Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
논문 정보
- Date: 2024-09-09
- Reviewer: hyowon Cho
- Property: Knowledge Distillation, LLM, Limited Budget
Google DeepMind (2024-08-30)
Introduction
많은 연구들이 이미 언어모델을 학습시키는 데 synthetic 데이터를 사용하고 있다. 이들 중, reasoning task에서 가장 일반적인 방법은 하나의 질문에 대해서 여러 가지 후보 답변들을 생성하게 하고, 이를 gold answer와 비교해, 맞는 정답을 가진 것들만 남기고 나머지는 버리는 것이다.
하지만, 이렇게 여러 개의 데이터를 strong LMs로 부터 생성해 사용하는 것은 비싸고, resource-intensive하다. 또한 현실적으로 우리가 사용할 수 있는 예산은 정해져있기 때문에 만들 수 있는 solution도 그리 많지는 못하다.
이 논문에서는 fixed compute budget 상황에서, weaker but cheaper (WC) model이 우리가 일반적으로 생각하는 것과 다르게 stronger but more expensive (SE) model을 사용하는 것보다 낫다고 주장한다.
이를 증명하기 위해 저자들은 크게 3가지 축에서 데이터들에 대한 비교를 진행한다.
-
coverage, the number of unique problems that are solved,
-
diversity, the average number of unique solutions we obtain per problem,
-
false positive rate (FPR), the percentage of problems that arrive at the correct final answer but with a wrong reasoning.
당연히 고정된 예산 하에서, WC model이 SE model보다 더 많은 데이터를 만들어낼 수 있다. 하지만 SE가 당연히 퀄리티는 높을 것. 그렇기 때문에, WC가 더 높은 coverage and diversity 그리고 동시에 higher FPR를 가질 것이라고 이야기한다.
이후, 저자들은 이 추측을 검증하기 위해서 SE and WC로 만든 데이터를 이용해서 모델들을 finetuning한다. 단순 하나의 방법이 아니라 여러 가지로.
-
knowledge distillation, where a student LM learns from a teacher LM (Hinton et al., 2015);
-
self-improvement, where an LM learns from self-generated data (Huang et al., 2022); and
-
a new paradigm we introduce called Weak-to-Strong Improvement, where a strong student LM improves using synthetic data from a weaker teacher LM.
저자들은 여러 개의 벤치마크에서 아주 일관적 SE-generated data 보다 WC-generated data로 학습한 결과가 훨씬 좋음을 보인다 (일반적인 믿음과 달리) 즉, WC-generated data에서 샘플링하는 것이 훨씬 compute optimal하다는 것.
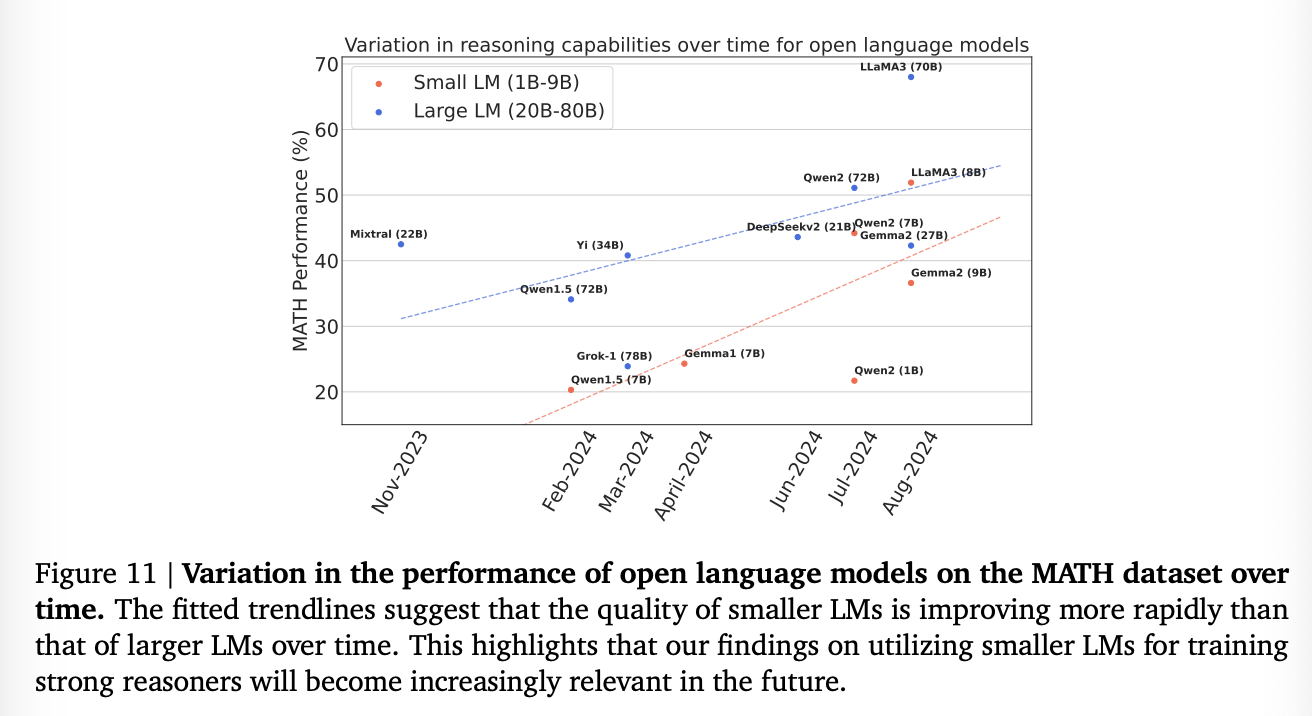
어느 정도 큰 스케일에서 더 작은 모델과 큰 모델의 성능 갭이 점차 줄어들고 있는 요즘, LM reasoners를 어떤 방식으로 학습할지 생각을 하게 한다.
Preliminaries
-
D = {𝑞𝑖, 𝑎𝑖} = training
-
reasoning questions = 𝑞𝑖
-
final answers = 𝑎𝑖
다 아시겠지만, 이들을 가지고 synthetic data를 만드는 방법은 다음과 같다:
-
sample multiple solutions for each 𝑞𝑖 at a non-zero temperature
-
create the synthetic data with reasoning chain & generated answer
-
filter the incorrect solutions by comparing 𝑎ˆ𝑖 𝑗 to 𝑎𝑖 and removing the solutions whose final answer do not match that of the gold answer
Metric
-
𝑐𝑜𝑣𝑒𝑟𝑎𝑔𝑒@𝑘 (aka 𝑝𝑎𝑠𝑠@𝑘)
- k개의 솔루션을 생성했을 때, 최소 하나 이상이 정답을 맞춤
-
𝑑𝑖𝑣𝑒𝑟𝑠𝑖𝑡𝑦@𝑘
- k개의 답변을 생성했을 때, k개중 정답을 맞춘 solution 개수의 평균
-
false positive rate
- 답은 맞았는데, reasoning이 잘못된 비율
Compute-Matched Sampling and Training
당연히 고정된 예산, 고정된 sampling budget (FLOPs) 상에서, 사람들은 더 weaker but cheaper (WC) model을 통해서 더 많은 샘플들을 만들어낼 수도 있고 혹은 stronger but more expensive (SE) model을 통해 더 적지만 양질의 데이터를 만들 수 있다.
WC model가 𝑃𝑊𝐶 parameters를 가지고, SE가 𝑃𝑆𝐸 parameters를 가진다고 하고, 두 모델을 이용해서 무조건 같은 예산만을 사용할 수 있다고 하면, 만들 수 있는 데이터의 개수는 다음과 같이 차이가 난다.
-
Following (Kaplan et al., 2020), FLOPs per inference token = 2𝑃
-
FLOPs for 𝑇 inference tokens = 2𝑃𝑇
-
assume that generating each solution requires an average of 𝑊 inference tokens
-
𝑆𝑊𝐶 and 𝑆𝑆𝐸 = number of samples we generate per question
-
total cost
-
𝐶𝑜𝑠𝑡𝑊𝐶 = 𝑛×𝑆𝑊𝐶 ×𝑊 × (2𝑃𝑊𝐶)
-
𝐶𝑜𝑠𝑡𝑆𝐸 = 𝑛×𝑆𝑆𝐸 ×𝑊 × (2𝑃𝑆𝐸)
-
𝑆𝑊𝐶 =(𝑃𝑆𝐸/𝑃𝑊𝐶)* 𝑆𝑆𝐸
-
즉, 고정 예산에서 𝑃_𝑆𝐸/𝑃_WC 만큼 WC에서 더 데이터를 만들어낼 수 있다는 말. 이렇게 둘 중 하나로 데이터를 만든 이후, 고정된 스텝으로 모델들을 학습시켜보고 비교하여 데이터들의 유용성을 판단할 수 있다.
언급했듯 학습 방법은 3가지:
- knowledge distillation(Student-LM finetuning)
- 일반적으로, student 모델의 학습용으로 만들어지는 데이터는 더 똑똑하고 강한 모델에서 만들어지는 데이터를 사용한다. 높은 퀄리티를 보장하기 위해서.
- self-improvement
- Prior work (Singh et al., 2023)는 finetuning a WC model through self-generated data는 1의 방식보다 훨씬 별로라고 증명해냈다. 하지만, 해당 연구의 비교 방식은 같은 예산을 사용하지 않았기 때문에 정당하지 않다고 언급한다. 따라서, 다시 정당하게 동일한 세팅으로 다시 하여 실험을 재개한다.
- 그리고 이들이 제안하는 novel weak-to-strong improvement paradigm
-
weak-to-strong improvement (W2S-I)은 일반적인 방법과 달리, 강한 모델은 약한 모델의 데이터로 학습하는 방식이다.
-
즉, 약한 모델도 강한 모델을 발전시킬 수 있다
Experimental Setup
-
Datasets
-
MATH
-
GSM-8K
-
-
Data Generation
-
Gemma2 models for synthetic data generation
-
Gemma2-9B : Gemma2-27B = WC : SE models
-
MATH using a 4-shot prompt
-
GSM-8K using an 8-shot prompt
-
9B model가 27B와 3배 정도 크기 차이가 나므로, 데이터를 3배 정도 더 만들 수 있다.
-
실험에서는 둘 나 낮은 예산의 경우: a low budget, where we generate 1 and 3 candidate solutions per problem from Gemma2-27B and Gemma2-9B
-
높은 예산의 경우: high budget, where we generate 10 and 30 candidate solutions per problem
-
-
Synthetic Data Evaluation
-
같은 비용을 가지는 개수끼리 coverge/diversity@k 계산
-
FRP는 50개 for each model에 대한 human eval & 500개에 대한 LLM eval
-
-
Evaluating Finetuned Models:
- pass@1 accuracy
Experiments and Results
-
(§5.1) we analyze the data along various quality metrics .
-
(§5.2) Subsequently, we present the supervised finetuning results for the different setups .
-
(§5.3) Finally, we perform ablation studies to study the impact of dataset size, sampling strategy, and the role of quality dimensions in the model performance.
1. Synthetic Data Analysis
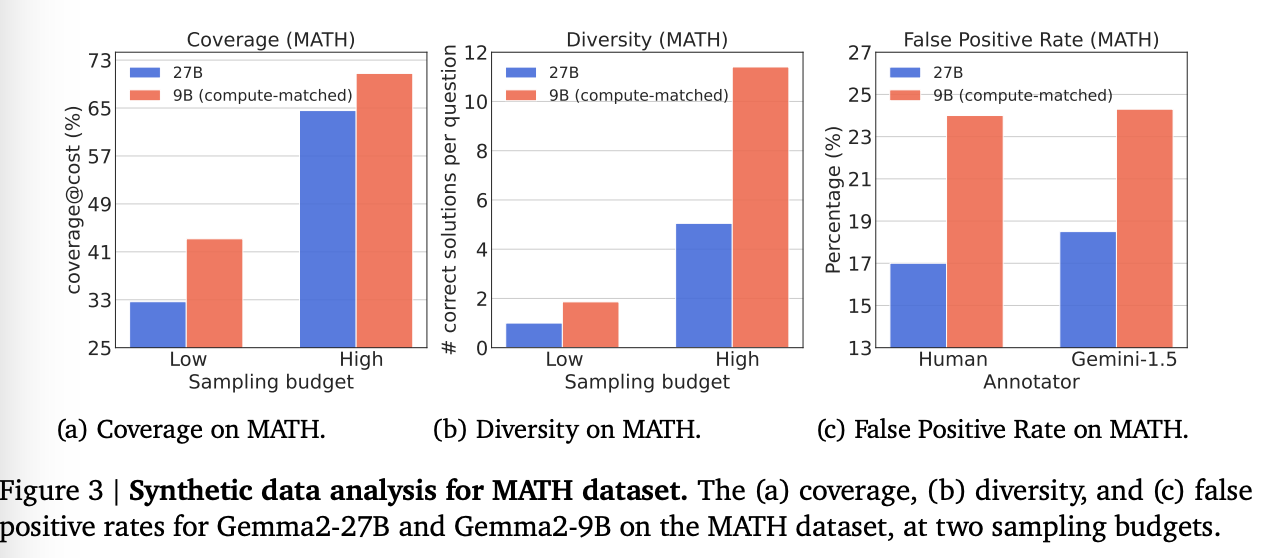
1) Coverage
결론: Gemma2-9B (WC)이 Gemma2-27B (SE)보다 훨씬 좋았다.
-
MATH:
-
11% and 6% at the low and high sampling budgets,
-
8% and 1% for GSM-8K.
즉, 더 많이 만드는 것이 퀄리티가 더 낮더라도 더 많이 문제를 푸는데 도움이 되었다. converge trend는 다양.
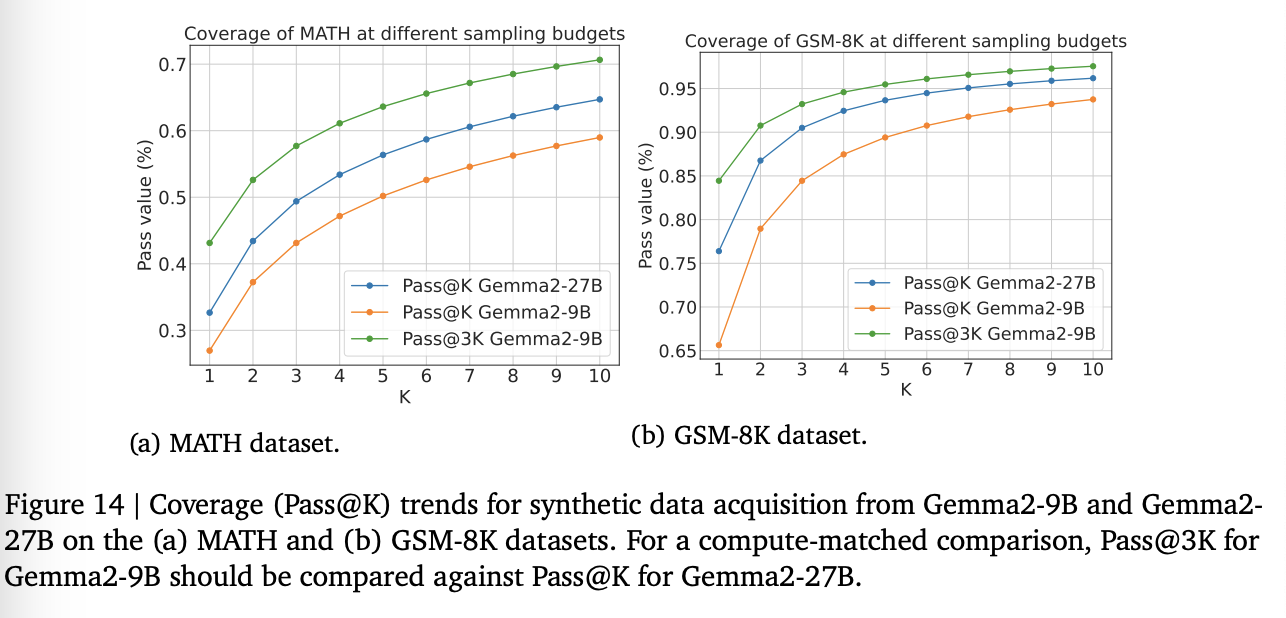
추가적으로, 더 많이 데이터를 만드는 것은 비단 낮은 난이도의 문제 뿐만 아니라 높은 난이도에서도 공통적이었다.
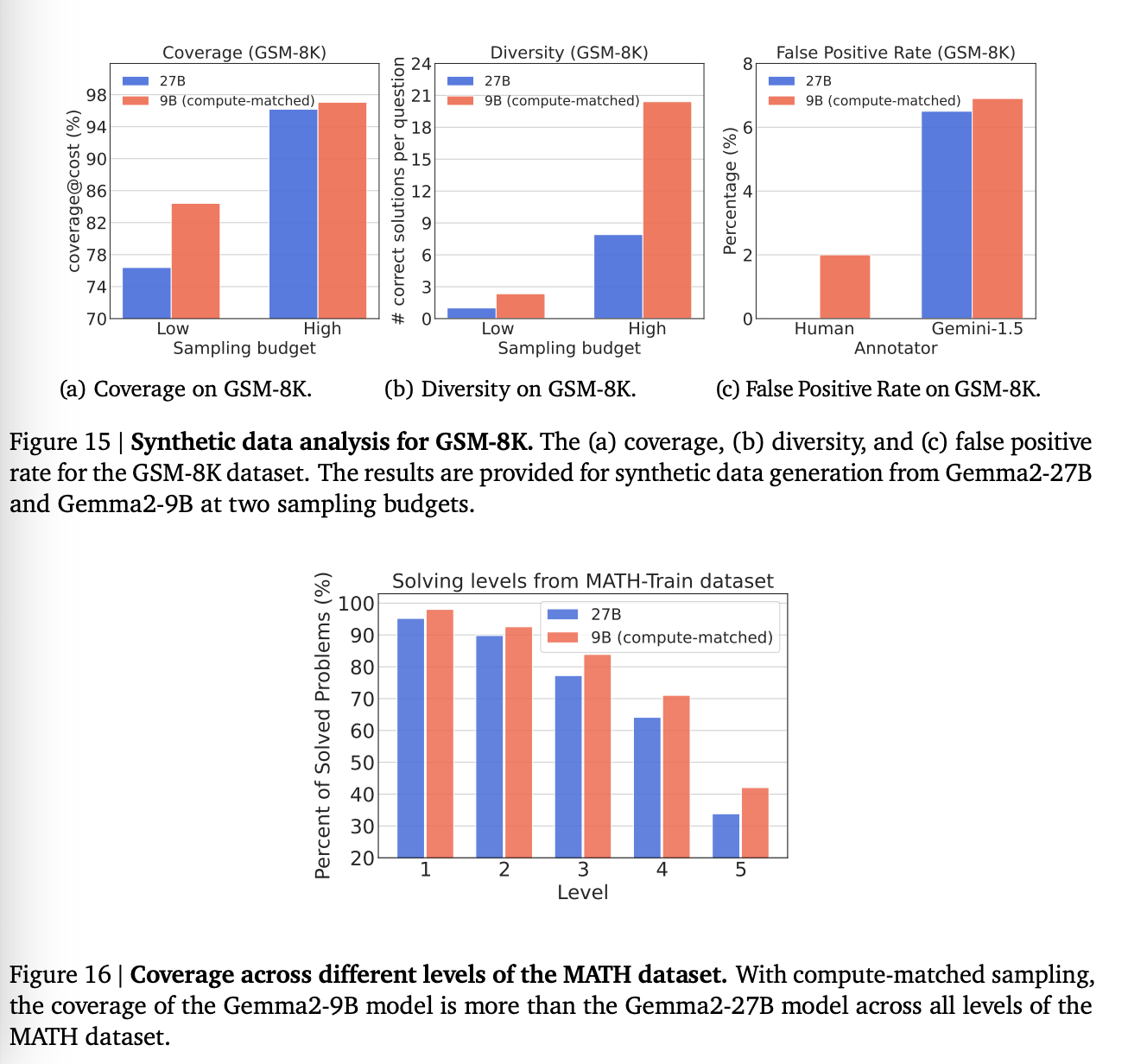
오히려 반대로, 더 큰 모델로 10개 만들 때는 풀지 못했던 어려운 문제도 더 약한 모델로 30번 만드는 경우에 자주 풀렸다고.

2) Diversity
Gemma2-9B에서 생성된 데이터의 다양성은 Gemma2-27B보다 MATH 데이터셋의 저예산에서 86%, 고예산에서 125% 더 높았으며, GSM-8K 데이터셋에서는 각각 134%와 158% 더 높음.
3) FPR
human 평가에 따르면 WC 모델이 생성한 해결책의 FPR이 MATH에서는 SE 모델보다 7% 높았고, GSM-8K에서는 2% 높았음. -> 생각보다 차이는 안나지만, 그럼에도 불구하고 좋지는 않음.
2. Compute-Optimality Results for Training
그렇다면 이들은 다양하게 학습해봤을 때는 어떨까.
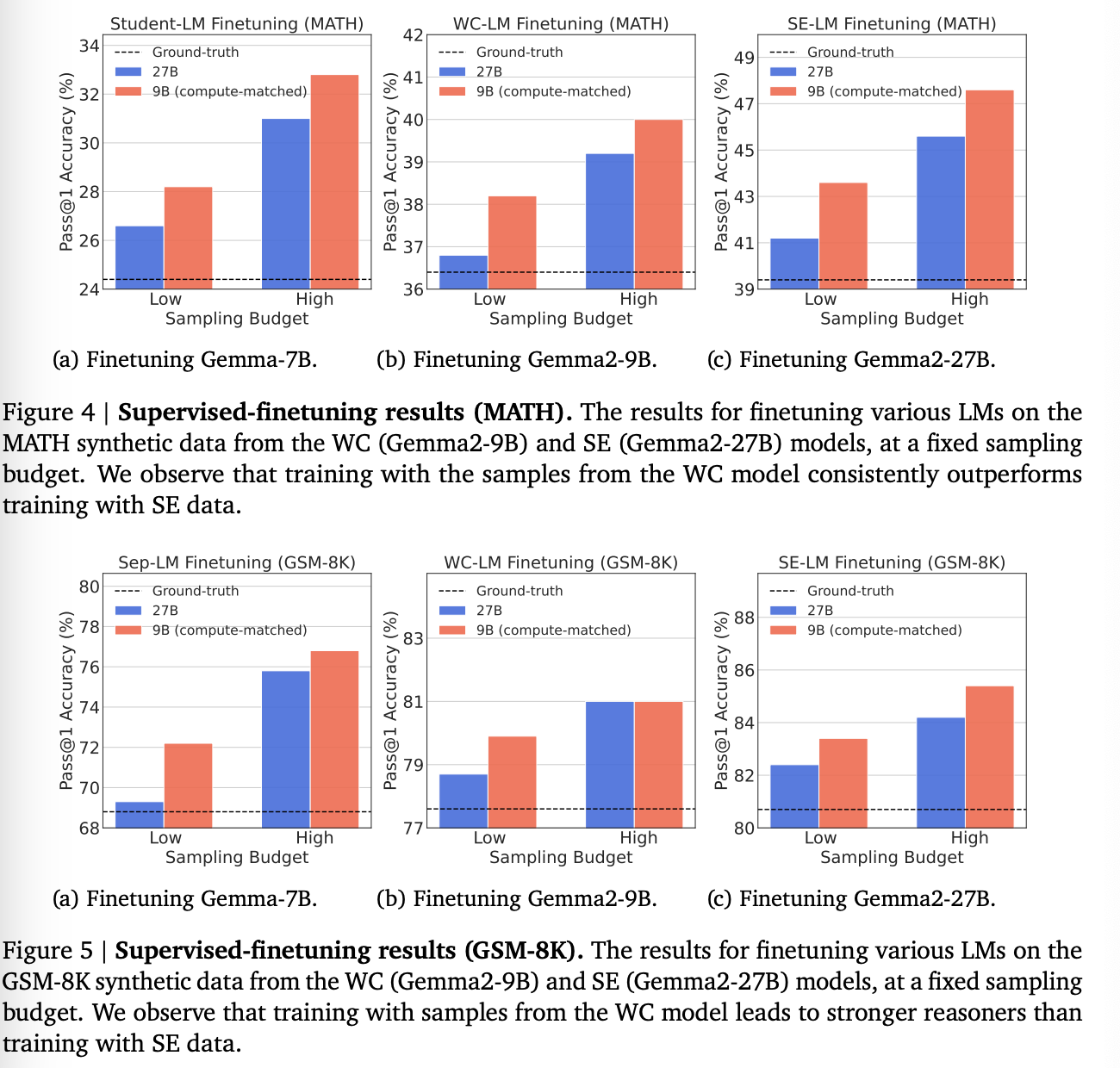
-
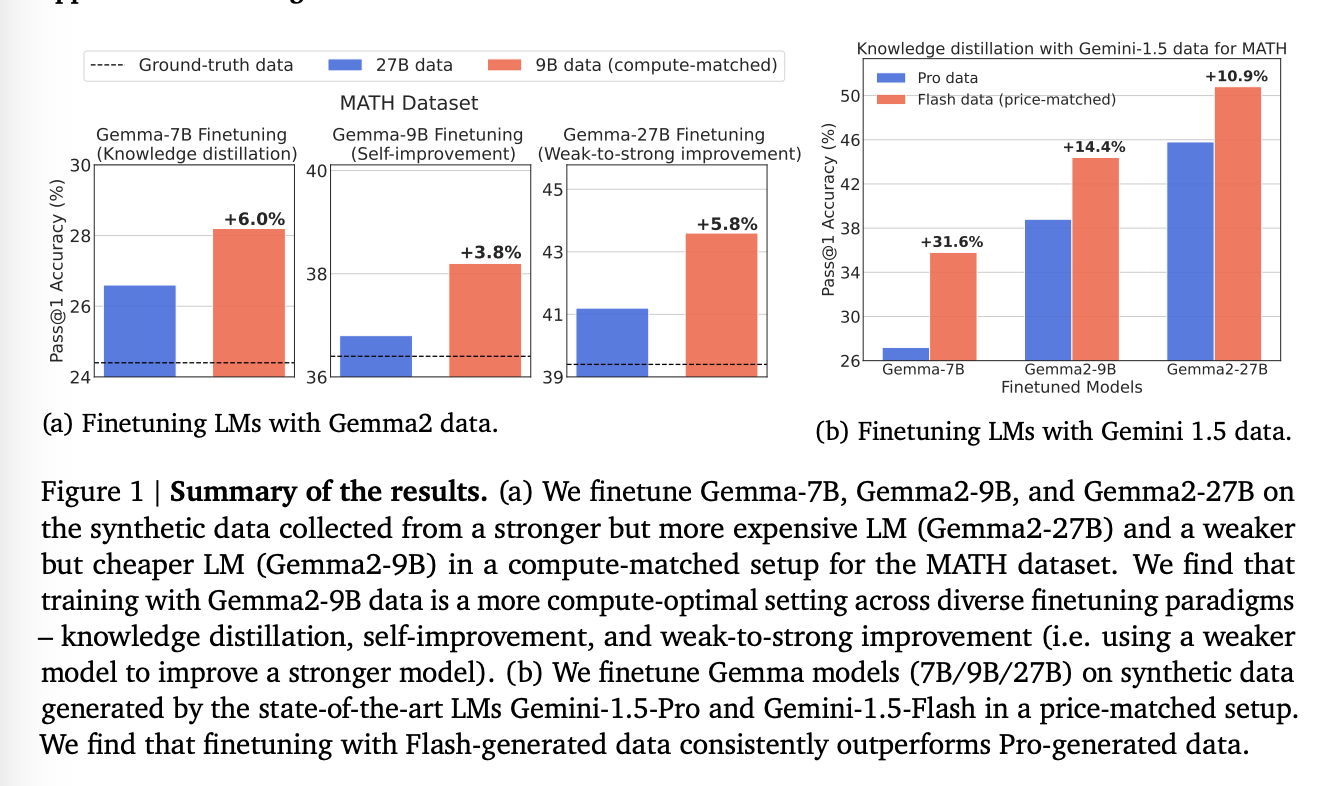
Student-LM Finetuning Gemma-7B를 WC와 SC로 학습한 결과. WC consistently outperforms the one finetuned on data from SC. 일반적인 믿음과 다르다.
-
WC-LM Finetuning Gemma2-9B를 Gemma2-9B가 만든 WC와 27B가 만든 SC로 학습한 결과. 대부분 WC가 더 나았지만, 그렇지 않은 경우도 존재. 저자들은 이것이 데이터가 너무 쉬워서라고 주장.
-
SE-LM finetuning Gemma2-27B를 양 데이터로 학습. 더 작은 모델로 만든 데이터가 놀랍게도 더 도움이 되었다.
Takeaway: Overall, our findings challenge the conventional wisdom that advocates training on samples from the SE model, by showing that training on samples from the WC model may be more compute-optimal across various tasks and setups.
3. Ablation Studies
Impact of Dataset Size
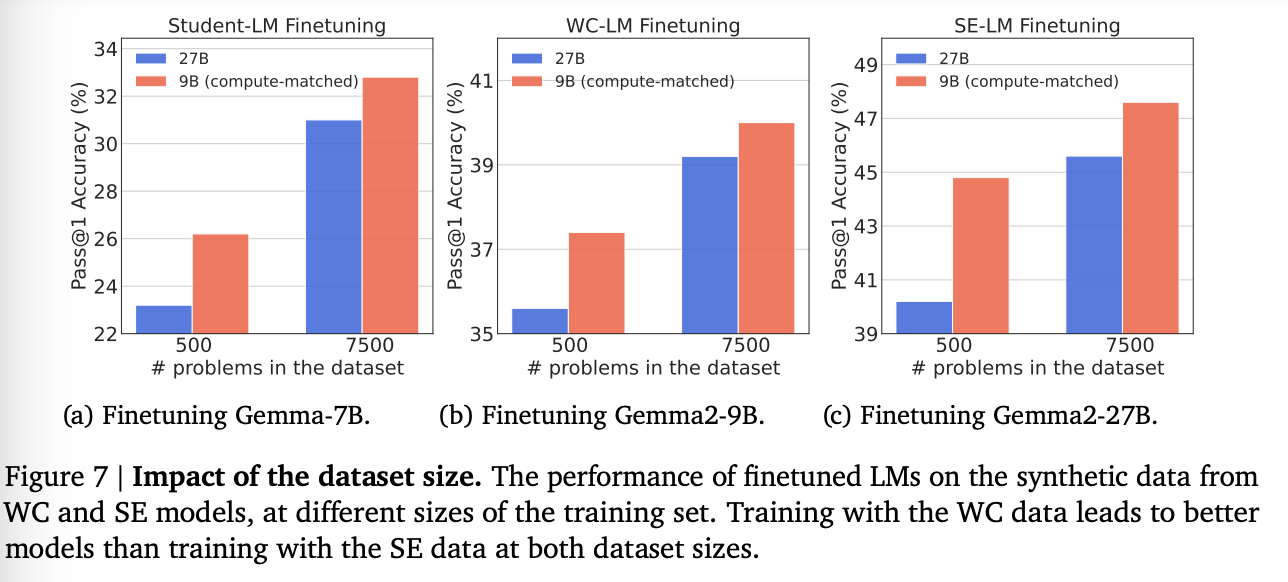
Default vs Compute-Optimal Sampling from Cheap LMs
그렇다면, 기존에 SE를 사용하던 일반적인 방법처럼 데이터 개수를 통일하면?
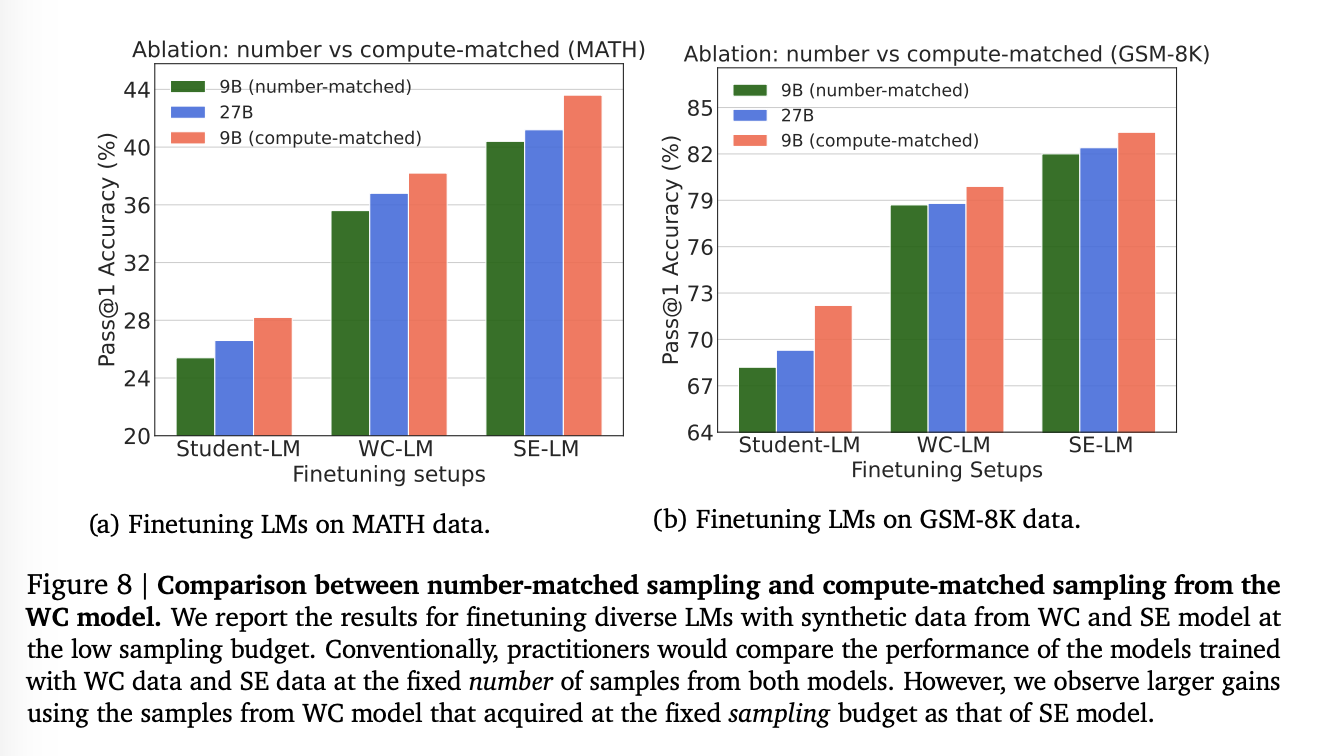
볼 수 있는 것처럼, 더 퀄리티 좋은 것을 사용하는게 더 좋은 것은 확실하다.
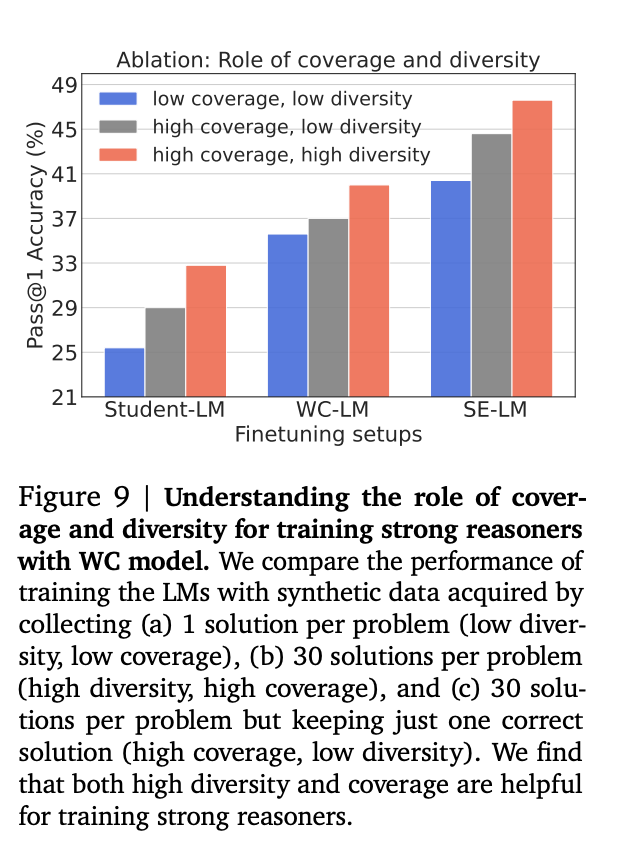
Coverage and Diversity:
데이터의 정답률과 다양성의 측면에서 얼마나 영향력이 큰가를 small scale로 실험한 결과물. 30개의 질문으로 구성.
-
high coverage, high diversity
-
high coverage, low diversity
-
하나의 질문 당 맞는거 하나만
-
reduces the diversity of the original WC dataset from 11 to 1, while maintaining the coverage.
- low coverage, low diversity
- one solution per problem from the WC model + 낮은 정답률 가지도록 일부러 필터
Scaling to state-of-the-art language models
위의 부분에서는 open LM들에 대해서 실험한 결과. 이 섹션에서는 Gemini-1.5-Pro and Gemini-1.5-Flash를 사용해본다.
모델 사이즈가 공식적으로 공개되지 않았기에, compute-matched sampling에는 pricing per output token을 Proxy로 사용한다고..
-
synthetic data from the Pro (SE) - $10.5
-
Flash (WC) models. - $0.3
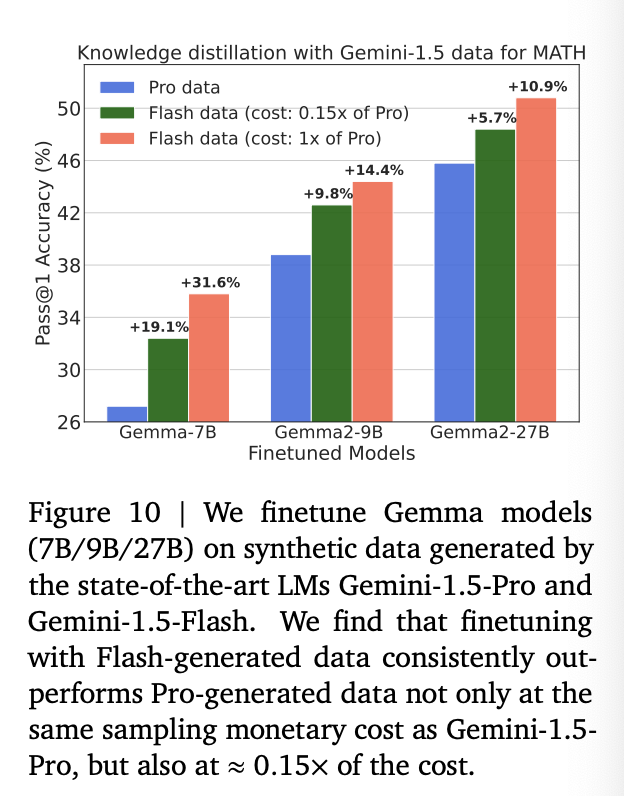
Takeaway: We demonstrate that price-matched sampling from weaker SoTA LMs produces superior reasoners compared to finetuning with data from stronger SoTA models.
Conclusion