Knowledge conflict survey
논문 정보
- Date: 2024-08-13
- Reviewer: yukyung lee
1. Introduction
Definition of Knowledge Conflict
-
In-depth analysis of knowledge conflicts for LLM
- blending contextual and parametric knowledge
-
Three types of knowledge conflicts
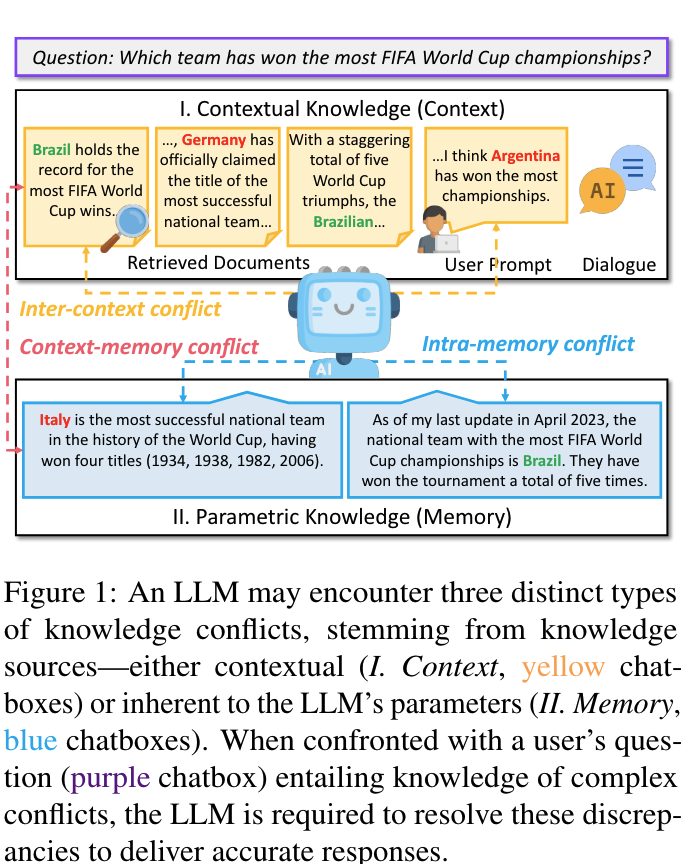
-
Context-memory (CM) : Context ↔ Parametric memory
-
Inter-context (IC): external document간에 일어나는 conflict
-
Intra-memory (IM): 모델 내부의 memory들끼리 conflict (원인→다양한 pre-trained dataset)
-
knowledge conflict가 일어나는 상황을 noise나 misinformation이 있는 상황에서 parametric knowledge와의 충돌로 보고있는듯 (abstract)
-
이 논문의 궁극적인 목표는 conflict를 해결해서 LLM의 robustness를 향상시키는 것으로 보임
Key terms
-
Parametric knowledge (memory): LM’s world knowledge
-
External contextual knowledge (context): user prompt, dialogues, retrieved documents
-
knowledge conflict: The discrepancies among the contexts and the model’s parametric knowledge are referred to as knowledge conflicts
- Knowledge Conflict (Causes - Phenomenon- Behaviors)
-
lifecycle of knowledge conflicts as both a cause leading to various behaviors, and an effect emerges from the intricate nature of knowledge
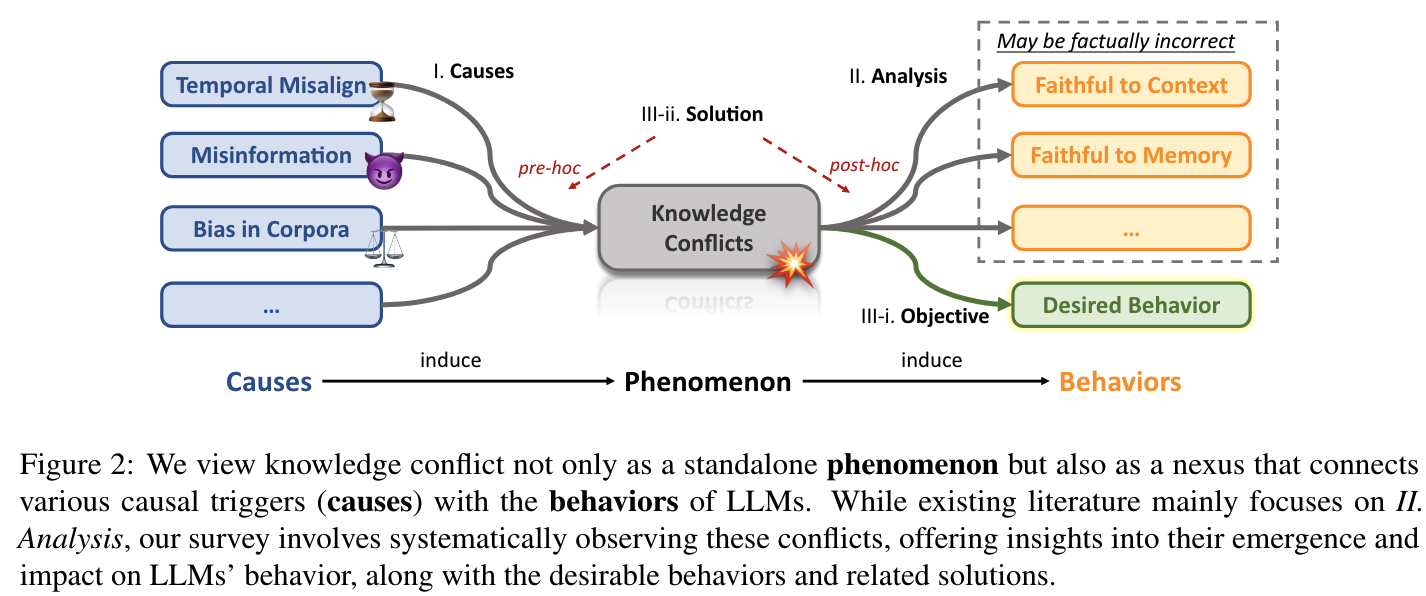
-
Knowledge conflict is originally rooted in ODQA (answer→ short / yellow)
-
전반적으로 external knowledge가 잘못된 지식인 경우에 문제가 발생할 수 있다는 이야기를 하고 있음
-
resolving knowledge conflicts;
-
-
Timing relative to potential conflicts: pre-hoc, post-hoc strategies
Taxonomy
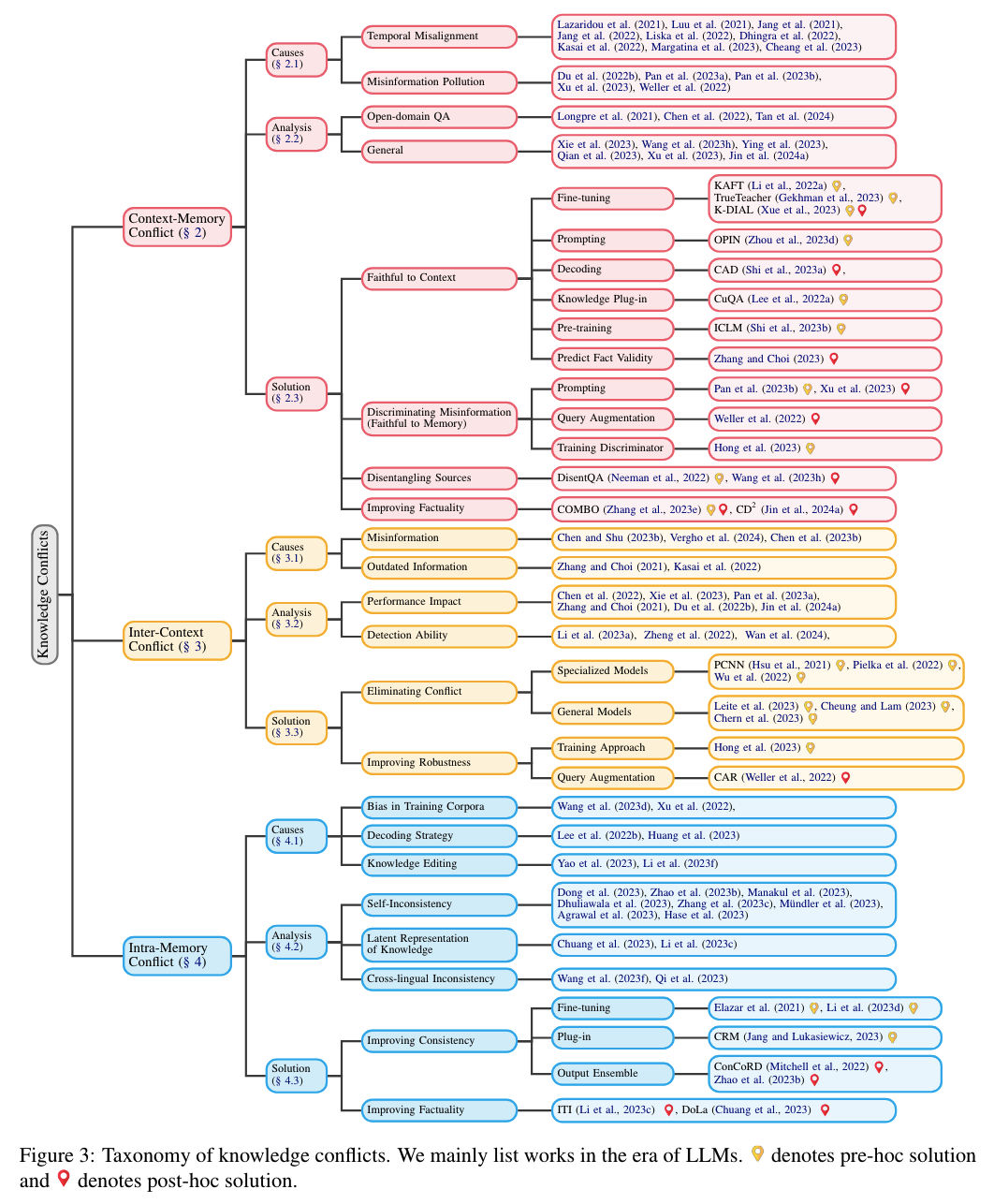
Related Dataset

2. Context-Memory Conflict
This static parametric knowledge stands in stark contrast to the dynamic nature of external information, which evolves at a rapid pace (De Cao et al., 2021; Kasai et al., 2022)
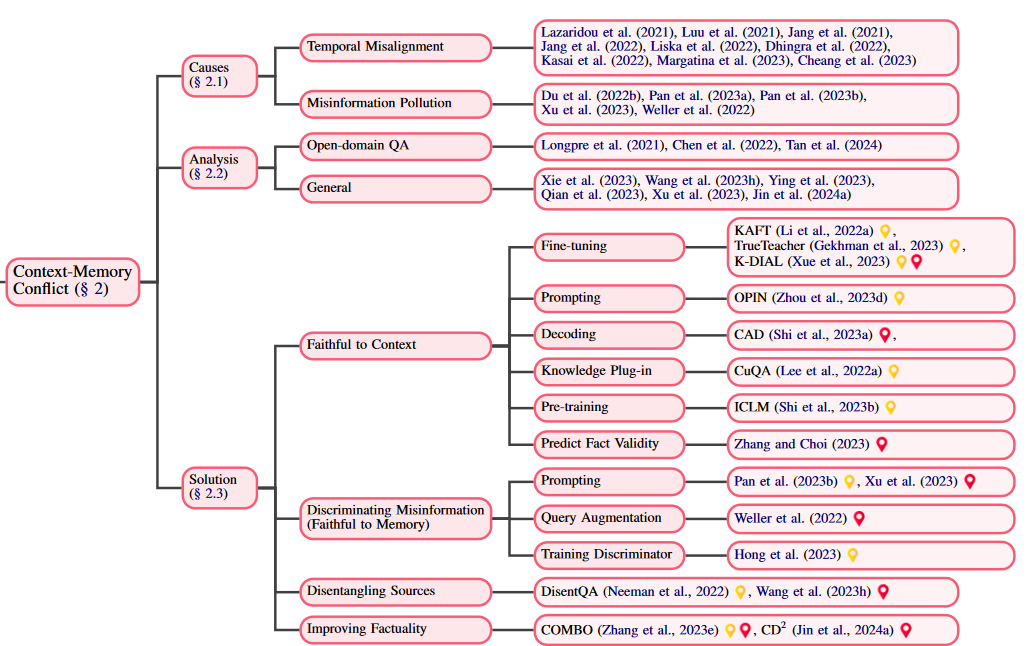
-
Causes: Why do context-memory conflicts happen?
-
Temporal Misalignment: trained on past data (shifts in language use, cultural changes, updates in knowledge) → up-to-date contextual information accurate (Faithful to Context 방법이 더 적합)
-
Knowledge Editing (KE): directly update the parametric knowledge of an existing pre-trained model
-
Retrieval Augmented Generation (RAG): leverages a retrieval module to fetch relevant documents from external sources (e.g., database, the Web) to supplement the model’s knowledge without altering its parameters
-
-
For RAG, it is inevitable to encounter knowledge conflicts since the model’s parameters are not updated (Chen et al., 2021; Zhang and Choi, 2021)
- Continue learning: update the internal knowledge through continual pre-training on new and updated data
- Misinformation Pollution: false or misleading information (particularly for time-invariant knowledge) → contextual information considered incorrect (Faithful to Memory 방법이 더 적합)
This vulnerability poses a real threat, as models might unknowingly propagate misinformation if they incorporate deceptive inputs without scrutiny (Xie et al., 2023; Pan et al., 2023b; Xu et al., 2023)
-
Analysis: How do LLMs navigate context-memory conflicts?
- Open-domain question answering (ODQA)
Longpre et al. (2021): The authors create an automated framework that identifies QA instances with named entity answers, then substitutes mentions of the entity in the gold document with an alternate entity, thus creating the conflict context. (parametric knowledge)
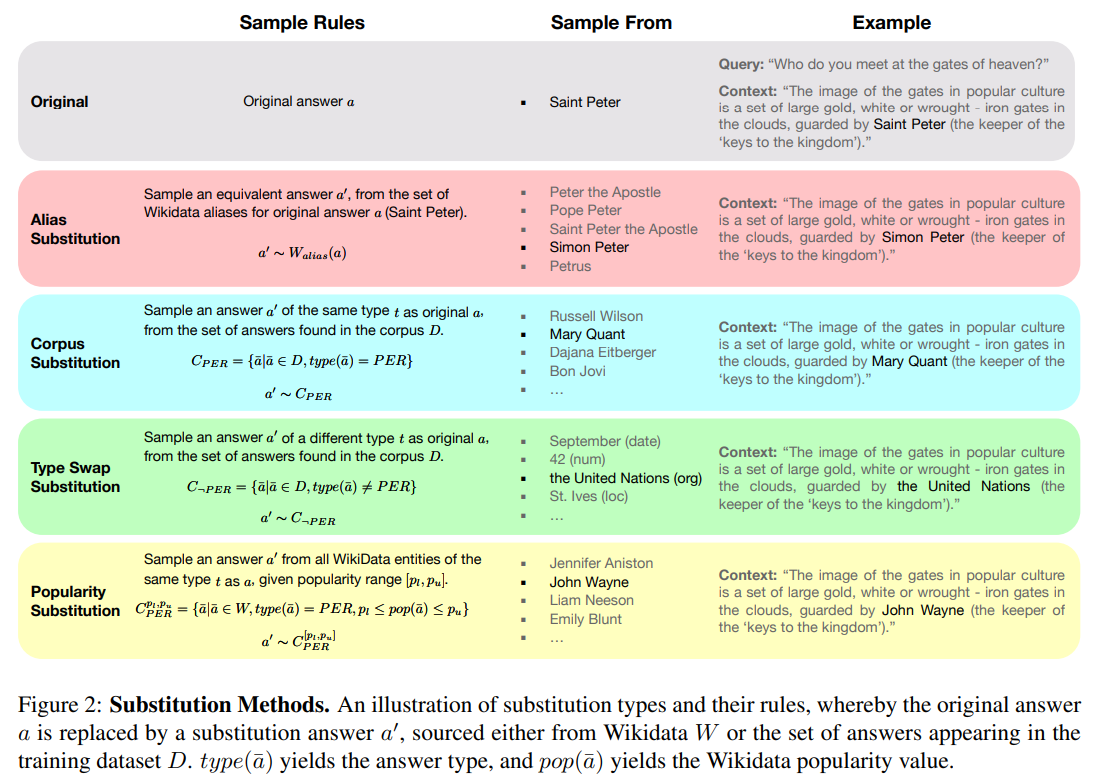
- entity substitution approach used by Longpre et al. (2021) potentially reduces the semantic coherence of the perturbed passages
- Longpre et al. (2021) based their research on single evidence passages
Chen et al. (2022): revisit this setup while reporting differing observations (contextual knowledge)
- Chen et al. (2022) utilizes multiple evidence passages
— Emergence of really Large Language Models (ChatGPT, Llama 2)—
- ***Tan et al. (2024):*** examine how LLMs blend retrieved context with generated knowledge in the ODQA setup **(parametric knowledge)**
- General QA
_Xie et al. (2023): _generate conflicting context alongside the memorized knowledge (contextual knowledge), **Meanwhile, they also identify a strong confirmation bias (Nickerson, 1998) in LLMs, i.e., the models tend to favsor information consistent with their internal memory **(parametric knowledge)
_Wang et al. (2023h): _desired behaviors when an LLM encounters conflicts should be to pinpoint the conflicts and provide distinct answers. While LLMs perform well in identifying the existence of knowledge conflicts, they struggle to determine the specific conflicting segments and produce a responsge with distinct answers amidst conflicting information.
_Ying et al. (2023): _two perspectives: factual robustness (the ability to identify correct facts from prompts or memory) and decision style (categorizing LLMs’ behavior as intuitive, dependent, or rational-based on cognitive theory) → LLMs are highly susceptible to misleading prompts, especially in the context of commonsense knowledge.
Qian et al. (2023): evaluate the potential interaction between parametric and external knowledge more systematically, cooperating knowledge graph (KG) → LLMs often deviate from their parametric knowledge when presented with direct conflicts or detailed contextual changes
Xu et al. (2023): study how LLMs respond to knowledge conflicts during interactive sessions → LLMs tend to favor logically structured knowledge, even when it contradicts factual accuracy.

Remarks
*I. Crafting Conflicting Knowledge. *Model’s behavior under context-memory conflict is analyzed by artificially creating conflicting knowledge, in early years through entity-level substitutions and more recently by employing LLMs to generate semantically coherent conflicts.
II. What is the conclusion? No definitive rule exists for whether a model prioritizes contextual or parametric knowledge. Yet, knowledge that is semantically coherent, logical, and compelling is typically favored by models over generic conflicting information.


-
Solution: _ What strategies are there to deal with context-memory conflicts_?
-
Faithful to Context: Context Prioritization
- Fine-tuning
-
_Li et al. (2022a): _Introduce Knowledge Aware FineTuning (KAFT) to strengthen the two properties (controllability and robustness) by incorporating counterfactual and irrelevant contexts into standard training datasets
_Gekhman et al., 2023): _TrueTeacher focuses on improving factual consistency in summarization by annotating model-generated summaries with LLMs
_Xue et al., (2023): _DIAL* *improves factual consistency in dialogue systems
- **Prompting**
_Zhou et al. (2023d): _specialized prompting strategies, specifically opinion-based prompts and counterfactual demonstrations
- Decoding
_Shi et al. (2023a): _Contextaware Decoding (CAD) to reduce hallucinations by amplifying the difference in output probabilities with and without context
- Knowledge Plug-in
_Lee et al. (2022a): _uses plug-and-play modules to store updated knowledge, ensuring the original model remains unaffected
- Pre-training
_Shi et al., (2023b): _extends LLMs’ ability to handle long and varied contexts across multiple documents
- Predict Fact Validity
_Zhang and Choi (2023): _introducing fact duration prediction to identify and discard outdated facts in LLMs
-
Discriminating Misinformation(Faithful to Memory): Parametric Prioritization
-
Prompting
-
Query Augmentation
-
Training Discriminator
-
-
Disentangling Sources: treat context and knowledge separately and provide disentangled answers
_Neeman et al., 2022: _DisentQA trains a model that predicts two types of answers for a given question: one based on contextual knowledge and one on parametric knowledge
_Wang et al. (2023h): _three-step process designed to help LLMs detect conflicts, accurately identify the conflicting segments, and generate distinct, informed responses based on the conflicting data
- Improving Factuality: Integrated response leveraging both context and parametric knowledge
_Zhang et al. (2023e): _COMBO uses discriminators trained on silver labels to assess passage compatibility, improving ODQA performance by leveraging both LLM-generated (parametric) and external retrieved knowledge
_Jin et al. (2024a): _CD2 maximizes the difference between various logits under knowledge conflicts and calibrates the model’s confidence in the truthful answer
Remarks
Some researchers regard that LLM should not rely solely on either parametric or contextual information but instead grant LLM users the agency to make informed decisions based on distinct answers (Wang et al., 2023h; Floridi, 2023)
3. Inter-Context Conflict
Outdated Information
-
Facts can evolve !
- Addressing conflicts that arise from documents bearing different timestamps, especially when a user’s prompt specifies a particular time period.
-
Some findings
-
knowledge source간의 inconsistency는 model의 confidence level에 거의 영향을 미치지않는다고 발견함 [1]
-
모델들은 질문과 관련된 context, model parametric knowledge와 일치하는 context를 선호 [1]
-
LLM이 모델의 parametric memory와 일치하는 evidence에 bias를 보인다고 주장 [2]
-
주어진 문맥 내에서 더 많은 문서에 의해 입증된 답변을 선호 [2]
-
데이터가 도입되는 순서에 대해 민감 [2]
-
-
References
[1] Rich knowledge sources bring complex knowledge conflicts: Recalibrating models to reflect conflicting evidence.
[2] Adaptive chameleon or stubborn sloth: Unraveling the behavior of large language models in knowledge conflicts 논문에서도 위와 같은 결과를 얻었다고 reporting
Solutions
-
Eliminating Conflict (유의미하게 참고할 것들은 없는듯)
- LLM with tool
-
Improving Robustness
- Query Augmentation (현실적이지만 novelty가 없음)
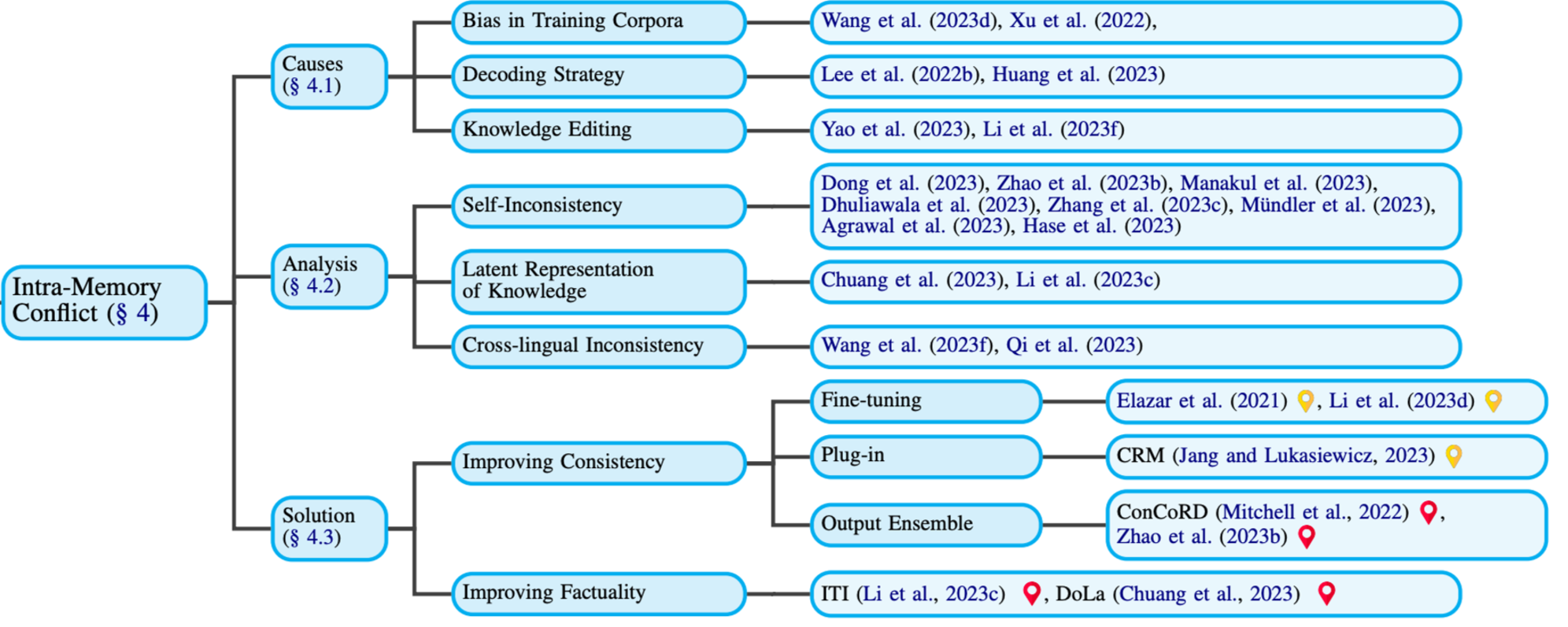
4. Intra-Memory Conflict
-
Definition: LLM의 **parametric knowledge 내부 **(latent representation)에서의 inconsistency들로 인해 발생되는 문제
-
Causes: IM이 발생하는 원인은 어떤게 있을까?
- Bias in Training Corpora
Training 과정에서 주목해야 하는 conflict 원인이다.
당연하게도 LLM이 parametric knowledge를 형성함에 pre-training 과정이 가장 많이 기여한다.
The training data 내부의 어떤 편향이나 논란의 소지가 있는 정보가 있을 때 conflict이 발생한다.
- ***examples***
Wang et al. (2023d) Parametric knowledge의 bias와 인과관계에 있는 Entity bias와 해결 방안에 대해 이야기한다.
Entity bias의 예로는 ‘빌 게이츠’라는 엔티티에 대해, ‘마이크로소프트’의 ‘visitor’(현재의 상태) 대신 ‘founder’라고 대답하는 것이다.
논문은 3가지 이런 Entity bias를 해결하기 위한 세 가지 방법을 제안한다.
- Structured Causal Model: Parameter estimation을 더 용이하게 하기 위한 방법이다.
- Training-time intervention: 내부를 확인할 수 있는 모델에 적용할 수 있는 방법으로, 학습 도중에 엔티티의 embedding을 주변 엔티티와 섞어 bias를 줄이는 방법이다.
- In-context intervention: GPT-3.5 같이 모델 내부를 확인할 수 없는 경우 활용하는 방법으로, inference 과정에서 엔티티들을 유사한 다른 엔티티로 교체해 bias를 줄이는 방법이다.
논문에서 제안하는 가능한 Future work로는 Better benchmark for comprehensive evaluation, Causal interventions (제안된 3가지 방법들) 의 응용 등을 제안했다.
Xu et al. (2023d) **해당 논문에서는 Entity typing (엔티티의 type을 결정하는 task) model과 모델 내부의 여러 상관관계들 그리고 발생하는 Bias와 해결방안**에 대해 이야기한다.
Bias의 종류
- Mention-Context Bias: 맥락(context)보다 엔티티 언급 자체에 너무 편향되는 경우
- Lexical Overlapping Bias: 엔티티를 언급하는 부분들에서의 어휘적 유사성에 의해 발생되는 편향
- Named Entity Bias: 너무 자주 언급되었던 엔티티의 경우 기존의 parametric knowledge에 너무 의존하는 편향
- Pronoun Bias: 고유명사에 비해 대명사를 사용한 inference에 더 좋은 성능을 보이는 편향
- Dependency Bias: 문맥 상 dependency 들을 잘못해석하는 경우 나타나는 편향
- Overgeneralization Bias: 많은 엔티티를 갖는 라벨쪽으로의 편향
Bias 해결방안: Counterfactual Data Augmentation
제안하는 Future work: 추가적인 bias나 debiasing technique의 발견, 더 robust한 모델 개발
- Decoding Strategy
Inference 과정에서 주목해야 하는 conflict 원인이다.
LLM의 인퍼런스의 직접적인 결과는 다음 토큰에 대한 probability distribution 으로부터 샘플링한 것이다.
최근 가장 널리 사용되고 있는 샘플링 방식은 stochastic 한데, stochastic sampling 때문에 인퍼런스 과정에서 inconsistency가 발생한다.
e.g.) 다른 사안에 대해 similarly phrased prompt를 사용 했을때, 혹은 같은 사안에 대해 다른 표현으로 질문했을 때 parametric knowledge 내에서의 충돌 발생
LLMs produce entirely different content, even when provided with the same context
- Knowledge Editing
모델의 parametric knowledge를 바꾸는 과정(e.g. fine-tuning)에서 주목해야 하는 conflict 원인이다.
파인튜닝이 코스트가 큰 만큼 최대한 작은 scope에서 parametric knowledge를 변경하는 여러 시도들이 있었다.하지만 조금씩 parametric knowledge를 수정하는 과정에서 일반화가 충분히 일어나지 않는 문제들이 발생했다.
→ 정리: Bias in Training Corpora가 IM conflict에 가장 많이 기여하고 Decoding strategy가 이를 악화시키는 것으로 나타난다. Knowledge editing을 하는 과정에서 기존 모델의 지식과 충돌이 일어나는 것은 자명하다.
-
Analysis
- Self Inconsistency
모델의 parametric model을 활용하는 과정에서 나타나는 knowledge inconsistency로 다음과 같은 경향을 가진다.
- LLM은 Uncommon knowledge에 대해 더 강하게 나타나는 경향을 보인다.
- 처음 내놓은 응답에 대해 계속 진위여부를 확인할 때 번복하는 경향을 보인다.
- 인코딩 기반의 모델들은 [가까이 있는 단어], [자주 등장하는 단어] 에 많은 영향을 받아 사실이 아닌 단어를 생성하는 경향을 보인다. → [지식의 진위여부와 관계 있는 단어]에 집중해야 하는데..!
co-occurence bias: LLM이 정답보다 바이럴을 더 선호하는 편향
- Pretraining 과정에서 함께 등장하지 않은 ‘대상’과 ‘역할’에 대해 추후에 Knowledge editing을 해줘도 잘 성능을 보이지 못하는 경향을 보인다. (예: 빌게이츠) → LLM은 Pretrain 단계에서, 즉 parametric knowledge가 형성되는 단계에서 training corpora의 단어 occurence에 취약하다.
- Latent Representation of Knowledge
LLM의 기반인 multi-layer transformer 구조는 inter-memory conflict를 유발한다.
LLM의 memory
- Shallow level memory: Low-level information
- Deeper level memory: Semantic information
- Factual information이 특정 트랜스포머 레이어에 집중돼있고, 나머지 레이어에 비슷한 내용에 대해 inconsistent하고 not reliable한 정보들이 저장되어있다.
- 올바른 정보가 latent space에 저장돼있다 한들, 그것을 불러오고 응답을 generate하는 과정에서 정확히 표현되지 않는 경우가 존재한다.
- Cross-lingual Inconsistency
언어별로 knowledge set이 달라 같은 사안에 대해 사실여부가 다르게 저장되어있다.
즉 같은 사실(semantically identical)이라도 다른 언어로 표현돼있는 knowledge의 경우, 모델 파라미터 내부에 서로 다른 영역에 저장되어있다.
-
Solutions
-
Improving Consistency
-
Fine-tuning (pre-hoc)
-
Plug-in (pre-hoc)
-
단어-뜻 piar를 통해 구성한 데이터셋으로 모델을 retrain한다
retrain한 모델의 파라미터와 기존 모델의 파라미터를 융합해 variance를 줄이는 방식
1. **Ouptut Ensemble **(post-hoc)
두개의 모델로부터 나온 output을 ensemble하는 방식
- Base model: 질문에 대한 답변 셋을 생성
- Relation model: 답변의 논리적 일관/일치성을 평가
-
Improving Factuality
-
DoLa (post-hoc)
Contrastive Decoding Approach Steps
1. Premature layer & Mature layer: 내재돼있는 parametric knowledge의 신뢰도에 따라 둘을 구분한다.
1. 모델이 다음 단어를 샘플링 할 때 확률을 premature layers와 mature layers 사이의 log probability의 차이 *(KLD, XE ..?) *를 통해 계산한 후 샘플링한다.
1. **ITI** (post-hoc)
DoLa와 유사한 방식
1. Ground truth일 가능성이 높은 모델의 영역(attention heads)을 찾아낸다. *TruthfulQA 벤치마크를 활용*
1. 모델이 답변을 생성할 때 신뢰도가 높은 정보와 높은 상관관계를 가지는 방향으로 모델의 activation들을 조정한다.
1. 답변의 모든 단어에 대해 이 과정을 반복한다.
5. Challenges and Future Directions
Knowledge Conflicts in the Wild
-
Retrieval Augmented Language Model에서 자주 일어날 수 있는 상황
- conflict : retrieved documents (from web)
Solution at a Finer Resolution
-
User query is important : subjective or debatable questions lead to conflicts
-
the source of conflicting information can vary ; mis info/ outdated facts/ partially corrected data
-
User expectation
Evaluation on Downstream Tasks
- 대부분의 연구들이 QA를 사용하는데, broder implication을 고려하여 다양한 task를 평가해봐야 한다고 주장
Interplay among the Conflicts
- internal knowledge inconsistency를 잘 잡아내는게 중요