LLAMA PRO: Progressive LLaMA with Block Expansion
논문 정보
- Date: 2024-05-21
- Reviewer: hyowon Cho
- Property: LLM, Continual Learning
SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling
Introduction
더 큰 모델을 만들기 위해 애쓰고 있는 현실. 하지만, 자원이 한정되어있는 이상 우리가 모델의 크기를 무한정 키우는 것은 불가능하기에 MOE와 같은 다양한 방법들이 나오고 있다.
이러한 방법은 효과적으로 LLM을 scale-up할 수 있지만, 여전히 학습과 추론의 단계에서 non-trivial한 변화를 만들어야 한다는 점에서 widespread applicability를 보장한다고 할 수 없다. 즉, 단순성이 필요하다는 것이다.
해당 논문의 저자들은 이러한 한계점을 돌파하기 위해 depth up-scaling을 제안한다. 이 방식으로 만든 10.7b모델이 llama2 70b 모델, mistral 8x7b 모델에 준하는 성능을 보이고 있다고 하니, DUS를 좀 더 파고들어보자.
Depth Up-Scaling
- Base model. llama2 architecture에 Mistral 7b weight를 가져와서 사용.
Depthwise scaling.
-
notation
-
n: base_model의 layer 수
-
s: target layer count
-
-
process
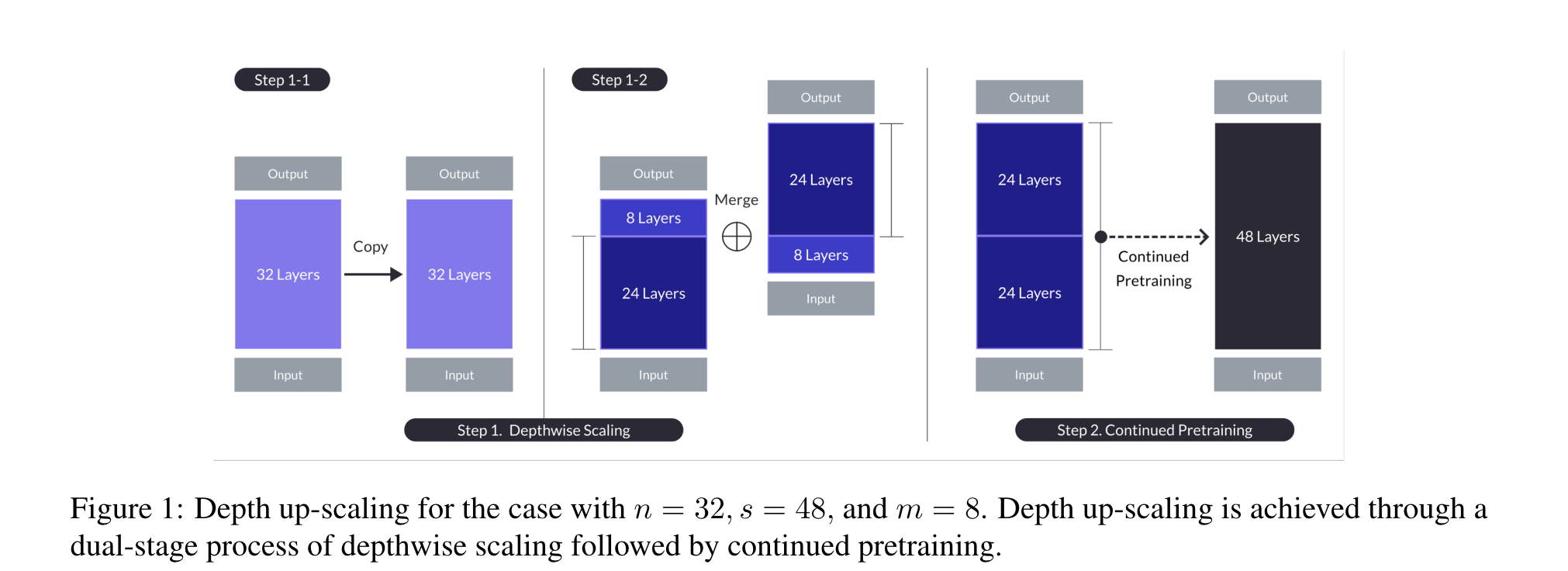
당연히 단순한 Merging만으로 성능이 오르는 것이 아니라, continual pretraining을 수행함. 하지만 요점은, 아주 빠른 성능의 복구가 일어났다는 것.
논문 상에 얼마나 continual pretraining을 했는지는 나와있지 않음.
이렇게 초반부를 잘라서 merging하는 방식 외에도, 사실 단순히 레이어를 다시 얹어서 반복하는 방식으로 크기를 키울 수 있을 것이다. 하지만, 이러한 방식은 layer간의 discrepency가 강해지기에 성능 복구하는데 더 오랜 시간이 걸린다고 한다. 중간 단을 merging하는 방식으로 heterogeneity를 낮췄기 때문에 모델 입장에서 성능 복구가 가능하다는 주장!
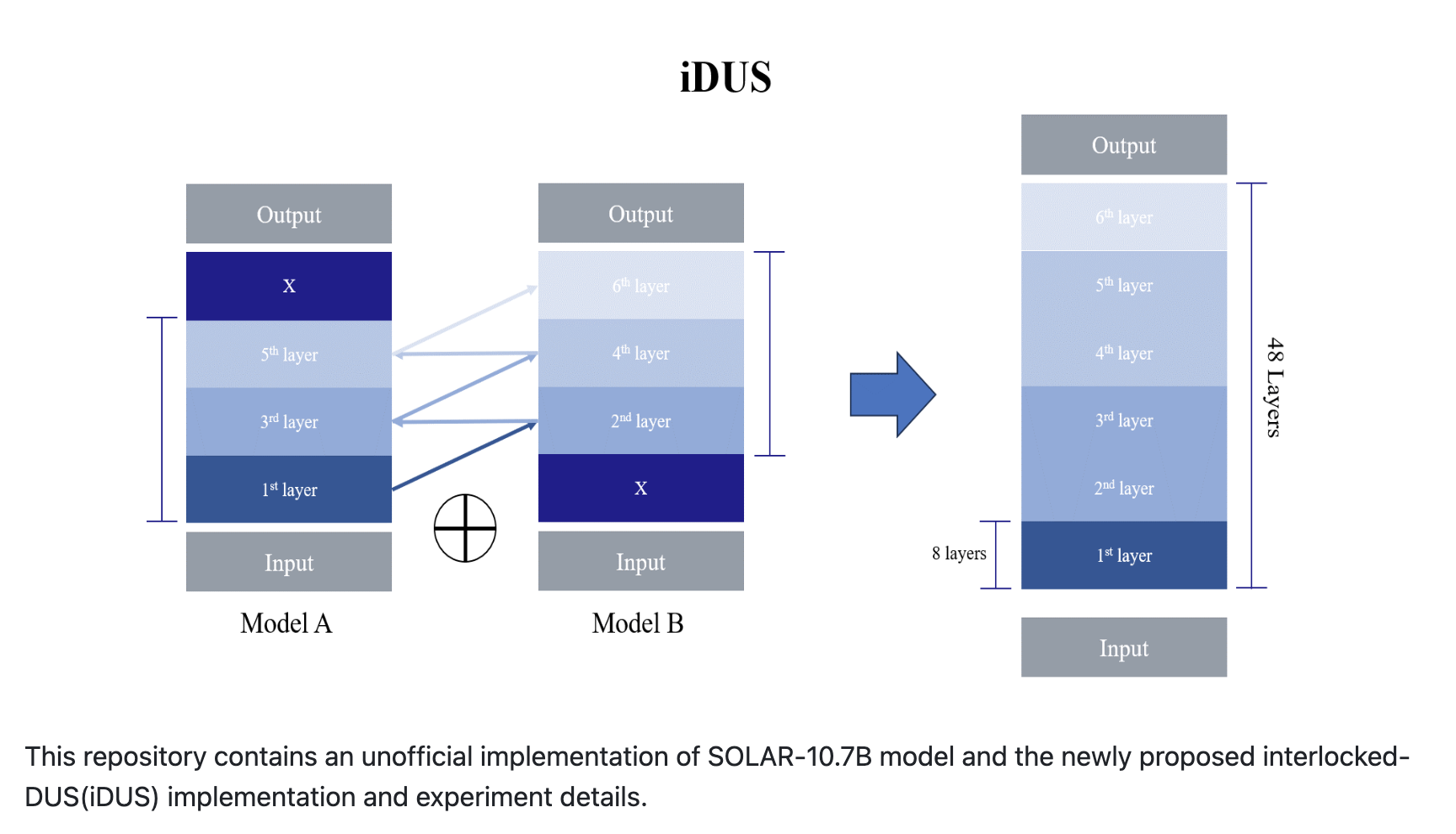
iDUS
https://github.com/gauss5930/iDUS
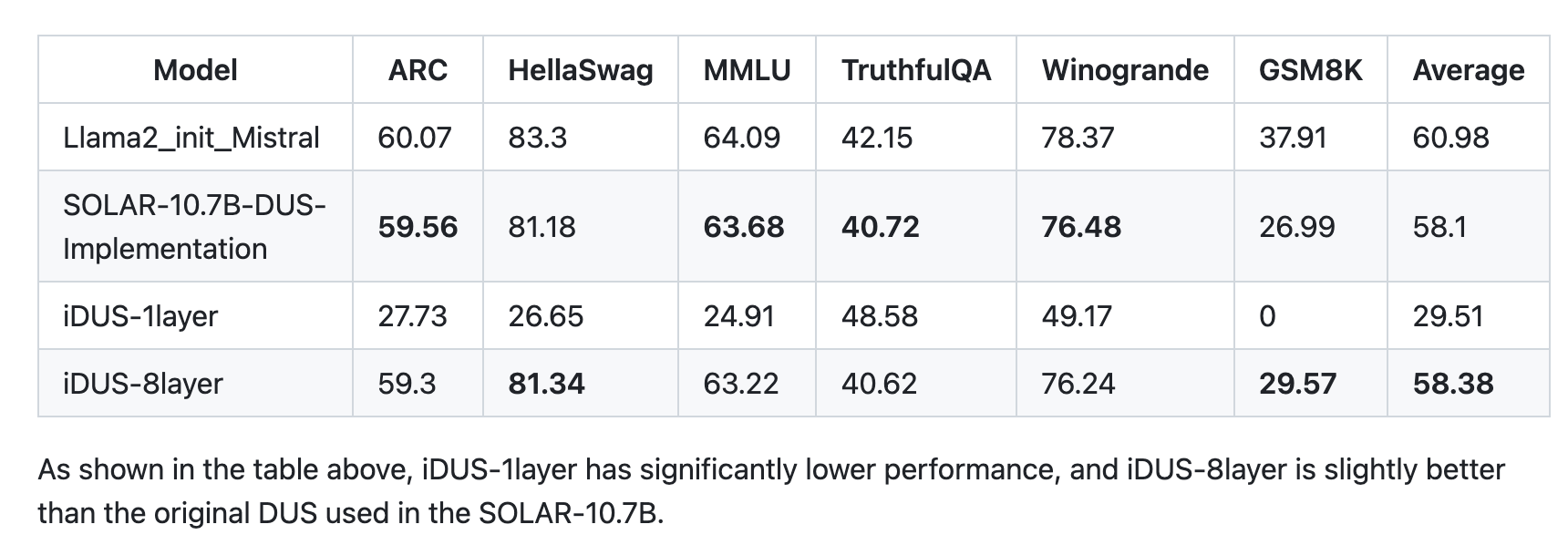
Results
Experimental Details
-
2 stage
-
instruction tuning: QA format
-
alignment tuning: sDPO
-
-
dataset
-
일부분만 sample하여 사용한 경우도 있음.
-
alpaca-styled chat template
-
6 evaluation tasks
-

-
model merging
-
avergage
-
slerp
-
Experiments
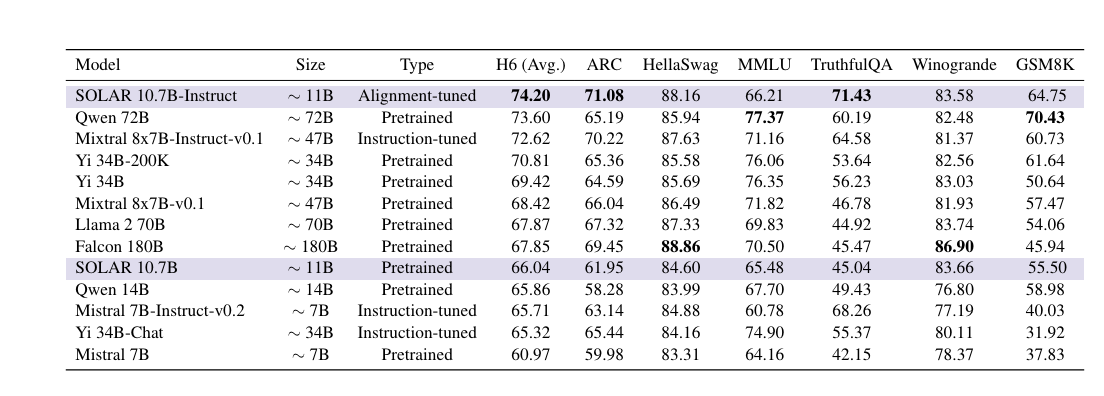
뒷 부분은 alignment/instruction/merging의 ablation이므로 생략함
LLAMA PRO: Progressive LLaMA with Block Expansion
LLM은 여전히 programming, mathematics, biomedical, finance과 같은 특정 도메인에서 부족한 점이 있다. 이에 따라 선행 연구들은 tailored data recipe를 이용해서 LLM의 능력을 향상시키려 했지만, 이는 많은 자원과 데이터를 필요로 하므로, 현실적으로 모든 연구자들이 사용할 수 있는 해결 방안은 아니다. 이에 따라, another line of research로 domain-adaptive pretraining(DAPT)를 이용해 이러한 문제를 개선하려 하지만, catastrophic forgetting 문제가 발생한다.
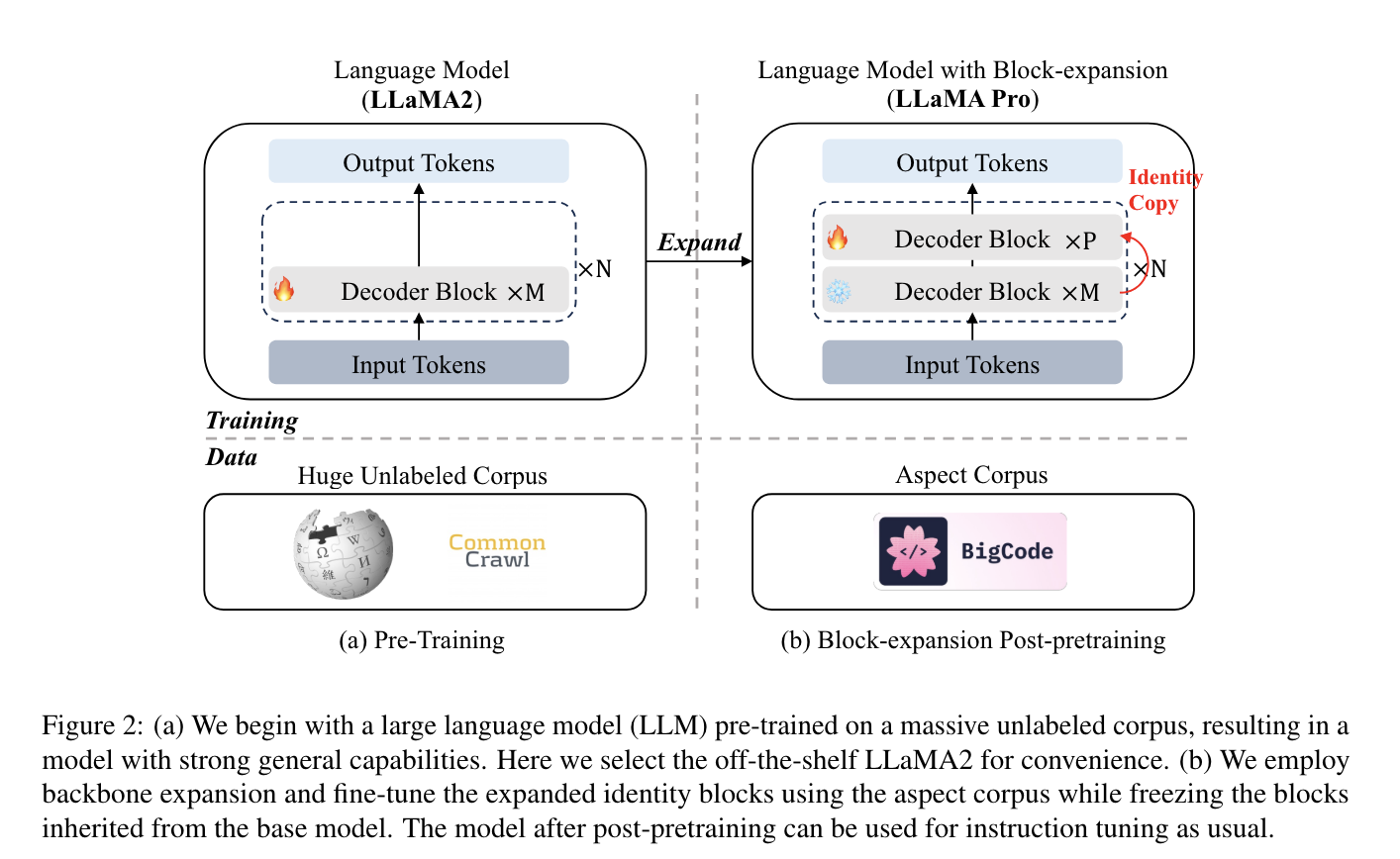
해당 연구에서는 이를 해결하기 위해, block expansion 라는 post-pretraining method를 제안한다.
이 방법은 Transformer 블록을 복사하여 LLM을 확장하고, domain-specific 코퍼스로만 추가 조정하여 모델의 일반 및 domain-specific 작업 모두에서 뛰어난 성능을 보이게 한다.
Method
Preliminaries: The LLaMA Block
LLaMA block을 구성하는 요소들은 다음과 같다:
-
multi-head self-attention (MHSA) mechanism
-
position-wise feed-forward network (FFN)
-
residual connections
-
Swish-Gated Linear Unit (SwiGLU)
Block Expansion
model with blocks (ϕ0, ϕ1, …, ϕL)이 있을 때, block expansion은 identity block ϕid를 각 original model block 다음에 붙이는 것이다. 이때, expanded model은 expansion 후에도 기존 output을 정확히 유지한다.
identity block is defined as ϕid(x) = x, where the input and output are identical.
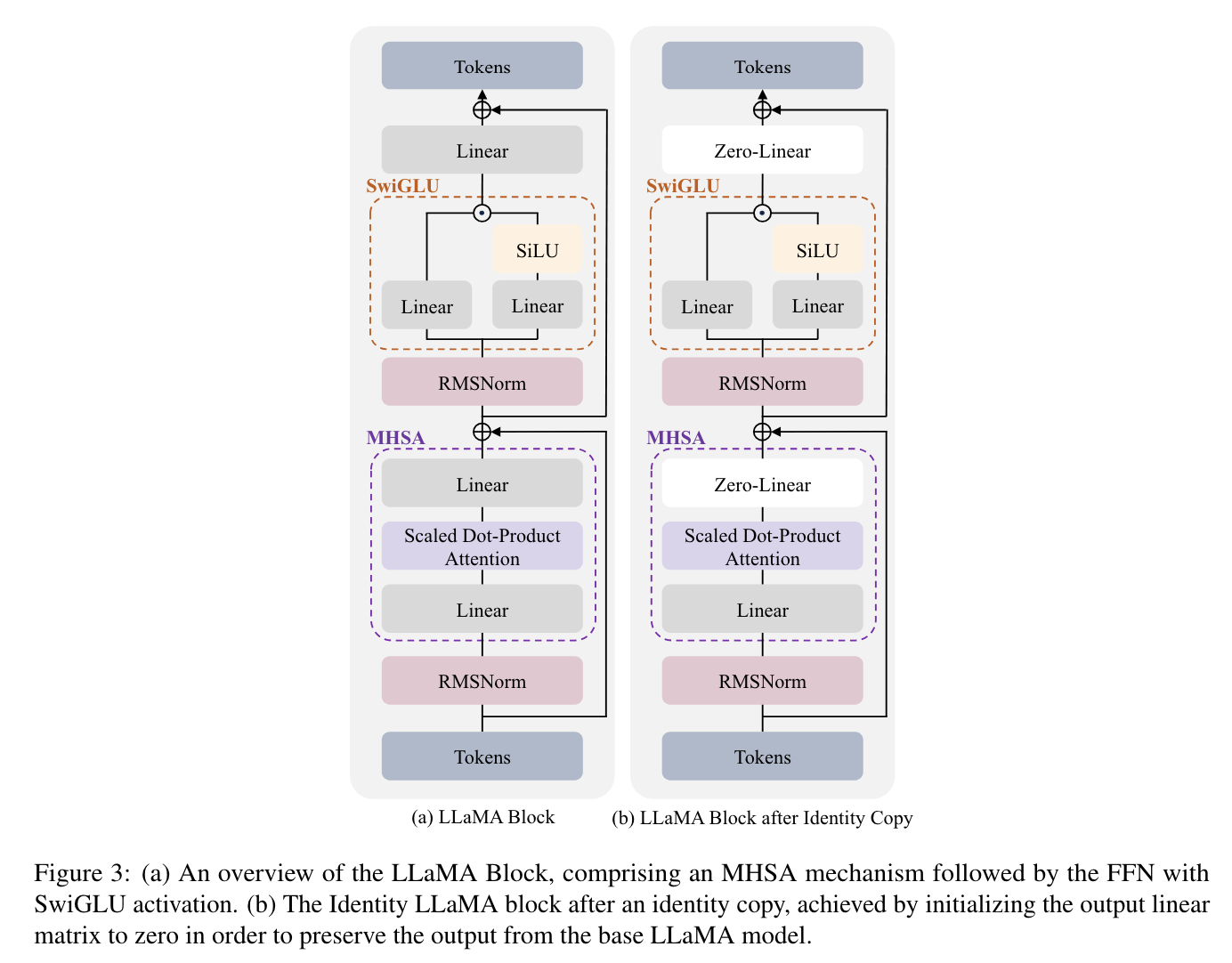
이때, 모델이 L개의 block을 가진다고 할 때, 다음의 절차를 거친다.
- partition the original L blocks into N groups.
- 각 group은 L/N의 block을 가짐
-
각 group 당, top P blocks에 대해 identity copies를 만든다.
-
stack them on top of each group.
이때 특정 위치(아래, 위, 중간)에만 넣지 않은 이유는, transfomer의 구조상, deeper block이 더 복잡한 정보를 encode한다는 선행연구들이 많기 때문.
initialization 관련해서도, 0으로 설정한 이유를 appendix에서 수학적으로 증명해놓음.
이후, domain-specific knowledge를 학습할 때는 추가된 블락에 대해서만 학습 진행.
Experiments
Experimental Settings
-
pretrain detail
-
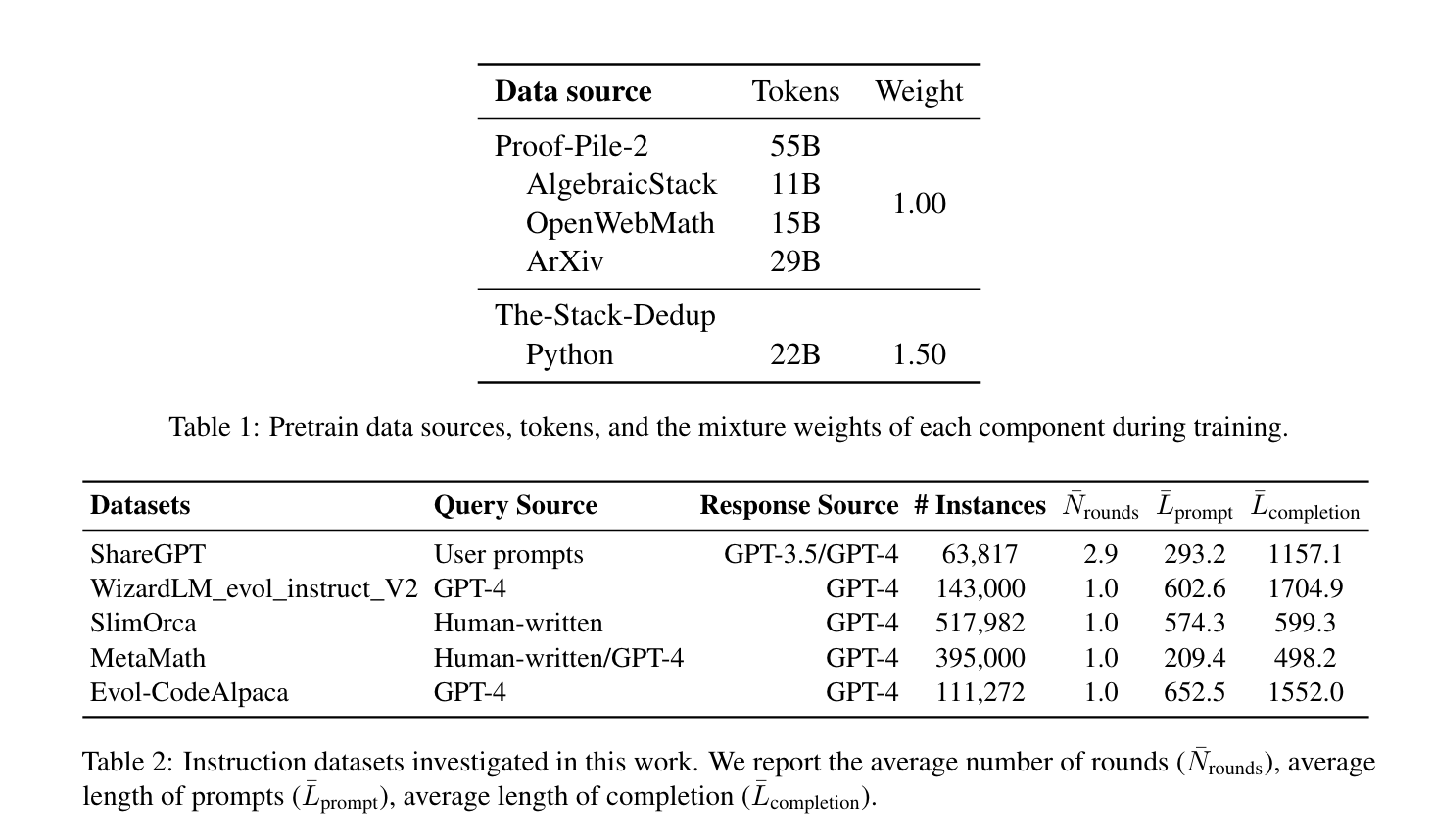
dataset
-
code: Stack-dedup dataset
-
math: Proof-pile-2
-
-
base model
- llama2-7b
-
config
-
P top block: 1
-
N 그룹 수: 8
-
-
gpu time
- (16 NVIDIA H800 GPUs for about 7 days)
-
-
SFT details.
-
instruction fine-tuning dataset
- ShareGPT1, WizardLM, CodeAlpaca, MetaMath, SlimOrca
-
fully fine-tuning of all the blocks
-
Results
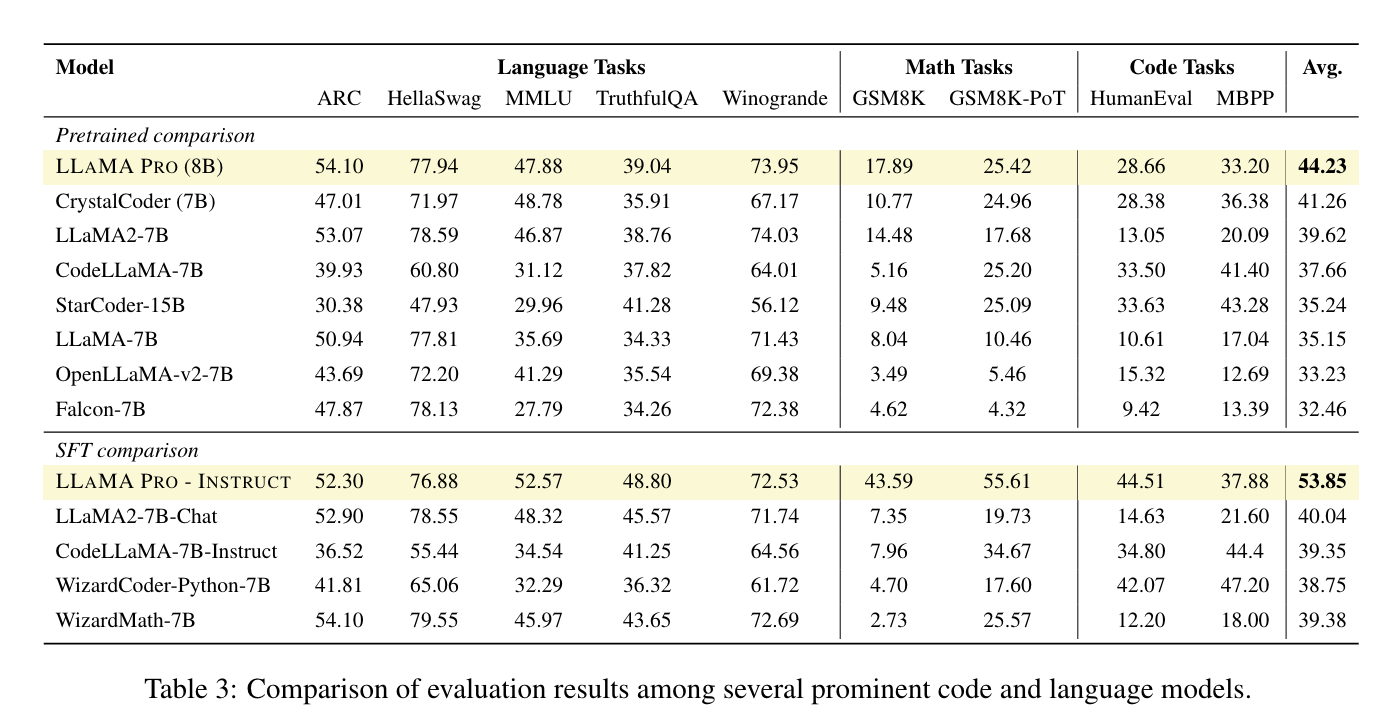
Pretrain Results
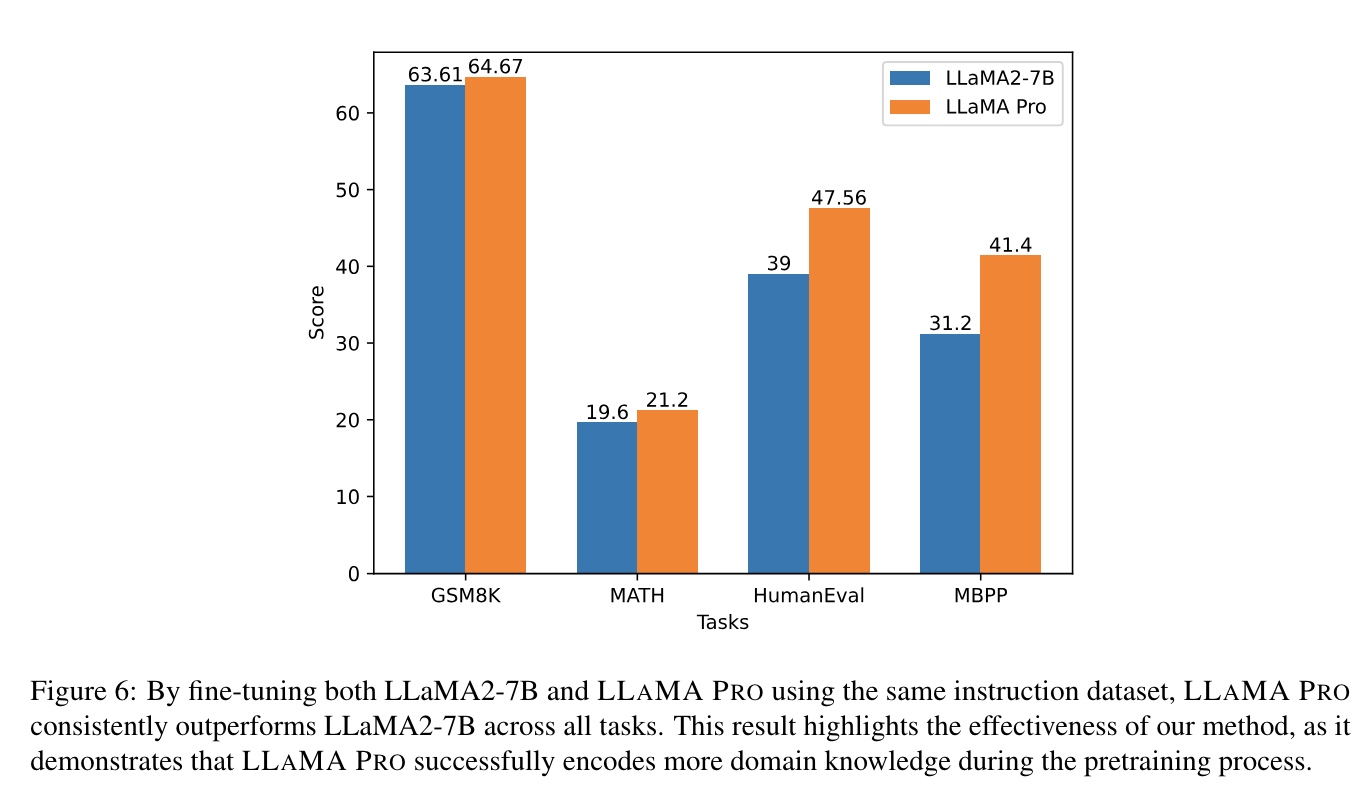
SFT Results
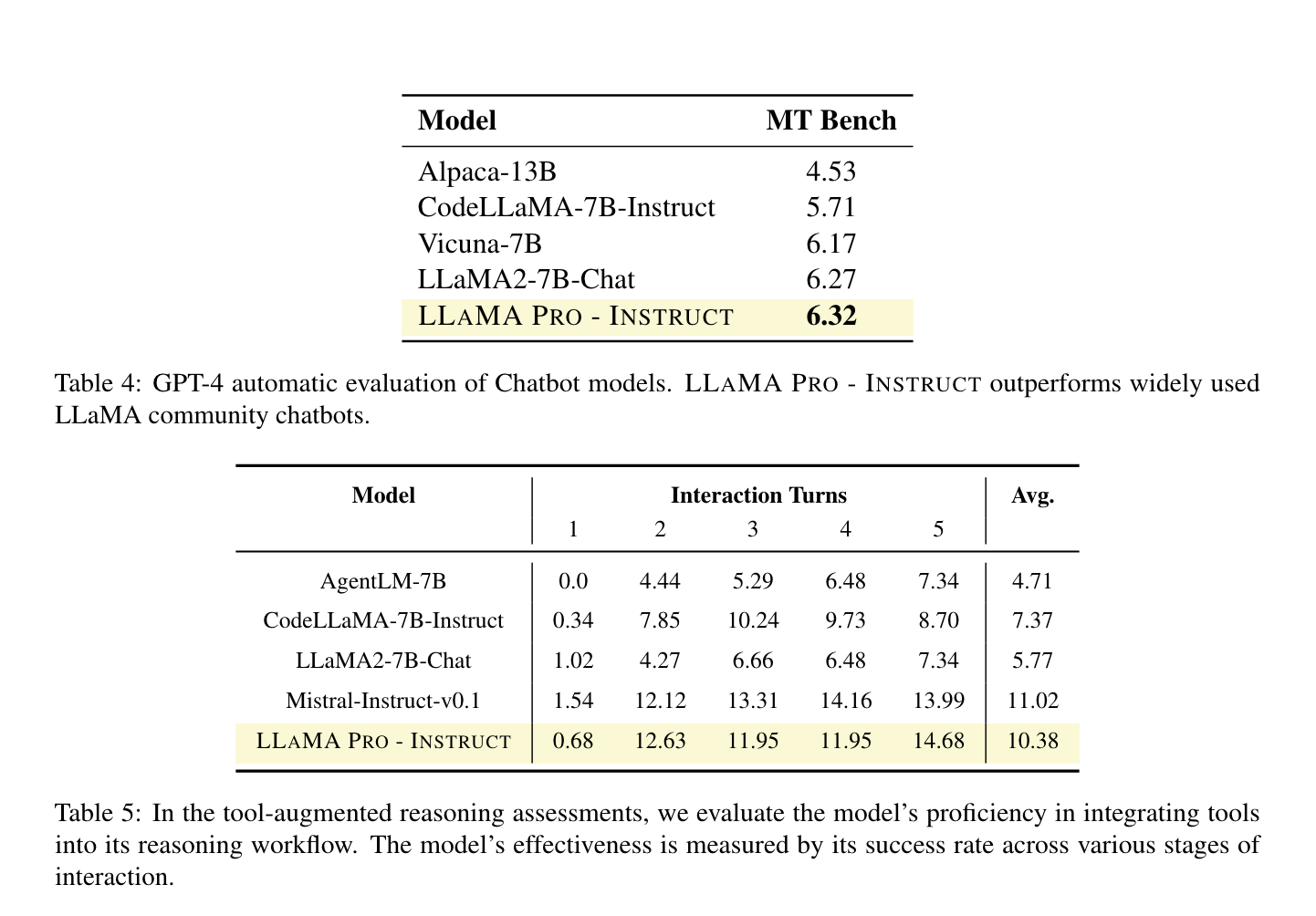
MINT-Bench tests LLMs’ ability to use tools by generating and executing Python code, focusing on tool-augmented task-solving and leveraging natural language feedback. MINT includes eight datasets covering reasoning, code generation, and decision-making.
Ablation Study
- LoRA vs SeqFT vs BE
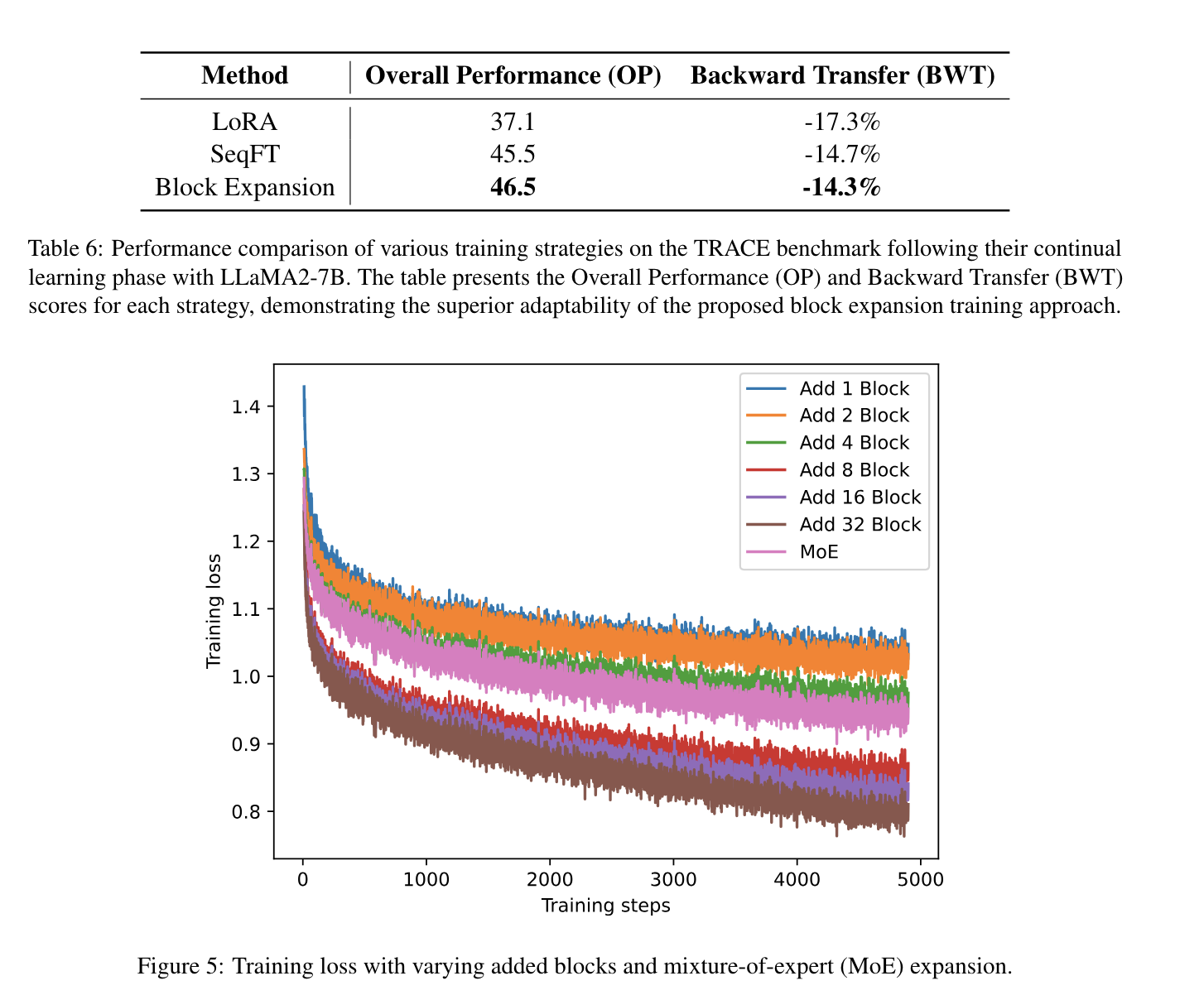
TRACE is designed to assess continual learning in LLMs and comprises eight distinct datasets that span challenging tasks such as domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning.
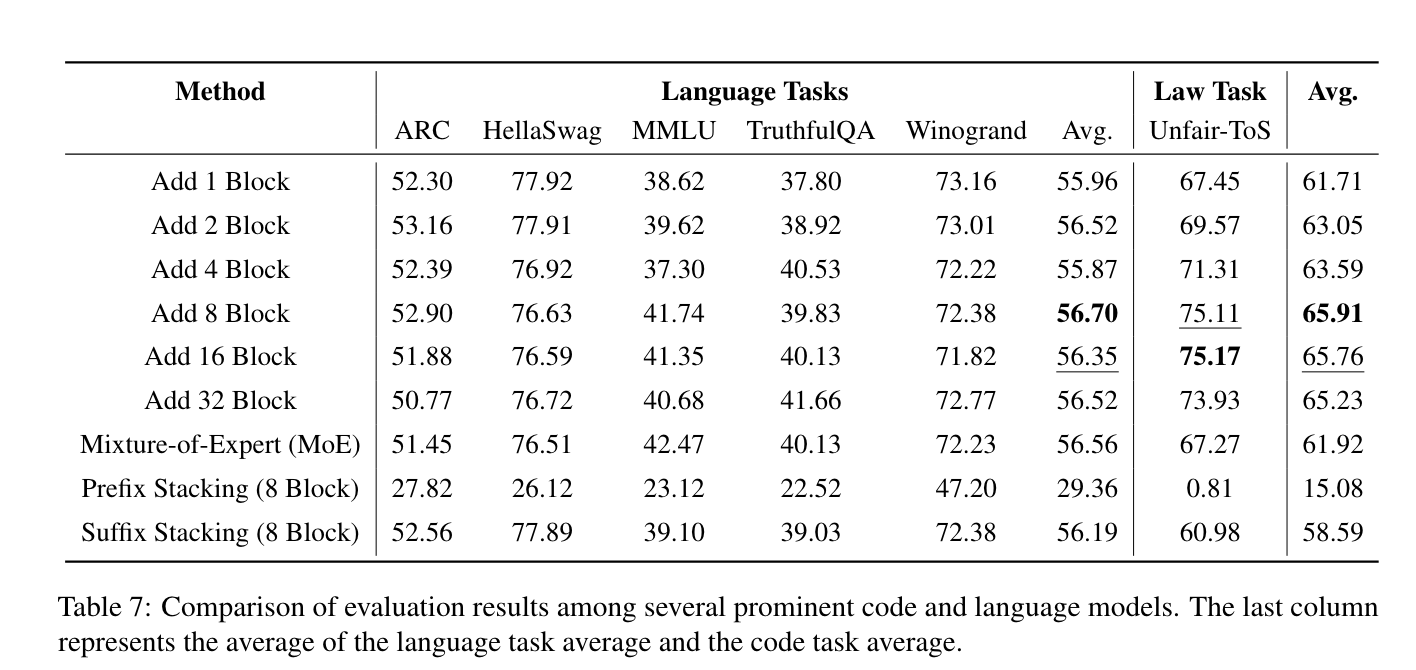
-
stacking 및 lora weight 사용 방식
-