Llama3 Tokenizer
논문 정보
- Date: 2024-07-02
- Reviewer: 준원 장
- Property: Tokenizer
Llama3의 개선사항
-
Llama3은 전작인 Llama2에 비해서 (1) 학습 데이터 증가 (2) 컨텍스트 길이 증가 (3) tokenizer 교체 (4) GQA등을 적용해서 성능을 향상시켰다고 알려져 있습니다.
-
이 글에서는 (3)에 대해서 보다 깊게 다뤄보고자 합니다.
Tokenizer의 역할
- [’FileExistsError:’]라는 string이 있을때 더 많은 token이 있는 Tokenizer는 ‘FileExistsError:’를 하나의 token으로 처리할 수 있는 반면, 적은 token이 있는 Tokenizer는 [’File’, ‘Exists’, ‘Error’, ‘:’]로 나누어서 해당 정보를 언어모델에게 처리시킵니다.
Llama3 Tokenizer의 개선 사항
Tokenizer의 교체
-
Llama3부터는 BPE(Byte Pair Encoding)기반의 https://github.com/openai/tiktoken?tab=readme-ov-file 라이브러리로 교체를 했다고 합니다. (효율성과 확장성 때문이지 않을까라고 사료됩니다)
-
ti-tokn 라이브러리는 token당 4 bytes의 압축률을 보인다고 합니다.
-
SentencePiece Tokenizer는 일본어,중국어와 같이 whitespace로 구분이 안되는 기존 언어들이 BPE(Byte Pair Encoding)나 Word Piece Tokenization 로 효과적으로 Tokenizing되지 않는 문제를 해결하기 위해 고안된 알고리즘입니다.
-
language-agnostic하게 정보의 손실이 없는 tokenizer를 만들어주기 위해 whitespace에 를 추가해줌으로써 알아서 전체 문장 내에 ‘’가 공백이라는 정보를 학습시켜줍니다.
-
‘_’는
detok = ’’.join(tokens).replace(’_’, ’ ’)를 통해 디코딩 과정중에 제거시켜줍니다. -
Sentencepiece는 하나의 프레임워크이기에 BPE, WordPiece Tokenization도 지원합니다.
- (e.g., 엄마가방에있다 → 엄머가 방에 있다.)
-
-
다른 Tokenization 알고리즘은 어떻게 동작할까요?
-
BPE(Byte Pair Encoding)
-
this is the hugging face course. this chapter is about tokenization. this section shows several tokenizer algorithms.과 같은 text가 있다고 할때, 대부분의 상용 tokenizer들은 **whitespace를 기준으로 pre-tokenizing **과정을 거칩니다.['this', 'is', 'the', 'hugging', 'face', 'course.', 'this', 'chapter', 'is', 'about', 'tokenization.', 'this', 'section', 'shows', 'several', 'tokenizer', 'algorithms.']
-
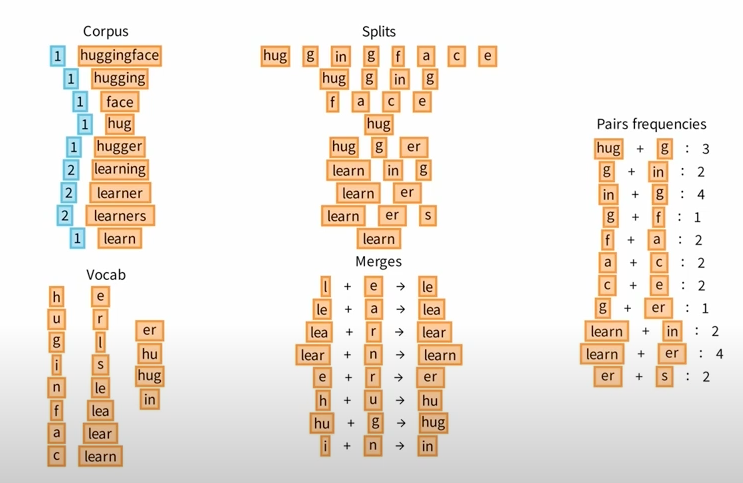
그럼 아래와 같은 frequency Corpus를 얻게되고, corpus내에 있는 unique한 vocab을 byte(character) 단위로 나누어서 unique한 Splits을 만듭니다.
-
UTF-8
-
영어 알파벳과 숫자: 1byte
-
유럽 언어의 일부 문자: 2byte
-
한글, 한자, 일본어 등 대부분의 비라틴 문자: 3byte
-
-
-
Pairs frequencies 기준으로 Vocab쌍에 원하는 Vocab쌍에 추가해나가는 방식입니다.
-
-

…. On Going ….
-
Word Piece Tokenization
-
BPE랑 거의 유사하지만, Splits가 만들어지는 방식과 Pairs frequencies가 상이합니다.
-
특히 Pairs frequencies의 경우 각 Splits의 frequencies과 Pairs의 frequencies를 통해 likelihood를 통해 score를 계산한 후 vocab을 추가합니다.
-
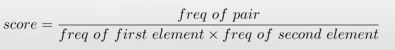
Token수의 확장 및 이를 통한 효용
-
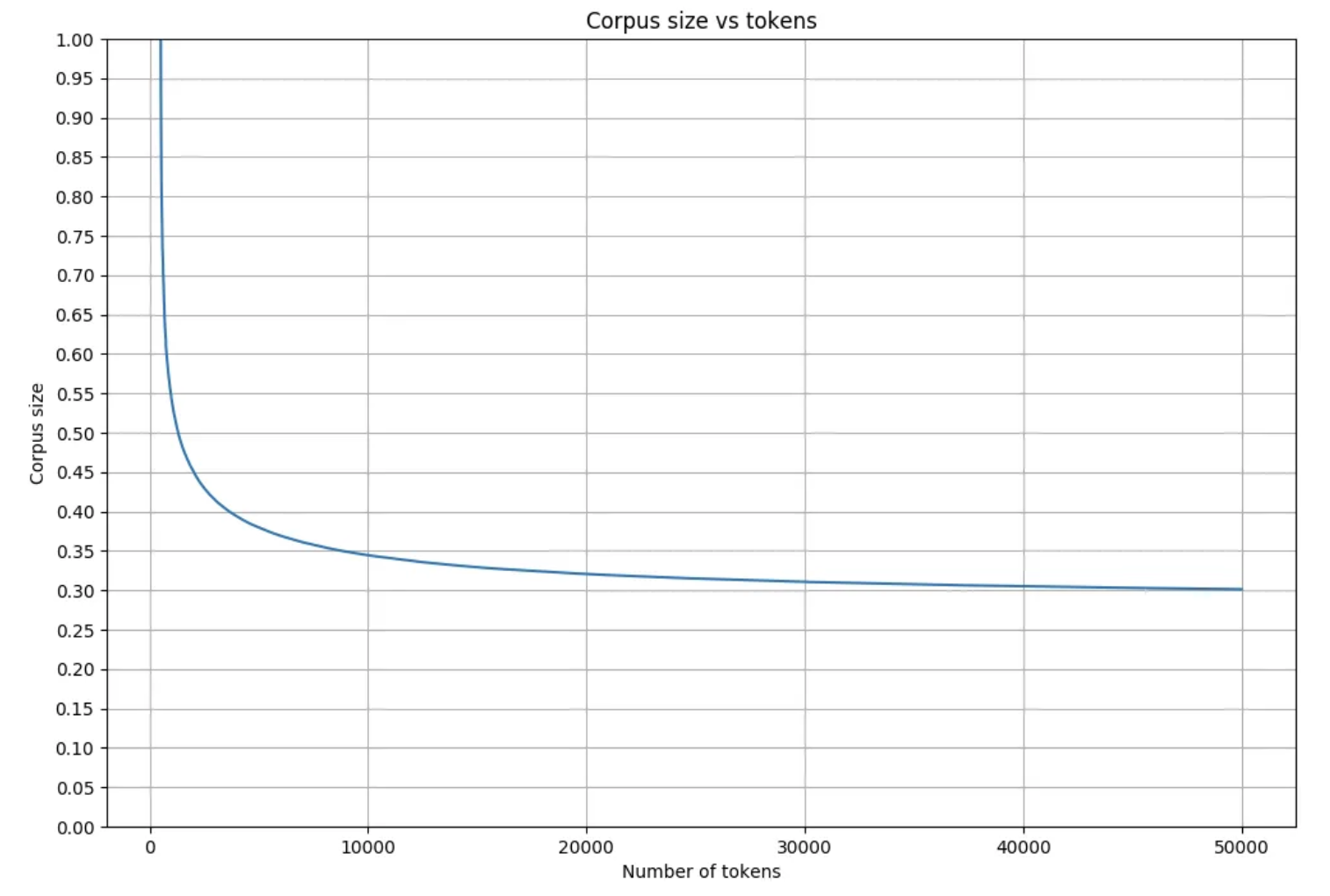
Tokenizer를 변경해 32K개의 토큰에서 128K개의 토큰으로 Vocab Size를 확장했습니다.
- 내부적으로 128K까지 확장했을때 다양한 task에서 성능 향상을 관찰했다고 합니다.
-
Compression Ratio = Number of Tokens/(Number of characters to encode & Number of bytes)
-
A 토크나이저 (30K vocab):
-
“The quick brown fox jumps over the lazy dog.” → [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”]
-
토큰 수: 9 tokens
-
Compression Ratio = \frac{9 \ tokens}{44 \ bytes} ≈0.2045
-
-
B 토크나이저 (100K vocab):
-
더 큰 vocabulary를 사용하여 단어들을 더 큰 단위로 처리할 수 있습니다.
-
“The quick brown fox jumps over the lazy dog.” → [“The”, “quick”, “brown”, “fox jumps”, “over”, “the lazy”, “dog”]
-
토큰 수: 7 tokens (더 큰 단위로 토큰화됨)
-
Compression Ratio = \frac{7 \ tokens}{44 \ bytes} ≈0.1591
-
-
-
그렇다면 Vocab Size 확장은 왜 중요할까요?
-
하나의 문장을 표현하는 Token 수가 압도적으로 줄어듭니다. (향상된 압축 비율)
- Research Scientist에 따르면, 영어문장 기준으로 보수적으로 잡을 때 Llama2 대비 15%이상 적은 token으로 같은 문장을 생성할 수 있다고 합니다. (다른 언어는 50% 이상 높은 압축 비율을 보이기 한다고 언급합니다.)
-
Pre-Training시에도 더 높은 Token 수는 도움이 됩니다.
-
Pre-Training의 목적은 Knowledge에 대한 Recall을 높히는 것입니다. 이런 관점에서 생각해볼 때, 같은 광범위한 데이터셋이라도 더 향상된 압축 비율(여러 token들로 굳이 나눠서 표현할 수 있는 것 대비 필요한 token들로만 나누어서)로 학습하는게 도움이 된다고 합니다.
-
영상에 직접적으로 언급은 없지만, vocab이 많기 때문에 다양한 corpus에 빠르게 fitting되는 경향이 있어 loss가 상대적으로 빠르게 수렴된다는 연구 및 실험 reporting도 많이 접했습니다.
-
-
당연한 이야기지만, 기술 용어와 고유 명사와 같은 특정 도메인 언어를 처리하는데 sub-word도 분리하는거보다 도움이 된다고 합니다.
-
Input과 Ouput에 적은 Token이 사용된다는 말은 Inference시에도 적은 cost를 가지고 generate() 용이하게 해 모델을 실제 환경에 배포하는 데 더 실용적이고 효율적으로 만듭니다.
-
Token수의 확장은 Not Free Lunch
-
이미 눈치채셨겠지만, Vocab Size를 4배 가량 확장했다는 의미는 Embedding Layer, lm_head(Research Scientist는 Debedding Layer라구하더라구요!ㅋㅋ)도 그만큼 확장해야 한다는 의미입니다.
-
실제로 이 이유가 Llama3가 7B가 아니라 8B로 끝난 이유라고 합니다..!
-
특히나 lm_head가 증가하면 inference 속도에 직접적인 영향을 주기 때문에 GQA를 줘서 완화를 했다고 합니다.
-
GQA는 MHA와 MQA 사이의 sweet spot이라고 하는데요, 조만간 다른글 혹은 해당 글의 연장선으로 찾아뵙도록 하겠습니다.
References
https://www.youtube.com/watch?v=qpv6ms_t_1A
https://github.com/openai/tiktoken?tab=readme-ov-file
https://discuss.pytorch.kr/t/llama-3-tokenizer-youtube/4899
https://www.youtube.com/watch?v=Tmdk_H2WDj4&utm_source=pytorchkr&ref=pytorchkr
https://medium.com/codex/sentencepiece-a-simple-and-language-independent-subword-tokenizer-and-detokenizer-for-neural-text-ffda431e704e