Preference-free Alignment Learning with Regularized Relevance Reward
논문 정보
- Date: 2024-04-02
- Reviewer: 준원 장
- Property: Reinforcement Learning, Alignment
0. Preliminary
- Preference
: prompt, pair of responses가 있는 (x, y{w}, y{l})에 대해서 y{w} > y{l} 을 보이는 setting
-
x : 된장찌개를 끓이는 방법을 알려줘
-
y_{w} : 된장찌개를 끓이는 법은 다음과 같습니다. 1. 재료를 준비합니다. 재료는…
-
y_{l} : 된장찌개를 끓이는 법은 다음과 같습니다. 1. 뚝배기를 한대..
에 대해서 y{w} > y{l} 을 보이는 setting
PPO (Chat-GPT Training)
- SFT
→ Instruction Tuning Data로 Pre-trained Model 학습
- Reward Model Training
→ 어떤 text prompt에 대한 응답(response)를 LLM(large language model)이 예측했을 때, 그 응답에 대한 reward score(보상 점수)를 예측하도록 Reward Model을 학습.
→ Using the Bradley-Terry Model to estimate the pairwise loss. (가장 기본)
class PairWiseLoss(nn.Module):
"""
Pairwise Loss for Reward Model
"""
def forward(self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor) -> torch.Tensor:
probs = torch.sigmoid(chosen_reward - reject_reward)
log_probs = torch.log(probs)
loss = -log_probs.mean()
return loss
- PPO
→ PPO를 학습하기 위해서는 3개의 Model이 필요함 (Trainable SFT(RLHF할 SFT), Frozen SFT, Reward Model)
3.1. 학습하고자하는 text prompt에 대해서 (1) Trainable SFT와 Frozen SFT logit outputs 사이의 KL-Divergence 계산 (2) Trainable SFT(RLHF할 SFT)의 text output을 Reward Model에 넣어서 reward score을 계산 (3) (1)+(2)를 더해서 PPO의 Reward를 계산
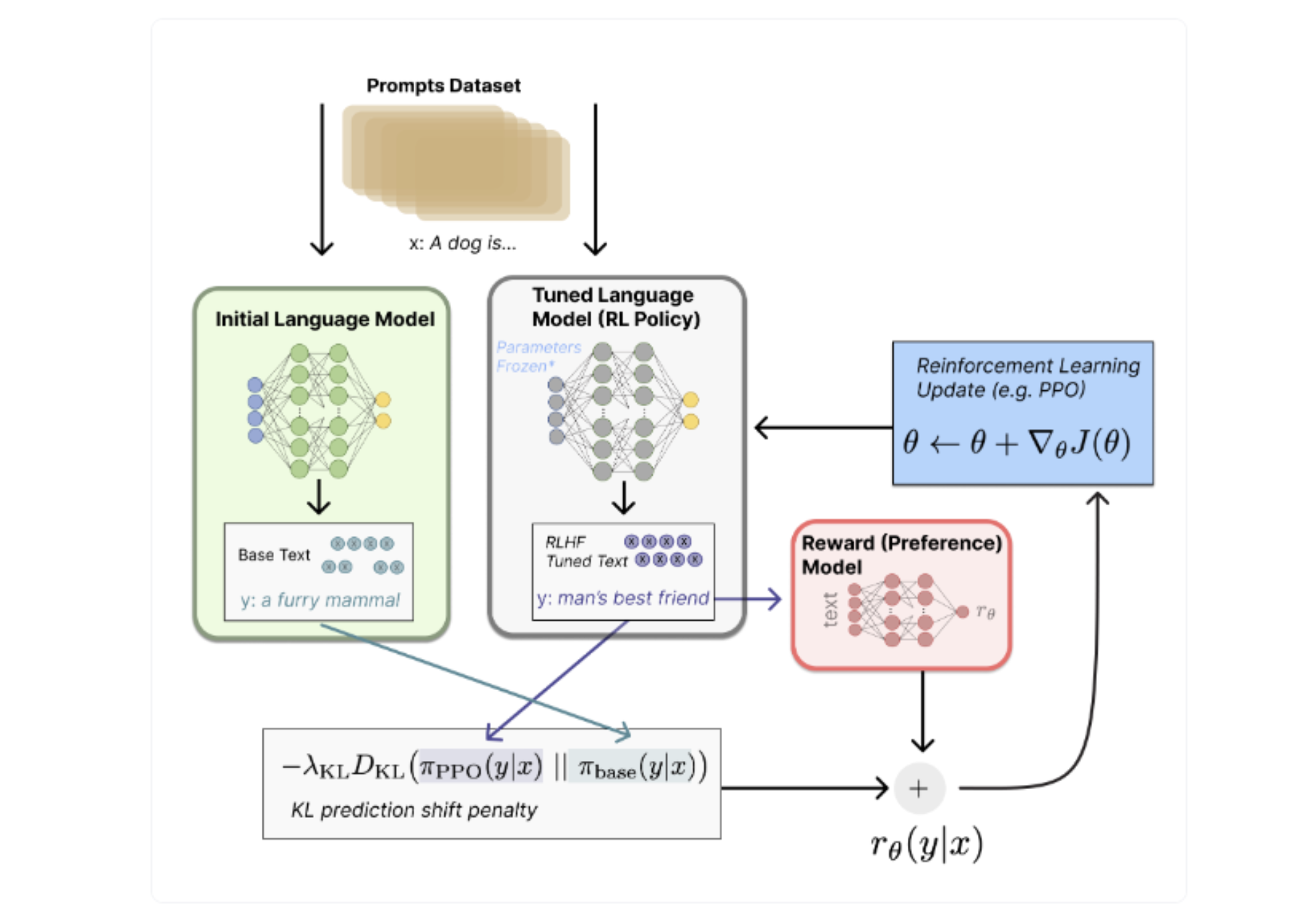
3.2. Ratio (New probs [학습하고자하는 text prompt에 대한 Trainable SFT(RLHF할 SFT)의 확률 값] / 학습하고자하는 text prompt에 대한 [Frozen SFT]의 확률)가 특정 범위 (0.8~1.2)에 일때만 학습이 되도록.
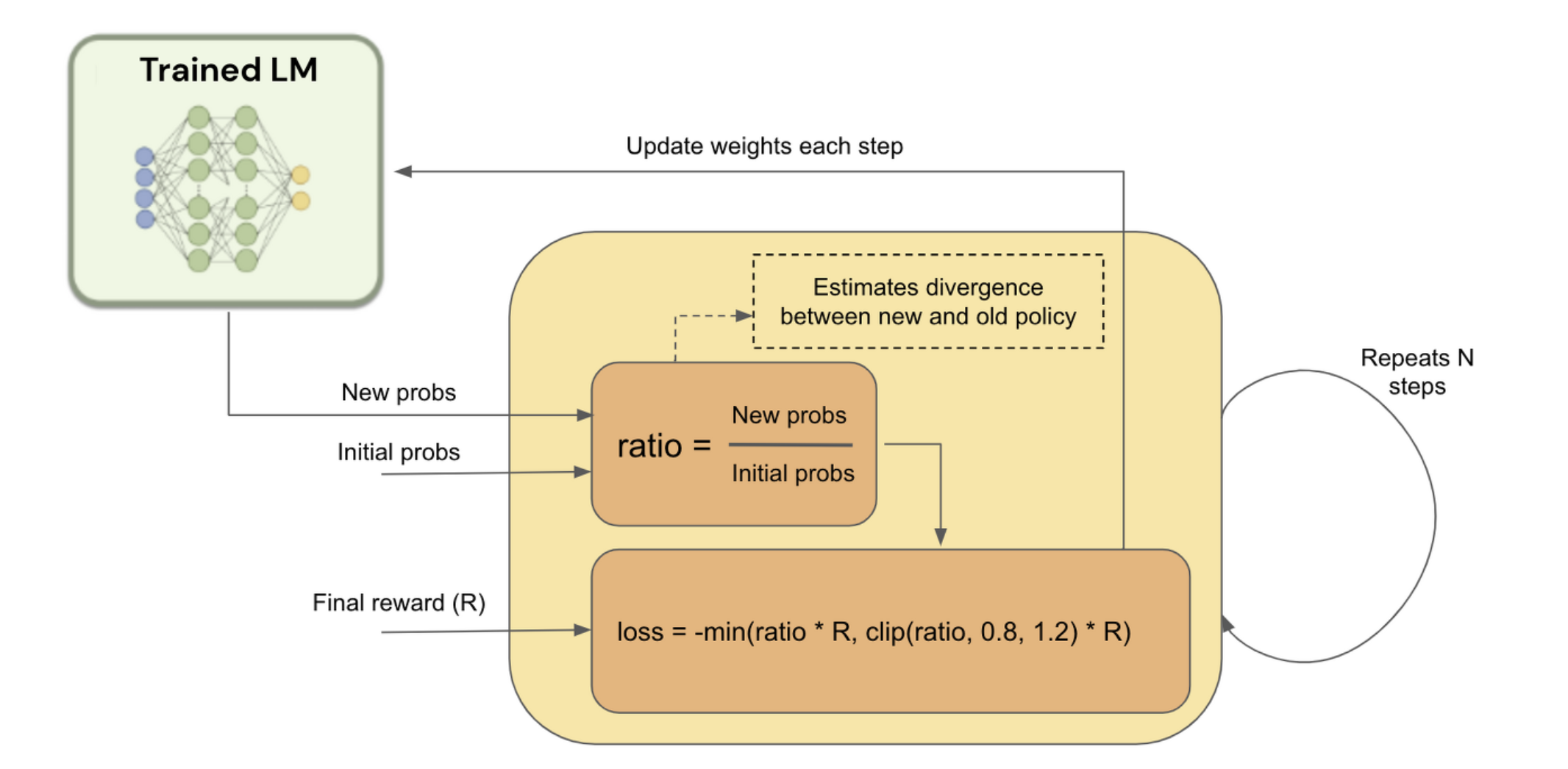
class PolicyLoss(nn.Module):
"""
Policy Loss for PPO
"""
def __init__(self, clip_eps: float = 0.2) -> None:
super().__init__()
self.clip_eps = clip_eps
def forward(self,
log_probs: torch.Tensor,
old_log_probs: torch.Tensor,
advantages: torch.Tensor,
action_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
ratio = (log_probs - old_log_probs).exp()
surr1 = ratio * advantages
surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages
loss = -torch.min(surr1, surr2)
if action_mask is not None:
loss = masked_mean(loss, action_mask)
loss = loss.mean()
return loss
DPO (Omit Reward Modeling)
: Clipping을 차용한 RLHF objective를 다음과 같은 수식으로 쓸 수 있음
→ DPO의 목적은 Reward Modeling training 없이 Pairwise triplet으로 Trainable SFT를 직접 Alignment Training할 수 있다를 수식적으로 증명+실험적으로 보인 논문.
- 수식 전개


→ Policy의 Ratio에 따라 Bradley-Terry Model에 부합하는 목적함수를 설계할 수 있게되며, Triplet을 직접 활용해 SFT Model을 직접적으로 학습할 수 있다.
1. Introduction
-
서두에 언급했듯이, RLHF나 대안인 DPO가 LM에 직접적인 pairwise human feedback을 주입하기 위해 활용된다.
-
논문에서는 human feedback이 가지고 있는 선천적인 한계점/bias을 지적한다.
- crowd source worker (concise하고 specificity 선호)랑 expert (factuality하고 completeness선호)의 preference 다름.
⇒ 이에 따라 human-preference로 training된 open-source RMs들이 주어진 input들에 대해서 on-topic인지 아닌지 구분하는 능력이 떨어진다고 함 (준원생각: 일관된 Reward signal을 주지 못함) [하단]
⇒ 반면, Contriever같은 unsupervised retriever들은 주어진 input들에 대해서** relevant한 대답**을 구분하는 능력을 가지고 있음. [상단]

-
Relevance를 Reward Signal로 주어서 LLM의 Alignment를 human preference 없이 증가시켜볼 수 있지 않을까?
-
이를 위해 Relevance에 대한 정의부터 하고 넘어감
as the degree to which an assistant system’s responses are appropriate and directly connected to the specific needs or requests presented by the users.
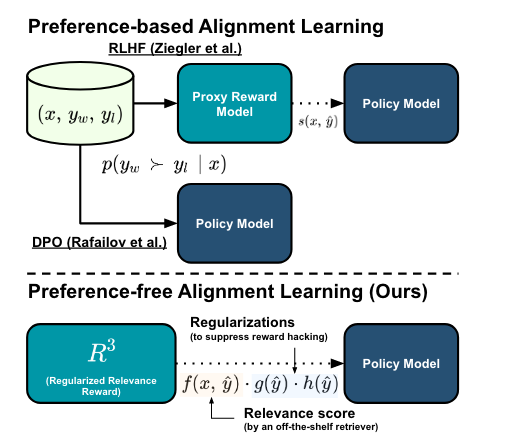
-
제안하는 방법론은
-
RLHF 방법론과 다르게 preference dataset이 필요하지 않다는 장점이 존재함
-
다양한 heuristic을 넣어서 Reward Hacking을 방지
-
다른 PPO 방법론들과 다르게 답변이 길어질수록 Relevance가 떨어지지 않음
-
Preference로 학습함에 따라 다른 NLP Downstream Task 성능이 하락하는 ‘Alignment Tax’에 강건함
-
2. Motivation and Preliminary Study
-
Relevance는 정의상 User의 Specific한 Need나 Request에 얼마나 적절한 답변을 할 수 있는가를 측정하는 척도이다.
-
Reward Model 관점에서 논문에서는 2가지 Research Question을 던진다.
1. 현존하는 Open-Source RMs들이 Relevance를 capture하는가?
-
PopQA에서 popularity가 1K이하인 530 entities에 대해서 (query, relevant response, irrelevant response triplet 구축)
-
irrelevant는 GPT API로 관련 없는 entity에 대해서 생성하도록 지시
(“Please tell me about {entity}”)
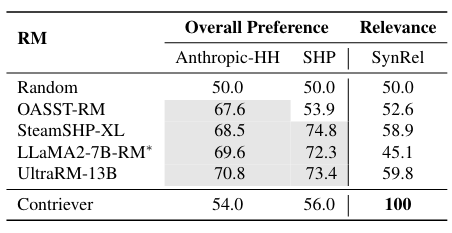
[회색: Anthropic-HH, SHP training set으로 학습한 RM, * 자체적으로 학습한 RM]
⇒ Anthropic-HH & SHP이 Human preference를 반영하는데에는 적합하더라도, trivial한 relevance는 capture하지 못한다.
2. Relevance가 Alignment를 위해서 좋은 지표인가?
-
Contriever를 직접적인 RM으로 사용해서 Reward Signal을 줘보자
-
x : query
-
\hat{y} : rollout response in the exploration stage of PPO
-
M(x) \cdot M(\hat{y})\rightarrow r_{x}\in \R^{1} : M is contriever
-
Anthropic-HH dataset 사용, Vicuna Bench
-
Preference가 Reward Training 이후 증가했는지 평가
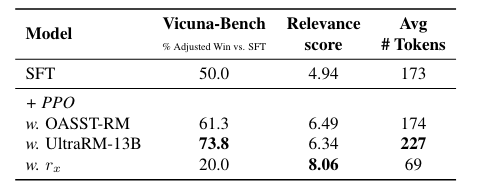
[For a fair comparison with the open-source RMs, we train SFT model based on LLaMA-2-7B (Touvron et al., 2023) with the 161k chosen responses in Anthropic-HH]
⇒ Contriever reward가 preference를 약화시킨다.
⇒ 또 해당 reward는 relevance는 높지만, response 길이가 짧다.
[Reward Hacking (agent가 편법과 같은 의도하지 않은 방법론을 통해 목표를 달성하는 것) 발생 → 40%가 question을 그대로 copy and paste하도록 LMs을 training하는 signal을 주었다고 함]
3. R^3: Regularized Relevance Reward
- 이전에 언급한 문제들을 해결하기 위해 다양한 Regularizing 기법들을 Reward Function에 주입하기 시작.
Length Incentive (LI)
-
r_{x} 가 response를 짧게하는 것을 방지하기 위함
-
LI(\hat{y})= \frac{# words \ of \ \hat{y}}{100}
-
주어진 query와 무관하게 longer generation을 하도록
Repetition Penalty (RP)
-
Length Incentive를 걸어두면 query랑 똑같은 문장을 계속 반복생성하는 Reward hacking이 일어남.
-
unique trigram을 보장하는 아래의 reward를 추가함
-
RP(\hat{y})= \frac{# unique \ trigram \ of \ \hat{y}}{# \ trigrams \ of \ \hat{y}}
⇒ r_{x} \cdot LI(\hat{y})\cdot RP(\hat{y})
-
높은 relevance
-
긴 generation
-
less repetition
Reference Answer Relevance (r_{y})
- Contrained/Factual한 Response를 요구하는 Query에서 여전히 Diverse한 답변을 생성하는 위의 Reward는 치명적일 수 있음
⇒ Closed Answer를 요구하는 Query에는 Relevance하고 간결하게만 답변하도록 Modeling해야 함.
-
저자들은 Open-ended/Closed Ended Query에 대해서 다른 Reward를 적용함.
-
F(r{y}) \ ,where \ M (y) · M (\hat{y}) → r{y}: 범위 맞춰주는 interpolation function
⇒ Mixture of Reward Function, Only needs SFT dataset!
Query Type Classification
-
저자분들도 Open-ended vs Closed Ended Query 구분 주관적이라고 인정
-
100개정도 GPT-4로 구분했을 때 83% 정확도 나왔고 사내 LLAMA2로 구분했을때 만족할만한 성능이라 사용했다고 보고.
PPO Training
4. Results
4.1 R^3가 human preference를 증가시키는가?
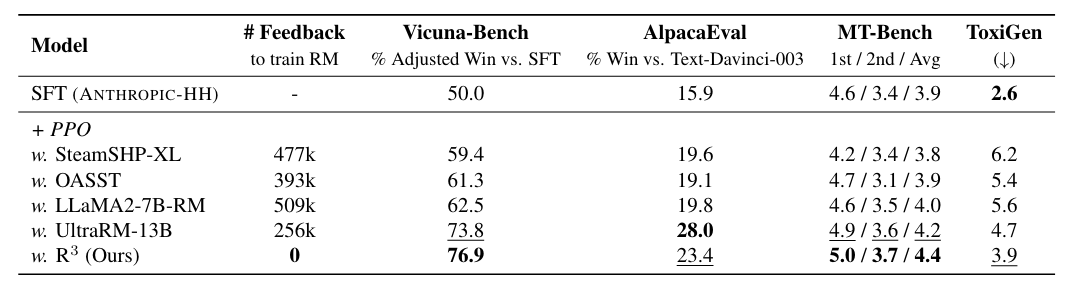
| [GPT-4-based benchmarks: Vicuna-Bench (Chiang et al., 2023), MT-Bench (Zheng et al., 2023), and AlpacaEval (Li et al., 2023) | Classifier-based safety benchmark, ToxiGen (Hartvigsen et al., 2022)] |
-
제안한 방법론이 SFT에 비해서 human preference 증가
-
PPO dataset을 보면 SFT에 비해서 의도적으로 에 helpful 치중된 subset 부분만을 활용했기 때문에 PPO training LM들이 Toxity가 향상되었는데 (왜…) R^3는 잘 방어가 되었다고 함
-
AlpacaEval 성능 낮은 이유는 reference answer나 bi-positional judgments가 안되어서라고 설명
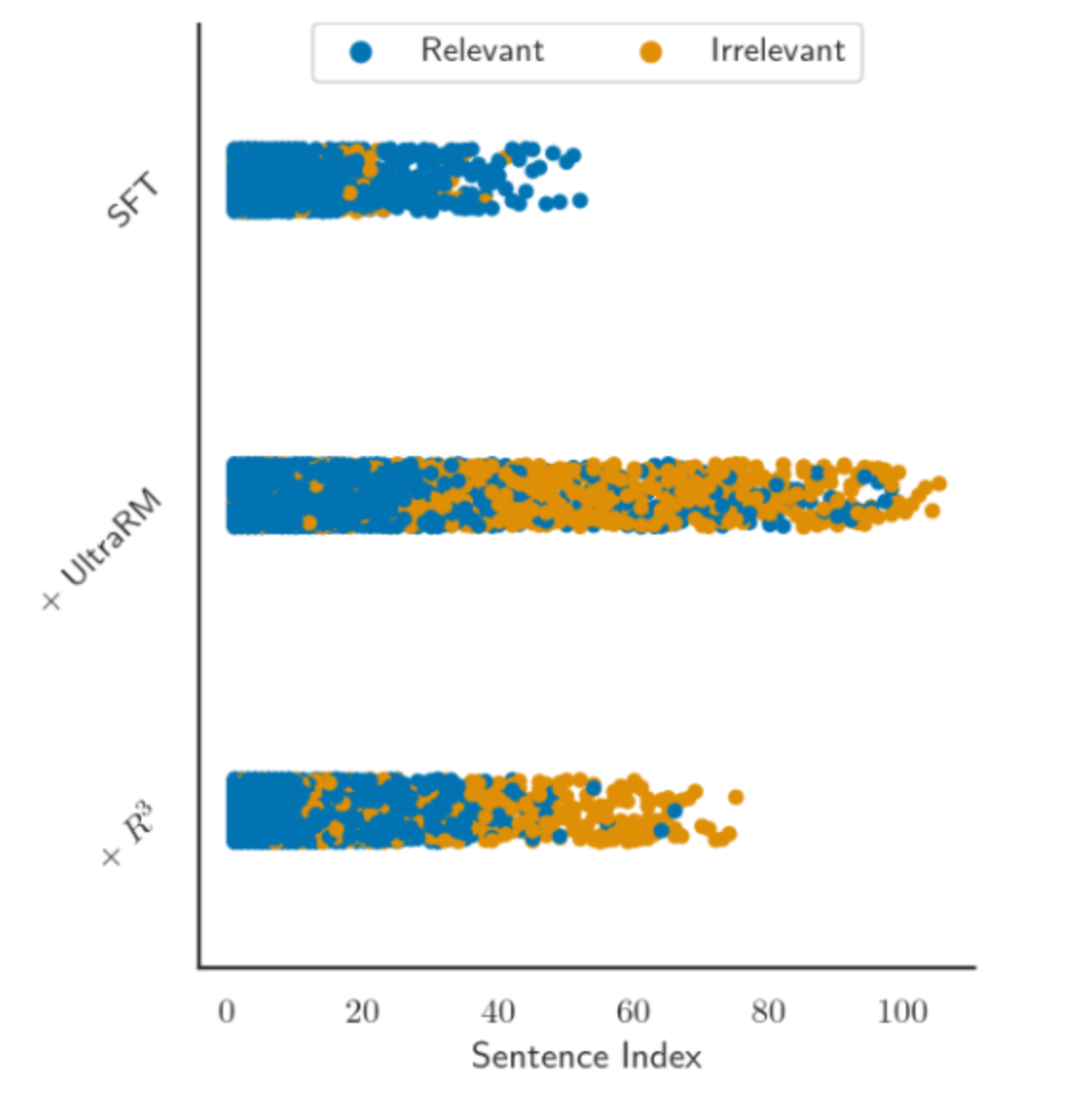
-
AlpacaEval set을 Sentence Index별로 Scatter plot 찍어놓은 그림, PPO training하면 response length가 길어지고 Irrelevant해지는 경향이 있음
-
GPT-4로 Relevance 평가해본 결과 R^3 (85.1%) vs UltraRM (83.1%) 기록
⇒ query relevance를 유지시키는 방법론임을 보여주는 실험
4.2 R^3의 Reward Design의 효과적인가? (Ablation)
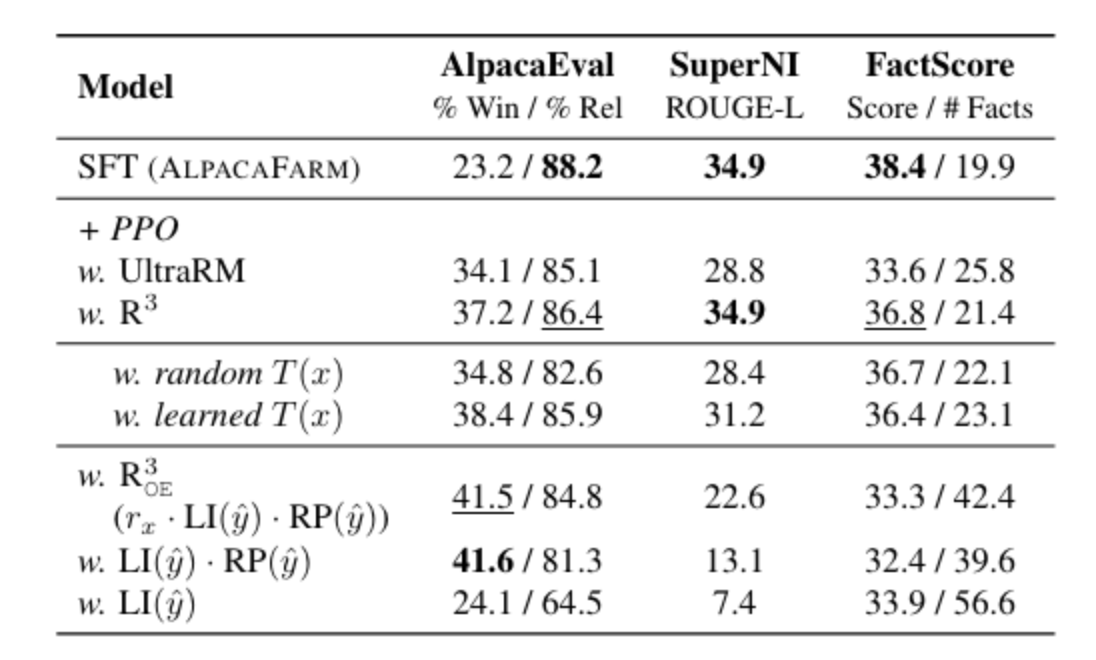
[SFT Model: Alpaca FARM]
[alignment tax 평가를 위해 closed form query가 많은 SuperNI, FactScore에도 평가]
-
UlteraRM에 비해서 alignment tax가 확실하게 개선됨
-
Relevance에만 중점적으로 Reward를 주는 Closed query를 안 쓰는 R_{OE}를 보면 Preference 증가 & Relevance 증가 & alignment tax 심화로 목적함수 설계가 의도대로 잘 작동함을 알 수 있음
-
Length Incentive만 Reward로 써도 SFT에 비해서 Preference가 증가하나 alignment tax 라는 trade off는 피하지 못함 (Fact Score)
-
Query Classification을 Original GPT4 → Learned LLAMA2로 했을때는 성능하락폭이 크지는 않으나 (논문주장), Random으로 바꾸면 큼
⇒ Query type에 따라 reward signal을 다르게 주는 것의 타당성을 이야기하고 싶었던 것 같음
4.3 R^3는 Generalizable한가?
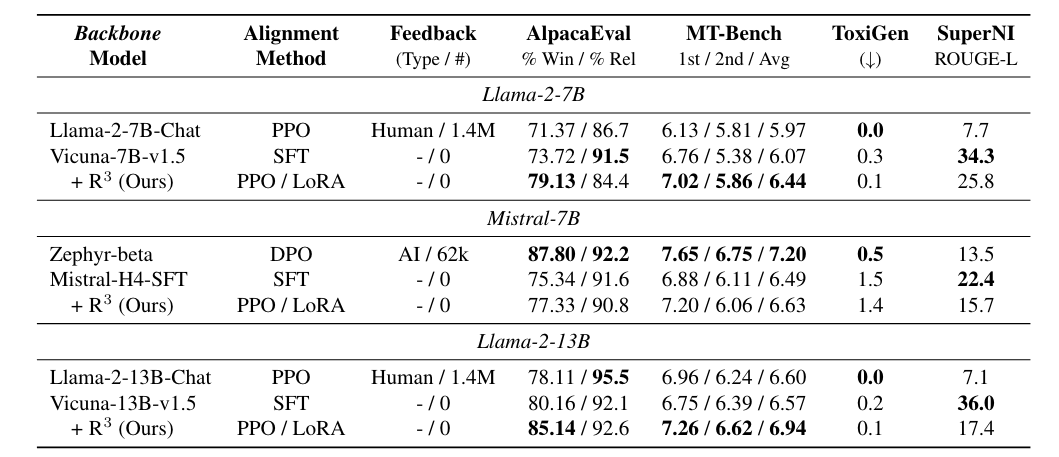
[다양한 backbone에 R^3를 실험]
-
최상단 Row: Backbone Pre-trained LLM (e.g., Llama-2-7B, Mistral-7B)
-
그 다음 상단 Row: In-house company에서 직접 SFT > RLHF Training한 LLM (e.g., Llama-2-7B-Chat)
-
2번째 Row: Open src로 풀린 Backbone Pre-trained LLM 기반 SFT Model (e.g., Vicuna-7B-v.1.5)
-
3번째 Row: 2번째 SFT Model 위에 ShareGPT, UltraChat (2개 데이터셋 원래 SFT를 위해 만들어진 데이터셋이나 R^3는 Triplet 필요 x) sampling해서 R^3로 PPO한 LLM
-
Vicuna-{7, 15}B-v1.5에서 PPO training을 한 LLM 같은 경우 AlpacaEval (Preference, Relevance)과 MT-Bench에서 대부분은 성능향상을 보임.
[MT-Bench: MT-Bench is a challenging multi-turn benchmark that measures the ability of large language models (LLMs) to engage in coherent, informative, and engaging conversations. It is designed to assess the conversation flow and instruction-following capabilities of LLMs, making it a valuable tool for evaluating their performance in understanding and responding to user queries.]
- Huggingface-Mistral SFT 대비 Preference는 향상시켰지만 DPO training한 Zephyr-beta 대비 성능이 낮은 이유를 (1) 해당 모델은 GPT-4-generated feedback를 사용 (2) Mistral-H4-SFT의 under SFT를 꼽음.
(모든 7B 모델들이 R^3 PPO training 후 preference(% Win)의 증가에 따라 relevance(% Rel)이 희생되지만, 13B 모델에서는 relevance도 향상된다고 하면서 model size 증가에 따라서 tradeoff 완화가 기대될 수 있음을 시사)
5. Conclusion
-
‘relevance’를 기반으로 preference-free한 alignment learning 방법론 제시
-
heuristic하지만 mixture of reward로 구성된 R^3가 open-source RMs보다 human preference에 training 되지 않았음에도 좋은 성능을 보였음
-
human preference data를 확보하기 어려운 상황(제일 큰 contribution)에서 (1) preference를 향상 (2) query relevance를 향상 (3) alignment tax를 완화시키는데에 탁월한 방법론
-
GPT-4-generated feedback보다 성능이 떨어지는 것을 보면, Contriever가 모델링하지 못한 Reward가 있다는 건데 이건 heuristic한 Reward 설계의 본질적인 한계라고 생각함.