Many-Shot In-Context Learning
논문 정보
- Date: 2024-04-30
- Reviewer: 상엽
- Property: ICL
Introduction
ICL : input-output 예시로 부터 패턴을 학습하는 방법
LLM의 context window 길이 제한과 few-shot을 만드는 노력으로 인해 한정된 수로 진행
Many shot learning : 수백개 이상의 매우 많은 shot을 이용한 ICL 방법
논문에서는 아래 3가지에 대한 실험을 진행.
- In cotext example의 수가 다양한 downstream task의 LLM 성능에 미치는 영향
-
math problem solving using MATH (Hendrycks et al., 2021) and GSM8K (Cobbe et al., 2021)
-
question-answering (GPQA, Rein et al., 2023)
-
summarization using XSum (Narayan et al., 2018) and XLSum (Hasan et al., 2021)
-
algorithmic reasoning (Big- Bench Hard, Suzgun et al., 2022)
-
outcome reward modeling (Code verification, Ni et al., 2023)
-
low-resource machine translation (FLORES, Goyal et al., 2022)
-
planning (Logistics, Seipp et al., 2022)
-
sentiment analysis (FP, Malo et al., 2014)
→ few-shot과 비교했을 때 상당한 성능 향상을 보임. (Gemini 1.5 pro 수십만개의 sample)
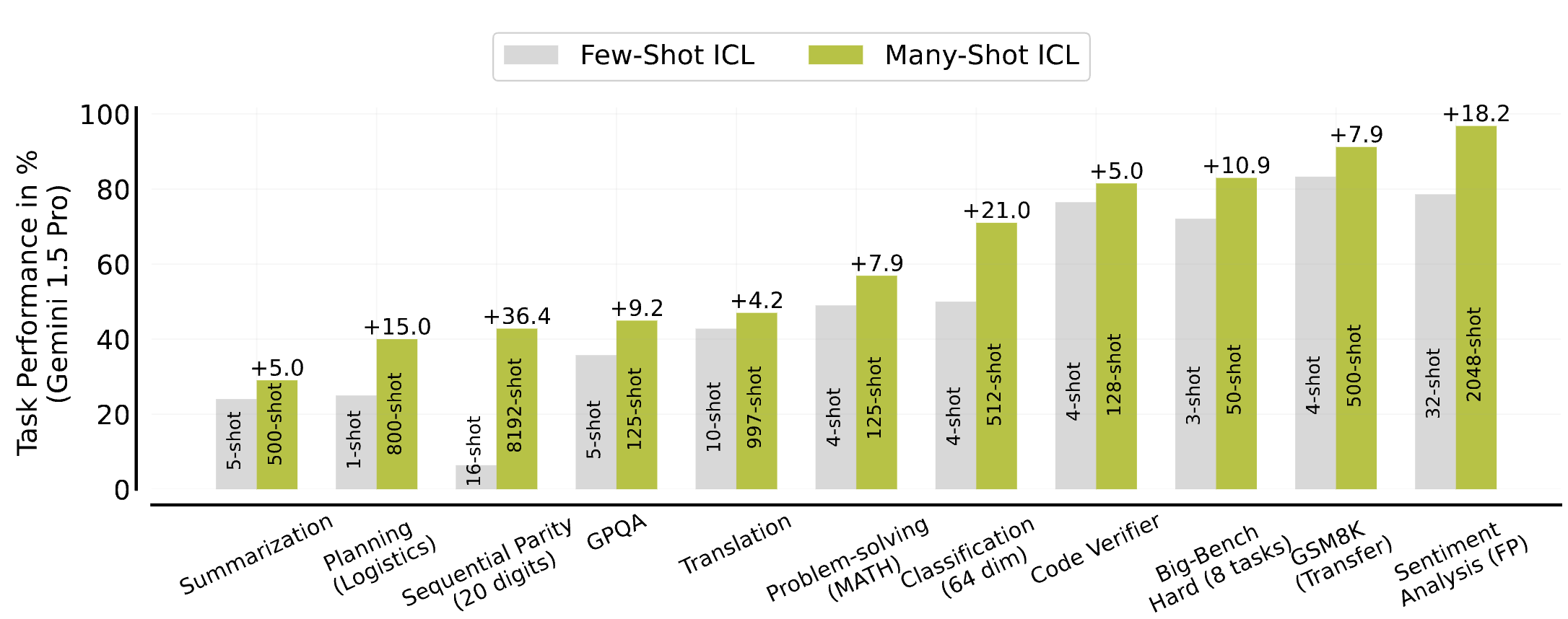
- Many-shot을 만들기 위한 리소스 한계 → 이를 해결하기 위한 방법 두 가지 탐색
-
reinforced ICL
- Inspired by the efficacy of model-generated solutions for fine-tuning (Singh et al., 2023) → 사람이 쓴 rationales → model이 만든 것 (정답을 맞춘 rationales을 이용)으로 바꾸자.
-
unsupervised ICL
- Inspired by task-recognition view of ICL (Xie et al., 2021) → 정답 없이 오직 문제만으로 ICL 구성
- Few-shot → Many-shot으로 갈 때 ICL의 learning dynamic을 확인
-
pre-training biases를 극복
-
high-dimensional prediction tasks 해결
-
the order of examples의 수는 many-shot에서도 여전히 중요한 영향을 미침.
-
next-token prediction loss가 ICL에 미치는 악영향
Contribution
-
Scaling In-Context Learning (ICL) : 여러 scale의 examples을 실험해봤으며 many-shot으로 가며 엄청난 성능 향상이 있음을 보임.
-
Reinforced and Unsupervised ICL : model을 활용해 사람의 개입없이 ICL을 하는 방법의 효과성을 보임
-
Analysing ICL : few-shot의 한계점을 극복할 수 있음을 보임 (pre-training biases & non-natural language prediction tasks)
Related Work
Scaling in-context learning
-
Brown et al. (2020), Lu et al. (2022) : example 수의 증가는 성능을 향상 시킨다.
-
context의 한계로 1000개 이상의 example을 사용한 실험은 진행되지 못함.
-
Li et al. (2023) : 1.3B 모델을 이용해 2000개의 example을 사용함. → 매우 제한된 환경, 많은 task를 수행하지 못하는 매우 작은 모델
→ 우리는 8192개 example까지도 사용했으며 여러 task에서 다 검증했다!
Long-context scaling laws
- Prior works (Anil et al., 2024; Gemini Team, 2024; Kaplan et al., 2020; Xiong et al., 2023)에서 context의 길이가 길어질수록 next-token prediction loss가 줄어듦을 보임.
→ 우리의 실험 결과도 이를 뒷받침함 + 성능과 상관없이 next-token prediction loss가 계속 줄어드는 것을 확인, next-token prediction loss를 long-context 성능 평가에 이용하는 것은 별로라 생각함.
Learning from self-generated data
-
Numerous recent works (Gulcehre et al., 2023; Singh et al., 2023; Yuan et al., 2023)에서 self-generated 데이터를 이용해 모델을 fine-tuning하는 것의 효과성을 보임.
-
샘플 생성, binary feedback을 이용한 데이터 필터링
-
위의 샘플을 활용해 fine-tuning
-
위의 과정 반복
-
→ 이것을 ICL에도 활용 (Reinforced ICL)
Self-generated data and in-context learning
- Kim et al. (2022) : self-generated 데이터를 ICL에 활용해 분류 문제 해결, test input이 가질 수 있는 레이블에 맞춰 예시 생성
→ test input에 접근없이 데이터를 생성 (Singh et al. (2023)) 어떤 문제에도 적용이 가능하게 함.
Learning Input-Output Relationships with ICL
-
Numerous works (Kossen et al., 2023; Lin and Lee, 2024; Min et al., 2022; Yoo et al., 2022) : input-output 관계를 ICL에 이용
-
Min et al. (2022) : ICL의 label을 랜덤하게 섞어도 성능에 큰 영향을 주지 않았음을 발견
-
Yoo et al. (2022) and Kossen et al. (2023) : 모델 사이즈와 task에 따라서 위의 결과가 항상 맞지는 않더라.
-
Lin and Lee (2024) : LLM이 많은 examples을 ICL에 이용한다면 input-output 관계를 배우긴 하더라.
→ 충분히 많은 example을 이용한다면 pre-training biases를 극복할 수 있음을 보였음.
Scaling In-Context Learning
Evaluation details
-
Gemini 1.5 Pro1 MoE model 이용 (1M 토큰 context 길이)
-
특별히 언급이 없다면 greedy decoding 이용.
-
K-shot examples 랜덤 샘플링 및 여러 랜덤 시드를 이용한 다수 실험 진행 후 평균을 report 함.
Machine Translation (MT)
-
샘플의 수 에 따른 성능 영향을 확인하기 위해 low resource 번역 task 수행
-
구글 번역기와 LLM 사이에서 가장 큰 성능 차이를 보였던 Tamil, Kurdish 선택
-
1 ~ 997개까지 실험 진행
-
chRF : standard MT metric 이용.

- Many-shot에서 google translate보다 우수한 성능을 보임.
Summarization
-
XSum task from the GEM benchmark
-
ROUGE-L을 이용해 평가
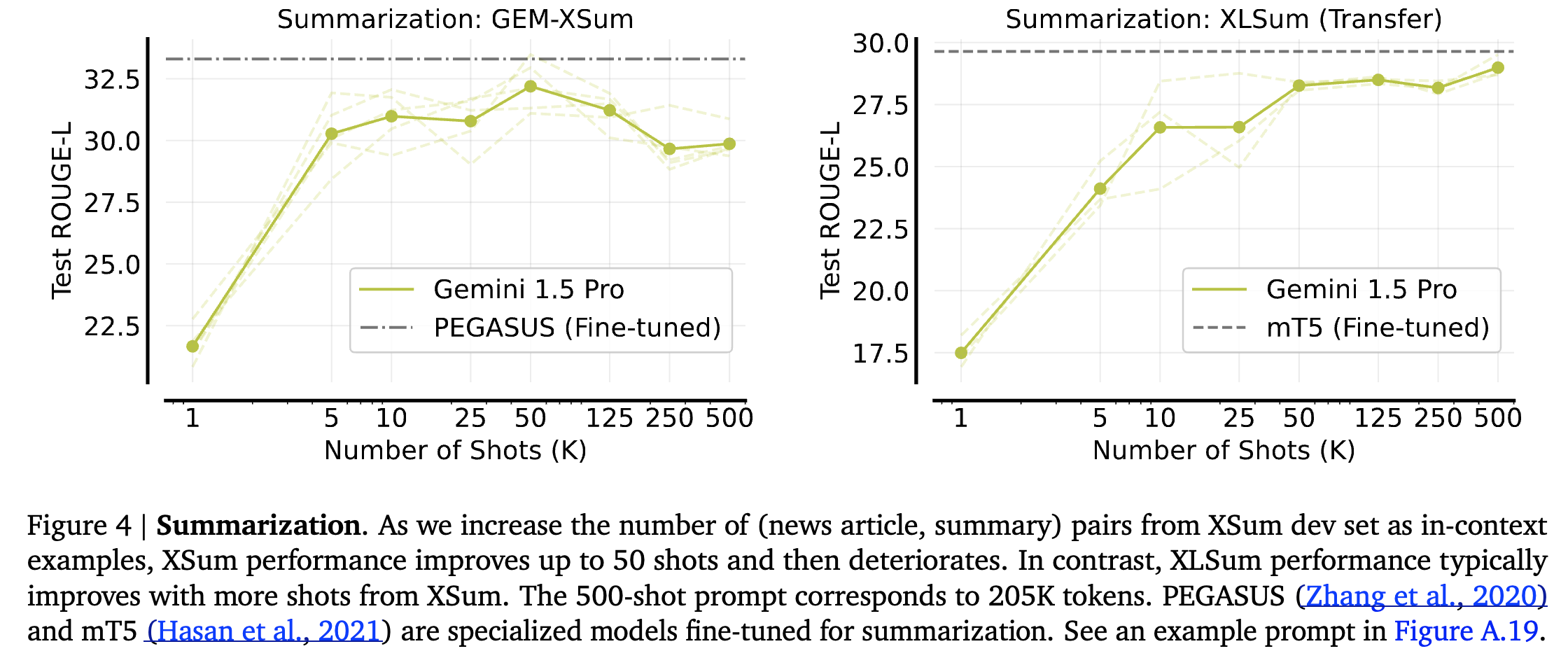
-
XSum과 XLSum task에 fine-tuned된 summarization 모델과 유사한 성능 향상을 보임.
-
Many-shot에서 날짜와 숫자에 관한 Hallucination이 빈번하게 발생했지만 성능 자체는 높아짐. (이유는 설명하지 못함.)
Planning: Logistics Domain
-
Commonsense planning (경로 최적화 문제)
-
도시 내 패키지 배달은 트럭으로 도시 간 패키지 배송은 비행기로 진행, 2~3개의 도시 1~2 패키지, 1 트럭, 도시당 비행기 1대 세팅으로 여러 가지 문제 상황을 제시
-
Fast-Downward planner를 이용해 few-shot 생성
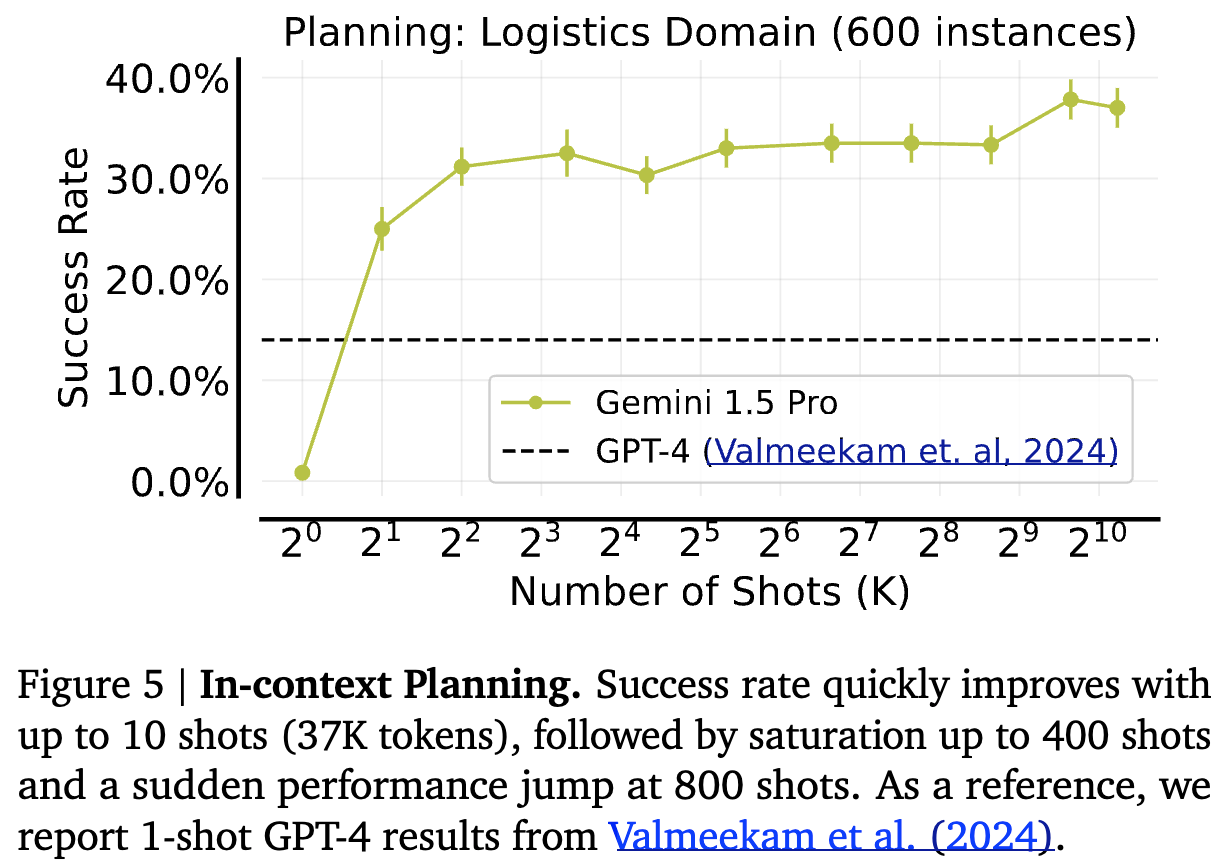
- GPT-4조차 못하던 task에서 상당한 성능 향상을 보임.
Reward Modeling: Learning Code Verifiers In-Context
-
LLM reasoning을 향상시키는 방법 중 standard는 test-time verification
-
LLM이 여러 답변을 생성
-
사전 학습된 verifier (reward model)이 답변을 rank
-
-
verifier를 LLM으로 하여 성능을 평가, 문제는 code verivication
-
평가 절차
-
gemini 1.0 Pro를 이용해 code-based 문제 추출 (correct/incorrect)
-
문제를 prompt에 example로 이용 “Is the solution correct?” Yes/No
-
test set에 대해 Yes/No 확률을 noramalize해서 사용.
-
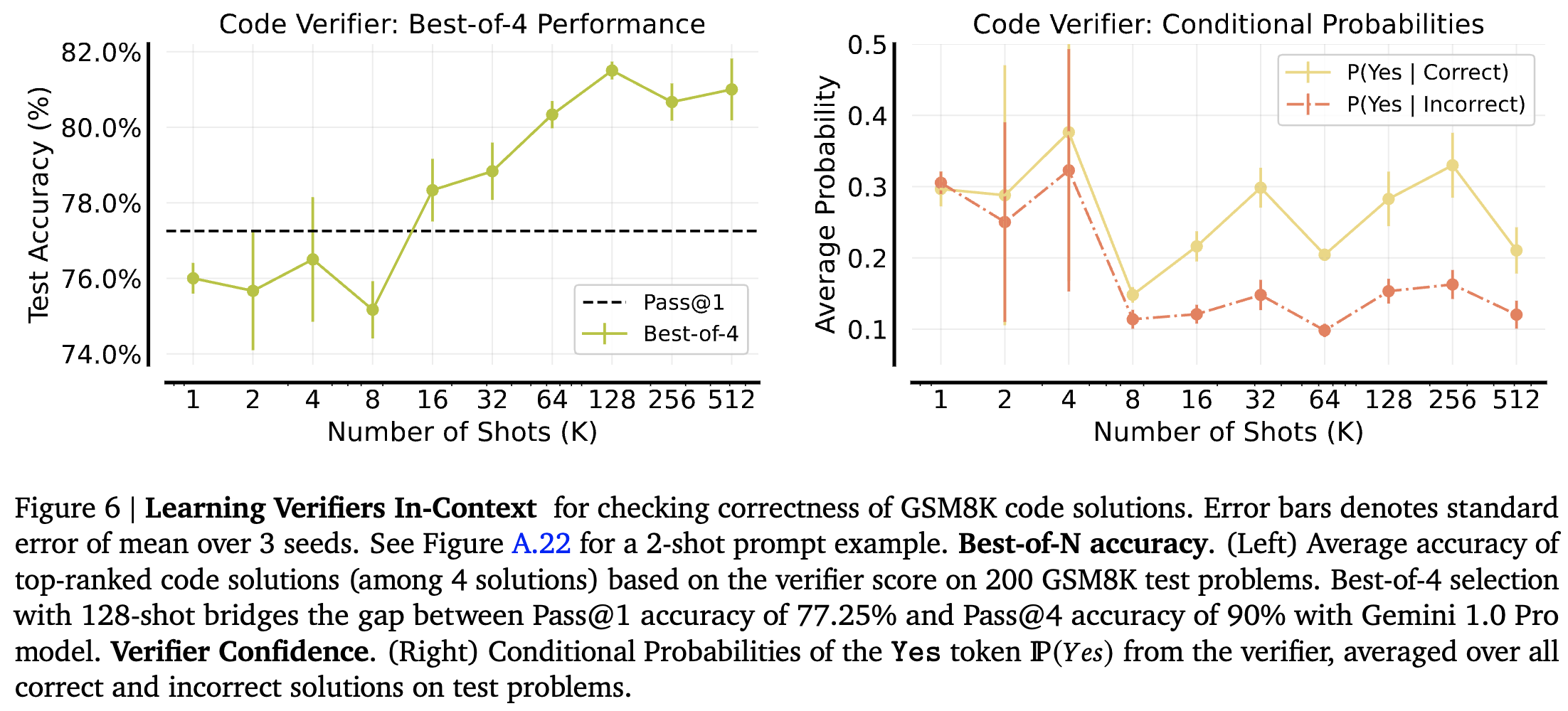
-
200개의 problem 중에 verifier를 이용해 4개를 선정 : Best-of-4
-
Pass@k : k 중에 하나라도 성공할 확률
-
Test accuracy : Best-of-4 중에서 최고로 뽑힌 하나의 성능
-
-
Left : 16개 이상부터 Pass@1 이김, 지속적인 성능 향상 (Pass@4 acc : 90%)
-
Right : verifier confidence
Many-shot Learning without Human-Written Rationales
복잡한 reasoning task를 동반하는 경우 example을 만드는 것은 매우 어려움.
이를 해결하기 위한 두 가지 방법 제시
Reinforced ICL
-
Reinforced Self-Training (ReST)
-
모델에 의해 생성된 rationales이 사람이 만든 rationales보다 더 효과적일 수 있음
-
Expectation-maximation for RL을 적용하는 것으로 간주할 수 있음? - 잘 모르겠음.
-
-
위를 토대로 model-generated rationales을 ICL에 이용하겠다.
-
Few-shot/Zero-shot CoT 프롬프트를 starting point로 이용해 다수의 rationales 추출
-
정답을 맞춘 rationales만 선별해 ICL example로 이용 (problem, rational pairs)
-
False positive : rationale이 틀렸지만 정답을 맞은 경우에 대한 문제는 뒷 부분에서 discussion (돌이켜보니 discussion이 없던데)
-
Unsupervised ICL
-
rationales이 없다면 어떨까? - 오직 input(problem)으로만 ICL에 이용해보자.
-
다음과 같이 prompt 구성.
-
preamble (such as, “You will be provided questions similar to the ones below:”)
-
List of unsolved inputs or problems
-
zero-shot instruction or a few-shot prompt with outputs for the desired output format.
-

-
가설 : task를 해결하기 위한 지식을 이미 가지고 있다면 prompt에 주어지는 문제는 task를 위해 필요한 지식이 무엇인지를 구체화해줄 수 있을 것이다.
-
스포) 대부분의 task에서 효과가 있었지만 output이 중요한 몇 가지 task에서는 성능이 좋지 않았다.
- low-resource machine translation (좀 당연한 문제!)
문제 난이도가 높아 실제로 사람이 examples을 생성하는 것이 어려운 문제들을 선택
Problem-solving: Hendrycks MATH & GSM8K
-
Unsupervised ICL에는 unsolved problem 이후에 4-shot exmple 추가
-
ICL (Ground-Truth) : 사람이 쓴 example 이용
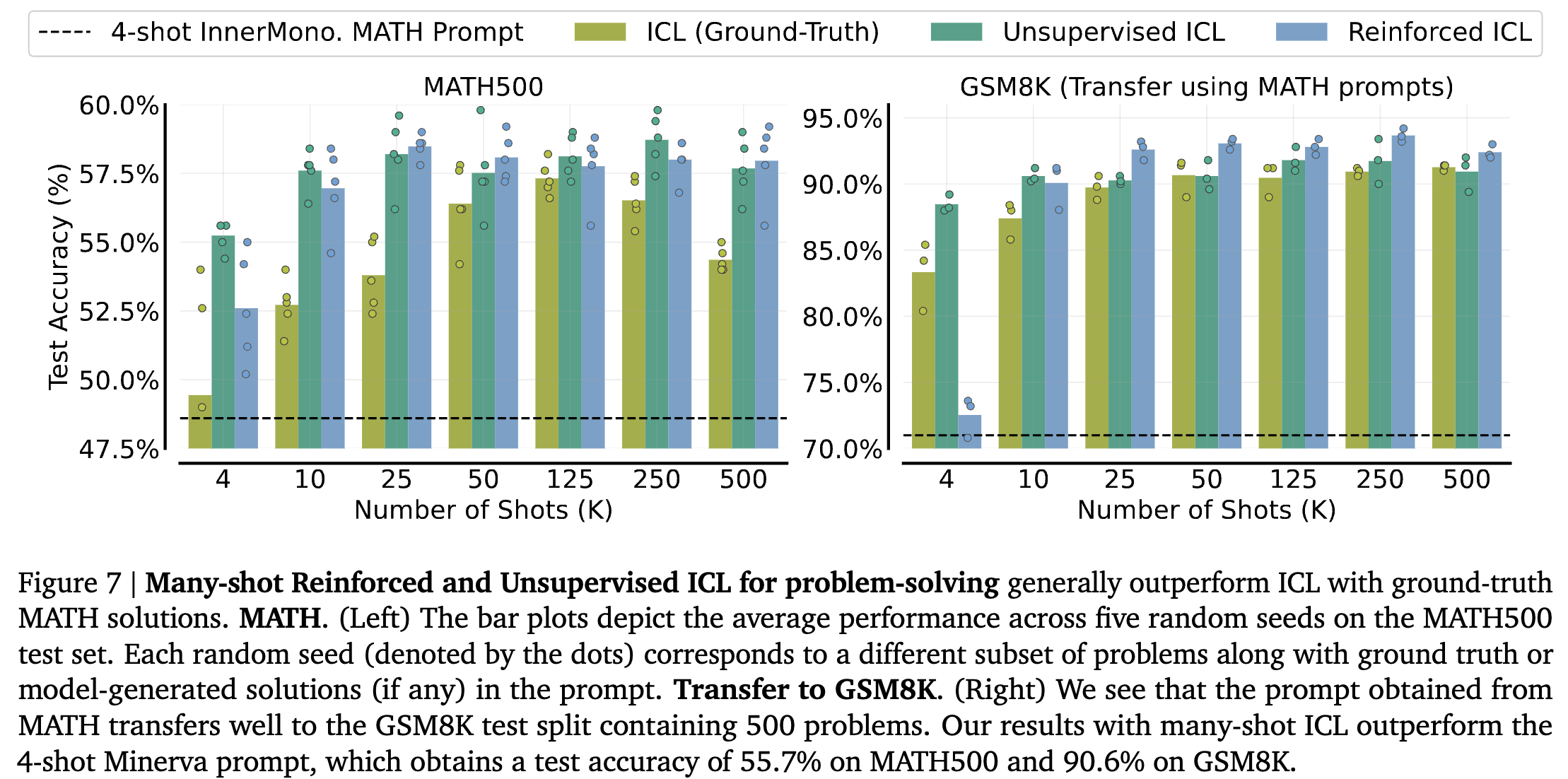
-
Left
-
제안하는 두 방법이 사람이 작성한 ICL을 능가함.
-
example이 많아질수록 그 차이는 커진다.
-
ICL과 달리 performance drop이 없다. (사람한테 500개나 문제를 풀라고 하면 drop 될듯)
-
-
Right
-
Singh et al. (2023)의 연구에서 MATH500으로 fine-tuning한 모델이 GSM8K 데이터에서 성능 향상을 보임. (OOD 문제 해결력)
-
Many-shot ICL에서도 transfer의 효과를 보이며 ICL (groun-truth)를 outperform
-
Question Answering: Google-Proof QA (GPQA)
-
대학원 수준의 생물학, 물리학, 화학 분야의 어려운 multiple choice QA benchmark
-
Diamond set : 도메인 전문가들은 풀지만 비전문가들의 경우 30분 이상 풀지 못하는 문제
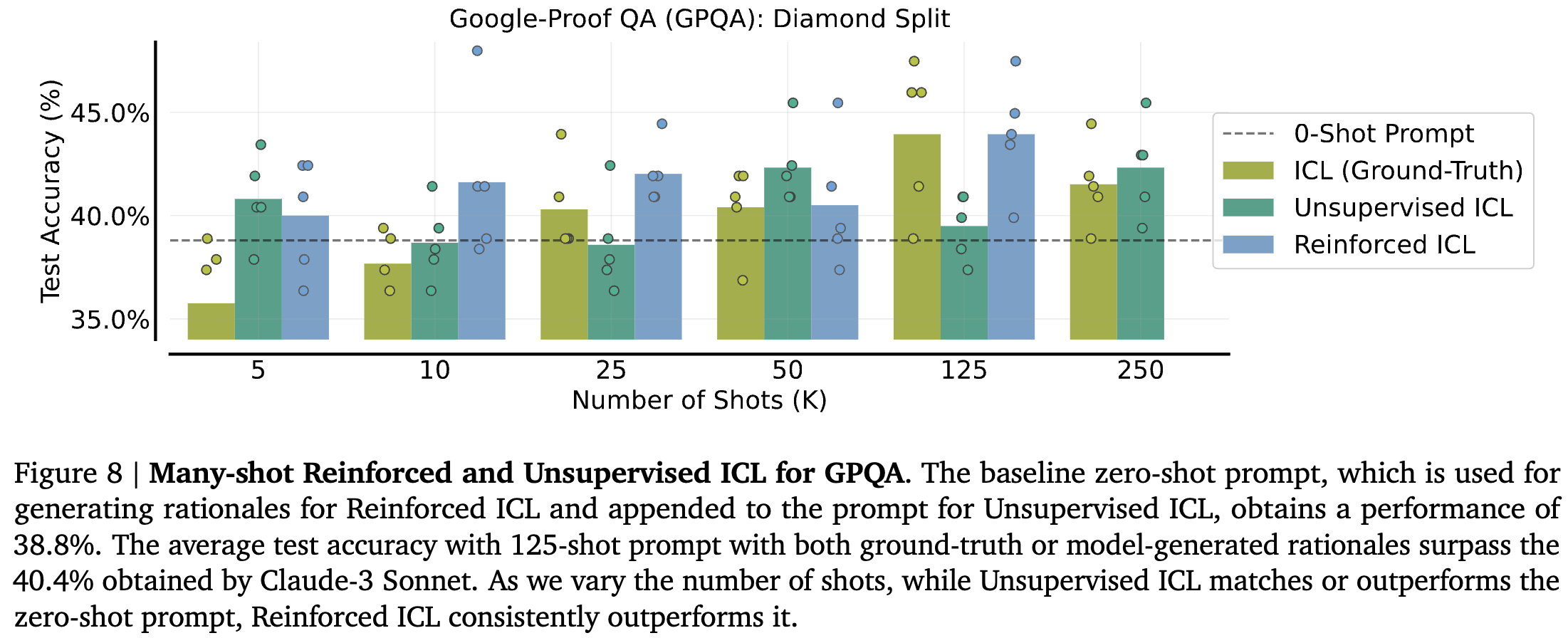
-
evaluation data가 적기 때문에 trend 확인은 어려웠다.
-
일관성 있는 결과를 보이지는 않지만 제안 방법들이 효과가 있다는 것은 보인다.
Algorithmic and Symbolic Reasoning: Big-Bench Hard
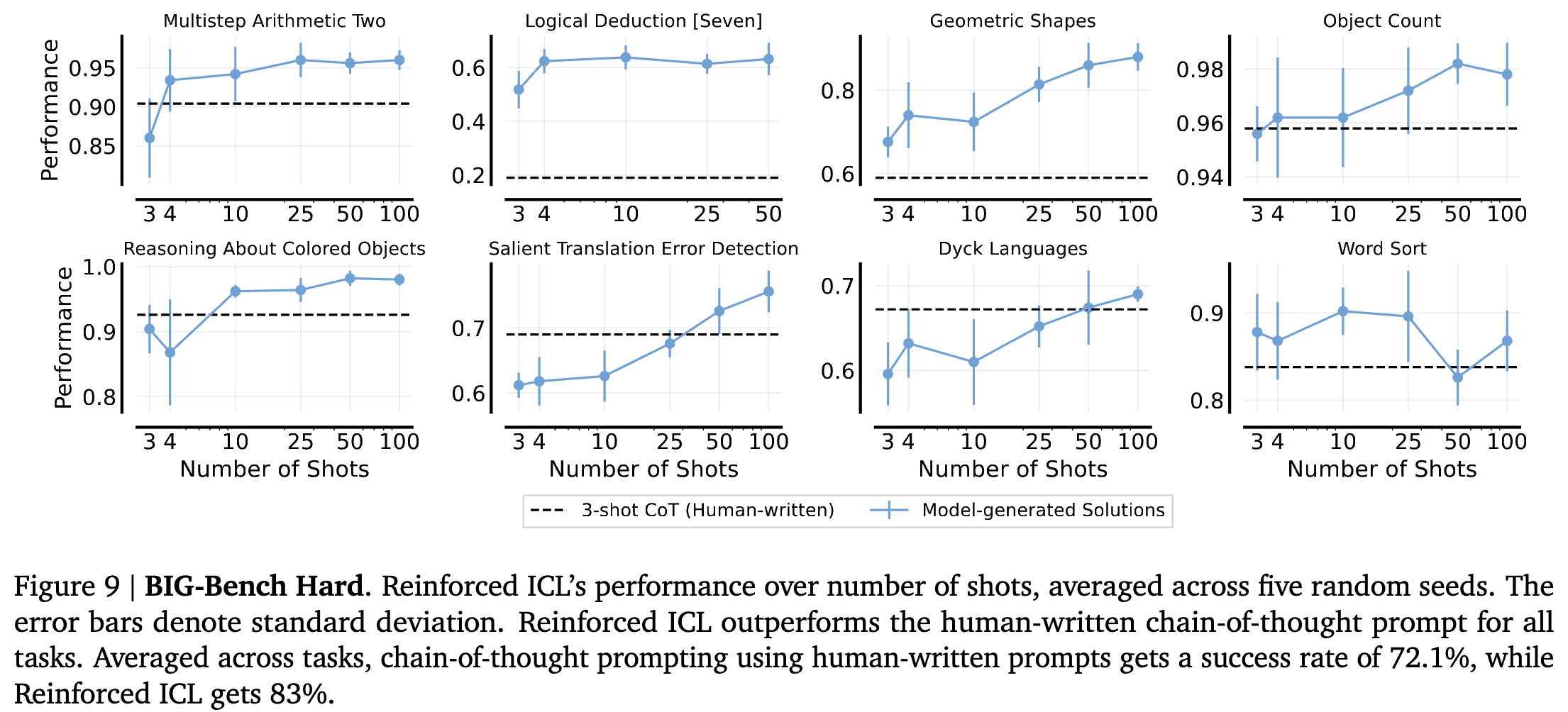
-
False positive 이슈가 큰 15개 task를 제외한 8개만 선정 (answer string이 길거나 정답의 옵션이 6개 이상인 것.)
-
3-shot CoT 프롬프트를 이용해 문제당 10 rationales를 생성, 정답이 맞는 것들만 골라서 3 ~ 100개씩 늘려가며 실험 진행
-
Model-generate Solutions > 3-shot CoT (Human-written)
-
(??) 왜 Unsupervised는 왜 없지
Analyzing Many-Shot In-Context Learning
Overcoming Pre-training Biases with Many-Shot ICL
-
ICL이 새로운 task를 배우는 능력은 보였지만 pre-training data로 부터 습득된 biases를 unlearning하는 것은 어려움을 겪음.
-
Few-shot이 아닌 Many-shot에서는 어떨까?
-
두 가지 label relationship 고려
-
Flipped Labels: Default labels are rotated
-
Abstract Labels: Semantically-Unrelated labels (e.g. “positive” → “A”)
-
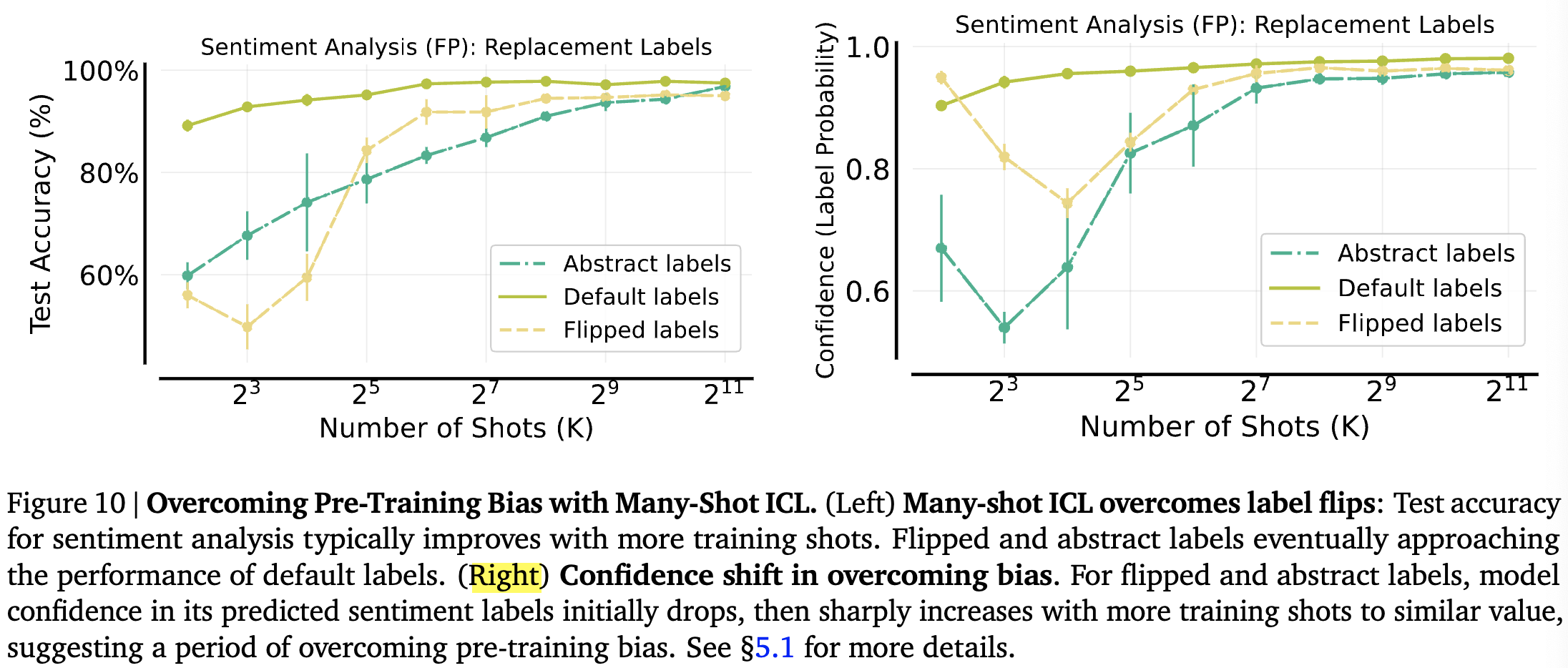
-
Left
-
few-shot일 때 정확도가 엄청 낮아지는 것은 확인
-
of shot이 증가함에 따라 성능이 원래의 성능에 수렴함.
-
-
Right
-
default에서 example 증가에 따라 confidence도 증가
-
충분히 많은 example을 제공할 경우 biases를 극복할 수 있다.
-
Learning Non-Natural Language Tasks
- 언어가 아닌 추상적인 수학적 함수를 학습하는 능력을 테스트
Linear Classification in High Dimensions
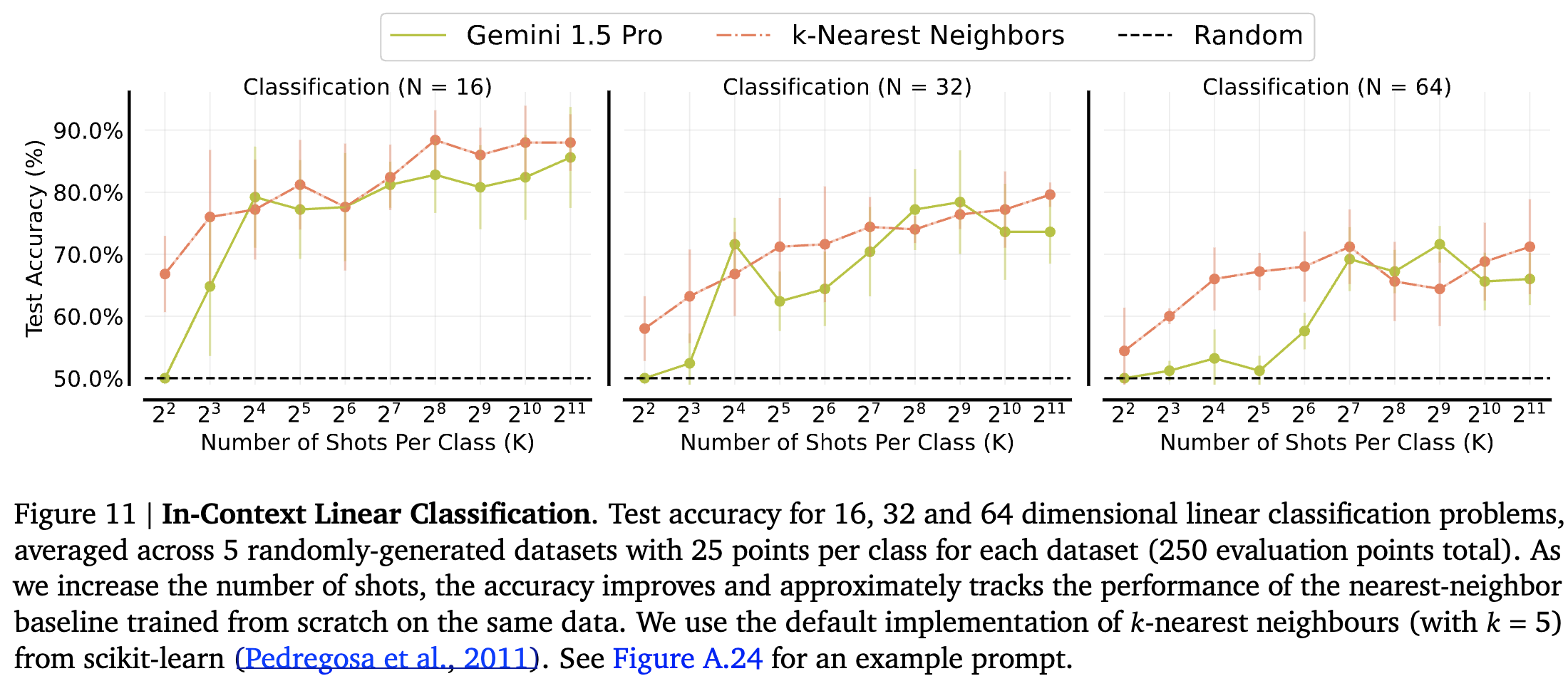
-
고차원 linear classification 실험
-
1 ~ 1000까지의 랜덤 정수로 이뤄진 N차원 벡터를 이용해 데이터셋 생성
-
hyperplane N차원 A vector를 이용해 데이터셋과 곱한 후 threshold 값을 기준으로 레이블을 결정
-
unseen sample에 대해 label을 맞출 수 있는지 평가
-
-
랜덤은 outperform, KNN과는 거의 같거나 때로는 높은 수준의 성능 달성
Sequential Parity
-
Parity : Boolean 함수, input sequence에서 1의 수가 짝수인지 홀수인지
-
ex) 1 → Odd, (1, 0) → Odd, (1, 0, 1) → Even
-
기존 LLM에서는 20개 이상을 넘어간 parity function에 한계가 있었음.
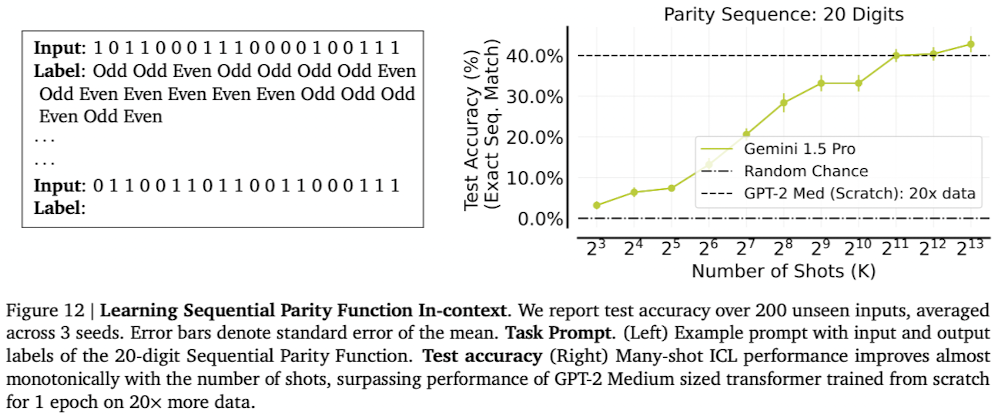
- shot 증가 → 성능 증가
Is Many-Shot ICL Sensitive to Example Ordering?
-
ICL에서 example의 순서가 성능에 미치는 영향이 매우 컸음. → many-shot에서는 어떨까?
-
고정된 50개 examples을 순서를 바꿔가며 실험 진행
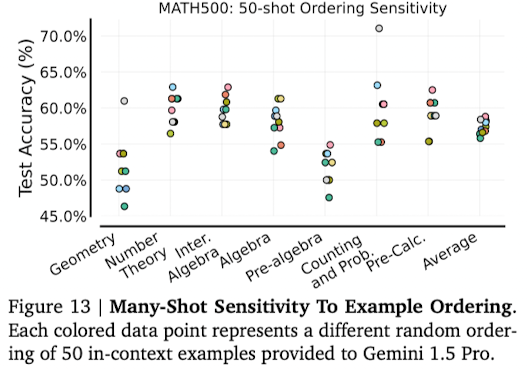
-
결과를 봤을 때 어떤 순서가 모든 task에서 더 우수하거나 하는 경향성은 전혀 없었음.
-
Geometry에서 제일 좋았던 순서가 Number theory에서는 제일 안좋기도 함.
-
여전한 Challenge이다.
NLL May Not Be Predictive of ICL Performance
-
Anil et al., 2024; Kaplan et al., 2020; Xiong et al., 2023의 연구에서 negative log-likelihood (NLL)이 context 길이 증가에 따라 감소하는 것을 확인
-
many-shot context learning에서도 이런 양상을 발견함. (GPQA, Hendrycks MATH and GSM8K)
-
하지만 NLL의 감소가 downstream task의 성능 향상을 보장하진 못했음.
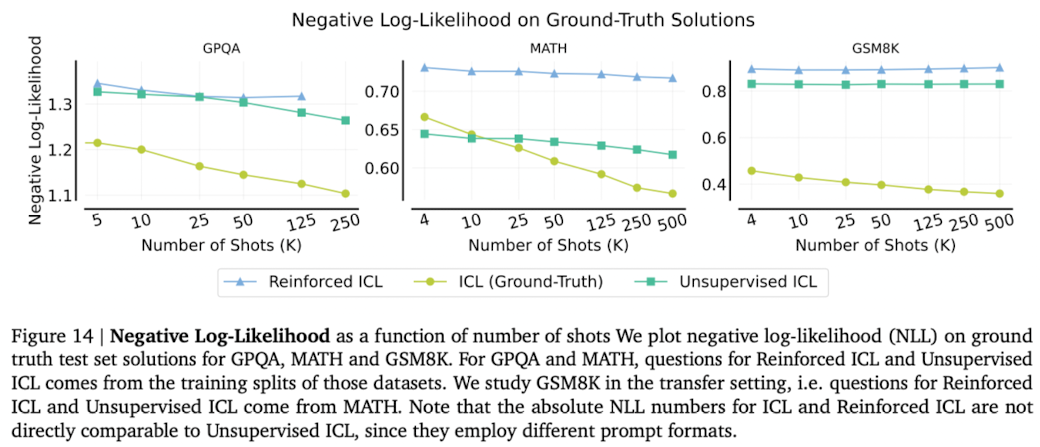
-
Reinforced & Unsupervised ICL에서 NLL 감소는 좀 더 적었다.
-
위의 결과들을 종합했을 때 test set의 분포에서 벗어나 프롬프트의 사용은 NLL의 downstream task에 대한 예측력을 해치는 요인이 되는 것으로 추정됨.
→ 결론적으로, 저자는 문제 해결력을 요구하는 복잡한 task에서 NLL이 final performance를 예측하기에 신뢰성이 부족하다.
→ 직관적으로 문제를 해결하는 과정은 여러 가지 방법이 있는데 이를 하나의 로그 가능성에 fitting하는 것이 최선의 결과가 아닐 수 있다라고 생각함.
Limitations
-
Gemini 1.5 Pro만 사용했음.
-
왜 더 많은 examples을 사용할 때 성능 감소가 발생하는지에 대해 이해할 방법이 없다.
Context가 길어지면서 ICL을 Fine-tuning의 특징과 연결지어 해석하려는 여러 논문들이 나오고 그 시리즈 중의 최고 길이의 실험.
방대한 실험을 수행함.
기존 논문들에서 발견한 ICL의 트렌드와 이슈들을 하나씩 검증해본다는 점에서 흥미롭다.
ICL (Groud-Truth)가 성능이 덜 좋을 수는 있지만 0-Shot보다 안좋을 수 있는가? (GPQA)
many-shot의 ordering을 본다고 했을 때 50개면 이전 실험에 비해 너무 적은 것은 아닌가?
많은 해석과 생각이 있을 것이라 생각했지만 섹션 4까지는 거의 실험 결과 나열이라는 점은 좀 아쉽.
가끔 몇몇 문장이 전혀 이해가 안될 정도로 쓰여 있어서 reference까지 찾아봐야 했음.