SimPO: Simple Preference Optimization with a Reference-Free Reward
논문 정보
- Date: 2024-05-28
- Reviewer: 건우 김
- Property: Alignment, RLHF
SimPO: Simple Preference Optimization with a Reference-Free Reward
1. Introduction
LM이 Human intention과 alignment를 형성하기 위해서는 (helpful, honest, harmless), human feedback으로 부터 학습하는 것이 효율적임. 이전 classical RLHF (e.g. PPO)는 좋은 성능을 보여주긴 하지만 아시다시피 multi-stage procedure (Training reward model + Optimize policy model)이 필요함.
최근에는 DPO와 같이 simpler offline preference algorithm이 많이 소개됨. DPO는 reward function을 reparameterize하여 preference data로 부터 policy model을 directly 학습시켜 별도의 reward model이 필요가 없음. (simplicity & training stability 보장)
DPO에서 implicit reward는 current policy model과 SFT model의 response의 likelihood의 log ratio로 구성이 되어 있음.
→ 하지만, 연구진들은 DPO reward 식은 policy model에 의해 생성되는 response의 average log likelihood를 통해 inference를 진행한다는 점에서 discrepancy가 존재하여 suboptimal performance를 보인다고 가정함.
본 연구에서는, DPO 보다 더 simple하고 효과적인 offline preference optimization algorithm인 SimPO를 소개함. 이 알고리즘의 핵심은 reward function을 generation metric과 align을 시킨 점이다.

SimPO는 크게 두 가지 components가 있음
-
length-normalized reward: policy model을 이용하여 response 내에 있는 모든 Token들의 log probability의 평균 값을 통해 산출
-
target reward margin: winning / losing responses 간의 reward difference를 보장함
저자가 정리하는 SimPO의 3가지 주요 properties
-
Simplicity: 별도의 reference model이 필요하지 않음.
-
Significant performance advantage: DPO와 variants( KTO, DPO-R, ORPO et.c)과 비교해도 consistent하게 instruction-following benchmarks에서 가장 높은 성능을 보여줌
-
Minimal length exploitation: SFT나 DPO에 비해 response length가 짤음
2. SimPO: Simple Preference Optimization
2.1 Background: DPO
DPO는 reward function (r)을 다음과 같이 reparameterize함.
-
pi_theta: policy model
-
pi_ref: reference policy (SFT model)
-
Z(x): partition function
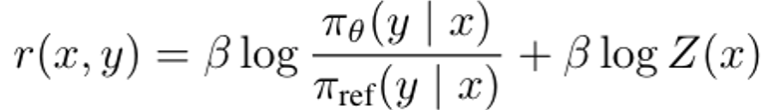
위 reward function을 Bradley-Terry (BT) ranking objective에 적용하면,
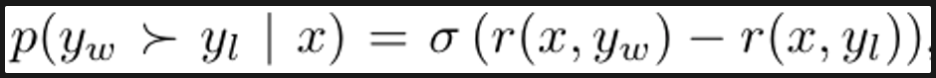
아래와 같이 도출됨.
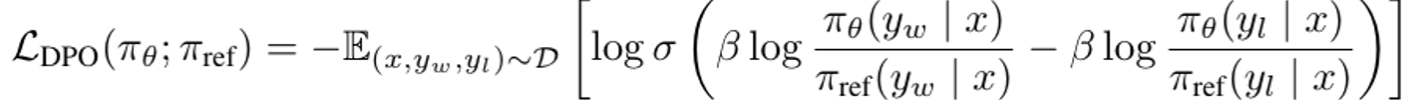
2.2 A Simple Reference-Free Reward Aligned with Generation
Discrepancy between reward and generation for DPO
앞에서 언급한 DPO에서 reward와 generation 간의 discrepancy에 집중을 해봄.
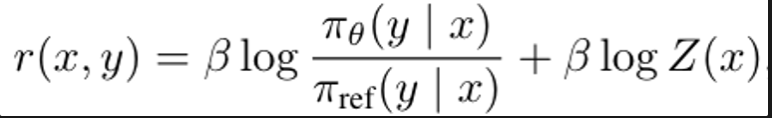
해당 implicit reward는 두가지 한계점이 존재함
-
별도의 reference model (pi_ref)가 필요하기 때문에, 추가적인 memory/computational cost가 요구됨
-
Training 단계에서 사용되는 reward와 inference 단계에서 generation metric에 사용되는 reward 간의 discrepancy가 존재함.
-
Training을 생각해보면, reward function을 최적화도록 되어 있고, 해당 function은 policy model (pi_theta)이 올바른 response를 생성하도록 유도함.
-
Generation을 생각해보면, policy model (pi_theta)는 input text (x)D에 대해서 average log-likelihood를 maximize하는 식으로 sequence를 생성함.
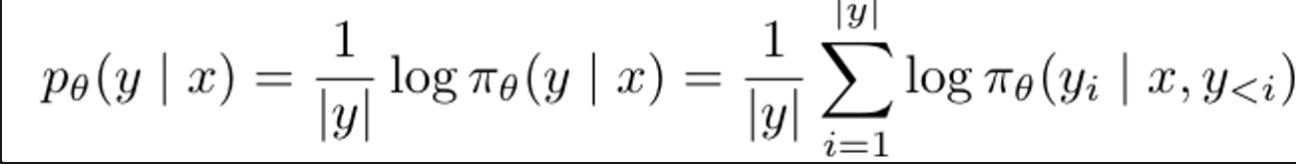
→ 즉, training은 preference data (ranking)을 기준으로 model을 optimzie 시킴.
-
(x, yw, yl) triplet에서 yw의 reward가 yl의 reward 보다 높으면 r(x, yw) > r(x, yl), yw가 더 좋은 response로 간주함.
-
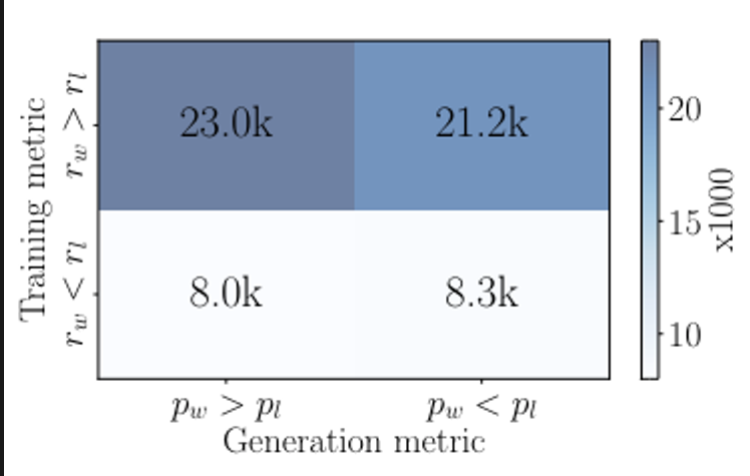
하지만 r(x, yw) > r(x, yl)을 만족한다고 해서 likelihood p_theta(yw x) > p_theta(yl x)를 항상 만족하지 않음. 아래 figure를 보면 DPO로 학습한 모델은 50%는 만족하지 않음.
Length-normalized reward formulation
위에서 언급한 DPO의 문제점을 고려해보면, reward function이 likelihood metric과 align이 되도록 다음과 같이 다시 구성해야한다.
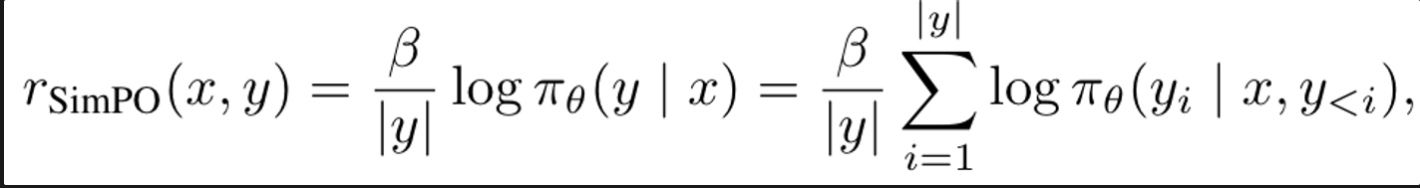
-
여기서 length normalization term을 지우게 되면, lower-quality with longer sequence를 생성하도록 bias가 생길 수 있음.
-
reference model을 없애며, computation/memory efficient한 점을 보여줌
2.3 The SimPO Objective
Target reward margin
Bradley-Terry objective에 target reward margin term (r)을 추가해주며 winning response에 대한 reward가 losing response보다 최소한 r 만큼 차이 나도록 보장해줌.
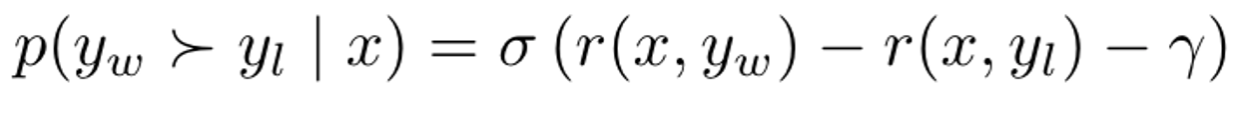
Objective function
위에선 언급한 내용들을 종합하여 최종 SimPO objective function은 다음과 같이 전개할 수 있음.
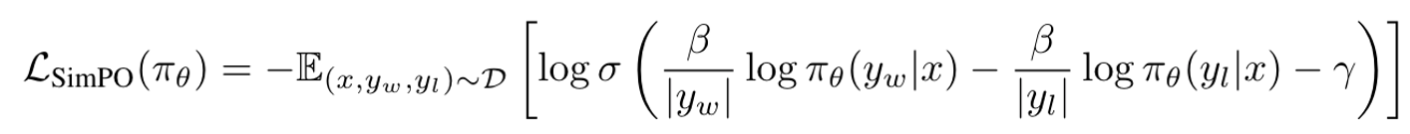
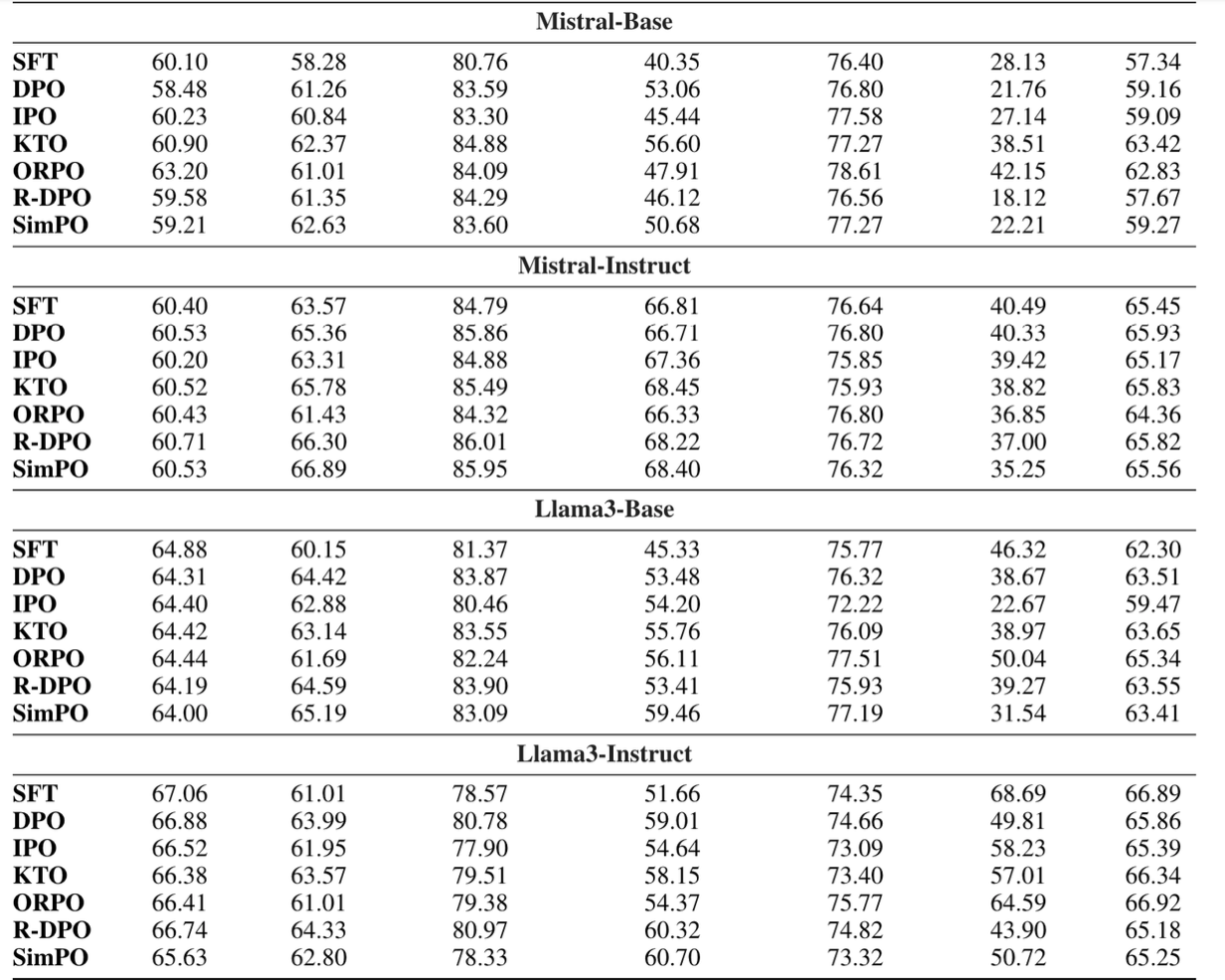
3. Experimental Setup
모든 실험은 Llama3-8B, Mistral-7B 각각에 대해 Base, Instruct setting으로 진행이됨.
Base: Zephyr와 동일하게 사용
-
init model (llama, mistral) 을 SFT 모델로 학습
-
UltraChat-200k dataset에 대해 base model을 학습
-
preference optimization 진행
-
UltraFeedback dataset에 대해 sft model을 학습
Instruct: off-the-shelf instruction-tuned model을 SFT model로 사용
-
meta-llama/Meta-Llama-3-8B-Instruct
-
mistralai/Mistral-7B-Instruct-v0.2
→ SFT model과 preference optimization에서 distribution shift를 완화하기 위해 preference dataset을 SFT model을 사용해서 구축함. (Iterative DPO alignment 2024)
-
UltraFeedback에서 하나의 prompt (x)에 대해 chosen/rejected response를 SFT로 각각 5번씩 생성.
-
PairRM으로 highest-score를 yw, lowest-score를 yl로 지정함
Evaluation benchmarks
-
MT-Bench
-
AlpacaEval 2
- win rate (WR) / length-controlled win rate (LC)
-
Arena-Hard v0.1
Baselines

-
fair한 비교를 위해 각 baseline에 대해서 Hypermarameter tuning을 많이 진행함
-
결론부터 말하면, variants of DPO들은 일반 DPO보다 성능이 구림
4. Experimental Results
4.1 Main Results and Ablations
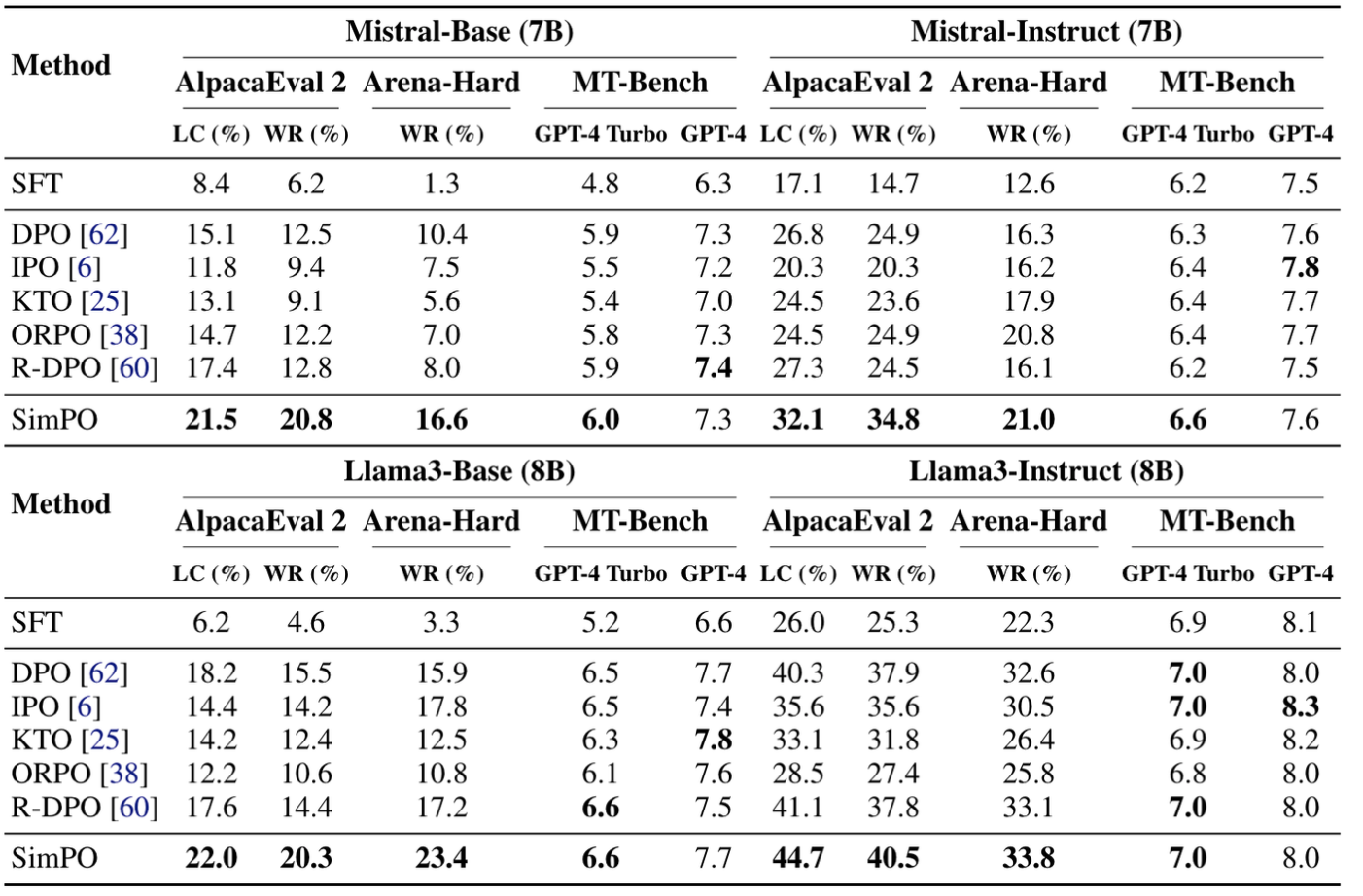
-
SimPO는 existing methods 대비 consistent하게 높은 성능을 보여줌
-
MT-Bench에서 점수들이 다 비슷한 점수대에 있는 이유는, benchamrk 자체가 데이터셋이 적어 randomness 요인으로 차이가 난 것
-
당연하게도** Instruct** 세팅에서 performance gain이 비약적으로 보임
-
SimPO에서 제안하는 components는 다 매우 중요함
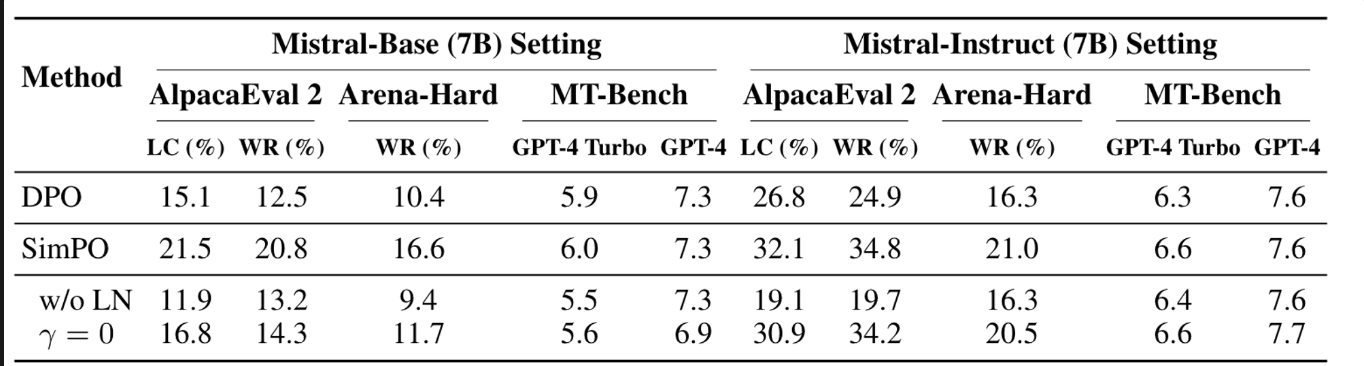
- Length Normalization: 이것을 지우면 (w/o LN), 가장 큰 폭으로 성능이 떨어지게 됨
→ this leads to the generation of long and repetitive patterns, substantially degrading the overall quality of the output

- Target reward margin: 이것을 지우면 (r=0), 역시 성능이 떨어지게 되는데 target reward margin이 필요함을 보임
4.2 Length Normalization (LN) Prevents Length Exploitation
LN leads to an increase in the reward difference for all preference pairs, regardless of their length
| SimPO는 reward difference가 target margin 이상으로 차이가 나도록 Bradely-Terry 목적함수가 되어 있는데, 여기서 reward difference r(x,yw)-r(x,yl)과 length difference | yw | - | yl | 간의 관계를 분석함. |
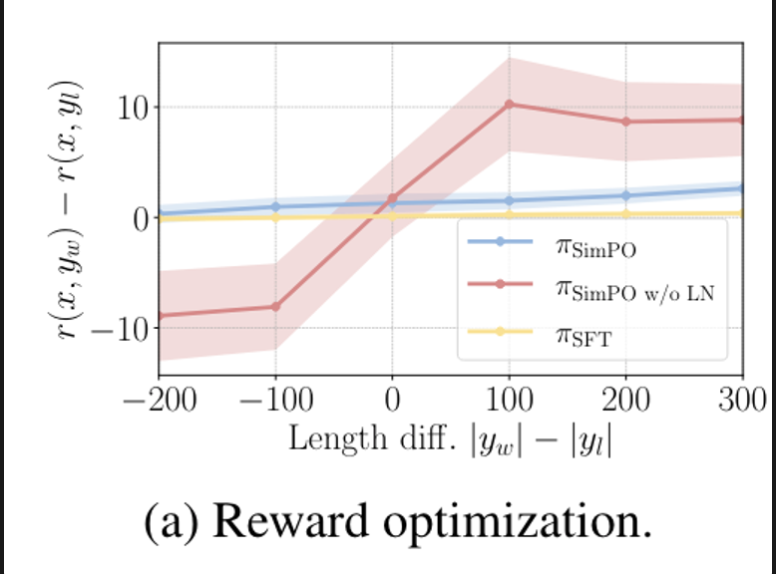
-
LN을 사용하는 SimPO는 consistent하게 모든 response pairs에 대해서 positive reward margin을 보임.
-
LN을 사용하지 않는 경우는 winning response가 losing response 보다 길이가 짧을 때, negative reward를 보임 → model이 해당 Instance에 대해 잘 학습하지 못함을 알 수 있음
Removing LN results in a strong positive correlation between the reward and response length, leading to length exploitation.
average log likelihood와 response length에 대해 상관관계를 분석함
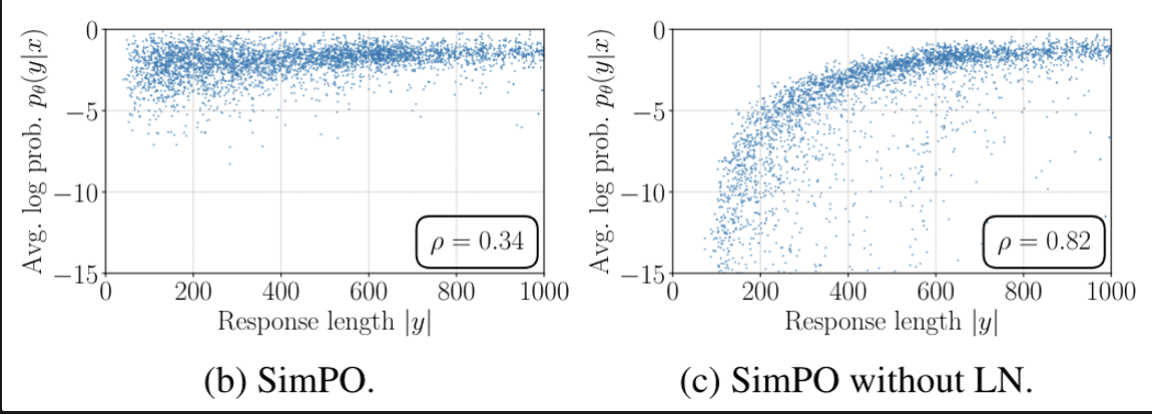
- LN을 사용하지 않은 경우는 likelihood와 response legnth간의 뚜렷한 상관관계를 보여줌
→ tendency to exploit length bias and generate longer sequences
4.3 The impact of Target Reward Margin in SimPO
Influence of γ on reward accuracy and win rate
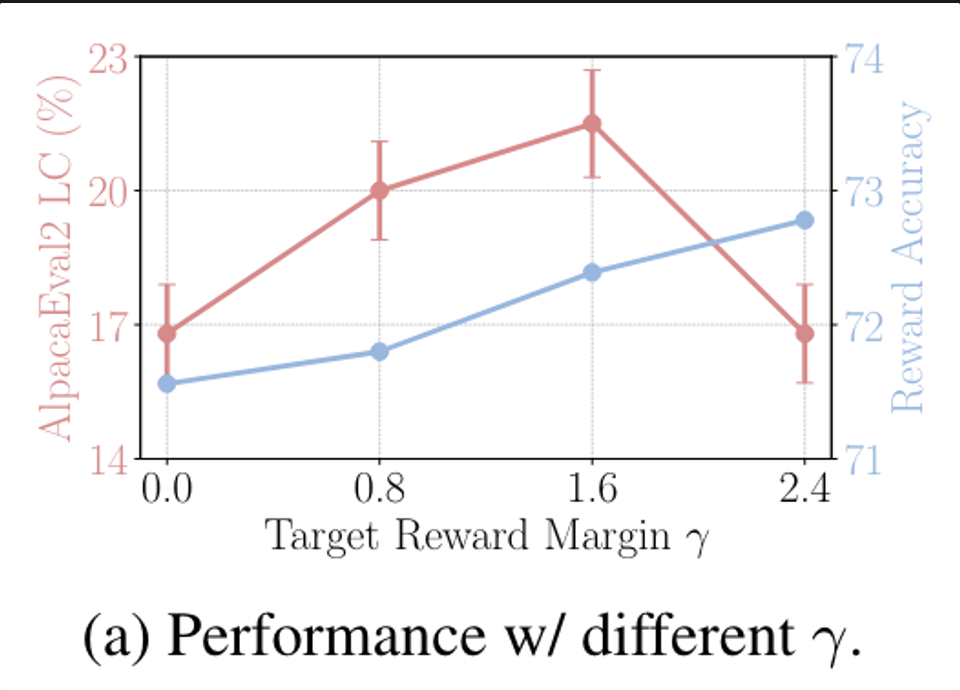
-
Reward accuracy는winning response가 losing response 보다 더 높은 reward를 받는 비율을 의미함
-
실험 결과를 보면 target reward margin이 올라감에 따라 reward accuracy가 향상되기는 하지만, geneartion quality (AlpacaEval2 LC) 자체가 보장되지는 않음
4.4 In-Depth Analysis of DPO vs. SimPO
-
Likelihood-length correlation
-
DPO reward implicitly facilitates length normalization.
-
DPO reward 식을 보면 length normalization term이 explicit하게는 없지만, policy model과 reference model 간의 log ratio가 length bias를 완화시켜 줄 수 있는 역할을 할 수 있음.
-
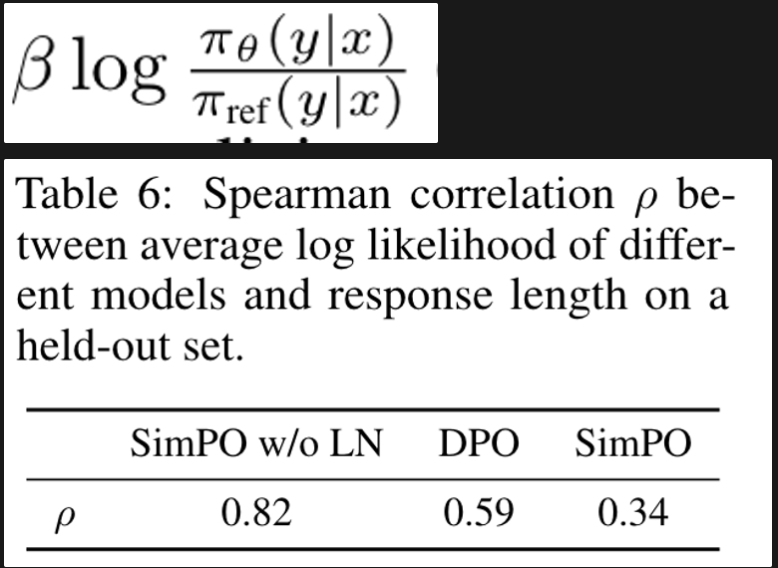
-
Reward formulation
-
DPO reward mismatches generation likelihood.
-
앞에서 언급한대로 DPO의 reward formulation과 average log likelihood metric 간의 차이가 있어서 generation quality에 영향을 줄 수 있음 → SimPO는 그렇지 않음
-
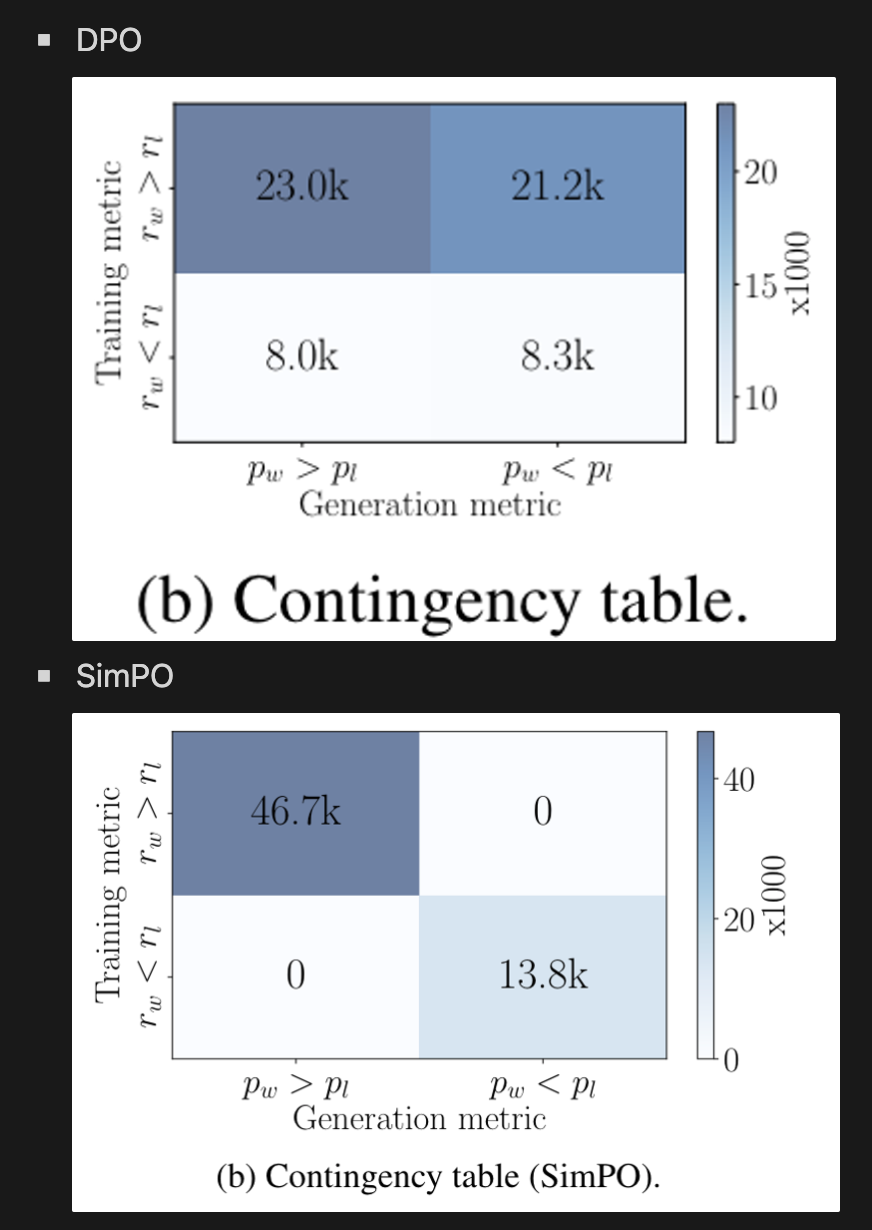
-
Reward accuracy
-
DPO lags behind SimPO in terms of reward accuracy
-
최종 학습된 reward가 preference lable에 대해 얼마나 잘 align이 되어있는지 확인한 결과, SimPO가 찢음
-
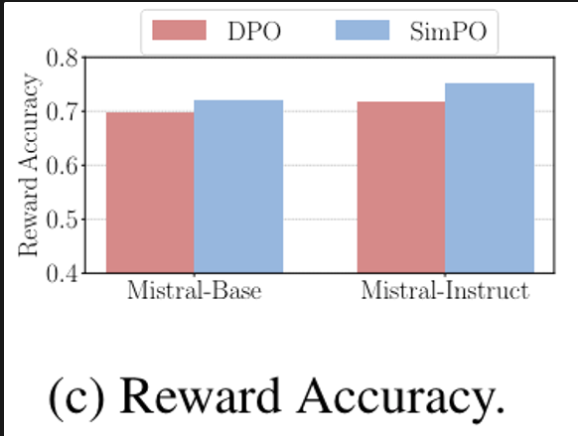
-
Algorithm efficiency
-
SimPO is more memory and compute-efficient than DPO
-
Reference model이 없는 SimPO는 DPO보다 GPU 학습 시간이 20% / GPU memory 사용량이 10% 정도 효과적임
-
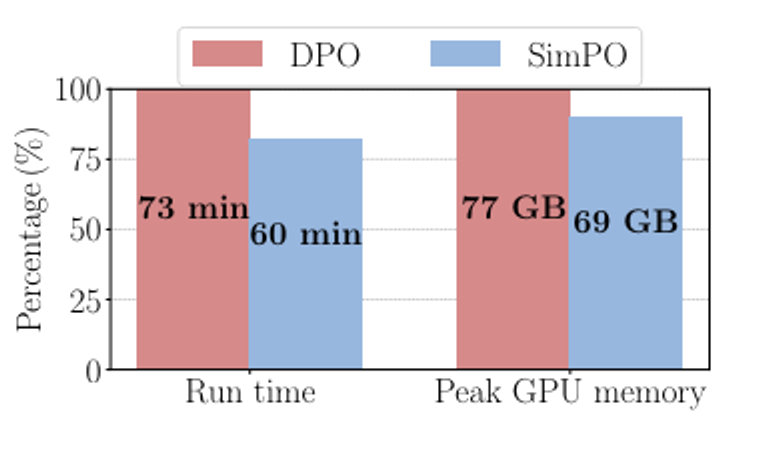
5. Conclusion
-
DPO의 reward term에서 reference model을 없애며 average log probability를 implicit한 Reward로 사용한 새로운 preference alignment 방법인 SimPO를 소개함.
-
방법도 간단하고 실험 결과도 (ORPO 대비) 매우 훌륭하지만, Appendix를 보면 huggingface leaderboard 결과가 sota는 아님.