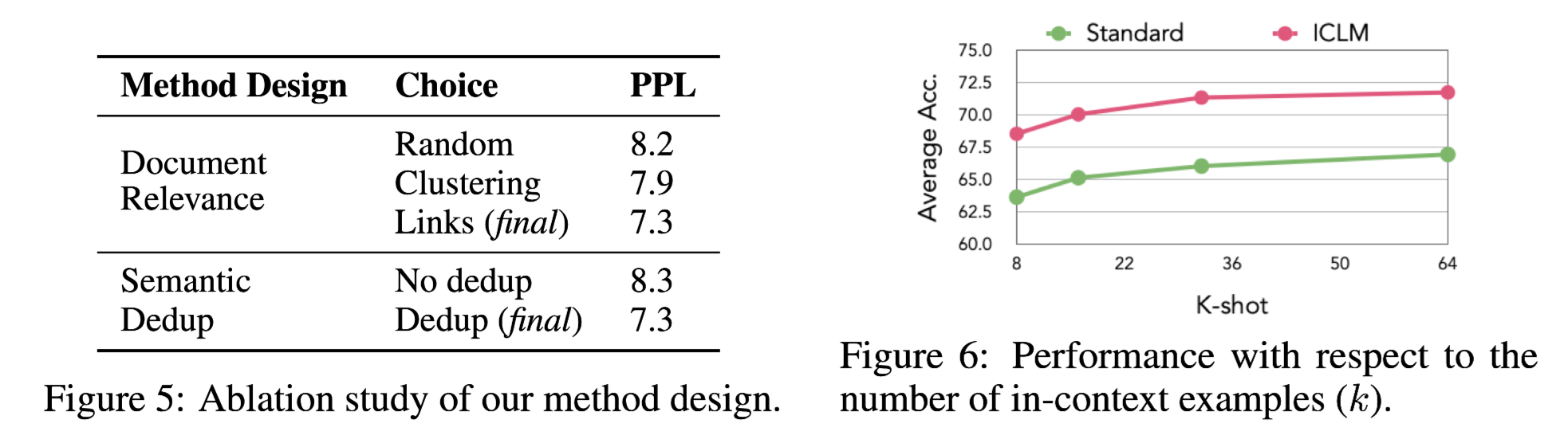
Ablation and K-shot
-
Ablation Study :
-
Document Relevance :
-
전체 코퍼스를 11k개의 클러스터로 분할
-
비슷한 주제를 가지는 문서를 Pretrain 시 Input으로 함께 구성 (동일 클러스터)
-
Clustering에 비해서도 제안 방식의 성능이 더 좋은 모습
-
동일 클러스터라 하더라도 서로 밀접한 관련이 있는 문서가 아닐 수 있음
- 제안 방법론은 제일 가까운 문서끼리 함께 Input으로 구성하므로 밀접한 문서를 Input으로 구성 가능
-
-
Semantic Dedup : 유사도가 과하게 높은 문서를 학습에서 제외
-
중복 문서 제외 결과 PPL이 상승하는 모습
-
중복문서를 ICL로 사용할 경우 단순 복사하는 태스크를 학습하게 되므로 실제 학습에 방해가 됨
-
-
-
K-Shot
-
K-Shot 수에 따른 성능 변화 관찰
-
Classification Task 들의 평균 성능 리포팅
-
K 값에 관계없이 ICLM의 성능이 높은 모습 관찰
-
7. Conclusion
-
엄격한 실험 환경 제한을 통해 효과적인 실험 수행
-
Pretrain 시 비용이 (상대적으로) 매우 적은 Input 구성 방법론 제안
-
ICLM의 In-Context Learning/RAG/Document 필요 태스크(QA) 등에서 높은 성능
-
모델 크기 및 태스크와 관계없이 꾸준히 높은 성능 리포팅
-
매우 다양한 Downstream Task에 대한 성능 리포팅을 통한 신뢰도 확보
-
참 말을 잘한다…
Future Works
-
Domain/Corpus 단위의 Relevant Document 수집 방법론
-
Multilingual Retriever를 통한 언어별 Input 구성 방법론
- 동일 레포에서 산출된 코드를 통한 ICL Pretrain 등