Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
논문 정보
- Date: 2024-07-23
- Reviewer: 전민진
- Property: Reasoning, Reinforcement Learning
Abstract
- Reasoning에서 RL의 challenge는 정답을 내는 action의 sequence를 식별하기 어렵다는 것
⇒ 아래와 같은 문제가 주어졌을 때, LLM이 정확한 방향을 잡고 문제를 차근차근 풀기 어려움.
중간 과정 하나라도 삐끗할 경우 문제를 정확히 풀 수 없음.
Q. 팝콘+영화티켓 세트는 20불이고, 음료를 추가하면 1불이다. 하지만 영화티켓을 단일로 살 결우 12불, 단일 팝콘 가격은 3불이다. 단일로 구매하는 것이 세트 가격보다 2불 이득이기 위해선 음료가 몇 불이어야 하는가?
A. 20+1-2=12+3+x ⇒ x는 4
-
기존 방법인 output supervision(최종 답에 대해서만 reward 부여)은 sparse reward로 어느 시점에 error가 발생되는지 알 수 없음
-
반대로, step마다 reward를 부여하는 process supervision 방식의 경우 annotation비용이 너무 커진다는 단점 존재
본 논문에서는 정답 rationale을 reverse curriculum방식으로 학습하여 이와 같은 문제를 해결하고자 함
-
정답 rationale이 {step1, step2, …, step N}으로 구성되어 있을 때, 특정 시점의 step을 시작점으로 사용하는 방식
-
최종 답변과 가까운 시점이 시작점일 때 > 쉬운 데이터로 간주 / 최종 답변과 먼 시점이 시작점일 때 > 어려운 데이터로 간주
-
outcome supervision을 step-level signal느낌으로 사용할 수 있음
Introduction
-
기존에 LLM을 활용해 reasoning task를 풀 땐 rationale을 생성하도록 학습(step-by-step Chain-of-Thought manner)
-
하지만 SFT는 human demonstaration을 따라하도록 학습하게 되어 일반화를 하기 위해선 대량의, 다양한, 고품질의 annatation이 필요
-
RL의 경우 exploration과 learning을 통해 reasoning을 향상 시키는 현실적인 대안으로 소개되어 옴
- 하지만 task가 어려워질수록 reasoning chain과 complexity가 증가 » 누적 에러와 여러 중간 과정의 uncertainty에 난항을 겪고 있음
-
process supervision은 모든 reasoning step에 적절한 feedback을 제공하지만 annotation비용이 너무 큼
-
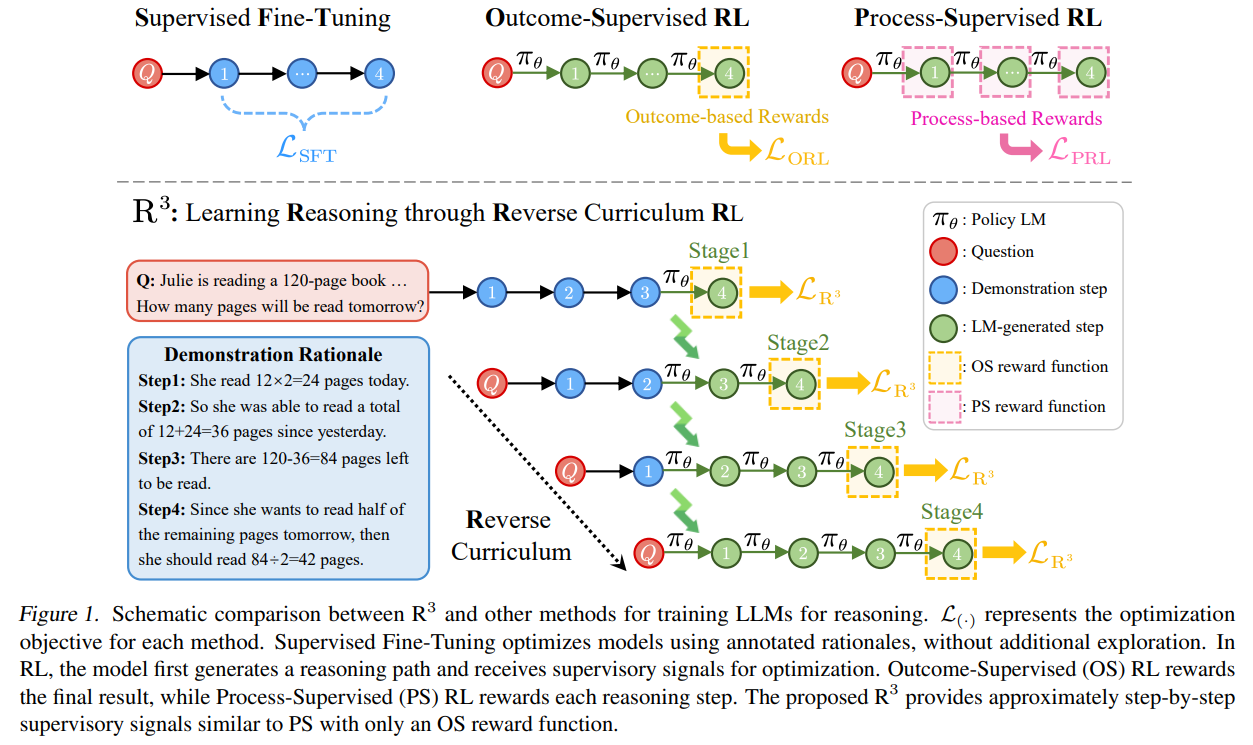
본 논문에서는 R^3: Learning Reasoning through Reverse Curriculum Reinforcement Learning을 제안
-
이 방법론에서는 correct demonstration에서 state를 sampling, 특정 state부터 action 생성, feedback을 제공
-
start state를 demonstration의 끝부분(정답 내기 직전)에서 처음 부분으로 천천히 이동, 모델이 각 point에서 쉬운 exploration을 경험하도록 함
- 이미 뒷부분은 풀도록 학습되었기 때문에 비교적 쉬워짐
-

-
이러한 방식으로, exploration difficulty를 점점 증가시키는 curriculum이 만들어지고, 이를 활용해 step-by-step supervisory signal을 근사적으로 이용할 수 있음
-
정답 풀이 과정 : A → B → C → D
-
C가 주어지고 D를 예측하는걸 먼저 학습, B가 주어졌을 때 C, D를 예측하는 것을 학습하는 방식
-
이 경우 C → D를 예측하면 reward 1, B → C → D를 예측하면 reward 1 이라서 일종의 step-by-step signal이라고 주장하는거 같음
- 글쎄..
-
-
또한, 원래는 N reasoning step이 있을 때 복잡도가 exponential하지만 해당 방법은 DP의 포맷으로 N에 linear한 시간에 학습 가능
-
학습 안정성을 위해 start state를 mix해서 사용
-
실험 결과, mathematical reasoning, logical reasoning, NLI 등에서 기존 SFT, RL보다 높은 성능 보임
Related works
-
RL basic
-
tau는 policy에서 sampling된 trajectory라는 걸 의미
-
각 시간 스텝 t에서 policy는 LM
-
state t는 prompt와 그 시점까지 생성된 text
-
action a_t는 t시점의 action으로 s_t를 바탕으로 다음에 올 토큰을 생성하는 것
-
이 확률은 \pi{\theta}(a{t+1} s_t)로 표기
-
-
여기서 R을 기존 정의와 동일, 각 state에서 얻은 reward를 discounted sum한 것
-
policy gradient
-
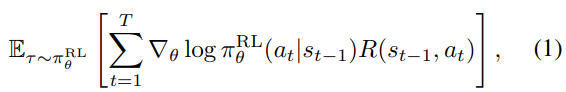
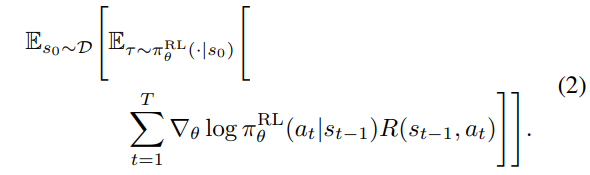
-
RL with outcome supervision
-
sampled sequence의 final result만을 보고 reward 부여하는 방식
-
나머지 토큰에 대한 reward는 0
-
rf는 reward function을 의미
-
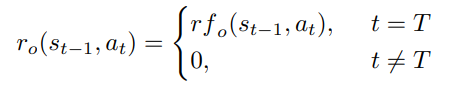
-
RL with process supervision
-
중간 지점마다 reward부여하는 방식
- 중간 지점은 부여하기 나름.
-
reward model rm_p는 각 중간 reasoning step에 대한 reward를 부여하도록 학습됨
-
그래서 학습하려면 fine-grained annotation이 필요
-
또한, reward model은 human preference가 반영되기 때문에, bias가 있을 수 있고 이는 objective correctness 혹은 usefulness와 완벽하게 align이 안될 수 있음
-
-
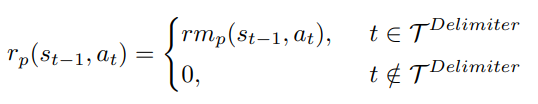
Proposed method
-
outcome과 process supervision의 이점을 합치는 방법론을 모색하다 찾음
-
fine-grained annotation이 필요하지 않으면서 golden outcome만 사용해 personal bias를 피할 수 있으면서 여전히 step-level supervision의 효과를 줄 수 있는.. 그런거..
-
본 논문에서는 오직 outcome-based reward function rrf_o (.)만 쓸 수 있다 가정
-
-
Start exploration from intermediate states of demonstration
-
multi-hop reasoning 문제에서 golden answer를 도출하는 여러 reasoning path가 있을 수 있음
-
본 논문에서는 한 개 이상의 demonstration에 접근할 수 있다 가정
-
모델이 초기 start state s_0에서 exploration을 시작하면 positive reawrd를 얻기 어려움
-

-
그래서 reasoning의 중간부터 exploration을 시작할 수 있게 함
-
\pi{\theta}(a{k+1:T} s_k) -
특정 중간 시점부터 끝까지 생성, 결과에 따라 reward 받음
- 시작 시점 전의 trajectory는 가이드 역할을 함(s_k에 시작 시점 전의 trajectory가 포함되어 있음)
-
-
Reverse curriculum learning for step-level supervision
-
target과 가까운 선택된 state에서부터 시작해서, 더 먼 state까지 순차적으로 학습
-
각 시점에서 모델들은 성공할 확률이 높은 쉬운 exploration problem을 풀게 됨
- 이미 그 다음 시점 exploration을 풀도록 학습되었기 때문
-
k는 T-1부터 시작해서 순차적으로 0을 이동
- 마지막 step은 original outcome-supervised RL과 동일
-
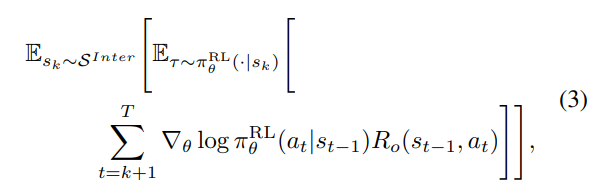
-
본 논문에선, demonstration에서 M개의 intermediate state를 샘플링, start state으로 사용
-
intermediate state는 line breaks 혹은 uniformly하게 추출
-
M은 5 혹은 6을 사용
-
-
이 방식을 vanilla staged RL이라 지칭
-
Mixing start states for generalization
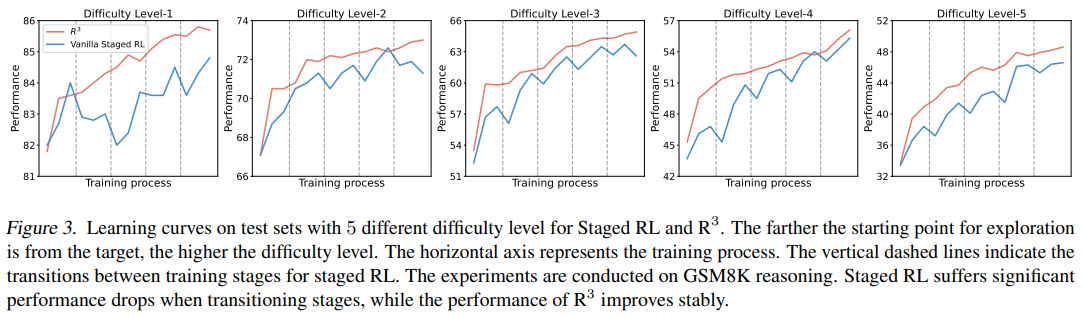
-
위의 그림을 보면 staged RL은 여러 문제가 있다는 것을 알 수 있음
-
모델이 초반의 쉬운 pattern에 오버피팅돼서, 후반에 일반화가 안될 수 있음
-
여기서 점선은 vanilla staged RL의 stage transition 시점을 의미
- 다시보니 괜찮은거 같기도..
-
-
또한 staged RL은 complex interaction, dependencies inherent를 포착하고 모델링하기 어려울 수 있음
- 걍 갖다 붙인 말인듯
-
그래서 본 논문에서는 multi-task learning방식으로 이러한 문제를 해결하고자 함
mixed strategy
-
Reward Design and Policy Optimization
-
본 논문에서는 PPO를 기본 policy gradient algorithm으로 사용
- RLHF에서도 효과적이었음
-
또한 mathematical reasoning task에서 partial reward를 도입
-
(답이 아니어도 숫자면 소량의 reward부여)

-
exploration difficulty에 기반으로 reward function을 설정
-
generalized advantage estimate(GAE)로 advantages를 계
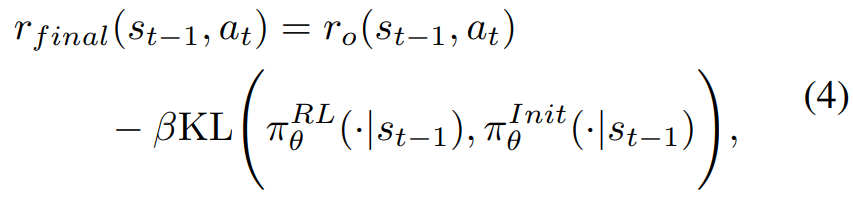
-
Algorithm
- 먼저 curriculum dataset를 구축하고 RL학습

Experiments
-
Experimental Setup
-
Datasets
-
mathematical reasoning : GSM8K, SVAMP
-
logical reasoning : BoardgameQA(main과 conflict subset선택)
-
reading comprehension : race@Middle, race@High
-
NLI : SNLI, MNLI / rationale로는 CoT-Collection
-
-
Model and baselines
-
CoT reasoning에선 Llama2-Base-7B를 backbone으로 사용
-
few-shot CoT, SFT, RL를 baseline으로 사용
-
P-CoT에선 Llama2-Base-7B와 Codellama-7B를 backbone으로 사용
-
few-shot CoT, SFT, RL을 baseline으로 사용
-
또한 최근에 제안된 data augmentation이 필요한 방법론들도 고려
- MAmmoTH-Coder, Tora, Tora-coder
-
-
Implementation details
-
A100-80GB GPU 8개 사용
-
few-shot CoT할 때는 seed 바꿔가며 5번 돌려서 다른 demonstration로 실행, 평균 성능을 기록
-
SFT에 대해선 2e-5, RL-related 방법들은 SFT로 warm-up하고 RL를 수행
-
\epsilon은 SVAMP에 대해서는 0.1, GSM8K에선 0.2로 세팅
-
CoT실험할 때, math reasoning에 대해선 \beta을 0.05로 다른 task에서는 0.3으로 설정 ; P-CoT에선 0.01
-
mathmatical task에서는 50, 다른 task에서는 5 epoch으로 RL학습
-
-
-
Results on CoT reasoning
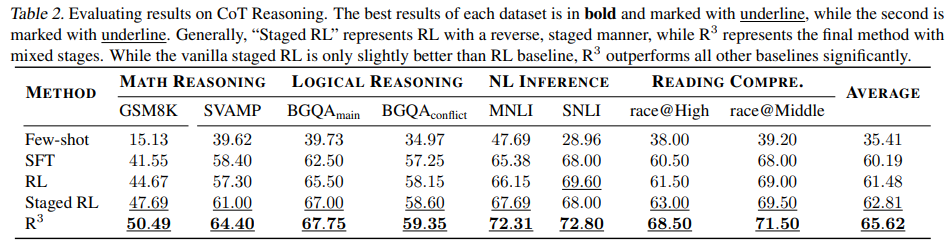
-
R^3이 타 방법론에 비해 월등한 성능을 보임
-
Staged RL도 높은 성능을 보이는 것으로 보아 어려운 단계별로 학습하는거 자체가 중요한거 같음(민진피셜)
-
Results on P-CoT reasoning
- 기존의 data augmentation방법론과 결합해도 높은 성능을 보임
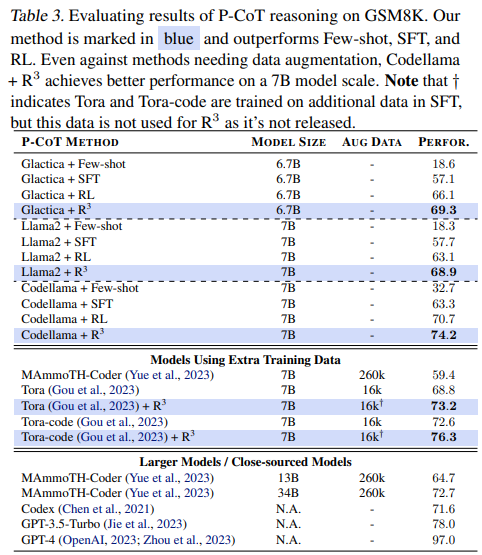
-
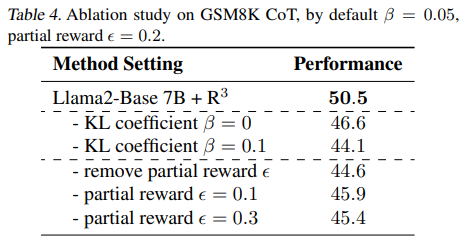
Ablation study
- KL coefficient beta, partial reward epsilon
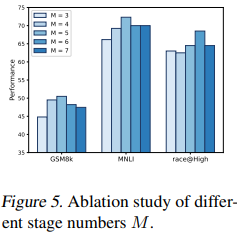
- Number of intermediate states selected M
- R^3 Delivers stable reinforcement learning
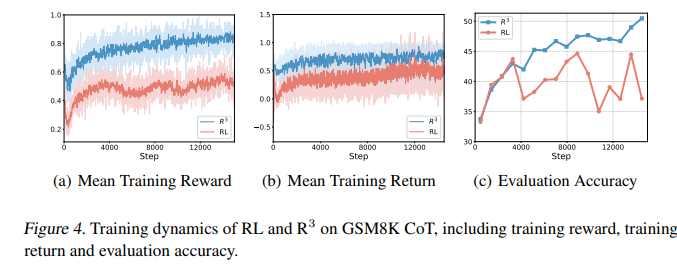
-
Analysis of training data construction
- 데이터에서 가장 중요한 건 어려운 데이터(처음부터 reasoning step 생성하는 것)
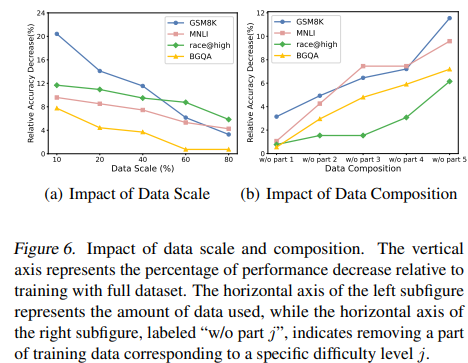
Conclusion
-
reverse curriculum RL방식으로 LLM의 reasoning ability를 향상시키는 방법론 제안
-
문제를 구체화하는거 까지는 멋졌는데… 방법론이 생각보다 막 좋은지는 모르겠다..
(다시 보니 괜찮은거 같기두..)
-
online인듯.. offline인듯한 이 방법론..
-
진짜 궁금한 지점(mixed strategy에서 어떤 방식으로 학습 데이터셋을 구성하는지)에 대한 설명과 실험이 부족