Self-Rewarding Language Models
논문 정보
- Date: 2024-02-06
- Reviewer: 상엽
- Property: Instruction Tuning
Introduction
Self-Rewarding Language Models
- LLM 자체가 reward를 계산하는 LLM-as-a-Judge 모델
human preference와 LLM을 align 시키는 것은 instruction following performance를 큰 폭으로 향상시킬 수 있음.
아래는 대표적은 예시
-
RLHF (Reinforcement Learning from Human Feedback) :
-
기존 문제점 : 대용량 데이터에서 LLM을 학습할 경우, 데이터의 퀄리티 문제 등으로 인간이 선호하는 답변을 학습하는 것에 어려움을 겪음.
-
human preference를 갖는 reward 모델을 사전 학습, PPO 알고리즘을 이용한 LLM 학습
-
-
DPO (Direct Preference Optimization)
-
기존 문제점 : reward 모델을 학습하는 것은 복잡하면 unstable함.
-
reward 모델을 학습하지 않고 human preference를 LLM 학습에 직접적으로 이용 (https://arxiv.org/pdf/2305.18290.pdf)
-
Bradley-Terry preference model : pairwise comparison의 결과를 예측하는데 사용되는 확률 모델
-
최종 DPO 식 : Bradley-Terry preference model을 이용해 다음과 같이 전개 가능.
→ 수식 전개를 통해 reward term을 없앨 수 있었음. 명시적인 reward 모델 학습없이 preference data를 직접적으로 모델 학습에 사용하자.
-
Self-Rewarding
-
기존 문제점: human prefernece data의 size와 quality
-
instruction following task와 preference data를 생성하고 평가하는 것을 동시에 진행하는 LLM framework를 만들자. (Language model + reward model)
-
act as instruction following models generating responses for given prompts
-
generate and evaluate new instruction following examples to add to their own training set
-
-
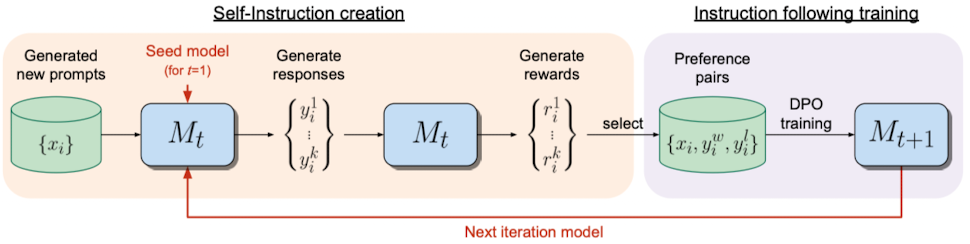
Iterative DPO procss를 이용해 학습
-
Starting from seed model (Llama 70b, fine-tuned on Open Assistant)
-
아래 Iteration 진행
-
Generate new prompt
-
Generate candidate responses
-
Assign reward by that same model (LLM-as-a-Judge prompt)
-
After adding the preference pairs to the training data, DPO training
→ Instruction following performance 향상
→ 학습 과정에서 reward model이 지속적으로 업데이트 가능!!
Self-Rewarding Language Models
준비물
-
base pretrained language model
-
small amount of human-annotated seed data
아래 두 가지 능력을 모두 갖춘 모델을 만들자.
-
Instruction following: given a prompt that describes a user request, the ability to **generate a high quality, helpful (and harmless) response. **(원래의 task도 잘하며)
-
Self-Instruction creation: the ability to generate and evaluate new instruction- following examples to add to its own training set. (reward까지 가능한)
Initialization
아래 두 데이터를 모두 이용해서 fine-tuning 진행.
Instruction Fine-Tuning (IFT) data
-
human-authored (instruction prompt, response) general instruction following examples
-
Supervised fine-tuning (SFT)에 이용
-
perfect score (여기선 5점)을 받은 response들만 데이터셋에 추가
Evaluation Fine-Tuning (EFT) data.
-
(evaluation instruction prompt, evaluation result response) examples
-
LLM-as-a-Judge prompt 사용
-
DPO를 이용한 학습이 아닌 supervised fine-tuning에 사용된다는 것이 이후 preference data와 차이점.
-
필수적이진 않다고 하나 성능적으로 도움이 되었기 때문에 사용한다고 함. (이게 필수적이란 말인 거 같은데)
-
Justification (CoT reasoning) → final score (0~5점)으로 구성 됨.

Self-Instruction Creation
학습하며 자신의 training data를 스스로 수정할 수 있는 모델. 아래의 3단계 절차로 진행
-
Generate a new prompt : IFT 데이터 샘플링을 통해 few-shot example 제공, 새로운 prompt x_i 생성
-
Generate candidate responses : N개의 candidate response 생성 {y{i}^{1},…,y{i}^{N}}
-
Evaluate candidate responses: 동일 모델에서 LLM-as-a-Judge ability 이용 N개의 candiate에 대해 reward 평가 진행. (r_{i}^{n} \in [0, 5])
Instruction Following Training
AI (Self-)Feedback을 통한 추가 학습 데이터 생성
AI Feedback Training
-
Prefereence pairs
-
(instruction prompt xi, winning response y{i}^{w}, losing response y_{i}^{l})
-
winning (highest score) & losing pair (lowest score), 같으면 버리기
-
DPO 학습 때 preference 학습에 이용
-
-
Positive example only
-
(instruction prompt , response)
-
supervised fine-tuning용 ses
-
→ preference pairs를 사용할 때 더 좋은 성능을 보였음.
Overall Self-Alignment Algorithm
M_1,…,M_T : a series of model where each successive model t uses augmented training data created by the t − 1th model
\text{AIFT}(M_T) : AI Feedback Training data created using model Mt.
M0 : Base pretrained LLM with no fine-tuning.
M1 : Initialized with M0, then fine-tuned on the IFT+EFT seed data using SFT.
M2 : Initialized with M1, then trained with AIFT(M1) data using DPO.
M3 : Initialized with M2, then trained with AIFT(M2) data using DPO.
(This iterative training resembles the procedure used in Pairwise Cringe Optimization and Iterative DPO introduced in Xu et al. [2023]; however, an external fixed reward model was used in that work.)

Experiment
Llama 2 70B를 base 모델로 이용.
Seed Training Data
-
IFT Seed Data
-
human-authored examples provided in the Open Assistant dataset for instruction fine-tuning.
-
we use 3200 examples, by sampling only** first conversational turns** in the English language that are high-quality, based on their human annotated rank
-
이를 학습한 모델을 SFT baseline이라 함.
-
-
EFT Seed Data
-
Open Assistant data에서는 동일 prompt에 대해 여러 답변과 각각의 rank가 제공됨.
-
CoT justifications and final scores out of 5을 구하기 위해 SFT baseline을 이용. human label과 SFT 모델의 결과의 순위가 동일한 데이터만 이용. 최종적으로 1775 train & 531 evaluation examples 이용
-
Evaluation Metrics
-
Instruction Following
-
AlpacaEval evaluation prompt와 GPT-4를 이용해서 256개 test prompt에 대해서 평가 진행.
-
pairwise 평가 시 순서 바꿔서 실험했으며 결과가 다르면 tie로 표기
-
GPT-4를 평가 기준으로 하여 AlpacaEval 2.0 leaderboard의 805 prompt를 평가, GPT-4 Turbo와 win rate 비교
-
-
Reward Modeling
-
Open Assistant dataset을 이용해 구축한 evaluation set에서 human ranking과 correlation 비교
-
모든 pairwise 조합에 대해서 order 일치 여부를 판단. (rank가 더 높다, 낮다.)
-
전체 rank에 대해 정확히 일치하는지 확인
-
Spearman correlation and Kendall’s τ.
-
human label이 5점인 항목에 대해서 실제로 몇 %나 5점을 주었는가도 검증
-
-
Training Details
Instruction folowing training
-
SFT
-
learning rate: 5.5e−6 which linearly decays to 1.1e−6
-
batch size: 16
-
dropout: 0.1.
-
only calculate the loss on target tokens instead of the full sequence.
-
-
DPO
-
learning rate: 1e−6 which linearly decays to 1e−7
-
batch size: 16
-
dropout: 0.1
-
β: 0.1.
-
early stopping by saving a checkpoint every 200 steps and evaluating generations using Claude 2 [Anthropic, 2023] on 253 validation examples
-
Self-Instrction creation
-
Generation of new prompts : fixed Llama 2-Chat 70B with 8-shot prompting
-
the other parts of the creation pipeline (generating the response, and evaluating it) use the model being trained.
-
candidate responses: 4 (temperature T = 0.7, p = 0.9)
-
candidate response 평가 시 variance를 방지하기 위해 3회 실행 후 평균
-
Results
Instruction Following Ability
EFT+IFT seed training performs similarly to IFT alone
- ** Iteration 1 (M1, **IFT + EFT data) vs SFT Baseline (Only IFT data)

→ 긍정적인 결과 : EFT 데이터를 학습해 reward 모델링을 진행해도 다른 task의 ability가 떨어지지 않는다.
→ 계속 iteration을 진행하자!
**Iteration 2 (M2) improves over Iteration 1 (M1) and SFT Baseline **
- Iteration 2 (M2) vs Iteration 1 (M1)

- Iteration 2 (M2) vs SFT baseline

M2에서부턴 명확한 성능 향상을 확인할 수 있음.
**Iteration 3 (M3) improves over Iteration 2 (M2) **
- Iteration 3 (M3) vs Iteration 2 (M2)

- Iteration 3 (M3) vs SFT baseline

→ M3는 M2와 비교해도 상당한 향상이 있었음.
Self-Rewarding models perform well on AlpacaEval 2 leaderboard
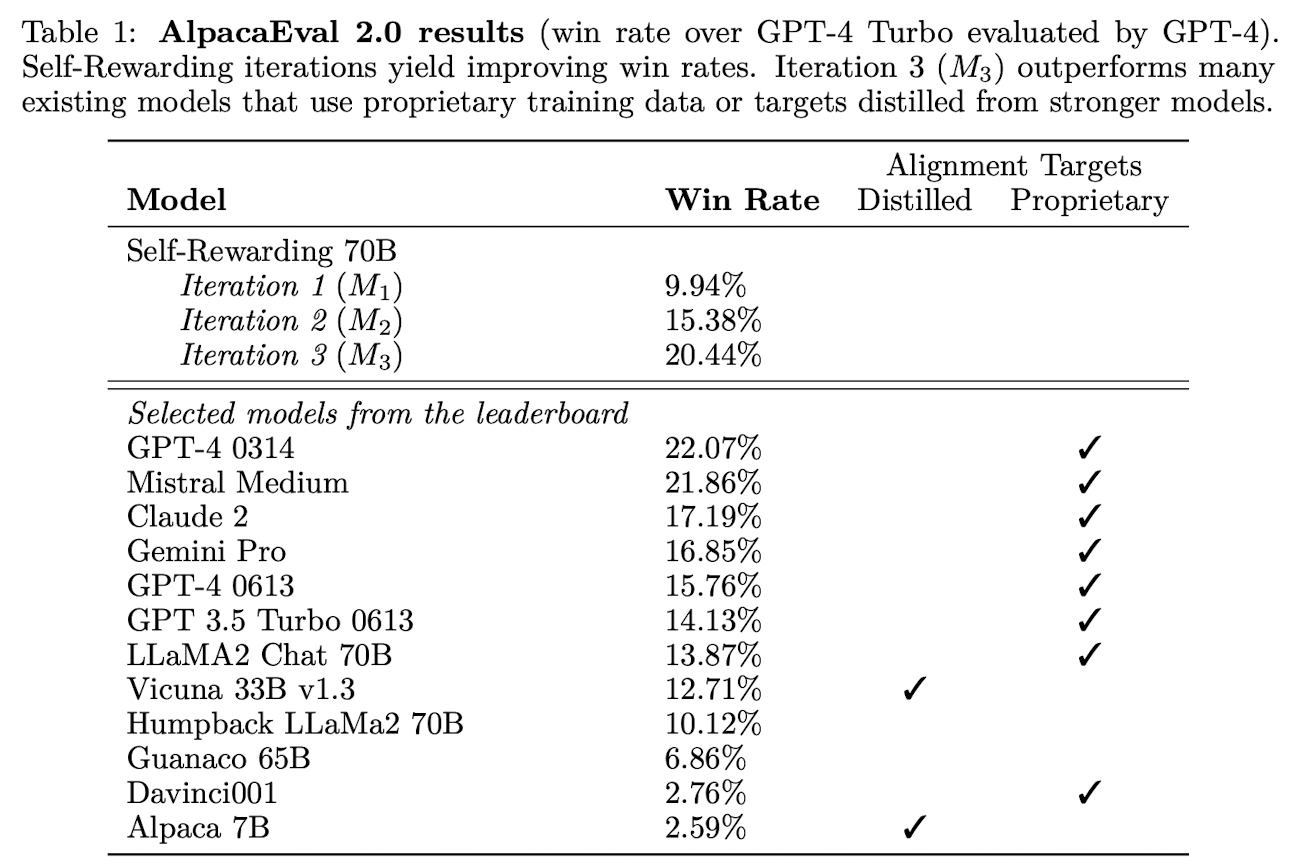
-
AlpacaEval 2.0 leaderboard format으로 평가 진행
-
Iteration이 진행됨에 따라 win rate가 증가하는 것을 확인할 수 있음.
-
Iteration 3 model은 대부분의 모델을 outperform함. (Claude 2, Gemini Pro, and GPT4 0613 등)
-
성능 좋은 모델들은 Proprietary alignment data를 이용한 경우가 많았던 반면 self-rewarding 모델은 small set of seed data만 이용.
Preference optimization outperforms augmenting with positive examples only
-
위에서 설명한 AI Feedback learning 전략 두 개 Prefereence pair, Positive example only 중 후자에 대해서는 효과를 거두지 못함.
-
Positive only vs SFT Baseline : 29% wins vs 30% wins
Data distribution analysis
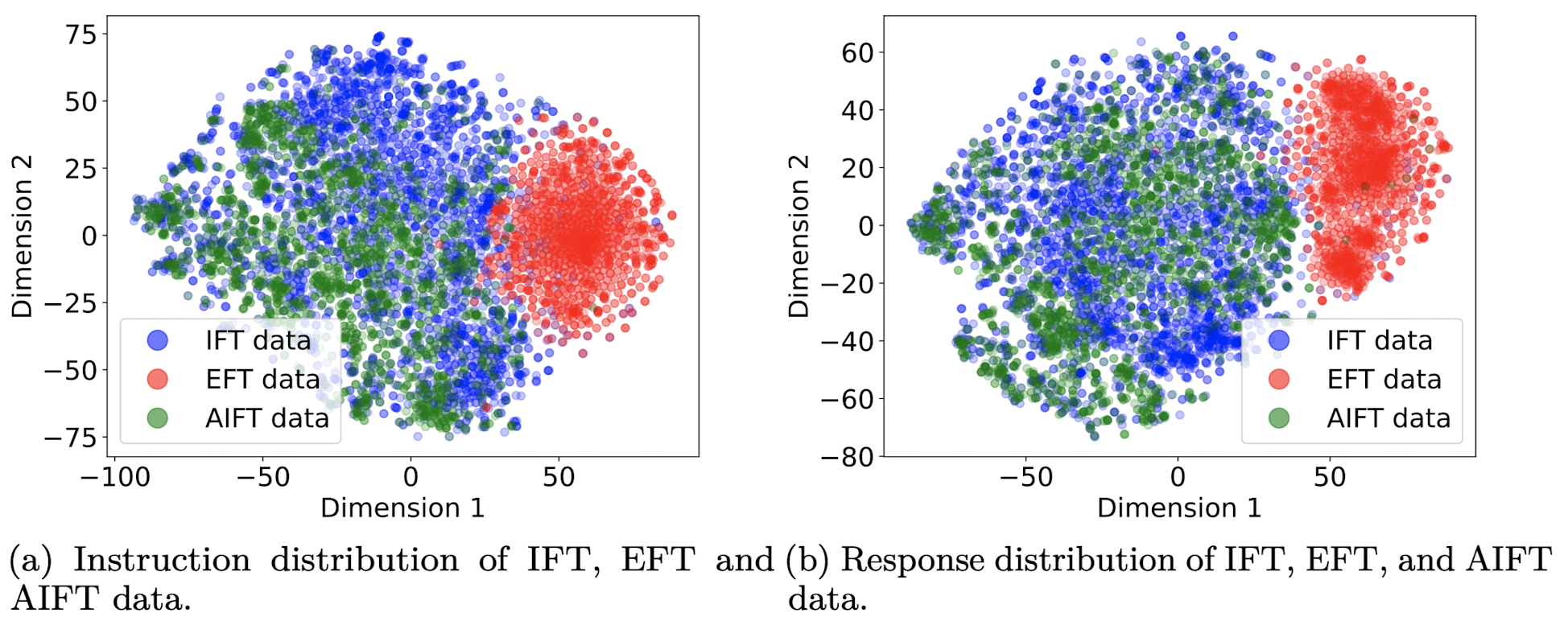
-
IFT, EFT, AIFT 데이터에 대해서 t-SNE를 이용해 데이터 분포를 봄.
-
IFT and AIFT(M1) examples 사이에 좋은 overlap을 형성, EFT는 조금 다른 영역에 위치
-
M1 have an average length of 1092, for M2 they are 1552, and for M3 they are 2552
- 길이의 증가와 성능간에 관계가 있는 것은 아닐까 추정한다 함. (GPT-4가 긴 답변에 대해서 bias를 갖는다는 논문 있었던 거 같은디….)
Reward Modeling Ability
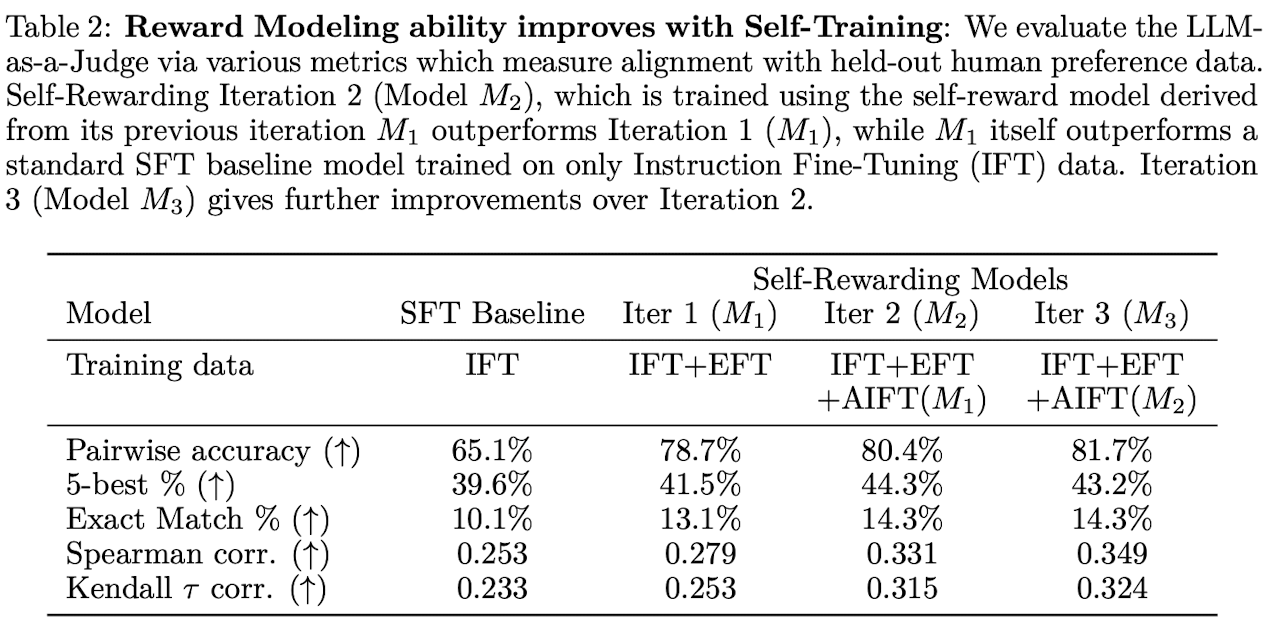
EFT augmentation improves over SFT baseline
-
구체적인 reward modeling과 관련된 EFT 데이터 추가는 당연한 성능 향상을 보임.
-
65.1% → 78.5% (13.4%p 상승)
Reward Modeling ability improves with Self-Training
-
self-reward training round를 진행함에 따라 성능 향상이 확인 됨. (instruction following ability 역시 향상 됐었음.)
-
Iteration 2 (M2)는 Iteration 1 (M1) 대비 모든 성능이 향상 됨.
-
Iteration 3 (M3)은 Iteration 2 (M2) 대비 3가지 metric에서 성능 향상 됨.
-
추가적인 ETF 데이터를 이용한 reward 모델링 없이 AIFT가 생성한 데이터를 이용한 SFT 학습만으로 성능 향상이 이뤄진다는 점에서 큰 의미가 있다. (because the model is becoming better at general instruction following, it nevertheless also improves at the LLM-as-a-Judge task.)
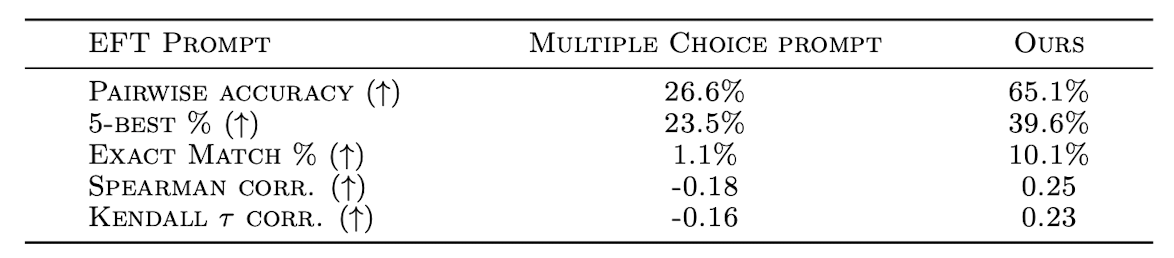
Importance of the LLM-as-a-Judge Prompt
-
다양한 prompt를 사용해봤으며 현재 prompt가 제일 좋았다.
-
Ours : 단계별로 점수를 추가하는 방식, 점수를 추가하기 위한 조건으로 다양한 quality 측면을 추가함.(읽어보니 신기했음.)
-
Li et al. [2023a] : bullet 형식으로 점수와 그것에 대한 설명이 있음.
-
-
두 prompt의 성능 차이는 크다.
Related work
-
RLHF : 앞에서도 설명을 많이 했다.
-
RLAIF : 전에 리뷰를 했다.
Conclusion
-
While this is only a preliminary study, we believe this is an exciting avenue of research because this means the** model is better able to assign rewards in future iterations** for improving instruction following – a kind of virtuous circle.
-
it still allows for the** possibility of continual improvement beyond the human preferences **that are typically used to build reward models and instruction following models today.
Limitations
-
단일 세팅에서 3 iteration 밖에 실험을 진행하지 못함. → 다양한 크기 모델에 대해 여러 iteration으로 실험해보자.
-
GPT-4 평가 외에 다른 automatic evaluation도 해보자.
-
길이 증가에 따른 성능 향상에 대해 실험하지 못함.
-
It would also be good to understand if so-called “’reward-hacking” can happen within our framework, and in what circumstances.
-
다른 모델들로도 위와 같은 framework로 실험을 해보고 싶다.
-
사전에 만들어진 human evaluation set 외에도 사람의 평가를 해보고 싶다.
-
이와 같은 방식으로 reward 모델 개선이 가능하다면 현재 연구가 이뤄지지 않고 있는 reward modeling과 safety training에 대해서 연구하고 싶다.
사견
-
내가 생각이 들었던 부분 대부분이 Conclustion과 Limitation에서 있더라.
-
읽어보면 생각보다 이전 논문과의 차이점이 좀 적은 거 같아서 미래의 가능성 부분을 강하게 어필하는 거 같다.
-
엄청 핫했던 거에 비해서는 모델의 특이점은 적은 느낌 + reward model을 없앤다는 생각은 쉽긴 하지만 실제로 했다는 것이 큰 의미인 거 같기도 하다.
-
scoring prompt 방식은 당장 적용해보자.
-
LLM이 자신이 만든 데이터를 보고 스스로 평가하는 것에서 human preference를 학습한다고 하기에는 애매하지 싶다.
-
설득 포인트가 현재는 성능뿐임.
-
인간을 위한 LLM이 인간의 선호를 넘어선 preference를 찾는다는 무슨 말일까
-
generated data를 써서 학습하는 것의 문제점에 대한 논문도 있던데 조금 더 조사를 해보면 좋을 거 같다.
-
→ 종합적으로 LLM만을 이용하는 것이 어떻게 가능한지 다양한 향후 연구 기대
- 우리같은 작은 기업과 학생들에게 메타의 연구 방향은 상당히 흥미롭다.
참고
-
RLHF : https://arxiv.org/pdf/2203.02155.pdf
-
DPO : https://arxiv.org/pdf/2305.18290.pdf
-
PPO : https://arxiv.org/pdf/1707.06347.pdf