Understanding the performance gap between online and offline alignment algorithms
논문 정보
- Date: 2024-05-27
- Reviewer: 전민진
- Property: RLHF
Abstract
-
RLHF은 요즘 LLM alignment를 위한 근본 방법론으로 자리 잡음
- 이에 따라, PPO, DPO, TRPO, self-judge등 엄청나게 많은 variation 방법론이 쏟아지고 있음
-
RLHF를 크게 online, offline alignmnt algorithm으로 나눠서, 둘의 성능 차이가 어떠한 원인에서 발생하는지 분석해보고자 함
Preliminary
-
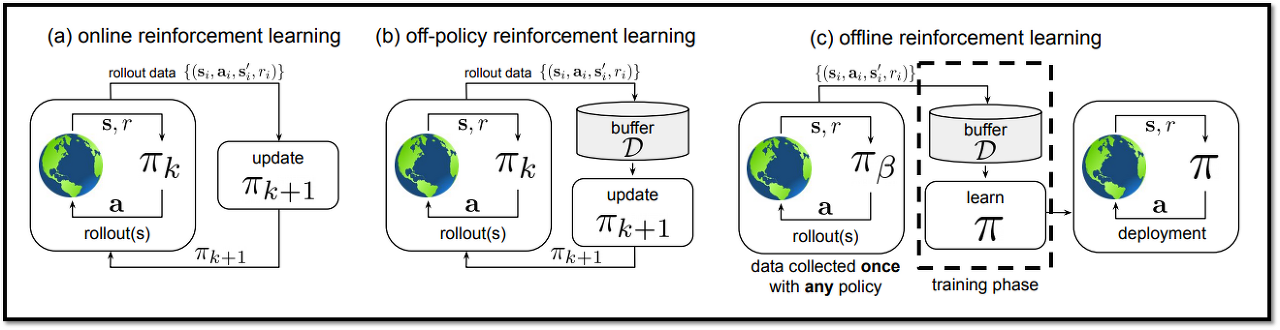
on-policy, off-policy, online, offline
-
on-policy
- behavior policy(데이터 샘플링할 때 사용한 policy) == target policy(학습할 policy)
-
ex) 직접 롤을 하면서 잘하는 방법을 터득함 ⇒ on-policy
ex) REINFORCE algorithm, PPO
-
off-policy
-
behavior policy(데이터 샘플링할 때 사용한 policy) != target policy(학습할 policy)
-
과거의 자기 모델(파라미터 업데이트하기 전)이 생성한 데이터여도 off-policy
-
ex) 유튜브에서 페이커가 롤하는 영상을 보고 잘하는 방법을 터득함 ⇒ off-policy
ex) Q-learning
-
online
-
agent가 직접 환경과 상호작용
-
policy를 업데이트할 때 지속적으로 환경과 상호작용하면서 샘플을 수집하는 상황을 가정
-
offline과의 가장 큰 차이가 policy optimization하는 동안 데이터를 샘플링하는가
-
online+on-policy(PPO, figure-a), online+off-policy(figure-b)알고리즘 모두 존재
-
-
offline(figure-c)
-
agent가 직접 환경과 상호작용하지 않음
-
환경과 상호작용 없이 고정된 데이터로만 학습하는 경우
-
즉, policy optimization을 수행하는 동안 추가적인 샘플링 과정이나 데이터 수집 과정이 없음 ⇒ 주어진 데이터만으로 학습
-
ex) DPO

Introduction
Is online RL necessary for AI alignment?
-
offline RL(DPO)같은 방법론의 경우 online RLHF에 비해서 훨씬 간단하고 연산량도 적음
-
과연 offline RL로도 충분히 alingment가 가능한지를 분석
-
online vs offline algorithms
-
online이 연산량이 훨신 큼
- due to sampling and training an extra reward model
-
budget(KLD with SFT model)을 기준으로 각 방법론이 어느 정도의 성능을 내는지를 비교
-
일반적인 RL setting에서는 당연히 online이 우세하나, RLHF에서 reward에 bottle neck이 발생하는걸 고려하면 애매
- LLM을RL로 학습할 때는 reward modeling을 human preference data로 한 후에, policy만을 업데이트
-
⇒ policy가 업데이트 되면서 분포가 reward model과 상이해질 수 있음
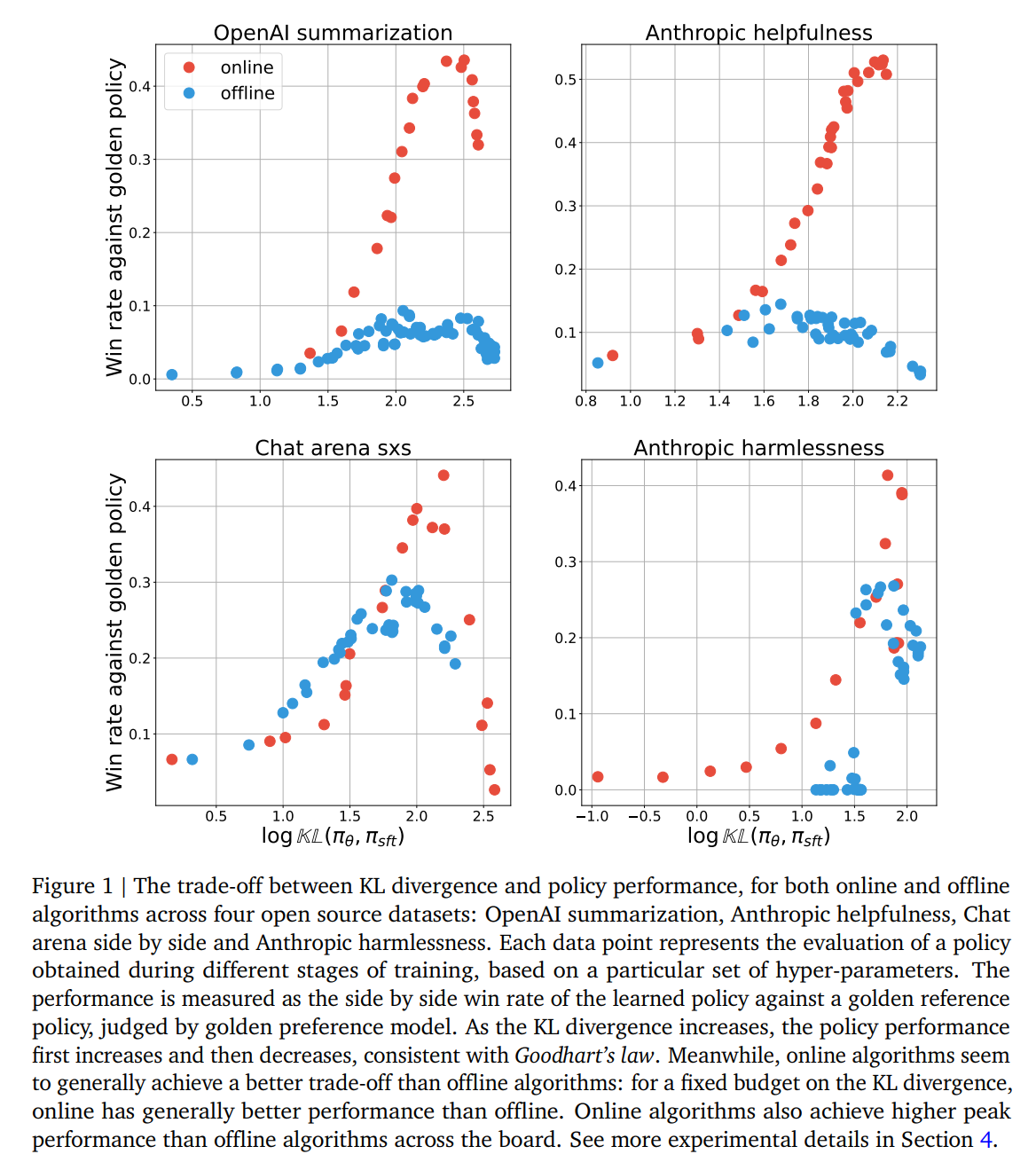
Comparing online and offline performance under Goodhart’s law
-
우선 online과 offline alignment method가 성능 차이가 나는지를 확인
-
면밀한 비교를 위해 둘다 IPO loss 사용, 차이는 \mu = \pi_\theta(online), \mu = D(offline)

- Online achieves better budget and performance trade-off than offline
- 실험 세팅
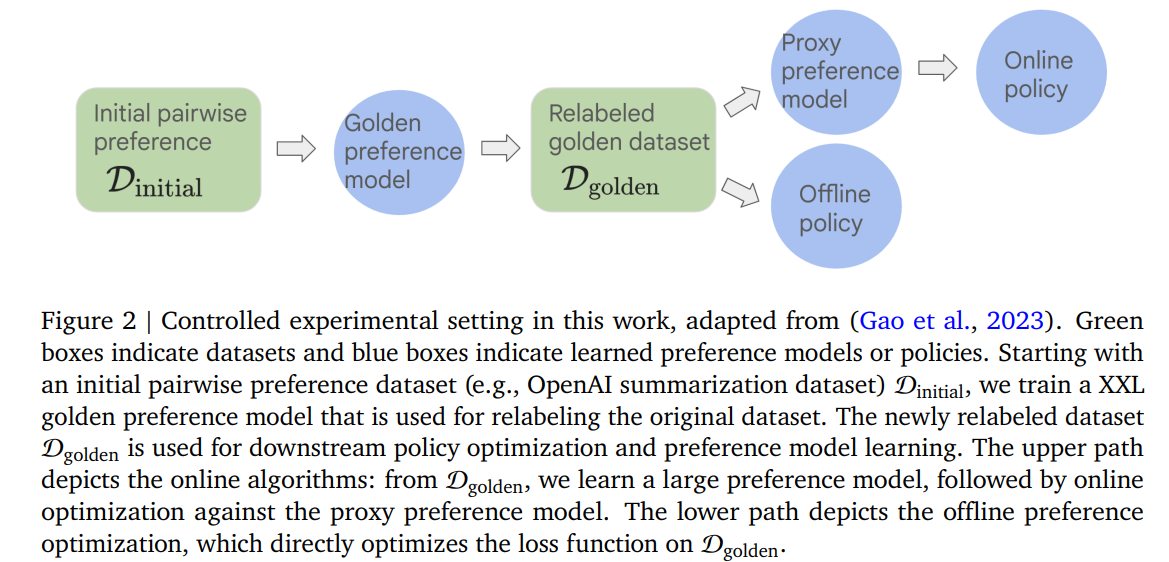
- golden policy : 기존의 human preference데이터로 golden preference model(reward model)을 학습, 이를 바탕으로 policy를 학습한 모델(T5X-XXL, 11B 사용)
- 다른 모델은 모두 golden preference model로 학습데이터를 다시 라벨링한 데이터셋 D_{golden}으로 학습(T5X-Large, 770M)
- D_{golden}은 기존 데이터셋에 비해 다소 너프된, 노이즈가 있는 데이터셋이라고 보면 됨
- 각각의 점은 학습된 policy 성능을 의미(미리 정해놓은 hyper-parameter + 학습 정도)
-
실험 결과, online algorithm이 offline에 비해서 더 높은 trade-off performance를 보임
-
online, offline 모두 overoptimization 현상이 발생하는 것을 알 수 있음
- 두 가지 모델 모두 특정 지점에서 peak를 찍고 다시 성능이 하락함
Hypotheses for the performance discrepancy
같은 데이터셋으로 학습하는데 왜 on, offline 모델이 성능 차이가 나는지 확인하기 위해 가설 설정
-
Hypothesis 1 : Data coverage
-
online algorithm are better because the dataset coverage is more diverse than the offline dataset
-
offline은 이미 구축된 데이터셋으로만 학습되는 대신, online의 경우 현재 모델로 response sampling, reward model로 분류한 뒤에 학습
-
당연히 데이터 다양성은 online algorithm이 압살
- online버전은 학습하면서 모델이 좀 더 aligment된 답변을 내놓을 것이기 때문
-
-
-
Hypothesis 2 : sub-optimal offlifne dataset
-
offline algorithms are at a disadvantage because the initial preference dataset is generated by a sub-optimal policy
-
preference dataset을 구축할 때 사용된 모델이 sub-optimal하기 때문에, 이걸로만 학습하는 offline 방식은 더 불리할 것
-
offline 방식은 사실상 SFT의 contrastive version으로 볼 수 있음
- 즉, 데이터의 품질에 더 영향을 받을 수 밖에 없다
-
-
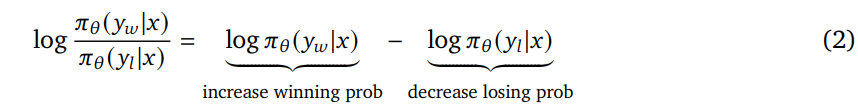
-
Hypothesis 3 : Better classification better performance
-
Offline algorithms typically train policies as classifiers
-
_However, as classifiers they might not be as accurate as proxy preference models (due to effectively different ways to parameterize the classification). _
-
If the accuracy improves, the performance will improve too
-
offline방식은 사실 policy를 preference classifier로 학습하는 것과 같음
-
만약, offline으로 학습한 policy의 classifier성능이 떨어진다면, 당연히 policy 자체의 성능도 향상될 수 없을 것
- 이런 상황이라면, classifier의 accuracy를 올렸을 때, policy 자체의 성능도 올라야 함
-
-
-
Hypothesis 4 : Non-contrastive loss function
-
How much of the performance gap is attributed to the loss function being contrastive, rather than samples being offline?
-
둘의 성능 차이가 sampling아니라 loss function이 contrastive에서 발생하는건지 확인
-
CL의 경우 hard negative와 같은 데이터가 중요한데, 그러면 당연히 계속 데이터를 sampling하는 online방식이 효과적일 것
-
SFT로 loss식을 바꾸면 on,off 성능차가 줄지 않을까?라는 의문에서 시작된 가설
-
-
-
-
Hypothesis 5 : Scaling policy is all you need
-
Scaling policy size upwards is all you need to bridge the gap between online and offline algorithms
- 모델 사이즈를 키우면 on,off 성능 차가 줄지 않을까?
-
** 실험 세팅
-
controlled setting to study KL vs. performance trade-off
-
한정된 세팅에서 실험하기 위해 D_{golden}을 학습 데이터셋으로 사용
-
scaling experiment을 제외하고는 policy와 proxy preference model로 Large T5X(with 770MM params)을 사용
-
learned policy와 SFT policy의 거리를 측정하는 메트릭으로 KLD(sft,learned policy)를 사용
-
-
supervised fine-tuning
-
SFT시, (x,y_w), (x,y_l)을 모두 데이터셋으로 사용
-
모델의 퀄리티를 향상시키는걸 목표가 아니라 RLHF의 시작을 보장하기 위한 용도
-
현실적인 상황을 가정
-
-
-
evaluation
-
2048에 대한 prompt에 대해 fixed policy baseline에 대한 win rate를 평가지표로 사용
-
fixed policy는 golden preference model를 바탕으로 online algorithm으로 학습한 모델
-
win rate는 golden preference model이 결정
-
-
hyper-parameter
-
baseline
- lr : 1e-5, beta : 0.1, gradient step : 4k
-
offline algorithm
- lr : (3e-6, 1e-5, 3e-5), beta : (0.1, 0.5, 1), training step : (4k, 20k steps)
-
Investigating the hypotheses
Hypothesis 1 : Data coverage
: on, off의 성능 차는 데이터의 다양성에서 기인할 것
⇒ online 학습에서 사용되는 데이터셋을 shuffle, 이를 바탕으로 offline 학습을 해보자
(shuffle안하면 online과 똑같음)
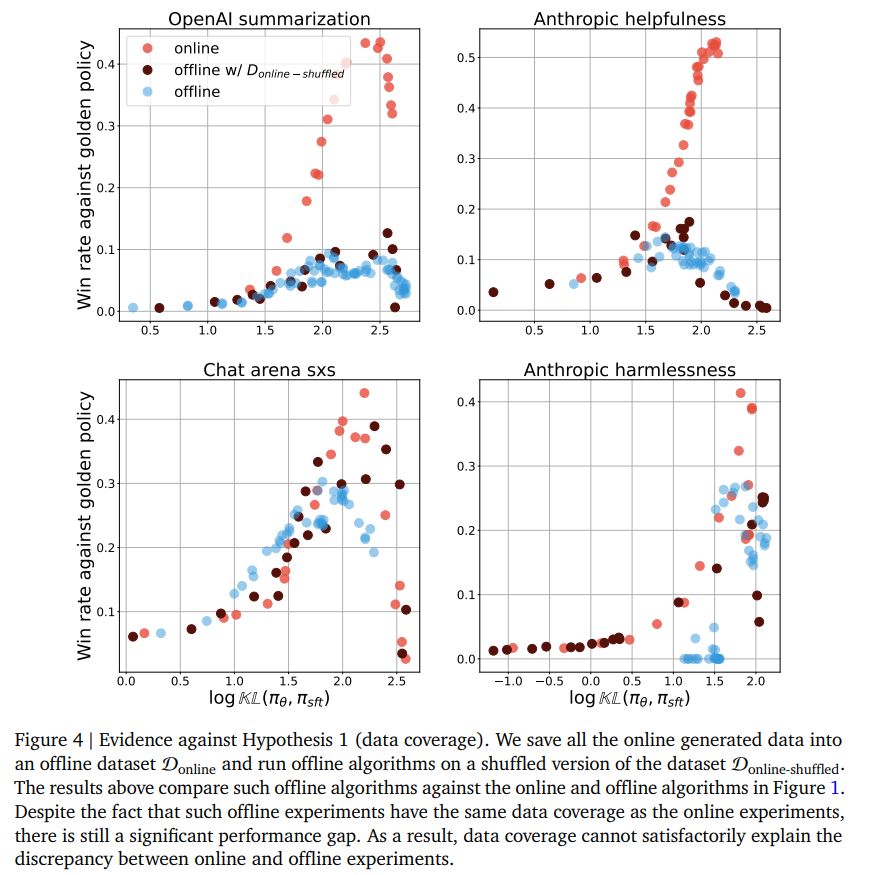
-
offline with d_online-shufflfe이 offline에 비해 근소한 성능 향상을 보였으나, 기존과 큰 차이 없었음
-
그나마 Chat arena에서 준수한 성능을 보임 → data coverage가 충분하면 data order는 크게 중요하지 않다..(고 하기엔 사실 online dataset을 활용하는거 자체가 현실성이 없음 ㅎㅎ…)
-
shuffle을 덜하면 성능이 향상됨
-
→ (민진생각) 모델의 상태에 알맞는 학습 데이터를 제공하는 것이 젤 중요한거 같음
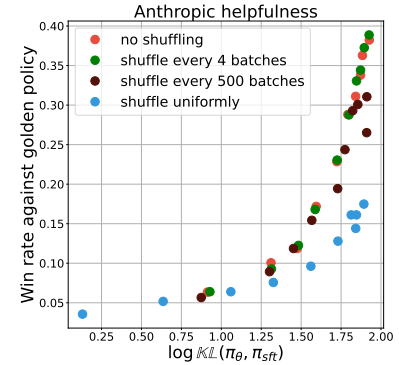
- 결론 : data coverage때문은 아님
Hypothesis 2 : Sub-optimal offline dataset
: offline dataset이 sub-optimal해서 offline 성능이 낮은 것이다
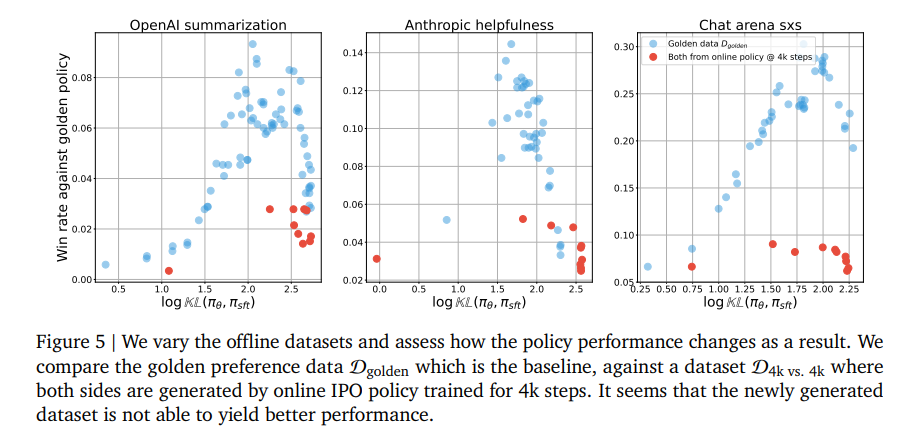
-
red dot : online policy로 4k step만큼 학습한 모델로 response sampling, golden preference로 다시 라벨링한 데이터로 학습
- 기존의 golden dataset에 비해 좀 더 tricky한 데이터라고 볼 수 있음
-
실험 결과, 성능에 도움 안됨
Hypothesis 3 : Better classification, better performance
: preference classification을 잘하면, policy의 성능이 높을 것이다
→ 1) proxy preference model이 policy를 classifier로 쓰는 것보다 높은 classification 성능을 보일 것
2) online과 offline의 성능 차이는 이러한 classification accuracy의 차이에서 기인했을 수도 있다
** policy는 preference classifier라고 볼 수 있음
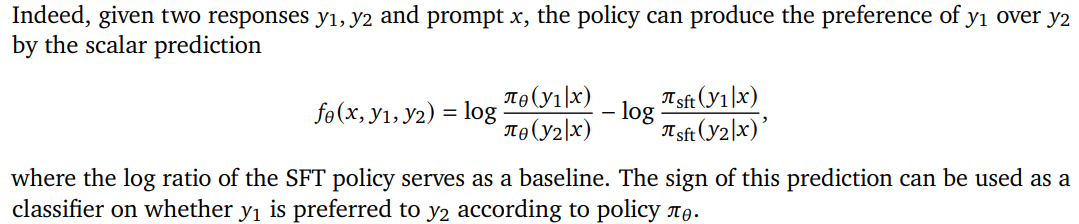
**preference model은 policy를 classifier로 쓰는거보다 더 expressive version이라고 볼 수 있음
왜지??? 그냥 likelihood가 아니라 score를 학습하도록 해서? 잘 모르겠다…
각 response r(x,y)마다 single scalar를 부여
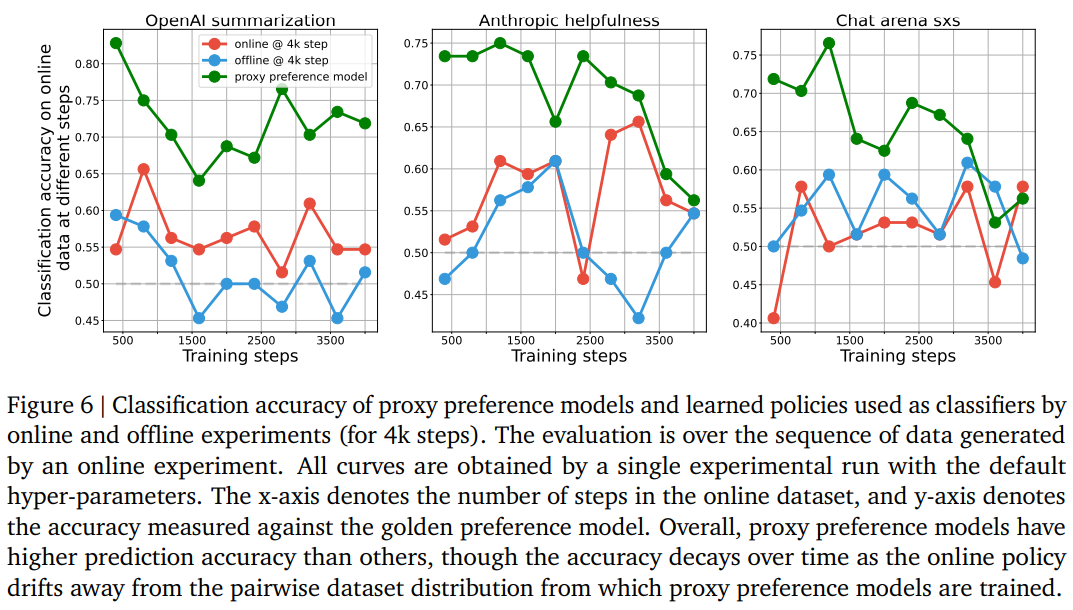
-
실험 세팅
-
proxy preference model : online에서 사용되는 reward model
-
online@4k, offline@4k : policy를 classifier로 사용한 경우
-
각 학습 스텝에서 나오는 online dataset으로 classifier의 성능을 측정
-
-
실험 결과, 학습할수록 on-policy dataset이 기존의 preference dataset과 멀어짐
→ proxy preference model 성능이 하락
→ 맨 처음 실험 장표에서 봤던 online algorithms의 over-optimization 문제를 부분적으로 설명
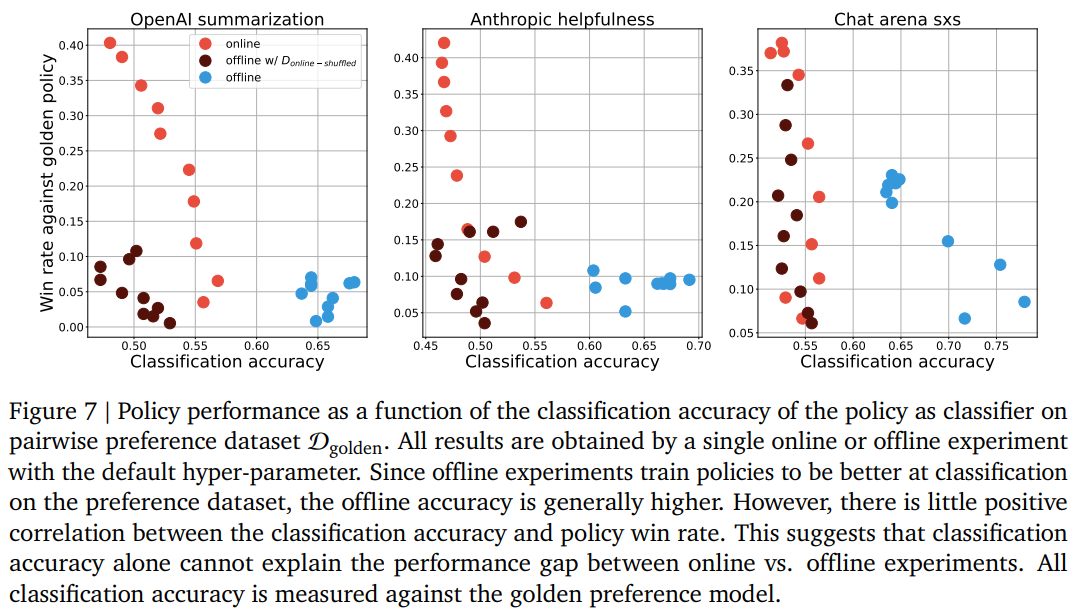
-
classifier 성능에 따른 policy자체의 성능(win rate)에 관한 장표
-
실험 결과, classifier의 성능과 policy 자체의 성능은 큰 연관성이 없었다..
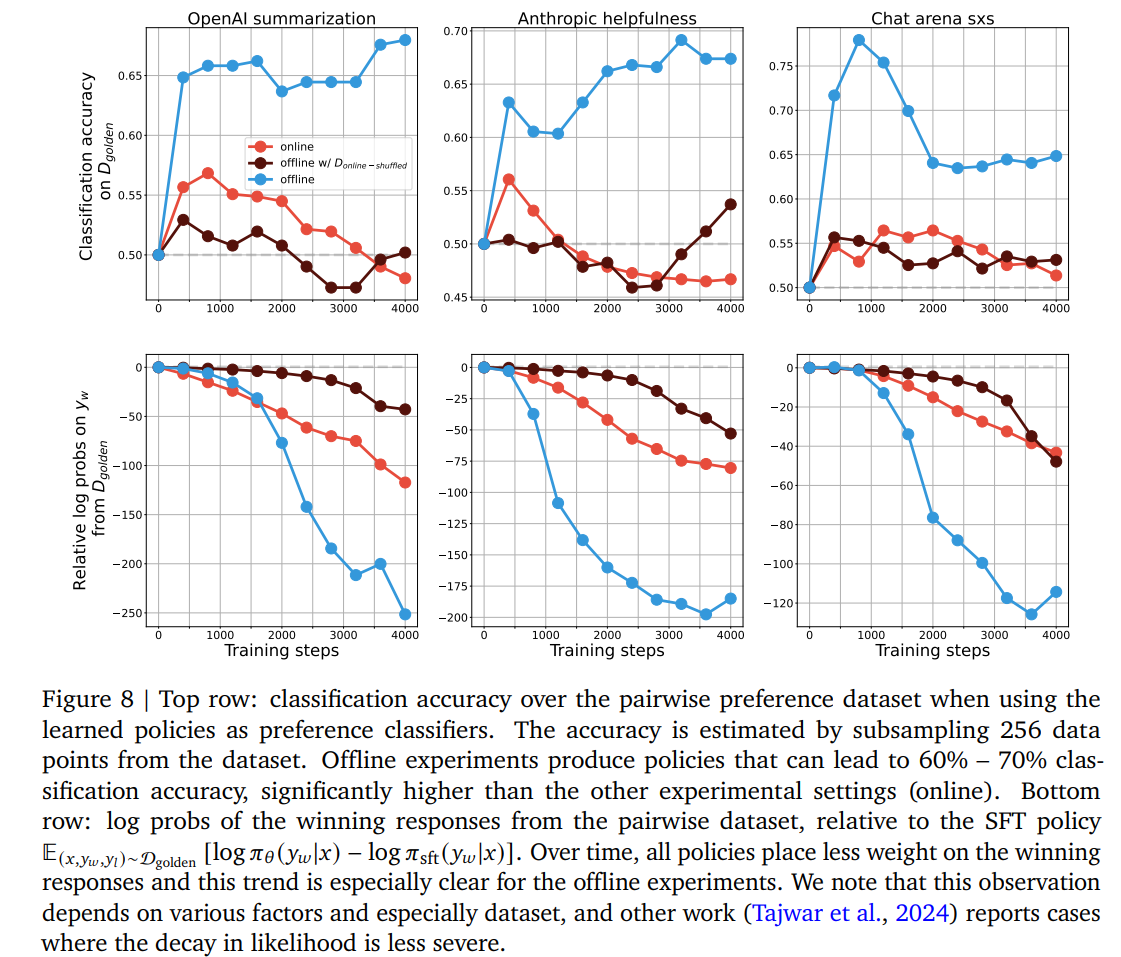
-
각 방법론의 학습 정도에 따른 classifier 성능과, D_golden에서 y_w의 relative log probs를 측정
-
log probs of the winning reponses from the pairwise dataset, relative to the SFT policy
-
\mathbb{E}{(x,y_w,y_l)\sim D{golden}}[log\pi_{\theta}(y_w x)-log\pi_{sft}(y_w x)]
-
-
(figure 8, top row) online의 classification accuracy가 낮은 것을 확인할 수 있음
- online의 경우 계속 data distribution이 이동
→ 고정된 분포(D_{golden})에 대한 classification은 낮지만 generative는 상대적으로 잘됨
-
(figure 8, bottom row) offline방식의 경우 winning response의 logit을 높이는 방식이 아니라 둘다 logit을 낮추되, losing response의 logit을 훨씬 크게 낮추는 방식으로 학습
-
물론 likelihood가 낮아진다고 해서, offline algorithm이 학습에 실패했다는 것은 아님
- 단지 offline optimization은 offline dataset에서 샘플링 된 winning response쪽으로 더 확률이 커지도록 확률 분포를 움직이는 게 아니라는 뜻
-
→ 우리가 일반적으로 생각하는 것보다 더 간접적으로 optimize..
- online 방식의 경우 현재 정책에서 발생할 가능성이 높은 응답만 관찰, offline과 다른 최적화 과정을 거친다는 것을 알 수 있음
Hypothesis 4 : Non-contrastive loss function
: off가 on보다 성능이 낮은 이유는 loss function이 contrastive 구조이기 때문
→ 데이터의 품질에 더 많은 영향을 받음
⇒ loss fuction을 SFT느낌으로 바꿔서 실험해보자

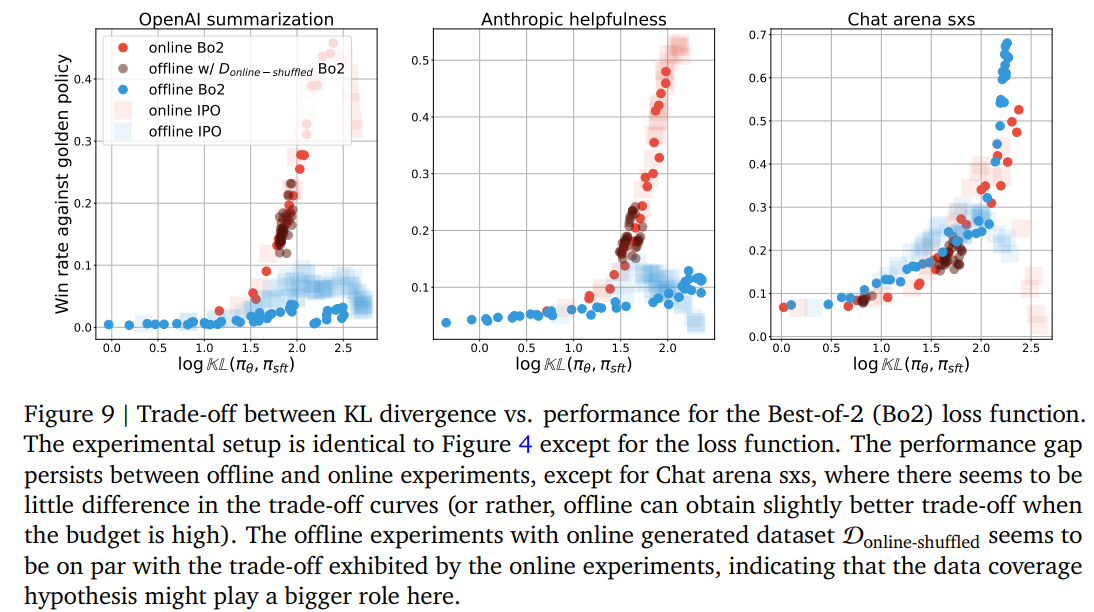
-
Bo2에서도 on,offline의 성능 차이는 비슷
- 다만 Bo2에선 data coverage를 높이면 성능이 향상됨
-
chat arena sxs에서는 Bo2를 사용한 on, off성능이 유사
→ winning response에 대한 SFT만으로도 성능을 충분히 낼 수 있음
Hypothesis 5 : Non-contrastive loss function
: policy model을 scaling up → 3B, 11B로도 학습 (자원때문에 batch size 낮춤)
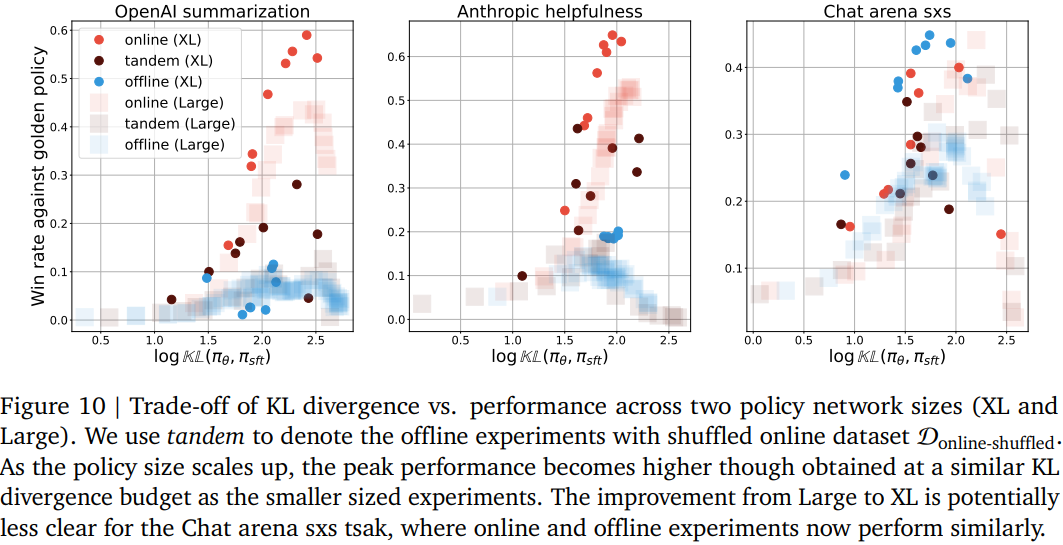
-
scaling up하면 model의 peak성능이 높아지긴 함
-
scaling up해서 실험한 결과, 모델이 작을 때와 유사하게 overoptimization문제를 발견
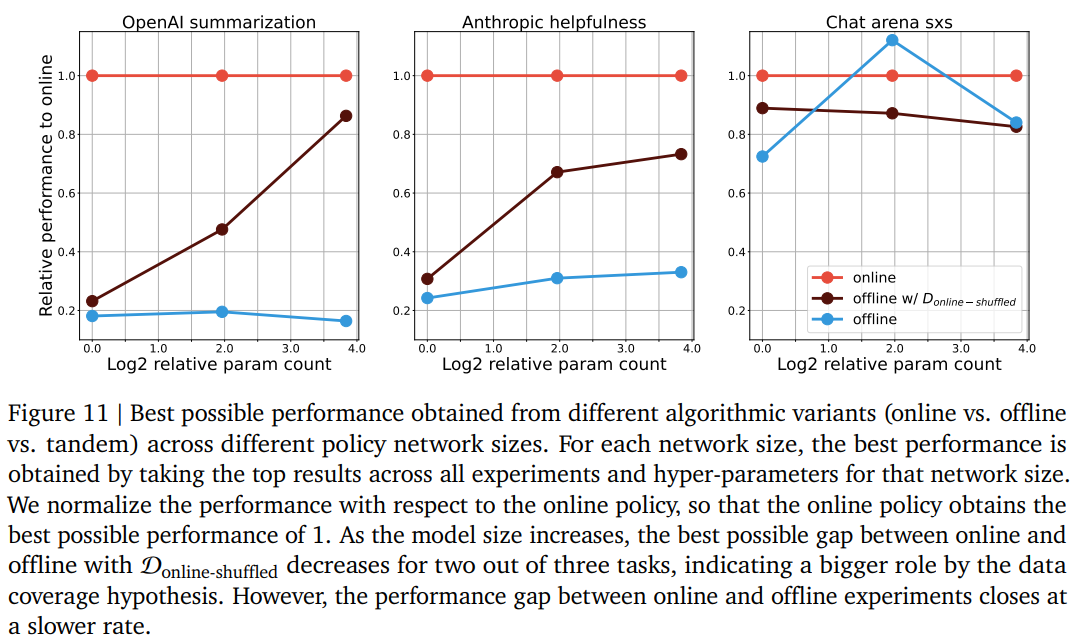
-
모델 크기를 키웠더니 offine with D_online-shuffle 성능이 크게 향상되긴 함
- 모델이 커지면 on,off 성능 차이를 data coverage로 설명할 수도 있다!
Making the dataset more on-policy improves offline learning
어떻게 데이터셋을 구축해야 offline learning의 성능을 향상시킬 수 있을까? 에 대한 ablation study
- 3가지 버전의 데이터셋을 구축
- : 각각의 데이터셋은 D_golden에서 prompt를 샘플링, 버전에 맞는 모델로 response sampling, golden preference model로 라벨링
-
구축한 후 D_golden과 비교
-
D_sft vs 800 : Two sides of the responses are generated by the SFT policy and the online algorithms’ learned policy at 800 step
-
D_800 vs 4k : Two sides of the responses are generated by the online algorithms’ learned policy at 800 step and 4k step
-
D_4k vs 4k : Two sides of the responses are both generated by the online policy at 4k step
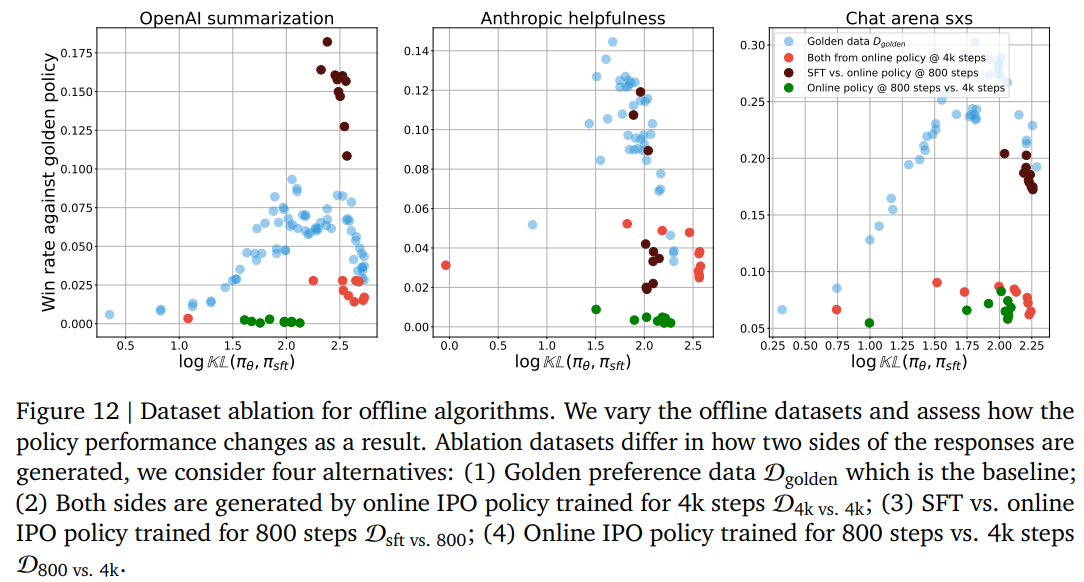
-
실험 결과, 학습데이터가 어느정도 SFT와 분포가 유사해야 잘 작동
- 분포가 offline초기 단계와 비슷해야 좀 더 on-policy와 유사하게 작동하기 때문으로 추정
-
응답 간의 퀄 차이만으로는 성능이 향상되지 않았음
Summary
-
Online과 offline의 성능을 budget 측면에서 비교했을 때, online이 성능이 우월
- on-policy data generation이 학습 효율 향상의 핵심인 것으로 추정됨
-
요즘 하도 다양한 RL방법론이 등장하고 있어서, 이들 사이에 차이가 발생해 성능이 차이나는지 분석하는 것도.. 좋을듯