Making Large Language Models A Better Foundation For Dense Retrieval
논문 정보
- Date: 2024-01-09
- Reviewer: 상엽
- Property: LLM, Retrieval
Introduction
-
dense retrieval : query와 document의 semantic 유사도를 반영할 수 있는 동일 latent space embedding을 만드는 것
-
활용처 : web search, open-domain QA, conversational system
-
Dense retrieval의 발전사
- Pre-trained Language model의 등장
- retrieval의 핵심인 backbone encoder : BERT, RoBERTa, T5
- Model size & training scale의 증가
-
accuracy, generality에 도움이 됨이 논문들을 통해 증명
-
Large Dual Encoders Are Generalizable Retrievers
-
Text Embeddings by Weakly-Supervised Contrastive Pre-training
-
C-Pack: Packaged Resources To Advance General Chinese Embedding
-
- LLM을 활용한 retrieval의 등장
-
LLM의 semantic understanding을 활용
-
modeling of complex query and document
-
document-level retrievers, because of context length of LLMs.
-
multi-task embedding model because of LLMs’ unprecedented universality and instruction following capability.
-
-
prompting과 fine-tuning을 활용한 여러 embedding 방법의 등장.
-
LLM을 활용한 기존 retrieval의 한계점
- LLM은 text generation을 위한 모델. → LLM의 embedding은 next-token 예측을 위해서만 사용됨. → local and near-future semantic of context
→ 진정한 의미의 LLM을 활용한 dense retrieval를 만들기 위해서는 global semantic about the entire context 필요
→ 이런 이유로 LLaRA 제안
-
Contribution
-
The first research work to adapt LLMs for the dense retrieval application.
-
LLaRA is designed to be simple but effective. (two simple pretext task → 성능 향상)
-
To facilitate the future research in this area, our model and source code will be made publicly available. (코드 공개)
-
Preliminary
Text embedding
-
tokenized sequence T:[\mathrm{CLS}], \mathrm{t} 1, \ldots, \mathrm{tN},[\mathrm{EOS}]
-
output embedding → text embedding 방법
-
Encoder 모델
-
CLS 토큰 임베딩만을 이용
-
mean pooling of output embedding
-
-
Decoder 모델
-
auto-regressive → CLS 토큰은 global context를 반영하지 않음.
-
special token [\mathrm{CLS}], \langle\backslash \mathbf{s}\rangle 이용.
-
-
RepLLaMA
-
LLaMA 모델을 backbone decoder로 활용
-
RankLLaMA (reranker)와 함께 text-retrieval 모델 제안
-
text embedding of RepLLaMA
-
InfoNCE loss를 이용해 학습.
LLaRA
-
LLM adatpeted for dense RetrivAl (LLaRA)
-
post-hoc adaptation of LLMs to improve their usability for dense retrieval.
-
extended training stage of the unsupervised generative pre-training.
-
**Objective **(remind)
-
The text embedding needs to represent the** semantic of the global context.**
-
The global context representation should facilitate the** association between query and doc**
-
-
Two pretext training tasks
-
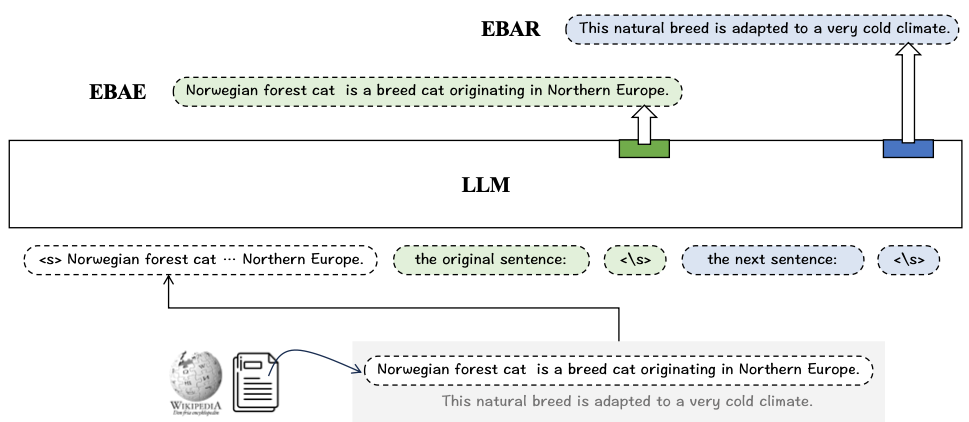
EBAE (Embedding-Based Auto-Encoding)
-
LLM is prompted to generate the text embeddings, which can be used to predict the tokens for the ***input sentence itself*.**
-
if the original input text can be predicted by e_t, the global semantic about the input text must be fully encoded by e_t. → objective 1
-
-
EBAR (Embedding-Based Auto-Regression)
-
LLM is prompted to generate the text embeddings, which can be used to predict the tokens for the ***next sentence*.**
-
Knowing that a relevant document is a plausible next-sentence for the query, **the association between query and document can be established by making representations for such a semantic. → **objective 2
-
-
-
Text embedding
-
EBAE template
- “[Placeholder for input] The original sentence: ⟨\s⟩”
-
EBAR template
- “[Placeholder for input] The next sentence: ⟨\s⟩”
-
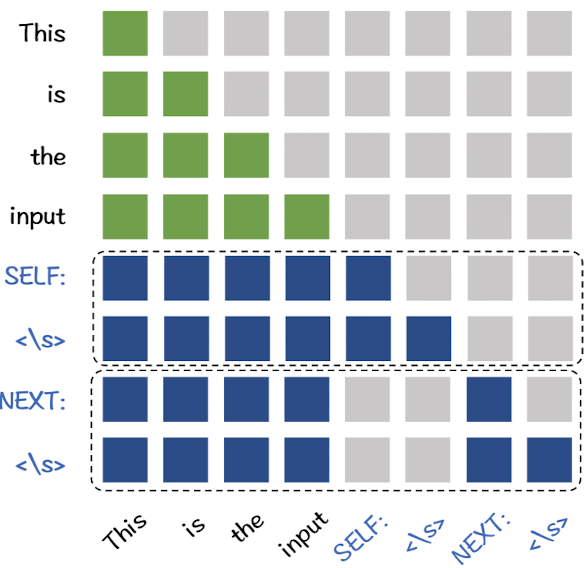
EBAE, EBAR decoding 과정에서 T를 중복으로 사용해 computation을 줄이자.
-
“[Placeholder for input] SELF ⟨\s⟩ NEXT ⟨\s⟩”
-
Attention mask를 아래와 같이 수정
-
-
-
Training objective
-
단순하지만 효과적이었던 목적함수
-
training of text embedding → multi-class classification 문제로 정의
-
\boldsymbol{W} \in \mathbb{R}^{ V \times d} -
T : collection of tokens of the input text itself or the next sentence
- V : vocabulary space
-
-
→ LLaRA 특장점
-
기존 LLM 모델에 추가적인 module을 필요로 하지 않음. sentence prediction은 LLM output 임베딩의 linear projection
-
competitive training efficiency : simple한 목적함수 + 뒷 부분에 등장하는 LoRA를 말하는 것으로 보임.
-
there is no need to collect any labeled data because LLaRA is performed purely based on the plain corpora.
Experimental Study
-
Settings
-
Fine-tuning for Information Retrieval : MS MARCO
-
generality : BEIR benchmark (zero-shot evaluation)
-
Training
-
base model : LLaMA-2-7b
-
dataset : wikipeida curated by DPR
-
RepLLaMA와 같은 방식으로 fine-tuning하지만 Hard negative만 사용.
-
-
-
Analysis
- MS MARCO, passage, document retrieval 모두에서 우수한 성능
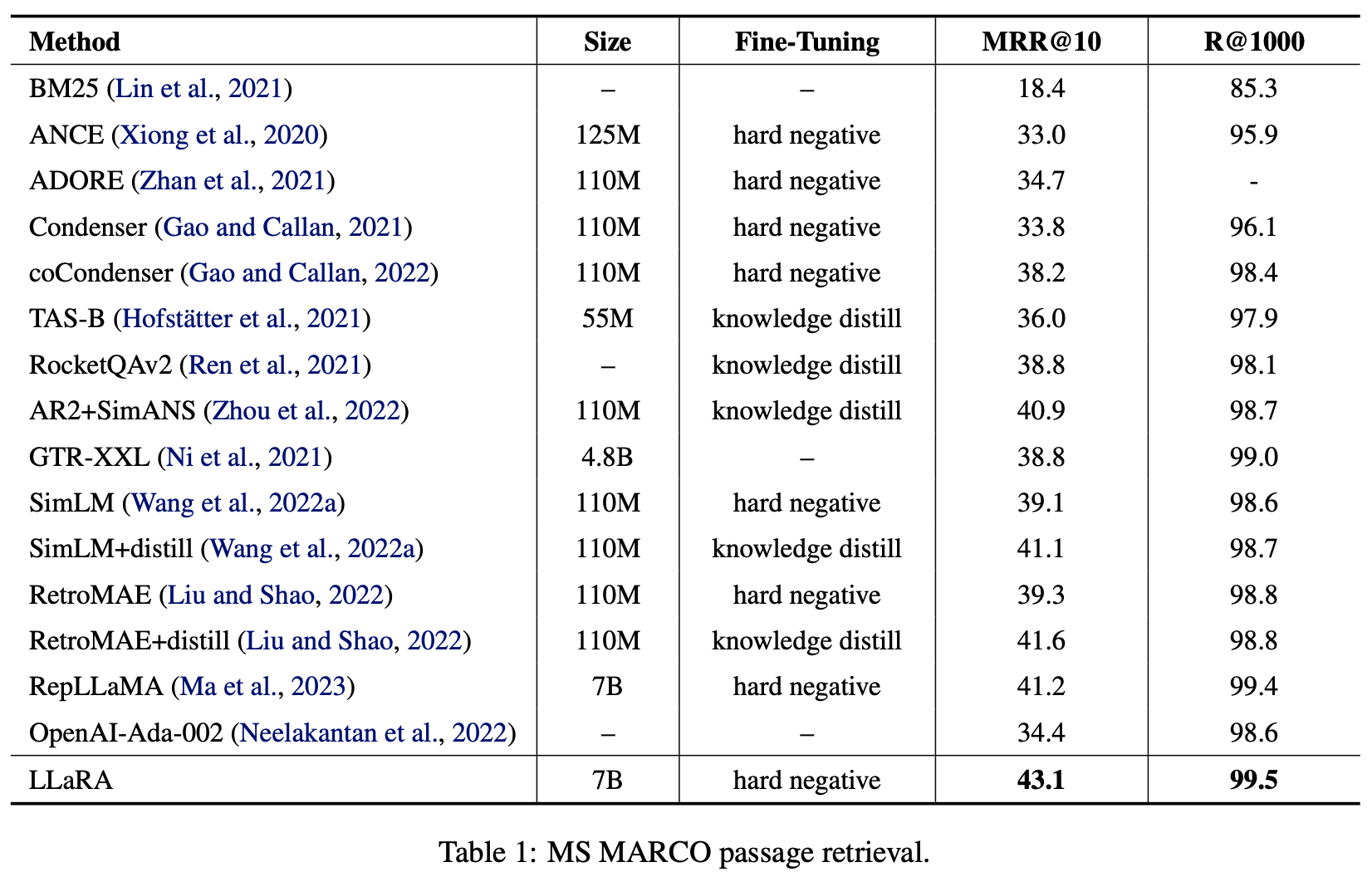
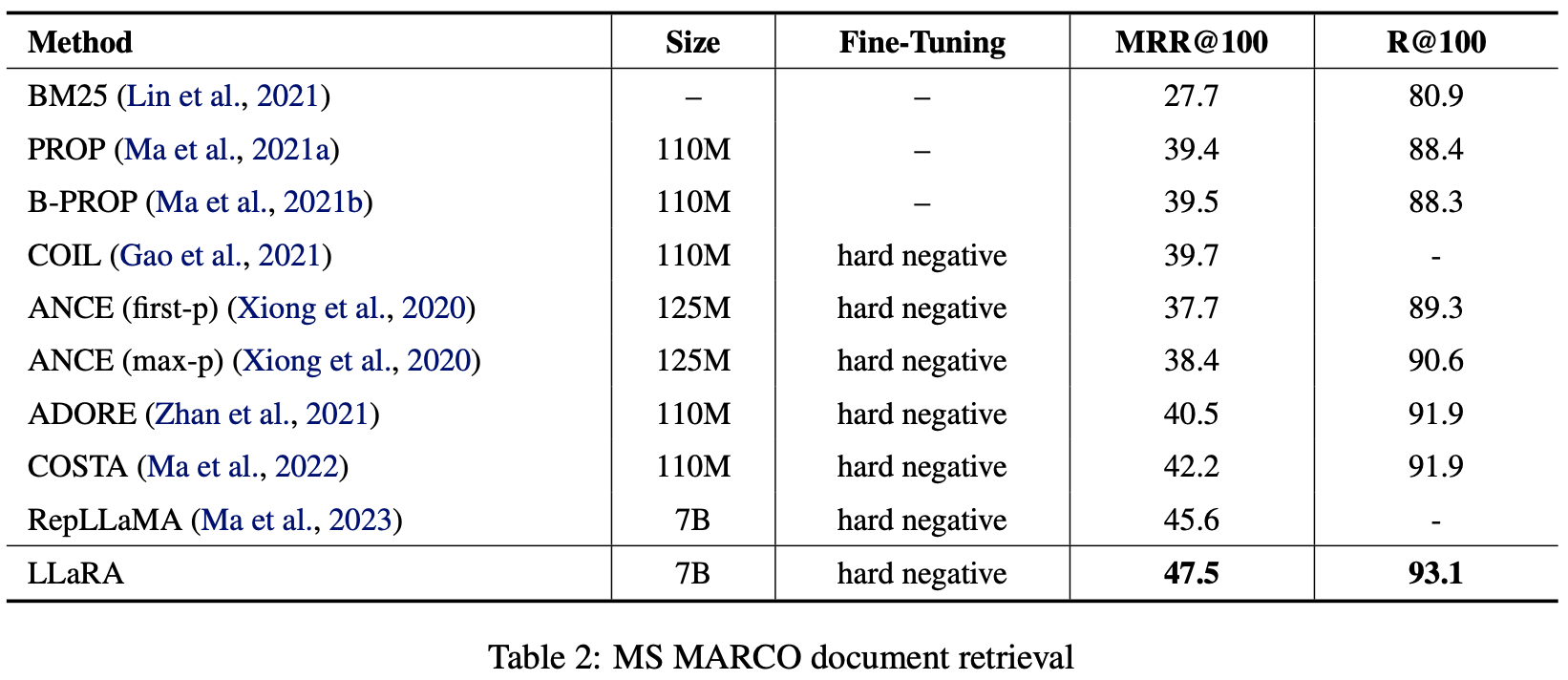
- BEIR 데이터셋에 대한 zero-shot retrieval 성능
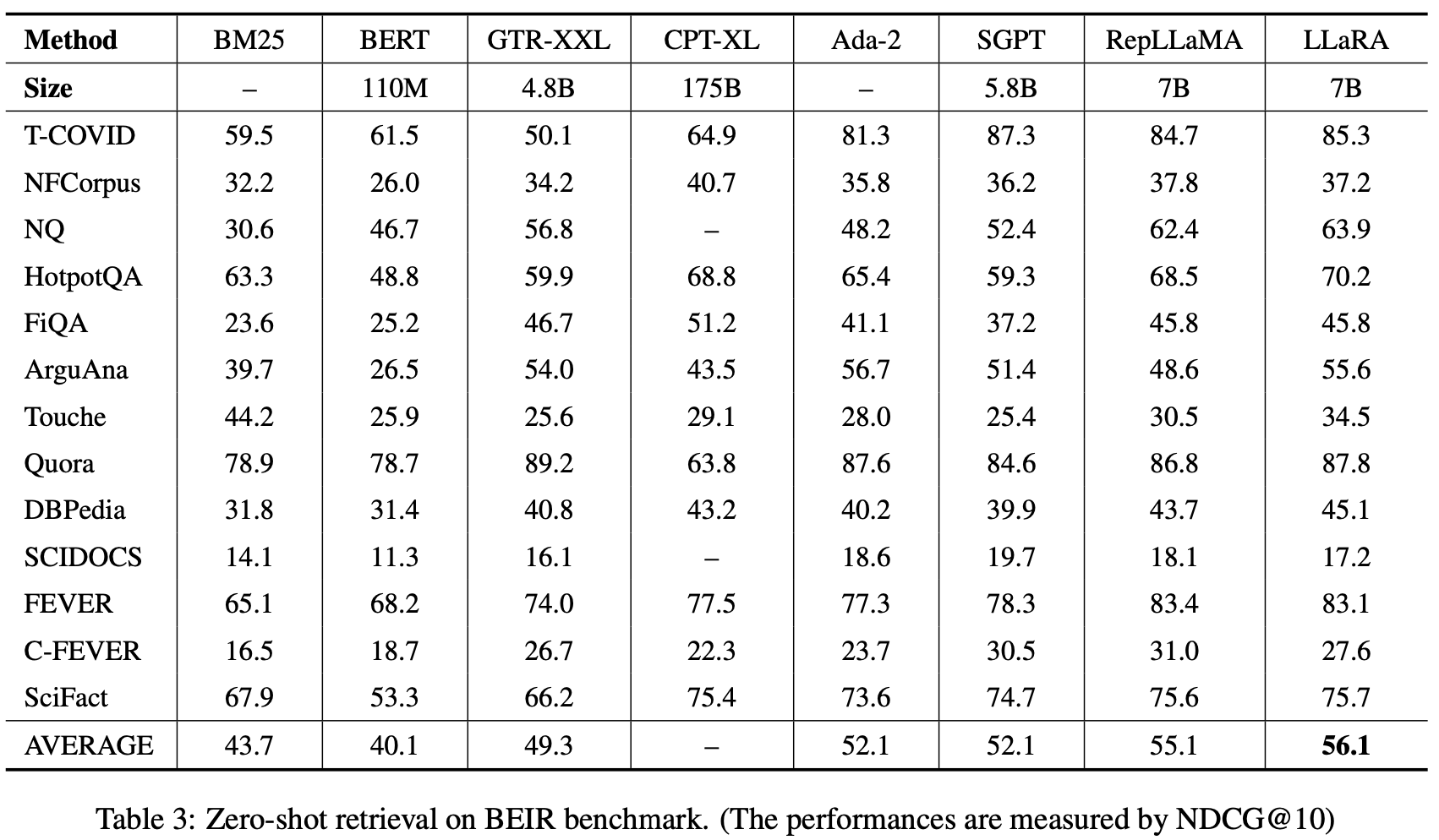
-
retrieval & rerank를 모두 사용하는 cross-encoder 모델 (Zhuang et al., 2023; Nogueira et al., 2019; Thakur et al., 2021)보다 성능이 뛰어나다고는 하나 표에는 없음.
-
BERT 계열 모델 : RetroMAE, SimLM보다는 월등히 뛰어난 성능
-
LLM 계열이 대체로 BERT보다 성능이 높음. (zero-shot에서 특히 차이가 심하게 나타남.)
-
LLaRA는 LLM을 이용하지만 Hard negative만을 이용해 간단히 학습가능하다는 점에서 메리트가 있다.
Conclusion이라기보다는 나의 의견
-
Unsupervised embedding + 간단한 목적함수로 학습 및 적용이 편할 거란 생각은 듦.
-
정말로 최초의 시도인지에 대해서는 잘 모르겠음. LLM을 어떻게 활용하는가에 따라 다르게 해석가능할듯.
-
코드가 나오면 한 번쯤 사용해보고 싶긴하다.
-
RepLLaMA + RankLLaMA는 retrieval + rerank까지 다 포함한 전체적인 IR 내용을 다뤘다면 여기는 Retrieval만 다루고 있음.
-
objective 2를 달성하기 위해 next sentence prediction을 활용하는 것에 대한 가정 “query → document (passage)로 이뤄진 문장 구조”가 얼마나 현실적인지는 모르겠다.
-
document retrieval로써 next sentence prediction의 효용은?
-
BAAI 그룹은 text embedding에 진심인 것 같다. (리더보드)