Scaling Laws for Data Filtering— Data Curation cannot be Compute Agnostic
논문 정보
- Date: 2024-04-13
- Reviewer: yukyung lee
- Property: LM, LLM, Efficient Training, Pre-training
https://arxiv.org/abs/2404.07177
tl;dr
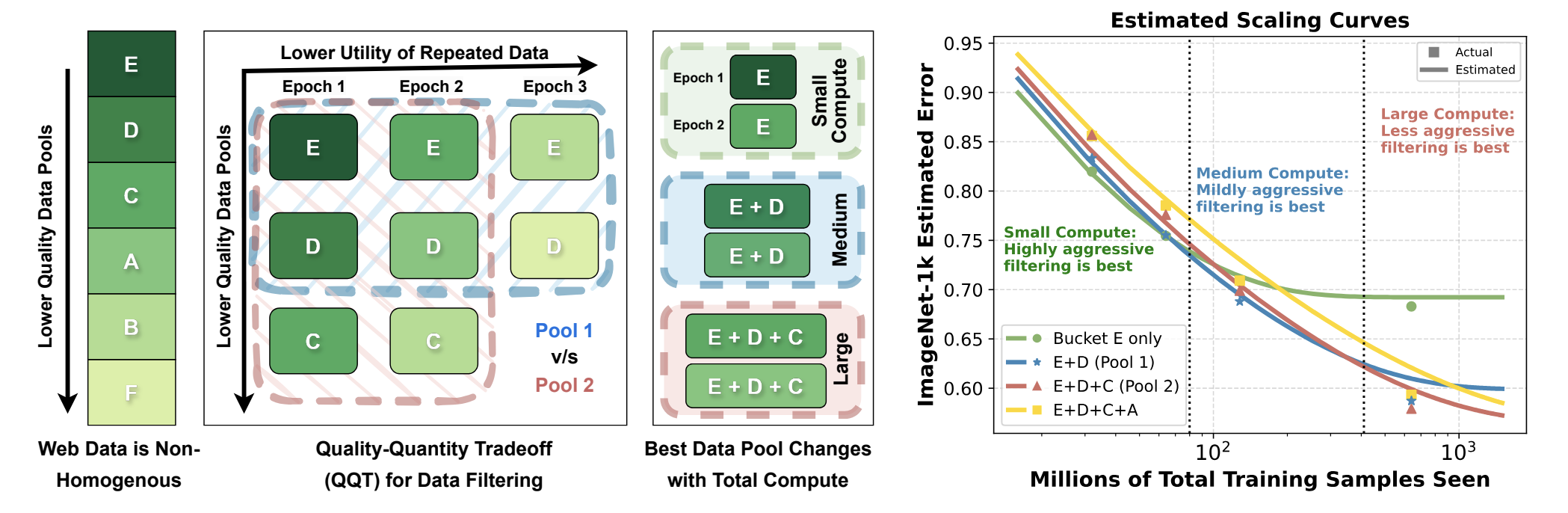
(a) The Dynamic Problem of Data Filtering
-
y-axis: web data는 non-homogenous하며 다양한 quality의 subset으로 구성됨
-
x-axis: bucket E와 같은 high-quality 데이터는 pre-training에서 quantity가 한정되어 있으며, epoch을 반복할수록 repetition으로 인해 utility가 떨어짐
-
이러한 현상을 quality-quantity tradeoff (QQT)로 명명함
-
Research Question:
-
Should we train on the best pool (E) for 6 epoch ? (가장 좋은 데이터 풀을 활용하여 학습을 해야하는지)
-
Should we train on the 3 best pools (E, D, C) for 2 epochs each (가장 좋은 데이터와 그 다음으로 좋은 데이터를 섞어서 학습하는것이 좋을지 == E+D / E+C를 각각 2epoch씩 학습하는게 좋을지)
-
How does the answer vary with the total compute budget ?
-
(b) Scaling laws for data filtering
-
본 논문에서는 이러한 web data들의 특징 (heterogeneous / limited data)을 고려한 scaling law를 소개함
-
데이터들의 개별 pool (A ~ F)의 initial utility와 utility의 rate of decay를 modeling함
-
Bucket들 간의 mutual interaction을 formulation 해서 각 pool들의 combination에 대한 성능을 추정함 (각 pool들로 학습된 모델의 예측성능을 추정한다는 의미)
-
이 method는 학습을 직접 해보지 않고도 scaling law를 추정할 수 있음
“our methodology does not involve training on combinations of data pools even for estimating their scaling laws”
0. Abstract
-
Vision-language model을 학습할 때 carefully curated web data를 활용하여 매우 오랜시간동안 훈련됨 (trained for thousands of GPU hours)
-
Data curation은 raw scraped data로 부터 high-quality 데이터의 subset을 보존하는 방식으로 발전해옴 - LAION 데이터의 경우 10%의 데이터만 보존함
-
하지만 이러한 전략들은 일반적으로 사용할 수 있는 training compute를 고려하지 않고 개발됨
-
본 논문에서는 training compute와 독립적으로 filtering에 대한 결정을 내리는것이 suboptimal하다는 것을 지적
- 한정된 고품질 데이터가 반복되어 학습 될 때 빠르게 utility를 잃어, 보이지 않는 ‘저품질’ 데이터를 포함해야 한다는 점을 보여줌
-
QQT를 다루기 위해, 기존 문헌에서 간과된 web data의 homogeneous nature를 고려한 neural scaling law를 소개함
-
제안하는 scaling law는
-
(i) web data의 다양한 quality subset의 ‘utility’를 characterize하고,
-
(ii) data point가 ‘n번째’ 반복될 때 utility가 어떻게 감소하는지를 고려하며,
-
(iii) 다양한 data pool이 결합될 때의 mutual interaction을 공식화하여, 결합된 여러 data pool에 대한 모델 성능을 추정할 수 있게 함
-
-
제안하는 scaling law는 다양한 compute에서 최고의 성능을 달성하기 위해 최적의 data pool을 큐레이션할 수 있게 함
1. Introduction
-
Foundation model pre-training을 더 많은 데이터 / compute / parameter로 scaling up 하는 것은 ML community에 high-performing model을 제공해주었음
-
기존 연구들은 neural scaling law에 따라서 예측된 model performance의 향상 가능성에 따라 scale up을 결정하는 것에 포커스 맞추어옴
-
최근에는 “data”가 closed model의 성능 향상에 영향을 주는 secret source로 받아들여지고 있음
-
data quality의 중요성이 증가함에 따라 large corpora로 부터 데이터를 filtering하는 기술이 중요해짐
-
기존 scaling law는 data quality를 고려하지 않음
-
-
Web data는 방대하지만 high quality data는 한정되어 있음
-
해당 논문에서는 limited high quality data와 대량으로 활용할 수 있는 low quality data의 trade off를 고려하여 scaling law를 결정 — quality-quantity tradeoff (QQT)
-
Data curation 과정에서 compute를 고려해야 함
-
Training for a low compute budget (less repetition) → dataset의 quality가 중요함
-
Computing scale much larger than the available training data → dataset의 quantity가 중요함 (less aggressive filtering이 필요)
-
2. Related Work
이 부분은 Introduction과 겹치는 부분이 많아서 발표에서 제외
-
data filtering에 대한 기존 방법론
-
lm / downstream task / CLIP에서의 scaling law를 설명하고 있음
3. Data Filtering for a Compute Budget
1) Experimental setup
-
VLM (CLIP)을 학습하기 위해 large initial pool이 준비되어 있음을 가정
-
다양한 compute budget에서의 data filtering 효과를 확인하고자 함
아래의 종류로 구분된 setting을 가짐
-
base unfiltered pool: medium scale — Datacamp 벤치마크 사용
-
다양한 compute budget (32M, 64M, 128M, 640M)에 대한 세팅이 존재함
-
각 세팅에서 filtering 성능을 연구하며, 필터링된 데이터의 양을 변경하면 각 training sample을 반복하는 횟수가 달라지게 됨
-
예를들어, 128M의 compute budget에서는 12.8M sample의 filtering pool에서 각 sample이 10번씩 반복됨
-
평가는 ImageNet, ImageNetOOD, CIFAR10 등의 classification task와 Flickr, MSCOCO와 같은 retrieva를 포함한 18개의 다양한 task로 구성 (Zeroshot 평가)
-
-
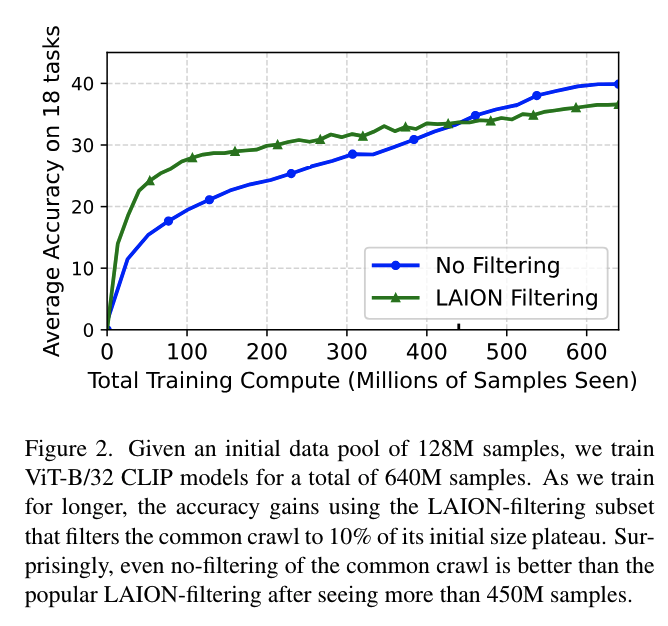
2) When “good” data performs worse
-
(start from) LAION 필터링 전략을 사용하여 LAION 데이터셋을 얻음.
-
CLIP 모델에 의해 측정된 높은 simliarity score(> 0.28)를 가진 이미지-캡션 pair를 필터링하여 원본 풀의 10%만 유지함
-
다양한 compute budget에서 필터링되지 않은 raw data와 LAION 필터링된 subset의 training 비교함
-
-
Good data is better at low compute budget
-
Data filtering hurts at high compute budget
3) Data filtering must be compute-aware
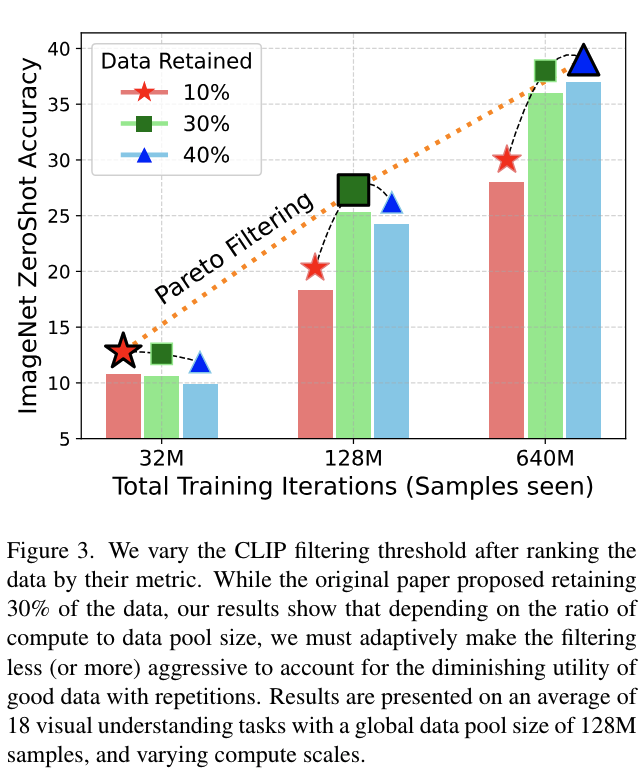
-
2)를 통해 LAION filtering은 compute budget이 증가할수록 gain이 줄어듦을 알 수 있었음
- 또한 compute budget이 커질수록 filtering하지 않은 데이터보다 낮은 성능을 기록하기도 함
-
이 현상은 LAION 필터링 방법에만 해당하는 것이 아니라 반복된 샘플의 utility가 감소한다는 저자들의 직관과도 동일함
-
CLIP 점수 필터링과 T-MARS 방법을 포함한 최신의 데이터 필터링 방법들의 성능을 다양한 컴퓨트 예산에서 분석 진행함
-
Aggressice filtering(상위 10-20% 데이터 보존): 32M에서는 최상의 결과를 제공하지만, compute가 증가함에 따라 이러한 경향이 완전히 역전됨
-
compute에 맞춘 필터링 전략이 필요하며, 반복될수록 빠르게 감소하는 high quality data의 initial utility와 더 천천히 감소하는 low quality data의 utility간 균형을 맞추는 전략이 필요함
-
4. Scaling Laws for Data Filtering
1) Utility 정의
-
scaling law에 대한 기존 연구들은 n개의 샘플로 학습한 후의 모델 오차를 y = an^b + d로 추정함
-
a, d > 0, b < 0는 경험적으로 결정되는 상수
-
y는 validation set에서의 loss와 같은 metric
-
직관적으로, b는 더 많은 데이터를 볼수록 성능 향상 폭이 줄어드는 것을 나타내며, 동시에 데이터 풀 자체의 utility를 모델링함 - b 값이 낮을수록 utility가 높다는 것을 의미함
-
a는 정규화 상수이며 d는 무한 학습 후의 최소 오차를 추정함
- n개 샘플로 학습 후의 손실을 추정하는 대신, 학습 중 어떤 시점에서의 샘플의 순간 utility를 고려할 수 있음
-
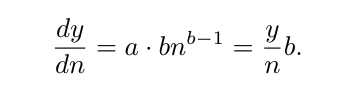
2) 반복에 대한 Utility
-
CLIP 스타일의 사전학습은 동일한 데이터에 대해 여러 epoch 동안 수행되나, 샘플이 여러번 반복될 때 utility의 변화에 대한 이해는 부족함
-
샘플이 학습에 등장하는 횟수에 따라 utility가 지수적으로 감소한다는 것을 가정함
-
k+1번 본 샘플의 utility parameter b는 아래와 같음
-
tau값이 클수록 utility가 느리게 감소
-
delta는 utility 함수를 간략하게 나타내기 위해 사용됨
-
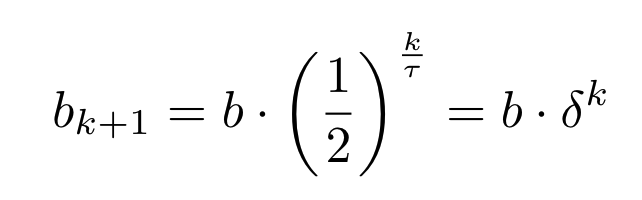
-
k번씩 n개 샘플을 본 후의 모델 손실에 대한 closed form은 아래와 같음
-
n_j는 j번째 epoch 학습 후 본 샘플 수
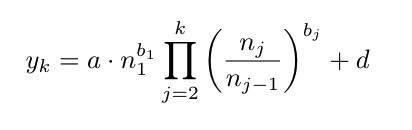
-
summary of parameter
-
Utility Parameter (b): loss변화(y)는 반복한 샘플 수^ b 값에 기반한 지수에 비례함— high quality data bucket은 low quality data bucket에 비해 더 낮은(음수이면서 절댓값이 큰) b 값을 가짐
-
Half life(τ): 반복 파라미터는 반복 데이터의 utility 감소를 나타냄. 직관적으로 τ는 data bucket의 다양성을 나타내며 다양성이 높은 데이터 버킷은 τ 값이 더 높아, 더 많은 반복을 허용함
-
Decay Parameter(δ): Decay Parameter는 τ로부터 직접 도출되며, 고유한 파라미터가 아님. δ는 해당 데이터로 1 epoch 학습 시 utility 파라미터의 분수 감소를 나타냄
-
Normalizer (a): Normalizer는 샘플 수에 따른 loss 변화를 연관 짓는 task의 intrinsic property를 나타내고자함. 모든 버킷에 대해 손실을 최소화하는 공통의 a 값을 학습하고, 이를 모든 버킷에 대해 고정된 상수로 취급함
-
Irreducible loss, 최소 손실(d): 이는 손실에 더해지는 상수 항으로, 더 이상 줄일 수 없는 값
-
3) The case of heterogeneous web data
-
서로 다른 품질의 데이터가 존재하는 경우에 대한 논의
-
web data는 일반적으로 다양한 subset으로 분할될 수 있으며, 각각의 subset은 고유한 parameter들을 가짐 (utility parameter들을 의미)
-
대규모 학습은 여러개의 data bucket의 조합에 대해 수행됨
-
어떻게 효과적으로 데이터 믹스의 손실을 추정할 수 있을까?
- 이를 추정하기 위해 여러가지 data mix에 대한 평균 오차를 활용함
Theorem 1.
-
p개의 데이터 pool S_1^n . . . S_p^n이 무작위로 균일하게 샘플링되었을 때, 각각의 utility 및 반복 파라미터가 (b_1, τ_1) . . . (b_p, τ_p)로 주어진다면, 각 bucket의 새로운 repetition half-life 는 τ̂ = p · τ
-
추가로 k번째 반복에서 조합된 pool의 utility 값 b_(eff)^((k))는 개별 utility 값의 가중 평균
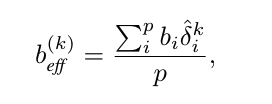
5. Fitting scaling curves for various data utility pool
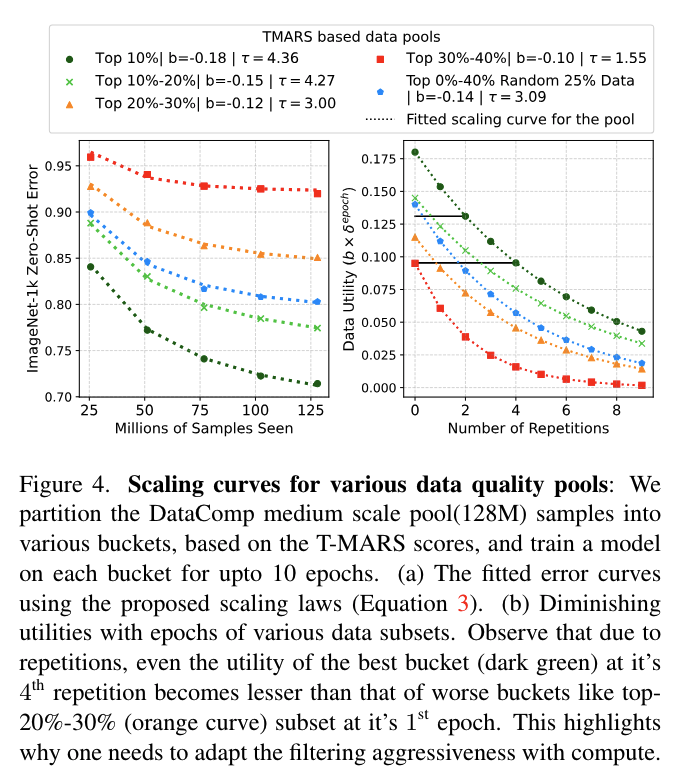
-
Figure 4: T-MARS 점수를 데이터 utility 메트릭으로 사용하여 다양한 데이터 utility 풀에 대해 fitting된 scaling curve / (right) 다양한 데이터 풀의 epoch에 따른 utility 감소
-
Web data is heterogeneous and cannot be modeled by a single set of scaling parameters
- 높은 품질의 pool(상위 10%)에서 낮은 품질의 pool(상위 30%-상위 40%)로 갈수록 크기가 단조롭게 감소함
-
Data diversity varies across pools
- repetition parameter(τ)의 변화를 보여주어 데이터 다양성 또한 균일하지 않음을 시사
-
Utility of high quality data with repetitions is worse than that of low quality data
- high quality data는 더 큰 초기 utility를 가짐에도 불구하고 연속적인 epoch에 걸쳐 utility가 급격히 감소함
-
Experiment setting
-
128M image-caption pair로 구성된 DataComp medium 사용
-
T-MARS, CLIP score를 활용하여 data들의 utility 추정치로 사용하고 이를 기준으로 web 데이터를 순위 매김
-
상위 10%(가장 높은 점수를 가진 데이터 포인트 10%)
-
상위 10%-20%
-
상위 20%-30%
-
상위 30%-40% 하위 집합
-
6. Results: Estimating the Scaling Laws for
Data Combinations under QQT
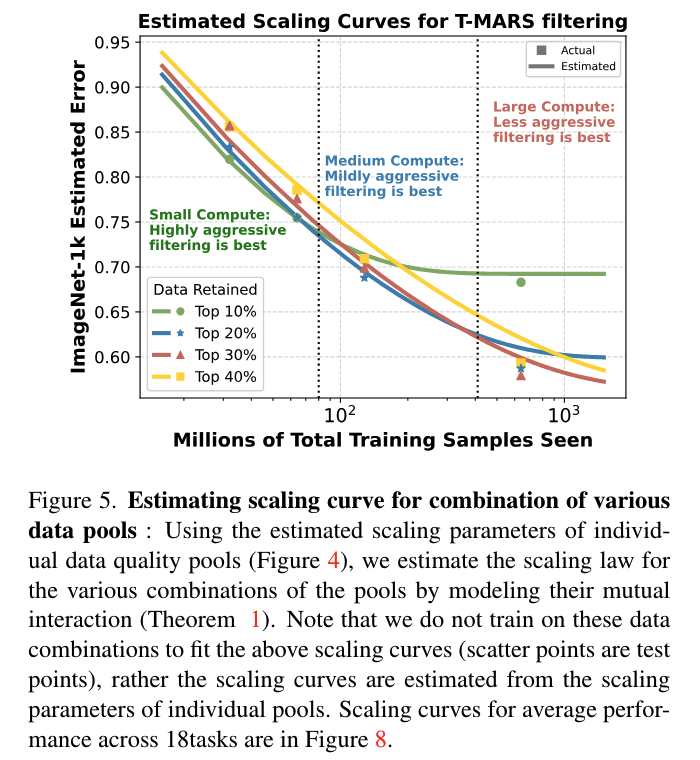
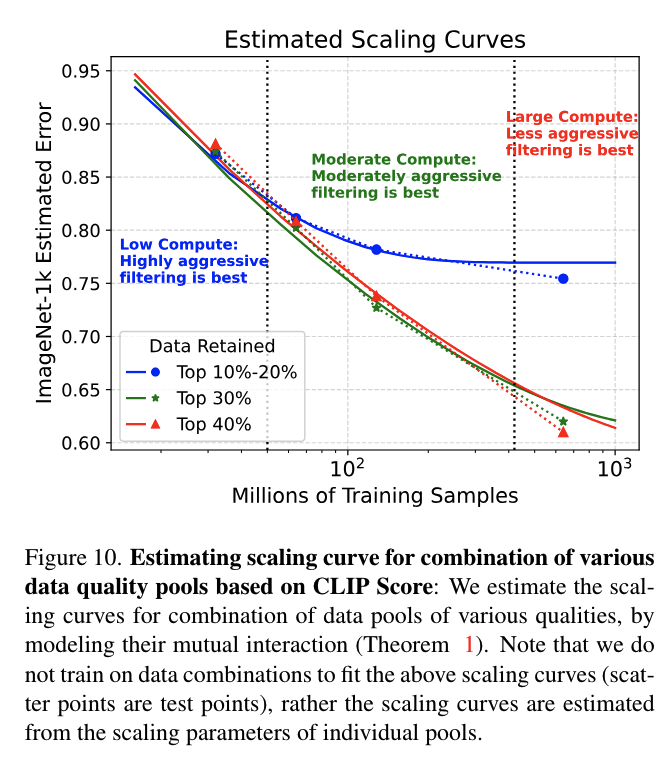
-
section 5에서는 다양한 quality의 pool에 대해 각각의 parameter를 도출했음
-
section 6의 목표는 주어진 학습 compute에 대해 가장 효과적인 데이터 큐레이션 전략을 결정하는 것
-
상위 20% pool은 상위 10%와 상위 10%-20% 데이터 quality pool의 조합으로 간주됨
-
scaling curve의 추세를 통해 주어진 compute에서 최적의 데이터 필터링 전략을 예측할 수 있음
-
-
Fig 5 / 10은 ImageNet에서의 성능을 평가하여 서로 다른 데이터 조합에 대한 scaling curve를 보여줌
-
theorem 1을 통해 직접 추정되는 curve임
-
Aggressive filtering is best for low compute/less repetitions regime
- 데이터 필터링을 적극적으로 수행하는 것은 반복이 최소화되는 low compute 체제에서 가장 유리함
-
**Data curation cannot be agnostic to compute **
- compute가 100M 샘플 이상으로 확장됨에 따라 최적의 데이터 큐레이션 전략이 바뀜
-
1) Scaling the scaling curves
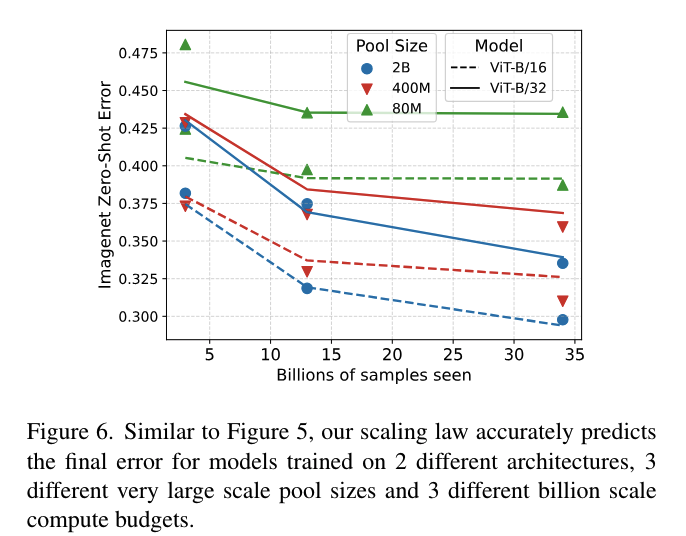
-
이전 연구들에서는 다양한 크기의 ViT 모델을 다양한 크기의 data pool로 학습함
-
이전 연구의 저자들이 제안 했던 방식(fit scaling laws)은 small dataset을 학습한 경우 매우 높은 error를 보였음
-
논문의 저자들은 error가 높은 이유를 utility의 감소를 고려하지 않은 탓으로 판단함
-
실제로 CLIP과 같은 모델들은 데이터를 여러 차례 반복하여 학습하므로, 단순히 데이터 크기만으로는 성능을 정확히 예측하기 어려움
-
-
따라서 논문의 저자들은 이전 연구의 모델들에 본 논문의 scaling law를 적용하여 성능을 예측하였음
-
Figure 6:
-
제안된 척도 법칙이 작은 사이즈의 문제뿐만 아니라 매우 큰 사이즈의 문제에도 잘 적용될 수 있음
-
데이터 반복에 따른 utility 감소를 고려하는 것이 정확한 성능 예측을 위해 중요함
-
단순히 데이터 양만으로는 성능을 정확히 예측하기 어려우며, 데이터의 반복과 이에 따른 영향을 명시적으로 모델링해야 함
-
7. Conclusion
-
scaling curve 자체를 fitting하여 data curation을 할 수 있는 전략을 제안함
-
compute power에 따라 적절한 data curation을 진행해야 한다는 점을 보여줌