Search-in-the-Chain: Interactively Enhancing Large Language Models with Search for Knowledge-intensive Tasks
논문 정보
- Date: 2024-03-26
- Reviewer: 상엽
- Property: Retrieval
Introduction
LLM의 여전한 한계
-
다양한 지식들을 합쳐서 추론하는 것에 대한 어려움.
-
memorization of long-tail and real-time knowledge
-
hallucination
-
reference없이 context만으로 생성하는 것은 traceability가 떨어지면 신뢰하기 어려움.
→ Retrieval-augmented method는 위의 문제들을 외부 지식과 모델을 결함시킴으로써 일부 해결
Retrieval-agumneted method를 도입할 때 역시 문제 존재
C-1 : IR을 LLM reasoning process에 바로 이용하는 것은 LLM의 reasoning chain을 훼손할 때도 있음. (LLM이 local sub-question reason만 하기 때문에) ← IR의 결과물이 들어가기 때문에 발생하는 문제점 + sub-question에 집중한 reasoning 방식
C-2 : IR 결과 vs LLM 자체 지식의 충돌 → 잘못된 결과를 만들 가능성이 존재.
C-3 : reasoning direction을 수정할 방법이 없음. (조금 억지)
Search-in-the-Chain (SearChain) 제안
-
IR-LLM interaction round를 여러 번 진행
-
IR-LLM interaction : reasoning → (verification → completion) 반복 → tracing
-
그림을 보자.
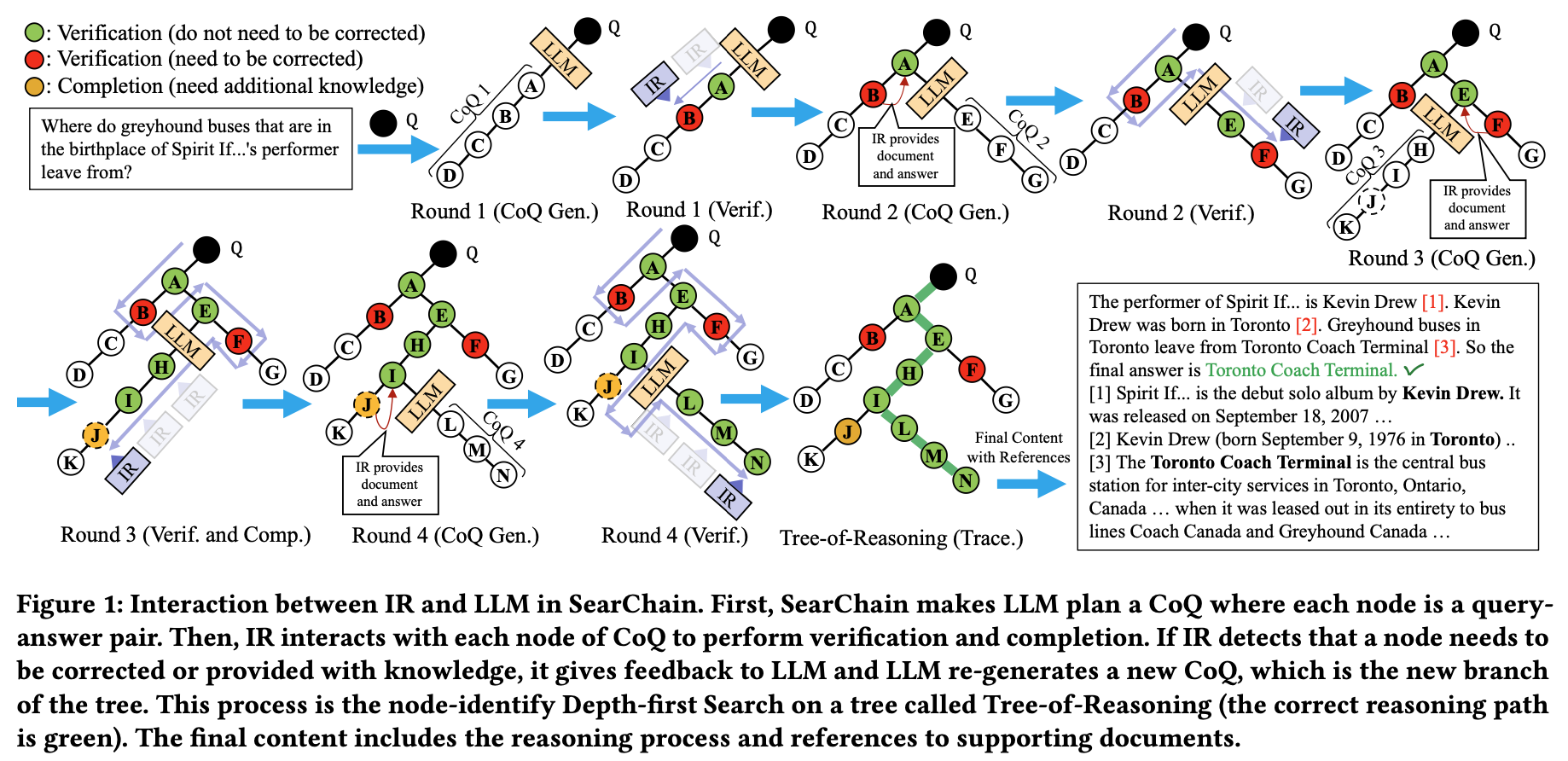
- CoQ를 만들기 위해 In-context learning 이용 복잡한 질문을 풀기 위한 IR-oriented query 형태로 분해해서 구성
-
reasoning
-
노드(node)** :** IR-oriented query
-
정답(answer)** :** 쿼리에 대한 LLM의 답변
-
flag : LLM이 추가 지식을 필요로 하는지 아닌지
-
→ 기존에는 IR을 활용할 경우 노드당 한 번의 reasoning만 가능했지만 CoQ는 우선 완전한 체인을 먼저 생성 → C-1 해결
- 각 노드에 대해 IR과 상호작용 진행, 구체적으로 아래 두 단계를 선택적으로 반복
-
verification
- LLM의 정답과 retrieved 정보가 일치하지 않고 IR이 high confidence를 가질 때 → IR 피드백을 이용해 정답을 다시 생성
-
completion
- flag → IR knowledge를 이용해 정답을 다시 생성
-
위의 IR interaction을 라운드마다 반복해 CoQ를 수정 → IR에 의한 오류를 감소시킴 → C-2 해결
- tracing : reasoning process를 만들고 각 reasoning step을 support하는 reference 선택
-
선택된 reference를 이용해 답변 생성 → traceability 향상 (RAG 방식은 공통이라고 생각.)
-
IR interaction은 reasoning path를 chain에서 node-identify Depth-first search로 바꿈 (Tree-of-Reasoning, ToR) (뒤에 설명)
-
IR을 이용해 node를 수정 → C-3 해결 (논문에서는 여기 적긴 했는데 verification에 좀 더 가까운듯)
Main contribution
-
We highlight the challenges in introducing IR into LLM from the perspectives of reasoning and knowledge. → ??? LLM에 IR을 도입할 때 있는 문제는 대체로 알던 거 아닌가?
-
SearChain not only improves the knowledge-reasoning ability of LLM but also uses IR to identify and give the knowledge that LLM really needs. Besides, SearChain can mark references to supporting documents for the knowledge involved in the generated content.
→ reasoning 실험 + (Retrieval-augmented 방식 + confidence 개념)
- Interaction with IR in SearChain forms a novel reasoning path: node-identify Depth-first Search on a tree, which enables LLM to dynamically modify the direction of reasoning.
→ ToR 제시
- Experiment shows that SearChain outperforms state-of-the- art baselines on complex knowledge-intensive tasks including multi- hop Q&A, slot filling, fact checking and long-form Q&A. → SOTA
Related work
-
CoT prompting
-
CoT, self-consistency 등
-
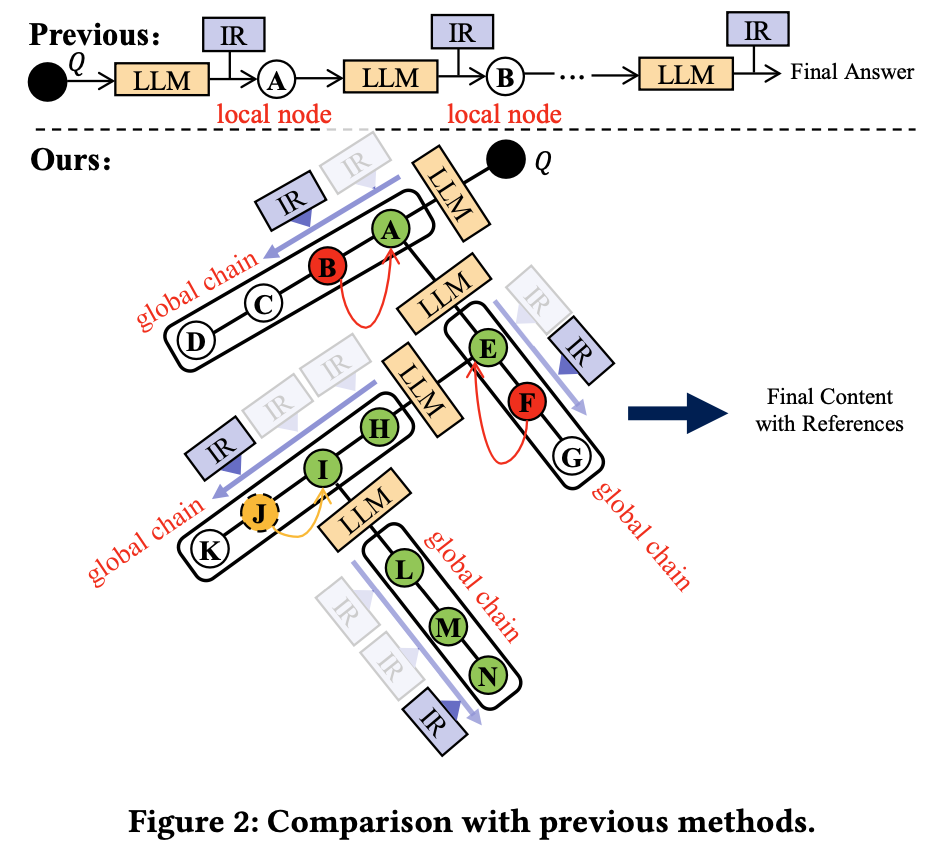
복잡한 질문을 작은 질문으로 나눈 후 각 질문을 locally 해결하는 것에만 집중
-
→ Search plan을 통한 global reasoning을 고려할 수 있는 형태로 바꿈.
-
Retrieval-augmented LM
-
기존 방식들에서는 one-step reasoning만을 진행 → global chain을 만들어서 logical relationship을 더 잘 이해함.
-
기존 IR은 정보 제공만 할뿐 수정에는 관여하지 않음. → IR iteraction은 missing knowledge를 가진 항목들에 대해서만 결과 수정을 제공하기 때문에 IR의 negative effect를 감소시키며 수정도 가능
-
Method
Chain-of Query Generation
-
In-context learning 이용
-
global reasoning chain for complex question
-
branch of Tree-of-Reasoning
-
q_i : IR-oriented query, a_i : its answer
-
-
Prompt

-
Construct a global reasoning chain
-
main task
-
“Global” : 완전한 reasoning chain을 만들어라.
-
“Global” means that LLM needs to plan a complete reasoning chain for the complex question, rather than answer the question directly or only solve “local” sub-questions (comparison shown in Figure 2)
-
generate a query to the search engine based on what you already know at each step of the reasoning chain
-
각 노드에서 IR-oriented query와 LLM만의 답변을 생성
-
만약 답을 모르겠다면 [Unsolved Query] flag 이용 (missing knowledge)
-
-
이후 있을 round에서도 CoQ 생성은 위의 방법을 따름.
Interaction with IR
-
CoQ의 각 노드에 대해 IR을 이용해 다음의 작업을 반복 - verification, completion
-
IR의 결과를 바탕으로 CoQ의 결과를 수정 → new branch of ToR (Tree of Reasoning)
-
Top-1 retreived document를 supporting document로 이용
-
더 이상 노드에 대한 수정이 필요없어지면 라운드 종료
-
correct reasoning path와 supporting document를 이용해 답변 생성
-
Algorithm

Verification
- IR 결과를 바탕으로 CoQ 각 노드의 정답이 맞는지 확인
- retrieved Top-1 document d_i → ODQA 데이터셋으로 학습된 reader(DPR) 이용해 answer g 추출
- confidence f : predicted value that measures whether g can answer q_i
\mathbf{H} \in \mathbb{R}^{L \times E} : input text “[\mathrm{CLS}] q_i[\mathrm{SEP}] d_i”의 last hidden state sequence (L : length, E : hidden dimension)
\mathbf{H}_{[\mathrm{CLS}]} : last hidden state of [\mathrm{CLS}] token
- a_i와 g 비교
-
short-form generation task
- a_i 안에 g가 있는지 여부
-
long-form generation task
- ROUGE between a_i and d_i > threshold \alpha
- a_i와 g의 결과가 일치하지 않음 & f > \theta (IR로 인한 성능 감소를 막기 위한 threshold)
- prompt
According to the Reference, the answer for q_i should be g, you can change your answer and continue constructing the reasoning chain for [Question]: Q. Reference: d_i.
- ai → a^{\prime}{i} 변경 후, (qi, a^{\prime}{i})를 root 노드로 하여 새로운 CoQ 진행
Completion
-
missing knowledge를 갖는 노드의 정답을 보충
-
[Unsolved Query]에 대해 진행
-
f값에 관계없이 다음 prompt 실행
According to the Reference, the answer for q^{\star}{i} should be g^{\star}, you can give your answer and continue constructing the reasoning chain for [Question]: Q. Reference: d^{\star}{i}.
- ai → a^{\star}{i} 변경 후, (qi, a^{\star}{i})를 root 노드로 하여 새로운 CoQ 진행
Tracing
-
reasoning process 생성 및 각 노드에 대해 supporting document mark
-
prompt
You can try to generate the final answer for the [Question] by referring to the [Query]-[Answer] pairs, starting with [Final Content]. [Query1]: q_1 [Answer1]: a_1 …[Query m]: q_m [Answer m]: a_m.
Node-identify Depth-first Search
-
SearChain이 만드는 reasoing path
-
Depth first search와 같이 정답이 해결되거나 unsolvable sub-question이 존재하면 계속 reasoning한다는 점에서 동일
-
“node-identify” : 하나의 search direction이 끝날 때 parent node로 가는 것이 아니라 node verification과 completation을 통해 시작 node를 결정한다는 것이 다름.
-
LLM - IR 상호작용을 통해 동적으로 reasoning direction을 결정
Experiments
Experimental setup
-
Datasets
-
multi-hop question-answering (HotpotQA (HoPo)
-
Musique (MQ)
-
WikiMulti-HopQA (WQA)
-
StrategyQA (SQA)
-
slotfilling (zsRE)
-
T-REx
-
fact checking (FEVER)
-
long-form question-answering (ELI5)
-
-
Evaluation Metric
-
long and free-form : ROUGE-L
-
cover-EM : 정답 포함 여부
-
-
Baselines
-
reasoning : CoT, CoT-SC, Auto-CoT, Recite-and-answer, Least-to-Most
-
IR : Direct, Self-Ask, ToolFormer, React, DSP, Verify-and-Edit
-
-
implementation
-
LLM : gpt-3.5-turbo
-
retrieval model : ColBERTv2 (V100 이용)
-
최대 interaction 라운드 수 : 5
-
\alpha : 0.35, \theta : 1.5
-
Main Results
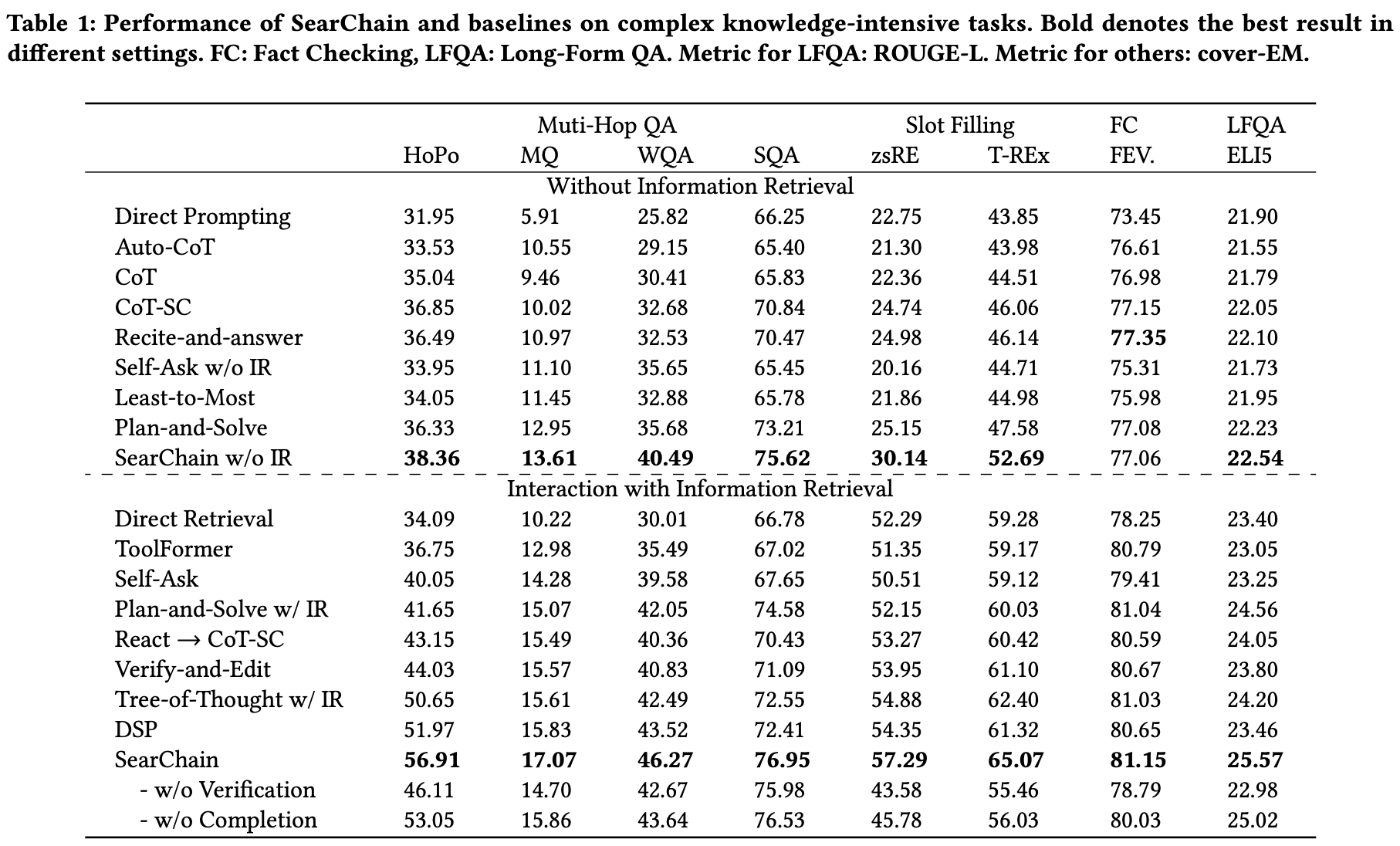
-
Effect of Chain-of-Query
-
outperform all baselines
-
local perspective : step by step으로 sub-question을 생성하고 답변하는 것
-
global perspiective : global reasoning chain of sub-questions
-
-
Effect of interaction with IR
-
again outperforms all the baselines.
-
CoQ는 IR interaction을 통해 LLM reasoning과 IR 결과의 일관성을 유지하기 때문 (IR 결과를 사용할지 말지 threshold가 있음.)
-
Analysis
KnowledgeDecoupling
-
4 multi-hop QA datasets의 knowledge source에 대해 분석
-
LLM의 knowledge
-
Corrected by IR (Verification) : IR과 일치하지 않은 결과로 인해 수정된 knowledge
-
Completed by IR (Completion) : LLM의 [Unsolved Query]에 대해 수정된 knowledge
-
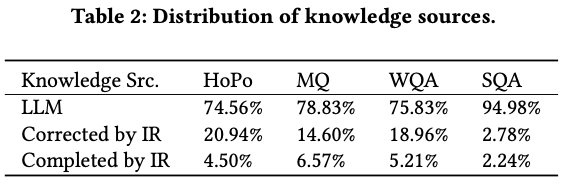
- 대부분은 LLM 자체 지식으로 해결되지만 IR 결과에 의해 수정되는 부분도 생각보다 많이 존재
- 데이터셋의 특징에 따라 그 비율은 많이 바뀌는 거 같음.
Positive and Negative Effects of IR on LLM
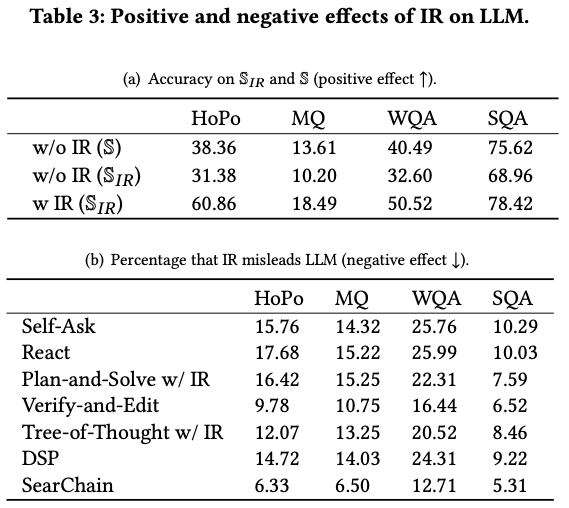
-
(a) Positive
-
\mathbb{S}_{I R} : IR 결과에 의해 수정, 보완된 answer들만 추출
-
w/o IR (\mathbb{S}_{I R}) < w/o IR (\mathbb{S}) : 실제로 LLM이 답변을 하는데 어려움을 겪음.
-
w IR (\mathbb{S}{I R}) > w/o IR (\mathbb{S}) > w/o IR (\mathbb{S}{I R}) : IR을 통한 답변 성능 향상
-
-
(b) Negative
-
LLM이 맞았지만 IR이 다른 정답을 준 비율
-
SearChain에서 confidence를 사용한 필터링이 효과적임.
-
CoQ vs Baselines in Reasoning
성능 외 reasoning을 평가하기 위한 두 가지 측면 추가적으로 제시
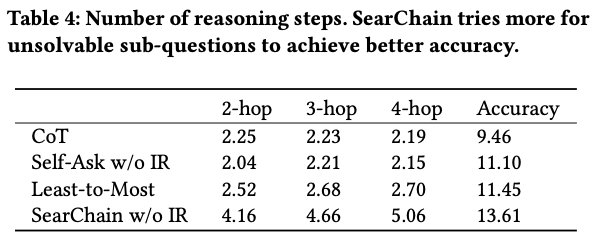
-
reasoning step의 수
-
복잡한 쿼리를 가지는 Musique 이용
-
제안 모델이 reasoning step이 많고 정확도 또한 높다.
-
-
어려운 sub-question 해결력

-
local perspective (주어진 쿼리를 해결하는 것에 집중) 방식으로는 reasoning을 멈추는 경향 이 큼. (Figure 4)
-
LLM gloobal chain reasoning을 유도함으로써 이런 현상이 줄어듦.
- 상엽 생각 : global을 확인할 수 있는 부분이 prompt에서 첫 문장 뿐이고 global chain이라는 용어가 생소할텐데 이게 어떻게 되는지 이해가 잘 안됨.
-
table 4의 결과 역시 더 많은 reasoning이 끊기지 않음을 뒷받침하는 근거
-
more case study
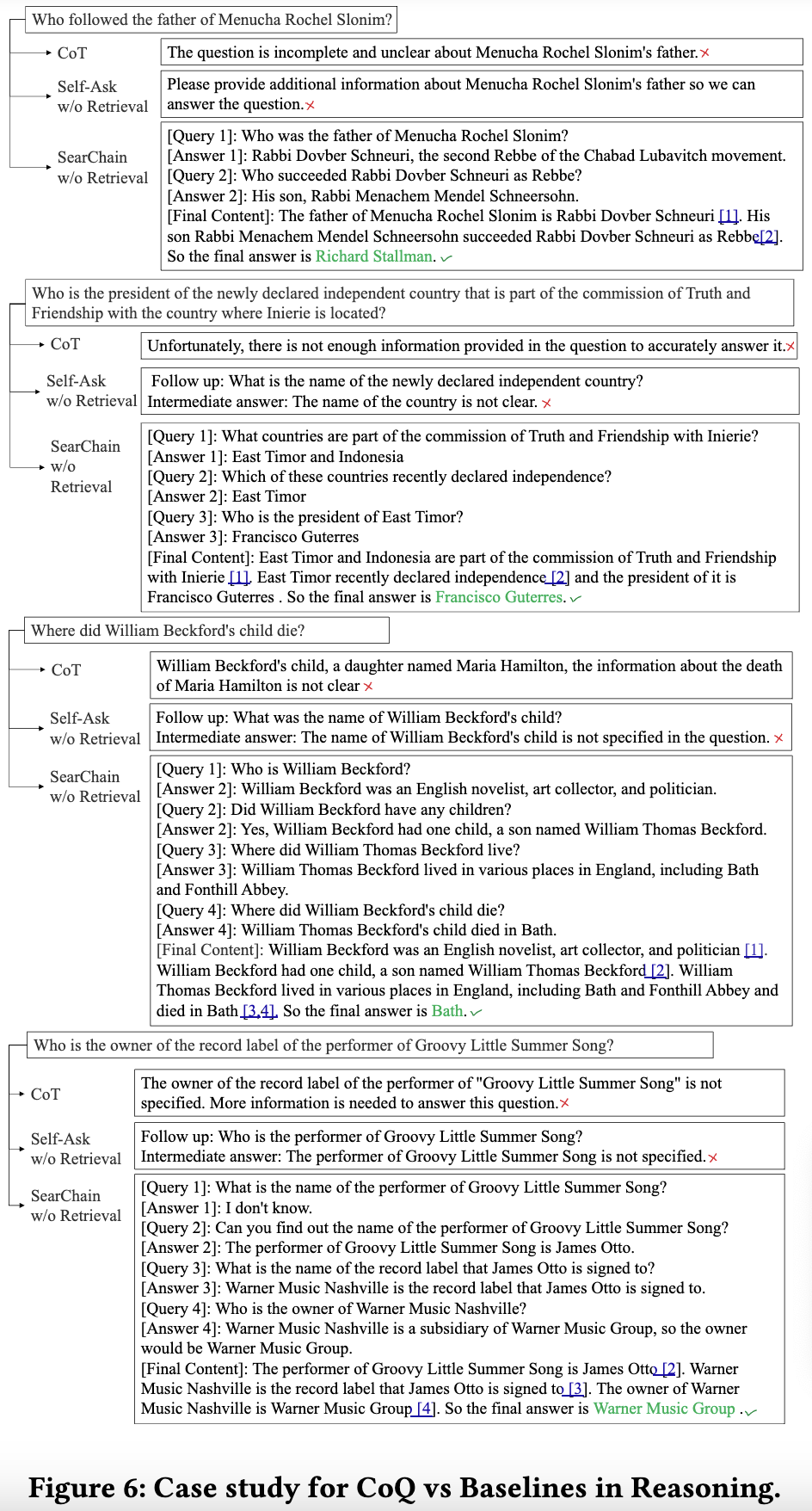
SearChain vs New Bing in Tracing
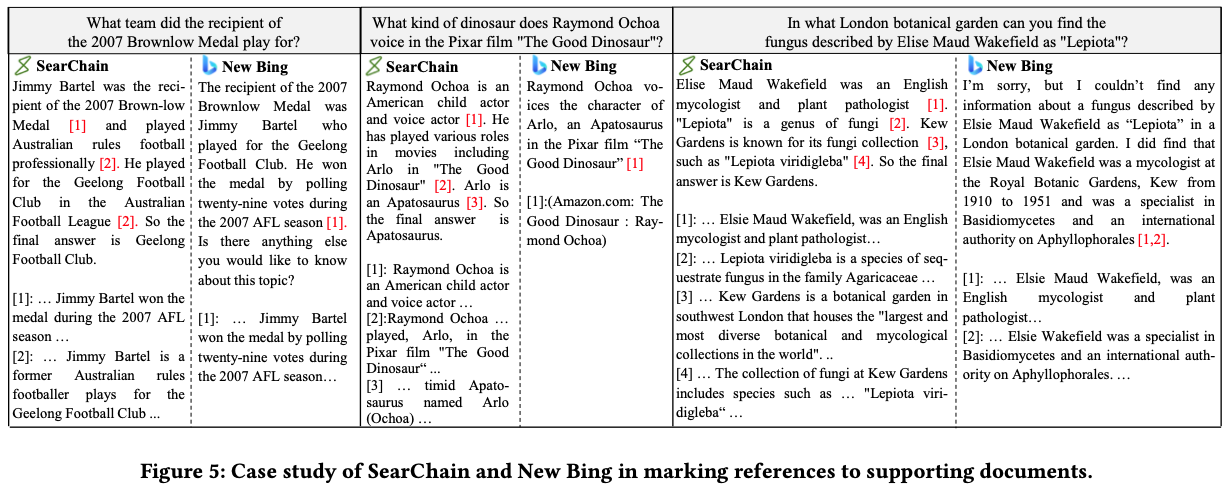
SearChain과 New bing search를 아래 두 가지 측면에서 비교
-
Scope of Knowledge Coverage (SKC) [0, +]:
-
답변에서 document에 의해 support 된다고 mark된 아이템의 수
-
SearChain (2.882) is better than New Bing (1.143)
-
-
Accuracy of Marking Position (AMP) [0, 1]
-
reference mark의 위치의 정확도, 3명의 대학원생이 평가
-
SearChain (0.80) is better than New Bing (0.45)
-
Efficiency Analysis
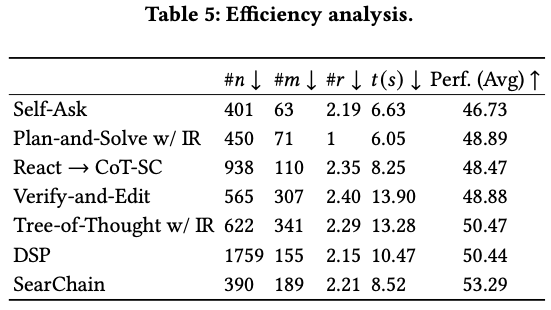
n : LLM의 input
m : LLM의 output
r : IR-LLM interaction 수
t : 응답 시간
나의 생각
[Unsolved Query]가 정말 잘 달릴까? Table 2에서 일부 확인 가능
Appendix와 본문을 봤을 때 threshold와 alpha를 정하는 과정에서 validation이 아닌 test set을 이용했을 가능성도 있는 거 같다.