KNOWLEDGE CARD: FILLING LLMS’ KNOWLEDGE GAPS WITH PLUG-IN SPECIALIZED LANGUAGE MODELS
논문 정보
- Date: 2024-02-20
- Reviewer: 전민진
Abstract
-
LLM은 static general-purpose model로, 재학습하거나 자주 업데이트하기 어려움
- 이러한 구조는, knowledge-intensive task에서 factual, relevant, up-to-date knowledge를 생성하기 어려움
-
이를 위해, Knowledge card, general-purse LLM에 새로운, 관련된 지식을 plug-in할 수 있는 modular framework를 제안
-
domain-specific LM을 지칭
-
specific domain LM에서 document들을 생성, 3가지 content selector를 통해 최종 generate에 사용된 document를 선택
- relevance, factuality, brevity
-
specific LM에서 얻은 (relevant, factual) knowledge를 LLM에 합치는 2가지 framework 방법론을 제안
- bottom-up, top-down
-
-
실험 결과, 6가지 데이터셋에서 SOTA 달성
Introduction
-
LLM은 knowledge-intensive task와 context에서 어려움을 겪고 있음
- hallucination, struggle to encode long-tail facts, update with new and emerging knowledge
-
이를 해결하기 위한 방법으로, retrieval augmentation, generated knowledge prompting이 제안됨
-
retrieval augmentation의 경우 retrieval system을 활용해 fixed retrieval corpus에서 관련 문서를 끌어와 이를 기반으로 답변을 생성하도록 하는 방법론
-
(민진피셜) 하지만 이 방법론 역시 기존의 정보를 업데이트하긴 어려움.
- 전체 corpus를 다시 구축해야함. 예를 들어, 현재 대통령에 관련한 문서가 있다면, 기존의 문제를 삭제해야 정보의 일관성이 유지됨. ⇒ 단순히 document를 추가하는 것으로 업데이트할 수 없음.
-
또한, 하나의 corpus를 가정하기 때문에 도메인별로 취사 선택해서 정보를 얻기는 어려울거 같음(domain이 여러개가 필요할 때) → 가능할지도? 근데 모델 다시 파야할거같음
-
기존과 다른 domain의 document를 추가하기 위해선 retrieval 학습 필요, 추가적으로 generator도 학습 필요할 수 있음
-
-
generated knowledge prompting은 prompt를 통해 필요한 정보를 LLM으로 생성, 이를 기반으로 답변을 생성하도록 하는 방법론
-
(민진피셜)새로운 정보를 업데이트하기 어려움.
-
또한, private information을 LLM 학습에 사용할 수 없으므로, custom하기도 어려움.
-
일부분의 domain만 업데이트하고 싶어도, 전체 파라미터를 건드려야하기 때문에 catastrophic forgetting문제 발생할 수 있음
-
-
-
하지만 이러한 방법론들은 knowledge의 2가지 특성을 반영하기 어려움
-
modular
-
knowledge는 여러 form, domain, source, perspective에서 존재하는 정보를 합친 것
-
modularity가 부족할 경우, 새로운 domain, targeted update의 일반화를 어렵게 함
-
-
collaborative
- 다양한 주체로부터 collaborative contribution이 가능하게 하면서, LLM이 다양한 측면에서의 정보를 통합하고, 표현할 수 있어야 함
-
retrieval augmentation의 경우 modular를 위해 확장될 수 있으나, 현재의 model sharing환경과 호환되지 않고, commuunity-driven effort를 용이하게 하지 않음
-
⇒ plug and play할 수 있는 knowledge card가 필요
Related works
-
Retrieval-Augmented Language Models
-
retrieval system을 encoder-decoder(FiD), decoder-only model(RAG)에 결합하는 방식
-
혹은, frozen LLM과 trainable retirever(REPLUG) or search engine을 결합
-
이러한 방식과 비교했을 때, Knowledge card는 유연한 information seeking, knowledge domain에 대한 검색, private knowledge source를 사용하는 것이 가능
-
또한, Retrieval-augmented방식은 하나의 retrieval corpus를 사용, 해당 corpus가 완전하다고 가정
- 하지만 domain coverage, knowldge update와 같은 문제 존재
-
-
Generated Knowledge Prompting
-
LLM에 prompt를 통해 background information을 생성, 이를 바탕으로 질문에 대한 답변 생성
-
LLM 파라미터에 내재된 지식으로 충분하다 가정
- hallucination, struggle to long-tail fact encoding과 같은 문제 존재
-
최근엔 LLM knowledge를 edit, update하는 방법론도 제안되고 있으나, 이는 white-box LLM을 가정, black-box LLM을 사용할 수 없음
-
-
Modular Language Models
-
Mixture-of-Expers(MoE)는 input instance를 기반으로 하나의 expert network를 활성화
-
이외 Adapter, parameter-efficient funing, parameter averagein, model fusion 등 LLM의 학습 가능성을 보여줌
-
하지만, 이러한 방법론은 LLM이 white-box임을 가정
-
Proposed Method
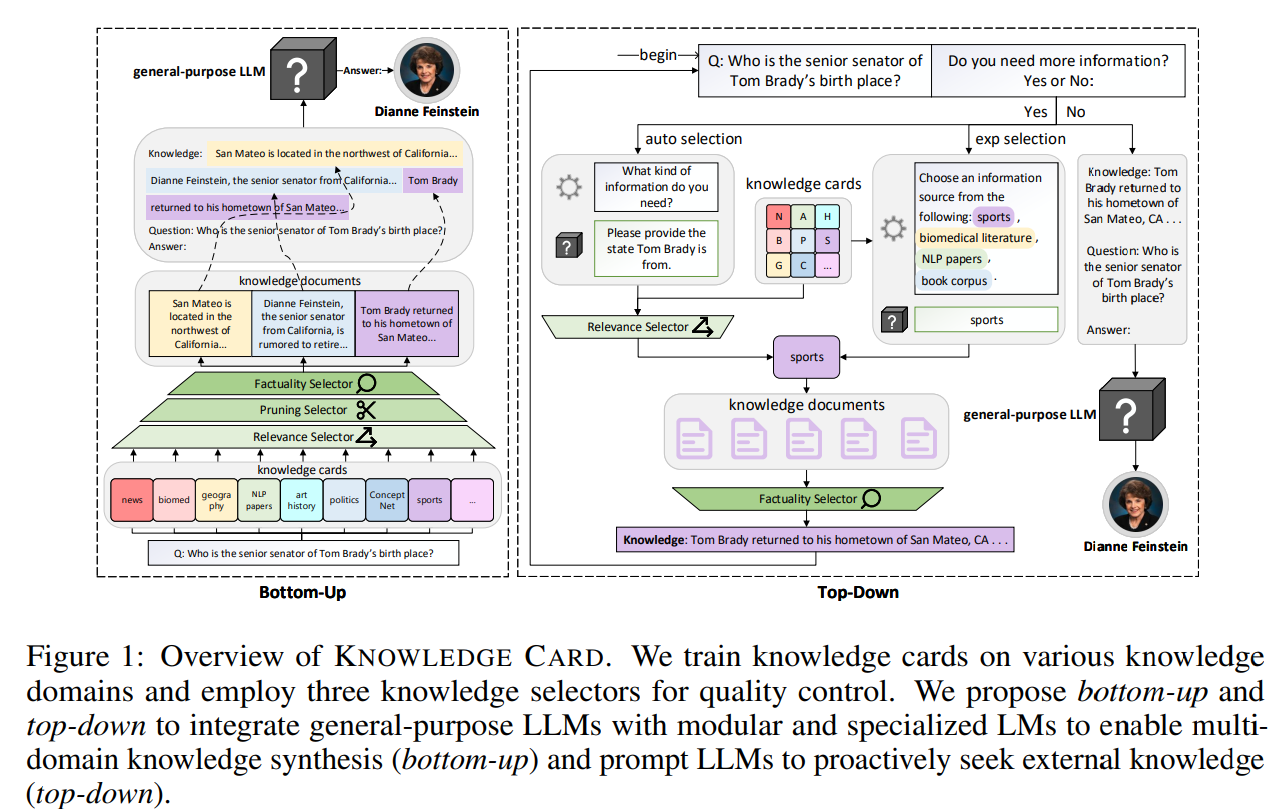
-
Knowledge cards
-
knowledge는 modular이기 때문에, 범용 LLM이 해당modular plug-and-play knowledge repositories를 사용해야한다 가정
-
knowledge repositories는 구성원이 같이 추가, 삭제, 편집, 업데이트 가능
-
knowledge component로 wikipedia factoids, biomedical literature, mathematical formulate, commonsense knowledge graph 등등 활용가능
-
-
이를 위해, black-box LLM보다 훨씬 작은 specilaized LM을 knowledge card로 활용
- 각각의 specific knowledge corpus에 autoregressive objective로 학습된 모델
-
LLM에 query가 주어질 때, 이러한 knowledge cards을 선택적으로 활성화, document를 생성
-
given query q, specialized LM c defines a mapping c(q): q \rightarrow d_q, where q is used as prompt to generate a continuation as the knowledge d_q
-
d_q are prepended into the context of peneral-purpose LLMs through various mechanism
-
-
-
Knowledge selectors
-
d_q를 바로 쓰지 않고, relevance, brevity, factuality에 따라 일종의 필터링 과정을 거침
-
Relevance Selector
-
specialized LM으로 생성한 document가 query와 적합한지 판단하는 단계
-
given a set of m generated documents {d_1,…,d_m} and the query q, we adopt a seperate encoder-based LM enc(.) that maps a token sequence to a feature vector and cosine similarity sim(.,.) to measure relevance
-
we retrain d_i if i \in topk_j(sim(enc(d_j),enc(q))) where topk is top-k argmax operation
-
-
Pruning Selecetor
-
생성한 document를 요약해 압축시키는 단계
-
given m documenets {d_1,…,d_m}, we adopt a pruning model prune(.), operationalized most simply as a summarization system to obtain the condensed versions separately {\tilde d_1,…,\tilde d_m}
-
-
Factuality Selector
-
요약한 문서가 기존 문서의 내용을 잘 담고 있는지, 생성된 문서가 factual한지 확인하는 단계
-
summarization factuality
-
pruned version \tilde d_i가 original d_i의 중요한 포인트를 잘 포착하고 있는지 확인
-
scoring fucntion(sum-fact(.,.))으로 기존에 제안된 factuality evaluation model을 사용
-
s_d^{sum} = sum-fact(\tilde d d) \in [0,1]
-
-
retrieval-augmented fact checking
-
knowledge document d가 주어질 때, retrieval corpus( e.g., wiki)에서 k개의 document를 retriever, fact-checking model을 scoring function으로 활용
-
sd^{fact}=max{1 \leq i \leq k}fact-check(d t_i) \in [0,1]
-
-
이후 2가지 factuality점수를 평균냄
-
factuality score를 기준으로 top-k factulity sampling을 사용
- top-k개로 구성된 knowledge document set에서 l개를 샘플링(k>l)
-
-
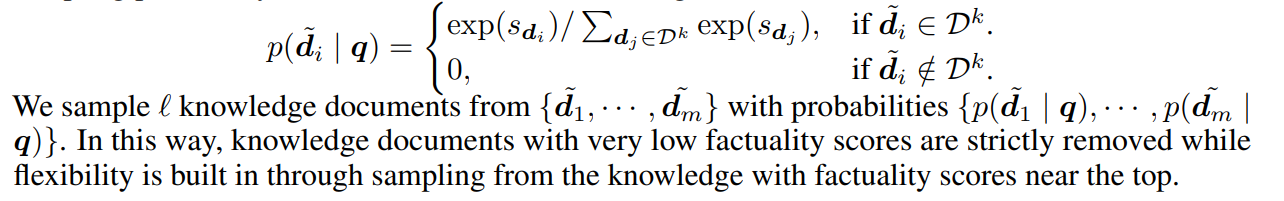
-
Knowledge intergration
-
Bottom-up
-
모든 knowledge card에서 documents를 생성, 3가지 selector를 거쳐 최종적으로 생성에 활용될 document를 추림
-
n개의 knowledge card C={c1, …, c_n}, query q가 있을 때, 각각의 knowledge card로부터 n_1개의 document를 생성, {d_1,…,d{n \times n_1}}를 얻음
-
relevance selector를 사용해 n2개의 relevant document를 선택, pruning selector로 pruning 실행, {\tilde d_1, …, \tilde d{n_{2}} }를 얻음
-
factuality selector로 high-quality knowledge document {\tilde d1, …,\tilde d{n_{3}}}을 최종 선택
-
마지막으로, “[”Knowledge:” \tilde d_1 … \tilde d_{n_{3}} q]”를 prompt로 LLM에 넣어줌 -
은 concatenation을 의미
-
- bottom-up은 다양한 도메인에서 document를 생성하므로, multi-domain knowledge synthesis에 강한 방법론
-
-
Top-down
-
textual description of specialized LMs S = {s_1,..,s_n} such as “biomedical literature”,”college calcculus”..
-
bottom-up과 달리, LLM에게 query를 바탕으로 external information이 필요한지를 먼저 물음(”Do you need more information? (Yes or No)”)
-
모델의 답변이 yes인 경우
-
아래 두 가지 방법 중 하나를 선택해 knowledge card선택
-
automatic selection
-
“What kind of information do you need?
-
relevance selector로 모델의 답변과 specialized LM textaul decription s와 비교
-
유사도가 가장 높은 knowledge card에서 document생성
-
factuality selector를 거쳐 가장 factuality score가 높은 문서를 선택
-
-
explict selection
-
“Choose an information source from the following: s1, . . . , sn”
-
LLM이 특정 knowledge card를 선택
-
다음 과정은 automatic selection과 동일
-
-
-
이 과정을 반복, external information이 필요하지 않다고 할 때까지 생성된 document를 기반으로 답변 생성
-
-
Experiment Settings
-
Implementation
-
knowledge card로 OPT-1.3B사용, 25개의 specialized LM을 각각 학습
- corpora in the Pile, branch-train-merge, knowledge graphs, news and social media 등을 활용
-
relevance selector : MPNet
-
pruning selector의 summarization model : PEGASUS
-
factuality selector의 retrieval system : WikiSearch API
-
summarization and fact-checking factuality scoring fucntion : FactKB와 VitaminC
-
black-box LLM으로는 Codex(CODE-DAVINCI-002)를 사용
-
-
Tasks and Datasetss
-
General-purpose QA
-
MMLU : multiple-choice QA dataset covering 57 tasks in humanities, STEM, social sciences…
-
5-shot in-context learning setting
-
-
multi-domain knowledge synthesis
-
LUN misinformation detection dataset with 2-way and 4-way
-
16-shot in-context learning setting
-
-
temporal knowledge update
-
MIDTERMQA : 2022 U.S. midterm elections
- 대부분의 black box 모델의 데이터는 최대 2021년도까지라, knowledge update능력을 확인할 수 있음
-
open-book(단답식), 2-way, 4-way
-
5-shot in-context learning setting
-
-
** 다른 temporal QA datset는 특정 사건이나 knowledge domain에 초점을 둔게 아니므로 평가 데이터셋으로 사용하지 않음
-
Baselines
-
vanilla black-box LLMs : Codex, PaLM, Flan-PaLM
-
generated knowledge prompting approaches : GKP, recitation, GRTR → LLM으로 같은 codex를 활용
-
retrieval-augemented language models : Atlas, RePlug, RePlus LSR
-
Results
-
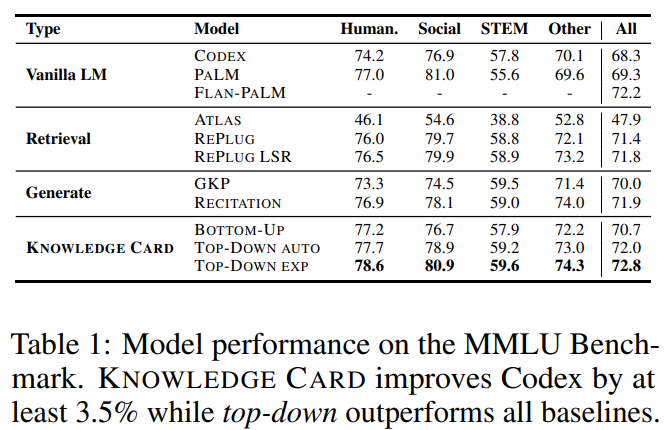
MMLU
-
다른 방식에 비해 Knowledge card가 높은 성능을 보임
- 특히 top-down방식이 bottom-up보다 높은 이유는 MMLU에서 external knowledge가 필요 없는 문제(e.g. math)들이 존재하기 때문이라 주장
-
특히, PALM모델의 경우 540B임에도 불구하고 Knowledge card(175B)보다 성능이 낮음
-
-
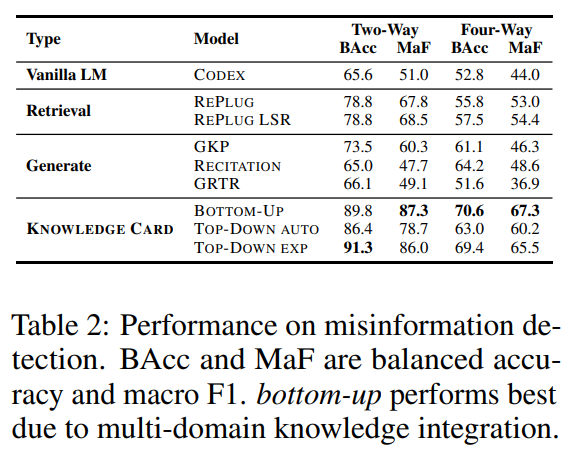
Misinformation Detection
-
MMLU와 달리, bottom-up이 더 높은 성능을 보임
-
저자들은, 해당 태스크에선 여러 domain의 정보를 통합하여 답을 내는 것이 중요하기 때문이라 주장
-
여러 도메인을 활용해야하는 상황에서는 knowledge card의 성능이 확실히 우세
-
-
-
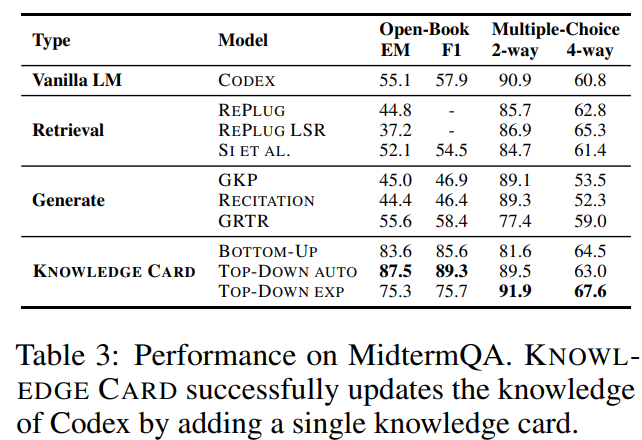
MidtermQA
-
2022 U.S midterm에 관한 news articles를 추가 knowledge card로 학습, 전체 프레임워크에 plug-in
-
특히 같은 midterm election news를 retrieval corpora로 사용하는 SI et al(codex+contriver)보다 성능이 우세
-
generated knowledgte prompting approches는 vailla Codex보다 성능이 대체로 낮음
- 내부 LLM knowledge가 outdated되거나 틀렸을 경우, LLM에서 prompting해서 knowledge를 생성하는 것이 비효율적임
-
-
Patching LLM Knowledge
-
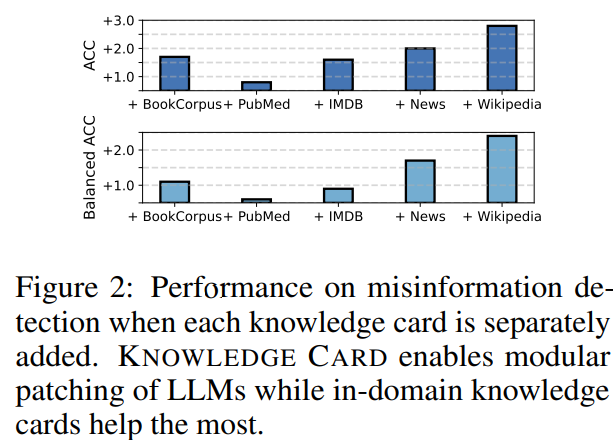
knowledge card를 추가할 때 마다, 성능 증가 폭을 보여줌(top-down 방식 사용)
-
풀고자 하는 task 기준 in-domain인 knoweldge card(News, wikipedia)를 추가했을 때가 가장 성능이 크게 향상됨
-
-
Knowledge Selctor Study
-
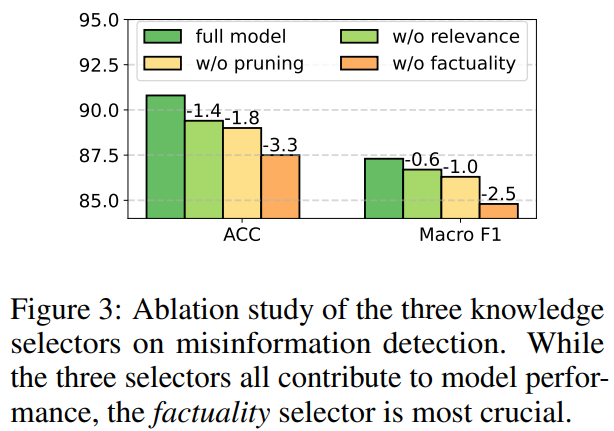
selector에 따른 성능 변화 보여줌
-
factuality selector가 성능에 가장 큰 영향을 끼침
-
-
Retireval vs Specialized LMs
-
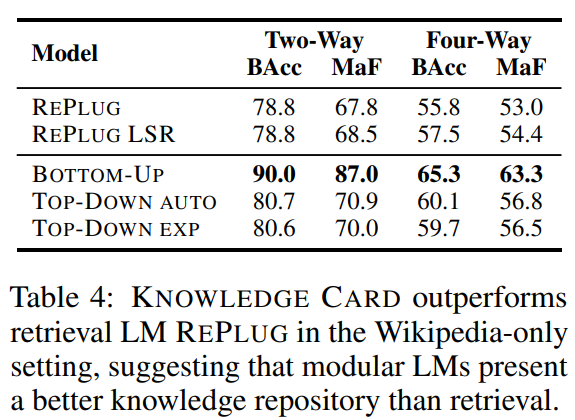
둘다 Wikipedia만 활용해 misinformation detection 성능 측정
-
Knowledge card의 성능이 우세한 것으로 보아, knowledge card가 더 나은 repository임을 주장
-
-
Knowledge Stream Analysis
-
n1 : 각각의 specialized LM에서 생성하는 document개수
-
n2 : 3가지 selector이후 남은 document 개수
-
n3 : LLM의 input으로 들어가는 document 개수
-
맨 왼쪽의 경우 어차피 같은 LM에서 생성되기 때문에 document에 큰 차이가 없어 n1이 커져도 성능 변화가 별로 없음
-
가운데 장표의 경우, n2가 커지면 커질수록 non relevance, non factual한 정보가 들어오기 때문에 성능에 해가 됨
-
맨 오른쪽 장표의 경우, n3를 어느정도 크게 해야 multi-domain의 이점이 생김
-
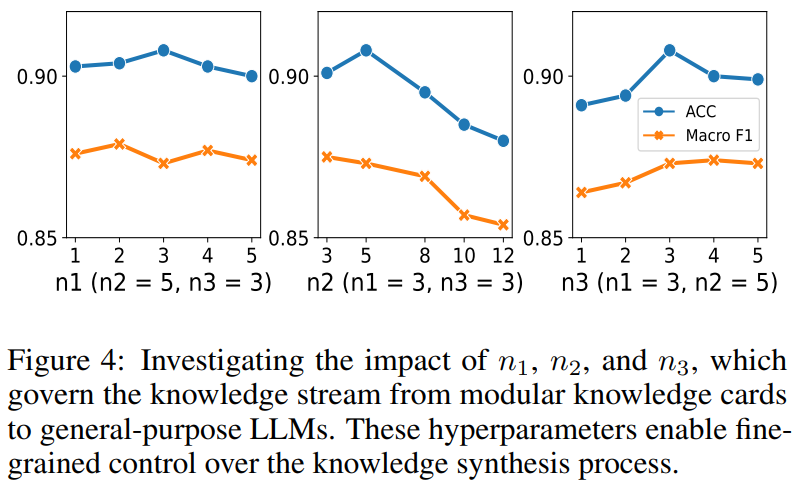
-
LLM Compatibility
- CODEX외의 다른 LLM(TEXT-DAVINCI-003, GPT-3.5-TURBO)를 사용했을 때의 성능
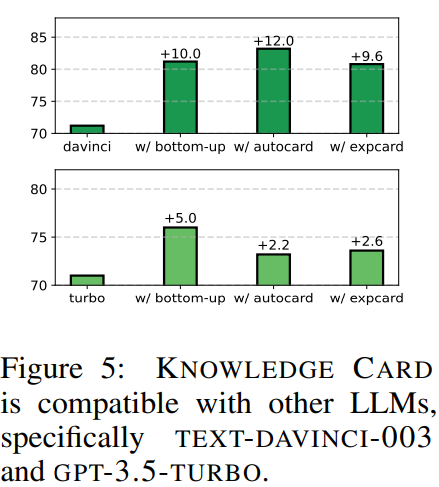
-
Yes/No in Top-Down
-
모델이 external information이 여부 선택에 따른 실제 incorrect, correct 수
-
no - incorrect : LLM이 자신의 knowledge를 과신하는 경우
-
yes - incorrect : specialized LM에서 좋은 document를 생성하지 못했을 경우
-

Conclusion
-
knowledge를 모듈화, LLM에 plug-in해 knowledge intensive task를 푸는 프레임워크 knowledge card를 제안
-
기존의 방법론 보다 성능이 뛰어나고, 정보 업데이트 및 특정 도메인 정보 추가가 용이하다는 강점을 지님
- 확실히 모델 파라미터를 바탕으로 그때 그때 필요한 document를 생성하기 때문에 RAG방식보다 정보를 유연하게 얻을 수 있다는 것도 강점
-
단점은 프레임워크를 구성하는 세부 모델이 너무 많음
- fact checking model, summarization model, seperate encoder, specialized-LM, black box LLM 등
-
얻는 성능 대비 cost가 너무 큼
-
상용화하긴 어렵지만, 그동안 factuality를 위해 진행되어 온 모든 모델을 잘 조합해서 성능이 높은 프레임워크?를 선보인 느낌
-
강점이 확실히 크긴 해서, 이렇게 필요한 정보만 업데이트할 수 있는 방식의 무언가..가 있으면 좋을거 같음.. 시도는 좋았다!