Unveiling the Generalization Power of Fine-Tuned Large Language Models
논문 정보
- Date: 2024-03-19
- Reviewer: 전민진
- Property: ICL, Generalization, Fine-tuning
Abstract
-
LLM은 다양한 task를 수행할 수 있는 능력이 있음이 밝혀졌고, 이러한 모델을 domain-specific dataset에 fine-tuning했을 때 fine-tuning을 하지 않았을 때 보다 좋은 성능을 보임
-
finetuning이 LLM의 generalization ability에 내재적으로 어떤 영향을 끼치는지 알아보고자 함
-
5가지 task의 다양한 데이터셋을 활용해서 실험 진행, 결과는 다음과 같음
-
generation task 혹은 classification task에 fine-tuning을 했을 때를 비교해보면, 모델의 generalization ability가 달라짐
-
classification task finetuned → test generation task를 했을 때는 성능이 박살
-
classsification으로 finetuning한 모델은 동일 task, out domain dataset에 대해서도 성능이 잘 나옴
-
generation에 finetuning한 모델은 동일 task, out damain에 대해 transfer가 잘 안됨
-
기타 등등..
-
-
-
generation task에 한해, fine-tuning시 ICL 전략을 곁들이면, 기존의 fine-tuning에 비해 모델의 generalization ability가 향상될 수 있음
Introduction
-
이전에 fine-tuning을 했을 때 모델의 generalization ability에 관한 여러 연구들이 존재
-
이전에 multi-task fine-tuning이 LLM의 zero-shot과 ICL 능력을 향상시킨다는 연구가 있었음
- 즉, seen task뿐만 아니라 모델의 내재된 학습 능력도 향상시킴
-
classification task에서 OOD generalization의 관점에서, few-shot fine-tuing과 ICL은 유사한 수준의 generalization ability를 보인다는 연구도 있었음
-
fine-tuning은 모델을 task-specific한 format으로 한정시켜서, 다른 새로운 태스크에 대한 adaptability를 타협한다는 연구도 존재
-
-
본 논문에서는 task-specific한 fine-tuning이 어떻게 LLM의 generalization ability에 영향을 끼치는지에 대한 연구를 진행
-
특히 in-domain(train dataset과 다르면서 유사한 데이터)과 out-domain으로 나눠서 모델을 평가
-
fine-tuning이 모델의 ICL 능력에 미치는 영향에 대해 분석
-
-
모델의 일반화 성능을 높이기 위해, ICL 전략을 fine-tuning에 덧붙인 방법론을 추가적으로 실험
Related Work
-
ICL은 모델의 내재된 parametric knowledge를 극대화, context를 이해해 답변을 생성하도록 함
-
FT와 ICL은 specialization과 generalization사이의 trade-off 관계를 조절
-
specialization → finetuning, generalization → ICL
-
FT는 모델은 특정 태스크에 한정해 높은 성능을 내도록 모델의 generalization ability를 제한
-
ICL은 모델의 broad applicability를 유지하면서도 특정 task에 대해서 suboptimal한 성능을 보임
-
-
few-shot FT와 ICL은 OOD test set에 대해 유사한 generalization을 보여줌
- 하지만 large-set feintuing은 ICL 능력을 감소시킴
-
이전에도 fine-tuning동안 in-context example를 사용하는 것이 length generalization에 도움이 된다는 연구가 있었음
⇒ 이를 확장해서 본 연구에 적용
Evaluation Design
-
task-specific한 fine-tuning이 LLM의 generalization ability에 끼치는 영향을 분석
-
same task, In-domain datasets
-
같은 태스크면서 동일한 혹은 유사한 domain의 데이터셋으로 평가
-
XSum → XSum, XLSum
-
-
same task, out-of-domain dataset
-
같은 태스크지만, train dataset과 다른 domain의 데이터셋으로 평가
-
XSum → PeerRead
-
-
different tasks
-
학습시 사용한 데이터셋과 다른 태스크로 평가
-
XSum → Socialqa (summarization → question generation)
-
XSum → Amazon (summarization → sentiment classification)
-
-
-
Evaluation Benchmarks
-
Generation Tasks
-
Summary Generation
- XSum, XLSum, CNN/DailyMail, PeerRead
-
Question Generation
- Socialqa, Tweetqa, Sciqa
-
-
Classification Tasks
-
Sentiment Classification
-
AmazonFood review, SST2, Yelp
-
positive, negative로 분류
-
-
Paraphrase Detection
-
Paws, QQP, STS-B
-
yes, no로 분류
-
-
Natural Language Inference
-
MNLI-1, MNLI-2, RTE, GPTNLI
-
entailment, neutral, contradiction로 분류
-
-
-
-
Experimental Setup
-
Model : Llama-2-7b
-
Metrics : ROUGE-L for generation task, Accuracy for classification task
-
Training Details
-
finetune llama-2-7b using varying size : 2000 4000 6000
-
classification같은 경우 predefined label의 확률을 바탕으로, 높은 것을 prediction으로 사용
-
하이퍼파라미터로 epoch 2, AdamW, learning rate 0.002 사용
-
generation length는 60으로 설정
-
-
Results and Findings
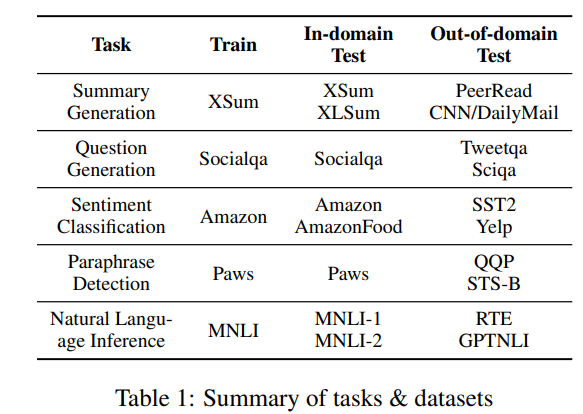
- Same Task , In-domain Datasets
-
전반적으로 ICL보다 finetuning 모델의 성능이 좋음
-
단, Amazon과 AmazonFood 제외
- 이미 Llama-2 모델이 sentiment analysis를 잘하기 때문에, 오히려 fine-tuning이 overfitting 혹은 conflicting training data의 효과를 일으켜 해가 되는 것으로 추정
-
-
fine-tuned LLM에 In-context example을 주는 것의 무의미한 경우가 많음
-
저자들은 “fine-tuning이 모델의 0-shot in-domain generalization을 강화”한다고 봄
-
단, ICL example을 inference시 큰 도움이 안되는 것으로 보았을 때, large set fine-tuning은 모델의 ICL능력을 제한한다고 봄
-
fine-tuning시 사용한 학습 데이터의 수가 성능에 직결되진 않음
-
(뇌피셜) just ICL로 잘 풀리는 task와 안 풀리는 task 차이가 큰듯
- NLI, Paraphrase Detection, Question generation
-
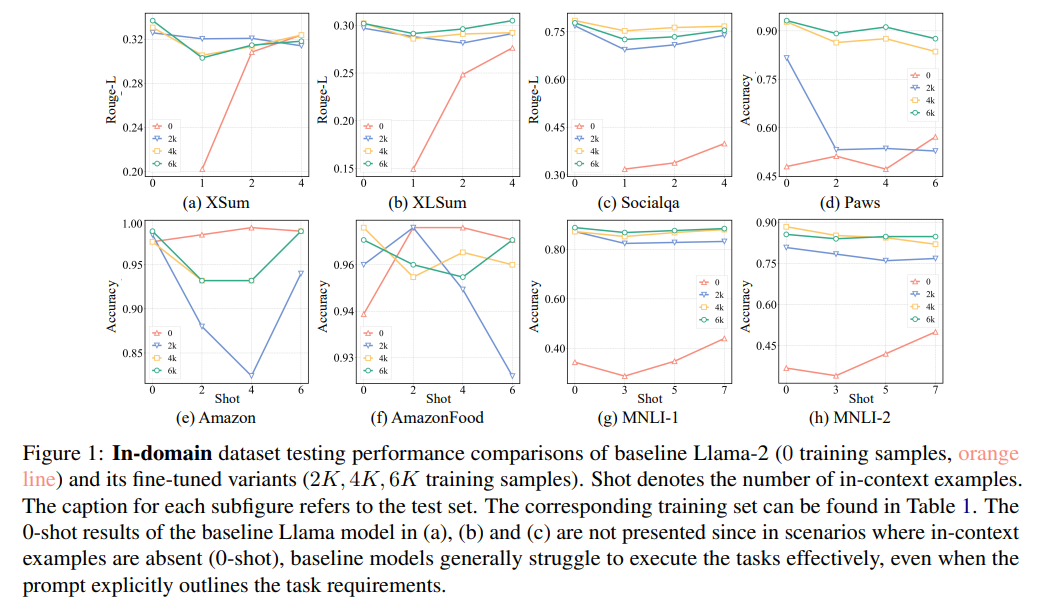
Same Task, Out-of-domain Datasets
-
In generation task, ICL > fine-tuning (a,b,c,d)
-
In classification task, ICL < fine-tuning (e,f,g,h,i,j)
-
classification에선 finetuned model의 generalization 성능이 좋지만, generation에선 좋지 못함
-
이는 output space의 제약 여부에서 기인한 것으로 추정.
- classification의 경우 domain은 달라도 같은 predefined label을 사용해 adaptation이 잘 되지만, generation의 경우 training set과 test set의 분포가 크게 달라서 adaptation이 잘 되지 않는 것 같다고 주장
-
-
(뇌피셜) 여기선 NLI를 ICL이 특히 못하는걸 볼 수 있음
-
QQP는 paraphrase detection인데 ICL 성능이 선방인거 같기도.. 아닌거 같기도..
-
question generation(Sciqa)의 경우 in-domain에선 fine-tuned성능이 높았지만, out-domain에선 fine-tuned성능이 크게 하락하면서 ICL이 더 나은 일반화 성능을 보임
- 확실히 생성 태스크는 fine-tuned모델의 generalization ability가 상당히 낮음
-
-
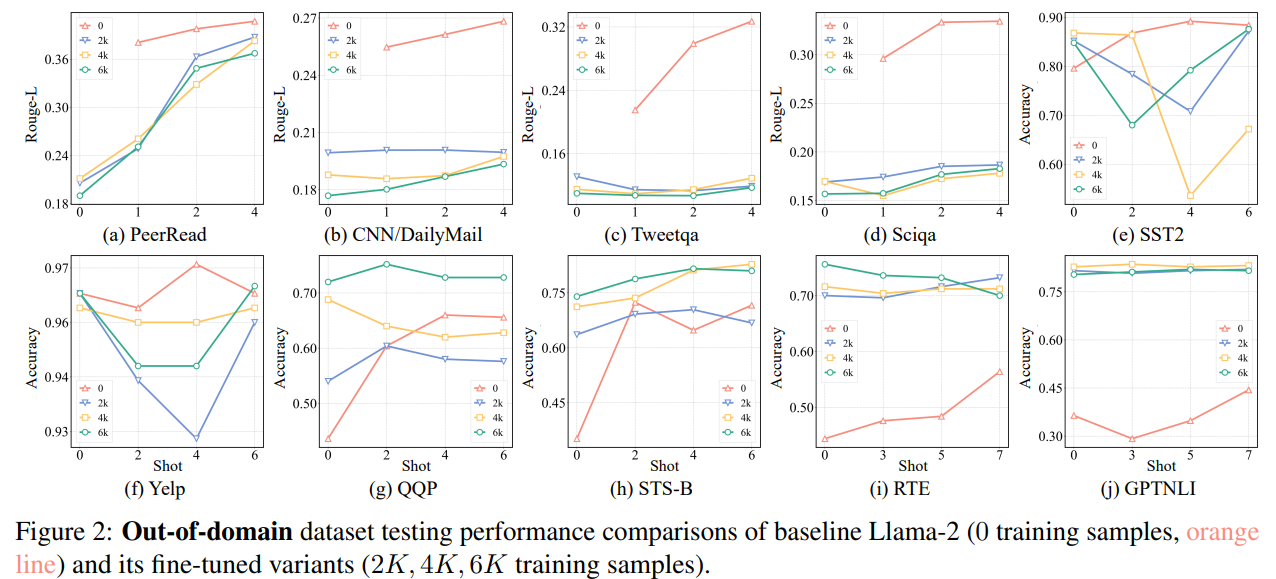
Different Tasks(2K로 학습)
- 첫번째 줄은 각 task에 대한 prompt의 시작이 모두 ###으로 동일할 때, 두번째 줄은 task마다 prompt의 시작 토큰을 다르게 설정했을 경우
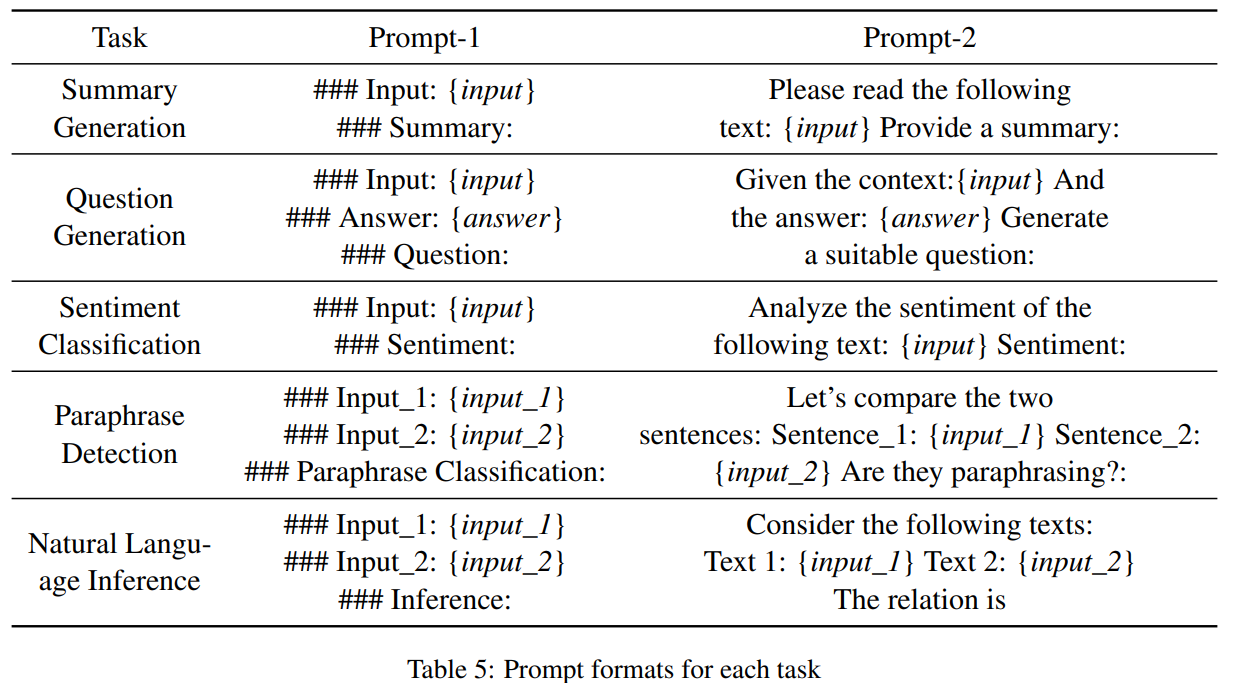
-
classification에 fine-tuned model은 generation task에 일반화가 안됨
-
d,e,i,j를 보면 amazon, mnli, paws로 학습한 모델은 성능이 땅바닥에 붙어있음
-
이는 이미 이전에 predefined label을 생성하도록 학습되어, coherent text 생성과는 잘 align이 되지 않기 때문
-
-
classification task로 평가할 때 prompt에 영향을 많이 받는다는 것을 볼 수 있음(a→f, b→g, c→h)
-
(민진) cross task setting에서 NLI, Paraphrases Detection(애매)를 제외하고는 ICL이 finetuned model보다 성능이 높음
- 확실히 finetuning은 양날의 검인듯.. 애초에 그걸 목적으로 고안된 방법론이기도 하고..
-
FTICL
-
fine-tuning할 때 ICL처럼 input을 주는 방법
-
1 or 2 in-context examples + input → output
-
2000개의 sample로 학습
-
-
Same Task (for generation task)
-
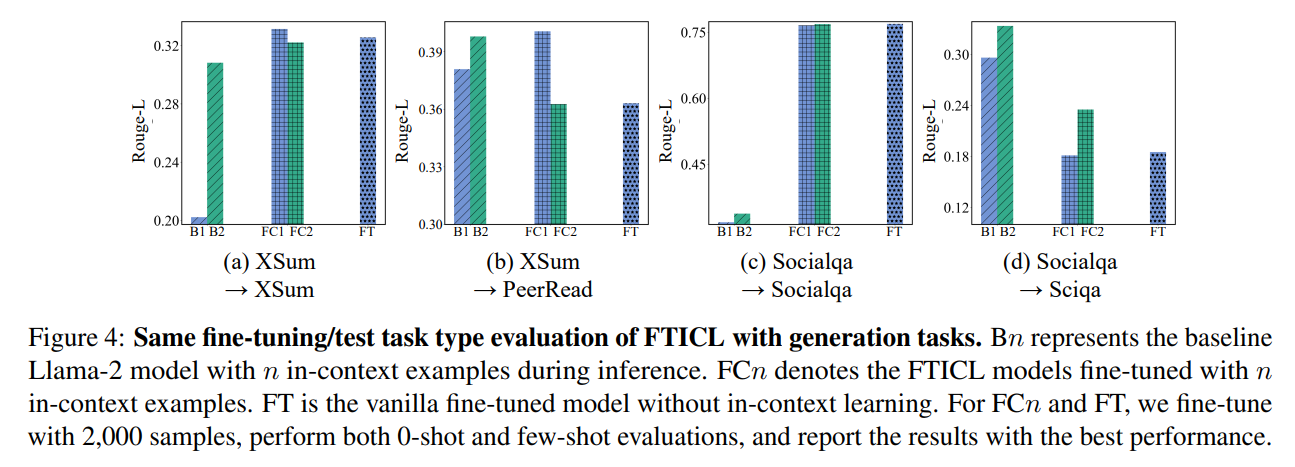
- B1,2 : 일반 ICL setting에서 1,2 shot을 의미(cross in context example을 주는건 아닌듯)
- FC1,2 : 학습할 때 In-context example을 1,2개 준 모델
- FT : 일반 fine-tuning
- **확실히 generation task에서 FT보다 FTICL의 out-domain 성능이 탁월**
- 저자들은 FTICL이 FT보다 모델의 학습한 capability를 유지하도록 함으로써, generation task에 대해 catastrophic forgetting을 줄이기 때문이라고 생각
- 걍 말을 붙인듯.
- Cross Task
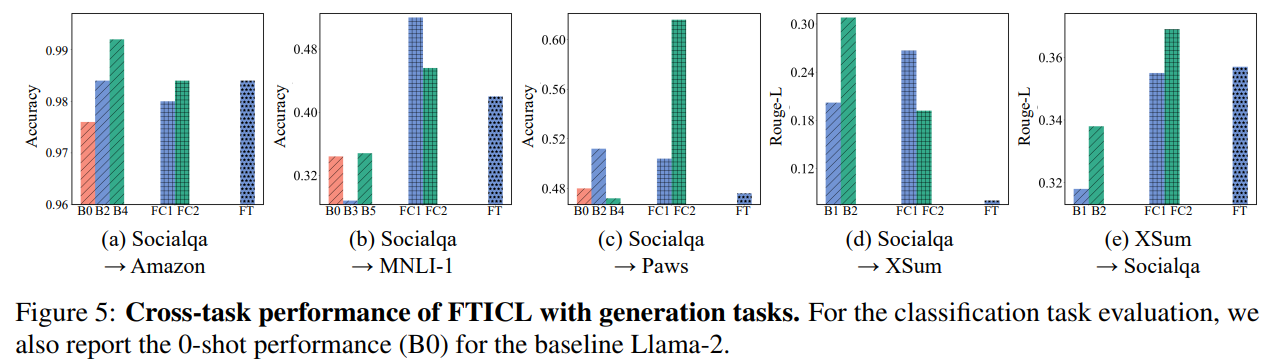
- **cross-task performance의 경우에도, FT보다 FTICL(FC)의 성능이 높음**
-
Potential Reason
-
왜 FTICL이 LLM의 일반화 성능을 강화하는지 대해 분석해보고자 함
- 가설 : FTICL이 FT보다 원래의 LLM의 파라미터에서 덜 바뀌는 경향이 있음
-
두 finetuned model사이의 평균 parameter weight차이를 계산..
-
socialqa에 대해 학습한 경우 : FTICL(7.95e-5) vs FT(8.65e-5)
-
XSUM에 대해 학습한 경우 : FTICL(8.03e-5) vs FT(1.0e-4)
-
⇒ in-context example이 새로운 태스크를 풀 때, 기존의 knowledge를 최대한 활용하도록 하기 때문!으로 해석..
- FTICL on Classification Tasks
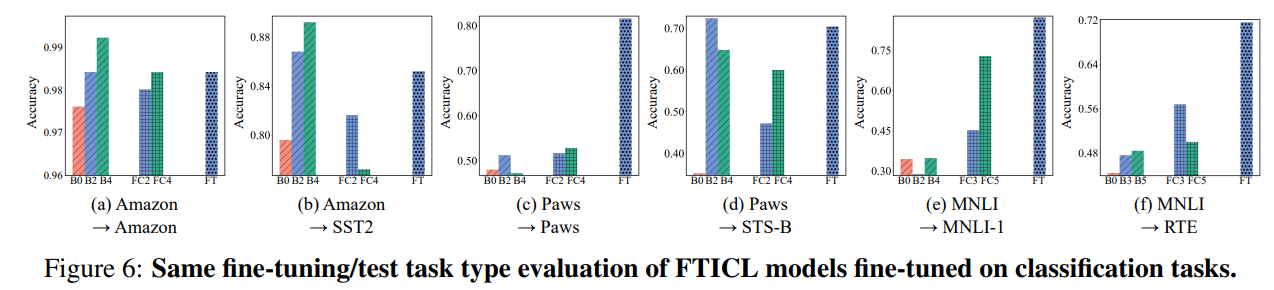
- in-domain setting에서 FTICL보다 FT가 성능이 높음(a,c,e)
- out-domain setting에서도 FTICL이 FT보다 generalization 성능이 높지 않음(b,d,f)
- 저자들은 이는 classification task에서는 in-context example에 민감하기 때문이라 주장
- 또한 학습 시, FTICL의 loss가 FT보다 훨씬 높았고, 이는 model이 lazy(학습을 적극적으로 안함)하기 때문이라 주장
- 이미 example에서 label이 다 나와있기 때문에, 학습하기 보다는 단순히 label을 copy하는거 같다고 함
- (뇌피셜)classification에서는 ICL이 특히 못하는 task를 제외하고는 ICL이 더 나은듯.
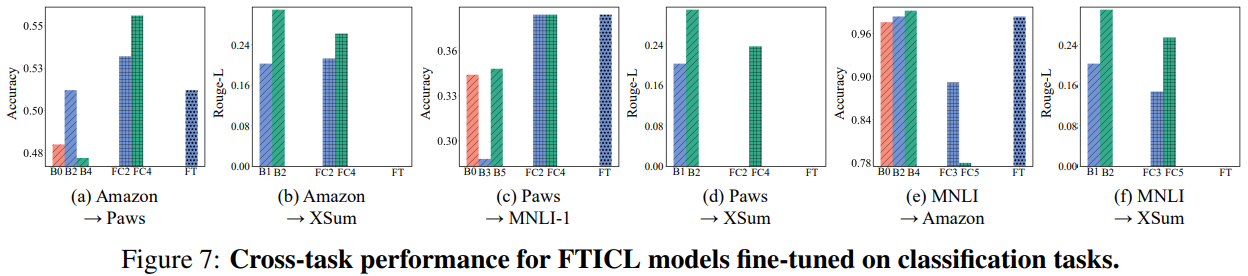
- 같은 classifcation task끼리는 FT도 은근히 adaptation이 되는데(a,c,e), 확실히 아예 결이 다른 task(generation)일 경우에는 하나도 성능이 나오지 않음(b,d,f).
- 반면 FTICL은 전반적으로 FT보다 cross task adaptation 능력이 출중(b,d,f)
- 위에서 언급했던 output space specialization issue를 완화해 그런 것으로 추정
- 왜지? 어차피 output은 predefined label이도록 학습했는데, test때 in-context example을 준다고.. 해결..?
Conclusion
-
generation task 혹은 classification task의 특성에 따라 finetuning 후 finetuned model의 generalization ability가 다른 양상을 띔
-
FT시 input을 ICL처럼 주는 FTICL방법이 generation task에서 모델의 generalization ability를 향상시킴
민진 정리
-
finetuning은 모델의 generalization ability를 저하시킨다
- 특히, generation task로 finetuned model 경우, domain이 달라질 경우 성능이 엄청나게 저하됨
-
Cross task setting의 경우 어지간한 finetuned model보다 ICL setting의 성능이 높다
- 단 NLI 제외
-
finetuning할 때 input을 ICL처럼 주면, (generation task한정, classification은 애매) same task&out domain setting과 cross task setting에서 성능이 높아진다.
- 즉, 그냥 finetuning하는거보다 generalization ability가 높아짐
총평
-
문제 자체는 흥미로운데, 실험 결과에 따른 해석이 너무 자의적이라고 생각
-
finetuning이 생각보다 generation task에서 일반화가 안되는게 신기했음
-
ICL.. 살짝 무시했었는데.. 몇몇 task를 제외하곤 뛰어난 방법론이었다..