KNOWLEDGE ENTROPY DECAY DURING LANGUAGE MODEL PRETRAINING HINDERS NEW KNOWLEDGE ACQUISITION
논문 정보
- Date: 2024-10-17
- Reviewer: hyowon Cho
- Property: Interpretability, Continual Learning
1. Intro
최근 연구들은 언어 모델이 매개변수 내에 저장된 지식을 어떻게 활용하여 응답을 생성하는지 분석해 왔으나, 모델이 사전학습(pretraining) 동안 이러한 지식을 통합하는 방식이 어떻게 변화하는지는 잘 알려져 있지 않다.
본 연구는 모델의 다양한 지식 통합 특성이 사전학습 중 어떻게 변화하며, 이러한 변화가 지속 학습(continual learning) 상황에서의 지식 습득 및 망각에 미치는 영향을 분석한다.
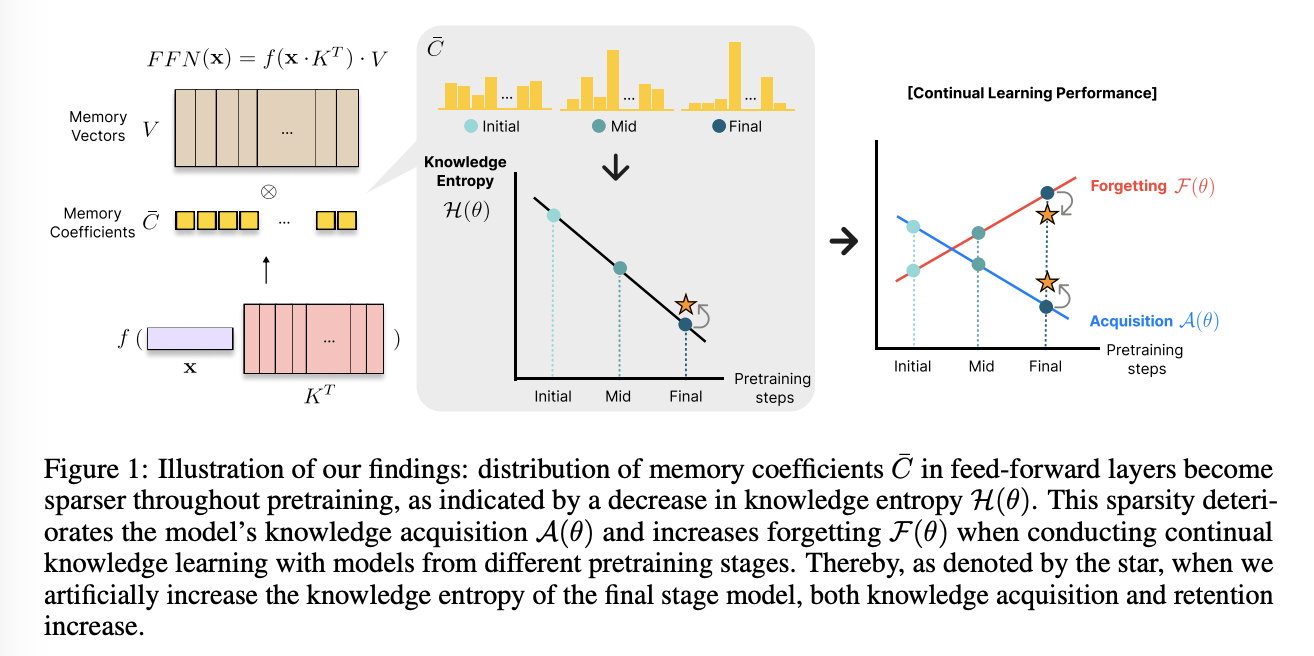
우리는 모델의 지식 통합 특성을 측정하기 위해 knowledge entropy 개념을 도입한다. 이는 모델이 메모리 벡터를 얼마나 폭넓게 통합하는지를 나타냅니다. 높은 지식 엔트로피는 폭넓은 메모리 벡터를 사용하는 것을, 낮은 엔트로피는 특정 메모리 벡터를 집중적으로 사용하는 것을 의미한다. 사전학습 단계별로 지식 엔트로피를 분석한 결과, 학습 후반부의 모델들은 낮은 지식 엔트로피를 보여, 폭넓은 메모리 벡터를 사용하던 초기와 달리 소수의 메모리 벡터에 집중하는 경향이 나타났다.
우리는 이러한 변화가 새로운 지식을 습득하는 모델의 행동에 영향을 미칠 것으로 가정하고, 다양한 사전학습 단계에서 시작한 모델들을 대상으로 새로운 도메인 코퍼스를 활용한 실험을 진행했다. 그 결과, 지식 엔트로피와 지식 습득 및 유지 능력 사이에 강한 상관관계가 있음을 확인했으며, 사전학습이 진행됨에 따라 두 요소가 감소한다는 사실을 발견했다.
우리는 이러한 양상이, 지식 엔트로피가 낮아지면 활성 메모리 벡터의 수가 줄어들어, 새로운 지식을 저장할 때 기존 메모리 벡터가 자주 덮어쓰이기 때문이라고 가정한다. 이를 테스트하기 위해, 비활성 메모리 벡터를 인위적으로 활성화하여 새로운 지식을 더 넓은 범위의 메모리 벡터에 저장하도록 유도한 실험을 수행했으며, 이를 통해 모델의 지식 습득 능력과 망각이 개선되는 결과를 얻었다.
결론적으로, 우리가 찾아낸 바는 다음과 같다:
-
사전학습이 진행될수록 모델은 메모리 벡터의 사용/통합 폭이 좁아져 지식 습득 및 유지 능력이 저하되는 것을 확인
-
초기 모델은 높은 지식 엔트로피로 인해 지식 습득 및 유지 능력이 뛰어나지만 언어 모델링 성능이 제한적이다.
-
중기 모델은 균형 잡힌 성능을 보여 새로운 지식을 추가 학습하기에 적합한 것으로 나타났다.
-
비활성 메모리 벡터를 인위적으로 활성화하여 새로운 지식을 더 넓은 범위의 메모리 벡터에 저장하도록 유도하면, 지식 습득 및 유지 능력이 향상된다.
2. Related Works
Dynamics of Knowledge in Language Models
-
언어 모델은 매개변수에 지식을 저장하고, 이를 통해 응답을 생성함 (Yang, 2024; Petroni et al., 2019; Wang et al., 2021).
-
연구 목적: 모델이 학습과 추론 과정에서 지식을 어떻게 학습하고 저장하며 사용하는지 이해.
-
주요 연구:
-
추론 과정 분석:
-
Geva et al. (2023): 언어 모델의 각 층의 역할 분석.
-
Allen-Zhu & Li (2024b): 모델 매개변수의 지식 저장 용량의 한계 제시.
-
Geva et al. (2021), Meng et al. (2022): 모델의 키-값 메모리 구조 연구.
-
-
사전학습 단계 분석:
-
Chang et al. (2024): 모델이 지식을 획득하는 과정 탐구.
-
Liu et al. (2021): 모델이 다양한 지식을 학습하는 순서 연구.
-
Sun & Dredze (2024): 사전학습과 finetuning의 상호작용 연구.
-
-
-
본 연구의 차별점: 언어 모델이 사전학습 중 지식을 통합하는 방식의 변화와 이로 인한 지속 학습 시 지식 습득 및 망각에 대한 영향 분석.
Entropy in Natural Language Processing
-
엔트로피 개념: 정보 이론에서 예측 가능한 사건은 낮은 엔트로피, 예측이 어려운 사건은 높은 엔트로피를 가짐 (Lairez, 2022; Majenz, 2018).
-
NLP에서 엔트로피의 사용:
-
Yang (2024): 입력 프롬프트 기반 모델 출력의 엔트로피 분석.
-
Araujo et al. (2022): 지속 학습 상황에서 각 층의 출력 엔트로피 계산.
-
Vazhentsev et al., Geng et al. (2024): 다음 단어 예측을 위한 토큰 확률 엔트로피 분석.
-
Kumar & Sarawagi (2019): 크로스 어텐션 층의 엔트로피로 모델의 불확실성 평가.
-
-
본 연구에서의 엔트로피:
-
Knowledge entropy: 모델의 매개변수에 저장된 지식 활용의 불확실성을 측정.
-
기존 연구들과 달리, 모델의 지식 통합 방식의 변동성을 분석하는 데 중점.
-
3. Knowledge Entropy
3.1 정의
본 연구에서는 모델의 매개변수 지식 통합 범위를 분석하기 위해 knowledge entropy라는 새로운 개념을 도입한다. 낮은 지식 엔트로피는 모델이 특정한 지식 소스에 의존하는 반면, 높은 지식 엔트로피는 다양한 지식 소스를 통합함을 의미한다.
기존 연구들이 피드포워드 레이어(FFN)를 키-값 메모리로 간주한 것에 착안해, 메모리 벡터(FFN의 두 번째 투영 행렬)를 지식 소스로 보고, 이를 통합하는 정도를 메모리 계수로 측정한다. 지식 엔트로피는 계수의 확률 분포를 이용해 계산되며, 이는 사전학습된 데이터셋을 기반으로 측정된다.
구체적인 설명은 다음과 같다:
Geva et al. (2021, Transformer feed-forward layers are key-value memories.) 은 FFNs이 ey-value neural memories (Sukhbaatar et al., 2015)와 비슷하게 동작한다는 key-value memory의 개념을 소개한 바 있다. FFNs는 두 개의 projection layer와 중간에 하나의 activation으로 구성되어 있다.
FFN(x) = f(x · K^T) · V
이때, 첫 번째 projection matrix는 key, 두 번째 projection matrix는 values, 또는 memory vector로 구성된 memories라고 볼 수 있다고 주장한다. 출력값인 FFN(x)는 메모리 벡터 v들의 linear combination이라고 할 수 있으며, coefficient는 C는 f(x · K^T)라고 볼 수 있다. 이는 다시 말해, coefficient가 memory vector를 어떻게 조합할지, 어느 정도의 중요도를 볼 지 결정한다고 볼 수 있다.
따라서, 우리의 knowledge entropy, H(θ)는 sum of layer-wise entropy로 정의하며, 이는 D라는 데이터셋의 모든 토큰들에 대한 average coefficient C¯^l를 구한 것이라고 할 수 있다.
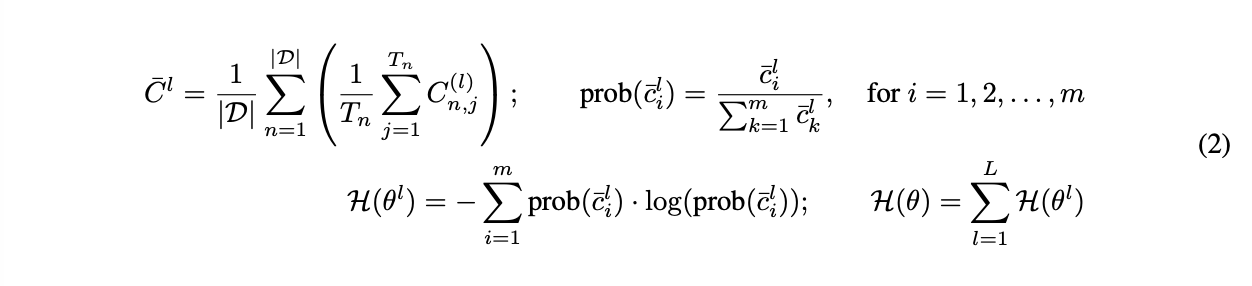
-
C^{(l)}_{n,j} = coefficient of j-th token position of n-th instance at layer l
-
c¯^l_i = i-th element from average coefficient C¯^l
-
T_n = sequence length of the n-th instance in the dataset D,
-
m is the inner dimension of feed-forward layer
-
L denotes the number of layers in the model.
3.2 실험 설정
OLMo (1B 및 7B) 모델들을 사용해 실험을 진행하며, Dolma 데이터셋을 기반으로 지식 엔트로피를 측정한다. 실험에는 Dolma의 일부 데이터(2천 개 인스턴스)를 사용해 모델의 사전학습 단계에서의 엔트로피 변화를 분석했다.
모델의 메모리 계수 (C)는 SwiGLU 활성화 함수를 사용해 계산하며, 절대값을 사용해 메모리 벡터의 기여도를 확률 분포로 변환한다.
C^{(l)}_{n,j} = abs(SwiGLU(x_j))
절대값을 사용한 이유는 linear combination을 할 때, 그것의 기여도를 알고싶었기 때문이다 (magnitude).
Please note that the trend persists across other corpora as well (Figure 6 in Appendix A.1); however, since we are analyzing the model’s behavior throughout training, we define knowledge entropy based on calculations using the training dataset.
이러한 지식 엔트로피는 dataset, activation function의 선택과 무관하게 일정한 trend를 가졌다.
- Appendix A.1.
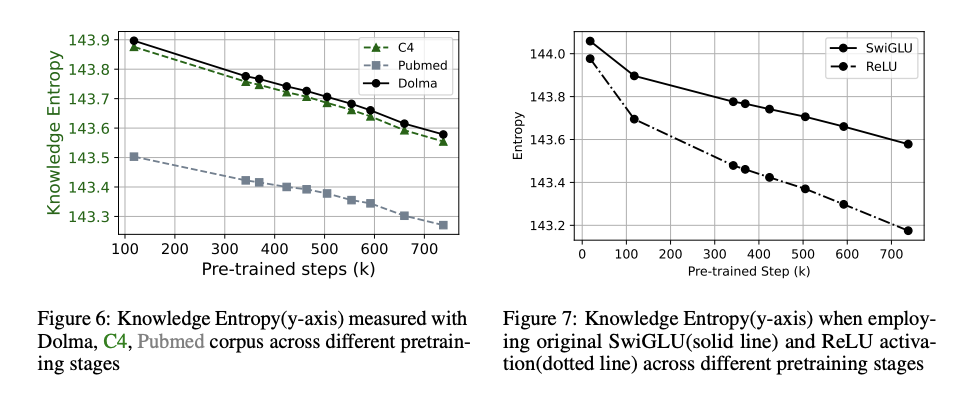
Does the choice of dataset change the trend? As expressed in Equation 2, knowledge entropy is dependent on the dataset D. We define D as the dataset used during pretraining, as knowledge entropy reflects how the model integrates the knowledge stored in its memory vectors, learned during pretraining. However, to further explore whether the choice of dataset influences the trend of knowledge entropy, we measure it using PubMed and C4. Figure 6 shows that the trend remains consistent regardless of the dataset used when calculating knowledge entropy. Does the choice of activation function change the trend? We also explored an alternative where we do not take the absolute value of the SwiGLU output. Instead, following the ReLU function (Agarap, 2018), another widely used activation function, we replaced all negative values with 0.
3.3 사전학습 후반부 모델은 낮은 지식 엔트로피를 보임
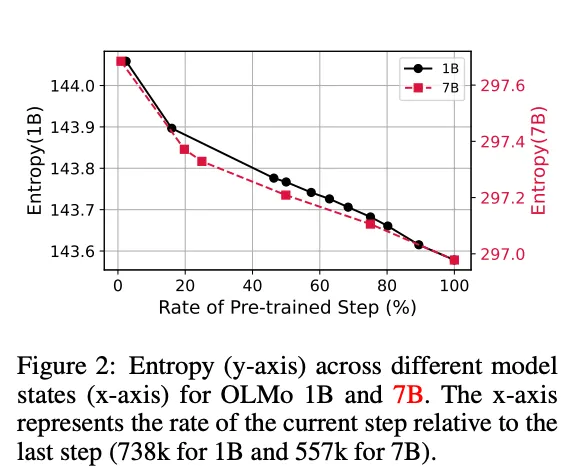
사전학습 단계별 지식 엔트로피의 변화를 분석한 결과, 사전학습이 진행될수록 지식 엔트로피가 감소함을 확인했다. 이는 모델이 학습 후반부에 특정 메모리 벡터에 더 집중하게 되며, 폭넓은 메모리 벡터를 사용하는 경향이 줄어듦을 의미한다. 이러한 감소는 대부분 레이어에서 관찰되었으며, 마지막 레이어에서 가장 뚜렷했다. (Appendix A.1)
- Appendix A.1
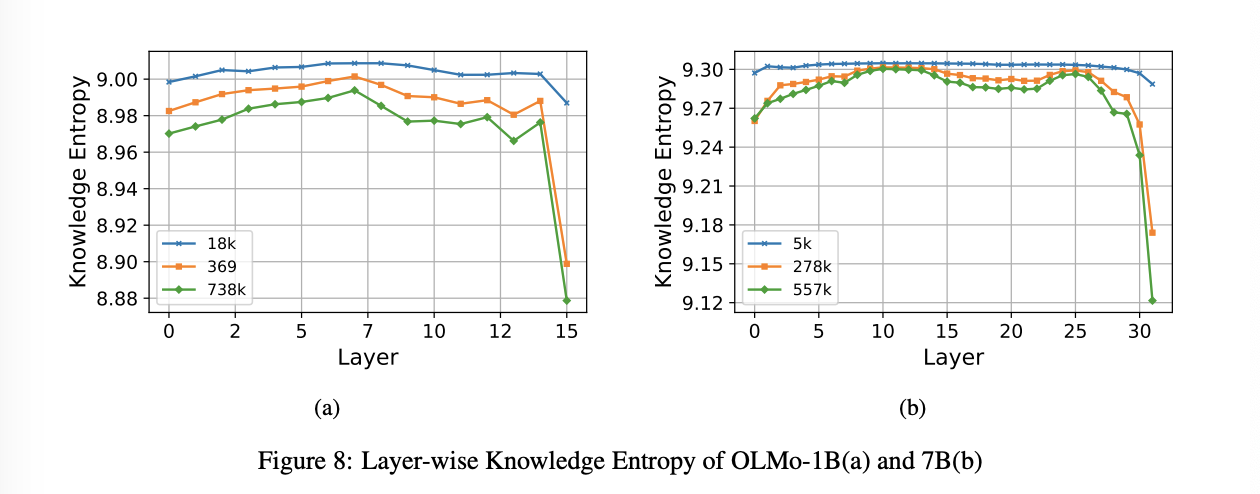
Layer-wise Knowledge Entropy Figure 8 shows how knowledge entropy changes during pretraining by layer. Knowledge entropy consistently decreases in every layer, with the most significant reduction occuring in the last layer, which closely resembles the output distribution right before the token prediction. OLMo-7B also shows similar trend with 1B model.
3.4 다른 엔트로피 정의에서도 유사한 경향이 관찰됨
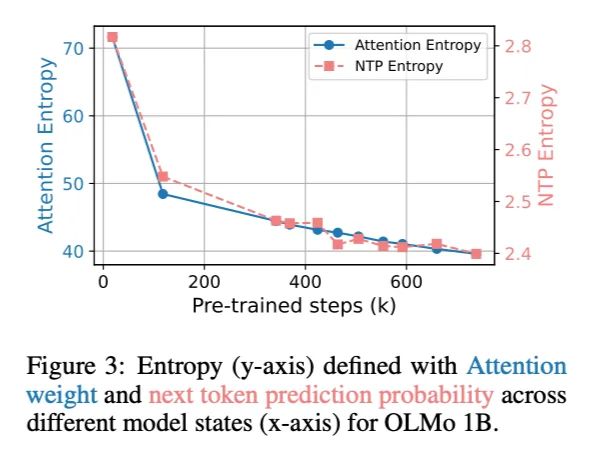
지식 엔트로피 외에도 어텐션 레이어와 Next Token Prediction의 엔트로피를 분석했다. 어텐션 엔트로피는 어텐션 가중치의 불확실성을 측정하며, 사전학습 초기 급격히 감소한 후 점진적으로 줄어드는 경향을 보였다. 이는 모델이 점차 중요한 토큰에 집중하게 됨을 시사한다. 또한, Next Token Prediction의 엔트로피는 사전학습이 진행될수록 감소하여 모델이 예측에 대해 더 확신을 가지게 됨을 나타냈다.
.
4. KNOWLEDGE ACQUISITION AND FORGETTING
4.1 실험 설정
-
모델 및 하이퍼파라미터: OLMo 모델의 사전학습 중간 체크포인트를 사용하며, continual knowledge learning 연구를 참고하여 하이퍼파라미터를 설정했다. 배치 크기, 학습률, 학습 기간 등 다양한 조합을 테스트했고, 기본 설정은 배치 크기 128, 학습률 4e-4, 1 epoch으로 설정했다.
-
데이터셋: PubMed는 새로운 지식이 많아 continual learning에 적합하다. 또한, FICTIONAL KNOWLEDGE dataset을 이용해, 모델의 새로운 정보 습득 능력을 평가한다. 학습 후에는 평가용 프롬프트를 이용해 지식 습득을 측정하고, 6개의 다운스트림 태스크를 통해 지식 망각을 평가한다.
-
Metric: 지식 습득은 주입된 지식을 얼마나 잘 불러내는지, 지곤 지식 C에 대한 각기 다른 paraphrased 혹은 연관된 probing 프롬프트 15개를 이용해 측정한다 (P). 또한, initial model에 비해서 얼마나 좋아졌는지를 A로 표기한다. 지식 망각은 사전학습 단계에서의 성능 감소로 측정한다.
4.2 지식 습득 및 유지 능력의 감소
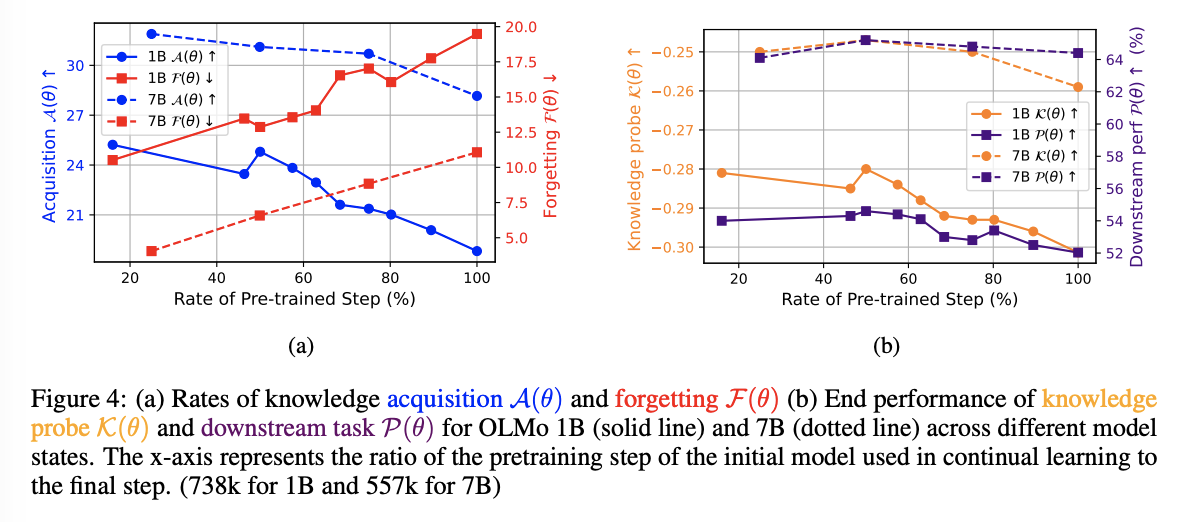
모델의 사전학습 단계별 성능을 분석한 결과, 사전학습 후반부의 모델은 새로운 지식을 습득하는 데 어려움을 겪으며, 더 많은 망각을 보였다.
사전학습 중간 단계에서 지속 학습을 시작한 모델이 지식 회상과 다운스트림 태스크 성능에서 가장 우수한 결과를 나타냈다.
초기 모델은 높은 지식 습득 능력을 보이지만, 언어 모델링 능력이 제한적이었으며, 반대로 후반부 모델은 더 큰 데이터셋으로 학습되었음에도 불구하고 낮은 지식 습득과 높은 망각 비율을 보였다.
이는 사전학습 모델이 새로운 지식을 학습하는 데 어려움을 겪는 이유를 설명하는 연구와 일치한다.
따라서 중간 단계 체크포인트를 사용하면 학습과 성능의 균형을 맞추기 위한 적절한 선택임을 제안한다.
이러한 양상은 batch size, learning rate, training corpus, and the number of epochs 등 다양한 하이퍼파라미터 세팅에서 모두 동일하였다.
- Appendix B
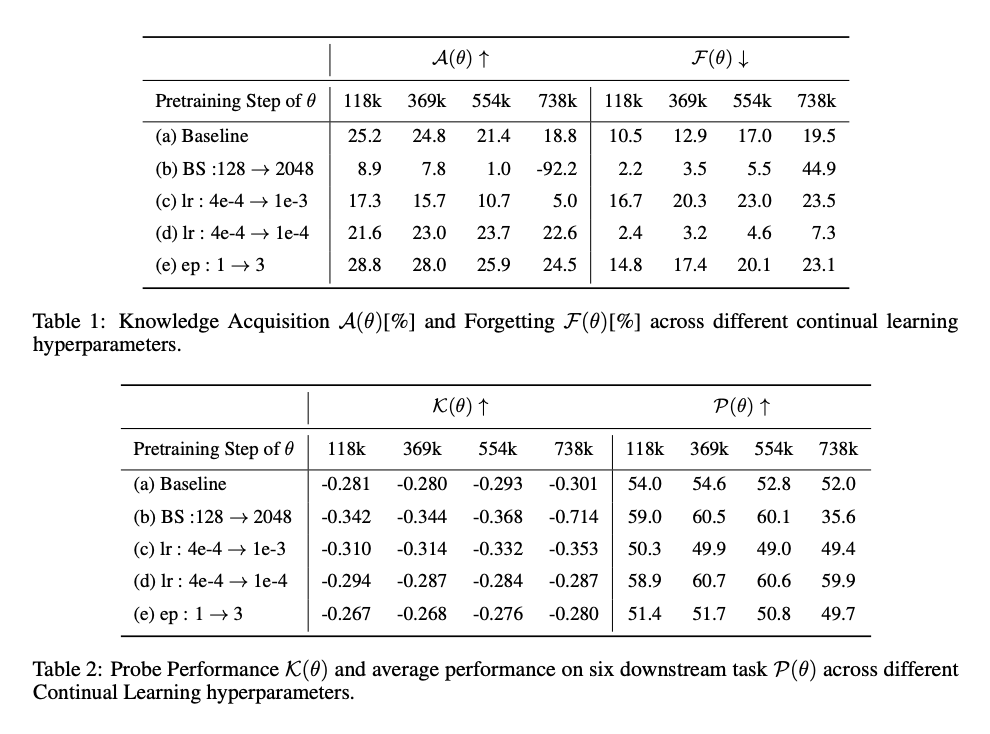
4.3 비활성화된 메모리 벡터의 활성화가 지식 습득을 증가시킴
지식 엔트로피 (Figure 2)와 모델의 지식 습득 및 유지 능력(Figure 4a) 사이에 강한 상관관계가 관찰되었다.
모델이 제한된 메모리 벡터에 의존할수록 (decrease in knowledge entropy), 모델의 추가적인 학습 과정에서 해당 벡터들만 업데이트하고, 이것이 새로운 지식 습득이 어려워지고, 망각률이 높아지는 원인이 된다는 가설을 검증하기 위해, 비활성 메모리 벡터를 인위적으로 활성화하는 실험을 수행했다.

비활성 메모리 벡터를 활성화하기 위해, 우리는 메모리 계수 C¯를 생성하는 up-projection matrix K를 수정한다. 구체적으로, Algorithm 1에 따라 가장 적게 사용되는 p%의 메모리 계수를 찾아내고, 그 부분에 특정 수치 m을 곱해준다. 이 수치는 각 레이어의 평균 계수 값을 해당 위치의 계수 값으로 나눈 후, 증폭 인수 q를 곱하는 방식이다. 이렇게 q의 값을 조정하면, 적게 활성화된 메모리 계수들이 얼마나 되살아나는지를 조절할 수 있고, 이를 통해 파라미터 업데이트의 크기를 조절하게 된다.
우리의 실험에서는 p=50, q는 변화하면서 실험을 진행한다.
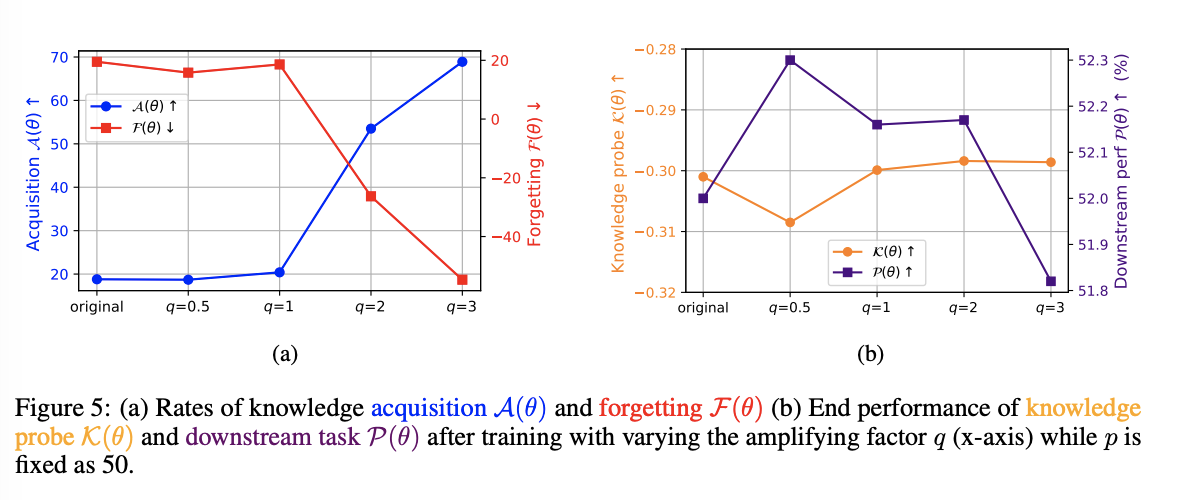
실험한 결과, 비활성 메모리 벡터를 활성화시킬수록 지식 습득 및 유지 성능이 향상되었다 (Figure 5a). 특히, q 값을 1 이상으로 설정한 경우 성능이 개선되었으나, q 값을 0.5로 설정했을 때는 성능이 저하되었다. 이는 특정 메모리 위치에 집중된 업데이트가 성능을 저하시킬 수 있음을 의미한다.
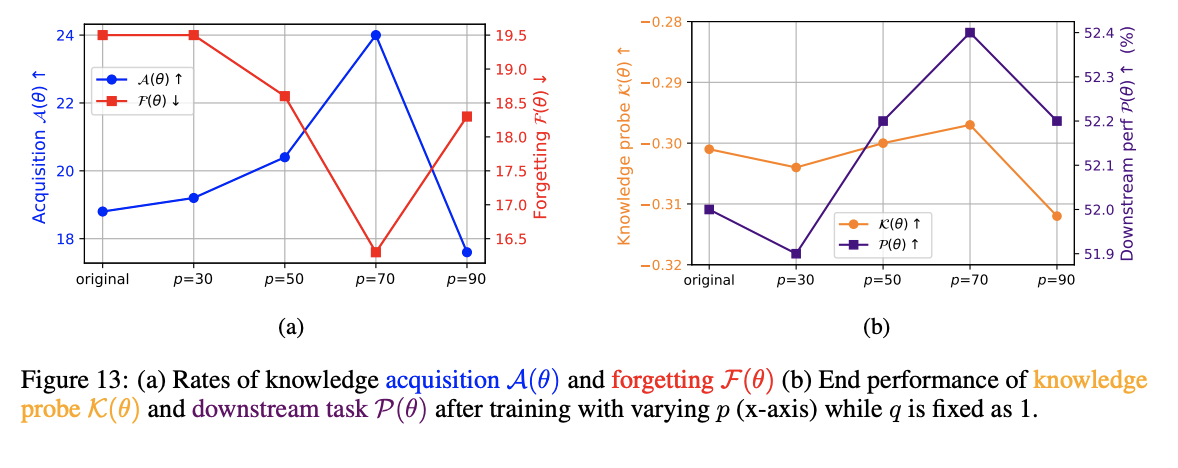
추가적으로, q 값을 고정하고, p 값을 변경해 비활성화된 매개변수의 더 큰 부분을 활성화했을 때, 일반적으로 성능이 향상되는 경향을 확인했다.
-
Appendix B.5
- q was fixed at 1
다양한 단계의 모델들을 사용했을 때, 모두 비슷한 양상을 보였지만, 학습의 후반부로 갈수록 그 효과가 더욱 두드러졌다.
-
Appendix B.6
-
Figure 14a illustrates the overall performance when q was fixed to 2 and p to 50, across different pretraining stages of the original model.
-
Figure 14b, end performance deteriorates when the beginning model is initial (118k) and mid (369k) stage model, indicating that resuscitation may impair performance when the model’s knowledge entropy is not low enough
-
This trend of the resuscitation showing a more positive effect for models in later stage of pretraining can also be seen in Figure 15, which shows the result when varying q while fixing p as 50:performance deteriorates when running continual learning on model from 369k, while improvement of performance with larger q is observed when model is from 554k
-
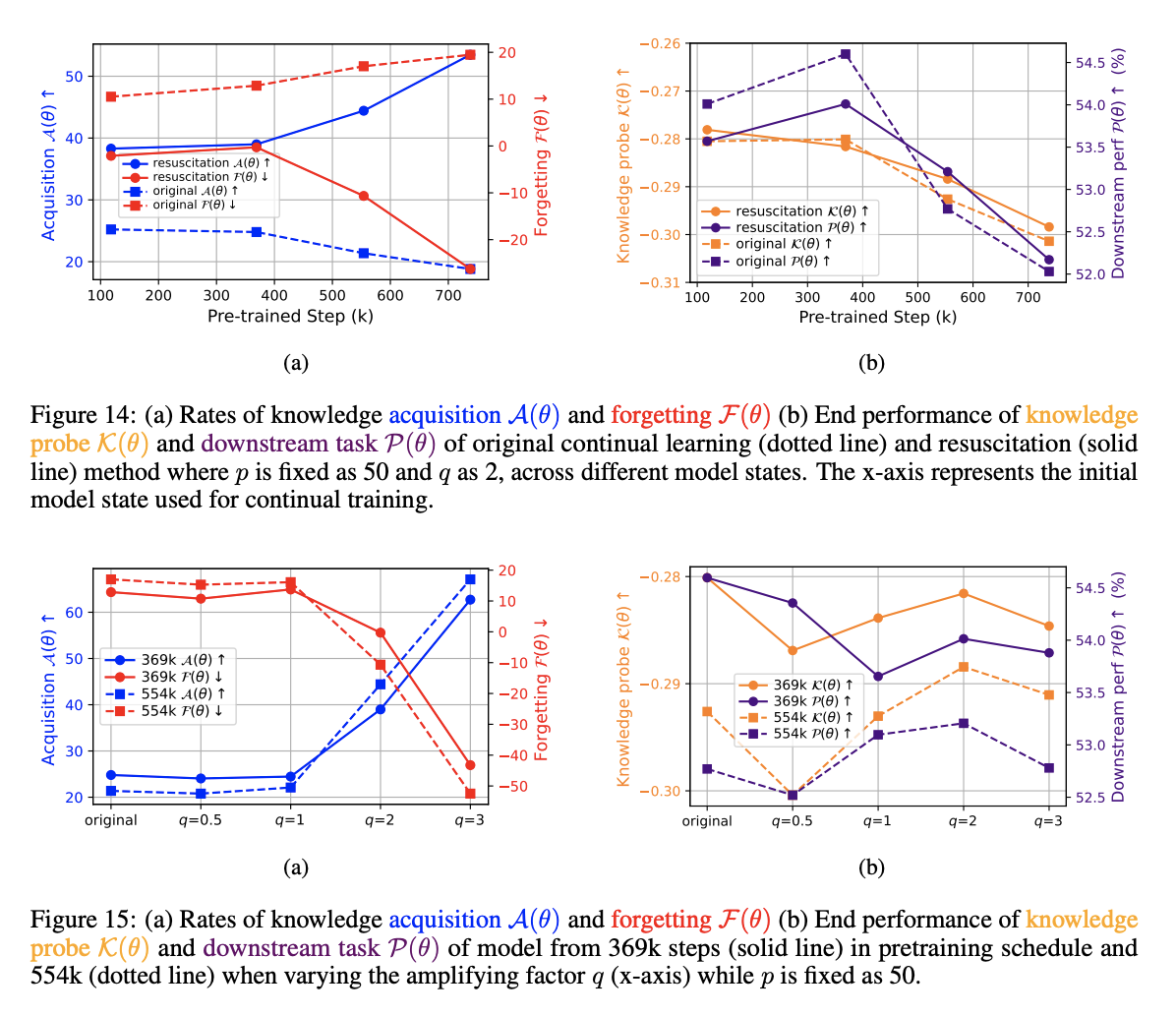
즉, 후반부 사전학습 단계 모델에서 비활성 메모리 벡터를 활성화했을 때, 성능이 개선되었지만 중간 단계 모델만큼의 성능 향상은 아니었다. 이는 모델의 근본적인 행동 변화를 유도하기 위해서는 보다 근본적이고 대체적인 접근이 필요함을 시사하며, 향후 연구에서는 이러한 매개변수 수정 방법에 대한 추가 탐구가 필요하다.
7. Conclusion
이 연구에서는 대형 언어 모델의 매개변수 지식을 통합하는 능력(knowledge entropy로 측정)이 사전학습 단계에서 어떻게 변화하며, 이러한 변화가 지속 학습 상황에서 지식 습득과 망각에 어떻게 영향을 미치는지를 분석했다.
-
연구 결과, 지식 엔트로피와 모델의 지식 습득 및 유지 능력 사이에 강한 상관관계가 있음을 발견했다.
-
사전학습 후반부 모델은 메모리 벡터를 좁게 활용하며, 이는 낮은 지식 엔트로피로 이어져 지식 습득 및 유지에 부정적인 영향을 미쳤다.
-
한편, 후반부 모델의 매개변수를 조정해 지식 엔트로피를 인위적으로 높이면 이러한 능력이 개선될 수 있음을 확인했다.
-
분석 결과를 바탕으로, 사전학습 중간 단계 모델이 지식 습득, 유지, 전반적인 성능 사이에서 균형을 이루며 새로운 지식을 학습하기에 적합한 선택임을 제안한다.
한계
-
본 연구는 자원의 제한으로 인해 continual learning 상황에서 지식 습득 및 망각을 측정했으며, 이러한 현상이 사전학습 단계에서도 발생하는지를 탐구하는 것이 향후 연구 과제이다.
-
OLMo 1B 및 7B 모델에 집중한 이유는 이들 모델만이 중간 사전학습 체크포인트를 공개하며 강력한 성능을 보여주기 때문이다. 다른 모델로 연구를 확장하는 것도 유의미한 연구 방향이 될 것이다.
-
모델의 매개변수를 조정하여 지식 습득과 유지 능력을 개선한 결과는 고무적이었지만, 초기 및 중기 모델에 적용했을 때는 성능 저하가 나타났다. 이는 언어 모델링 능력을 보존하면서 임의의 수정 없이 모델 매개변수를 되살리는 보다 정교한 방법이 필요함을 시사한다.
-
또한, 중간 단계 모델이 추가 학습에 적합하다는 점을 확인했지만, 중간 단계를 정확히 정의하는 것은 여전히 미해결 과제로 남아 있다. 본 연구에서는 학습률 스케줄의 50%를 중간 단계로 가정했다.