LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
논문 정보
- Date: 2024-09-02
- Reviewer: 김재희
- Property: Embeddings, LLM
1. Intro
Scaling을 통해 좋은 능력을 보유한 Decoder 모델을 Encoder로 간단히 Adaptation 할 수 있다!
-
BERT와 GPT 이후 이어진 Encoder vs Decoder 대전
-
BERT는 패배하였다… → Encoder model의 경우 scaling을 통한 성능 개선 및 활용처가 분명하지 않음
-
Decoder-only: scaling을 통한 성능 개선 효과 확실
-
⇒ 성능 개선을 통해 다양한 태스크로 확장 및 도메인 확장이 가능
-
Embedding: 여전히 광범위한 태스크에서 활용
- Information Retrieval, Sentence Classification, Clustering 등등
⇒ Encoder 모델이 여전히 높은 성능을 보이고 있는 분야
⇒ PLM의 성능 개선이 어려워 비약적 성능개선이 매우 어려움
→ Scaling을 통해 성능을 개선시키는 Decoder 모델을 사용할 수는 없을까?
MNTP + UCL을 통해 Decoder를 Encoder로 활용 가능
2. Method
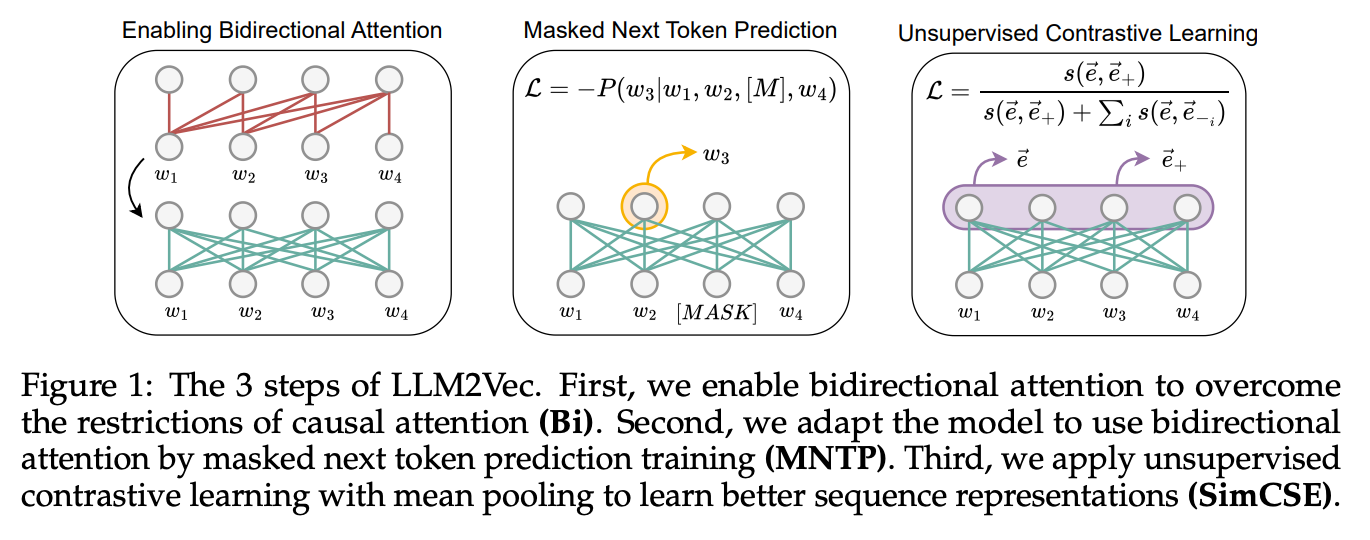
3단계 과정으로 구성
2-1. Bidirectional Attention
**기존 Decoder only 모델의 Attention layer를 bi-Directional Attention으로 변경 **
→ 기존 pretrained weight는 그대로 활용
2-2. MNTP(Masked Next Token Prediction)
Decoder가 적절히 Embedding task를 학습하도록 유도
-
문장 내 임의의 토큰을 마스킹하고, 이전 시점의 representation으로 마스킹된 토큰을 예측
-
BERT의 MTP(Masked Token Prediction)과 GPT의 NTP(Next Token Prediction)의 중간 수준
-
MTP: 문장 중간 토큰을 Masking하고 예측
- bi-directional 모델을 이용하여 context를 반영한 Representation 생성 학습
→ Encoder에 적합한 학습 방식
-
NTP: 매 토큰의 다음 토큰을 예측
- Scaling에 용이하고 높은 성능 달성이 가능
→ Pretrain 시 학습한 태스크를 유지
2-3. Unsupervised Contrastive Learning
Sentence Level의 Representation을 생성하도록 학습
-
SimCSE 학습 방법론 이용
-
query: 임의의 문장
-
positive: query 문장에 대해 dropout을 다르게 적용한 Representation
-
negative: in-batch negatives
3. Experimental Setup
Masking Token: “_”
-
Decoder model은 masking token이 없음
-
나는 바보가 아니다. → 나는 _ 아니다.
- 나는
아니다.
- 나는
training step (1 A100)
-
MNTP: 1,000 step, 100 minutes
-
UCL: 1,000 step, 3 hours
Training Method: LoRA
Training Dataset
Wikipedia 데이터 이용: 모든 LLM의 사전학습에 포함
→ 모델에게 새로운 지식 주입 X, Encoder로서의 태스크 학습
-
MNTP: Wikitext-103
-
UCL: Wikipedia sentences
4. Experiments
4-1. Word Level Tasks
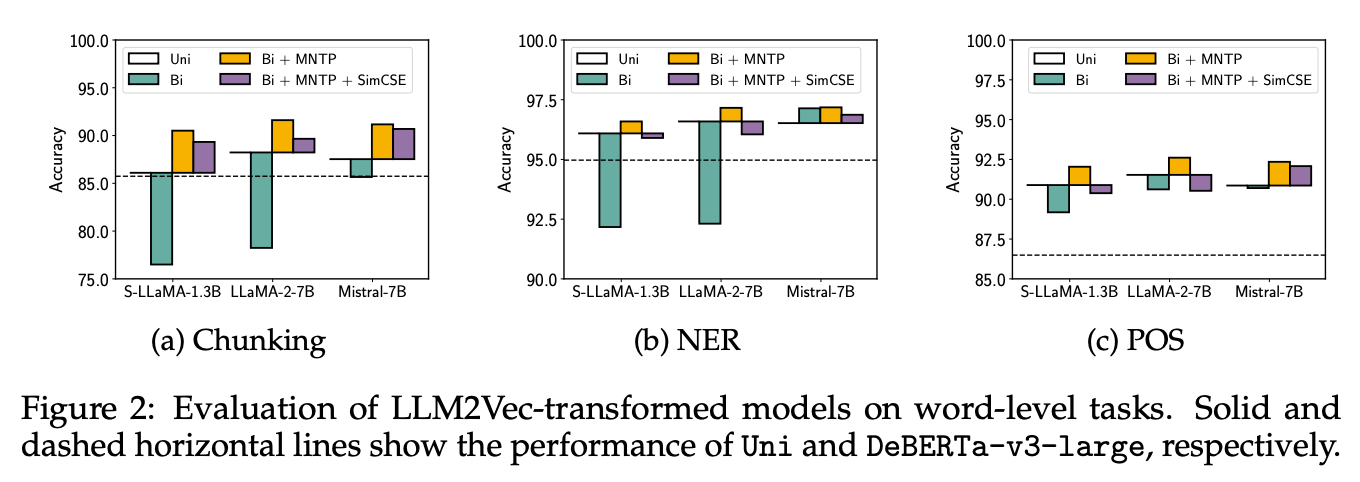
-
token 수준의 representation을 필요로 하는 Task
-
실험 모델
-
Uni: Decoder only LLM (직선)
-
DeBERTa-v3-large: Pretrained Encoder (점선)
-
Bi: LLM의 attn을 bi-directional attn으로 변경, 학습 X
-
Bi + MNTP : MNTP 학습된 모델
-
Bi+ MNTP + SimCSE: MNTP로 학습된 모델 + SimCSE 훈련
-
-
실험 해석
-
Bi: 심각한 학습 저하 양상을 보임 → LLM은 attn만 바꾸어서는 적절한 representation 생성 X
-
MNTP: 성능 개선 관찰 → 1,000 step 학습으로 좋은 Representation 형성 가능
-
SimCSE: word-level task에서도 MNTP 대비 성능저하 적음
-
4-2. Sentence Level task
MTEB 벤치마크 내 15개 태스크에 대한 평균값
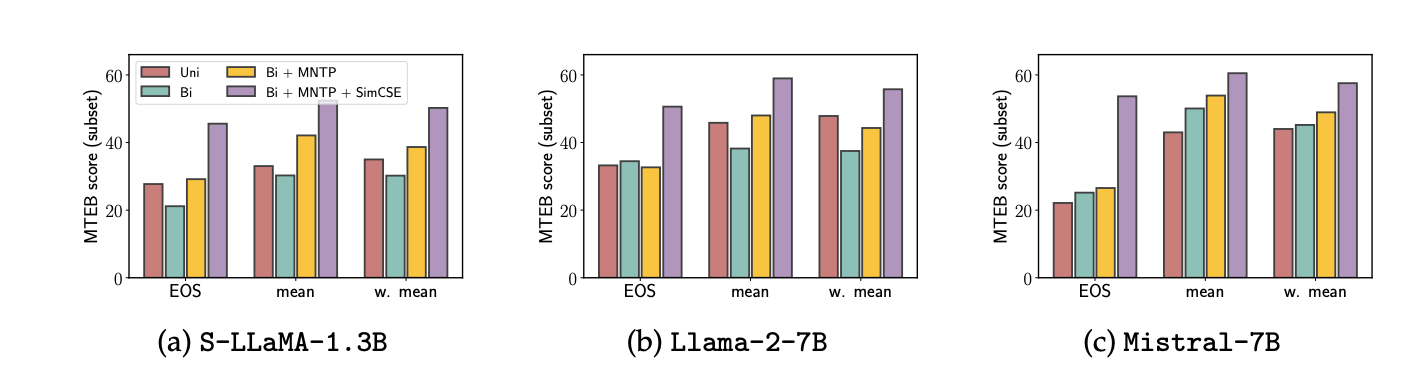
-
Pooling 방법론과 관계없이 SimCSE가 가장 좋은 성능을 보임
-
Mistial: Bidirectional Attn만 적용하더라도 성능 개선이 관찰되는 모습을 보임
- 다른 LLM과 다른 경향성
⇒ 학습 데이터 or pretrain method에 있어 차이점이 존재한다고 추측 But 공개 X
(재희) Mistral 사전 학습 과정에서 token level task가 적용…?
-
Bi Directional Attn만으로는 Decoder 모델의 Encoder 전환 불가
-
MNTP 태스크로 적은 step만 학습하더라도 모델은 쉽게 Encoder로 전환됨
-
Unsupervised Contrastive Learning 적용 시 sentence level에서 더 높은 성능 달성
4-3. MTEB Benchmark
- MTEB: Retrieval, Rerank, Clustering, Sentence Pair Classification, STS, Extractive Summarization 등 Encoder용 태스크에 대한 범용 벤치마크 데이터셋
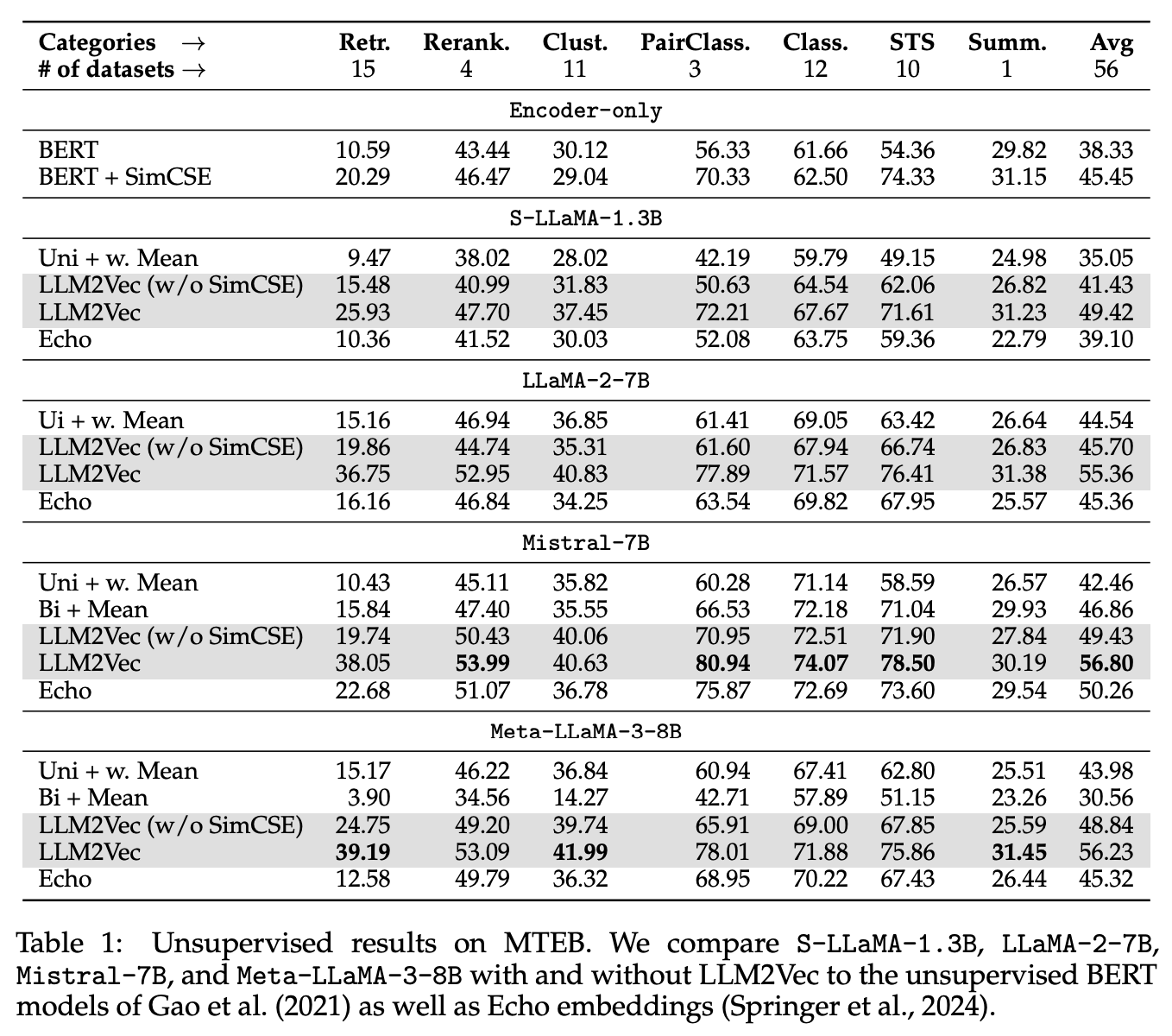
- Echo Embedding: 동일 문장을 두번 반복하여 입력하고, 뒷 문장에서 Representation을 획득하는 방법
→ 뒷문장의 모든 토큰은 앞문장을 통해 모든 토큰에 대해 attn할 수 있으므로 bi-directional attn의 효과를 얻을 수 있음
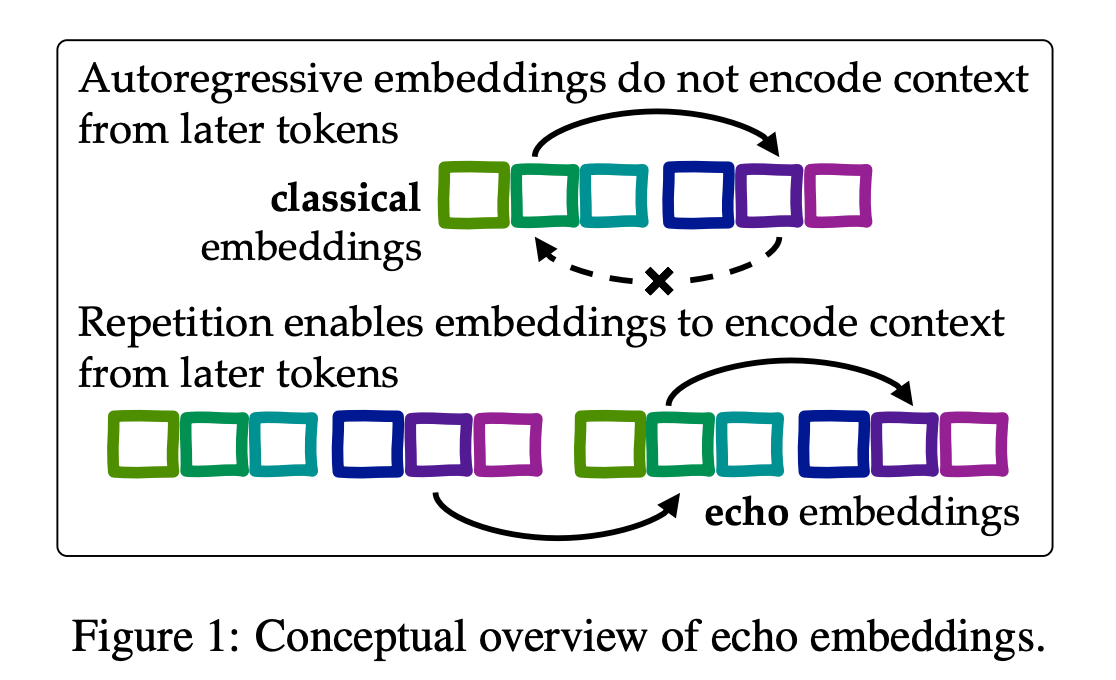
-
Uni + Mean: Decoder 모델의 Representation에 대해 mean pooling 적용
-
BERT + SimCSE와 유사한 성능 가능
-
Decoder Model이 Scaling up되면서 모델 구조의 한계를 넘을 수 있음
-
(재희): Decoder 모델을 이용하여 Encoder를 만들어야 하는 방향성의 근거
-
Bi + Mean: Decoder 모델에 대해 Bi Attn만 적용하고 모든 token에 대한 Mean pooling 이용
- Mistral을 제외한 모델의 경우 매우 안좋은 성능 기록
-
LLM2Vec(w/o SimCSE): 거의 모든 태스크에서 Uni + Mean 대비 높은 성능 도출
- Sentence Level 태스크라는 점을 고려하면 LLM2Vec이 단순하면서 강력한 방법론임을 보여줌
-
LLM2Vec: 매우 높은 성능 도출
- 적은 학습으로도 Decoder 모델이 Sentence 단위로 representation을 매우 능숙하게 생성할 수 있음
⇒ 최근 MTEB 상위 방법론들이 모두 동일한 경향성을 보임 (LLM + Bi Attn + Contr. Learning)
4-4. Analysis 1(MNTP의 효과)
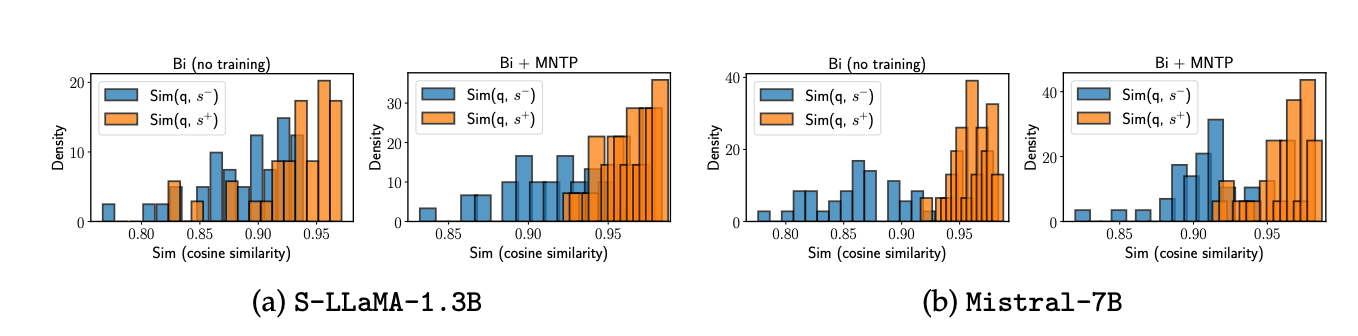
LLM2Vec을 통해 학습되는 것은 무엇인가?
-
B, C: 비슷한 의미의 문장
-
B, D: 다른 의미의 문장
-
A 문장의 토큰에서 pooling하여 representation을 산출
- Bidirectional이 잘된다면: q_i, s^+_i는 비슷한 Representation이어야 함. → 뒷문장의 정보가 A 문장으로 흘렀어야 함으로
-
모델 크기에 관계없이 MNTP 이후 pos와 Neg 간 거리가 벌어짐
- MNTP: 위치에 관계없이 Token들이 서로 attn하도록 학습
4-5. Analysis 2(why Mistral works)
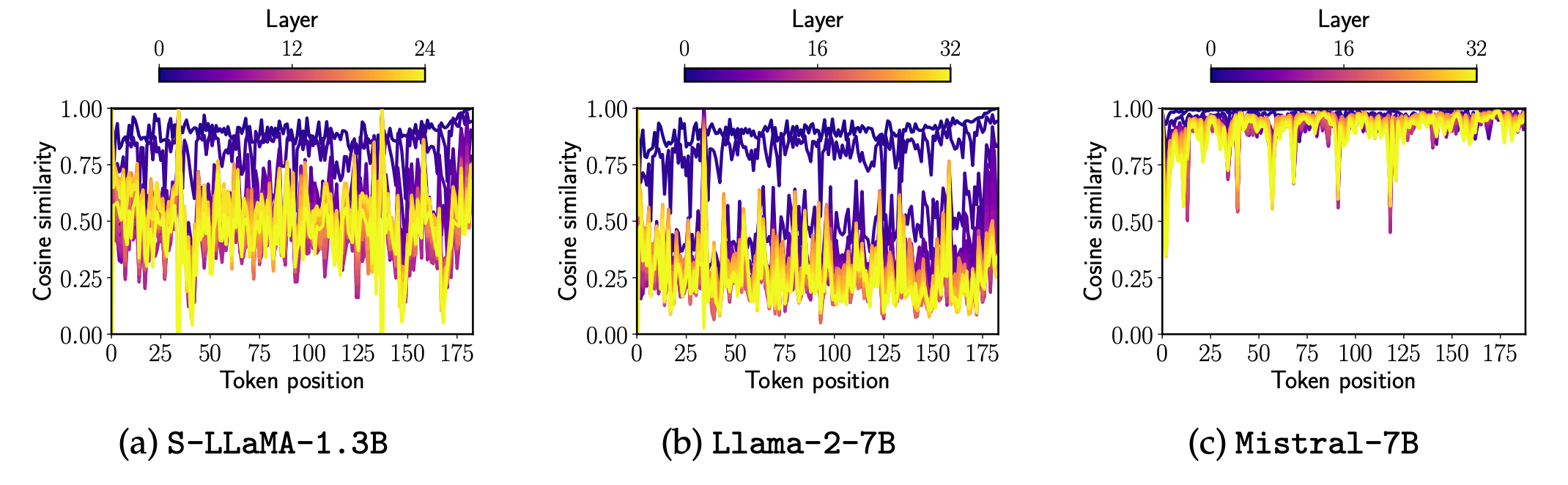
-
동일 데이터에 대한 original attention(llm)과 bi directional attention 시의 token/layer 단위 Representation 비교
-
sheared LLaMA, LLaMA 2 모두 상위 레이어로 갈수록 두 attn 간 다른 Representation이 생성됨
-
Mistral: bi directional attn 적용 시에도 모든 레이어에서 기존 attn과 비슷한 representation이 형성 됨
-
→ Mistral이 뭔짓을 한 것 같은데… 뭔지는 몰라유…
5. Conclusion
-
Decoder 모델을 Encoder로 전환하는 방법론 제안
- MNTP: NTP와 MTP 사이의 task
-
단순: 1,000 step, 128 batch size, 1 a100 80GB면 충분히 학습이 됨
-
범용: MNTP + SimCSE로 학습된 모델은 범용적인 encoder로서 사용 가능
- 다른 encoder 학습 방법론 역시 추가적으로 적용 가능 ⇒ MTEB 상위 모델 대부분의 baseline
-
Encoder Pretraian 시 scaling 효과가 없는 상황에서 Encoder 분야 향후 발전 방향
-
Decoder는 Scaling 효과가 있음
-
Scaling하여 Decoder 훈련 → LLM2Vec 적용 ⇒ Scaling 효과가 적용된 Encoder 개발 가능
-