Knowledge-Augmented Reasoning distillation for Small Language Models in Knowledge-Intensive Tasks (KARD)
논문 정보
- Date: 2024-08-20
- Reviewer: 전민진
- Property: Reasoning, Knowledge Distillation
Abstract
-
이전 연구에서는 labeled data로 fine-tuning하거나 LLM을 distilling하는 방법론에 집중
-
이러한 방법론은 knowledge-intensive reasoning task에는 적합하지 않음
- 필요한 knowledge를 기억하기에 small LM의 capacity가 제한적이기 때문
-
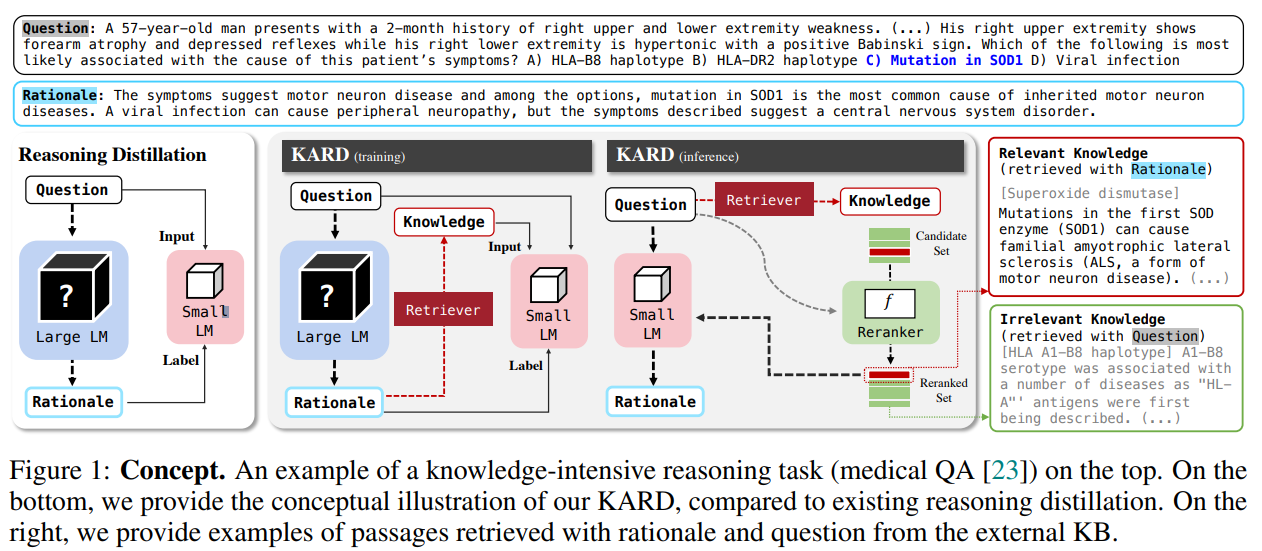
본 논문에서 Knowledge-Augmented Reasonign Distillation(KARD)
- 외부 knowledge base에서 검색한 정보를 합쳐서 LLM으로부터 얻은 rationales를 생성하도록 작은 LM을 fine-tuning하는 방법론을 제안
-
또한, rationale generation에 관련된 문서를 얻기 위해 reranker 학습 방법론을 제안
-
실험 결과, MedQA-USMLE, StrategyQA, OpenbookQA와 같은 knowledge-intensive reasonign dataset에서 fine-tuned 3B 모델보다 250M KARD 모델이 더 뛰어난 성능을 보임
Introduction
-
최근에 LLM의 파라미터 수를 늘림에 따라 knowledge encoding과 reasoning capability이 상당히 향상
-
이런 LLM은 knowledge-intensive task에서도 뛰어난 성능을 보임
- 예를 들어서, MedQA같은 경우 의학적 지식도 있어야 하고, reasoning 능력도 있어야 함

-
LLM은 성능이 매우 뛰어나지만, 너무 많은 메모리를 소요하고, privacy leakage의 우려도 존재
- GPT3-175B모델을 띄우기 위해선 326GB GPU mem 필요
-
결론적으로, 이러한 knowledge-intensive task을 수행할 수 있는 white-box small Lm이 필요!
-
이를 해결하기 위해 기존에 reasoning distillation이라는 방법론이 존재
-
LLM에서 각 QA에 대한 rationale을 생성, small LM이 rationale을 생성할 수 있도록 finetuning하는 방식
-
저자들은 여기서, “domain knwoeldge와 reasoning ability를 동시에 transfer하는게 가능한가?”라는 reasearch question을 갖게 됨
-
-
task을 풀기 위한 knowledge를 작은 모델이 다 기억할 수 없기 때문에, 현재의 reasoning distillation방식은 suboptimal한 방식이라 주장
- 이를 해소하기 위해 knowledge augmented reasoning distillation(KARD)를 제안
-
contribution
-
기존의 knowledge distillation방식으로는 knowledge-intensive reasonign task를 수행하기에 부족하고, 외부 메모리가 중요한 역할을 한다는 사실을 밝힘
-
현재 retriever method의 한계를 보이고, 이를 보완하는 reranker학습 방식을 제안
-
여러 종류의 데이터셋에서 우수한 성능을 보임
-
Related Workds
-
LLM
- LLM의 가장 큰 강점은 knowledge를 memorize할 수 있고, 이를 바탕으로 knowledge-intensive reasoning task를 수행할 수 있다는 것
-
Reasoning Distillation from LLM
- 이전 연구에서 정확한 rationale을 생성하는데 중요한 factual knowledge들 사용하지 않기 때문에, reasoning distillation은 knowledge-intensive reasoning task에서 덜 효과적이라는 것이 밝혀짐
-
Knowledge-Augment LMs
-
현재의 검색 모델은 knowledge-intensive reasoning task을 풀기 위한 관련된 passage를 검색하는 능력이 충분하지 않다는 것이 이전 연구에서 밝혀짐
-
이러한 한계를 극복하기 위해, query가 주어졌을 때, LLM으로 생성된 rationale에 관련된 passage를 더 우선순위에 두도록 학습한 reranker를 제안
-
Motivation: Effect of Knowledge-Augmentation on Memorization
-
LLM은 training data를 memorize하는 것으로 알려져있고, memorization capacity는 모델의 크기가 클수록 커지는 경향이 있음
-
언어 문제를 잘 풀기 위해서는 학습 데이터의 암기력이 중요하다는 연구 결과도 있었음.
-
즉, knowledge augmentation없이 small LM으로 reasoning distillation하는 방법은 성능을 감소시킬 것
-
학습 데이터를 암기할 능력 부재
-
성능이 나오려면 암기가 필요
-
-
아래의 수식으로, 본 논문의 저자들은 external knowledge base(KB)을 non-parametric memory로 사용하는 것이 모델이 성능을 내기 위해 필요한 암기의 양을 줄인 다는 것을 증명함
(사실 수식은 정확히 이해 못했습니다..)
[Background without Knowledge-Augmentation]

-
train data와 algorithm A로 학습한 모델 M의 overall error을 이렇게 수식으로 표현할 수 있음
-
q(meta-distribution)과 n( # of train data)이 주어질 때, overall error를 최소화하는 optimal learner A_opt가 있다고 가정
-
여기서 말하는 task는 abstraced language problem으로 N개의 reference string을 보고 다음 symbol 맞추는 문제.. 같은 것!
- 각각의 string은 d bit로 표현됨

- 그러면 이전 연구에서 증명된 바와 같이, 어떤 알고리즘 A가 eps-suboptimality를 달성하기 위해선 training data nd bit를 외워야만 함
[Memorization with knowledge-Augmentation]
-
Theorem 1에서, d는 knowledge base의 크기와 같고, 만약 KB의 크기가 작다면 작은 모델도 이를 다 암기할 수 있음
-
하지만 KB의 크기가 커지면, 작은 모델이 \Omega(nd) 정보를 다 외울 수 없으므로 성능이 크게 떨어질 것
-
하지만 이때, knowledge-augmentation을 통해서 task에 필요한 정보량 \Omega(nd)를 O(nlog_2(N+R))로 줄일 수 있음!

Knowledge-Augmented Reasoning Distillation
-
KARD는 2가지 learning process로 구성됨
-
- reasoning distillation
-
- reranker training
-
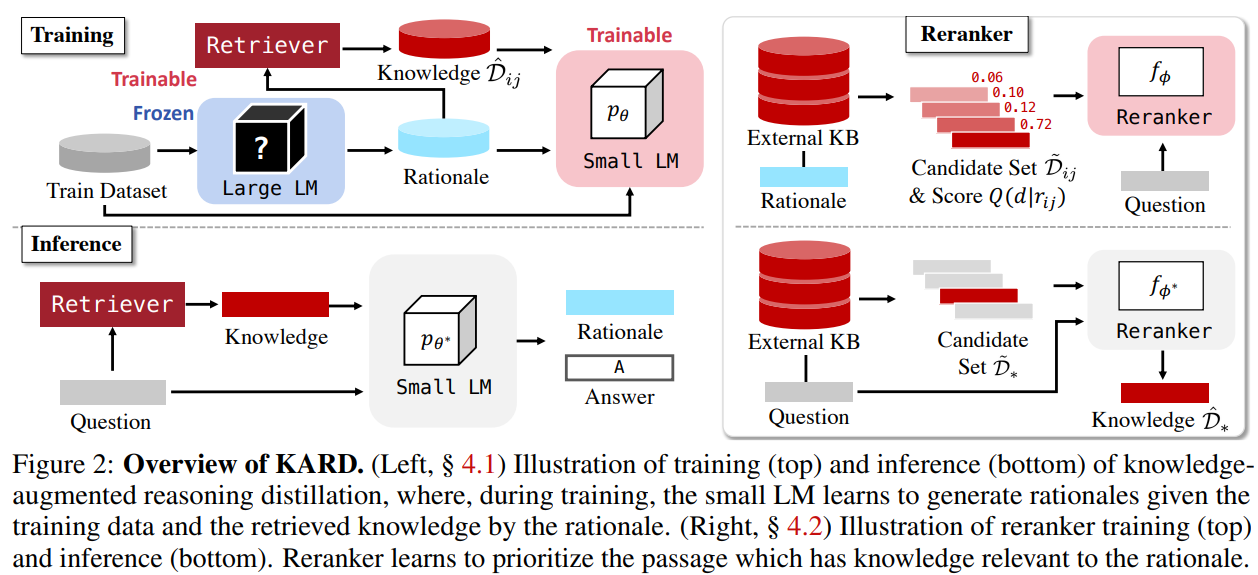
Teach small Models to Generate Rationales with External Knowledge
[Rationale Generation with LLMs]
-
target task의 training dataset ((xi,y_i)){i=1}^n이 있다 가정
-
black-box LLM에 prompt, question, answer을 넣어서 각각 l개의 rationale을 생성(j는 rationale index)
-
r_{ij} = LLM(p,x_i,y_i)
-
p는 chain-of-thought prompt
-
[Fine-tuning Small Models on Rationales] - 기존의 reasoning distillation 방법
- 위에서 생성한 rationale을 바탕으로 rationale, answer을 순차적으로 생성.
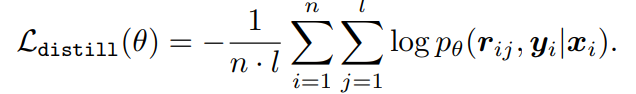
-
knowledge augmentatino없이 small model을 reasoning distillation하는 방식은 rationale generation에서 성능 저하가 발생할 수 있음
- small model은 training data를 암기할 능력이 부족하기 때문..
[Intergrating External Knowledge Base] - KARD의 방법
-
LLM이 생성한 rationale을 query로 relevant passage k개를 검색, 이를 바탕으로 모델이 rationale, answer를 학습하도록 함
-
\hat{D}_{ij}=topk(p(d r_{ij};D),k)\subset D
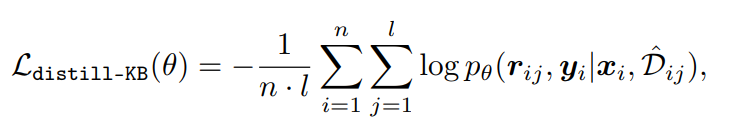
Training Neural Reranker for Rationale Generation
-
Intergrating external knowlege base방식의 문제가 inference때는 rationale을 query로 사용할 수 없다는 것
-
inference때에는 query로 question을 사용해야하는데, 이 경우 학습 때와 다르게 rationale을 생성하는데 중요하지 않은 passage가 뽑힐 수 있음
-
이를 해결하기 위해, rationale을 query로 썼을 때의 결과와 유사하게 나오도록 reranking을 해주는 reranker 학습 방법을 제안
-
\tilde{D}_{ij}=topk(p(d r_{ij};D),k_1)\cup topk(p(d x_i;D),k_2) - k_1과 k_2는 후보 document의 수
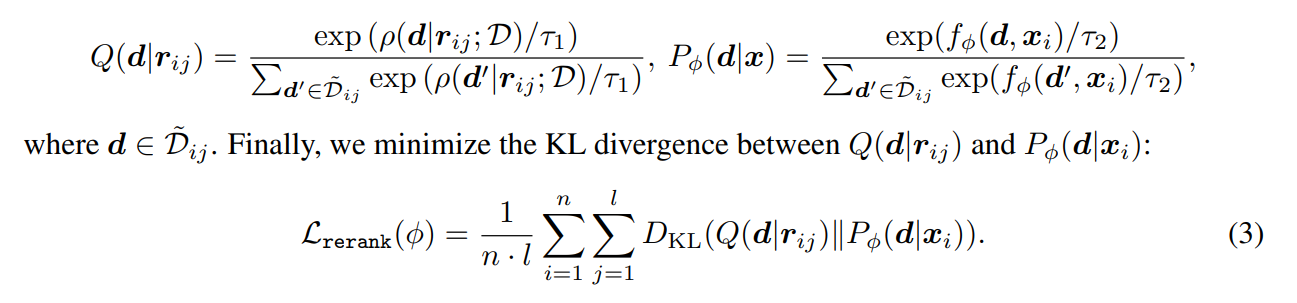
-
rationale을 query로 썼을 때 검색된 document랑, question을 query로 썼을 때 검색된 document를 합쳐서 candidate document set을 만듦
-
set안의 문서를 대상으로 rationale을 query로 줬을 때 검색 모델이 계산한 relevance score를 normalize한 것이 Q
-
set안의 문서를 대상으로 question을 query로 줬을 때 reranker 모델이 계산한 relevance score를 normalize한 것이 P
-
이 둘의 KL divergence를 loss로 reranker를 학습
- rationale과 유사한 passage에 대해 높은 점수를 주도록 학습
Inference
- 학습된 small LM과 reranker로 inference 진행
-
question을 query로 retriever(BM25)을 통해 candidate document를 k*(100)개 추출
-
document를 re-ranking, 최종적으로 k개의 document를 선택
-
question과 k개의 document를 small model에 넣어서 rationale 생성
-
question, k개의 document, rationale을 바탕으로 최종 답변 생성
Experiments
Experimental Setting
[Task and Dataset]
knowledge-intensive reasoning task에 집중
-
MedQA : medical multiple-choice question dataset
-
USMLE : US medical licensing exam에서 가져온 4 multiple-choice question
-
StrategyQA : 복잡한 multi-step reasoning skill과 여러 도메인의 정보를 취합하는 능력이 필요한 task. 이지선다
-
OpenbookQA : 초등학교 수준의 과학 질문. 사지선다.
[Baselines]
-
Few-shot ICL
-
Few-shot ICL + CoT : 예시 + rationale 생성 및 rationale 기반으로 답변 생성하도록
-
Fine-tuning : input으로 question이 주어졌을 때 바로 answer 생성하도록 학습
-
위의 방법에 knowledge-augmented 방식도 접목 (knowledge base는 wikipedia), 학습과 추론 모두 retrieved passasge 사용
-
Reasoning Distillation : LLM으로 rationale, 답 생성, small LM이 rationale 생성해서 답하도록 학습
-
Oracle model : query로 question이 아닌 rationale을 사용했을 때의 성능
[Language Models]
-
Flan-T5 base, large, XL
-
OPT-350M, 1.3B
-
reranker - LinkBERT
-
teacher LLM - GPT-3.5-turbo
Experimental Result
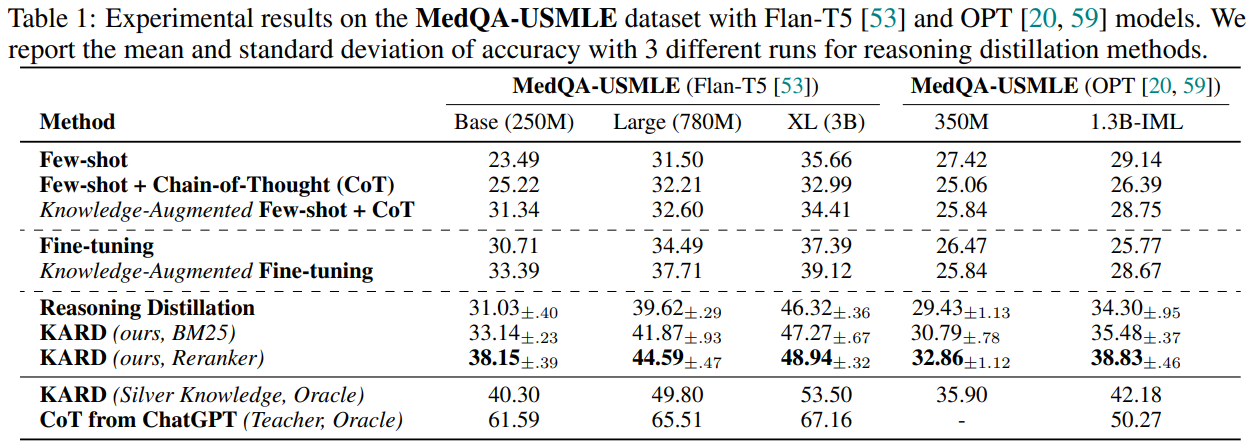
-
위의 결과를 보면 여러 데이터, 모델에 KARD방식으로 학습했을 때 성능이 크게 향상
-
단, 확실히 모델 크기가 커질 수록 KARD의 성능 향상이 낮아짐
-
knowledge augmentation방식은 reasoning distillation, few-shot CoT, FT에서도 성능 향상에 도움이 됨
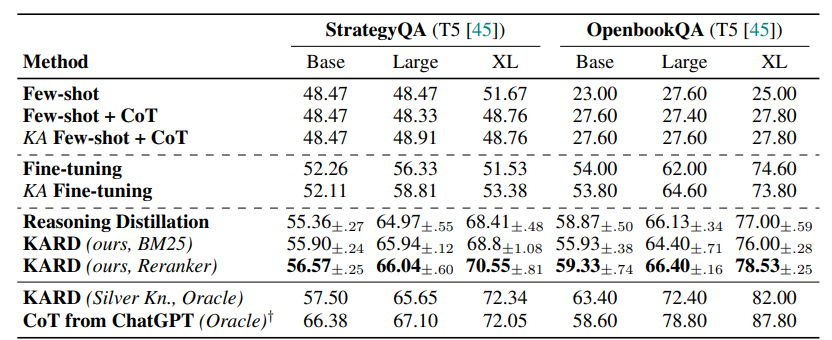
-
SterateyQA와 Openbook QA에서도 성능 향상을 보임
- medical dataset에서보다 성능 향상 정도가 낮은걸 보면, 좀 더 specific하고 전문 지식이 필요한 도메인에서 강점이 있는 방법론인듯
Analysis
[Experiments with DAPT]
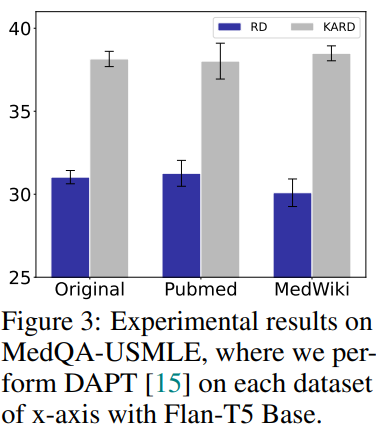
-
Flan-T5 base model을 2개의 biomedical corpora(Pubmed abstracts, MedWiki)로 pretraining하고 나서 각각 reasoning distillation, KARD 방식으로 학습했을 때의 성능 비교
- KARD 방식이 우월한 성능을 보임
[Efficiency on Dataset and Model Sizes]
-
학습 데이터 양에 따른 FT와 KARD 성능 차이 비교
-
학습 데이터가 적어도 KARD가 효율적으로 학습되는 것을 볼 수 있고, 학습 데이터가 많을수록 둘의 성능 격차가 벌어짐
-
모델 크기에 따른 성능을 보면 250M KARD가 11B ICL성능과 유사함
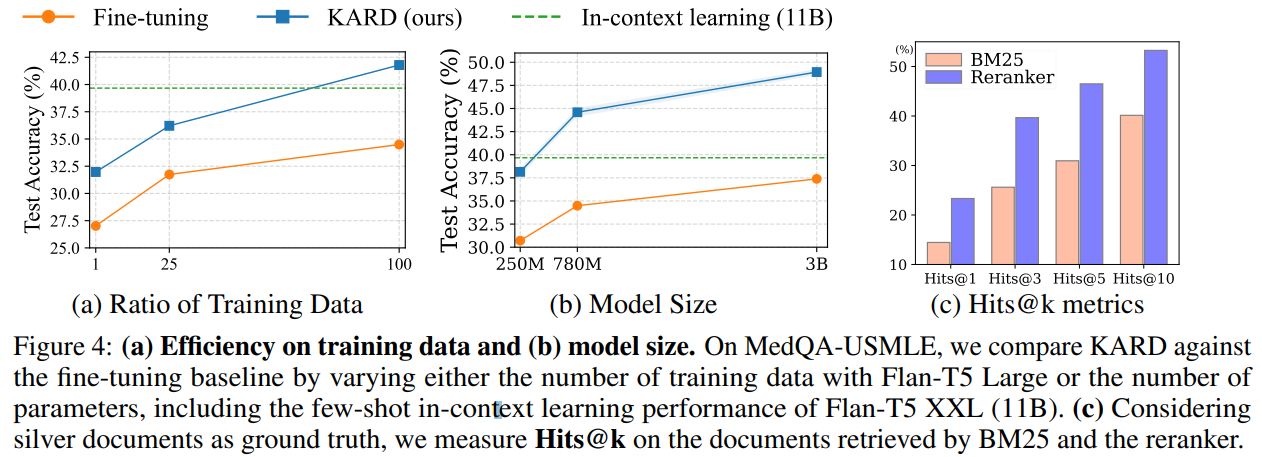
[Retrieval Performance]
-
LLM이 생성한 rationale을 query로 썼을 때 검색된 문서들을 정답 문서 top-3로 보고 hit ratio계산
-
기존 BM25만 사용하는 것보다 reranker의 성능이 뛰어남
[The Number of Rationales During Traning]
-
학습 때 사용하는 데이터 당 rationale 수에 따른 성능 비교
-
l=3이상 일때는 큰 차이가 없었음
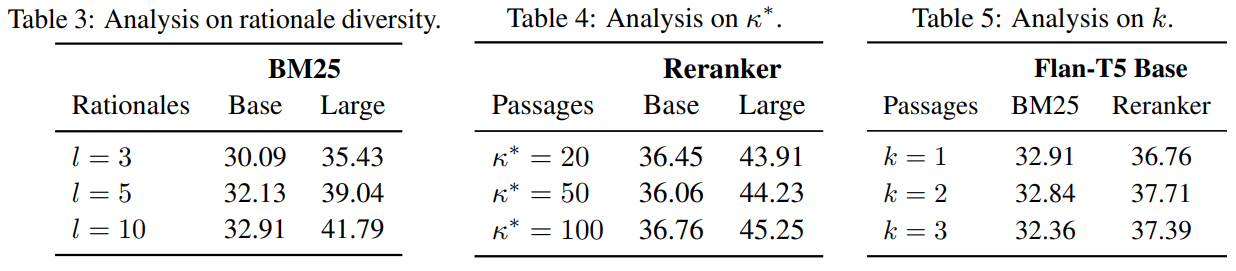
[The Number of Candidate Documents for Reranker]
- k의 개수를 바꿔가며 실험, k가 클수록 reranker 성능이 높아짐
[The Number of Passages Used for Inference]
-
inference에 사용하는 passage의 수를 바꿔가며 실험
-
BM25는 k가 커질수록 성능이 하락함 → 관련 있는 passage의 수가 느는게 중요!
[Qulitative Analysis]
- knowledge augmentaiton없는 모델을 그럴듯하지만 틀린 답변을 생성

Discussion
[Comparision to Retrieval-augmented Generation]
-
KARD와 RAG의 차이는 RAG에선 query로 question을 쓰고, retriever와 generator를 같이 학습한다는 것
-
reasoning distillation에 RAG를 한 모델을 시험
-
trainable retriever로 DPR사용
-
KARD가 훨씬 높은 성능..
- 그러면 오히려 retriever학습이 망한건가..? 정확한 차이를 모르겠음
[Failure Case Analysis]
-
failure case를 분류해봤을 때 1) reranker가 잘못된 경우(관련 있는 passage가 뽑히지 않음) 2) small model이 잘못한 경우(관련 있는 passage가 있으나 답을 생성하지 못함) 2가지 경우였음
-
30개를 조사해봤을 때 1)에 해당하는 데이터가 15개, 2)에 해당하는 데이터가 15개였음
Conclusion
-
knowledge-intensive task에서 단순히 reasoning distillation을 하는것 만으로는 성능 향상에 한계가 있음을 지적
-
knolwedge augmentation의 필요성을 이론적으로 증명하고, 이에 해당하는 새로운 knowledge-augmented reasoning distillation방법론을 제안
-
실험 결과, 기존의 distillation, RAG, FT방식보다 높은 성능을 보임