Understanding Emergent Abilities of Language Models from the Loss Perspective
논문 정보
- Date: 2024-04-16
- Reviewer: 준원 장
- Property: Pre-training
1. Introduction
-
Emergent Abilities
- 작은 Model에서는 못하지만 큰 Model에서는 발현되는 LM의 능력들 (e.g., few-shot, KG-intensive task, ..)
-
Emergent Abilities의 실체에 대한 의문이 제기되는 이유
-
많은 Token을 본 LLaMA-13B가 GPT-175B보다 MMLU 성능이 더 좋다
-
Downstream Task를 측정하는 nonlinear or discontinuous metrics 때문에 Emergent abilities가 있는것처럼 보여지는 것이다.
-
Chinchilla가 제한된 Training Compute내에서 Model Size와 Training Tokens를 변경해가면서 조합별로 pre-training loss가 매번 다르게 수렴하는 것을 실험적으로 밝혀냈지만, 이 pre-training loss와 downtream task간의 관계를 규명하고자 하는 연구는 많이 진행되지 않았음
-
이를 위해서 본 연구에서는 30개의 크기가 다른 LM들을 ‘pt data corpus’, ‘tokenization’, ‘model architecture’ 을 고정시킨채 from the scratch로 학습하면서, loss 변화에 따라서 12개의 다른 downstream performance를 측정한다.
⇒ LM 크기나, pt data corpus에 상관없이 pre-training loss가 downstream tasks의 성능을 보여줄 수 있는 지표로써 역할을 함을 증명함.
Emergent Abilities를 재정의: Pre-training Loss가 일정 Threshold이하로 떨어지면 발현됨
기존 Emergent Abilities가 model size or training compute로 정의 → model size or training compute는 Pre-training Loss와 연결점을 만들 수 있음 (Chinchilla Law) → 따라서 기존 연구들의 방향성과 대치되는 주장도 아니라고 방어적인 표현도 보임
2 The Pre-training Loss Predicts Task Performance?
-
Pre-training LMs
-
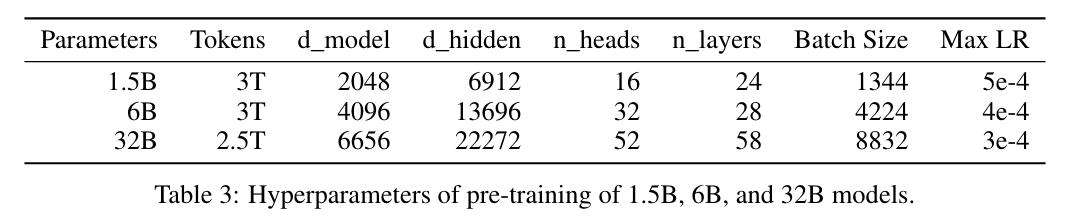
different model sizes (300M, 540M, 1B, 1.5B, 3B, 6B, and 32B)을 fixed data corpus, tokenization, architecture setting에서 from the scratch부터 pre-training
-
English Corpus: Chines Corpus = 4:1
-
- Default Training Setting
-
Small Scale Models
- 각 열에 보이는 number of tokens과 Max LR에 대응되는 학습 step까지 학습한 models
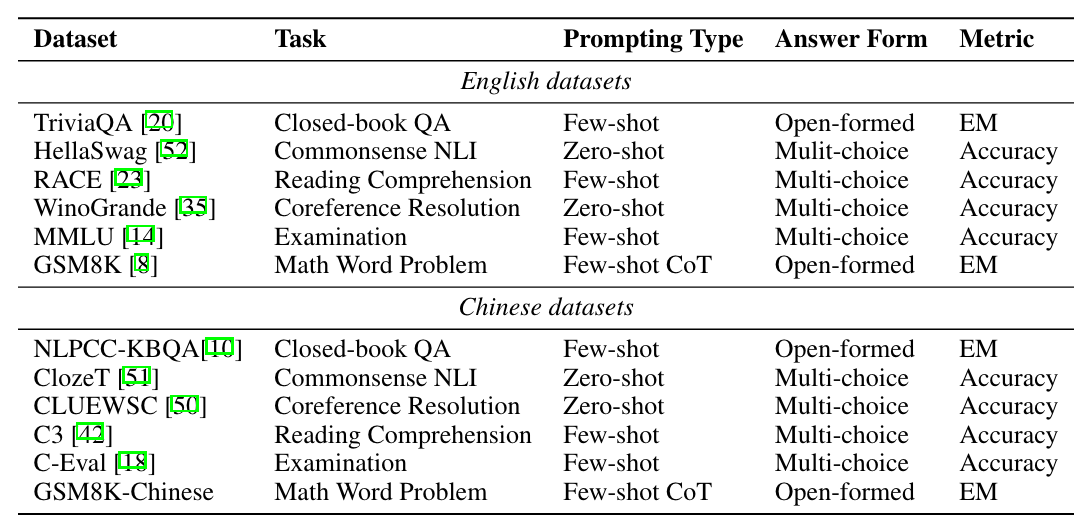
- Downstream Tasks
→ EM은 single token match 환경만 상정
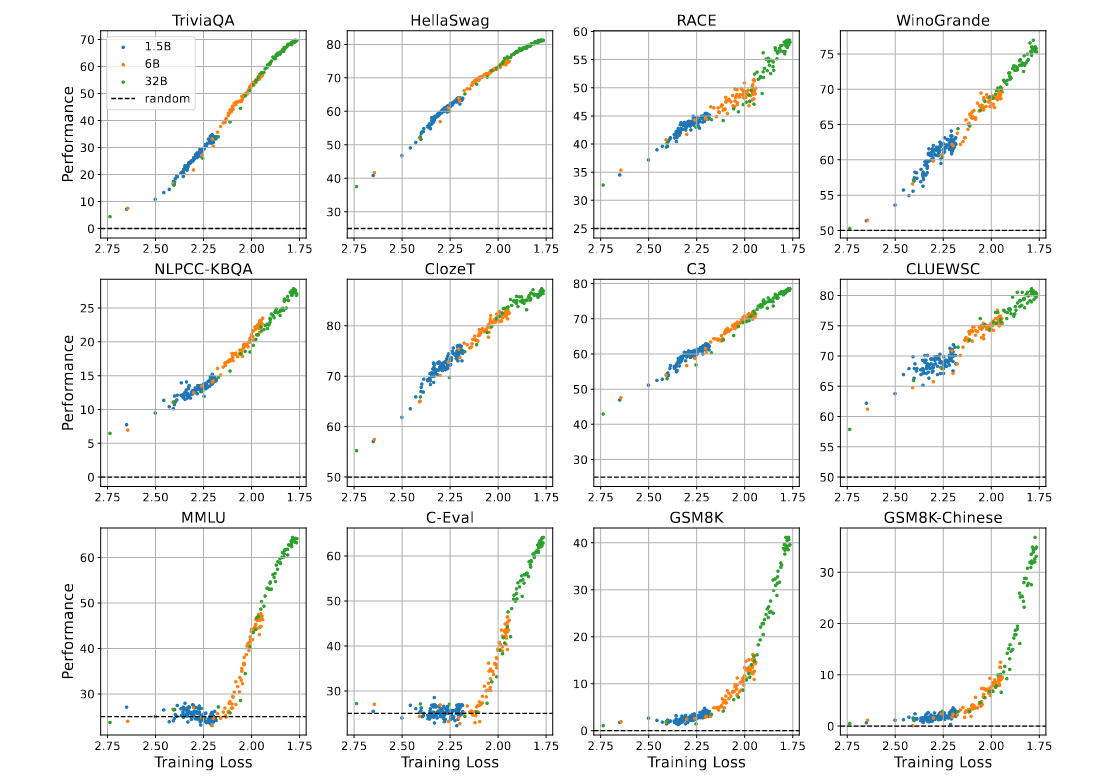
→ 매 43B PT token마다 plotting
→ Model Size와 관련 없이 PT Loss가 수렴할수록 DT Task 성능이 향상되며, MMLU, C-Eval, GSM8K, GSM8K-Chinese의 경우 model 크기와 상관없이 loss 2.2까지 전부 랜덤 성능을 보임 (→ KG가 parameterized 되어야 = (loss 수렴으로 논문에서는 설명) 성능 향상이 나타나기 시작함)
→ Model 크기에 따라서 절대적인 성능 차이는 분명히 존재하나, pre-training loss와 downstream task 사이의 correlation은 model 크기와는 무관하게 경향성으로 보이고 있음
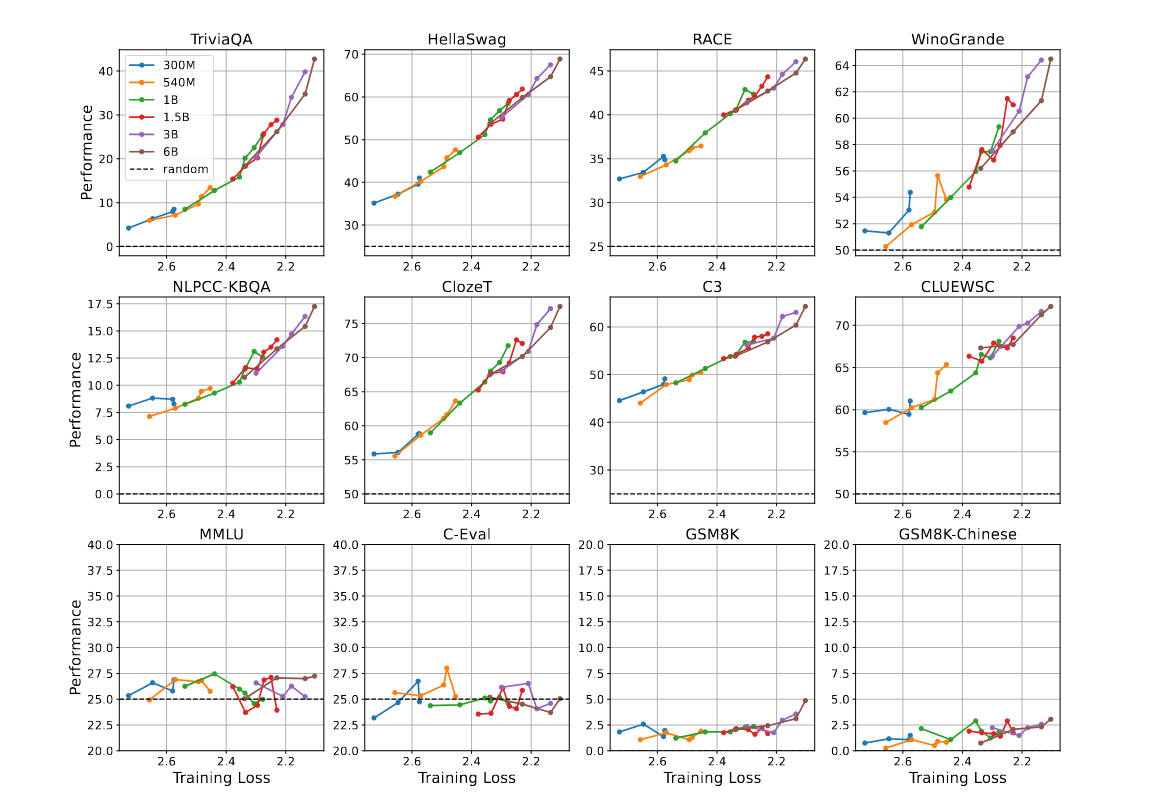
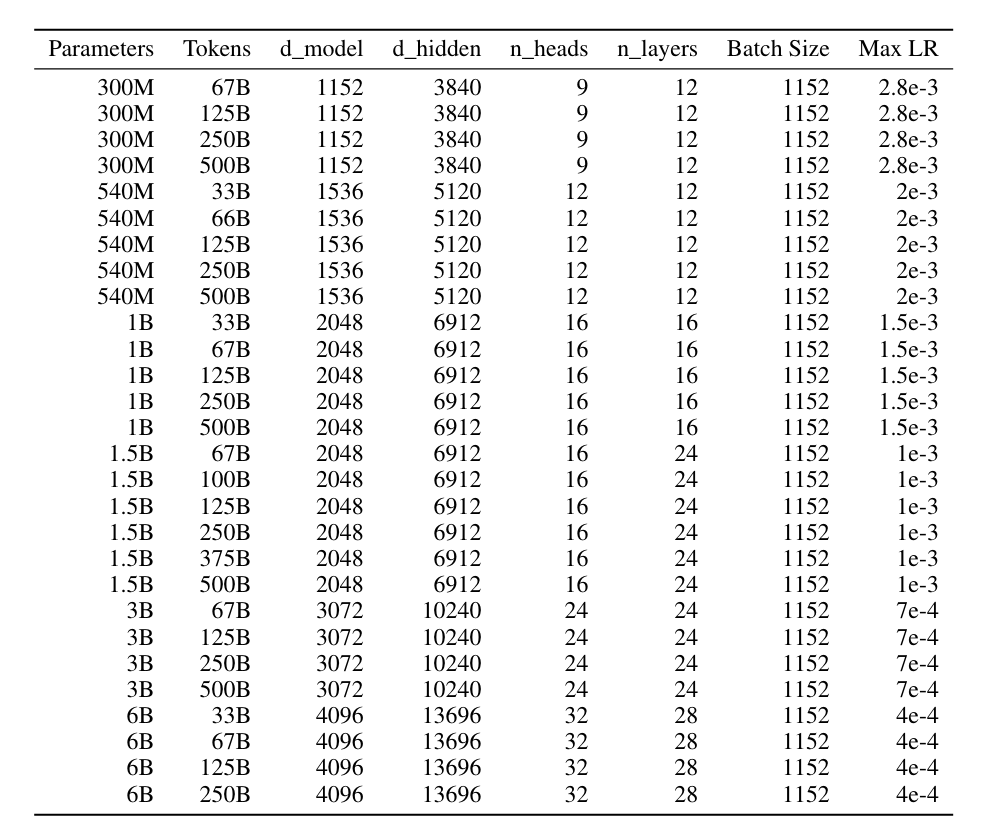
→ scaling laws에 따라 조금 더 작은 scale의 model(300M, 540M, 1B, 1.5B, 3B, 6B)을 더 적은 pre-training corpus를 가지고 실험.
→ 각 model을 상기표에 표기된 configuration까지 pre-training을 완료한 다음 last checkpoint의 pre-training loss & downstream performance를 plotting 함
- 학습 중간과정에서 저장한 checkpoint plotting한 performance는 아래와 같음 (same trend, but larger variance)
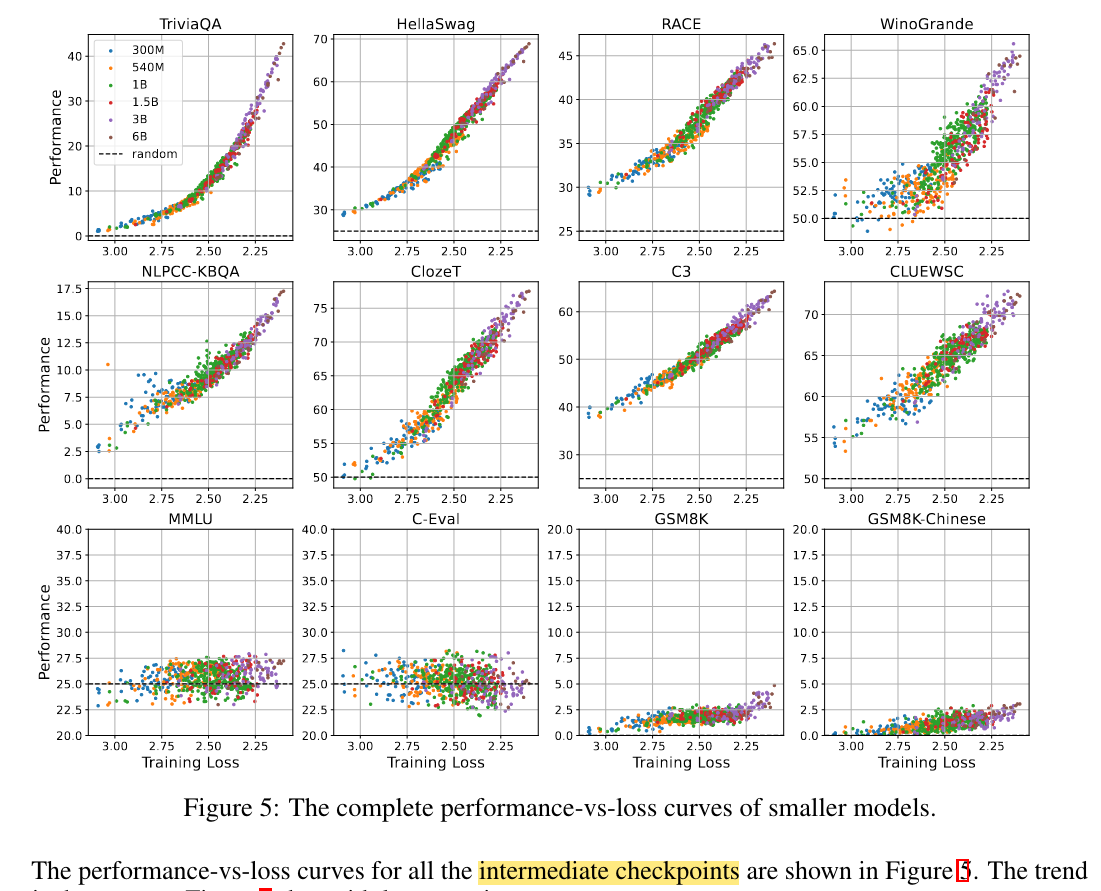
→ Model 크기, 학습 Token수가 다르더라도 pre-training loss가 유사한 구간에 있으면 downstream task도 유사한 performance를 보임
→ MMLU, C-Eval, GSM8K, GSM8K-Chinese의 경우 ~500B로는 loss를 수렴시키기 불충분하지 않았을까라는 나의 추측
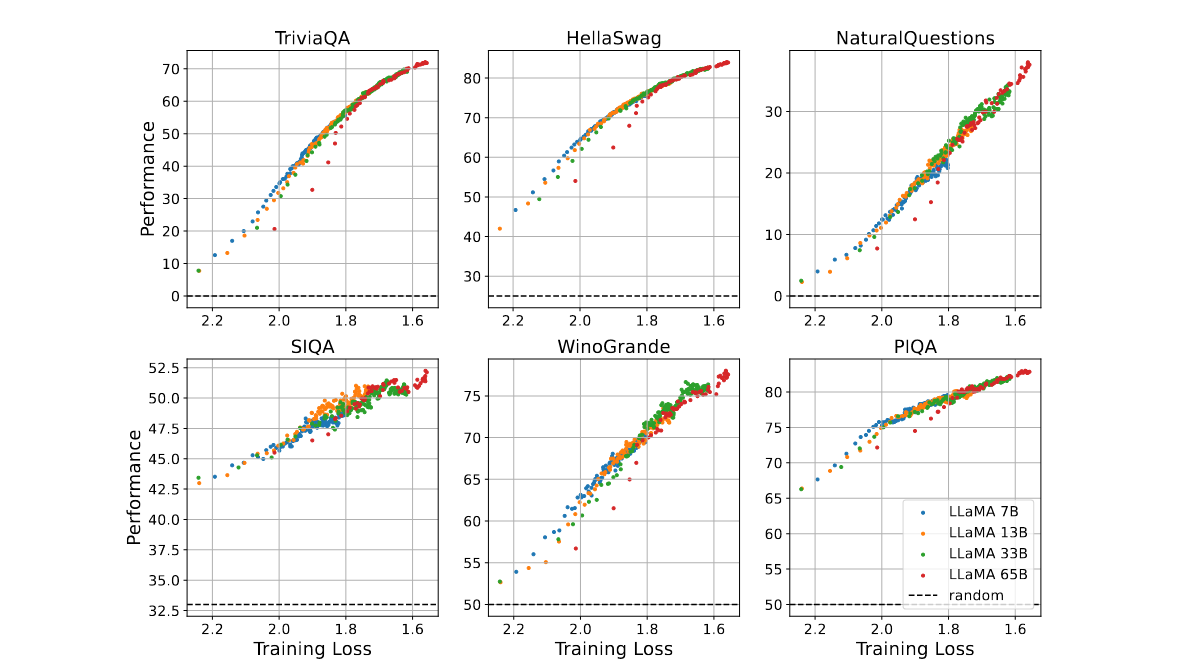
→ LLAMA1 original paper에서 Token Step별 Training Loss와 6개 Downstream Task Performance 결과를 재구성해 가져와보면 동일한 경향성을 보였음을 알 수 있음
→ LLaMA-65B가 loss 1.8보다 큰 구간에서 이상치가 나오는데 intermediate checkpoint 직접 분석할 수가 어쩔 수 없다라고 함..
⇒ 모델학습 전반에 걸쳐서 나오는 경향성인듯
3. Analysis of Different Tasks and Metrics
#### 3.1 Performance Trends of Different Tasks
-
2개의 GROUP으로 나누어서 분석을 시작함
-
G1: TriviaQA, HellaSwag, RACE, WinoGrande, NLPCC-KBQA, ClozeT, CLUEWSC, C3
-
G2: MMLU, C-Eval, GSM8K, GSM8K-Chinese
-
-
G1는 pre-training loss랑 performance score랑 linear한 관계를 보이나, G2는 어느순간 (e.g., 2.2) performance score가 random이상의 성능을 보이기 시작, 저자들은 이에 대한 분석을 제시
-
당연하게도, G2가 G1보다 task difficulty가 높다
-
G1(Hellaswag.RACE)은 commonsense, 단순 qa수준의 문제. 반면 GSM8K는 tuning안한 PLM이 Chain-of-Thought prompting안하고 풀기 어렵다고 알려져있음.
-
Model이 Training dataset에 Overfitting된 한참 후에 전체 data distribution에 generalization 되는 Grokking현상
-
Pre-training corpus는 mixture of corpus이기 때문에 model이 어떤 corpus(e.g., code)는 fitting되더라도 다른 corpus에는 underfitting되어 있는게 당연하기 때문
-
기존 Emergent Abilities 정의와의 연관성
-
pre-training loss가 줄어들면서 G2 performance가 향상하는 지점과 model size가 scaling하는 지점이 유사
-
training tokens이 고정되었다면, pre-training loss는 model 크기의 power law를 따라 감소하는 경향이 있음
#### 3.2. Influence of Different Metrics
-
Emergent abilities는 ‘researchers가 nonlinear or discontinuous metrics를 사용했기 때문에 나오는 후천적인 현상이다’라는 논문의 주장이 본인들의 현상에도 들어맞는지 확인하기 위해 continuous한 metric으로 변경해서 ablation 진행
-
ACC
-
CorrectChoiceProb
-
BrierScore
-
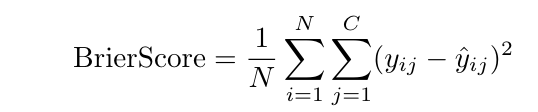
(where ˆ yij is the predicted probability of sample i for class j and yij is the ground probability)
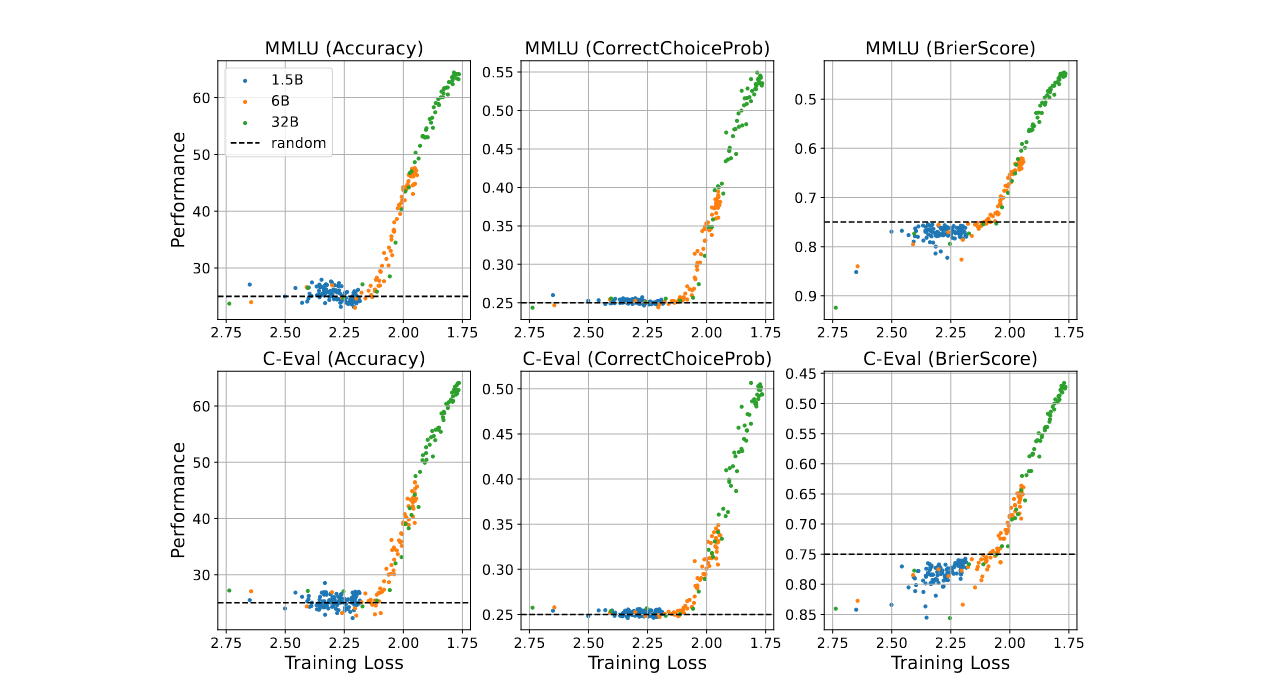
→ BrierScore 역시 random guess (0.25^2*3+0.75^2=0.75) 이상 성능을 보이려면 pre-training loss가 일정 성능 이하로 떨어져야 한다.
→ 더 크게 보면, pre-training loss가 감소할수록 BrierScore 감소하는 경향을 보이긴 하나 BrierScore의 감소가 task performance의 성능 향상과 직결되는 지표는 아니기 때문에 참고로만 보라고 저자들은 당부함
→ LM의 emergent abilities는 tippling pt loss가 지나야 발현됨
4. Defining Emergent Abilities from the Loss Perspective
-
위의 실험들로부터
-
pre-training loss는 downstream task의 성능을 예측하는 지표가 될 수 있으며
-
일부 downstream task는 model 크기, 학습 token 수 (이건 살짝 무리수), metric의 continuous 유무와 관계 없이 pre-training loss가 특정 임계값 아래로 randombess 수준에서 성능이 향상된다는 것을 입증
-
Emergent Abilities의 재정의
Definition. An ability is emergent if it is not present in models with higher pre-training loss but is present in models with lower pre-training loss.
- emergent ability를 normalized performance로 재정의 할 수 있다.
→ L은 PT Loss, f (L) 단조 감소함수, 에타는 threshold
- [Scaling laws for autoregressive generative modeling]라는 논문에 따라 Training Token D가 고정일때, Model Size N이 고정일 때 L를 아래처럼 정의할 수 있음
→ Loss는 N(model size)에 대해서 power-law + constant(irreducible)한 형태의 방정식을 가짐
- 위의 식 2개를 결합하면,
→ 언어모델의 파리미터 사이즈가 N0 \cdot \left(\eta - L{\infty}\right)^{-\frac{1}{\alpha_N}} 이상이면 pre-treiaining loss가 감소하고, 이는 downsetream task에서의 normalized performance 증가로 이어진다.
5. Related Work
#### Relationship of Pre-training Loss and Task Performance.
-
같은 pre-training loss를 가진 LMs이라도 model sizes, model architectures, and training algorithms에 따라 inductive bias가 사용되고 transfer learning 이후에 확연히 다른 downstream task 성능을 보인다고 알려져 있다.
-
Training trajectories of language models across scales [ACL 2023]에 따르면, perplexity가 ICL 성능을 예측하기 위한 좋은 지표라고 주장했지만, OPT Model만을 가지고 실험했다는 한계가 명확하게 존재
-
Naver에서 발표한 On the effect of pretraining corpora on in-context learning by a large-scale language model [NAACL 2022]은 pre-training corpus를 변경하면서 실험한 결과, low-perplexity가 항상 높은 ICL 성능을 보장해주지는 않음을 보임.
#### Emergent Abilities.
-
Llama1의 필두로 크기가 작은 모델에 엄청난 Token수로 모델을 학습시키면 undertrained된 Larger LLMs을 뛰어넘을 수 있다는게 밝혀지면서 기존의 **Emergent Abilities **정의가 도전에 직면 받고 있다.
-
뿐만아니라, NIPS splotlight paper에 따라서 Emergent Abilities가 metric에 의해서 발생되는 현상이 아니냐?라는 지적이 최근에 많은 연구를 통해 지속적으로 제기되고 있다.
⇒ 본 연구에서는 Emergent Abilities를 pre-training loss 관점에서 해석하고자 함.
6. Conclusion
-
model size나 training compute보다 pre-training loss가 downstream task에서 LMs의 scaling effect를 확인하기 더 좋은 지표임을 실험적으로 제시
-
pre-training corpus recipes (e.g., domain)에 따른 분석이 없는것은 아쉽지만, 이 부분까지 실험하기에는 매우 비용이 많이 들것으로 사료됨
-
(정리자 생각) 32B에서 loss가 2.1 → 1.8~1.7으로 떨어져야 MMLU, GSM8K성능이 향상되는 것을 보면, 다른 데이터셋과는 다르게 (1) model size가 충분히 큰 모델이 (2) 관련된 KG를 충분히 parameterized 시켜야 (loss 수렴[다른 데이터셋에 비해서 loss 절대치가 낮음]) 성능이 나온다는게 실험적으로 보인 건데, 해당 논문에서 보여진 장표는 domain 별로 확장해서 생각해볼 여지가 많은 실험 결과로 보임