In-Context Retrieval-Augmented Language Models
논문 정보
- Date: 2024-07-30
- Reviewer: 김재희
- Property: Retrieval, ICL, In Context Learning
1. Intro
1-1. Contributions
2023년 01월에 발표된 논문이라는 점을 감안
- Off-the-shelf Retriever을 이용한 RAG 프레임워크 유효성 입증
- RAG 프레임워크 내 설계 요소(retriever, stride, reranker)에 대한 실험 진행
-
전반적인 논문의 서술은 최근 활발히 사용되는 RAG 프레임워크에서 크게 다르지 않음
- 당연한 내용을 당연할 수 있도록 정리한 논문!
1-2. TL;DR
-
Off-the-shelf Retriever 역시 Reader 성능 향상에 도움을 준다.
-
Retriever의 종류(sparse, dense)와 관계없이 성능 향상에 도움을 준다.
-
stride는 적절히 짧게, retrieved passage의 수는 많을수록 성능 향상에 도움이 된다.
-
하지만 stride가 짧을수록, retrieved passage가 많을수록 연산량 증가
-
Reranker는 당연하게도 도움이 된다.
RALM의 Design Choice는 초록색 글씨로 표시하였습니다.
2. Related Works
2-1. Retriever-Augmented Generation(RAG)
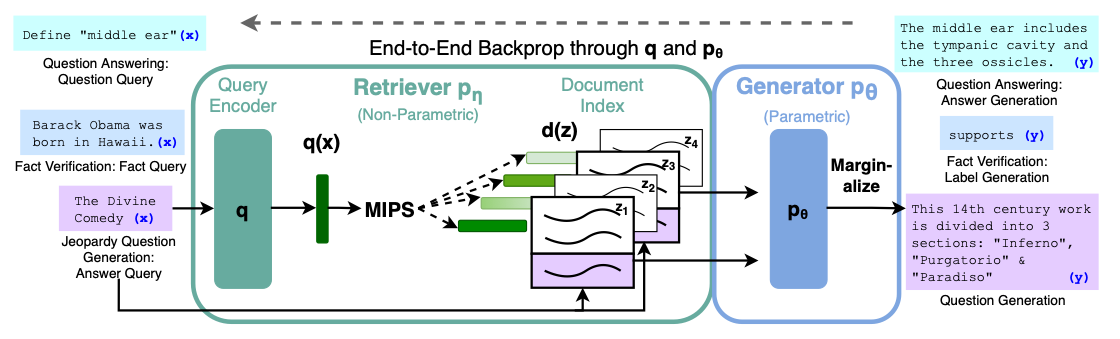
-
Knowledge Intensive Task 시 외부 Document를 적절히 이용하도록 Retriever를 이용하는 방법론 제안
-
Retriever(query encoder)와 Generator(T5)를 동시에 훈련하는 학습 방법론 제안
2-1-1. 학습 방법
-
Retriever 훈련: Knowledge Intensive Dataset(NQ, TriviaQA)으로 훈련된 DPR 모델 이용
-
End-to-End 훈련: (Retrieve된 document k개, relevance score k개, Generation Prob)을 이용하여 Generator와 Retriever 훈련
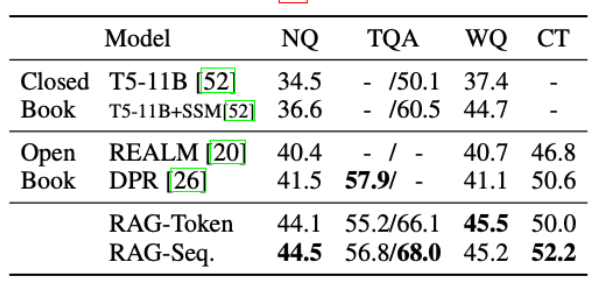
2-1-2. 성능
-
다양한 Knowledge Intensive Task에서 기존 방법론 대비 높은 성능 달성
-
기존 방법론:
-
Closed Book: 외부 Document를 이용 X
-
Open Book: 외부 document를 이용하되, Encoder-only Reader 사용
-
2-2. Improving language models by retrieving from trillions of tokens(RETRO)
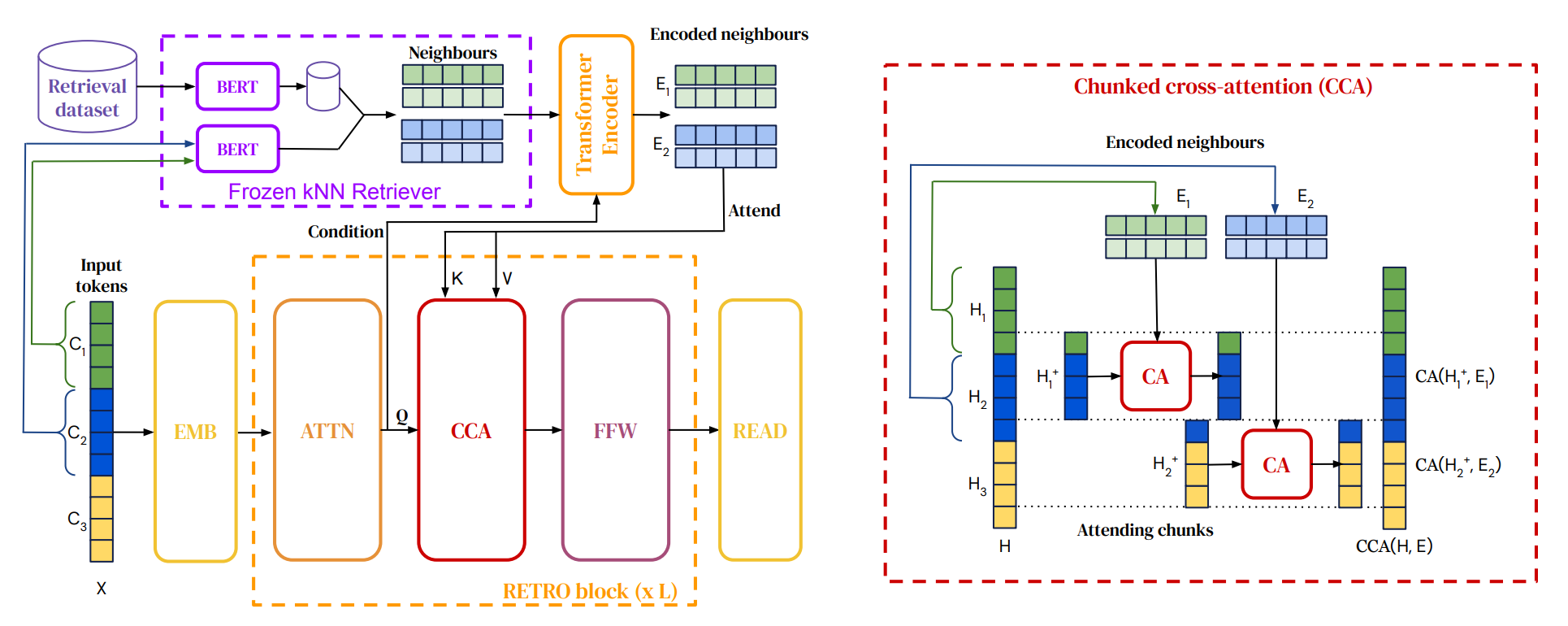
-
RAG를 확장하여 다양한 일반 태스크에 적용할 수 있는 프레임워크 제안
-
Retriever(BERT)를 Freeze하고 query와 가장 가까운 문서의 representation에 대한 attention(Chunked Cross-Attention)구조 제안
2-2-1. 성능
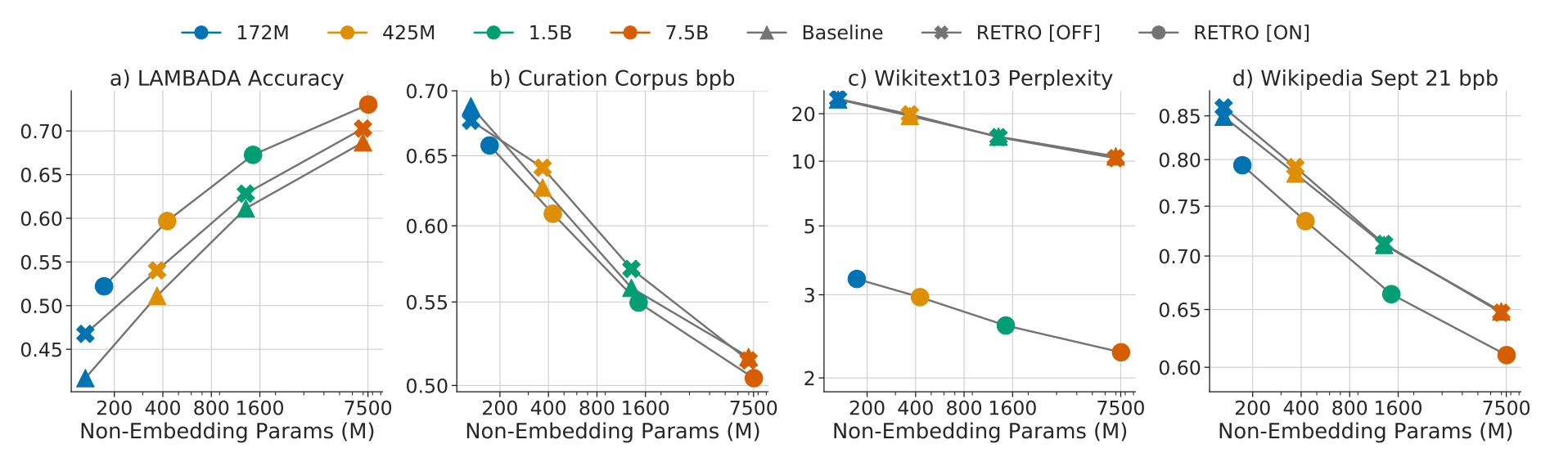
-
모델 크기(million to billion)에 관계없이 일관된 성능 개선 관찰
-
Retriever 사용 여부(on/off)가 성능 개선에 큰 영향을 미치는 것 확인
2-3. 요약
2023년의 상황
-
LLaMA의 등장 이후 Open Source LLM에 대한 연구 진행
-
Zero/Few-shot 성능을 개선시키기 위한 다양한 방법론 제안
-
CoT, In-Context Learning
-
-
Million Scale의 RAG 프레임워크 연구들이 끝물을 향해 가고 있음
- FiD, Atlas, FiD-Light
-
LLM에 RAG 프레임워크 적용이 활발히 시작되던 시기
3. Methods
3-1. In-Context RALM(Retriever-Augmented Language Modeling)
3-1-1. Language Modeling
- Prefix(x_{<i})를 바탕으로 현재 시점(i)의 토큰 분포를 생성하는 작업
3-1-2. Naive In-Context RALM
-
기존 LM에 Retriever 추가
-
\mathcal{R}{\mathcal{C}}(x{<i}): Prefix를 query로 Retriever 수행한 Top-k document
-
매 시점마다 다음 과정 수행
-
Retrieval: 현재 시점까지의 prefix를 query로 document retrieval
-
Concatenation: 기존 텍스트(x_{<i})와 Retrieved Document를 concat
-
concat된 텍스트가 model의 max length를 넘을 경우 기존 텍스트(x_{<i})를 truncation
-
Generation: 기존에 생성된 텍스트(x_{<i})와 Retrieved Document를 모두 입력으로 하여 i 시점의 token dist. 생성
-
3-2. RALM Design Choices
3-2-1. Retrieval Stride(s)
오늘 서울에서 대전까지 가는 동안 날씨가 어떻게 변할 것 같아? 금일 서울의 날씨는 28도로 온화 … 금일 대전의 날씨는 35도로 매우 더울 예정 … 전국 날씨는 비가 오지 않습니다.
-
Naive RALM: 매 토큰마다 Retrieval 진행
- Retrieval 비용 + 새롭게 representation 계산 비용 발생 → High cost
-
Retrieval Stride(s): retrieval을 수행할 간격
- s=3: 3토큰 생성 시마다 새롭게 retrieval을 수행
-
n_s(=n/s): 전체 text length가 n일 때, retrieval 횟수
-
s의 크기는 속도(연산량)과 성능 간 trade-off 관계
- s가 커질수록 속도는 빨라지지만, 성능은 저하됨
3-2-2. Retrieval Query Length(\ell)
오늘 서울에서 대전까지 가는 동안 … \mathcal{R}{\mathcal{C}}(오늘 서울에서 대전까지 가는 동안) → 서울? 대전? \mathcal{R}{\mathcal{C}}(대전까지 가는 동안) → 대전의 날씨!
-
Naive RALM: 현재까지 생성된 모든 text를 query로 사용
- 현재 시점 token dist. 생성 시 중요한 정보가 희석될 수 있음
-
qj^{s, \ell}:=x{s \cdot j-\ell+1}, \ldots, x_{s \cdot j}: 현재까지 생성된 토큰 중 직전 \ell 길이의 토큰만 query로 활용
3-3. Reranking
3-3-1. LM as Zero-Shot Rerankers
-
LM을 학습없이 Reranker로 활용하는 방법론 제시
-
k: Top-k개의 Retrieved Document
-
Objective: k개의 Document 중 성능 개선에 도움을 줄 수 있는 top-1 doc을 rerank
⇒ train data가 없는 환경에서 해당 정보가 반영된 Reranker 구축 X
-
입력된 text의 일부를 validation data로 활용
-
reranking: 입력 텍스트의 마지막 s’개 토큰 PPL을 최소화하는 document 탐색 작업
- LM을 이용하여 zero-shot reranker 구축 가능
3-3-2. Training LM-dedicated Rerankers
-
RoBERTa를 훈련하여 Reranker로 활용하는 방안 제시
- Language Modeling 상황에서 활용 가능한 reranker 훈련 방법론
-
Relevance Score: Reranker의 score를 normalize하여 사용
-
Training Objectives: PPL을 낮추는 Document의 Relevance Score를 높이도록 학습
4. Experiments
4-1. Experiment Setup
4-1-1. Datasets
-
Language Modeling(Perplexity)
-
WikiText-103: 일반적인 LM 성능 평가용 corpus
-
The Pile(ArXiv, Stack Exchange, FreeLaw): 특정 도메인(과학, 코드, 법률)에 대한 LM 성능 평가 목적
-
RealNews: 일반적인 RALM 프레임워크 사용 환경(Knowledge-Intensive task)에 대한 성능 평가 목적
-
Open-Domain Question Answering(Exact Match)
-
RALM의 실제 정답 생성 능력 평가 목적
-
지식 기반의 질의응답 데이터셋 이용
-
Natural Questions, TriviaQA
4-1-2. Models
-
Language Models
-
GPT-2(110M ~ 1.5B): Wikipedia 문서가 제외되어 학습
⇒ WikiText-103을 이용하여 완전한 zero-shot 상황에서의 성능 확인 가능
-
GPT-Neo, GPT-J(1.2B ~ 6B)
-
OPT(125M ~ 66B)
-
LLaMA1(7B ~ 33B)
-
다양한 scale의 모델에 대한 효과 검증
-
Wikipedia가 학습에 이용되었으므로 학습데이터의 RALM 효과 확인
Context Length: 1024
-
Retriever
-
Sparse Retriever: BM25
-
Dense Retriever
-
BERT: RETRO와 동일하게 retriever finetune되지 않은 경우의 성능 확인
-
Contriever, Spider: Unsupervised Manner로 학습된 Retriever
-
Reranker
-
RoBERTa-base 사용
-
향후 실험에서 학습 여부에 따른 성능 실험 진행
Retrieved Document Length: 256
4-2. Effectiveness of Retriever
4-2-1. 모델 별 RALM 적용 시 성능 변화(s=4, l=32)
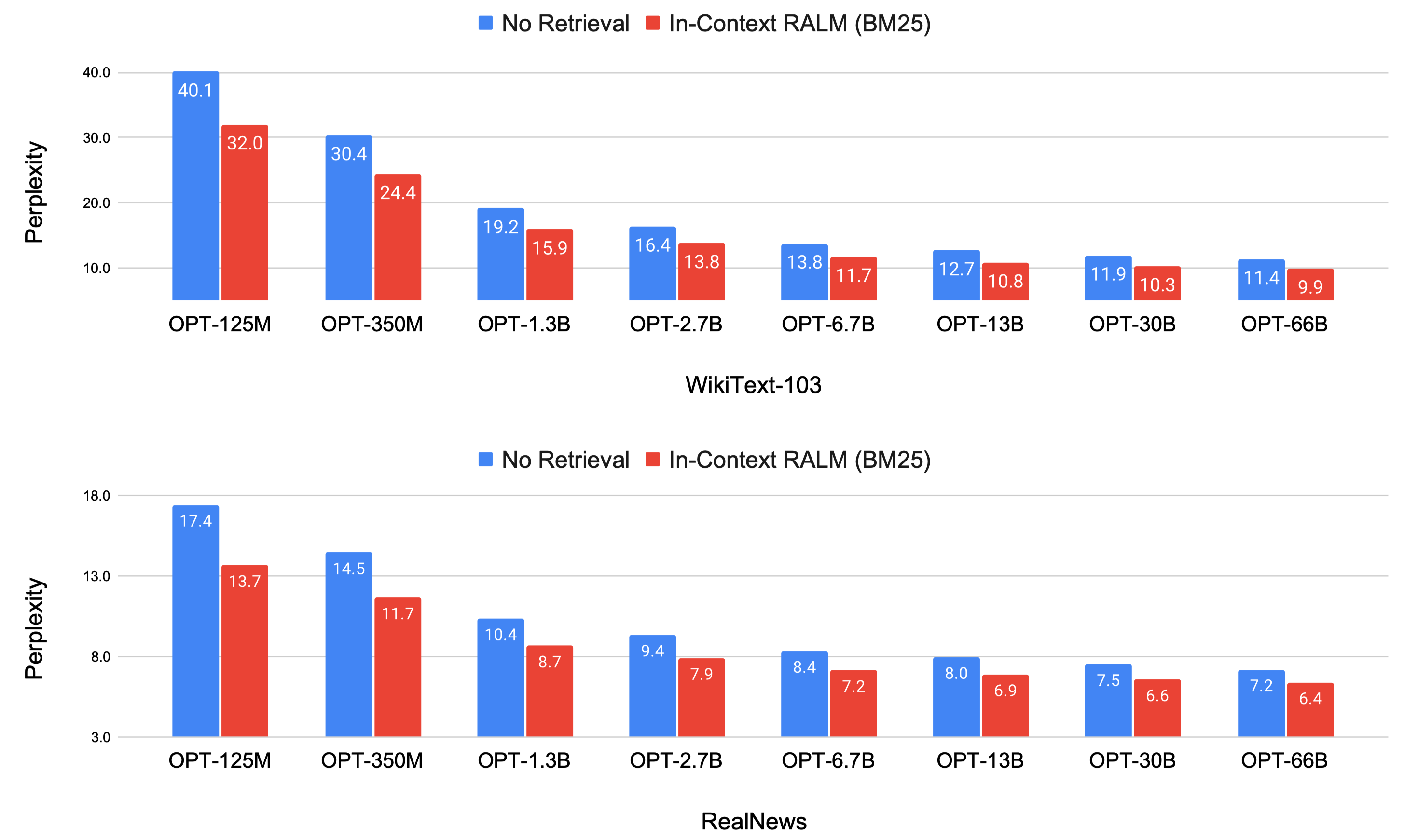
모델 크기와 관계없이 RALM 적용 시 성능이 개선됨
-
BM25: RETRO 및 RAG와 다르게 LM과 함께 학습된 Retriever X, Sparse Retriever
-
모든 모델에서 RALM 적용 시 PPL이 개선되는 모습
-
큰 모델 w/o Retriever < 작은 모델 w/ Retriever
- OPT-66B w/o Retriever < OPT-6.7B w/ Retriever
4-2-2. Retrieval 종류 별 성능 양상
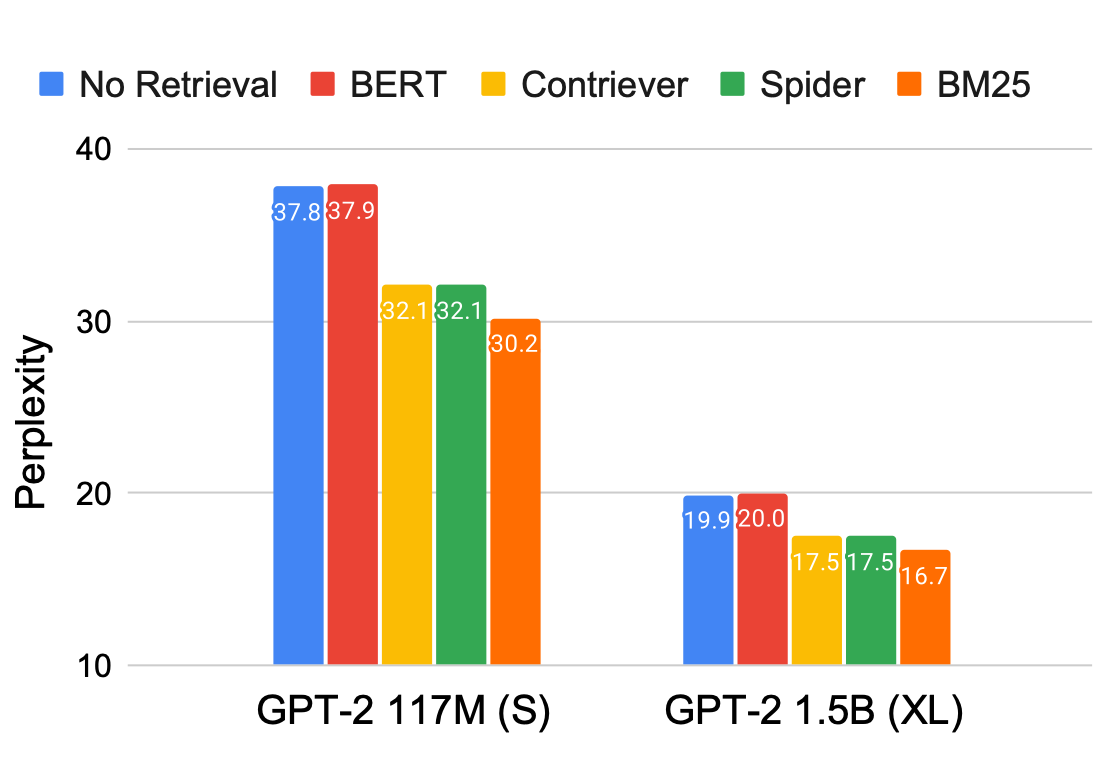
Sparse Retriever가 Dense Retriever보다 높은 성능 달성 가능
-
Language Modeling 태스크에서 Sparse Retriever(BM25)가 가장 좋은 성능 달성
-
모델 크기에 관계없이 동일한 양상 유지
-
Wikipedia(Spider), Wikepedia + CCNet(Contriever)의 경우 비슷한 성능 도출
- BM25보다 성능이 좋지 않으나, Retrieval을 사용하지 않은 경우보다 개선
-
BERT의 경우 성능 개선 X
-
RETRO: BERT를 Freeze하여 Retrieval Module로서 활용
-
RALM 프레임워크에서 Retrieval의 성능이 중요
-
4-3. Design Choice of RALM
4-3-1. Retrieval Stride
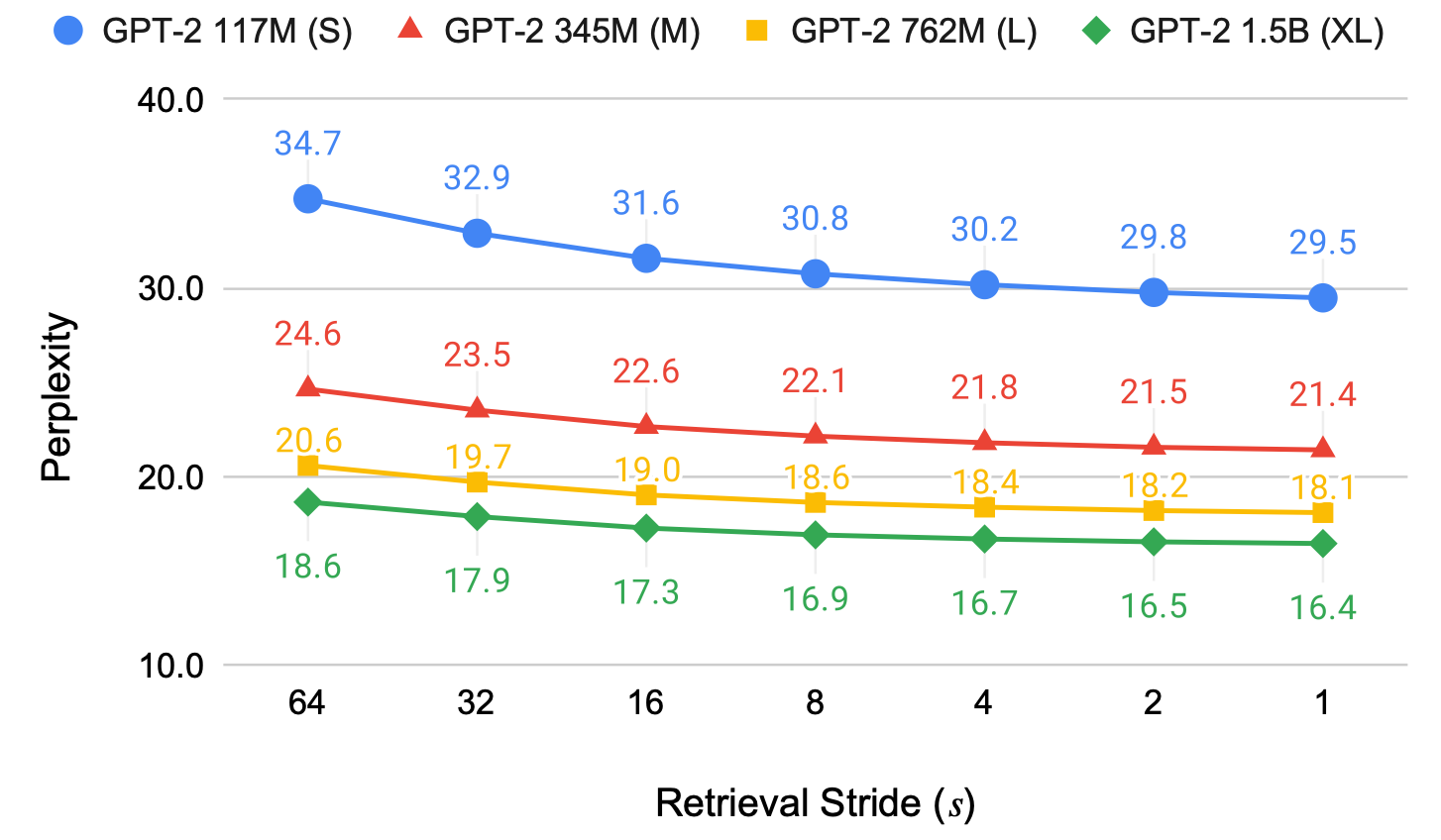
Stride에 따른 성능과 속도 Trade-off 관계 존재 확인
-
Stride가 짧을수록 성능이 개선되는 경향성 포착
-
짧은 Retrieval Stride: 자주 Retrieve → 현재 생성하고자 하는 정보와 유사한 정보를 Retrieve할 수 있음
4-3-2. Retrieval Query Length
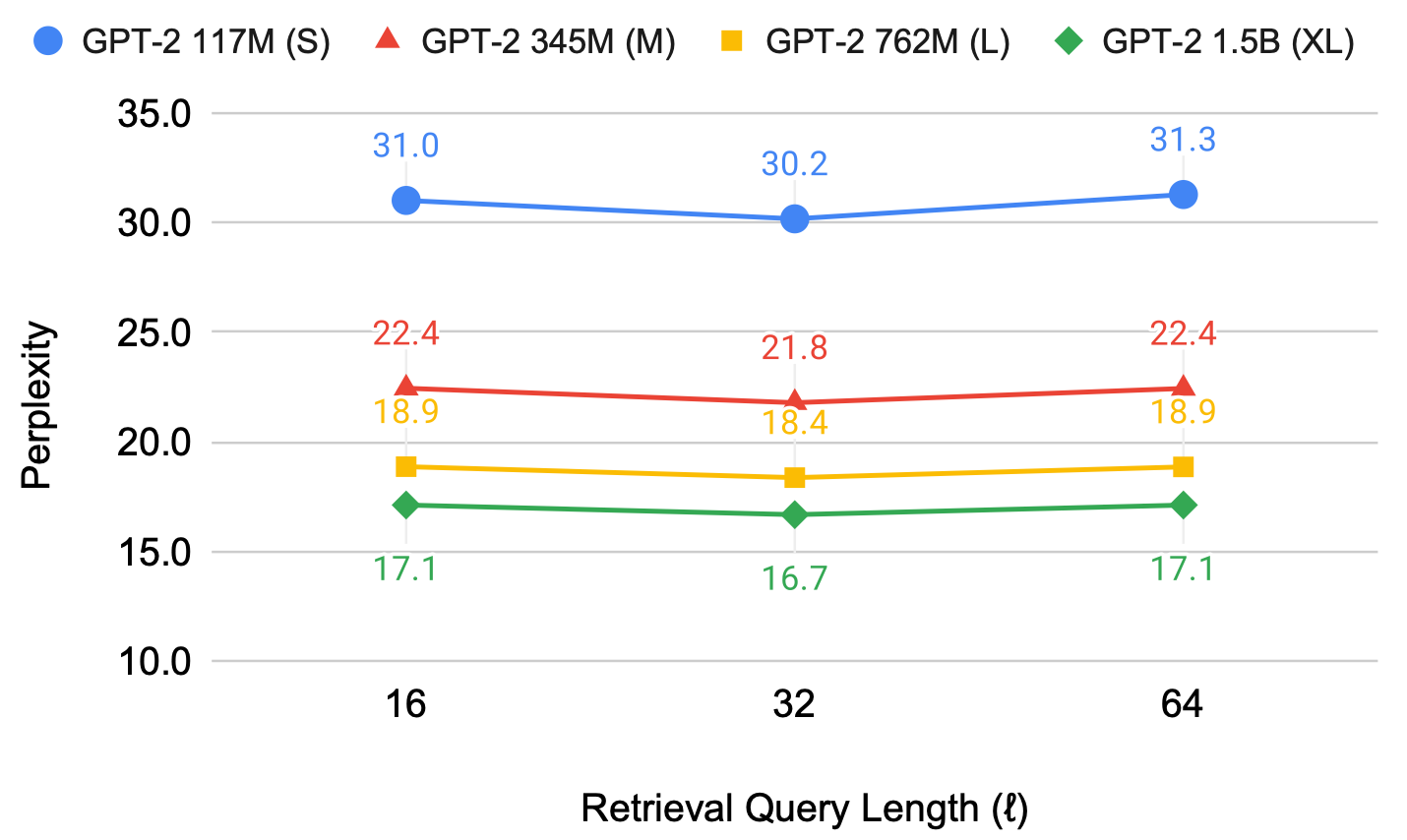
적절한 길이의 Query Length가 Retrieval 효과 결정
-
BM25 이용 시 Query Length에 따른 성능 변화
-
Query Length=32일 때 최적의 성능 도출
-
Dense Retrieval 사용 시 64 길이가 최적
-
너무 긴 Query Length: Retrieve해야 하는 정보가 희석
-
너무 짧은 Query Length: Retrieve해야 하는 정보가 충분히 반영 X
4-4. Effect of Reranker
4-4-1. Reranker 사용의 효과
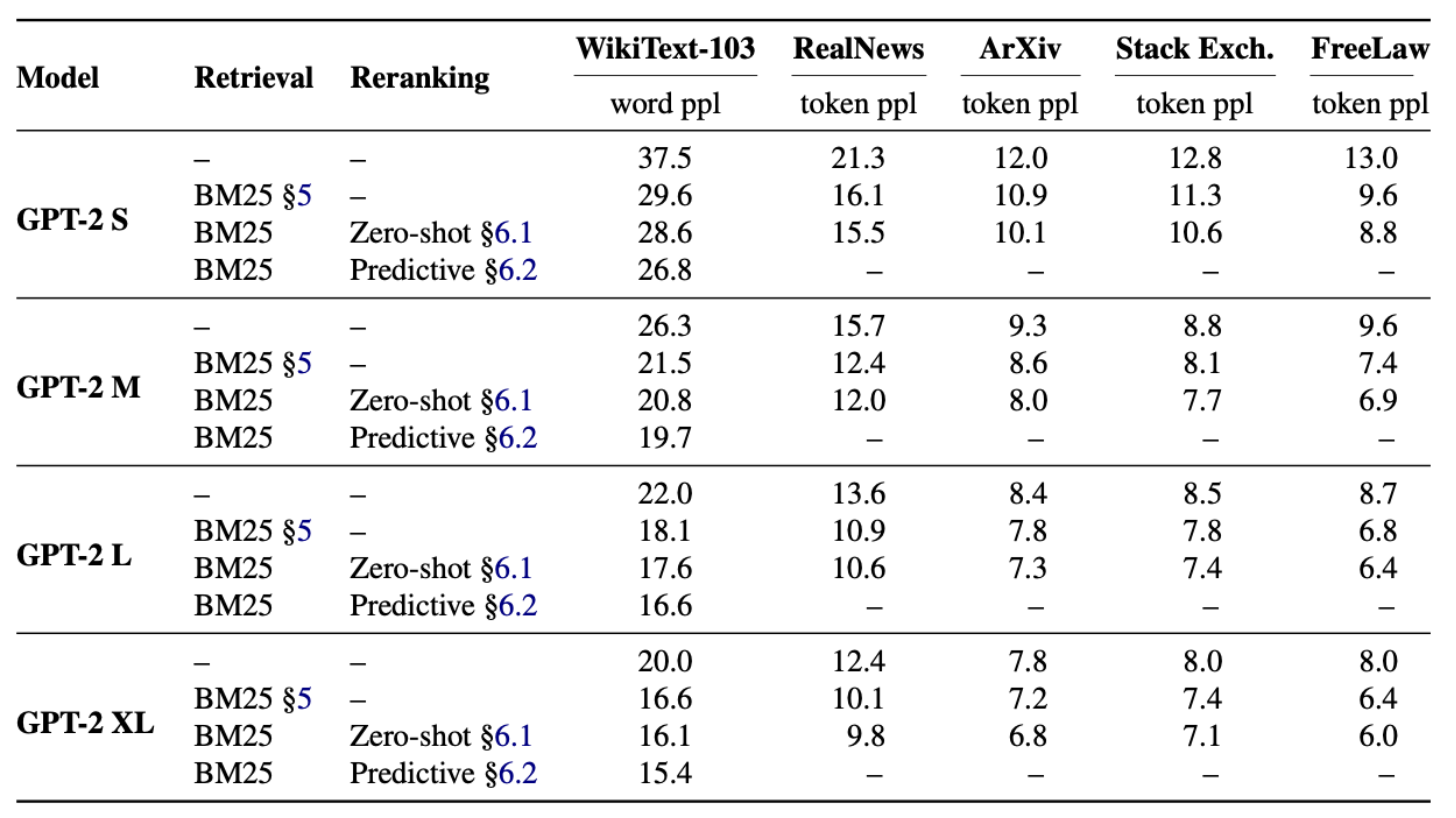
w/o Retrieval < w/ Retrieval < w/ Reranker < w/ Trained Reranker
-
모든 데이터 및 모델에서 동일한 경향성 포착
-
Retrieval 사용(top-1) 시 가장 큰 성능 개선 확인
-
Reranker 사용(top-16) 시 추가적인 성능 개선 확인
-
4-4-2. Reranker 효과의 원인
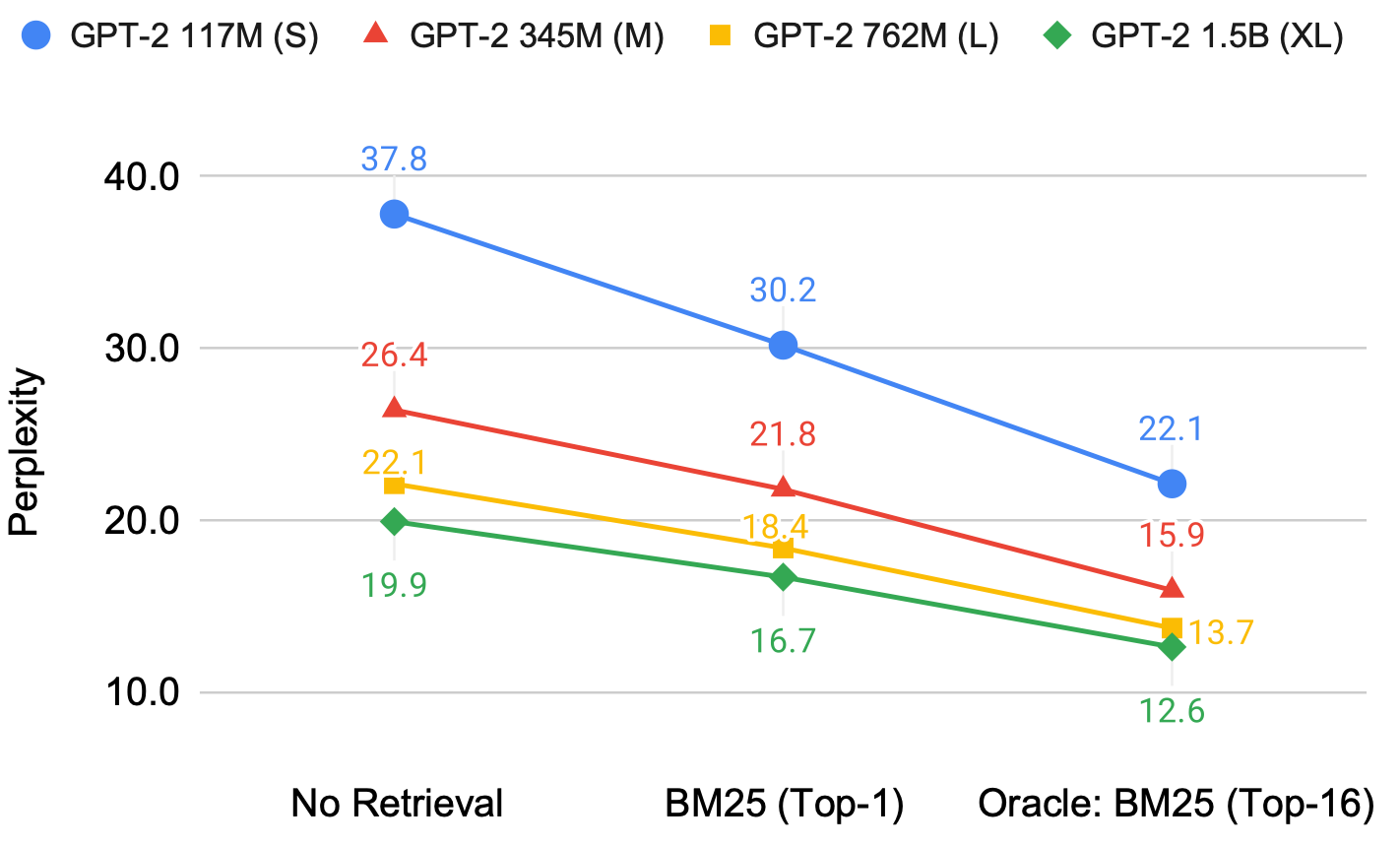
_Retrieved Document 중 최선의 문서는 따로 있다. _
-
Oracle: Top-16 document 중 가장 성능 개선이 큰 Document의 성능
-
Retrieval 특성 상 Top-1 Document가 항상 최선의 문서 X
-
Document 중 실제 성능 개선이 더 도움이 되는 Doc을 탐색하는 작업이 중요
-
4-4-3. Zero-Shot Reranker
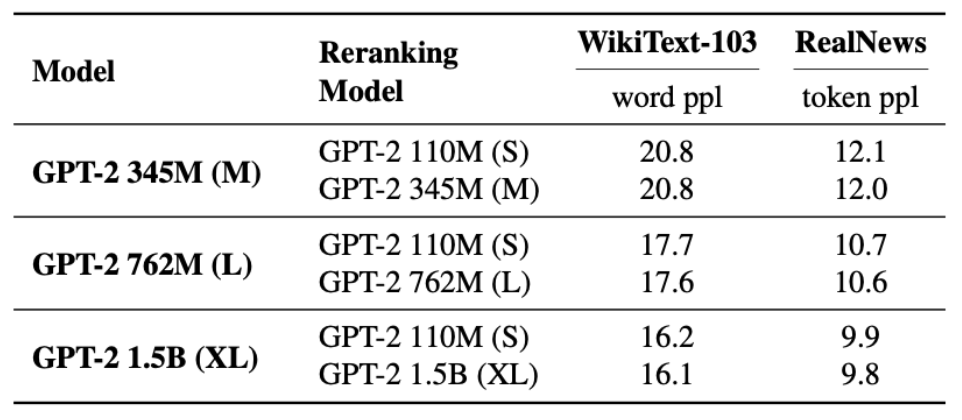
Zero-shot Reranker의 크기는 중요하지 않다
-
Zero-shot Reranker: 사전학습된 LM을 이용하여 Reranking 작업 수행
- 실제 Language Modeling을 수행하는 LM일 필요 X
⇒ 작은 LM을 Reranker로 이용한다면 효율적 reranking 가능
4-5. Open-Domain Question Answering
4-5-1. ODQA w/ RALM
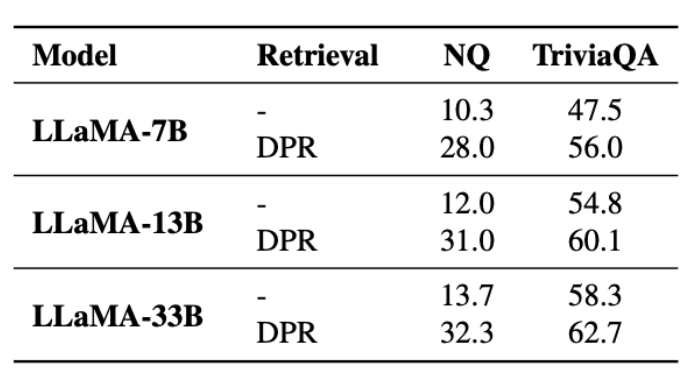
_LLM을 ODQA에 활용할 때도 RALM은 매우 효과적이다. _
-
DPR: NQ와 TriviaQA로 학습된 Retriever
- 이전과 다르게 In-Domain Retriever 활용
-
RALM을 통해 LLM의 Knowledge Intensive Task 성능을 비약적으로 증가시킬 수 있음
4-5-2. # of Document for ODQA
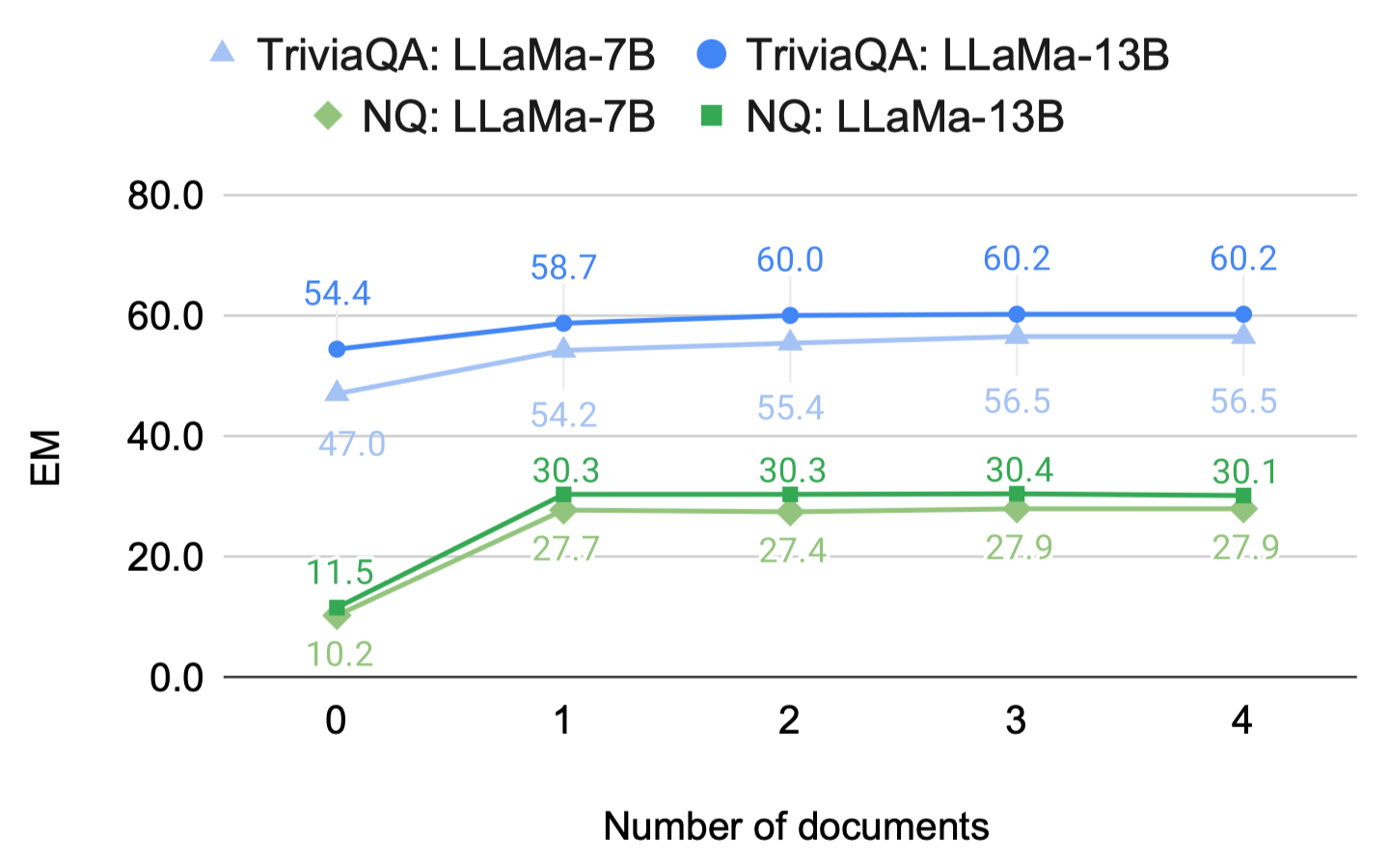
_ODQA에서는 Document의 수가 많을 필요가 없다. _
-
다소 혼재된 실험
-
Retrieval: DPR
-
이전과 다르게 In-Domain Retriever: Retrieved Document의 품질이 Language Modeling 시보다 좋을 수 밖에 없음
-
⇒ Contriever, Spider 등의 Unsupervised Dense Retriever 사용 시에도 비슷한 성능 양상이 나타나는지 확인 필요
- 모델 크기와 관계없이 일관된 Optimal Document 수가 정해짐(1, 2)
7. Conclusion
- Off-the-shelf Retriever을 이용한 RAG 프레임워크 유효성 입증
- RAG 프레임워크 내 설계 요소(retriever, stride, reranker)에 대한 실험 진행
-
BM25: Language Modeling 시 강력한 Retriever baseline으로 동작
- 최근 연구되는 다양한 embedding model들이 더 나은 성능을 보임
→ 모델 크기 증가(~7B)를 통한 일반화 Retrieval 성능 개선
-
Off-the-Shelf Retriever의 Language Modeling 시의 성능 개선 효과 확인
-
기존 연구: Retriever를 LM과 함께 학습 → LLM과 joint train 시 매우 큰 비용 발생
-
별도로 학습된 Retriever or BM25를 활용하는 것만으로도 성능 개선이 가능함
-
-
이후 RAG 기반 연구들의 baseline으로서 동작하는 연구